 Elizabeth A. Crinzi1
Elizabeth A. Crinzi1 Emma K. Haley1
Emma K. Haley1 Kerry E. Poppenberg2,3
Kerry E. Poppenberg2,3 Kaiyu Jiang1
Kaiyu Jiang1 Vincent M. Tutino2,3
Vincent M. Tutino2,3 James N. Jarvis1,4*
James N. Jarvis1,4*- 1Department of Pediatrics, University at Buffalo Jacobs School of Medicine & Biomedical Sciences, Buffalo, NY, United States
- 2Canon Stroke and Vascular Center, University at Buffalo Jacobs School of Medicine & Biomedical Sciences, Buffalo, NY, United States
- 3Department of Neurosurgery, University at Buffalo Jacobs School of Medicine & Biomedical Sciences, Buffalo, NY, United States
- 4Genetics, Genomics, & Bioinformatics Program, University at Buffalo Jacobs School of Medicine & Biomedical Sciences, Buffalo, NY, United States
Introduction: Genome wide association studies (GWAS) have identified multiple regions that confer genetic risk for the polyarticular/oligoarticular forms of juvenile idiopathic arthritis (JIA). However, genome-wide scans do not identify the cells impacted by genetic polymorphisms on the risk haplotypes or the genes impacted by those variants. We have shown that genetic variants driving JIA risk are likely to affect both innate and adaptive immune functions. We provide additional evidence that JIA risk variants impact innate immunity.
Materials and methods: We queried publicly available H3K4me1/H3K27ac ChIP-seq data in CD14+ monocytes to determine whether the linkage disequilibrium (LD) blocks incorporating the SNPs that tag JIA risk loci showed enrichment for these epigenetic marks. We also queried monocyte/macrophage GROseq data, a functional readout of active enhancers. We defined the topologically associated domains (TADs) encompassing enhancers on the risk haplotypes and identified genes within those TADs expressed in monocytes. We performed ontology analyses of these genes to identify cellular processes that may be impacted by these variants. We also used whole blood RNAseq data from the Genotype-Tissue Expression (GTEx) data base to determine whether SNPs lying within monocyte GROseq peaks influence plausible target genes within the TADs encompassing the JIA risk haplotypes.
Results: The LD blocks encompassing the JIA genetic risk regions were enriched for H3K4me1/H3K27ac ChIPseq peaks (p=0.00021 and p=0.022) when compared to genome background. Eleven and sixteen JIA were enriched for resting and activated macrophage GROseq peaks, respectively risk regions (p=0.04385 and p=0.00004). We identified 321 expressed genes within the TADs encompassing the JIA haplotypes in human monocytes. Ontological analysis of these genes showed enrichment for multiple immune functions. Finally, we found that SNPs lying within the GROseq peaks are strongly associated with expression levels of plausible target genes in human whole blood.
Conclusions: These findings support the idea that both innate and adaptive immunity are impacted by JIA genetic risk variants.
Introduction
While multiple genetic risk loci for juvenile idiopathic arthritis (JIA) have been identified and validated (1–4), the field is still faced with three important tasks: (1) identifying the actual causal variants on the risk haplotypes that exert the biological effects that confer risk; (2) identifying the cells in which those variants exert their effects; and (3) identifying the genes that are impacted by the causal variants (“target genes”) (5). We have recently shown that the latter 2 tasks can be facilitated by understanding the chromatin architecture that encompasses the JIA risk regions (6–8). For example, the JIA risk haplotypes are highly enriched (compared to genome background) for H3K4me1/H3K27ac ChIPseq peaks, epigenetic signatures typically associated with functional enhancers. This enrichment can be seen in CD4+ T cells, a cell long thought to be involved in JIA pathogenesis (9), and also in neutrophils, for which there is an accumulating body of evidence for involvement in JIA pathobiology (10, 11). Furthermore, activation markers of innate immunity, the myeloid related proteins (MRP), remain our most reliable biomarkers of disease activity and durability of remission (12, 13). Thus, we have hypothesized that genetic variants that confer risk for JIA are likely to impact both innate and adaptive immune systems (14).
There is accumulating evidence that other cells of the myeloid lineage, especially CD14+ monocytes/macrophages, play a role in the immunobiology of JIA (15). We therefore examined the chromatin architecture encompassing the JIA risk regions using publicly available genomic data from CD14+ monocytes and macrophages. Our findings add further support to the notion that risk-driving genetic variants in JIA impact both innate and adaptive immune functions.
Materials and methods
Figure 1 shows the work flow processes through which we queried the JIA risk regions. Further details are provided in each of the following sections.
Figure 1 Summary of methods used to query JIA risk regions using the Single Nucleotide Polymorphism Annotator (SNiPA) and publicly available genomic data.
Disease phenotypes and identification of risk haplotypes
We queried the JIA risk-associated SNPs identified in the Hersh (1) and Herlin (2) reviews, the Hinks Immunochip study (3), and the McIntosh meta-analysis (4) of GWAS data. All of these studies include patients with both oligoarticular JIA and rheumatoid factor-negative, polyarticular JIA. The rationale for this strategy has been that these phenotypes exhibit striking commonalties, including: (1) age of onset typically before puberty; (2) female:male predominance of 3:1; and (3) risk for chronic inflammatory eye disease (uveitis) in younger patients expressing antinuclear antibodies. Although oligoarticular and polyarticular disease are currently categorized as distinct forms of JIA based on the number of involved joints at disease presentation, it is increasingly recognized that this is an arbitrary classification. For example, more than half of children who present with an oligoarticular phenotype pursue a polyarticular disease course (16). In addition, oligo- and polyarticular (RF-negative) subtypes also share HLA associations (17, 18). Thus, the field increasingly views these 2 phenotypes as a disease continuum, sometimes referred to as “polygo” JIA (pJIA) (19, 20), rather than distinct nosocomial entities.
To identify linkage disequilibrium blocks associated with the risk SNPs, we used the Single Nucleotide Polymorphism Annotator (SNiPA) (21), available publicly at https://snipa.helmholtz-muenchen.de/snipa3/. We queried European populations, i.e., the populations represented in the referenced genetic studies, using GRCh37/Ensembl 87 and setting r2 = 0.80. We subsequently converted GRCh37/hg19 coordinates to GRCh38/hg38 using the liftover tool to map relevant chromatin data. These regions are shown in Table 1.
