
Abstract
Model-informed drug development involves developing and applying exposure-based, biological, and statistical models derived from preclinical and clinical data sources to inform drug development and decision-making. Discrete models are generated from individual experiments resulting in a single model expression that is utilized to inform a single stage-gate decision. Other model types provide a more holistic view of disease biology and potentially disease progression depending on the appropriateness of the underlying data sources for that purpose. Despite this awareness, most data integration and model development approaches are still reliant on internal (within company) data stores and traditional structural model types. An AI/ML-based MIDD approach relies on more diverse data and is informed by past successes and failures including data outside a host company (external data sources) that may enhance predictive value and enhance data generated by the sponsor to reflect more informed and timely experimentation. The AI/ML methodology also provides a complementary approach to more traditional modeling efforts that support MIDD and thus yields greater fidelity in decision-making. Early pilot studies support this assessment but will require broader adoption and regulatory support for more evidence and refinement of this paradigm. An AI/ML-based approach to MIDD has the potential to transform regulatory science and the current drug development paradigm, optimize information value, and increase candidate and eventually product confidence with respect to safety and efficacy. We highlight early experiences with this approach using the AI compute platforms as representative examples of how MIDD can be facilitated with an AI/ML approach.
Graphical abstract

Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Model-informed drug development (MIDD) is an approach that involves developing and applying exposure-based, biological, and statistical models derived from preclinical and clinical data sources to inform drug development and decision-making. MIDD was formally recognized in Prescription Drug User Fee Act (PDUFA) VI. There have been many regulatory applications of MIDD to address a variety of drug development and regulatory questions. Likewise, pharmaceutical sponsors have been investing in the approach to ensure that MIDD capabilities meet regulatory expectations and fulfill the needs of the various project teams that rely on the approach to de-risk stage-gate decision and maintain documentation and transparency for regulatory authorities. As pharmaceutical sponsors have invested in MIDD for 20 or more years in some cases, there is better quantitative data on the impact of the approach, its efficiency in decision-making, and its impact on drug development in general. Most of these factors lead to a very positive conclusion regarding the approach. But still, the question remains, can we do it better and more efficiently?
The scope of this review is to describe the current MIDD approach in the context of the data, model types, and decision value across the drug development continuum in comparison to the evolving use of AI/ML to inform various aspects of drug development. The primary objective is to consider an AI/ML-based approach which is either complementary to or entirely self-sufficient to inform stage-gate decision-making in a manner comparative to the current MIDD paradigm with some discussion regarding how ROI (return on investment) can be further enhanced with some discussion about future requirements to enhance regulatory acceptance and more dedicated investment for this purpose by pharmaceutical sponsors. It is also important and relevant that non-AI stakeholders are able to assess the value of the approach and are integrated into the ecosystem that interprets and endorses the approach from both an MIDD and a decision-making perspective.
Traditional MIDD Data Flow and Parallel Model Development
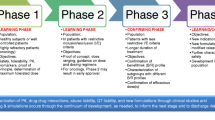
Model-informed drug development (MIDD) is an approach that involves developing and applying exposure-based, biological, and statistical models derived from preclinical and clinical data sources to inform drug development and decision-making [1, 2]. Most discrete models are generated from individual experiments or preclinical/clinical trials resulting in a model expression that is utilized to inform an individual stage-gate decision (see Fig. 1). In the preclinical arena, most of the effort is focused on two main themes. Primarily, the emphasis is based on creating a rationale for target candidates to fulfill requirements to treat an unmet medical need as defined in the target product profile (TPP). In addition to experiments that generate data designed to assess a candidate molecule’s druggability and desired ADME properties, some notion of a preclinical proof-of-concept (POC) is conducted. Secondary to the preclinical POC, a battery of safety pharmacology and toxicology studies that determine if a candidate molecule is adequately safe to pursue clinical phase testing in humans is conducted. Single- (acute) and multiple-dose (chronic) toxicology and toxicokinetic studies are conducted in multiple species as part of this effort. Complementary to the pharmacology and toxicology studies that help to project the human therapeutic window and justify the FIH dosing strategy and early clinical development plan are experiments that support the development of early formulations. Table I summarizes the data (types and dimensions), model types, and decisions to inform across the drug development continuum with a traditional MIDD approach implemented.

MIDD deliverables linked to development phase and stage-gate decisions informed by the various model constructs, illustrating the trend of integrating discrete model types
Each of these experiments is often informed by models that help define the experimental design, sampling scheme, and sample size at a minimum. Most of the inputs (data) for these models are generated by the sponsor themselves either from the active drug substance’s chemical attributes or early in vitro or in vivo experiments. There exists a sequential nature to the design and conduct of these experiments such that early experiments often are used to refine these models and help design the next phase of testing. For small molecules and most therapeutic proteins, there is an implicit relationship that defines the dose ➔ exposure ➔ response sequence that is unique to the drug substance being developed. It is the implicit goal of the sponsor to quantify this relationship in as rapid a manner as possible and accelerate favorable candidates to the next phase of testing or abandon those with unfavorable characteristics in the so-called “quick kill” approach. Efficiency in this effort is facilitated by adopting the MIDD approach. Evidence to the benefit of the MIDD approach for this purpose has been previously published by both pharmaceutical sponsors themselves [3,4,5] and regulatory authorities [6,7,8,9].
Likewise, clinical phase testing encourages the continuation of this approach with more emphasis on human patient level PK/PD evaluation with additional knowledge of the formulation properties of what hopefully will be the final market image (route, dosage form, and strengths to be submitted/approved). Linkage between parameters that define the PD response and endpoints that will represent the basis for approval if warranted is also sought. The same sequential flow is still in place and expected (one or more trials informing models that inform the next phase of testing) but there is also the occasion to introduce other data types potentially as a compound moves into later phases of clinical evaluation (phases 2 and 3). Such sources may also have been generated outside of the host company (natural history data, claims data, and other RWD sources that help define the standard of care of the patient population). The rationale for their inclusion in various MIDD modeling assets is based on the information value they at least theoretically bring to refining the expected clinical performance in the target population.
Other model types provide a more holistic view of disease biology and potentially disease progression depending on the appropriateness of the underlying data sources for that purpose. More recently, there is a growing awareness of the benefit of integrating various discrete model types both from the standpoint of shared and integrated data as well as the development of structural models and diverse but complementary model types that support a broader set of stage-gate decisions. These model types are developed with less frequency as they often reflect more multidisciplinary investment and buy-in and occasionally require input (data and intellectual contributions) from external subject matter experts as well. This level of engagement may require contractual relationships including confidentiality obligations which can extend timelines and potentially incur delays that impact their effectiveness at informing stage-gate decisions.
