 Mareike Wendorff1*
Mareike Wendorff1* Heli M. Garcia Alvarez2
Heli M. Garcia Alvarez2 Thomas Østerbye3
Thomas Østerbye3 Hesham ElAbd1
Hesham ElAbd1 Elisa Rosati1
Elisa Rosati1 Frauke Degenhardt1
Frauke Degenhardt1 Søren Buus3
Søren Buus3 Andre Franke1*†
Andre Franke1*† Morten Nielsen2,4†
Morten Nielsen2,4†- 1Genetics & Bioinformatics, Institute of Clinical Molecular Biology, Christian-Albrechts-University of Kiel, Kiel, Germany
- 2IIBIO, UNSAM-CONICET, Buenos Aires, Argentina
- 3Department of Immunology and Microbiology, University of Copenhagen, Copenhagen, Denmark
- 4Department of Health Technology, Technical University of Denmark, Lyngby, Denmark
Human Leukocyte Antigen class II (HLA-II) molecules present peptides to T lymphocytes and play an important role in adaptive immune responses. Characterizing the binding specificity of single HLA-II molecules has profound impacts for understanding cellular immunity, identifying the cause of autoimmune diseases, for immunotherapeutics, and vaccine development. Here, novel high-density peptide microarray technology combined with machine learning techniques were used to address this task at an unprecedented level of high-throughput. Microarrays with over 200,000 defined peptides were assayed with four exemplary HLA-II molecules. Machine learning was applied to mine the signals. The comparison of identified binding motifs, and power for predicting eluted ligands and CD4+ epitope datasets to that obtained using NetMHCIIpan-3.2, confirmed a high quality of the chip readout. These results suggest that the proposed microarray technology offers a novel and unique platform for large-scale unbiased interrogation of peptide binding preferences of HLA-II molecules.
Introduction
The highly diverse major histocompatibility complex (MHC) proteins play a major role in the adaptive immune system. MHC class II proteins present peptides of variable lengths mainly derived from extracellular antigens (1). In humans, MHC is called human leukocyte antigen (HLA). The HLA locus is highly polymorphic, resulting in different HLA molecules having a specific peptide binding preference and specific peptidomes. The HLA is an important susceptibility locus in genetic studies of many immune-related diseases, often with multiple HLA alleles playing a role (2–4). However, beyond the suggested association, these studies do not inform about the causes of a disease, i.e., the antigen/epitope that binds to associated HLA proteins and potentially drive the disease onset. To make this link between HLA and antigen, further studies to characterize the peptidome bound by specific HLAs are necessary (5, 6). To this end, efficient and reliable high-throughput technologies for measuring peptide-HLA interaction are needed. Different assay types may be used to record the interaction between HLA and peptides (7). Classical in-vitro assays measure one single interaction of a synthetic peptide and an HLA-molecule in one experiment. Mass spectrometry of HLA eluted peptides considers the whole process of antigen synthesis up to presentation might fail the identification of low abundant peptides or modified peptides. To avoid costs and time delays in-silico prediction tools for HLA binding and antigen presentation have been trained on measured assay data (8–17).
Here, we set out to overcome the experimental limitations outlined above by employing our high-density peptide microarray data, a new high-throughput in-vitro technology (18, 19), combined with synthetic in-vitro generated HLA-II molecules (20) to perform large-scale unbiased characterization of HLA-II allele-specific binding. Earlier work has used peptide microarray for measuring peptide-HLA interaction, but this was limited to thousands of peptides per array (21). Here, the high-density peptide microarray enables the in-situ synthesis of over 2 million peptides per array on about 2 cm2 (18). To this end, we synthesized about 70,000 random peptides in triplicates on one array, allowing us to generate vastly more data points than the combined number of all HLA-DR epitopes registered in the immune epitope database IEDB (www.iedb.org) (7). This technology enables the analysis of whole proteomes of interest in one single experiment and the systematical analysis of post-translational modifications. Our presented technology offers a unique solution to produce large datasets to characterize binding properties of HLA-II molecules and improve the in-silico prediction of peptide-HLA interaction while being suitable for hypothesis driven tests.
To prove the quality of the high-density peptide microarray for characterizing peptide-HLA-II interactions, we selected four HLA-DRB1 proteins that are known to be strongly associated with ulcerative colitis, a complex chronic inflammatory bowel disease (2). For DRB1*01:03, DRB1*03:01, DRB1*15:01, and DRB1*15:02, a set of 69,815 random peptides were analyzed. To mine the extracted datasets and to learn predicting peptide-HLA binding, we applied NNAlign (22), as well as a deep learning approach, referred to as PIA (Peptide Immune Annotation). Using the obtained models, we assessed the quality of the chip readout in terms of identified binding motifs, and power to predict publicly available MS data from elution experiments as well as CD4+ epitope datasets in comparison to NetMHCIIpan-3.2 (8).
