A Novel Key Features Screening Method Based on Extreme Learning Machine for Alzheimer’s Disease Study
 Jia Lu
Jia Lu Weiming Zeng
Weiming Zeng Lu Zhang
Lu Zhang Yuhu Shi
Yuhu Shi- 1Laboratory of Digital Image and Intelligent Computation, Shanghai Maritime University, Shanghai, China
- 2Basic Experiment and Training Center, Shanghai Maritime University, Shanghai, China
- 3College of Information Engineering Shanghai Maritime University, Shanghai, China
The Extreme Learning Machine (ELM) is a simple and efficient Single Hidden Layer Feedforward Neural Network(SLFN) algorithm. In recent years, it has been gradually used in the study of Alzheimer’s disease (AD). When using ELM to diagnose AD based on high-dimensional features, there are often some features that have no positive impact on the diagnosis, while others have a significant impact on the diagnosis. In this paper, a novel Key Features Screening Method based on Extreme Learning Machine (KFS-ELM) is proposed. It can screen for key features that are relevant to the classification (diagnosis). It can also assign weights to key features based on their importance. We designed an experiment to screen for key features of AD. A total of 920 key functional connections screened from 4005 functional connections. Their weights were also obtained. The results of the experiment showed that: (1) Using all (4,005) features to diagnose AD, the accuracy is 95.33%. Using 920 key features to diagnose AD, the accuracy is 99.20%. The 3,085 (4,005 - 920) features that were screened out had a negative effect on the diagnosis of AD. This indicates the KFS-ELM is effective in screening key features. (2) The higher the weight of the key features and the smaller their number, the greater their impact on AD diagnosis. This indicates that the KFS-ELM is rational in assigning weights to the key features for their importance. Therefore, KFS-ELM can be used as a tool for studying features and also for improving classification accuracy.
Introduction
Alzheimer’s disease (AD) is a neurodegenerative disease. Compared to cognitively normal individuals, the AD patient’s brain undergoes morphological or functional changes. For example, Kazemifar et al. (2014) found significant atrophy of the temporal cortex in AD patients. Supekar et al. (2008) used resting-state fMRI to find reduced local efficiency of functional brain networks in AD patients. Buckner et al. (2009) used resting-state fMRI data to find that the distribution of core nodes in the functional brain network overlaps highly with the brain regions where Aß amyloid is deposited in AD patients. It means that the brain connection hub area is vulnerable to receive attacks. Zhou et al. (2012) used resting-state functional brain networks to predict the course of developmental changes in AD pathology. These studies above not only provide experimental evidence for the brain region disconnection hypothesis of AD from the perspective of functional integration, but also provide an explanation for the abnormalities in functional integration of the AD brain.
The AD Neuroimaging Initiative (ADNI), led by Dr. Weiner, was launched in 2004. This is a long-term research plan jointly composed of several institutions. It integrates the database of multi-center and cross-disciplinary longitudinal studies carried out by various methods. Such as clinical cognitive function evaluation, neuroimaging examination, and detection of molecular biological markers of cerebrospinal fluid and blood (Susanne et al., 2005). Its primary goal is to explore the patterns of relationships between clinical, cognitive, imaging, genetic and biomarker features as the disease progresses. It also has the goal of establishing standardized methods for imaging/biomarker collection and analysis, and ultimately for use in clinical research.
In 2004, Huang et al. (2004) proposed the Extreme Learning Machine (ELM). ELM generates random input weights and uses the Moore-Penrose pseudo-inverse (MPP) to calculate the output weights. It is a feed-forward neural network based on randomization(RFNN). The RFNN was introduced by Schmidt et al. (1992) and Suganthan and Katuwal (2021). Methods using random input weights and MPP also include random vector function linked neural networks (RVFL) (Pao et al., 1994), and a method proposed by Guo et al. (1995).
The ELM be widely used in many fields such as disease diagnosis, traffic sign recognition, image quality assessment and so on (Chyzhyk et al., 2015; Huang et al., 2016; Wang et al., 2016). ELM strives to solve the research problems in machine learning fields such as regression, classification, supervised learning and unsupervised learning under a single framework (Huang et al., 2014). From the perspective of learning efficiency, ELM is concise to implement, with extremely high learning speeds and less human intervention. From the perspective of theoretical studies, ELM can still maintain SLFN’s interpolation ability (Huang et al., 2016), general approximation ability (Huang and Chen, 2007) and classification ability (Huang et al., 2012) even in the case of randomly generating hidden layer neuron parameters. From the perspective of structural risk minimization, the VC dimensionality (Vapnik-Chervonenkis dimensionality) of ELM depends on the number of neurons in the hidden layer (Liu et al., 2012). The size of the VC dimensionality can be controlled by adjusting the number of neurons in the hidden layer of ELM, to make a compromise between training error and model complexity, and get the optimal generalization performance. ELM has also been extended to a deep learning model (Tang et al., 2015; Kim et al., 2017), and made a lot of research results.
In recent years, RFNN has also been gradually used for AD studies based on medical images. Sharma et al. (2021) proposed that the FAF-DRVFL method achieved 86.67% accuracy in classifying AD with CN. Malik et al. (2022) proposed the IFRVFL method for diagnosing AD. Its performance is better than standard ELM and RVFL. Lama and Kwon (2021) proposed the ElM+Graph embedding method achieved 90.93% accuracy in classifying AD, MCI, CN. Nguyen et al. (2019) proposed the MVPA+ELM method achieved 98.86% accuracy in classifying AD, MCI, CN. The RFNN is often used as a classifier in these studies. It is mainly used to process selected low-dimensional features. Few studies have used RFNN as a feature screening method.
The ELM classifier has redundant hidden layer nodes when the number of hidden layer nodes is large enough. Rong et al. (2008) proposed the method Pruned-Extreme Learning Machine (P-ELM), as well as Miche et al. (2010, 2011) improved the P-ELM method, which was used to pruning of the hidden layer nodes with the aim of making the ELM classifier more compact, with high speed and more robustness. But it cannot improve the accuracy of the classifier. In ELM classifiers with high feature dimensionality, some input nodes have no positive effect on classification. Useless input nodes are removed using the idea of P-ELM. It can screen features that have an impact on the classification. It may even improve the accuracy of the classifier.
We analyzed the state of machine learning techniques in diagnosing AD (Tanveer et al., 2020). We found no method to prune the network to extract key features. Some of the work involving AD feature extraction (Bi et al., 2018; Richhariya et al., 2020; Hao et al., 2021; Sadiq et al., 2021) have achieved good results in terms of classification accuracy, but none have assigned weights to the importance of these features. In this study, we propose a novel key features screening method based on extreme learning machine (KFS-ELM) to screen key features of AD. It is a data-driven approach that is not based on empirical assumptions or prerequisites. It prunes the ELM classifier to determine the relationship between each feature and AD, screens the key features, and identifies their importance. This will make the key features more intuitive, facilitate the study of the patterns behind AD, and benefit the construction of better classifiers to diagnose AD. The KFS-ELM can be used not only for studying AD, but also for other research fields where the studied subjects have a high dimension of features.
The rest of this article is organized as follows. The section “Materials and Methods” describes the “Brain Functional Connectivity Network,” “ELM,” and “KFS-ELM method.” The section “Experiment” introduces the experimental procedure, experimental environment, data preparation, screening of key features by the KFS-ELM method, and validation of key features. The section “Results” presents the streamlining ability of the KFS-ELM method, the distribution of the screened key features, and the effect of the key features on the classification of the ELM classifier. The section “Discussion” discusses the limitations of the ELM method and the advantages of the KFS-ELM method, and analyzes the key features. The section “Conclusion” summarizes the work of this study.
Materials and Methods
Brain Functional Connectivity
Brain functional connectivity network is a mathematical representation defined by a set of nodes and edges (Rubinov and Sporns, 2010; Liu et al., 2016). These nodes represent brain regions on different scales. The temporal correlations (functional connectivity) between the fMRI time course of these nodes form the edge of the brain’s functional network. The smaller the size of a node, the greater the number of nodes and edges. The more complex the described pattern of neural activity in the brain, the more difficult it is to calculate and analyze. Researchers often divide the brain into regions or nodes by using atlas. automated anatomical labeling (AAL) (Tzourio-Mazoyer et al., 2002) is one of the most commonly used atlas. Templates is one of the most commonly used templates. AAL divides the brain into 116 regions, including 90 regions of the cerebrum and 26 regions of the cerebellum. The feature measures adopted in this paper is the whole cerebrum functional connectivity network. It includes 4005 functional connectivity features.
Extreme Learning Machine
Extreme learning machines belong to single hidden layer feed forward neural networks (SLFNs) and have the characteristics of single hidden layer neural networks. (1) Implement complex nonlinear mapping directly from the input layer. (2) It can provide appropriate classification model for large category data sets. Compared with other single hidden layer neural network models, the speed of model training and classification is faster. Huang and Babri (1998) indicated that the input layer weights and hidden layer bias values of other SLFNS networks need to be iteratively adjusted to fit the current training data. When there are a large number of hidden layer nodes, this calculation can lead to significant computational time consumption (Huang and Chen, 2008; Huang et al., 2011). At the same time, since gradient descent has become an effective method to solve SLFNs, this method not only limits the solving speed, but also can easily fall into the local minimum from the calculation principle of the calculation method. Aiming at the above problems, Huang et al. (2006) proposed the algorithm of extreme learning machine. It transformed the iterative solution method into the solution method of linear equations by randomly specifying the weight and bias values of the input layer, and finally obtained the analytical solution of the network. It can be quickly solved on the premise of ensuring the accuracy of calculation.