An important baseline for the current MIDD approach applied to the traditional drug development paradigm is that MIDD is applied based on regulatory timelines dictated by the IND and NDA process that has not changed much over the last 30 years with respect to the content expectations. These content requirements necessitate that the sponsors plan and conduct the requisite experiments and clinical trials in a certain order based on an implicit evaluation of the probability of technical success (PTOS). The evaluation of PTOS across the traditional phases of development suggests that PTOS is neither consistent across the phases nor linear over time [10]. Simply put, some phases are more risky than others. It is appreciated by many that MIDD has improved PTOS in all phases, but the current approach has not altered the content of the submissions, or the timelines dictated by the IND and NDA process in any systematic manner.
To manage the computational aspects of an MIDD approach, sponsors either have to invest in internal compute infrastructure or purchase computing services. Historically and mainly motivated by IP, confidentiality, and security considerations, most organizations initially preferred to purchase the required hardware and software maintaining their own governance over their compute environments and, at least in theory, facilitating the transfer of the required data into these systems. Many constructed home-grown solutions envisioned by their modeling community and governed by their IT staff. Most of these have had a short lifetime, especially with many internal IT services being contracted out over the same window of time. With the evolution of secure and flexible cloud-based computing services, hybrid or entirely cloud-based computing services have become more prevalent. Figure 2 highlights the current compute environment to support traditional MIDD paradigms and exposing the general compute infrastructure components that support the environment. An important emphasis for this evolving environment is how to cope with complex data types (e.g., digital data and various real-world data (RWD) sources) and how to integrate disparate data types into analysis datasets. The extent to which these various newer data types inform an MIDD approach is currently unknown but will certainly be a part of the future evaluation of the approach.

Environment to support traditional MIDD paradigms (a) and general compute infrastructure components to support AI/ML-enabled MIDD (b)
An AI/ML-Based Paradigm Focused on Information Value and Regulatory Milestones
Artificial intelligence approaches to inform drug development are most focused at early and late stages of development mostly based on the nature and type of data generated in these stages. At early stages of development, the chemical space is generally viewed as comprising >1060 molecules [11]. The virtual chemical space is vast and suggests a geographical map of molecules by illustrating the distributions of molecules and their properties. The idea behind the illustration of chemical space is to collect positional information about molecules within the space to search for bioactive compounds, and thus, virtual screening helps to select appropriate molecules for further testing. Several chemical spaces are open access, including PubChem, ChemBank, DrugBank, and ChemDB.
AI is well-suited for these tasks because it can handle large volumes of data with enhanced automation. AI involves several method domains, such as reasoning, knowledge representation, solution search, and, among them, a fundamental paradigm of machine learning (ML). ML uses algorithms that can recognize patterns within a set of data that has been further classified. A subfield of the ML is deep learning (DL), which engages artificial neural networks (ANNs). While discovery groups are eager to leverage AL/ML to acquire meaningful insights from the enormous data they hold or acquire, the accuracy of the AI/ML models depends on the volume and quality of the data used as an input for training them. Inaccurate input data results in misleading outcomes delivered by the AI/ML models. While automation systems can cleanse data based on explicit programming rules, it is almost impossible for them to fill in missing data gaps without manual intervention or plugging in additional data source feeds. However, machine learning can make calculated assessments on missing data based on its reading of the situation.
The cost of bringing new drugs from bench to bedside has become excessively steep. In identifying these trends, AI/ML-driven in silico platforms are alluring to the pharmaceutical and healthcare industry due to their multidimensional, predictive capabilities, and the associated increased efficiency. Traditional MIDD approaches have been used in drug discovery and development over the last two decades with the recent increase in complexity from the usage of AI/ML-driven in silico platforms. Application opportunities for AI/ML can be associated with all stages of drug discovery and development, for example, drug-target validation and engagement, identification of prognostic biomarkers and evaluation of digitized clinical pathology data in clinical trials, and finally high-accuracy predictions of the pharmacokinetic, pharmacodynamic, and efficacy parameters from a limited pool of physiological and pharmacological preclinical and clinical datasets. Recently, in the drug development pipeline, AI/ML has had a marked impact in clinical trial design, conduct, and analysis. In addition, the COVID-19 pandemic may increase the pace of the usage of AI/ML in clinical trials due to an increased trust in digital technologies in clinical trial design and conduct. There have been significant advances in AI/ML-driven MIDD in the context of the drug discovery and development pipelines recently [12, 13], and many companies are at various stages of development in the use of AI/ML and even attached to data services and platforms supporting various pharmaceutical industry supports. Table II provides an initial landscape assessment of companies focused on AI-based technologies to support drug development. There is much diversity of companies and business models with several companies utilizing AI to identify key drug candidates internally. For this evaluation, we will focus on a few platforms including VeriSIM Life (VSL) and some case studies from literature to illustrate the essentials of the approach and make comparisons with more traditional MIDD approaches.
Many of the companies listed in Table II contain compute platforms through which AI/ML approaches are enabled with connectivity to relevant data sources. VSL has developed BIOiSIMTM, an AI-enabled computational platform that integrates MIDD-based mechanistic systems biology modeling with AI/ML algorithms to enable an effective data-driven decision-making engine. The platform is constantly validated by available public databases and publications, generating data with partnerships with CROs and data partnerships with national academic labs and FDA-associated institutions that provide informed decision-based models to the regulatory institutions. Classical MIDD in the context of PK modeling typically faces several challenges: non-adaptive simulation, insufficient data to reach accuracy, time consumption, where the existing software is built out one model at a time, and scalability. BIOiSIMTM addresses many of these challenges by integrating data across diverse compounds from public and private sources, running validation reports across these extensive datasets frequently, scaling the software to AWS cloud, making the GUI user-friendly for diverse researcher backgrounds, and utilizing AI/ML algorithms to predict cases by imputation and adaptive simulations, where parameter values are unknown or require extensive data collection. Other platforms have different approaches to data and model integration in the context of decision-making but many are only focused on early stage drug development (see Table II).