State of Research
Peptide-HLA Assays
The IEDB collects all types of immune epitopes. The oldest record is from 1952 (7). From the 90s to 2010, in-vitro assays measuring binding of synthetic peptides to HLA molecules (20, 23) were the most common MHC binding assays (www.iedb.org). In the last 5 years, mass-spectrometry (MS) sequencing of HLA eluted peptides (24, 25) became more popular (first records already in 1991).
Both methods have their strengths and weaknesses. In-vitro binding studies can measure interaction of individual peptide-HLA combinations. However, this approach is highly cost-intensive (one assay per peptide) and the assay fails to address some events leading up to effective HLA antigen presentation such as antigen processing, the effects of chaperones like HLA-DM, editing of the repertoire of HLA bound peptides (12, 14), and HLA-peptide complex stability. In contrast, recent advances in MS technology have expanded the detectable peptide repertoire presented by HLA molecules (immunopeptidome) by use of liquid chromatography MS. Immunopeptidome data include comprehensive information on the complex HLA ligand presentation (26), and analysis results of such data are a rich source of information for learning about the underlying rules of HLA antigen presentation. However, MS HLA peptide elution data mainly covers self-peptides and is assumed to miss low abundant peptides (26), further post-translational modifications might be identified but misinterpreted (27). Another problem arising with natural cell lines is that they most often present different HLA proteins. To solve this problem, either homozygous cell lines, tagging of a specific HLA allele (14, 28) or algorithms for deconvolution of the HLA proteomes can be employed (16, 17, 29). However, deconvolution has been shown to be of limited success in cases of lowly expressed HLA proteins or cells expressing HLA proteins with overlapping proteome specificity (14).
Peptide-HLA Binding Prediction
Beyond the different experimental approaches developed to specify peptide-HLA interaction, large efforts have been made to develop prediction models capable of accurately predicting peptide-HLA binding. Historically, most in-silico methods have been developed based on in-vitro binding data and an exemplary state-of-the-art computational method is NetMHCIIpan (8, 9, 30). Recently, prediction methods have been developed from HLA-II elution data (10–15). The results suggest that the inclusion of elution data has a positive impact on the predictive power of in-silico methods in particular for the prediction of HLA antigen presentation (10–15). Algorithms can be trained on either in-vitro or in-vivo data (8, 11, 14, 16), but a benefit from training on the two data types combined has been reported (10, 12, 13, 15, 17). However, currently even the best methods for prediction of HLA-II binding and antigen presentation suffer from an excessive number of false positive predictions.
Materials and Methods
Microarray
Peptide microarrays were produced by Schafer-N (Copenhagen, Denmark). Briefly, a Nexterion E microscope slide (Schott, Jena, Germany) were amino functionalized with a 1% w/v linear copolymer (1T0C) of N,N-dimethylacrylamide (Sigma-Aldrich) and aminoethyl methacrylate (Sigma-Aldrich) and used as substrate for solid-phase peptide synthesis. The peptide synthesis was initiated with the coupling of one unit of epsilon-amino-capronic acid (EACA) followed by the peptide sequences. The 1T0C and EACA unit served as a spacer between the array surface and the peptides allowing the HLA class II molecules to interact and peptides to protrude out of the HLA in both ends. For each experiment the same array-design was chosen. The peptide chips were subdivided into 12 sectors with a marker peptide “PVSKMRMATPLLMQA” of the HLA-II antigen gamma chain (CD74; UniProt: P04233-1: 103-117) placed multiple times in all the sectors corners. 69,815 different random natural 13-mer peptides were placed on the chip in triplicates. The chip does not contain peptides containing more than four poly residues (e.g., RRRR) as poly residues are difficult to synthesize and have a tendency toward unspecific binding.
Peptide microarrays were incubated with different HLA-DR molecules as previously described (31). Briefly, HLA-DR molecules were diluted from a stock (8 M Urea, 25 mM Tris, pH8) to achieve a final concentration of 500 nM HLA-DR in PBS, 0.05% Lutrol F68, 20% Glycerol pH 7.4 and added (overlaid) to the peptide array surface and allowed to fold for 24 h at 18°C before washing and staining with monoclonal mouse anti-HLA-DR (L243) and goat anti-mouse-Cy3. The peptide arrays were scanned with a laser-scanner (InnoScan, Innopsys, France) at a resolution of 1 μm and the amounts of bound HLA-DR were quantified to intensities between 0 and 254 by a proprietary software (Peparray, Schafer-N, Denmark). Larger spots with high values were excluded as noise.