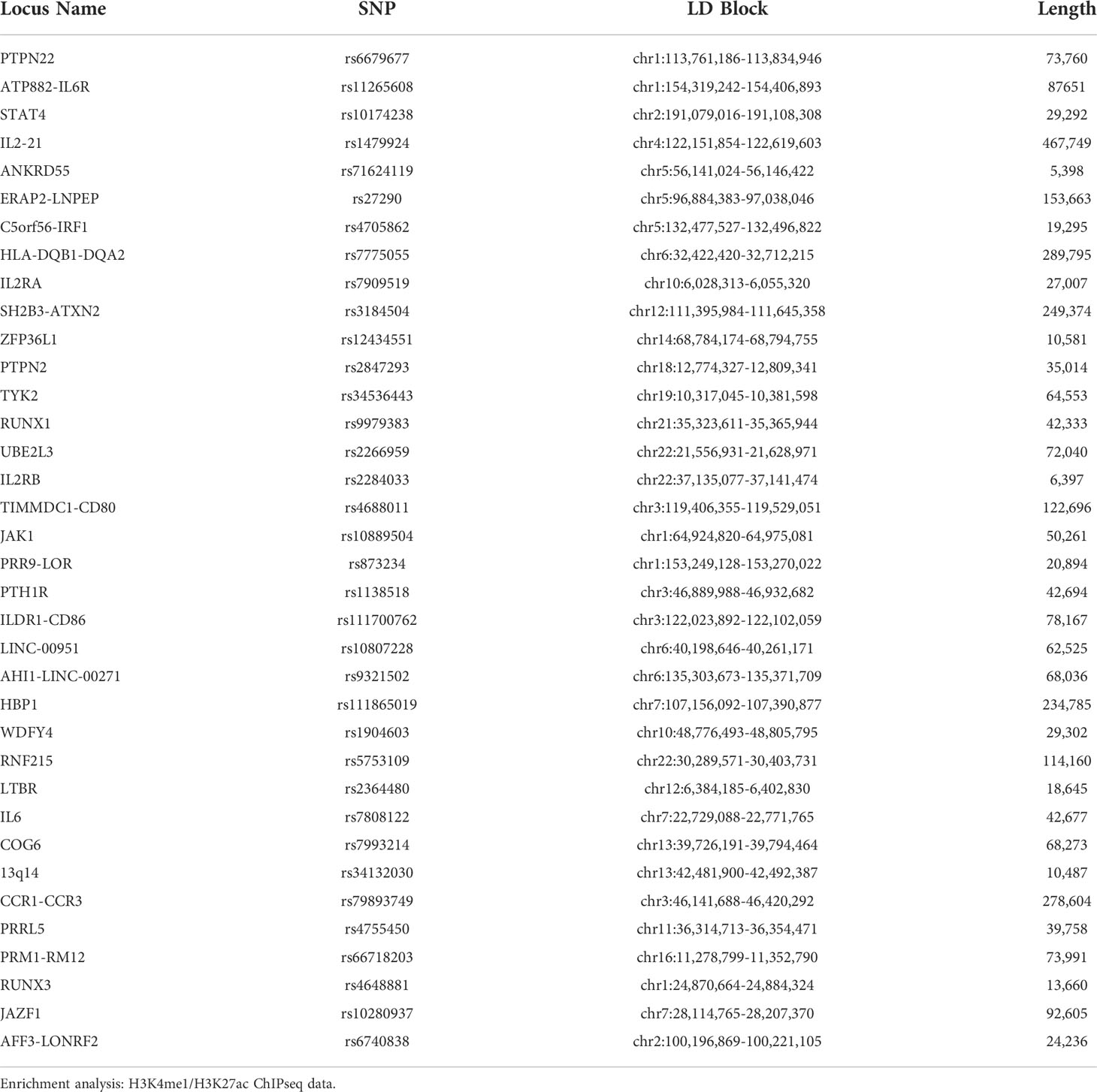
Table 1 Positional Information of 36 JIA risk haplotypes (r2 = 0.80) in hg38.
We investigated the presence of potential enhancers within the JIA risk regions by defining enrichment (compared to genome background) for H3K4me1 and H3K27ac histone marks from publicly available ChIPseq data. We used the BedTools software to assess for enrichment in CD14+ human monocytes, following the method described by Poppenberg et al. (22). Briefly, we mined publicly available CD14+ H3K4me1 and H3K27ac ChIPseq using the Cistrome database
(http://cistrome.org/db/#/). We selected datasets that passed all of Cistrome’s quality checks and prioritized those by authors with data available for both marks of interest. We first queried a single data set for each H3K4me1 (GEO accession #GSM1003535) and H3K27ac (GEO accession #GSM2818004). We then independently validated these findings from 2 additional data sets for H3K4me1 (GSM1102793 and GSM995353) and 3 additional data sets for H3K27ac (GSM1102782, GSM995355, and GSM995356). Using the intersect command in BedTools, we overlapped these peaks with the JIA haplotypes. We created 36 random regions of 86,676 base pairs, or the average length of all the JIA haplotypes, to compare ChIPseq peak enrichment against the background genome. We repeated this random region generation 1000 times to approximate a normal distribution. We then calculated the associated p value with this normal distribution by aligning the curve with number of overlaps between the JIA haplotypes and the ChIP-seq peaks. We considered a p value of p<0.05 as statistically significant.
Enrichment analysis: GROseq data
Although H3K4me1/H3K27ac ChIPseq peaks are epigenetic characteristics associated with enhancers, additional functional data can also be used to identify these regulatory elements. Danko et al. (23) have shown that global run-on sequencing (GROseq) data can be used to identify the bi-directional RNA synthesis that is a hallmark of functional enhancers. We therefore use dReg (23) to identify GROseq peaks using publicly available data from resting macrophages and macrophages activated with Kdo2-Lipid-A (KLA), a lipopolysaccharide derived from E. coli (24). Using the intersect command in BedTools, we overlapped these GROseq peaks with the JIA haplotypes. We created 36 random regions of the average length of all the haplotypes, to compare the GROseq enrichment against the background genome. We repeated this random region generation 1000 times to approximate a normal distribution. We then calculated the associated p value with this normal distribution by aligning the curve with number of overlaps between the JIA haplotypes and the GROseq peaks. We considered a p value of p<0.05 as statistically significant.
Defining topologically associated domains
Identifying target genes influenced by enhancers that harbor disease-driving genetic variants can be facilitated by knowing the larger 3D chromatin architecture that encompasses the risk haplotypes that harbor the relevant enhancers and variants (8). For example, Gasperini et al. (25) showed that, on a genome-wide CRISPRi screen, 71% of enhancers regulate genes within the same TAD. We therefore adapted the method described by Poppenberg et al. (22) to identify TAD structures that encompass the JIA risk haplotypes in monocytes. In brief, we first analyzed a publicly available HiC data set (26) using Juicebox software (27) following the method described by Kessler et al. (8) to identify interacting regions in the monocyte THP-1 cell line. Since TADs are anchored by complexes of CTCF and cohesin (28), we sought to assure the relevance of these analyses, excluding from subsequent analysis any HiC-defined interacting region that did not also have clear CTCF anchors as identified from a publicly available CTCF ChIPseq data set generated from the primary human monocytes (29) (Figure 2).
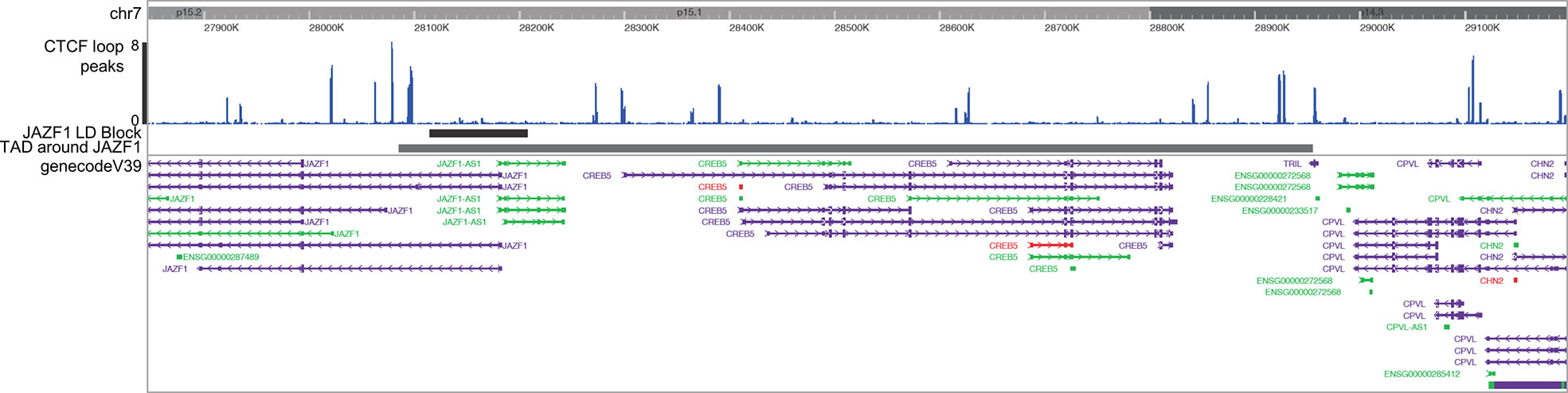
Figure 2 Washington University Epigenome Browser visualization of the JAZF1 risk locus (short solid bar), the corresponding TAD that surrounds the JAZF1 locus (longer solid bar) and, CTCF ChIPseq peaks (blue) and the genes located within the TAD. Note that each end of the TAD is anchored by CTCF.