Static vs Dynamic Framework
Given the high attrition rate, rising costs, and time to bring new therapeutic agents to market, newer approaches and technologies are being incorporated into drug development to bring in much needed efficiencies. Moreover, the translational gap increases the chances of drug failures as the cross-functional decision-making process is highly complicated and not well-informed. Currently employed methods are static and non-adaptive and geared towards statistical inference only for a specific outcome (e.g., ADMET, Pop-PK) than the comprehensive data-driven predictions to make accurate, informed decisions that will help reduce animal trials and more personalized human trials. Furthermore, the deployed models are not often scalable as they are not validated thoroughly and are often biased to fit the single-case/use scenario. Recently, the use of artificial intelligence, owing to its capability to analyze large volumes of data and generate meaningful insights, has been increasing in various sectors, particularly the pharmaceutical industry. The potential of AI in the drug development pipeline from the bench to the bedside can be imagined since it can aid rational drug design; assist in decision-making; determine the right therapy for a patient, including personalized medicines; and manage the preclinical and clinical datasets for potential drug development of new chemical entities and associated downstream predictions. One concern for AI to be used effectively is the need for vast amount of data for training and testing the algorithms which is a limitation in pharma/biotech industry either due to reluctance in sharing data or non-availability or highly variable data. A hybrid AI approach can transform the static system to a dynamic adaptive one where sophisticated AI/ML algorithms can be integrated to mechanistic/semi-mechanistic systems biology models to boost physiological relevance. A platform which learns massively from the historical datasets, utilizes AI/ML approaches to fill in missing data, validates the outcomes from thousands of datasets, and continuously optimizes parameters as complexities are introduced is highly desirable and is consistent with the VSL offering. Because of this highly differentiated infrastructure, it allows the system to continuously self-tune-and-adapt to provide the scalability and accuracy to predictions, consequently shortening the translational gap.
Preclinical to Clinical Translation-Submission Opportunities
Drug developers seek to advance drug candidates in their pipeline from discovery to first in human trials in the context of safety and efficacy. To determine a safe, well-tolerated, and efficacious dose in humans, researchers first need to run a gamut of experiments on animals. The animal experiments attempt to predict human PK profiles, interpret toxicity outcomes, and anticipate drug-drug interactions to minimize the risks and safety issues presented to treating human patients. These experiments provide the drug developers with enough data to support a successful IND application, granting the developer permission to administer the drug product to humans. A strong IND application includes pivotal 14- or 28-day toxicity studies in 2 different species, one of which is typically a larger-sized species such as a dog or monkey. These experiments are extremely costly and can last over 4 months each when all procedural aspects of dosing, recovery, reporting, and auditing are included. Because these experiments are so costly and time-consuming, researchers base their trial design on data obtained from Drug Metabolism and Pharmacokinetic (DMPK) experiments performed on small rodents, such as mice or rats. DMPK data provides critical guidance for choosing the correct species and dosage for the pivotal longer-term toxicity studies. Each animal model has strengths and weaknesses, and their importance can vary depending on the indication and the drug’s mechanism of action.
An AI-enabled platform has the potential to interject at any stage of drug development starting from early proof-of-concept studies to clinical trials. Insights generated from the platform from these stages can be used in the “front-loading” late-stage drug development datasets in parallel to discovery-stage outcomes. The following insights resulting from the platform include, but are not limited to: prediction of drug disposition across different routes of administration; modeling drug disposition as a function of drug-specific parameters; prediction of compound safety and efficacy by modeling signaling pathways associated with drug targets and validating with associated biomarkers; optimizing dosing strategies based on desired PK/PD outcomes; prediction of multi-species PK from a chemically diverse set of compounds within 3-fold of the industry standards; and finally, translating outcomes from in vivo preclinical subjects to humans using parameterization to drug-specific and species-specific parameters.
Cloud services are typically, but not always, required for the various AI platforms. Companies such as Exscentia, Valo Health, Recursion Pharmaceutics, and VSL take advantage of the cloud and cloud services. The VSL computing environment is entirely hosted and facilitated by Amazon Web Services (AWS). VSL uses a variety of AWS services including virtual server hosting, storage, database hosting, and networking. VSL virtual servers are organized by use case and by computing demand within the AWS platform, separated into multiple clouds. These servers are the drivers behind the technologies underlying BIOiSIMTM, such as whole-body simulations, machine learning modeling, and web portals. The virtual servers used within AWS are fully scalable, as are the VSL software systems designed to run on them. This allows for the execution of millions of simulations, when necessary, run on on-demand virtual machines. Networking systems used by VSL are protected by the firewalls standard throughout the AWS product, as well as access settings specified in infrastructure that only allow as much access as is necessary for the operation of VSL’s systems. Internal AWS systems are also protected by VSL-maintained Virtual Private Networks, providing access to only those explicitly allowed into each cloud network defined by VSL. Access to VSL systems is provided on a least-privileged basis, only providing as much access as is necessary to perform job functions. This process is defined by documented policy, and access and revocation requests are requested by a standard form and recorded for review.
Pumas-AI (https://pumas.ai/) introduced the Pumas software which brings all tasks required to perform modeling and simulation projects into one integrated tool. Scientists can wrangle data, explore data, calculate non-compartmental parameters, build non-linear mixed-effects (NLME) models, perform diagnostics including graphing, simulate clinical trials, and conduct statistical analyses. Recently, Pumas-AI has made advances in NLME by integrating it with deep learning to form neural-embedded non-linear mixed-effects (NENLME) models (https://arxiv.org/abs/2012.07244v2) and created a tool called DeepPumasTM (https://pumas.ai/company/scientist-machine-learning/). These models are configured to embed neural networks into existing NLME structures, allowing for domain knowledge to serve as a prior to drastically reduce the amount of data required to train the neural networks compared to typical methods of direct usage of machine learning to replace the NLME models. The applications of DeepPumasTM range from drug discovery, optimizing manufacturing controls, identifying non-responders, detecting influential genomic markers, pharmacoeconomics, and safety surveillance.
AI-Enabled Use Cases
The probability of technical success (PTOS) of preclinical and clinical investigations and trials is critical for researchers both in the biopharma and the healthcare industry for the evaluation of a go or no-go decision on a drug, fundamental scientific insights, and the best treatment option for the patients. Without real-time estimates of the PTOS, most pharmaceutical companies end up investing immense time and resources in generating valuable preclinical translatable endpoints. Furthermore, the development of new drugs follows a discrete development pipeline: a series of defined steps that must be cleared prior to reaching clinical trials. Needless to say, this linear drug development approach is error prone. Compound failure rates as high as 96% have been observed using this classical approach spanning different therapeutic areas [10]. The key lies in shortening the translatability gap. To that end, the VSL hybrid AI-driven computational platform incorporates physiological phenomena of animals and humans combined with AI that enables users to accelerate research in drug development and personalized health by parallelizing and streamlining the process. One of the biggest challenges in estimating the success rate of clinical trials is access to accurate information on trial characteristics and outcomes. Gathering such data is expensive, time-consuming, and susceptible to error. VSL has done exhaustive research and generated insightful outcomes for addressing the translational challenges that arise from the deployment of the classical paradigm in different stages of the drug development pipeline [14,15,16,17,18,19].