The data was normalized by taking the median intensity of each repeated measurement for each peptide and transformed to fall in the range 0–1 by . The data was split into one test dataset comprising 10% of the data and a 10-fold cross-validation dataset of the remaining data. To ensure limited data redundancy between subsets, therefore similar peptides [e.g., a 9-mer overlap (underlined amino acids in the following are the same), for example AALITRGLTEMGR and ARTALITRGLTEM, or at least 11 of the 13 amino acids in the same order, for example ADLGSGAGAAGLA and ALGSGAAGAAFGL] were placed into the same subset. For the performance evaluation, the data was back-transformed to the intensity scale.
Consistency Metrics
We evaluated the consistency of the triplicates using the coefficient of variation (CoV) and the Pearson Correlation Coefficient (PCC) between three replicates. The CoV for each repeated peptide measurement was calculated as the standard deviation of intensity divided by mean intensity +1 and the mean CoV over the 69,815 peptides for all four alleles was given.
The PCC between the three replicates was calculated combining the pairwise PCCs R12, R13, and R23 as R123= (32).
Epitope and Eluted Ligand Test Datasets
T cell epitopes and HLA ligands obtained from mass spectrometry were downloaded from IEDB and used as independent test data (www.iedb.org, June 18th 2019) (7). Only positive linear peptides with a length between 13 and 19 amino acids were used. Data with an overlapping sequence of at least 9 amino acids with the peptide microarray data or an unknown amino acid were excluded. This resulted in 502 epitopes and 719 ligands for the four alleles (Supplementary Table 1).
Negative data (peptides thought not to bind the respective alleles) were added by downloading the sequence of the epitope/ligand source protein as linked by IEDB from NCBI (www.ncbi.nlm.nih.gov), and in-silico digesting by a sliding window of the length of the ligand/epitope into overlapping peptides. Peptides with an overlap of 9 amino acids with the peptides used in training or the positive peptides were excluded.
For predicting the binding affinity for a peptide, prediction on all 13-mer subsequences was made and the highest prediction value reported.
Finally, the performance for each epitope/ligand was reported as the Frank value. The Frank value of a binding peptide is the ratio of the number of peptides with a higher predicted binding score in the source protein divided by the overall number of peptides within the protein (8).
NNAlign
NNAlign-2.1 was used on the peptide microarray data (22). NNAlign generates artificial neural network models of receptor-ligand interactions. The program takes as input a set of ligand sequences with target values; it returns a sequence alignment, a binding motif of the interaction, and a model that can be used to scan for the motif in other sequences. Further details of the used parameters can be found in the Supplementary Methods. The motifs generation by Seq2Logo (33) is automatically performed by NNAlign.
Deep Learning Model PIA
PIA is a gated recurrent neural network (GRU) based model (34) implemented using Keras (https://keras.io) deep learning framework with TensorFlow (www.tensorflow.org). Further details on the model architecture can be found in the Supplementary Methods.
For generating the logos, 500,000 13-mers were randomly selected from the human reference proteome and screened using PIA. The top 1% of peptides were submitted to GibbsCluster-2.0 (29) for motif identification.
Results
High-density peptide microarrays were used to identify large, unbiased peptidome datasets for four HLA-DR molecules. We describe the raw peptide chip readout to quantify data consistency and make comparisons to earlier in-vitro binding experimental results. Further, we describe the results of applying two machine-learning frameworks to mine and extract the rules for peptide-HLA binding from the chip data, and we assess the quality of the chip data by comparing the power of the constructed models to that of NetMHCIIpan-3.2 for prediction of HLA ligands and epitopes.
Microarray Experiments
The peptide microarray contained 69,815 random 13-mer peptides. An example of the raw readout of the array is shown in Supplementary Figure 1, confirming overall clear signals corresponding to discrete peptides. To assess the accuracy and consistency of the array readout, two metrics were used: the CoV and correlation coefficient between the three repeated peptide measurements (for details see Materials and Methods). Overall, this analysis demonstrated highly consistent values with a mean CoV over the 69,815 peptides for all four alleles of 0.135 and a correlation coefficient over 0.988 for the single microarrays (Supplementary Figure 2).
For further validation of the microarray readout, the amino acid composition of the top 2% peptides with highest signal was compared to the amino acid composition of peptide binders as obtained from the IEDB for the HLA molecules where available. The results of this analysis are shown in Supplementary Figure 3 and confirmed an overall high consistency between the two with correlation coefficients for HLA-DRB1*03:01 and HLA-DRB1*15:01 above 0.910.
For further analysis, the median of the triplicate was used.