Identification and ontology analysis of expressed genes within the HiC/CTCF ChIPseq-defined TADs
To characterize the most likely gene targets of identified enhancers, we used the UCSC and Washington University Genome Browsers to align each defined TAD with RefSeq genes as shown in Figure 2. Pseudogenes and non-coding RNA were filtered out within the browser settings. RefSeq genes were filtered by expression level in human monocytes using RNAseq data published by Schulert et al. (30). We excluded any gene with a TPM of < 1. We determined functionality of the expressed genes using gene ontology analysis. We used the publicly available Gene Ontology enRIchment anaLysis and visuaLizAtion (GORILLA) to compare the significance of the expression of these genes as compared to a background set comprising all genes expressed in human monocytes but not situated within the TADs encompassing the JIA risk haplotypes. We input the significant GO terms from GORILLA into the Reduce and Visualize Gene Ontology (REVIGO) tool to visualize gene functionalities by semantic categories.
Enrichment analysis: identifying enhancers that harbor expression-altering variants identified using a massively parallel reporter assay
In myeloid K562 cells, we used a massively parallel reporter assay (MPRA) identical to that described by Tewhey et al. (31) to identify SNPs that have the intrinsic ability to alter gene expression when compared to the common allele (32). The assay uses bar coded oligonucleotides (“oligos”) with a minimal promoter driving green fluorescence protein expression, making it suitable for querying allelic effects on non-coding genomic functions. The allele of interest is placed in the center of the 180 bp oligo with the cognate flanking sequences on either side, providing a degree of genomic context for the reporter. Bar coding allows expression levels (determined by RNAseq) to be determined for each SNP and compared to the common allele. For these assays, we studied both resting K562 cells and cells stimulated with interferon gamma (K562+IFNG) (32) a pathologically relevant ligand (33).
Using the ‘intersect’ command in BedTools, we overlapped these GROseq peaks with the MPRA regions. We created 18 random regions of the average length of all the MPRA regions, to compare the GROseq enrichment against the background genome. We repeated this random region generation 1000 times to approximate a normal distribution. We then calculated the associated p value with this normal distribution by aligning the curve with number of overlaps between the MPRA regions and the GROseq peaks. We considered a p value of p<0.05 as statistically significant.
Linking genetic variants in GROseq peaks to human expression whole blood expression levels
As proof of concept that SNPs within enhancers might influence gene expression, we used the data from the analysis of MPRA SNPs and GROseq peaks as described above to determine whether the genetic variants within the GROseq peaks could be demonstrated to influence gene expression in human peripheral blood cells. As noted, the MPRA was performed in myeloid K562 cells, which have similar TAD features to myeloid THP-1 cells and, thus, to human CD14+ monocytes (8). From the TAD data, we then identified genes that were likely to be regulated by the GROseq-defined enhancers, and thus be influenced by the MPRA-identified SNPs. We used the expression quantitative trait locus (eQTL) calculator on the Gene-Tissue Expression (GTEx) web site [https://www.gtexportal.org/home/testyourown] to query the effects of individual SNPs on gene expression derived from 670 individuals in the GTEx project. The eQTL software calculates statistical significance after correcting for multiple comparisons and the threshold for significance varies with individual genes and SNPs.
Results
Enrichment analysis: H3K4me1/H3K27ac ChIPseq data
We investigated the enrichment of H3K4me1 and H3K27ac ChIPseq peaks within 36 LD blocks conferring JIA risk in CD14+ monocytes to determine whether these regions are enriched for epigenetic signatures of enhancers, as they are in neutrophils and CD4+ T cells (6, 7). Out of the 36 risk regions, 22 were enriched for both H3K4me1 and H3K27ac peaks, while 7 were enriched for H3K4me1 alone. Thus, 7 of 36 LD blocks did not contain any overlaps with ChIP-seq peaks for either H3K4me1 or H3K27ac. This was expected, as it is unlikely that genetic risk in every region operates in every relevant cell type. The presence or absence of histone ChIPseq peaks for each haplotype is outlined in Table 2. Overall, the JIA haplotypes were enriched in CD14+ monocytes to a significant degree: p<0.022 for H3K27ac enrichment and p<0.00021 for H3K4me1. We were able to independently confirm these results by performing the enrichment analyses on 3 independent data sets for H3K4me1 with significant p-values for each data set. (GSM1102793 p=0.0012; GSM995353 p=0.0012; and GSM1003535 p<0.00021). We were able to independently confirm these results by performing the enrichment analyses on 2 independent data sets for H3K4me1 with significant p-values for each data set (GSM1102793 p=0.0012; GSM995353 p=0.0012). We were also able to independently validate the findings from H3K27ac ChIPseq enrichment analysis (GSM1102782 p=0.00014; GSM995355 p=0.00011; and GSM995356 p=0.000030).
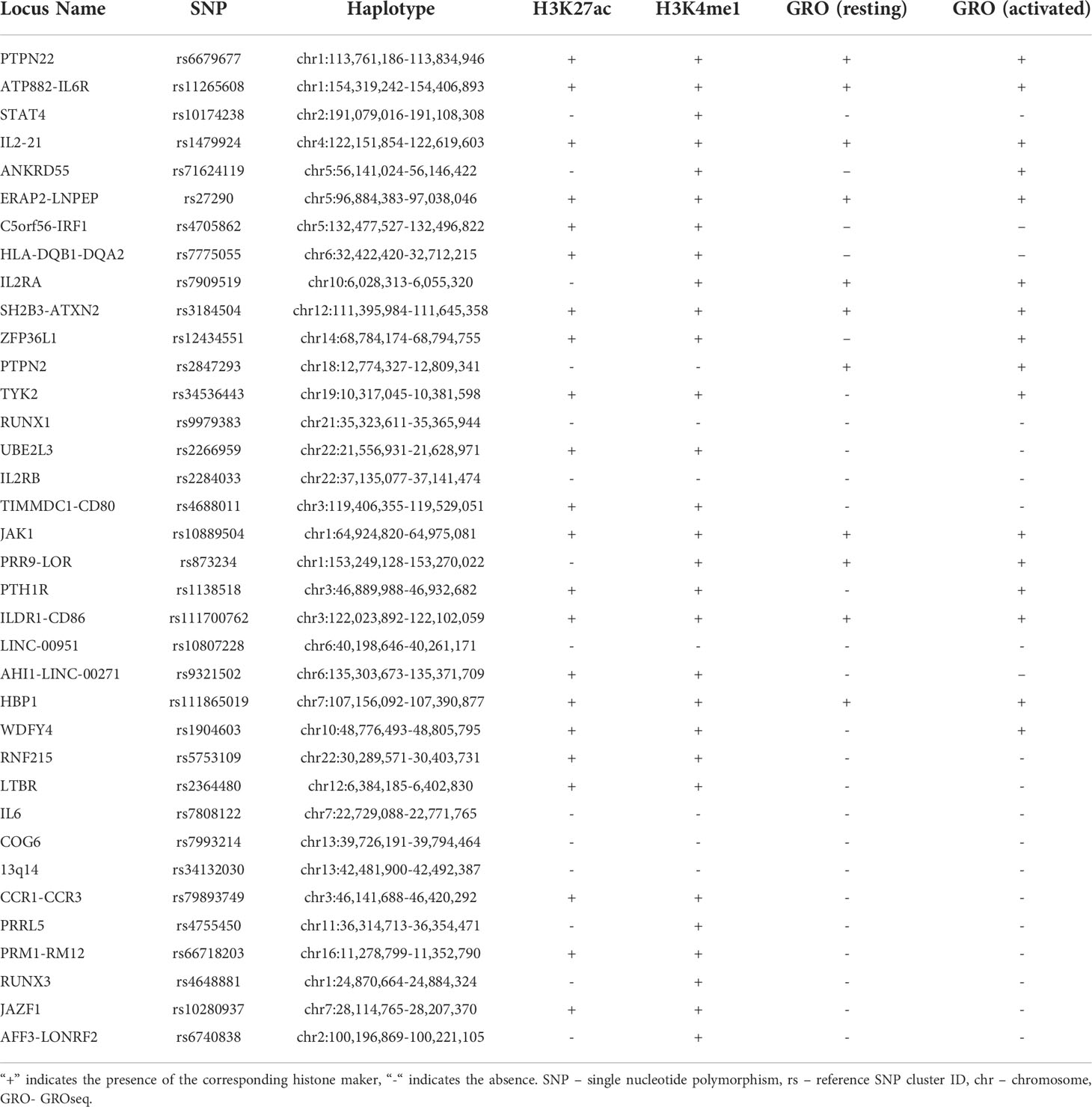
Table 2 Histone marks present in JIA associated haplotypes.