Extreme learning machine can be described as: given N arbitrary samples {Xi,ti}, Xi= ∈ Rn,ti= ∈ Rm. For a single hidden layer neural network with L hidden layer nodes, it can be expressed as
Where g(x) is the activation function. Wi=[wi,1,wi,2,…,wi,n] is input weight. βi= is output weight, bi is the bias of the ith hidden layer node. Oj= is output of the sample Xj. The goal of single-hidden layer neural network learning is to minimize the output error, can be represented as
There exist βi, Wi and bi, such that
It can be expressed in matrix form
Where H is the output of the hidden layer node, β is the output weight, and T is the expected output.
In the ELM algorithm, Wi and bi are randomly determined, and the output matrix H of the hidden layer is uniquely determined. The training of the single-hidden layer neural network can be transformed into adding a linear system, Equation (4). And the output weight β can be determined by Equation 7.
Where H† is the Moore-Penrose inverse of H. and the solution norm of is minimal and unique. We solve for to construct ELM.
In this paper, the ELM classifier is constructed by dividing the data set into three sets: training set, validation set, and test set. The training set is used to build enough classifiers. The validation set is used to verify the accuracy of each classification, and find the best ELM classifier. As the input weights of the ELM classifier are randomly generated, its classification accuracy will also vary randomly. To ensure that the classifier has high accuracy, a sufficient number of ELM classifiers need to be trained, until the average accuracy of all classifiers converges. The number of classifiers constructed is Loop, and the average accuracy of ELM classifiers is . The value of the variable Loop should satisfy the constraint of Equation 9, where the parameter p is the allowed fluctuation of the average accuracy. The loop calculation produces 2*Loop accuracies, and the absolute value of the difference between the average accuracies of any consecutive Loop times should be less than or equal to parameter p. The 2*Loop ELM classifiers are validated with the validation set, and the classifier with the highest accuracy is the optimal classifier we are looking for. In this experiment p = 0.15%.
KFS-ELM Method
The main idea of the KFS-ELM algorithm lies in pruning the ELM classifier. Removing input nodes and hidden layer nodes (including the weights connected to them) which have no positive impact with the classification, and keeping the accuracy of the ELM classifier from decreasing on the training and validation sets. The features corresponding to the input layer nodes of the pruned classifier are considered as key features. They are strongly related to the classification. Definition 1: Wi is the diagonal matrix, i ∈ [1,…,n],n is the dimensionality of the subject’s features. Wi satisfies the constraints of rank(Wi) = i, rank(*) denotes the rank of the matrix. Definition 2: βj is the diagonal matrix, j ∈ [1,⋯,L], L is the number of hidden layer nodes of the ELM classifier. βj satisfies the constraints of .
In the ELM classifier the output weight , the input weight W, and the bias b are known quantities. The output weights after pruned can be expressed as . The input weights can be expressed as W⋅Wi. The key feature matrix of the subject can be expressed as Wi⋅X. One Wi corresponds to a group of key features. The pruned ELM classifier can be described by Equation (10) as
g(*) is the activation function. X is the input matrix consisting of the features of the input data set (training set, validation set and test set). X = [X1,⋯,XN], where Xi denotes the feature vector of the ith subject, and there are N subjects. O is the output matrix.O = [O1,⋯,ON], Oi is the label vector output by the ELM classifier, corresponding to a subject. Oi=, there is only one oi,j=1,oi,j ∈ Oi, the others oi,j=0. T = [T1,⋯,TN] is the set of labels corresponding to the data set, where Ti denotes the label vector corresponding to the ith subject. Ti=, there is only one ti,j=1,ti,j ∈ Ti, the others ti,j=0. The accuracy of the ELM classifier can be expressed as Equation 11. ∥*∥ denotes the Modulus of the vector.
In Equation 10, Wi and βj are the variables to be solved, and the other parameters are known quantities. Wi should satisfy inequality (Equation 12). βj should satisfy inequality (Equation 13).
Pruning an ELM classifier obtains a Wi, which corresponds to a set of key features. Pruning enough ELM classifiers will obtain enough Wi. The merge set of W*=∑Wi correspond to the complete key features. It should be noted that the datasets used for validation W* are the training and validation sets and do not include the test set.
KFS-ELM Algorithm Steps
1. Construct an ELM classifier using all the features from the training and validation sets.
2. Prune the input layer nodes and their corresponding output weights in the ELM classifier, which means that keeping βj constant to solve Wi iteratively. The initial values of Wi and βj are nth-order unit matrix and Lth-order unit matrix, respectively, where n is the feature dimensionality of the subject and m is the number of ELM hidden layer nodes. When the inequality (12) is satisfied, take Wi and βj into step 3.
3. Prune the input layer nodes and their corresponding output weights in the ELM classifier, which means that keeping Wi constant to solve βj iteratively. When βj satisfies inequality (13), take Wi and βj into step 2. When Wi and βj satisfy both inequalities (10) and inequality (11), take Wi into step 4.
4. Loop through steps 1-3, find W*=∑Wi. And Construct ELM classifier based on the key features corresponding to W*. When the accuracy of the ELM classifier is no longer increasing, the calculation ends. The features corresponding to the final W* are the key features screened by the KFS-ELM method.
Experiment
Flow of the Experiment
This experiment consists of three parts: data preparation, screen features by using KFS-ELM, test ELM classifier, and validate key features (as shown in Figure 1).
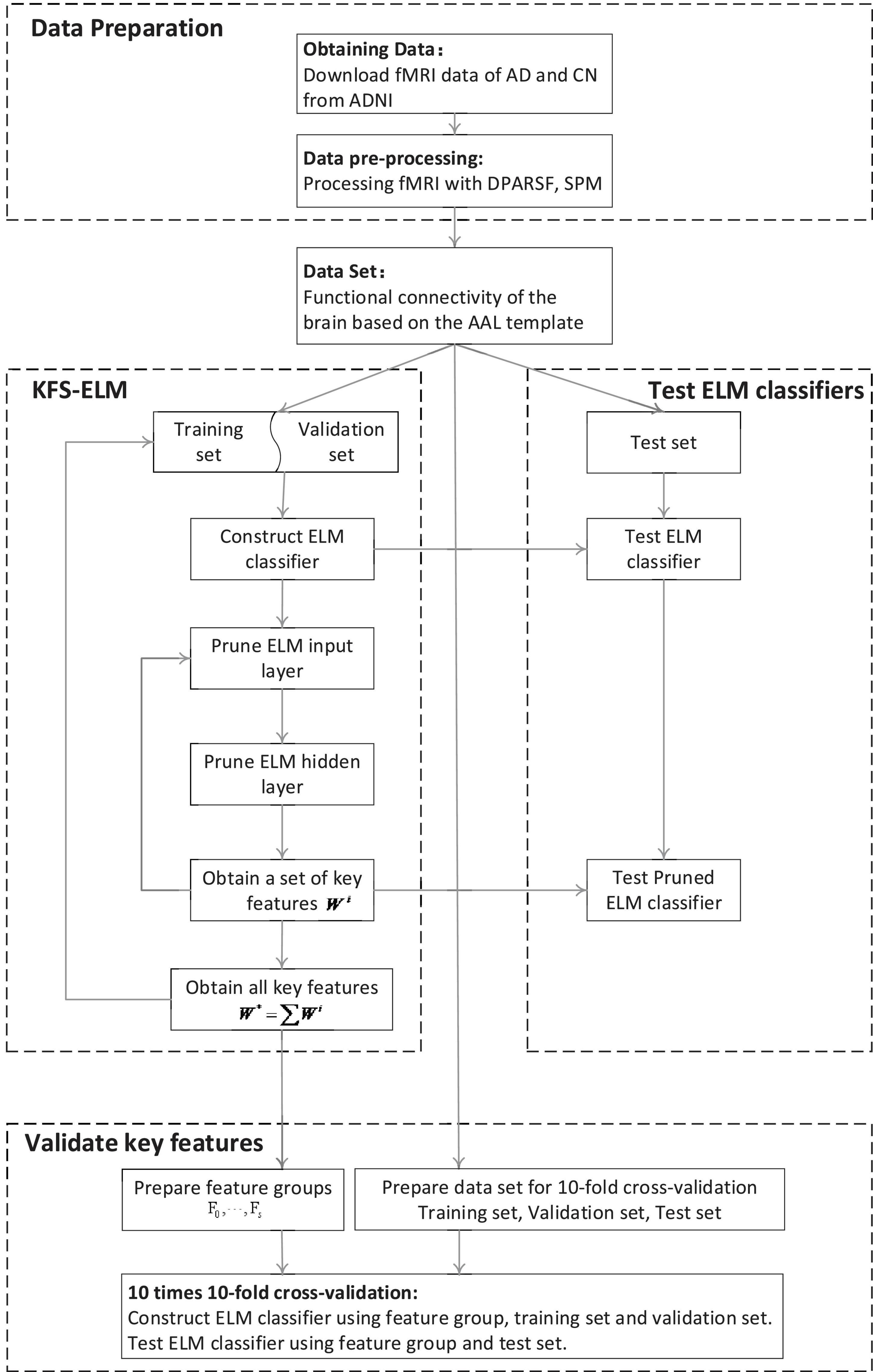
Figure 1. Flow of the experiment.