Prediction of Microarray Data
For building the prediction models, the microarray data was log-transformed to reduce the skew and to optimize the range of the data. We trained the NNAlign and the GRU based PIA models using 10-fold CV for each allele. In all cases, PIA outperformed NNAlign. Figures 1A,B show the PCC and the Spearman correlation coefficient (SCC) performance values of the two models on the test dataset. Here, PIA outperforms NNAlign in all cases. Figure 1B also includes the SCC performance of NetMHCIIpan-3.2, which is trained on in vitro IC50 binding values demonstrating at least a SCC of above 0.53 for the different alleles for predicting the chip test data.
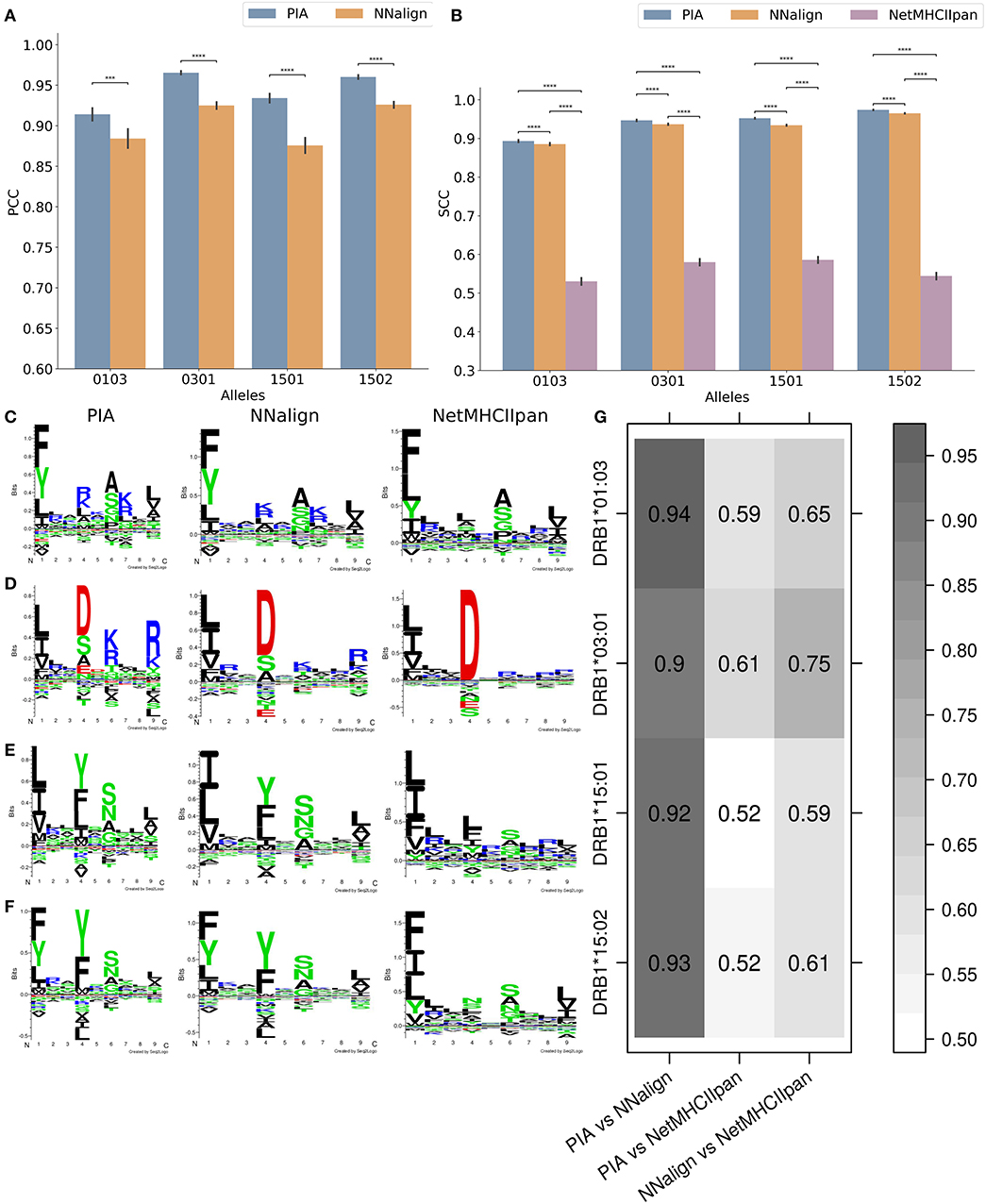
Figure 1. Performance of the models on peptide microarray data and resulting motifs. (A) The Pearson correlation coefficient (PCC) and (B) the Spearman correlation coefficient (SCC) on the independent test dataset of the peptide microarray are shown. The pairwise p-values were calculated using a non-parametric bootstrap hypothesis test with 1,000,000 bootstrap iterations. *0.01 < p ≤ 0.05, **0.001 < p ≤ 0.01, ***0.0001 < p ≤ 0.001, and ****p ≤ 0.0001. Motif plots of (C) DRB1*01:03, (D) DRB1*03:01, (E) DRB1*15:01, and (F) DRB1*15:02 based on the top 1% (from a pool of 100,000 random natural peptide) binding peptides generated with the deep learning model (PIA), NNAlign model and NetMHCIIpan-3.2 (8). (G) Pearson correlation coefficient (PCC) of the position specific scoring matrices (PSSM) between the different models.