Many AI-enable companies including VSL offer solutions that span from late-stage drug discovery to phase II clinical trials. These platforms allow seamless integration in the several stages of drug development to provide a focused road map and accurate enablement for drug asset maturation within their programs. The following are some use cases of AI/ML in MIDD from literature and BIOiSIMTM:
Predicting Drug-Drug Interactions (DDI) with AI/ML-Driven Platform, BIOiSIMTM: PK Modeling and Simulation of Enzyme Engagement and Target Interaction: a Promising Approach
Concomitant administration of drugs can lead to drug-drug interactions (DDI) if one of them has the potential to inhibit or induce an enzyme that is critical to the distribution and elimination of another. DDIs can affect the pharmacokinetics of drugs in patients receiving polytherapy, which can increase the risk of reduced safety or efficacy as victim drug concentrations exceed the maximum acceptable levels or fall below the therapeutic range. AI-driven platform is capable of predicting DDI via simulation of drug engagement with critical enzymes responsible for drug absorption (p-glycoprotein) and metabolism (Cytochrome P450). A PBPK model that is meant for evaluating DDI risk simultaneously solves the differential equations of both drugs generating the outcoming changes of the PK profiles. Clearance of a victim drug is predicted as reduced or increased due to loss or gain of active enzyme arising from reversible inhibition, time-dependent inhibition, or induction. BIOiSIMTM platform can predict the intrinsic clearance of the victim drug in various situations, including the absence or presence of inhibitors or inducers, changes in the abundance of an enzyme isoform due to mechanism-based inhibition, and the presence of an inducer. Additionally, predicting drug-drug interactions (DDIs) resulting from target engagement can be accomplished by comparing the association (Ka) and dissociation (Kd) contents of multiple drugs, which can determine potential perpetrator and victim compounds and suggest potential changes in their efficacy, a critical factor in the drug development stages in given therapeutic area
Effects of Magnesium, Calcium, and Aluminum Chelation on Fluoroquinolone Absorption Rate and Bioavailability: a QSPR-Based Computational Study; BIOiSIMTM: Use Case
Reduction of drug efficacy after co-administration of oral drugs is one of the frequent challenges faced during formulation development leading to a substantial decrease in therapeutic efficiency. Due to the interaction of antimicrobial agents belonging to the class fluoroquinolones with bivalent metal ions present in some therapeutics, their bioavailability and absorption rate may be lowered by up to 90%. Therefore, elaboration of the appropriate beneficial drug formulation requires significant resources and time, hence resulting in substantially prolonged path to the final drug product. Computational approaches can provide detailed structural and mechanistic insight into quinolones and their metal complexes. BIOiSIMTM has been utilized to simulate the effects of fluoroquinolone and metal complexation on absorption rate through a combined molecular and pharmacokinetic modeling study. Quantum mechanical calculations elucidated binding energies between fluoroquinolones and cations, which were leveraged to predict the magnitude of reduced bioavailability via a quantitative structure–property relationship (QSPR). The fundamental challenge was to examine what benefits computational approaches can bring for simulation and prediction of the drug pharmacokinetic profile, thus helping reduce the time and cost of drug formulation development studies and avoid the loss of potentially helpful medicines.
Quantum mechanical computations were implemented for molecular modeling of interactions between fluoroquinolone structures and bivalent and trivalent metal ions [15]. The necessary geometry optimization was performed using the Perdew–Burke–Ernzerhof (PBE) method (a generalized gradient approximation), the 6–31G(d) basis set, and the D3 dispersion correction with Becke–Johnson dampening. Those QSPR modeling procedures require the presence of values for a series of specific physicochemical and pharmacokinetic parameters for the development of quantum descriptors. AI/ML model training across a vast dataset of experimental data was deployed to predict those features for 13 fluoroquinolone drugs and their combination with salts of aluminum, calcium, and magnesium. Therefore, joint efforts of QSPR modeling and AI/ML predictions helped inform clinical pharmaceutical formulation design, allowing de-risking of possible dietary effects and anticipating possible drug-drug interactions earlier stages of the drug development pipeline.
AI-Powered Prediction of Species-Specific PK Profiles and BBB Permeability for Drug Candidates; BIOiSIMTM Use Case
The prediction of the PK profile of experimental drug candidates is a routine process that entails utilizing an AI module integrated with a PBPK model and a drug database. Since the PK predictions of small molecule drugs are independent of their therapeutic area and mechanism of action, we deployed BIOiSIM which was utilized in multiple projects to forecast PK profiles for humans and various animal species, including mice, rats, dogs, and non-human primates. The accuracy of typical drug compounds meeting the basic requirement of the Lipinski rule of 5 usually falls into 3-fold discrepancies with experimental observables. Some approaches can aid in improving the simulation accuracy results via potential improvements to the mechanistic model, which can give further insight into compound success and failure. PK simulation for highly lipophilic compounds is usually hindered due to peculiarities of the distribution, and implementation of BIOiSIM’s capacity helped to predict PK behavior of a set of NOX4 inhibitors, characterized by extremely high LogP value. BIOiSIM generated and ranked in silico PK predictions from structural data of the NOX4 compounds based on their concentration in plasma and target tissues such as the lung, kidney, heart, liver, and skin. PK predictions were based on area under the curve (AUC) and total clearance (CL) values that were indicative of the potential benefits and/or liabilities of the compound PK profiles [20]. Cross-species scaling made it possible to extrapolate drug PK profiles in mice into human species indicating the translatability potential of the test drugs.
AI/ML-Driven Simulations of Drug PD Properties: Model Training, Predictions, and Translatability for Novel Drug Candidates; BIOiSIMTM Use Case
In contrast to PK predictions, the AI-based simulations of drug PD properties, such as potency and efficacy under in vitro and in vivo conditions, necessitate particular model training for each pathway or target. All machine learning-driven PD studies follow a comparable workflow that begins with descriptor development and analysis, followed by model development using different algorithms like support vector machines, decision trees, LightGradientBoost, CatBoost, and XGBoost, among others [21]. The successful implementation of BIOiSIM enabled the prediction of IC50 and ED50 for novel drug class candidates inhibiting NOX4 enzymes for both intravenous and inhalation routes of administration. The results demonstrated a ranking of drug efficacy that revealed the most powerful compounds interacting with the targets in the skin and lung tissue, respectively. The modeling and simulation of PK/PD assisted in translating efficacy predictions from preclinical to potential clinical results. For the execution of the project devoted to the prediction of the antitumor drug activity, ML models were trained against small datasets comprising 50 in vitro data entries and less than 20 in vivo results. By employing back-imputation to the training dataset, VSL created an algorithm that could predict the ED50 of compounds, which showed efficacy, with more confidence than the less effective compounds. Out of the few hundred predicted efficacy results, 64% of them aligned with the observed value within a 3-fold range, 24% had predictions that were outside of a 3-fold range but within a 10-fold range, and 12% had predicted values that went beyond a 10-fold range. The BIOiSIM platform was successfully used to predict drug efficacy, even skipping in vitro potency components, which was demonstrated in the simulation of the analgesic activity exerted by NAV1.7 antagonists. Despite the ML model being trained with disproportionate in vivo data that had 80% experimental responses above the limit of quantitation, the predicted ED50 values showed an agreement with observed values within 3-fold for 88% of the compounds, which instilled confidence in the predicted PD profile for over 500 compounds. Drug candidates were grouped into 3 tiers based on potency (tier 1, ED50 < 3 mg/kg; tier 2, 3 ≤ ED50 10 ≤ mg/kg; and tier 3, ED50 > 10 mg/kg).