1. Data preparation: fMRI data for AD and CN are acquired from the ADNI database and pre-processed using DPARSF, SPM to obtain the functional brain connectivity matrix for all subjects.
2. Screen key features using KFS-ELM: Screening for key features which are relevant to the diagnosis of AD.
3. Test ELM classifier: Test the ELM classifier before and after pruning, and observe the change in classifier performance.
4. Validate key features: compare the ability to diagnose AD using the key feature set versus the full feature set. Compare the impact of key features with different weights on diagnosing AD.
Environment of the Experiment
All experiments run on a PC with intel core i7-8700 @ 3.20GHz, NVIDIA GeForce RTX 2080 8GB, 16GB DDR4 3600MHz, 1TB SSD.
Data of the Experiment
The fMRI data used in this paper are all from LONI’s ADNI database ADNI2 project. It included 100 Cognitively Normal (CN) subjects, 49 females and 51 males, with a mean age and standard deviation of 74.09 ± 5.45. And it included 100 Alzheimer’s disease (AD) subjects, 44 women and 56 men, with a mean age and standard deviation of 75.07 ± 7.59. All subjects used the same acquisition parameters. Field Strength = 3.0 tesla; Flip Angle = 80.0 degree; Manufacturer = Philips Medical Systems; Matrix X = 64.0 pixels; Matrix Y = 64.0 pixels; Mfg Model = Intera; Pixel Spacing X = 3.3125 mm; Pixel Spacing Y = 3.3125 mm; Pulse Sequence = GR; Slices = 6720.0; Slice Thickness = 3.312999963760376 mm; TE = 30.000999450683594 ms; TR = 3000.0 ms; The subject data can be downloaded at http://adni.loni.usc.edu.
Pre-processing of Data
The data pre-processing tools chosen for this experiment are ‘‘Data Processing Assistant for Resting-State fMRI Advanced Edition’’ (DPARSF 4.4 Advanced Edition1)(Yan and Zang, 2010) and ‘‘ Statistical Parametric Mapping’’ (SPM122). Remove the first 10 time points for each subject in order to remove the phase where the subject is familiar with the MRI scanner environment at the beginning of the data scan, and where brain activity is not smooth during the noise. Slice Timing and Head Motion correction is performed for each subject, and EPI template is used for standardization. Band-pass filtering is used to obtain signals between 0.01 and 0.1Hz. After processing, the bounding box of all subjects is [-90-126-72; 90 90 108], and the Voxel size is [3 3 3]. And then detrend the signal. The functional connectivity network of the brain is extracted based on the ALL template. Finally, we obtained 100 functional connectivity matrices for each of the two categories of subjects, AD and CN.
Grouping of Data Sets
The 200 functional connection matrices are divided into three groups: training set, validation set, and test set. The ratio of AD subjects to CN subjects within each group is 1:1.
In the KFS-ELM and test ELM classifier sections, the ratio of subjects in the training set, validation set and test set is 90:90:20. The test set is generated randomly. It does not change during the KFS-ELM calculation. The training and validation sets were randomly divided for the construction of each ELM classifier. The training set is used to construct the ELM classifier. The validation set is used to evaluate and find the best ELM classifiers. In the pruning process, both the training and validation sets are used to evaluate the change in the accuracy of the ELM classifiers. Test set for evaluating changes in ELM classifier before and after pruning.
In the validation of key features section, the ratio of subjects in the training set, validation set and test set is 160:20:20.
Construction of ELM Classifier
The training and validation sets are re-divided before each training of the classifier. The number of subjects and the proportion of categories in each set are kept constant. The number of input layer nodes is 4005, corresponding to all functional connections of the cerebrum. In our previous study, we found that the number of hidden layer nodes is positively correlated with the accuracy of the classifier in scenarios with small sample size and high feature dimensionality. The number of hidden nodes is set to 64,000 as the hardware performance allows. Due to the fact that this experiment involves two categories of data, the number of output nodes is set to 2. The convergence precision threshold p = 0.0015. The only things that need to be set manually are the number of hidden layer nodes and the convergence precision threshold. After the ELM classifier has been constructed, it will be tested using the test set.
Pruning of the Input Layer
The pruning of the input layer is actually solving Equation 10 for Wi, While ensuring that it satisfies the constraints of the set of inequality (12). As there are two variables Wi and βj in Equation (10), the value of βj is fixed first when solving for Wi. Due to the fact that the activation functions of the hidden layer nodes are nonlinear and the input layer is fully connected to the hidden layer, pruning the input layer nodes will result in a nonlinear variation in the output of the ELM classifier. Different pruning order or different number of nodes per pruning may screen different input layer nodes. Thus there are various ways of solving Wi. In this experiment, Wi is solved by zeroing the elements on the diagonal of Wi one by one according to their order. that is, a new Wi is generated when the accuracy of the ELM classifier is unchanged or improved (using the training and validation sets) after zeroing an element in Wi. Also because of the nonlinearity of ELM, if one or more nodes are pruned in the input layer pruning process, the pruning process needs to be executed again until no input node can be pruned. For the same reason, if βj changes, it is also necessary to prune the input layer again.
Pruning of the Hidden Layer
In the process of pruning the hidden layer nodes, the hidden layer nodes that have no effect on the accuracy of ELM classifier or improve the accuracy are pruned in turn. And then find βj. Because the ELM output is a linear summation of the hidden node outputs, no iterative computation is required. If any hidden layer node is pruned, the new βj and Wi should be substituted into the process of “ELM classifier input layer pruning” to update Wi again. If no hidden layer nodes are pruned, the pruning process of a single ELM classifier is completed.
Obtain Key Features
A single Wi corresponds to only part of the key features. ELM classifiers constructed by them are also less accurate. As more key features corresponding to W* are available, the higher the accuracy of the ELM classifier constructed using it will be. When the accuracy of the ELM classifier is no longer improved, the corresponding key features become complete.
Validate Key Features
First, set the weights of non-key features equal to 0. A series of feature groups is formed by gradually excluding the features with the lowest weights from all features. We write the feature group as Fi,i = [0,⋯,s], s is the highest weights of key features. Fi is the feature group, containing all features whose weight i. s+1 feature groups will be formed.
Then, redivide the training set, validation set and test set randomly. The ratio of training set, validation set and test set is 160:20:20, and the ratio of AD to CN in each set is 1:1. The data input to the ELM classifier is the features which are selected from each data set base on the feature group Fi.
Finally, the ELM classifier constructed from each group of features is used to validate the feature group classification (diagnostic) ability. 10 times 10 fold cross-validation is performed for each feature group.
Results
According to the KFS-ELM method, the accuracy of ELM classification constructed using the key feature set corresponding to W* is no longer improved when screening to the 17th group Wi. The accuracy of the 17 ELM classifiers is shown in Table 1. The average training accuracy is 100%, the average verification accuracy is 97.84%, and the average test accuracy is 92.35%.

Table 1. Accuracy of ELM trained with full amount of features,
The accuracy of the 17 ELM classifiers after pruning is shown in Table 2. After pruning, the average training accuracy of all ELM classifiers remained 100%. the average validation accuracy increased from 97.84% to 99.8%. And the average test accuracy decreased from 92.35 to 84.71%. The number of input nodes and the number of hidden nodes are drastically reduced. The average number of input nodes decreases from 4005 to 106.24, which is 2.65% of the original number of input nodes. The average number of remaining hidden nodes decreased from 64,000 to 1042.53, which is 1.63% of the original number of hidden nodes.