To quantify the consistencies between different data types and prediction models, binding motifs were estimated for each HLA molecule and prediction model (Figures 1C–F). The binding motifs identified by the peptide microarray based models are close to identical and in most cases similar to those generated with NetMHCIIpan-3.2 using Seq2Logo (8, 33). To compare the motifs obtained by the two microarray-based models, we performed a correlation analysis of the 9 × 20 position specific scoring matrix produced by Seq2Logo defining the predicted binding motif. In all four cases, we obtained PCC values above 0.90 (Figure 1G). When comparing the NNAlign and NetMHCIIpan motifs, the correlation values were still very high with 0.59–0.75.
Predict Ligands Measured by Mass Spectrometry
To further assess the predictive power of the developed methods, we performed a benchmark on a set of HLA eluted ligands as obtained from the IEDB (7). Here, the Frank value was used as performance measure (8). In short, Frank is the proportion of peptides within a source protein with a prediction value greater than the given ligand. The Frank is 0 if the ligand is the peptide with the highest binding score and 0.5 for random predictions. To limit the effect of noise and falsely positive assigned data points, only ligands that obtained a Frank value of 0.15 or less for at least one of the included prediction models were included in the benchmark. As the IEDB currently does not contain any ligands for DRB1*15:02 the molecule was excluded from our analysis (Supplementary Table 1). The results (Figure 2A) demonstrate an overall comparable performance of the three methods. The microarray-based methods and NetMHCIIpan-3.2 each outperform the other for one dataset (NetMHCIIpan-3.2 performs better for DRB1*01:03, and PIA and NNAlign for DRB1*15:01). No consistent performance difference was observed between the NNAlign and PIA models.

Figure 2. Comparisons of prediction quality on (A) MS ligand and (B) epitope data. The center line inside the box indicates the median Frank and the triangle shows the mean Frank. The data points available in IEDB are represented using a jitter plot. The colored box covers the interquartile range. The whiskers represent 1.5-fold of the interquartile range. Pairwise p-values were calculated using a Wilcoxon signed-rank test (applying Pratt's zero method). *0.01 < p ≤ 0.05, **0.001 < p ≤ 0.01, ***0.0001 < p ≤ 0.001, and ****p ≤ 0.0001.
Predict CD4+ Epitopes
The same analysis performed on the HLA eluted ligand data was done on a set of CD4+ T cell epitopes available from the IEDB (Supplementary Table 1). The results (Figure 2B) show that the microarray-data based models in most cases performed on par with NetMHCIIpan-3.2. For DRB1*15:01, NetMHCIIpan-3.2 significantly outperformed both peptide microarray-based methods. For DRB1*01:03, the microarray-based models showed an increased performance compared to NetMHCIIpan-3.2. This latter difference was, however, not statistically significant due to the limited number of epitopes available in the benchmark. Moreover, the results indicate a slightly improved performance of NNAlign over PIA.
Discussion
Genetic variants in the HLA gene region have been associated with a multitude of diseases, not only autoimmune conditions. Earlier work suggests this to be caused by an intrinsic property of particular HLA variants [for instance different HLA-DQ alleles influencing IL-17 production in T-cells irrespective of the peptide ligand (35)]. However, beyond this and for most HLA's and diseases, the detailed underlying mechanisms and candidate antigens remain unknown. Experimentally testing all possible peptide-HLA combinations to identify the relevant antigens for a given disease is a major undertaking, and with current technologies in most cases not feasible.
To deal with this limitation, we here present a new type of HLA-II antigen interaction assay based on high-density peptide microarrays. This technique allows the assessment of more than 200,000 independent peptide-HLA interaction tests within one single experiment.
We demonstrate how this high-density peptide array serves as a novel, valuable source for high-throughput and high-volume data to accurately characterize the peptidome of HLA-II molecules and its binding specificity. We demonstrated this by quantifying the consistency between internal replica (peptides analyzed multiple times on a given microarray), and by comparing the amino acid composition of the peptidomes as obtained from the peptide microarray to that obtained using conventional in-vitro binding assays with solid phase synthesized peptides. We furthered the validation by applying machine learning methods to mine and extract the HLA binding signal from the microarray data and compared the derived binding motif and power of the associated prediction model to state-of-the-art methods trained on conventional in-vitro binding data. All comparisons confirmed a high consistency of the microarray data with conventional methods.