Enrichment analysis: GROseq data
We also interrogated the JIA risk haplotypes for GROseq peaks in both resting macrophages and macrophages activated by KLA from data published by Kaikkonen et al. (24). We also sought to determine whether the presence of GROseq peaks occurred at a greater-than-expected frequency on JIA haplotypes compared with randomly-selected regions of the genome. There were GROseq peaks in 11 out of the 36 LD blocks in resting macrophages, and in 16 LD blocks in KLA-stimulated macrophages. This pattern occurred at a higher-than-expected frequency using genome background as a comparison in both macrophages (p=0.04385) and KLA stimulated macrophages (p=0.00004). The five additional LD blocks that became enriched for GROseq peaks after macrophage differentiation with KLA were ANKRD55, TYK2, ZFP36L1, PTH1R, and WDFY4. In resting macrophages, 7 LD blocks were enriched for both GROseq peaks and H3K27ac peaks, and in 13 haplotypes in KLA-stimulated macrophages (Table 2).
Monocyte GROseq peaks intersect with SNPs identified on MPRA
We next asked whether the GROseq peaks overlapped with expression-altering SNPs that we have identified using an MPRA in myeloid K562 cells (32) as described in the Methods section. From the MPRA data, we identified 18 chromatin regions containing 42 SNPs lying within H3K4me1/H3K27ac-marked regions derived from ChIPseq data in human CD14+ monocytes. Table 3 provides chromatin coordinates for these regions. We next sought to determine how many of these regions also encompassed a GROseq peak.

Table 3 Chromatin coordinates of enhancers identified by MPRA in unstimulated K562 in Hg38.
Note that many of these regions are longer that the typical 800-1,000 bp length of individual enhancers. These are broad regions of open chromatin where multiple H3K4me1/H3K27ac peaks are identified, and likely represented so-called super enhancer complexes. We identified an additional 19 SNPs in IFNG-stimulated K562 cells, also lying within H3K4me1/H3K27ac-marked regions (again using human CD14+ monocyte ChIPseq data). Table 4 provides chromatin coordinates for these regions.

Table 4 Chromatin coordinates of enhancers identified by MPRA in K562+IFNG in Hg38.
We next sought to determine how many of these SNPs also intersect with a GROseq peak. Of the 18 MPRA-identified regions in resting K562 cells, 7 SNPs overlapped GROseq peaks in resting macrophages, and 8 overlapped with GROseq peaks in KLA-stimulated macrophages (Table 5).

Table 5 GROseq peaks that overlap SNPs detected on MPRA in resting K562 cells.
Out of the 19 MPRA-identified SNPs in K562+IFNG cells, 8 SNPs overlapped GROseq peaks in resting macrophages, and 7 overlapped with GROseq peaks in KLA-stimulated macrophages (Table 6).

Table 6 GROseq peaks that overlap SNPs detected on MPRA in K562+IFNG.
Defining topologically associated domains and identifying expressed genes within the TADs
As described previously, target genes of enhancers are almost always located within the associated topologically associated domains (TADs) that encompass those enhancers (25). Therefore, we defined the TADs encompassing the identified enhancers in the JIA LD blocks to begin our investigation of each enhancer’s target genes. We outlined TADs using publicly available Hi-C data and Juicebox software (8, 27) for each of the 29 LD blocks that displayed enrichment for either both H3K27ac and H3K4me1 or H3K4me1 alone. TADs are invariably flanked by CTCF anchors at each end of the loop, so to strengthen the pathological relevance of these analyses, we excluded regions that displayed interactions in HiC data in THP-1 cells that did not also have clear CTCF anchors at either end of the loop in human CTCF ChIPseq data, as described in the Methods section and shown in Figure 2. We excluded a single region, PTPN22, based on these criteria. TADs encompassing all 28 of the enhancer regions are shown in the supplemental results.
Within each of the 28 analyzed TADs, we identified the monocyte genes most likely to be regulated by the enhancers on the JIA risk haplotypes using the UCSC browser and Refseq gene alignment feature. Filtering this list for genes expressed in monocytes with a TPM of >1 using control monocyte expression data from Schulert et al. (30) revealed 321 potential target genes. We completed an ontological analysis to compare the enriched (p<0.01) functions of target genes regulated by enhancers on the risk haplotypes. We identified 14 associated biological processes involved in multiple immune related functions (cytokine binding, interleukin-6 receptor binding, and MHC class II receptor activity, etc.), as well as other basic cellular processes such as peptide receptor activity (Figure 3).
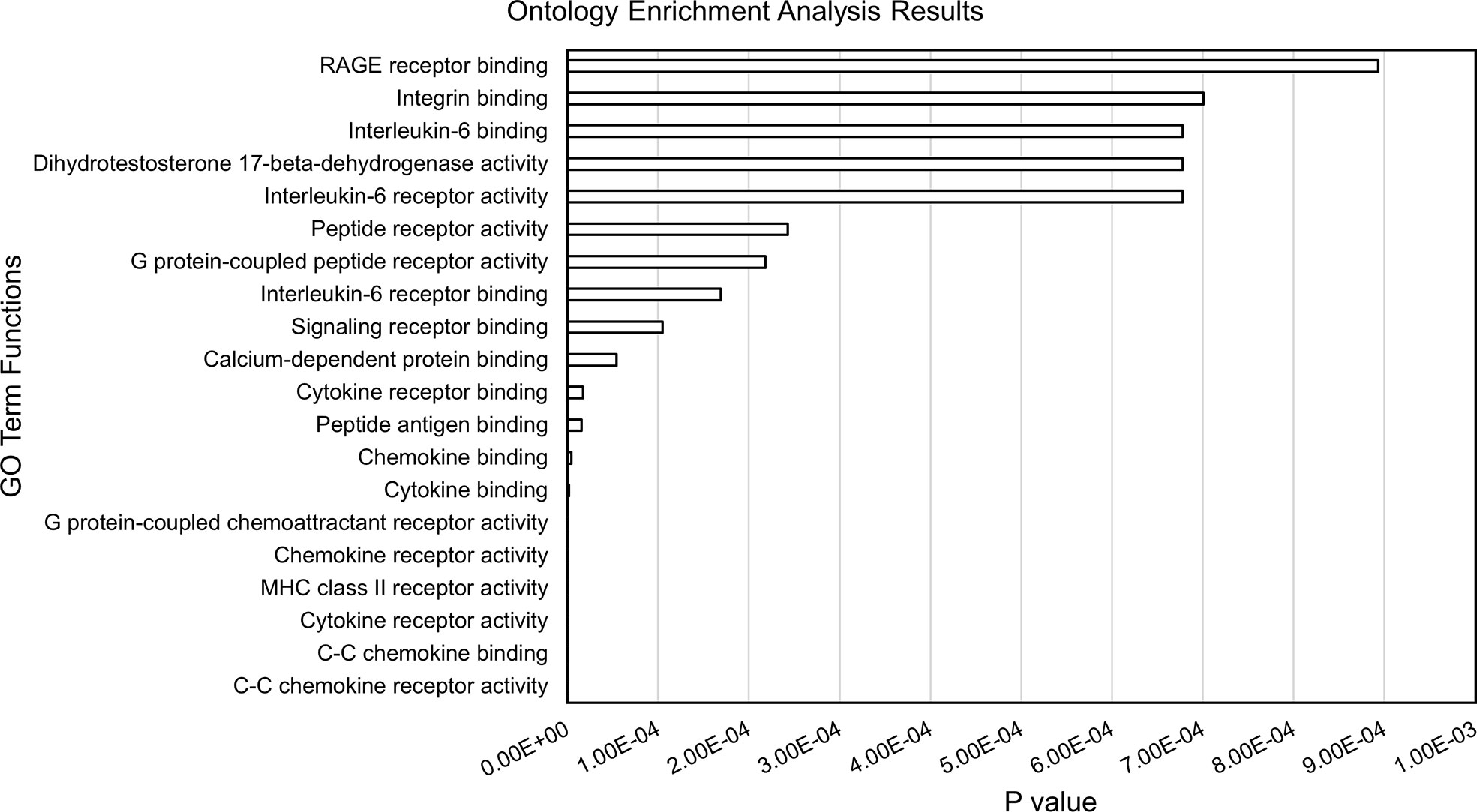
Figure 3 Results from ontology enrichment analyses of genes within the TADs encompassing the JIA risk loci and expressed in human monocytes.