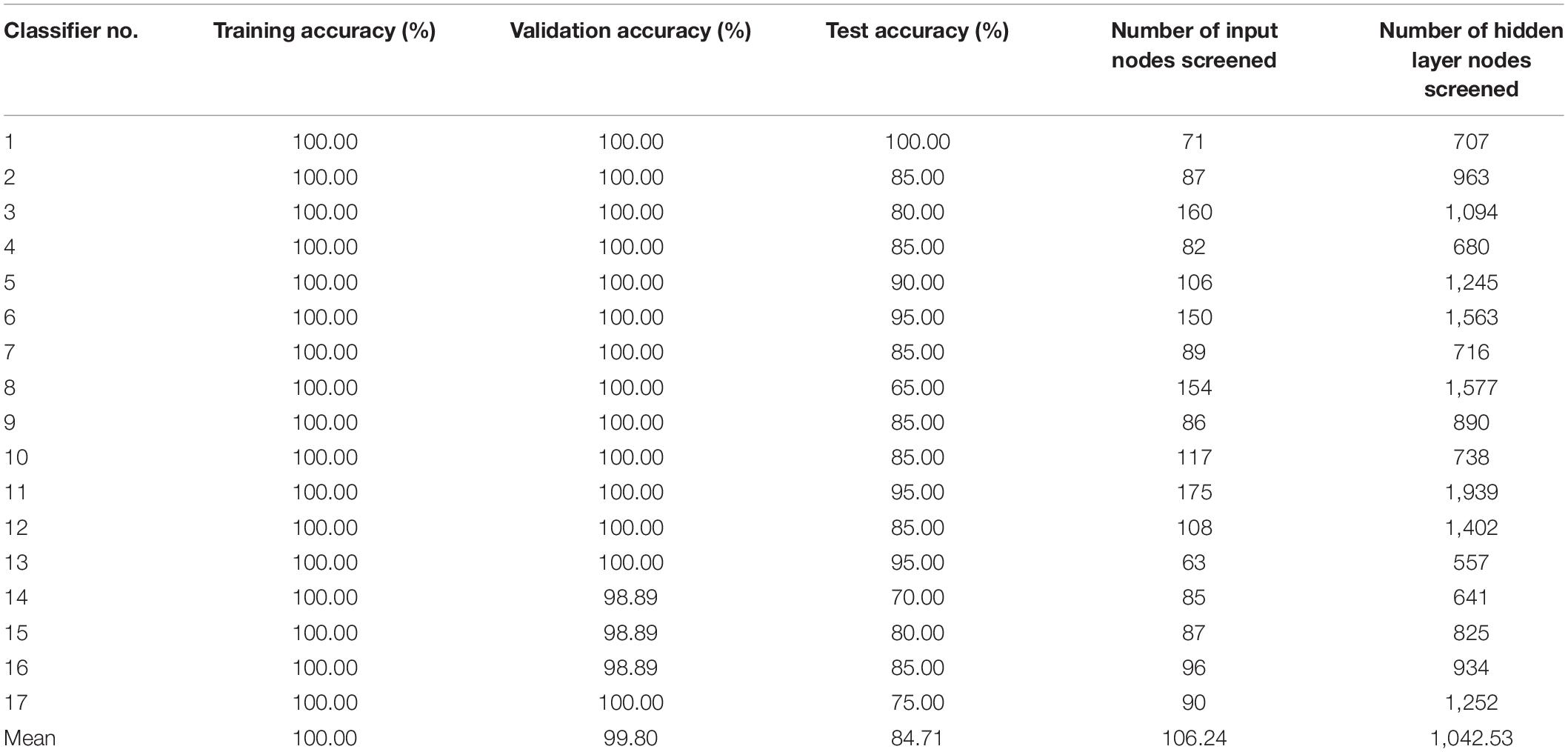
Table 2. Number of nodes and accuracy of ELM classifier after pruning.
The key features corresponding to the pruned ELM classifier are shown in Figure 2 by the functional connectivity matrix. Figures 2A–C are the image representations of the key features (functional connectivity matrix) of the 1st, 2nd, and 3rd ELM classifier, respectively. Figure 2D is the image representation of W*. The horizontal and vertical coordinates of the image correspond to the serial numbers of the 90 brain regions of the AAL template. The colors of the points correspond to the weights of the key features. The total number of key features corresponding to W* is 920. where the highest weight is 12. That is, the intersection of 17 Wi is empty.
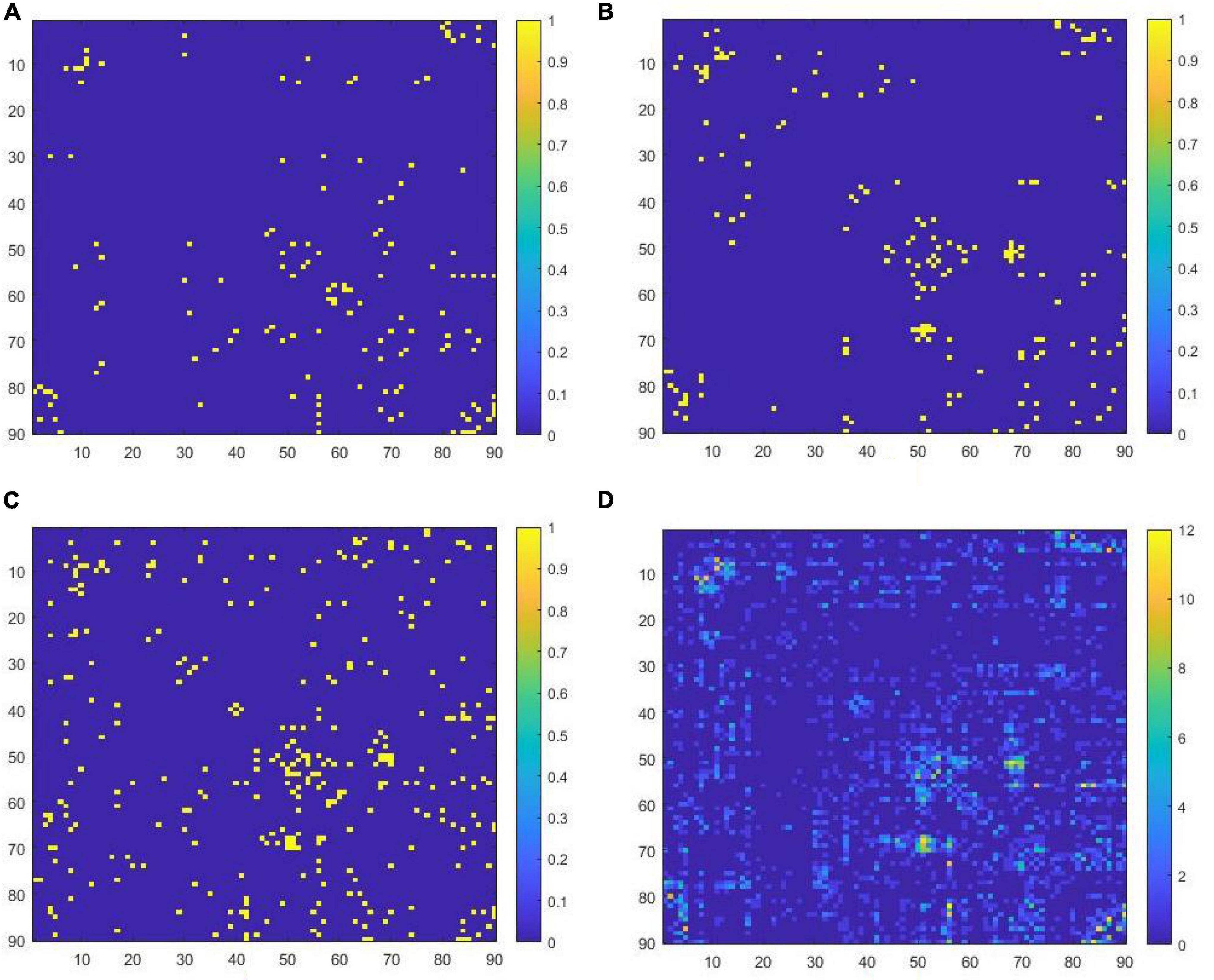
Figure 2. (A) Key features filtered in the first ELM classifier, (B) key features filtered in the second ELM classifier, (C) key features filtered in the third ELM classifier, (D) the concatenated set of all key features.
Table 3 shows the performance of testing the classification (diagnosis) ability of key features with different weights versus full features for AD. Perform ten times 10 fold cross-validation and calculate the average of their accuracy rates. The ELM classifier trained using the full amount of features had a test accuracy of 95.33% with a standard deviation of 0.0035. The ELM classifier trained with all key features (920 features, 22.97% of the total number of features) had the highest test accuracy of 99.20% with a standard deviation of 0.0021. When the number of key features is 199 (4.97% of the total number of features), its test accuracy is 95.24%, which is only 0.09% lower than the accuracy of the full number of features. That is, the number of selected features was reduced from 4005 to 199, and the accuracy of the constructed ELM classifier test did not decrease significantly. When the number of selected features is 45 (1.12% of all features), its verification accuracy can still reach 100%, and the test accuracy is 87.84%. When the selected features are further reduced, the accuracy of the ELM classifier is also further reduced. When the number of selected features is 4 or 1, the ELM test accuracy is close to 50%. It is no longer practical to do classification using only these features.