In our study, two different machine learning algorithms were applied to mine the large-scale microarray datasets. The first is NNAlign, which is the basis for NetMHCIIpan-3.2 and NetMHCII 2.3 (8, 22) accepted to be among the best available for prediction of peptide binding to HLA-II (30). The second, PIA is based on GRU, a deep learning architecture developed for sequence learning. Both algorithms are able to capture the signal within the peptide microarray data and predict the microarray test dataset with very high performance.
Moreover, the two prediction models trained on the microarray data were benchmarked against NetMHCIIpan-3.2 on independent data of HLA eluted ligand and CD4+ epitope data obtained from the IEDB. Here, all models were found to perform at par, suggesting that the measurements obtained from the microarray are accurately capturing signals of peptide-HLA binding.
The microarray experiments performed here were conducted in the absence of HLA II peptide- loading chaperones such as HLA-DM and HLA-DO earlier demonstrated to play a role in editing the repertoire of HLA class II binding peptides (36, 37). Future work will tell if similar results are obtained in the context of the peptide-microarray technology.
Overall, our results suggest that the described microarray technology for large-scale evaluations of peptide-HLA-II interaction is accurate, precise and highly scalable. We believe this result opens a venue of novel applications addressing challenges and biological problems that can only to a limited extent be addressed using conventional immunoassays. Such applications include mapping the impact of peptide-specific post-translational modifications (such as phosphorylation, deamination, or citrullination, all of these modifications can be added in the peptide synthesis step, i.e., in the array design process) on HLA-II binding and unbiased large-scale screening for HLA-II binding of pathogen proteomes. The herein presented in-silico technology data is in our opinion a good addition to immunopeptidome data for the next generation of prediction tools.
Data Availability Statement
The high density peptide raw datasets generated for this study can be downloaded from https://www.ikmb.uni-kiel.de/resources/download-tools/publicly-available-data. All other data are available from the corresponding authors upon request.
Author Contributions
ER, TØ, SB, AF, and MW designed the wet lab experiments. TØ performed the wet lab experiments. MW prepared the data for training. HE implemented PIA. HG trained NNAlign and prepared the IEDB data, and plotted the final figures. MW, HG, FD, and MN performed statistical analysis. MW and MN wrote the paper with input from HG and HE. All authors commented on the final manuscript.
Funding
MW and HE were funded by the German Research Foundation (DFG) (Research Training Group 1743, Genes, Environment and Inflammation). MN was researcher of CONICET. This project received infrastructure support by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany's Excellence Strategy—EXC 2167-390884018, the Agencia Nacional de Promoción Científica y Tecnológica, Argentina (PICT-2016-0089), the Independent Research Fund Denmark award DFF−6110-00644 and the Danish MS Society award A31444.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fimmu.2020.01705/full#supplementary-material
References
1. Chicz RM, Urban RG, Gorga JC, Vignali DA, Lane WS, Strominger JL. Specificity and promiscuity among naturally processed peptides bound to HLA-DR alleles. J Exp Med. (1993) 178:27–47. doi: 10.1084/jem.178.1.27
2. Goyette P, Boucher G, Mallon D, Ellinghaus E, Jostins L, Huang H, et al. High-density mapping of the MHC identifies a shared role for HLA-DRB1*01:03 in inflammatory bowel diseases and heterozygous advantage in ulcerative colitis. Nat Genet. (2015) 47:172–9. doi: 10.1038/ng.3176
3. Liu H, Irwanto A, Fu X, Yu G, Yu Y, Sun Y, et al. Discovery of six new susceptibility loci and analysis of pleiotropic effects in leprosy. Nat Genet. (2015) 47:267–71. doi: 10.1038/ng.3212
4. Liu JZ, Hov JR, Folseraas T, Ellinghaus E, Rushbrook SM, Doncheva NT, et al. Dense genotyping of immune-related disease regions identifies nine new risk loci for primary sclerosing cholangitis. Nat Genet. (2013) 45:670–5. doi: 10.1038/ng.2616