Assessing CD8 Cell Penetration in Advanced Solid Tumors
Immunotherapy is a recent advancement in cancer therapy where the immune system is trained to remove cancerous cells using T-lymphocytes. Response to immunotherapy is heterogeneous across patients, and therefore, identifying patient subpopulations who might or might not respond to therapy is a challenge [22]. It is hypothesized that there are signatures in the images of tumors that might predict the treatment response. Radiomics is a new and emerging image analysis technique that automatically extracts several texture and shape features from medical images that are not usually visible to the human eye [23]. A combination of some or all these features can be evaluated as a potential biomarker using ML to be correlated to clinical outcomes, such as treatment response. This example sought to examine if ML could be used to in advanced uncurable solid tumors to identify biomarkers in medical images that can predict treatment response for individualized therapy. A prospective clinical trial was conducted to assess if high-throughput genomic analysis in patients with advanced solid tumors can improve clinical outcomes [24]. Computed tomography (CT) image data and RNA-sequencing genomic data were retrospectively collected from the said trial for the purpose of this analysis [22]. Using 78 radiomic features extracted from the CT image and 5 binary variables for tumor location, an ML algorithm, namely elastic net regression, was fitted to identify a biomarker signature that best predicted tumor infiltration. ML pinned down 5 radiomic features and 3 tumor location variables that best predicted infiltration of CD8 cells. This identified radiomic signature was validated on external data and provided adequate prediction performance on different types of clinical outcomes, such as tumor infiltration, progression free survival, and CD8 gene expression.
Cohort Search Using Prospective Inclusion-Exclusion Criteria
Recruitment of patients in clinical trials is very expensive and time-consuming [25]. With the rising availability of electronic health record (EHR) data, cohorts can be prospectively defined, and their feasibility can be explored. These cohort definitions can then be translated to inclusion-exclusion criteria written in protocols to be subsequently implemented in clinical trials. However, creating cohort queries based on traditional methods is subjective, requires subject matter expertise, and is technically infeasible making cohort search extremely challenging for clinicians. Natural language processing (NLP) methods can be used to convert plain unstructured text into structured data representations depending on the question intended to solve, which can then be used for any number of tasks such as text classification and labeling content. The emphasis of this example was to develop a natural language interface (NLI) that can automatically identify subjects eligible for a clinical trial based on prospective inclusion-exclusion criteria. Criteria2Query is an open-source NLI (https://github.com/OHDSI/Criteria2Query) that takes as input the prospective inclusion-exclusion criteria in plain text format and outputs cohort queries. Queries can be used to search EHR for identifying subjects who might be eligible for a clinical trial. The tool first converts the plain text inclusion-exclusion criteria into structured data representations by labeling them as one of the several topics including but not limited to words, phrases, or sentences being a measurement (serum creatinine), condition (for e.g., chronic heart failure), value (for e.g., 18 to 70 years of age), drug name or class (for e.g., cephalosporins), or temporal relationship (for e.g., current depressive episode greater than 6 months), called as information extraction. The information is then processed to formulate a structured query language (SQL) query than can be used to search EHR and understand if there are patients that meet the criteria being planned.
Binge Eating Disorder (BED) Trial Enrichment
Approximately 50% of BED trials have failed to show a separation between treatment and placebo. One of the main reasons for negative trial outcomes is because of placebo response—a clinically significant reduction in the BED symptomology in patients receiving placebo. Excluding placebo responders at the beginning of the trial can help with increased PTOS. This example was centered around the question of whether BED trials could be enriched by identifying placebo responders at baseline. Data from 12 prospective trials that evaluated different treatments for BED was collected retrospectively for this meta-analysis [26]. For identifying moderators of placebo response, the kinds of information such as baseline disease severity, diagnosis of co-morbid psychiatric conditions, and patient demographics were used as inputs, and ML models were fitted. The final model identified baseline disease severity and a co-morbid diagnosis of general anxiety disorder to be the most important predictors of placebo response. Using model interpretation approaches, such as Shapley analysis, cut-off for baseline disease severity that best separates placebo responders and non-responders was identified. This model can potentially be used for enriching BED trials to increase the PTOS of such trials by excluding placebo responders.
Modeling Natural Disease Progression in Huntington’s Disease (HD)
Huntington’s disease (HD) is a neurodegenerative disorder that lasts several decades until death [27]. HD is complex because it is protracted over multiple years with gradually changing symptomology depending on the disease state. Multistate models can be built on longitudinal natural history data collected from observational studies to characterize the disease progression. Once described, the signatures (or latent variables) provided by the model can be correlated to any number of clinical outcomes and can potentially be useful in the design and analysis of clinical trials [28, 29]. This example focused on the development of a disease progression model of HD using a large patient database for patient selection to in HD trials. Motor, cognitive, and functional measure data totaling up to 44 assessments collected longitudinally in four large observational studies was consolidated resulting in more than 25,000 patients. A multistate model called a continuous time hidden Markov model that can handle longitudinal data collected at irregular timepoints was built on the 9 latent variables extracted from the 44 assessments. The model described the disease as consisting of 9 disease states. The ML method was able to discern patterns that might not be apparent to clinical observation. For example, the model identified that occupation score started worsening as early as stage 2 and that it is an early indicator of functional impairment. This model is a signal extraction method, in that signals extracted from the model can be correlated with any number of clinical outcomes and can also be potentially used for enriching HD trials by identifying patient subpopulations [27].