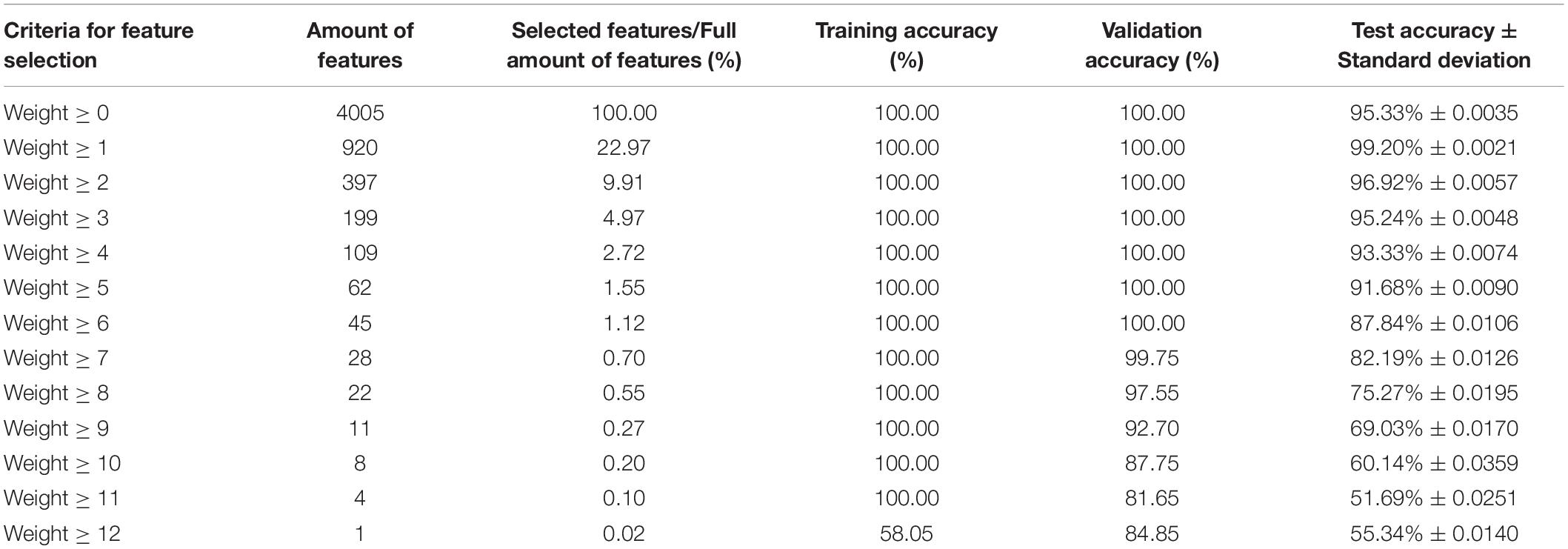
Table 3. Accuracy of constructing ELM classifier with full amount of features or key features with different weights.
Considering the visualization effect, this paper takes 45 key features with weights greater than or equal to 6 as an example to show their distribution. Table 4 shows the features (functional connectivity) and their corresponding weights. Table 5 shows the brain regions corresponding to the features and their weights. Its weight is the sum of the weights of all functional connections involving that brain region. Figure 3 is a demonstration of these key features. The visualization tool used is BrainNet Viewer (Xia et al., 2013).
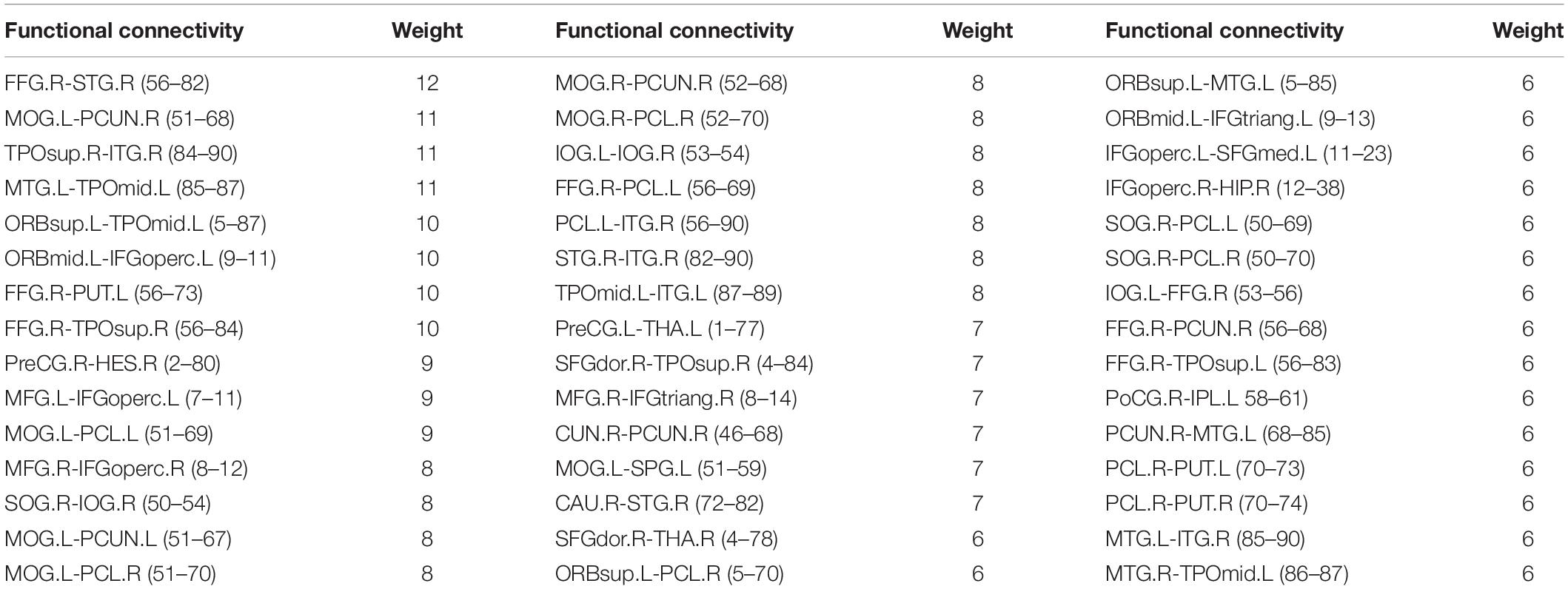
Table 4. The key features with weight value greater than or equal to 6.
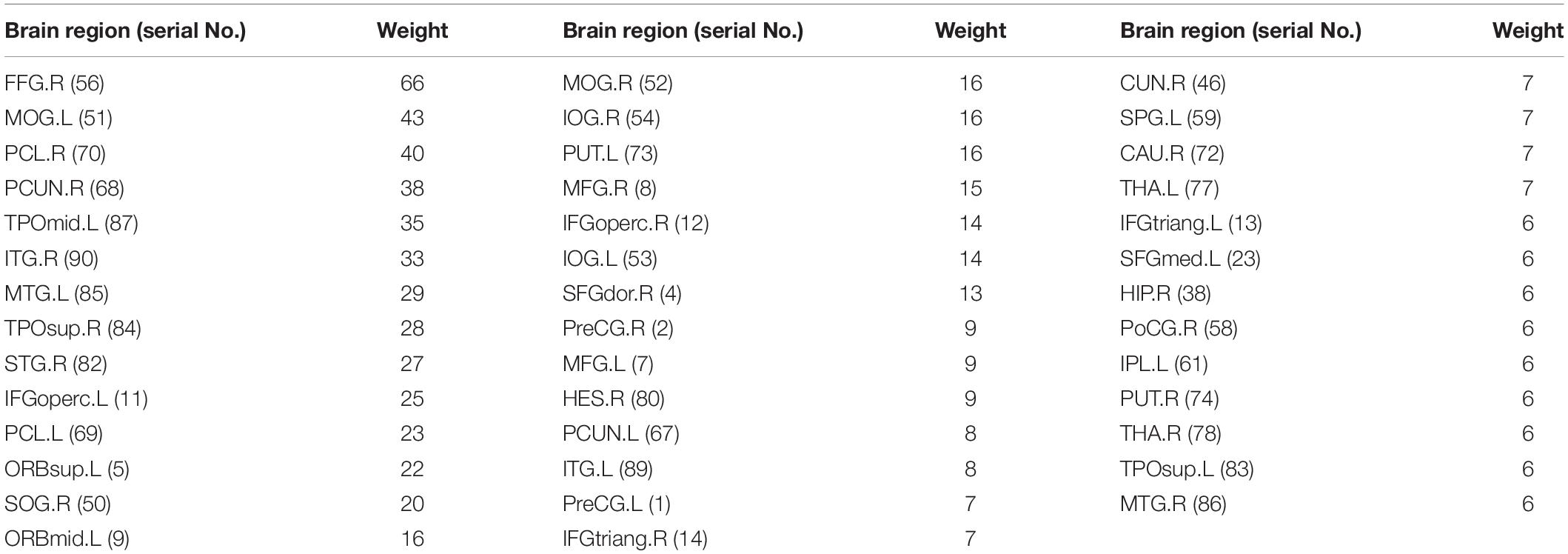
Table 5. The brain regions corresponding to the key features with weight greater than or equal to 6.