SNPs within monocyte GROseq peaks are associated with expression levels of genes that are plausible targets of these enhancers
Using BedTools, we identified 12 SNPs, situated in 4 different loci, that were previously identified by MPRA and that also overlapped with monocyte GROseq peaks. Because enhancers typically regulate genes within the same TAD (25), we posited that the target genes influenced by these SNPs would be one (or more) or those genes within the TADs previously defined. We therefore queried the Genotype-Expression (GTEx) data set using the eQTL calculator and querying whole blood gene expression data, as described in the Methods section. Each of these 12 SNPs was shown to be an eQTL for at least one gene within the monocyte TADs, as shown in Table 7.
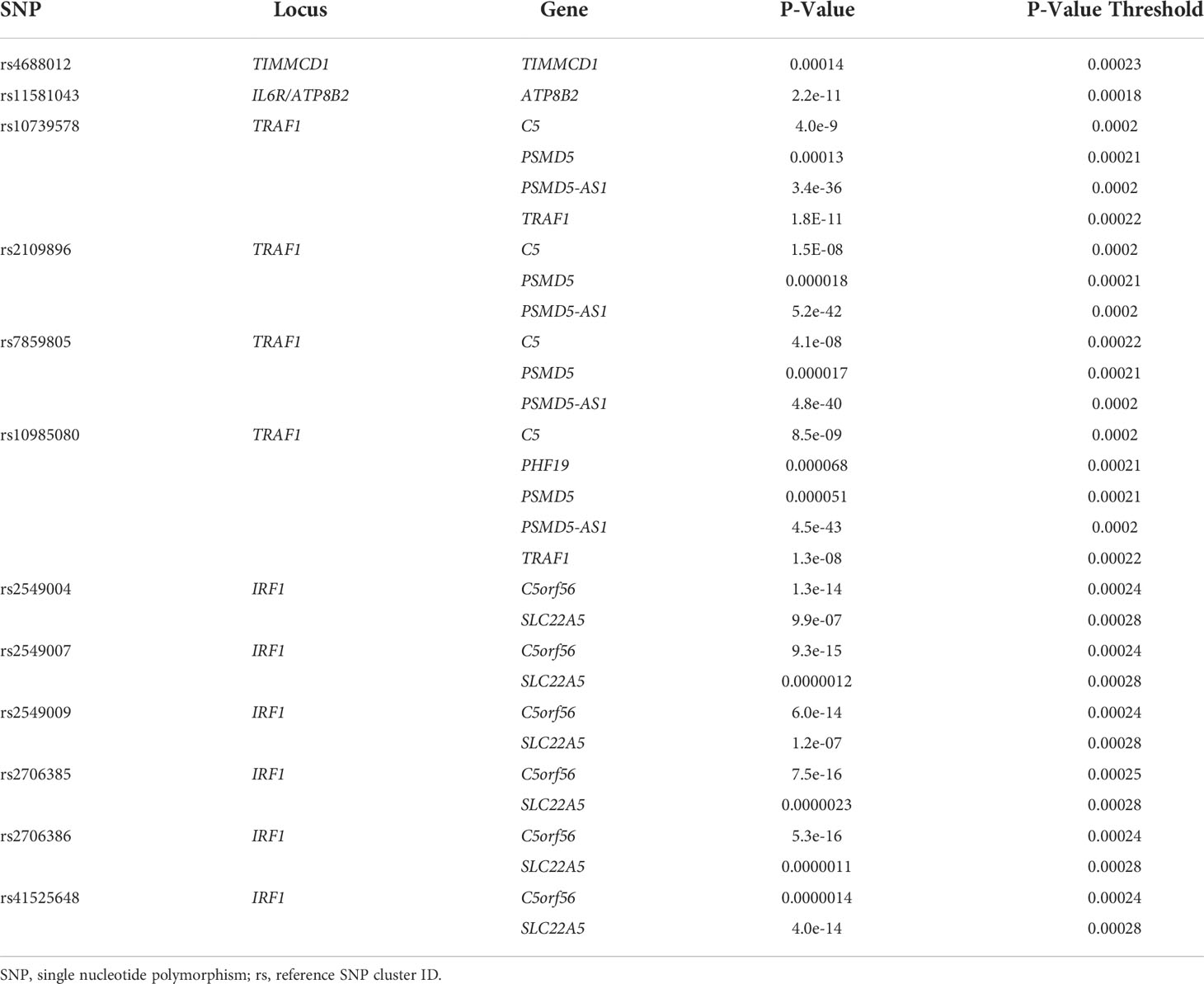
Table 7 eQTL SNPs Within Monocyte GROseq Peaks.
Thus, human data corroborate the in-silico analysis, demonstrating that SNPs within monocyte enhancer regions are associated with alterations in baseline gene expression in whole blood.
Discussion
We have previously hypothesized that genetic variants of JIA may confer disease risk by modulating both innate and adaptive immune systems (14). We have also shown that characterizing the chromatin architecture of risk haplotypes yields a strategy for elucidating genetic mechanisms, including the identification of genes that are likely to be affected by genetic variants within non-coding regions (the so-called “target genes”). Furthermore, this strategy may assist in identifying the cell types whose functions are impacted by disease-driving variants on risk haplotypes. For example, we have shown that, in immune cells such as neutrophils and CD4+ T cells, the JIA risk haplotypes are enriched for epigenetic features of non-coding regulatory functions, including H3K4me1 and H3K27ac, which commonly identify poised or active enhancers (9–11). Similarly, we have shown that the genetic risk loci for intracranial aneurysm are highly enriched for these same epigenetic features in endothelial cells but not immune cells, which can be observed in affected vessels (34). Our interest in monocytes/macrophages in the current study extends our interest in the interplay between innate and adaptive immunity (14), which may be a feature of other autoimmune disease such systemic sclerosis/scleroderma (22).