5. Karnes JH, Bastarache L, Shaffer CM, Gaudieri S, Xu Y, Glazer AM, et al. Phenome-wide scanning identifies multiple diseases and disease severity phenotypes associated with HLA variants. Sci Transl Med. (2017) 9:1–13. doi: 10.1126/scitranslmed.aai8708
6. Miyadera H, Tokunaga K. Associations of human leukocyte antigens with autoimmune diseases: challenges in identifying the mechanism. J Hum Genet. (2015) 60:697–702. doi: 10.1038/jhg.2015.100
7. Vita R, Mahajan S, Overton JA, Dhanda SK, Martini S, Cantrell JR, et al. The immune epitope database (IEDB): 2018 update. Nucleic Acids Res. (2019) 47:D339–D343. doi: 10.1093/nar/gky1006
8. Jensen KK, Andreatta M, Marcatili P, Buus S, Greenbaum JA, Yan Z, et al. Improved methods for predicting peptide binding affinity to MHC class II molecules. Immunology. (2018) 154:394–406. doi: 10.1111/imm.12889
9. Andreatta M, Trolle T, Yan Z, Greenbaum JA, Peters B, Nielsen M. An automated benchmarking platform for MHC class II binding prediction methods. Bioinformatics. (2018) 34:1522–8. doi: 10.1093/bioinformatics/btx820
10. Chen B, Khodadoust MS, Olsson N, Wagar LE, Fast E, Liu CL, et al. Predicting HLA class II antigen presentation through integrated deep learning. Nat Biotechnol. (2019) 37:1332–43. doi: 10.1038/s41587-019-0280-2
11. Shao XM, Bhattacharya R, Huang J, Sivakumar IKA, Tokheim C, Zheng L, et al. High-throughput prediction of MHC class I and II neoantigens with MHCnuggets. Cancer Immunol Res. (2020) 8:396–408. doi: 10.1158/2326-6066.CIR-19-0464
12. Barra C, Alvarez B, Paul S, Sette A, Peters B, Andreatta M, et al. Footprints of antigen processing boost MHC class II natural ligand predictions. Genome Med. (2018) 10:84. doi: 10.1186/s13073-018-0594-6
13. Reynisson B, Barra C, Kaabinejadian S, Hildebrand WH, Peters B, Nielsen M. Improved prediction of MHC II antigen presentation through integration and motif deconvolution of mass spectrometry MHC eluted ligand data. J Proteome Res. (2020) 19:2304–15. doi: 10.1101/799882
14. Abelin JG, Harjanto D, Malloy M, Suri P, Colson T, Goulding SP, et al. Defining HLA-II ligand processing and binding rules with mass spectrometry enhances cancer epitope prediction. Immunity. (2019) 51:766–79.e17. doi.org/10.1016/j.immuni.2019.08.012
15. Garde C, Ramarathinam SH, Jappe EC, Nielsen M, Kringelum J V., Trolle T, et al. Improved peptide-MHC class II interaction prediction through integration of eluted ligand and peptide affinity data. Immunogenetics. (2019) 71:445–54. doi: 10.1007/s00251-019-01122-z
16. Racle J, Michaux J, Rockinger GA, Arnaud M, Bobisse S, Chong C, et al. Robust prediction of HLA class II epitopes by deep motif deconvolution of immunopeptidomes. Nat Biotechnol. (2019) 37:1283–6. doi: 10.1038/s41587-019-0289-6
17. Alvarez B, Reynisson B, Barra C, Buus S, Ternette N, Connelley T, et al. NNAlign_MA; MHC peptidome deconvolution for accurate MHC binding motif characterization and improved T-cell epitope predictions. Mol Cell Proteomics. (2019) 18:2459–77. doi: 10.1074/mcp.TIR119.001658
18. Buus S, Rockberg J, Forsström B, Nilsson P, Uhlen M, Schafer-Nielsen C. High-resolution mapping of linear antibody epitopes using ultrahigh-density peptide microarrays. Mol Cell Proteomics. (2012) 11:1790–800. doi: 10.1074/mcp.M112.020800
19. Hansen LB, Buus S, Schafer-Nielsen C. Identification and mapping of linear antibody epitopes in human serum albumin using high-density peptide arrays. PLoS ONE. (2013) 8:e68902. doi: 10.1371/journal.pone.0068902
20. Justesen S, Harndahl M, Lamberth K, Nielsen L-LB, Buus S. Functional recombinant MHC class II molecules and high-throughput peptide-binding assays. Immunome Res. (2009) 5:2. doi: 10.1186/1745-7580-5-2
21. Gaseitsiwe S, Valentini D, Ahmed R, Mahdavifar S, Magalhaes I, Zerweck J, et al. Major histocompatibility complex class II molecule-human immunodeficiency virus peptide analysis using a microarray chip. Clin Vaccine Immunol. (2009) 16:567–73. doi: 10.1128/CVI.00441-08
22. Nielsen M, Andreatta M. NNAlign: a platform to construct and evaluate artificial neural network models of receptor–ligand interactions. Nucleic Acids Res. (2017) 45:2–7. doi: 10.1093/nar/gkx276