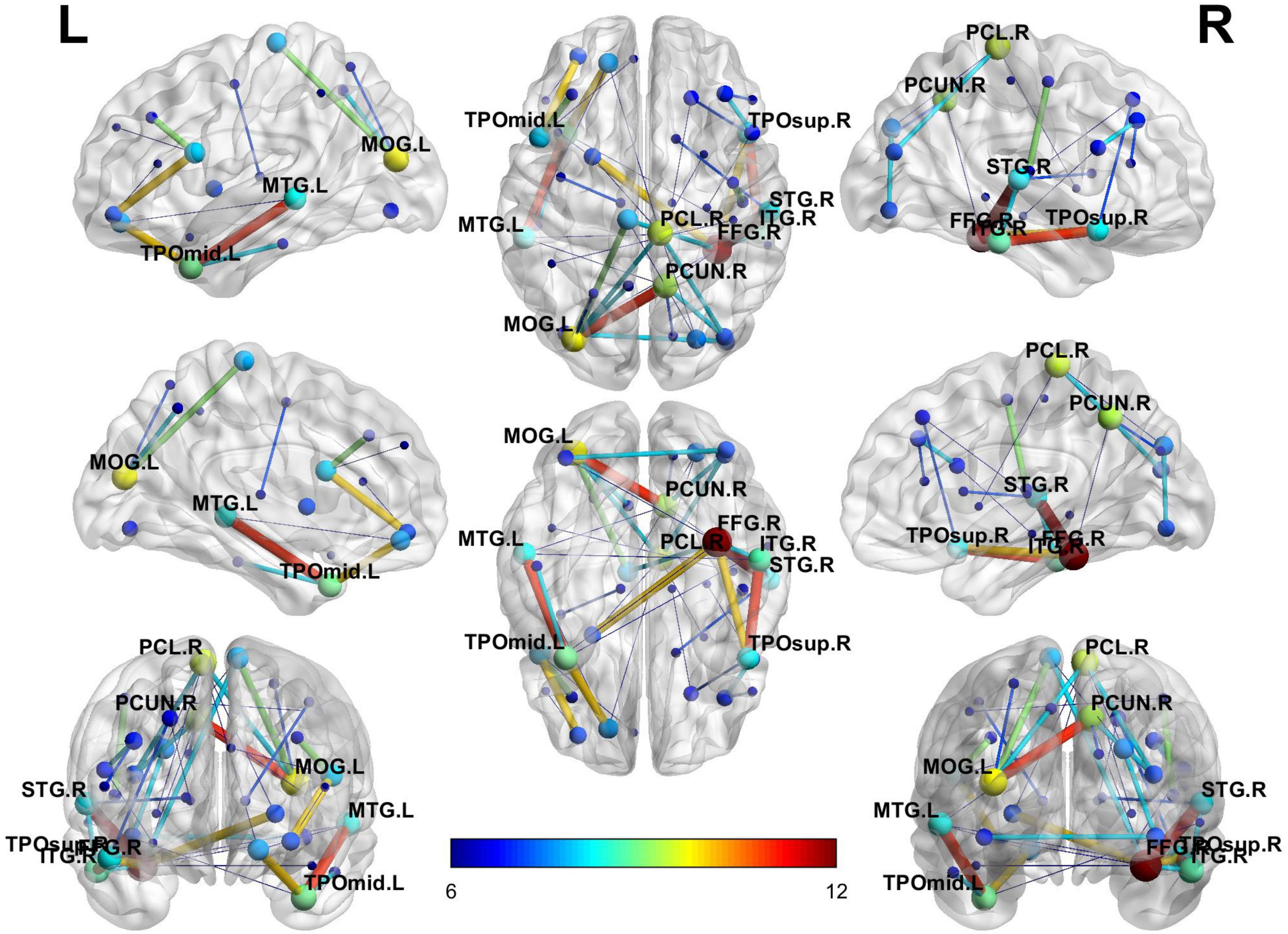
Figure 3. Full-view diagram of key features with weights greater than or equal to 6.
Discussion
Comparing the ELM classifier before and after pruning (according to Tables 2, 3), a significant decrease in the number of input nodes was observed. The average number of input nodes decreased from 4005 to 106.24. Its corresponding number of key features accounts for 2.65% of the total number of features. According to the constraints of Inequality (12) and Inequality (13), removing any of the key nodes will lead to a decrease in the accuracy of the classifier. It shows that all these features are important. The KFS-ELM feature screening experiments yielded 17 groups of key features whose intersection is empty. This indicates that the key features that contribute differently in different classifiers. Therefore, the union of these key feature groups can describe AD more comprehensively.
The performance of the full amount of features and key features in building ELM classifiers was tested in the experiments. The ELM classifier trained using the full amount of features (4,005 features) has a test accuracy of 95.33%. The ELM classifier trained using all key features (920 features) has a test accuracy is 99.20%. It indicates that, training the ELM classifier with fewer features results in higher test accuracy, the 3,085 (4,005 − 920 = 3,085) features that were excluded had a negative effect in classification. Therefore, the KFS-ELM is effective in screening key features.
In this experiment, the weights assigned to the features by KFS-ELM are from 0 to 12, and the bigger the weights, the more important they are. In the testing section, we divided the features into 13 groups according to their weights and gradually excluded the group with the lowest feature weights to test the diagnostic ability of the remaining features for AD. For example, in Table 3, the row where “Weight ≥ 1” indicates the diagnostic ability of all key features (excluding features with weights equal to 0) for AD. Comparing the results of “Weight ≥ 0” and “Weight ≥ 1,” the features with weight equal to 0 play a negative role in AD diagnosis. The row where “Weight ≥ 2” indicates that the key features “Weight = 0” and “Weight = 1” are excluded. Comparing the results of “Weight ≥ 2” and “Weight ≥ 1,” we can judge the effect of the “Weight = 1” feature group on the diagnosis of AD. Adding the feature group of “Weight = 1” to the feature group of “Weight ≥ 2” increased the number of features by 523 (920 - 397), and the training and validation accuracy did not change, while the test accuracy increased by 2.28% (99.20 - 96.92%). That is, the 523 features(“Weight = 1”) contributed 2.28% to the test accuracy of AD. In this way, the effect of the features with weight = 10 on the diagnosis of AD can be shown by comparing the experimental results of “Weight ≥ 10” and “Weight ≥ 11.” The feature group with Weight = 10 contributed 6.10% (87.75 - 81.65%) to the validation accuracy and 8.45% (60.14 - 51.69%) to the test accuracy in AD diagnosis. According to this rule, the effect of feature groups with different weights on AD diagnosis was calculated based on the results in Table 3, as detailed in Table 6. In addition, according to Table 3, the accuracy of the training set was 58.05% when “Weight ≥ 12”, which means that the group of features with Weight = 12 is not enough to distinguish AD from normal people, so this result is not adopted as the basis for Table 6. Therefore, in Table 6, the impact of AD diagnosis can only be assessed for the feature groups with weights from 0 to 10.
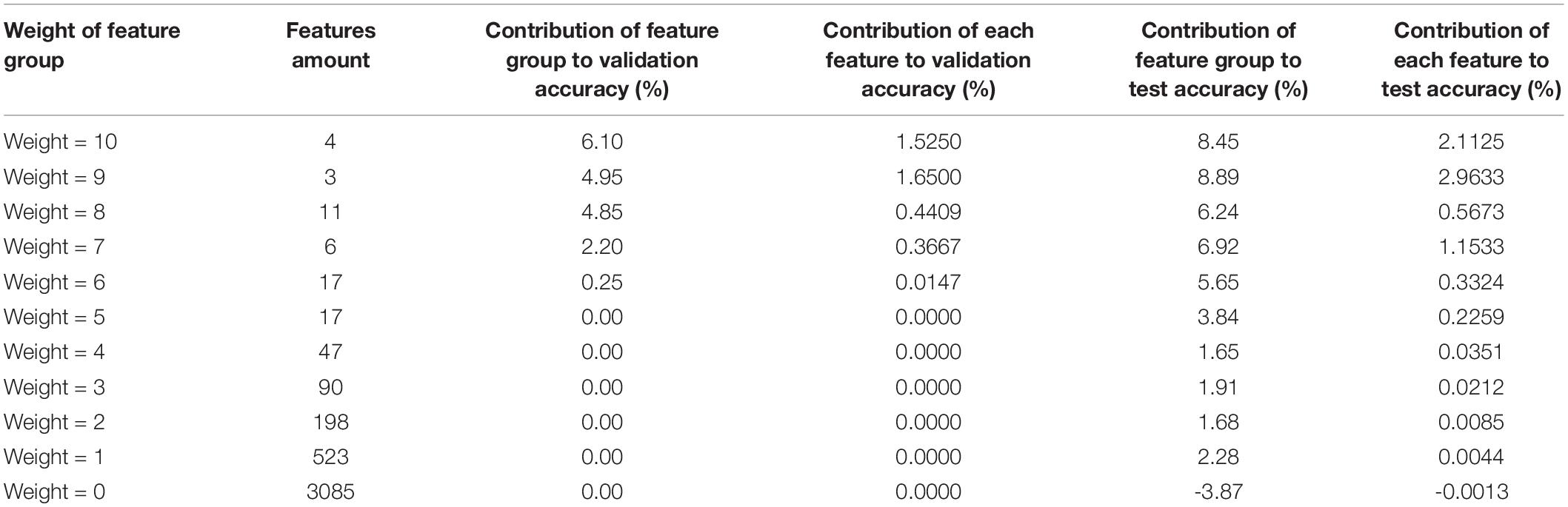
Table 6. Effect of features with different weights on AD diagnosis.
Each row in Table 6 indicates the effect of a key feature group on the accuracy of AD diagnosis for a given weight. The first column indicates the weights of the feature group. The second column indicates the number of features in the group. The third column indicates the contribution of the feature group to the validation accuracy. The fourth column indicates the average contribution of each feature in the group to the validation accuracy. The fifth column indicates the contribution of the feature group to the test accuracy. The sixth column indicates the average contribution of each feature in the group to the test accuracy.
According to Table 6, in terms of the contribution of single feature to the validation accuracy (column 4), basically the higher the weight of the feature, the more it contributes to the AD diagnosis (except weight = 9). In terms of the contribution of single feature to the test accuracy (column 6), basically the higher the weight of the feature, the more it contributes to the AD diagnosis (except weight = 8 and weight = 9). Basically, it can be considered that the higher weight the feature has, the greater contribution it makes to the AD diagnosis.