In this study, we investigated the chromatin architecture surrounding 36 JIA risk loci in CD14+ monocytes. We found that these regions, like those in neutrophils and CD4+ T cells, are enriched for epigenetic signatures of non-coding regulatory functions. This was true whether we examined post-translational modifications to histones (H3K4me1/H3K27ac-identified on ChIPseq), or a more functional read-out, the presence of bi-directional RNA synthesis as identified on GROseq (23). We also provide additional evidence that JIA-associated genetic variants may alter enhancer function in these regions: variants that show intrinsic ability to alter gene expression on an MPRA in myeloid K562 cells are located within regions that have a GROseq peak in human macrophages. Using GTEx whole blood expression data, we showed that these SNPs strongly influence the expression of genes within the TADs harboring the GROseq defined enhancers. The GTEx analysis is unlikely to reflect effects exerted in CD14+ cells alone, since they make up only a small part of the signal in whole blood expression profiles. It is just as likely that the observed effect comes from neutrophils, the most abundant cell in the peripheral blood, and, like CD14+ monocytes, of myeloid lineage. However, these findings demonstrate that SNPs within the defined regions are functionally significant.
The enhancer regions we identified in CD14+ monocytes and macrophages are situated within chromatin loops that encompass 321 coding genes that are expressed in these cells. This is a slightly larger number of genes than are situated in the TADs that encompass the JIA haplotypes in CD4+ T cells, where we have identified 287 expressed genes. Thus, JIA-driving risk variants potentially influence a greater number of genes in CD14+ monocytes/macrophages than in CD4+ T cells. Furthermore, the range of cellular functions likely to be impacted by disease-driving variants is broad. Gene ontology analyses of these candidate target genes show significant enrichment for 14 biological different processes, the majority of which are immune related (Figure 3).
These findings have clinical implications and may point to new targets of therapy. GO analysis of the genes within the TADs that subsume the JIA risk haplotypes reveal already-known targets of therapy in JIA (e.g., IL6/IL6R), but suggest others as well. The most significant GO category identified on these analyses were related to the function of the receptor for advanced glycation end products (RAGE). RAGE is the ligand for the myeloid-related proteins (MRP), which are known to be elevated in the plasma of children with polyarticular JIA (35) and may serve as biomarkers of active disease (36). The interactions between MRP/S100 proteins and RAGE activate toll-like receptor pathways in myeloid cells and facilitate pro-inflammatory responses (37). Strategies to blunt MRP binding to RAGE or to dampen RAGE signaling may be attractive, particularly in individuals whose genotypes demonstrate causal variants affecting these pathways.
It is important to note that many of these potential target genes are not situated on the JIA risk haplotypes themselves. The field has become increasingly aware that, for complex traits, genetic effects are not always exerted on the most proximal gene (in terms of linear genomic distance), to the SNPs that are used to tag the genetic risk loci on GWAS or genetic fine mapping studies (38). Furthermore, Pelikan et al. have published direct evidence that enhancer-associated variants on risk haplotypes for systemic lupus erythematosus exert their strongest effects on genes not actually on the risk haplotypes (39). These findings highlight the importance of considering the 3D structure of the genome and chromatin in probing genetic mechanisms that influence JIA risk and/or disease course (8).
While monocytes/macrophages are well-known to be involved in the pathobiology of systemic onset JIA (sJIA) (15, 40–44), less is known about their role in the pathogenesis or pathobiology of the polyarticular/oligoarticular forms of JIA. The most recent understanding stems from alterations to polarization patterns of macrophage activation under JIA inflammatory conditions (15). Circulating monocytes that are recruited to the synovium are stimulated by inflammatory mediators such as TNFα, GM-CSF, IL-1β, and IL-10 to differentiate into tissue resident macrophages. The tissue macrophages are stimulated by the hypoxic environment, microRNAs, and other mediators to differentiate into mixed inflammatory polarizations. Cytokines, chemokines, and growth factors such as VEGF that have been shown to be upregulated in the synovial fluid and serum of patients with JIA are secreted by these synovial monocytes and macrophages. Furthermore, the products of these monocyte/macrophages are the targets of several therapeutics used to treat JIA, such as TNFα inhibitors etanercept and adalimumab, IL-1β receptor antibody anakinra, and IL-6 receptor antibody tocilizumab (15). Our findings support the idea that many of these steps may be under genetic influence and that genetically-mediated variation in these processes may contribute to disease risk.
Although inflammatory states may recruit circulating monocytes to enter tissue and differentiate into tissue resident macrophages, the circulating monocytes only contribute to forming a small portion of the permanent population of tissue macrophages that remain after the inflammatory period has concluded (45). Tissue resident macrophages may instead have origins from variable populations, including embryonic yolk-sac precursors and fetal liver derived hemopoietic stem cells, in addition to adult monocytes (45). This lack of consistency and shared lineage in the cells that repopulate tissue resident macrophages suggests that genetic risk variants might occur in the more cohesive population of tissue resident macrophages themselves rather than their diverse monocyte precursors or circulating CD14+ monocytes/macrophages.
There are several other limitations to this study that need to be considered. The first is the limitations of the enrichment analysis, which compares the chromatin structures on the risk haplotypes to randomly-generated regions of the genome. It must be noted that the distribution of genes and functional regulatory elements across the genome is not uniform, and there are large regions of the genome that contain neither. These facts dictate the need to repeat the randomization procedure 1,000 times in order to come as close as possible to a true and representative randomization that reflects a normalized distribution of genes and functional elements. The genetic risk loci for most complex traits, and certainly for the autoimmune diseases, occur in gene-rich regions. This, of course, complicates the task of identifying the genes that are impacted by the actual risk-driving variants. However, the richness of coding genes on the haplotypes is not prima facie evidence that these regions will also have enhancers, silencers, etc. Those regulatory elements could just as easily be in regions other than the haplotypes themselves, given that regulatory elements, especially enhancers, operate at a considerable distance from the genes they regulate. Ironically, there’s evidence that we may have that paradigm all wrong (i.e., “target genes on the haplotypes, regulatory elements on or off the haplotypes”). Pelikan et al. (39) have shown that the disease-driving variants for SLE are likely to be within enhancers that are on the haplotypes, but the target genes actually not. The findings in the Pelikan paper point to the importance of examining the broader chromatin architecture within which autoimmune risk haplotypes are subsumed, as we do in the current paper.
It is also important to note that that the presence of H3K4me1 and/or H3K27ac ChIPseq peaks, even in a region of open chromatin, is not prima facie evidence that a region has enhancer activity. Invariably, enhancer activity has to be confirmed experimentally, preferably in the context of native chromatin. In contrast, the presence of bidirectional RNA synthesis, as detected on GROseq, provides a strong functional read-out of enhancer activities, as the synthesized strands are invariably so-called enhancer RNAs (eRNA) that facilitate the interaction between the enhancer and promoter (23).
It is also important to note that not every patient with JIA has a disease-driving variant on every haplotype. Thus, although we can make inferences as to the spectrum of innate immune functions that might be altered in patients harboring variants on the risk haplotypes (e.g., Figure 3), this does not mean that these pathways are affected in every patient. Indeed, the impetus toward precision medicine initiatives is based on the premise that each patient’s genetic vulnerabilities (and strengths) is unique, and that therapy should be directed to those unique features of an individual patient’s disease biology.
It is also important to note the limitations of the MPRA assay used in these analyses. The most important limitation of these assays, of course, is that they don’t detect effects as they occur in native chromatin. They simply detect the intrinsic ability of a given allele to affect the expression of the reporter gene. Effects that are dependent of specific chromatin interactions might be missed. The MPRA used in these analyses was originally performed as a first step in assessing potential genetic effects that are exerted on neutrophils in JIA (32). After completion of the monocyte enrichment analyses, we sought to determine whether there were, in fact, plausible causal variants within the identified GROseq peaks. We determined that, because there is considerable overlap in the broad chromatin architecture of the JIA risk loci and the TADs encompassing them when cell lines and primary human cells are compared (8), the existing MPRA data might be informative. Our results, using GTEx whole blood expression data, corroborated the idea that expression-influencing SNPs lying within the monocyte GROseq peaks do influence human gene expression. However, one cannot conclude that the relevant biological effects are specifically exerted in monocytes, because the GTEx whole blood data reflect expression of multiple myeloid and lymphoid cell lineages.