23. Sidney J, Southwood S, Moore C, Oseroff C, Pinilla C, Grey HM, et al. Measurement of MHC/peptide interactions by gel filtration or monoclonal antibody capture. Curr Protoc Immunol. (2013) Chapter 18:Unit 18.3. doi: 10.1002/0471142735.im1803s100
24. Bassani-Sternberg M, Coukos G. Mass spectrometry-based antigen discovery for cancer immunotherapy. Curr Opin Immunol. (2016) 41:9–17. doi: 10.1016/j.coi.2016.04.005
25. Caron E, Kowalewski DJ, Chiek Koh C, Sturm T, Schuster H, Aebersold R. Analysis of major histocompatibility complex (MHC) immunopeptidomes using mass spectrometry. Mol Cell Proteomics. (2015) 14:3105–17. doi: 10.1074/mcp.O115.052431
26. Vaughan K, Xu X, Caron E, Peters B, Sette A. Deciphering the MHC-associated peptidome: a review of naturally processed ligand data. Expert Rev Proteomics. (2017) 14:729–36. doi: 10.1080/14789450.2017.1361825
27. Ramarathinam SH, Croft NP, Illing PT, Faridi P, Purcell AW. Employing proteomics in the study of antigen presentation: an update. Expert Rev Proteomics. (2018) 15:637–45. doi: 10.1080/14789450.2018.1509000
28. Yang J, Jaramillo A, Shi R, Kwok WW, Mohanakumar T. In vivo biotinylation of the major histocompatibility complex (MHC) class II/peptide complex by coexpression of BirA enzyme for the generation of MHC class II/tetramers. Hum Immunol. (2004) 65:692–9. doi: 10.1016/j.humimm.2004.04.001
29. Andreatta M, Alvarez B, Nielsen M. GibbsCluster: unsupervised clustering and alignment of peptide sequences. Nucleic Acids Res. (2017) 45:W458–63. doi: 10.1093/nar/gkx248
30. Zhao W, Sher X. Systematically benchmarking peptide-MHC binding predictors: From synthetic to naturally processed epitopes. PLoS Comput Biol. (2018) 14:e1006457. doi: 10.1371/journal.pcbi.1006457
31. Osterbye T, Nielsen M, Dudek NL, Ramarathinam SH, Purcell AW, Schafer-Nielsen C, et al. HLA class II specificity assessed by high-density peptide microarray interactions. J Immunol. (2020) 205:290–9. doi: 10.1101/2020.02.28.969667
32. Wang J, Zheng N. Measures of correlation for multiple variables. arXiv. (2014). 1–20. Available online at: http://arxiv.org/abs/1401.4827v6 (accessed January 27, 2020).
33. Thomsen MCF, Nielsen M. Seq2Logo: a method for construction and visualization of amino acid binding motifs and sequence profiles including sequence weighting, pseudo counts and two-sided representation of amino acid enrichment and depletion. Nucleic Acids Res. (2012) 40:281–7. doi: 10.1093/nar/gks469
34. Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Conference on Empirical Methods in Natural Language Processing (EMNLP 2014). (2014) Available online at: https://arxiv.org/abs/1406.1078v3 (accessed September 03, 2020).
35. Mangalam AK, Taneja V, David CS. HLA class II molecules influence susceptibility versus protection in inflammatory diseases by determining the cytokine profile. J Immunol. (2013) 190:513–19. doi: 10.4049/jimmunol.1201891
36. Abelin JG, Harjanto D, Malloy M, Suri P, Colson T, Goulding SP, et al. Defining HLA-II ligand processing and binding rules with mass spectrometry enhances cancer epitope prediction. Immunity. (2019) 51:766–79.e17. doi: 10.1016/j.immuni.2019.08.012
Keywords: ultra-high density peptide microarray, MHC class II, HLA, antigen presentation, prediction, peptide binding, high-throughput, machine learning
Citation: Wendorff M, Garcia Alvarez HM, Østerbye T, ElAbd H, Rosati E, Degenhardt F, Buus S, Franke A and Nielsen M (2020) Unbiased Characterization of Peptide-HLA Class II Interactions Based on Large-Scale Peptide Microarrays; Assessment of the Impact on HLA Class II Ligand and Epitope Prediction. Front. Immunol. 11:1705. doi: 10.3389/fimmu.2020.01705
Received: 21 February 2020; Accepted: 25 June 2020;
Published: 05 August 2020.
Edited by:
Laura Santambrogio, Weill Cornell Medicine, United StatesReviewed by:
Markus Maeurer, Champalimaud Foundation, PortugalJames Drake, Albany Medical College, United States
Copyright © 2020 Wendorff, Garcia Alvarez, Østerbye, ElAbd, Rosati, Degenhardt, Buus, Franke and Nielsen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mareike Wendorff, m.wendorff@ikmb.uni-kiel.de; Andre Franke, a.franke@mucosa.de
†These authors have contributed equally to this work