According to the pattern in column 2 of Table 6, the lower the weight of the feature group, the higher amount of features it contains. However, the group with a weight of 9 has fewer features than expected and the group with a weight of 8 has more features than expected. This also caused the contribution of features to diagnose AD deviated when the weight equals 8 and 9. We consider that this is due to the ELM classifier’s randomness in the utilization of features (refer to Figure 2). There are some deviations in the results of feature screening from the probability distribution of the features. Features with weights of 8, 9, 10, 11, and 12 account for 0.27, 0.07, 0.10, 0.07, and 0.02% of all features, respectively, and there are only 22 of these features in total, accounting for 0.55% of the total number of features. If there is a deviation of 0.1% in the feature screening, the results may deviate from the expected pattern, as it happens in Table 6 when the weights are equal to 8 and 9. When the number of features in the feature set is greater than or equal to 17 (0.42% of the total features), no such deviation occurs.
We have taken four references with similar work for comparison, as shown in Table 7. They all use functional connectivity as a feature measure, and they all screen for features as well. All the five studies used different feature screening methods. Bi et al. (2018) obtains feature sets by clustering, without assigning weights. It selects a class with the best classification performance from a large number of classes. Nguyen et al. (2019) set thresholds on the original values of the features. These values do not have a clear relationship with classification. Sadiq et al. (2021) and Hao et al. (2021) have in common that the features are given new weights by the feature screening method. They are both selected the top N features according to the weight. Hao et al. (2021) did not test the effects of different numbers of features on classification. It cannot be shown that there is a clear relationship between the weights of the features and the classification. Sadiq et al. (2021) used the ReliefF method to screen for features. This is a method that is widely used for feature screening. They tried 100, 200, 300, 400, 500 features for classification, respectively. The accuracy did not show a positive correlation with the number of features. Our experimental results show a clear positive correlation between the accuracy and the number of features.
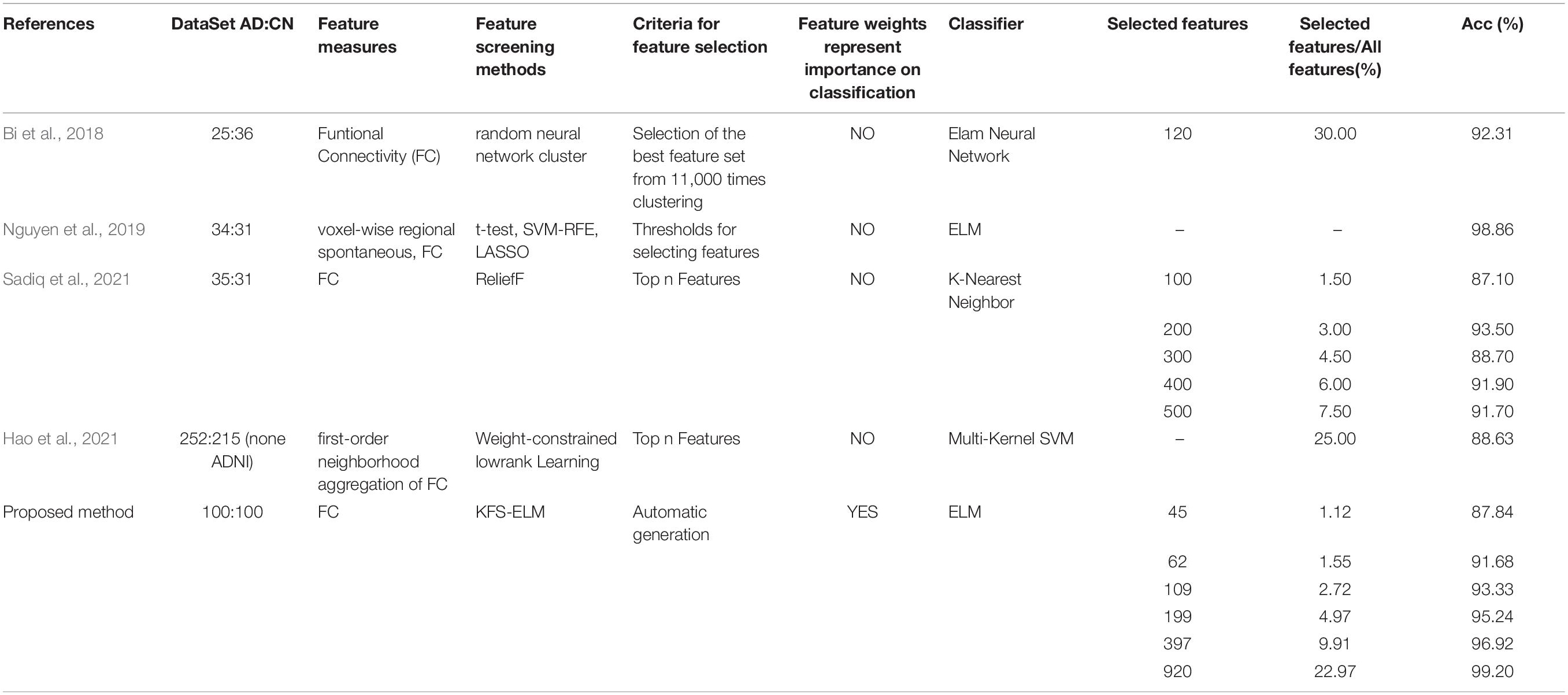
Table 7. Comparison the performances with references.
In summary, the KFS-ELM method can rationally identify the weights of key features. The higher the weights of the features, the greater the impact in AD diagnosis.
Extreme learning machine is linearly transformed between the hidden and output layers. The KFS-ELM method has achieved good performance based on ELM. Some other representative RFNN methods may achieve high classification accuracies in scenarios with high-dimensional features, such as RVFL, where it is non-linearly transformed between the hidden and output layers. In the future, we will attempt to use the idea of key feature screening for research on the RVFL. We will also apply the proposed method to explore patterns in AD-like diseases or other brain sciences.
Conclusion
The experimental results and discussion analysis showed that, the KFS-ELM method can effectively screen key features related to the diagnosis of AD, and can assign rational weights to the features to identify their importance for the diagnosis of AD. The KFS-ELM can be used to construct better classifiers for the diagnosis of AD, and can also be used as a feature analysis tool to study the patterns inherent in the brains of AD patients. We consider that the KFS-ELM is also applicable to the classification and the study of feature patterns of the other objects with high feature dimensions, even with small sample sizes.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
Ethics Statement
The studies involving human participants were reviewed and approved by ADNI. All the fMRI data used in this manuscript are from LONI’s ADNI database ADNI2 project. It can be downloaded from http://adni.loni.usc.edu. All ADNI participants signed an informed consent form at the time of fMRI and related information collection, and the protocol for consent was approved by the institutional review board at each site. The ethical approval was obtained by ADNI and can be found at http://www.loni.usc.edu/ADNI/. All studies in this manuscript were conducted in accordance with the relevant guidelines.
Author Contributions
JL and WZ contributed to the conception of the study. JL performed the experiment and data analyses and wrote the manuscript. JL and LZ contributed significantly to the analysis and manuscript preparation. YS helped to perform the analysis with constructive discussions. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by the National Natural Science Foundation of China (Grant Nos. 31870979 and 61906117) and the Shanghai Sailing Program (Grant No. 19YF1419000).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
Thanks to the Alzheimer’s Disease Neuroimaging Initiative (ADNI) for fMRI data sharing.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnagi.2022.888575/full#supplementary-material
Footnotes
References
Bi, X. A., Jiang, Q., Sun, Q., Shu, Q., and Liu, Y. (2018). Analysis of Alzheimer’s disease based on the random neural network cluster in fMRI. Front. Neuroinform. 12:60. doi: 10.3389/fninf.2018.00060
Buckner, R. L., Sepulcre, J., Talukdar, T., Krienen, F. M., Liu, H., Hedden, T., et al. (2009). Cortical hubs revealed by intrinsic functional connectivity: mapping, assessment of stability, and relation to Alzheimer’s disease. J. Neurosci. 29, 1860–1873. doi: 10.1523/JNEUROSCI.5062-08.2009
Chyzhyk, D., Savio, A., and Graña, M. (2015). Computer aided diagnosis of schizophrenia on resting state fMRI data by ensembles of ELM. Neural Netw. 68, 23–33. doi: 10.1016/j.neunet.2015.04.002
Guo, P., Chen, C. P., and Sun, Y. (1995). “An exact supervised learning for a three-layer supervised neural network,” in Proceedings of the1995 International Conference on Neural Information Processing, (Beijing: Publishing House of Electronics Industry), 1041–1044.