Improving Pharmacometric Models by Integrating Machine Learning into Modeling Workflows
Tumor growth dynamics (TGD) and overall survival (OS) are frequently modeled in cancer therapies using non-linear mixed effect modeling approaches and parametric/semi-parametric survival models respectively. Prognostic scenarios can then be simulated using these models to identify an optimal course of action. For example, TGD and OS model for nivolumab was used to simulate different dosing regimens, and a new regimen that could reduce healthcare burden (by increasing the dosing interval) was identified without compromising on safety and efficacy [30]. In TGD models, for each parameter that is estimated, there might be tens or hundreds of covariates that can help explain the between-subject variability, and in the OS models, there might be a large number of covariates that are required to be evaluated to predict time to mortality. Using traditional stepwise covariate methods for identifying covariates becomes prohibitively cumbersome when there are tens or hundreds of covariates. ML models can help with covariate selection with ease and can scale up to hundreds of thousands of covariates. This example focused on identifying the prognostic and predictive factors associated with OS and parameters of the TGD model. The data for this analysis was part of the JAVELIN Gastric 100 trial [31]. Two separate ML analyses were conducted: one for OS and one for TGD31. For OS, 89 time-dependent and time-independent covariates were evaluated using the Boruta method on the random forest (RF) algorithm [31]. The covariates identified as important using the ML models and physiological plausibility were used to build the parametric time to event model. For TGD, 52 covariates were evaluated to be a potential predictor for each empirical Bayes estimate (EBE) of each model parameter. Using the relative importance obtained from Shapley analysis, covariates were selected to be included in the final TGD model. The ML analysis for both TGD and OS models did not identify the treatment effect as an important covariate; therefore, patient subpopulation that might benefit from the treatment was not identified that was consistent with the literature [32]. The covariate selection method for both models was performed in one step each making the ML method time efficient.
Potential ROI Comparison and Collaboration
Return on investment (ROI) can be generally defined as a performance metric used to evaluate the outcome of an investment or compare the outcomes of several investments. A high ROI means the investment’s gains compare favorably to its cost. In the context of evaluating MIDD approaches and paradigms, ROI can provide a quantitative comparison of both resource savings (e.g., time and cost savings in trials and regulatory submissions) and operational costs (FTE, outsourcing, hardware/software, etc.) (see Table III for representative resource partition for a traditional MIDD approach). ROI from an industry perspective is very clear and growing as MIDD has the great potential to reduce R&D cost by allowing go/no-go decisions to be made earlier, obviating the need for certain clinical trials and enabling comparisons to be made between new drug candidates and potential competitors, so accurate market share assessments can be produced. The comparison between traditional and AI-led approaches is difficult because there have not been adequate deployments of an end-to-end, AI-based MIDD approach. Individual narrow efforts look very promising, however. For instance, rank ordering compounds using AI-driven MIDD require less than a month effort that could potentially save millions of dollars in performing several experiments and years of time. It can be used as an effective screen in order to reduce the number of wasted cycles, having only computationally validated compounds go through live animal testing before being sent to clinical trials. This should speed up time and drive down cost savings tremendously. Furthermore, new programs can leverage the massive information collected over the past few decades to not only add differentiation but also potentially gain millions of dollars in commercial value. It will take more investment and integration of AI/ML into the drug development efforts of a few early adopters to judge whether this aspiration ROI matches reality, but the premise seems reasonable.
One step in the process of early adoption is the co-investment in collaborations. Pharmaceutical sponsors small and large have recognized the necessity to co-invest in AI/ML technologies and, while the level of investment varies across companies most recognize that some level of in-house support is necessary along with collaboration with academic experts as well as others in the field for which discussions in the precompetitive space can be held. The Machine Learning for Pharmaceutical Discovery and Synthesis Consortium (MLPDS; https://mlpds.mit.edu/) brings together computer scientists, chemical engineers, and chemists from MIT with scientists from member companies to create new data science and artificial intelligence algorithms along with tools to facilitate the discovery and synthesis of new therapeutics. MLPDS educates scientists and engineers to work effectively at the data science/chemistry interface and provides opportunities for member companies and MIT to collectively create, discuss, and evaluate new advances in data science for chemical and pharmaceutical discovery, development, and manufacturing.
Specific research topics within the consortium include synthesis planning; prediction of reaction outcomes, conditions, and impurities; prediction of molecular properties; molecular representation, generation, and optimization (de novo design); and extraction and organization of chemical information. The algorithms are developed and validated on public data and then transferred to member companies for application to proprietary data. All members share intellectual property and royalty free access to all developments.
Discussion
The MIDD approach is well entrenched in the current drug development paradigm both from innovators seeking to develop new drugs and new drug targets and regulators who must judge the suitability of evidentiary proof that proposed new treatments are both safe and efficacious. The current approach is highly dependent on quantitative scientists with expertise in various forms of modeling and simulation methodologies, a suite of software solutions that permit the development, codification, and validation of discrete models that de-risk decision-making and a modern compute environment to house the software and model libraries so that such resources can be maintained in a secure, Part 11 compliant manner and share among its practitioners. Most importantly, the current MIDD approach relies on buy-in from senior leaders within the organization and favorable interactions with regulatory authorities. Likewise, as the approach evolves and certainly if considerations for an AI-enabled approach are put forward, these interactions will require revisiting with additional education and performance confirmation.
The field is constantly evolving requiring additional skillsets and expertise as well as diverse software solutions, customized and secure compute platforms, and new methodologies and approaches. Sponsors likewise appreciate that investment in MIDD is similarly evolving and growing. As the industry constantly seeks more efficient and cost-effective solutions, MIDD is not immune to this scrutiny. Much of the recent effort to improve the efficiency of MIDD is based on improved access to integrated data sources, creating libraries of model elements that can be shared and combined as needed and improving the compute platform to ensure that relevant tools and software solutions can coexist on the same platform. Little has been done to alter the data or model types that inform the commonly held critical decisions as outlined in Fig. 1 and Table I.
Artificial intelligence has received much interest of late as a complementary tool to answer specific drug development questions, and pharmaceutical sponsors have been both dedicating internal resources and investing in external partnerships to enhance their knowledge and expertise in this discipline [33]. An outgrowth of this interest has been the submission of some of these efforts to regulatory authorities. As recent work suggests [34], the number of these submissions has increased dramatically recently allowing authorities to gain an understanding of the diversity of applications that might support drug development and judge the usefulness of the approach for regulatory decision-making. Some positive outcomes from this early experience include the generation of early thoughts on guiding principles and the development of consortiums and shared resources[35, 36]. While these are early days in the process of getting comfortable with the approach and gaining confidence in the application, it is also an opportunity to assess future regulatory requirements for submission of such AI/ML implementations considering how transformative the approach could be in a more coordinated manner. Early regulatory guidance [37, 38] suggests that regulatory authorities are also anticipating broader utilization.