In conclusion, we provide evidence, based on the chromatin architecture surrounding the genetic risk haplotypes, that genetic risk for JIA exerts effects in cells of the monocyte-macrophage lineage. These findings provide a strong rationale to test this concept empirically, using both patient cells (39) and in vitro approaches (46).
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found in the article/Supplementary Material.
Author contributions
EC – Performed data analyses and interpretation. Assisted in writing the manuscript. EH – Performed data analysis and interpretation. Assisted in writing the manuscript. KP – Developed analysis pipelines and methods, assisted in data analysis. KJ – Assisted in data analysis, interpretation, and preparation of the manuscript. VT - Developed analysis pipelines and methods, assisted in data analysis. JJ – Designed and directed the study, assisted with data analysis and interpretation, and assisted with preparation of the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by R21-AR071878 and R21-AR076948 from the National Institutes of Health (JJ), and medical student summer research preceptorships from the Rheumatology Research Foundation (to EC and EH). It was also supported by the National Center for Advancing Translational Sciences of the National Institutes of Health under award number UL1TR001412 to the University at Buffalo. The content is solely the responsibility of the authors and does not necessarily represent the official views of the NIH.
Acknowledgments
The authors wish to thank Drs. John Lis and Charles Danko for their guidance in analyzing and interpreting GROseq data using their dReg pipeline.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fimmu.2022.913555/full#supplementary-material
References
1. Hersh AO, Prahalad S. Immunogenetics of juvenile idiopathic arthritis: A comprehensive review. J Autoimmun (2015) 64:113–24. doi: 10.1016/j.jaut.2015.08.002
2. Herlin MK, MBr P, Herlin T. Update on genetic susceptibility and pathogenesis in juvenile idiopathic arthritis. Eur Med J Rheumatol (2014) 1:73–83.
3. Hinks A, Cobb J, Marion MC, Prahalad S, Sudman M, Bowes J, et al. Dense genotyping of immune-related disease regions identifies 14 new susceptibility loci for juvenile idiopathic arthritis. Nat Genet (2013) 45(6):664–9. doi: 10.1038/ng.2614
4. McIntosh LA, Marion MC, Sudman M, Comeau ME, Becker ML, Bohnsack JF, et al. Genome-wide association meta-analysis reveals novel juvenile idiopathic arthritis susceptibility loci. Arthritis Rheumatol (2017) 69(11):2222–32. doi: 10.1002/art.40216
5. Gallagher MD, Chen-Plotkin AS. The post-gwas era: From association to function. Am J Hum Genet (2018) 102(5):717–30. doi: 10.1016/j.ajhg.2018.04.002
6. Jiang K, Zhu L, Buck MJ, Chen Y, Carrier B, Liu T, et al. Disease-associated single-nucleotide polymorphisms from noncoding regions in juvenile idiopathic arthritis are located within or adjacent to functional genomic elements of human neutrophils and Cd4+ T cells. Arthritis Rheumatol (2015) 67(7):1966–77. doi: 10.1002/art.39135
7. Zhu L, Jiang K, Webber K, Wong L, Liu T, Chen Y, et al. Chromatin landscapes and genetic risk for juvenile idiopathic arthritis. Arthritis Res Ther (2017) 19(1):57. doi: 10.1186/s13075-017-1260-x
8. Jiang K, Kessler H, Park Y, Sudman M, Thompson SD, Jarvis JN. Broadening our understanding of the genetics of juvenile idiopathic arthritis (Jia): Interrogation of three dimensional chromatin structures and genetic regulatory elements within jia-associated risk loci. PloS One (2020) 15(7):e0235857. doi: 10.1371/journal.pone.0235857
9. Grom AA, Hirsch R. T-Cell and T-cell receptor abnormalities in the immunopathogenesis of juvenile rheumatoid arthritis. Curr Opin Rheumatol (2000) 12(5):420–4. doi: 10.1097/00002281-200009000-00012
10. Jarvis JN, Petty HR, Tang Y, Frank MB, Tessier PA, Dozmorov I, et al. Evidence for chronic, peripheral activation of neutrophils in polyarticular juvenile rheumatoid arthritis. Arthritis Res Ther (2006) 8(5):R154. doi: 10.1186/ar2048
11. Jarvis JN, Jiang K, Frank MB, Knowlton N, Aggarwal A, Wallace CA, et al. Gene expression profiling in neutrophils from children with polyarticular juvenile idiopathic arthritis. Arthritis Rheum (2009) 60(5):1488–95. doi: 10.1002/art.24450
12. Anink J, Van Suijlekom-Smit LW, Otten MH, Prince FH, van Rossum MA, Dolman KM, et al. Mrp8/14 serum levels as a predictor of response to starting and stopping anti-tnf treatment in juvenile idiopathic arthritis. Arthritis Res Ther (2015) 17(1):200. doi: 10.1186/s13075-015-0723-1
13. Hinze CH, Foell D, Johnson AL, Spalding SJ, Gottlieb BS, Morris PW, et al. Serum S100a8/A9 and S100a12 levels in children with polyarticular forms of juvenile idiopathic arthritis: Relationship to maintenance of clinically inactive disease during anti-tumor necrosis factor therapy and occurrence of disease flare after discontinuation of therapy. Arthritis Rheumatol (2019) 71(3):451–9. doi: 10.1002/art.40727
14. Jiang K, Wong L, Sawle AD, Frank MB, Chen Y, Wallace CA, et al. Whole blood expression profiling from the treat trial: Insights for the pathogenesis of polyarticular juvenile idiopathic arthritis. Arthritis Res Ther (2016) 18(1):157. doi: 10.1186/s13075-016-1059-1
15. Wu CY, Yang HY, Huang JL, Lai JH. Signals and mechanisms regulating monocyte and macrophage activation in the pathogenesis of juvenile idiopathic arthritis. Int J Mol Sci (2021) 22(15):7960. doi: 10.3390/ijms22157960
16. Guillaume S, Prieur AM, Coste J, Job-Deslandre C. Long-term outcome and prognosis in oligoarticular-onset juvenile idiopathic arthritis. Arthritis Rheum (2000) 43(8):1858–65. doi: 10.1002/1529-0131(200008)43:8<1858::AID-ANR23>3.0.CO;2-A
17. Hinks A, Bowes J, Cobb J, Ainsworth HC, Marion MC, Comeau ME, et al. Fine-mapping the mhc locus in juvenile idiopathic arthritis (Jia) reveals genetic heterogeneity corresponding to distinct adult inflammatory arthritic diseases. Ann Rheum Dis (2017) 76(4):765–72. doi: 10.1136/annrheumdis-2016-210025
18. Hollenbach JA, Thompson SD, Bugawan TL, Ryan M, Sudman M, Marion M, et al. Juvenile idiopathic arthritis and hla class I and class ii interactions and age-at-Onset effects. Arthritis Rheum (2010) 62(6):1781–91. doi: 10.1002/art.27424
19. Nigrovic PA, Martinez-Bonet M, Thompson SD. Implications of juvenile idiopathic arthritis genetic risk variants for disease pathogenesis and classification. Curr Opin Rheumatol (2019) 31(5):401–10. doi: 10.1097/BOR.0000000000000637