Hao, X. K., An, Q. J., Jiang, T., Guo, Y. C., Li, J., Shi, S., et al. (2021). “Multi-template neuroimaging feature selection using weight-constrained low-rank learning for alzheimer’s disease classification,” in Proceedings of the 2021 36th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanchang, 173–178. doi: 10.1109/YAC53711.2021.9486487
Huang, G., Song, S. J., Gupta, J. N. D., and Wu, C. (2014). Semi-supervised and unsupervised extreme learning machines. IEEE Trans. Cybern. 44, 2405–2417. doi: 10.1109/tcyb.2014.2307349
Huang, G. B., and Babri, H. A. (1998). Upper bounds on the number of hidden neurons in feedforward networks with arbitrary bounded nonlinear activation functions. IEEE Trans. Neural Netw. 9, 224–229. doi: 10.1109/72.655045
Huang, G. B., and Chen, L. (2007). Convex incremental extreme learning machine. Neurocomputing 70, 3056–3062. doi: 10.1016/j.neucom.2007.02.009
Huang, G. B., and Chen, L. (2008). Enhanced random search based incremental extreme learning machine. Neurocomputing 71, 3460–3468. doi: 10.1016/j.neucom.2007.10.008
Huang, G. B., Wang, D. H., and Lan, Y. (2011). Extreme learning machines: a survey. Int. J. Mach. Learn. Cybern. 2, 107–122. doi: 10.1007/s13042-011-0019-y
Huang, G. B., Zhou, H. M., Ding, X. J., and Zhang, R. (2012). Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man. Cybern. 42, 513–529. doi: 10.1109/tsmcb.2011.2168604
Huang, G. B., Zhu, Q. Y., and Siew, C. K. (2004). “Extreme learning machine: a new learning scheme of feedforward neural networks,” in Proceedings of the IEEE International Joint Conference on Neural Networks (Budapest: IEEE), 985–990. doi: 10.1109/IJCNN.2004.1380068
Huang, G. B., Zhu, Q. Y., and Siew, C. K. (2006). Extreme learning machine: theory and applications. Neurocomputing 70, 489–501. doi: 10.1016/j.neucom.2005.12.126
Huang, Z., Yu, Y., Gu, J., and Liu, H. (2016). An efficient method for traffic sign recognition based on extreme learning machine. IEEE Trans. Cybern. 47, 920–933. doi: 10.1109/TCYB.2016.2533424
Kazemifar, S., Drozd, J. J., Rajakumar, N., Borrie, M. J., and Bartha, R. (2014). Automated algorithm to measure changes in medial temporal lobe volume in Alzheimer disease. J. Neurosci. Meth. 227, 35–46. doi: 10.1016/j.jneumeth.2014.01.033
Kim, J., Kim, J., Jang, G. J., and Lee, M. (2017). Fast learning method for convolutional neural networks using extreme learning machine and its application to lane detection. Neural Netw. 87, 109–121. doi: 10.1016/j.neunet.2016.12.002
Lama, R. K., and Kwon, G. R. (2021). Diagnosis of Alzheimer’s disease using brain network. Front. Neurosci. 15:605115. doi: 10.3389/fnins.2021.605115
Liu, X., Zeng, Y., Zhang, T. L., and Xu, B. (2016). Parallel brain simulator: a multi-scale and parallel brain-inspired neural network modeling and simulation platform. Cogn. Comput. 8, 967–981. doi: 10.1007/s12559-016-9411-y
Liu, X. Y., Gao, C. H., and Li, P. (2012). A comparative analysis of support vector machines and extreme learning machines. Neural Netw. 33, 58–66. doi: 10.1016/j.neunet.2012.04.002
Malik, A. K., Ganaie, M. A., Tanveer, M., and Suganthan, P. N. Alzheimer’s Disease, and Neuroimaging Initiative (2022). Alzheimer’s disease diagnosis via intuitionistic fuzzy random vector functional link network. IEEE Trans. Comput. Soc. Syst. (in press). 1–12. doi: 10.1109/TCSS.2022.3146974
Miche, Y., Sorjamaa, A., Bas, P., Simula, O., Jutten, C., and Lendasse, A. (2010). OP-ELM: optimally pruned extreme learning machine. IEEE Trans. Neural Netw. 21, 158–162. doi: 10.1109/TNN.2009.2036259
Miche, Y., van Heeswijk, M., Bas, P., Simula, O., and Lendasse, A. (2011). TROP-ELM: a double-regularized ELM using LARS and Tikhonov regularization. Neurocomputing 74, 2413–2421. doi: 10.1016/j.neucom.2010.12.042
Nguyen, D. T., Ryu, S., Qureshi, M. N. I., Choi, M., Lee, K. H., Lee, B., et al. (2019). Hybrid multivariate pattern analysis combined with extreme learning machine for Alzheimer’s dementia diagnosis using multi-measure rs-fMRI spatial patterns. PLoS One 14:e0212582. doi: 10.1371/journal.pone.0212582
Pao, Y. H., Park, G. H., and Sobajic, D. J. (1994). Learning and generalization characteristics of the random vector functional-link net. Neurocomputing 6, 163–180. doi: 10.1016/0925-2312(94)90053-1
Richhariya, B., Tanveer, M., and Rashid, A. H. Alzheimer’s Disease Neuroimaging Initiative (2020). Diagnosis of Alzheimer’s disease using universum support vector machine based recursive feature elimination (USVM-RFE). Biomed. Signal. Proces. 59:101903. doi: 10.1016/j.bspc.2020.101903
Rong, H. J., Ong, Y. S., Tan, A. H., and Zhu, Z. X. (2008). A fast pruned-extreme learning machine for classification problem. Neurocomputing 72, 359–366. doi: 10.1016/j.neucom.2008.01.005
Rubinov, M., and Sporns, O. (2010). Complex network measures of brain connectivity: uses and interpretations. Neuroimage 52, 1059–1069. doi: 10.1016/j.neuroimage.2009.10.003
Sadiq, A., Yahya, N., and Tang, T. B. (2021). “Diagnosis of Alzheimer’s disease using pearson’s correlation and relieff feature selection approach,” in Proceedings of the 2021 International Conference on Decision Aid Sciences and Application (DASA), Bahrain, 578–582. doi: 10.1109/DASA53625.2021.9682409
Schmidt, W. F., Kraaijveld, M. A., and Duin, R. P. (1992). “Feed forward neural networks with random weights,” in Proceedings of the International Conference on Pattern Recognition, Netherlands, 1–1.
Sharma, R., Goel, T., Tanveer, M., Dwivedi, S., and Murugan, R. (2021). FAF-DRVFL: fuzzy activation function based deep random vector functional links network for early diagnosis of Alzheimer disease. Appl. Soft Comput. 106:107371. doi: 10.1016/j.asoc.2021.107371
Suganthan, P. N., and Katuwal, R. (2021). On the origins of randomization-based feedforward neural networks. Appl. Soft Comput. 105:107239. doi: 10.1016/j.asoc.2021.107239
Supekar, K., Menon, V., Rubin, D., Musen, M., Greicius, M. D., and Sporns, O. (2008). Network analysis of intrinsic functional brain connectivity in Alzheimer’s Disease. PLoS Comput. Biol. 4:e1000100. doi: 10.1371/journal.pcbi.1000100
Susanne, G. M., Michael, W. W., Leon, J. T., Ronald, C. P., Clifford, R. J., William, J., et al. (2005). Ways toward an early diagnosis in Alzheimer’s disease: the Alzheimer’s Disease Neuroimaging Initiative (ADNI). Alzheimers Dement. 1, 55–66. doi: 10.1016/j.jalz.2005.06.003
Tang, J. X., Deng, C. W., Huang, G. B., and Zhao, B. J. (2015). Compressed-domain ship detection on spaceborne optical image using deep neural network and extreme learning machine. IEEE Trans. Geosci. Remote 53, 1174–1185. doi: 10.1109/tgrs.2014.2335751
Tanveer, M., Richhariya, B., Khan, R. U., Rashid, A. H., Khanna, P., Prasad, M., et al. (2020). Machine learning techniques for the diagnosis of Alzheimer’s disease: a review. ACM Trans. Multim. Comput. 16, 1–35. doi: 10.1145/3344998
Tzourio-Mazoyer, N., Landeau, B., Papathanassiou, D., Crivello, F., Etard, O., Delcroix, N., et al. (2002). Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the MNI MRI single-subject brain. Neuroimage 15, 273–289. doi: 10.1006/nimg.2001.0978
Wang, S. G., Deng, C. W., Lin, W. S., Huang, G. B., and Zhao, B. J. (2016). NMF-based image quality assessment using extreme learning machine. IEEE Trans. Cybern. 47, 1–12. doi: 10.1109/TCYB.2015.2512852
Xia, M. R., Wang, J. H., and He, Y. (2013). BrainNet viewer: a network visualization tool for human brain connectomics. PLoS. One 8:e68910. doi: 10.1371/journal.pone.0068910
Yan, C. G., and Zang, Y. F. (2010). DPARSF: a MATLAB toolbox for “pipeline” data analysis of resting-state fMRI. Front. Syst. Neurosci. 4:13. doi: 10.3389/fnsys.2010.00013
Keywords: fMRI, brain functional connectivity, extreme learning machine, AD, KFS-ELM
Citation: Lu J, Zeng W, Zhang L and Shi Y (2022) A Novel Key Features Screening Method Based on Extreme Learning Machine for Alzheimer’s Disease Study. Front. Aging Neurosci. 14:888575. doi: 10.3389/fnagi.2022.888575
Received: 03 March 2022; Accepted: 25 April 2022;
Published: 25 May 2022.
Edited by:
M.Tanveer, Indian Institute of Technology Indore, IndiaReviewed by:
Hong Wang, Central South University, ChinaPonnuthurai Suganthan, Nanyang Technological University, Singapore
Copyright © 2022 Lu, Zeng, Zhang and Shi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Weiming Zeng, zengwm86@163.com