A future, but hopefully near-term effort should include the consideration of AI/ML application as either a complementary or entirely self-sufficient approach to support an MIDD paradigm. Early adopters of the approach tend to compartmentalize the effort into certain drug development sectors [12, 39] but few have considered this as an end-to-end solution. Moreover, the approach is still being compared to traditional MIDD efforts, specifically around the comparison of AI/ML prediction against specific model types (PBPK, PK/PD, CTS, etc.) and not around the data types and dimensions that would inform the various approaches or whether a revamped approach considering the optimal information value (driven by data and models) needed to guide regulatory milestones. Clearly, the path forward involves collaboration and open mind with respect to optimized and informative data generation coupled with tools that can be utilized with high fidelity based on mutually agreed and objective performance criteria. Remaining challenges will continue to include education and confidence building among non-AI quantitative scientists and decision-makers as well as the continued generation of compelling use cases.
Data Availability
Data generated herein for this analysis is based on literature and web review but is available from the PI upon request.
References
Leinfuss E. Changing the drug development playbook – model-informed drug development has arrived. PharmaVOICE, Nov-Dec 2016, https://www.certara.com/app/uploads/Resources/Articles/AR_ChangingDrugDevPlaybook.pdf. Accessed 17 Jan 2022.
Lesko LJ. Perspective on model-informed drug development. CPT Pharmacometrics Syst Pharmacol. 2021;10(10):1127–9. https://doi.org/10.1002/psp4.12699. Epub 2021 Aug 17. PMID: 34404115; PMCID: PMC8520742
Morrissey KM, Marchand M, Patel H, et al. Alternative dosing regimens for atezolizumab: an example of model-informed drug development in the postmarketing setting. Cancer Chemother Pharmacol. 2019;84:1257–67. https://doi.org/10.1007/s00280-019-03954-8.
Marshall S, Madabushi R, Manolis E, Krudys K, Staab A, Dykstra K, Visser SAG. Model-informed drug discovery and development: current industry good practice and regulatory expectations and future perspectives. CPT Pharmacometrics Syst Pharmacol. 2019;8(2):87–96. https://doi.org/10.1002/psp4.12372. Epub 2019 Feb 1. PMID: 30411538; PMCID: PMC6389350
Combes FP, Einolf HJ, Coello N, Heimbach T, He H, Grosch K. Model-informed drug development for everolimus dosing selection in pediatric infant patients. CPT Pharmacometrics Syst Pharmacol. 2020;9(4):230–7. https://doi.org/10.1002/psp4.12502. Epub 2020 Apr 5. PMID: 32150661; PMCID: PMC7180003
Wang Y, Zhu H, Madabushi R, Liu Q, Huang S-M, Zineh I. Model-informed drug development: current US regulatory practice and future considerations. Clin Pharmacol Ther. 2019;105:899–911.
Madabushi R, Benjamin JM, Grewal R, Pacanowski MA, Strauss DG, Wang Y, Zhu H, Zineh I. The US Food and Drug Administration’s model-informed drug development paired meeting pilot program: early experience and impact. Clin Pharm Ther. 2019;106(1):74–8. https://doi.org/10.1002/cpt.1457.
EFPIA MID3 Workgroup, Marshall SF, Burghaus R, Cosson V, Cheung SY, Chenel M, Della Pasqua O, Frey N, Hamrén B, Harnisch L, Ivanow F, Kerbusch T, Lippert J, Milligan PA, Rohou S, Staab A, Steimer JL, Tornøe C, Visser SA. Good practices in model-informed drug discovery and development: practice, application, and documentation. CPT Pharmacometrics Syst Pharmacol. 2016;5(3):93–122.
Manolis E, Brogren J, Cole S, Hay JL, Nordmark A, Karlsson KE, Lentz F, Benda N, Wangorsch G, Pons G, Zhao W, Gigante V, Serone F, Standing JF, Dokoumetzidis A, Vakkilainen J, van den Heuvel M, Mangas Sanjuan V, Taminiau J, et al. EMA Modelling and simulation working group. CPT Pharmacometrics Syst Pharmacol. 2017;6(7):416–7. https://doi.org/10.1002/psp4.12223. PMID: 28653481
DiMasi JA, Grabowski HG, Hansen RW. Innovation in the pharmaceutical industry: new estimates of R&D costs. J Health Econ. 2016;47:20–33. https://doi.org/10.1016/j.jhealeco.2016.01.012.
Paul D, Sanap G, Shenoy S, Kalyane D, Kalia K, Tekade RK. Artificial intelligence in drug discovery and development. Drug Discov Today. 2021;26(1):80–93. https://doi.org/10.1016/j.drudis.2020.10.010. Epub 2020 Oct 21. PMID: 33099022; PMCID: PMC7577280
Maharao N, Antontsev V, Wright M, Varshney J. Entering the era of computationally driven drug development. Drug Metab Rev. 2020;52(2):283–98. https://doi.org/10.1080/03602532.2020.1726944. Epub 2020 Feb 21
Chen EP, Bondi RW, Michalski PJ. Model-based target pharmacology assessment (mTPA): an approach using PBPK/PD modeling and machine learning to design medicinal chemistry and DMPK strategies in early drug discovery. J Med Chem. 2021;64(6):3185–96. https://doi.org/10.1021/acs.jmedchem.0c02033.
Antontsev V, Jagarapu A, Bundey Y, Hou H, Khotimchenko M, Walsh J, Varshney J. A hybrid modeling approach for assessing mechanistic models of small molecule partitioning in vivo using a machine learning-integrated modeling platform. Sci Rep. 2021;11:11143. https://doi.org/10.1038/s41598-021-90637-1.
Walden DM, Khotimchenko M, Hou H, Chakravarty K, Varshney J. Effects of magnesium, calcium, and aluminum chelation on fluoroquinolone absorption rate and bioavailability: a computational study. Pharmaceutics. 2021;13(5):594. Published 2021 Apr 21. https://doi.org/10.3390/pharmaceutics13050594.