20. Nigrovic PA, Colbert RA, Holers VM, Ozen S, Ruperto N, Thompson SD, et al. Biological classification of childhood arthritis: Roadmap to a molecular nomenclature. Nat Rev Rheumatol (2021) 17(5):257–69. doi: 10.1038/s41584-021-00590-6
21. Arnold M, Raffler J, Pfeufer A, Suhre K, Kastenmuller G. Snipa: An interactive, genetic variant-centered annotation browser. Bioinformatics (2015) 31(8):1334–6. doi: 10.1093/bioinformatics/btu779
22. Poppenberg KE, Tutino VM, Tarbell E, Jarvis JN. Broadening our understanding of genetic risk for Scleroderma/Systemic sclerosis by querying the chromatin architecture surrounding the risk haplotypes. BMC Med Genomics (2021) 14(1):114. doi: 10.1186/s12920-021-00964-5
23. Danko CG, Hyland SL, Core LJ, Martins AL, Waters CT, Lee HW, et al. Identification of active transcriptional regulatory elements from gro-seq data. Nat Methods (2015) 12(5):433–8. doi: 10.1038/nmeth.3329
24. Kaikkonen MU, Spann NJ, Heinz S, Romanoski CE, Allison KA, Stender JD, et al. Remodeling of the enhancer landscape during macrophage activation is coupled to enhancer transcription. Mol Cell (2013) 51(3):310–25. doi: 10.1016/j.molcel.2013.07.010
25. Gasperini M, Hill AJ, McFaline-Figueroa JL, Martin B, Kim S, Zhang MD, et al. A genome-wide framework for mapping gene regulation Via cellular genetic screens. Cell (2019) 176(6):1516. doi: 10.1016/j.cell.2019.02.027
26. Phanstiel DH, Van Bortle K, Spacek D, Hess GT, Shamim MS, Machol I, et al. Static and dynamic DNA loops form ap-1-Bound activation hubs during macrophage development. Mol Cell (2017) 67(6):1037–48.e6. doi: 10.1016/j.molcel.2017.08.006
27. Durand NC, Robinson JT, Shamim MS, Machol I, Mesirov JP, Lander ES, et al. Juicebox provides a visualization system for Hi-c contact maps with unlimited zoom. Cell Syst (2016) 3(1):99–101. doi: 10.1016/j.cels.2015.07.012
28. Hnisz D, Day DS, Young RA. Insulated neighborhoods: Structural and functional units of mammalian gene control. Cell (2016) 167(5):1188–200. doi: 10.1016/j.cell.2016.10.024
29. Heinz S, Texari L, Hayes MGB, Urbanowski M, Chang MW, Givarkes N, et al. Transcription elongation can affect genome 3d structure. Cell (2018) 174(6):1522–36 e22. doi: 10.1016/j.cell.2018.07.047
30. Schulert GS, Pickering AV, Do T, Dhakal S, Fall N, Schnell D, et al. Monocyte and bone marrow macrophage transcriptional phenotypes in systemic juvenile idiopathic arthritis reveal Trim8 as a mediator of ifn-Γ hyper-responsiveness and risk for macrophage activation syndrome. Ann Rheum Dis (2021) 80(5):617–25. doi: 10.1136/annrheumdis-2020-217470
31. Tewhey R, Kotliar D, Park DS, Liu B, Winnicki S, Reilly SK, et al. Direct identification of hundreds of expression-modulating variants using a multiplexed reporter assay. Cell (2016) 165(6):1519–29. doi: 10.1016/j.cell.2016.04.027
32. Jiang K, Liu T, Kales S, Tewhey R, Kim D, Park Y, et al. A systematic strategy for identifying causal single nucleotide polymorphisms and their target genes on juvenile arthritis risk haplotypes. bioRxiv (2022) doi: 10.1101/2022.03.07.483040
33. Throm AA, Moncrieffe H, Orandi AB, Pingel JT, Geurs TL, Miller HL, et al. Identification of enhanced ifn-Γ signaling in polyarticular juvenile idiopathic arthritis with mass cytometry. JCI Insight (2018) 3(15), e121544. doi: 10.1172/jci.insight.121544
34. Poppenberg KE, Jiang K, Tso MK, Snyder KV, Siddiqui AH, Kolega J, et al. Epigenetic landscapes suggest that genetic risk for intracranial aneurysm operates on the endothelium. BMC Med Genomics (2019) 12(1):149. doi: 10.1186/s12920-019-0591-7
35. Hu Z, Jiang K, Frank M. Complexity and specificity of the neutrophil transcriptomes in juvenile idiopathic arthritis. Sci Rep (2016) 6:27453. doi: 10.1038/srep27453
36. Pelikan RC, Kelly JA, Fu Y, Lareau CA, Tessneer KL, Wiley GB, et al. Phagocyte-specific S100 proteins and high-sensitivity c reactive protein as biomarkers for a risk-adapted treatment to maintain remission in juvenile idiopathic arthritis: a comparative study. Ann Rheum Dis (2012) 71(12):1991–7. doi: 10.1136/annrheumdis-2012-201329
37. Foell D, Wittkowski H, Vogl T, Roth J. S100 proteins expressed in phagocytes: a novel group of damage-associated molecular pattern molecules. J Leukocyte Biol (2007) 81:28–37. doi: 10.1189/jlb.0306170
38. Brodie A, Azaria JR, Ofran Y. How far from the snp may the causative genes be? Nucleic Acids Res (2016) 44(13):6046–54. doi: 10.1093/nar/gkw500
39. Pelikan RC, Kelly JA, Fu Y, Lareau CA, Tessneer KL, Wiley GB, et al. Enhancer histone-qtls are enriched on autoimmune risk haplotypes and influence gene expression within chromatin networks. Nat Commun (2018) 9(1):2905. doi: 10.1038/s41467-018-05328-9
40. Mellins ED, Macaubas C, Grom AA. Pathogenesis of systemic juvenile idiopathic arthritis: Some answers, more questions. Nat Rev Rheumatol (2011) 7(7):416–26. doi: 10.1038/nrrheum.2011.68
41. Yasin S, Schulert GS. Systemic juvenile idiopathic arthritis and macrophage activation syndrome: Update on pathogenesis and treatment. Curr Opin Rheumatol (2018) 30(5):514–20. doi: 10.1097/bor.0000000000000526
42. Lin YT, Wang CT, Gershwin ME, Chiang BL. The pathogenesis of Oligoarticular/Polyarticular vs systemic juvenile idiopathic arthritis. Autoimmun Rev (2011) 10(8):482–9. doi: 10.1016/j.autrev.2011.02.001
43. Schulert GS, Fall N, Harley JB, Shen N, Lovell DJ, Thornton S, et al. Monocyte microrna expression in active systemic juvenile idiopathic arthritis implicates microrna-125a-5p in polarized monocyte phenotypes. Arthritis Rheumatol (2016) 68(9):2300–13. doi: 10.1002/art.39694
44. Shimizu M, Yachie A. Compensated inflammation in systemic juvenile idiopathic arthritis: Role of alternatively activated macrophages. Cytokine (2012) 60(1):226–32. doi: 10.1016/j.cyto.2012.05.003
45. Ginhoux F, Jung S. Monocytes and macrophages: Developmental pathways and tissue homeostasis. Nat Rev Immunol (2014) 14(6):392–404. doi: 10.1038/nri3671
Keywords: juvenile arthritis, genetics, monocyte, macrophage, haplotype, causal variant, enhancers
Citation: Crinzi EA, Haley EK, Poppenberg KE, Jiang K, Tutino VM and Jarvis JN (2022) Analysis of chromatin data supports a role for CD14+ monocytes/macrophages in mediating genetic risk for juvenile idiopathic arthritis. Front. Immunol. 13:913555. doi: 10.3389/fimmu.2022.913555
Received: 05 April 2022; Accepted: 06 September 2022;
Published: 29 September 2022.
Edited by:
Janine Lamb, The University of Manchester, United KingdomReviewed by:
Paul Martin, The University of Manchester, United KingdomMatteo Vecellio, University of Oxford, United Kingdom
Copyright © 2022 Crinzi, Haley, Poppenberg, Jiang, Tutino and Jarvis. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: James N. Jarvis, jamesjar@buffalo.edu