Chakravarty K, Antontsev VG, Khotimchenko M, Gupta N, Jagarapu A, Bundey Y, Hou H, Maharao N, Varshney J. Accelerated repurposing and drug development of pulmonary hypertension therapies for COVID-19 treatment using an AI-integrated biosimulation platform. Molecules. 2021;26(7):1912. https://doi.org/10.3390/molecules26071912. PMID: 33805419; PMCID: PMC8037385
Walden DM, Bundey Y, Jagarapu A, Antontsev V, Chakravarty K, Varshney J. Molecular simulation and statistical learning methods toward predicting drug-polymer amorphous solid dispersion miscibility, stability, and formulation design. Molecules. 2021;26(1):182. https://doi.org/10.3390/molecules26010182. PMID: 33401494; PMCID: PMC7794704
Maharao N, Antontsev V, Hou H, Walsh J, Varshney J. Scalable in silico simulation of transdermal drug permeability: application of BIOiSIM platform. Drug Des Devel Ther. 2020;11(14):2307–17. https://doi.org/10.2147/DDDT.S253064. PMID: 32606600; PMCID: PMC7296558
Khotimchenko M, Antontsev V, Chakravarty K, Hou H, Varshney J. In silico simulation of the systemic drug exposure following the topical application of opioid analgesics in patients with cutaneous lesions. Pharmaceutics. 2021;13(2):284. https://doi.org/10.3390/pharmaceutics13020284. PMID: 33669957; PMCID: PMC7924840
Gallo JM. Pharmacokinetic/ pharmacodynamic-driven drug development. Mt Sinai J Med. 2010;77(4):381–8. https://doi.org/10.1002/msj.20193.
Chen W, Liu X, Zhang S, Chen S. Artificial intelligence for drug discovery: Resources, methods, and applications. Mol Ther Nucleic Acids. 2023;31:691–702. https://doi.org/10.1016/j.omtn.2023.02.019. PMID: 36923950; PMCID: PMC10009646.
Sun R, Limkin EJ, Vakalopoulou M, et al. A radiomics approach to assess tumour-infiltrating CD8 cells and response to anti-PD-1 or anti-PD-L1 immunotherapy: an imaging biomarker, retrospective multicohort study. Lancet Oncol. 2018;19(9):1180–91. https://doi.org/10.1016/S1470-2045(18)30413-3.
Parekh V, Jacobs MA. Radiomics: a new application from established techniques. Expert Rev Precis Med Drug Dev. 2016;1(2):207–26. https://doi.org/10.1080/23808993.2016.1164013.
Massard C, Michiels S, Ferté C, et al. High-throughput genomics and clinical outcome in hard-to-treat advanced cancers: results of the MOSCATO 01 trial. Cancer Discov. 2017;7(6):586–95. https://doi.org/10.1158/2159-8290.CD-16-1396.
Yuan C, Ryan PB, Ta C, et al. Criteria2Query: a natural language interface to clinical databases for cohort definition. J Am Med Inform Assoc JAMIA. 2019;26(4):294–305. https://doi.org/10.1093/jamia/ocy178.
Goyal RK, Kalaria SN, McElroy SL, Gopalakrishnan M. An exploratory machine learning approach to identify placebo responders in pharmacological binge eating disorder trials. Clin Transl Sci. Published online September 24, 2022:cts.13406. https://doi.org/10.1111/cts.13406
Mohan A, Sun Z, Ghosh S, et al. A machine-learning derived Huntington’s disease progression model: insights for clinical trial design. Mov Disord. 2022;37(3):553–62. https://doi.org/10.1002/mds.28866.
Barrett JS, Nicholas T, Azer K, Corrigan BW. Role of disease progression models in drug development. Pharm Res. 2022;39(8):1803–15. https://doi.org/10.1007/s11095-022-03257-3.
Le-Rademacher JG, Peterson RA, Therneau TM, Sanford BL, Stone RM, Mandrekar SJ. Application of multi-state models in cancer clinical trials. Clin Trials. 2018;15(5):489–98. https://doi.org/10.1177/1740774518789098.
Zhao X, Shen J, Ivaturi V, et al. Model-based evaluation of the efficacy and safety of nivolumab once every 4 weeks across multiple tumor types. Ann Oncol. 2020;31(2):302–9. https://doi.org/10.1016/j.annonc.2019.10.015.
Moehler M, Dvorkin M, Boku N, et al. Phase III trial of avelumab maintenance after first-line induction chemotherapy versus continuation of chemotherapy in patients with gastric cancers: results from JAVELIN Gastric 100. J Clin Oncol. 2021;39:966–77.
Terranova N, French J, Dai H, et al. Pharmacometric modeling and machine learning analyses of prognostic and predictive factors in the JAVELIN Gastric 100 phase III trial of avelumab. CPT Pharmacomet Syst Pharmacol. 2022;11(3):333–47. https://doi.org/10.1002/psp4.12754.
Liu Q, Zhu H, Liu C, Jean D, Shiew-Mei Huang M, ElZarrad K, Blumenthal G, Wang Y. Application of machine learning in drug development and regulation: current status and future potential. Clin Pharm Ther. 2020;107(4):726–9. https://doi.org/10.1002/cpt.1771.
Liu Q, Huang R, Hsieh J, Zhu H, Tiwari M, Liu G, Jean D, ElZarrad MK, Fakhouri T, Berman S, Dunn B, Diamond MC, Huang SM. Landscape analysis of the application of artificial intelligence and machine learning in regulatory submissions for drug development from 2016 to 2021. Clin Pharmacol Ther. 2022. https://doi.org/10.1002/cpt.2668. Epub ahead of print.
Rhodes C (2019). Perfect Harmony: Pharma’s MELLODDY Consortium Joins Forces with NVIDIA to Supercharge AI Drug Discovery, https://resources.nvidia.com/en-us-federated-learning/ai-drug-discovery-co.
Whelan S. (2023). Accelerating efficient drug discovery with the power of AI, https://www.technologynetworks.com/drug-discovery/blog/accelerating-efficient-drug-discovery-with-the-power-of-ai-370479. Accessed 17 Jan 2022
US Food and Drug Administration. Use of artificial intelligence within drug development programs https://www.fda.gov/media/ 13261 2/download (2019). Accessed 17 Jan 2022.
US Food and Drug Administration. Good machine learning practice for medical device development: guiding principles https://www.fda.gov/medical-devices/software-medical-device-samd/good-machine-learning-practice-medical-device-development-guiding-principles (2021). Accessed January 17, 2022.
Chelliah V, van der Graaf PH. Model-informed target identification and validation through combining quantitative systems pharmacology with network-based analysis. CPT Pharmacometrics Syst Pharmacol. 2022. https://doi.org/10.1002/psp4.12766. Epub ahead of print.
Author information
Authors and Affiliations
Contributions
All authors contribute to the writing of the manuscript and the editing. JB, JV, and RG created the outline of the paper and JG and SB provided use case summaries.
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare no competing interests.
Additional information
Guest Editors: Lawrence Yu, Hao Zhu and Qi Liu
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors confirm that Jeffrey S. Barrett, PhD, FCP, is the PI responsible for this research and analysis.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Barrett, J.S., Goyal, R.K., Gobburu, J. et al. An AI Approach to Generating MIDD Assets Across the Drug Development Continuum. AAPS J 25, 70 (2023). https://doi.org/10.1208/s12248-023-00838-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1208/s12248-023-00838-x