
Abstract
Quantum machine learning has become an area of growing interest but has certain theoretical and hardware-specific limitations. Notably, the problem of vanishing gradients, or barren plateaus, renders the training impossible for circuits with high qubit counts, imposing a limit on the number of qubits that data scientists can use for solving problems. Independently, angle-embedded supervised quantum neural networks were shown to produce truncated Fourier series with a degree directly dependent on two factors: the depth of the encoding and the number of parallel qubits the encoding applied to. The degree of the Fourier series limits the model expressivity. This work introduces two new architectures whose Fourier degrees grow exponentially: the sequential and parallel exponential quantum machine learning architectures. This is done by efficiently using the available Hilbert space when encoding, increasing the expressivity of the quantum encoding. Therefore, the exponential growth allows staying at the low-qubit limit to create highly expressive circuits avoiding barren plateaus. Practically, parallel exponential architecture was shown to outperform the existing linear architectures by reducing their final mean square error value by up to 44.7% in a one-dimensional test problem. Furthermore, the feasibility of this technique was also shown on a trapped ion quantum processing unit.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 4.0 license. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
The successes of quantum computing in the past decade have laid the foundations for the interdisciplinary field of quantum machine learning (QML) [1, 2], where parameterised quantum circuits are used as machine learning models to extract features from the training data. It was argued [3] that such quantum neural networks (QNN) could have higher trainability, capacity, and generalization bound than their classical counterparts. Practically, hybrid quantum neural networks (HQNN) have shown promise in small-scale benchmarking tasks [4–7] and larger-scale industrial tasks [8–10]. Nevertheless, the utility, practicality, and scalability of pure QNNs are still unclear. Furthermore, [11] provided a thorough overview of this field, showing that while classical machine learning is solving large real-world problems, QNNs are mostly tried on synthetic, clean datasets and show no immediate real-world advantages in its current state 1 . It also suggested that the QNN research focus should be shifted from seeking quantum advantage to new research questions, such as finding a new, advantageous quantum neuron. This work explores a new quantum neuron that argues for moving beyond using the Pauli-, single-qubit gates for encoding data and instead employing higher-dimensional unitaries through gate decomposition.
Since quantum gates are represented by elements of compact groups, Fourier analysis is a natural tool for analysing QNNs. Schuld et al [15] showed that certain quantum encodings can create an asymptotically universal Fourier estimator. A universal Fourier estimator is a model that can fit a trigonometric series on any given function. As the number of terms in the series approaches infinity, the fit becomes an asymptotically perfect estimate. This estimator can initially infer the coarse correlations in the supplied data, and by increasing the number of Fourier terms, it can incrementally judge the more granular properties of the dataset. This provides an adjustable, highly-expressive machine learning model.
In [15], the authors showed that a QNN could operate as such in two ways: a sequential single-qubit architecture with n repetitions of the same encoding could yield n Fourier bases, which could also arise from an n-qubit architecture with the encoding gates applied to all qubits in parallel.
The sequential architecture is widely shown to be an efficient Fourier estimator, demonstrated both theoretically [15] and empirically [16, 17]. However, sequential circuits are often deep [17], and assuming that near-term quantum computers will have a non-negligible noise associated with each gate, these circuits can experience noise-induced barren plateaus [18]. Barren plateaus are a phenomenon observed in optimization problems where the gradients of the model vanish, rendering them impossible to train. More importantly, a single qubit can be simulated efficiently in a classical setting, so this architecture brings no quantum advantage.
In contrast, the parallel setting offers the exponential space advantage of quantum computing but poses two challenges for large numbers of qubits:
- An exponentially growing parameter count with the number of qubits required to span the entire group space
 [19], which could also lead to noise-induced barren plateaus. Spanning the full space is especially important for a priori problems, where the best model lies in the Hilbert space. Still, the machine learning scientist has no prior knowledge of parameterising a circuit to reach this point. In addition, gradient calculations in QNNs—as of this publication—use the parameter-shift rule discovered and presented in [20]. This method requires two evaluations of the QNN to find the derivative of the circuit with respect to each of the trainable parameters. An exponentially growing number of trainable parameters translates to exponentially increasing resources required for gradient computation. In mitigation, [21, 22] showed that a polynomially-growing number of parameters could generate a similar result based on the quantum t-design limits [23].
[19], which could also lead to noise-induced barren plateaus. Spanning the full space is especially important for a priori problems, where the best model lies in the Hilbert space. Still, the machine learning scientist has no prior knowledge of parameterising a circuit to reach this point. In addition, gradient calculations in QNNs—as of this publication—use the parameter-shift rule discovered and presented in [20]. This method requires two evaluations of the QNN to find the derivative of the circuit with respect to each of the trainable parameters. An exponentially growing number of trainable parameters translates to exponentially increasing resources required for gradient computation. In mitigation, [21, 22] showed that a polynomially-growing number of parameters could generate a similar result based on the quantum t-design limits [23]. - Strongly-parameterised QNNs have a vanishing variance of gradient which decreases exponentially with the number of qubits [24]. This means that for a large number of qubits if one initialises her QNN randomly, they will encounter a barren plateau. This happens because the expectation value of the derivative of the loss function with respect to each variable for any well-parameterised quantum circuit is zero, and its variance decreases exponentially with the number of qubits. Mitigation methods have been suggested in [25, 26], and most notably in [27], it was shown that by relaxing the well-parameterised constrain to only include a logarithmically growing circuit depth with the number of qubits in the system and use local measurements, the circuit is guaranteed to evade barren plateaus. Zhao and Gao [28] developed a platform based on ZX-calculus 2 to explore which QNN architectures are affected by the barren plateau phenomenon and found that strongly-entangling, hardware efficient circuits suffer from them. In contrast with the previously-mentioned cases of barren plateaus, the latter is not noise-induced. Thus, this problem must be addressed even in the fault-tolerant future of quantum computing.

Therefore, the practising QML scientist is limited in choosing her QNN architectures for general data science problems: they need to be shallow 3 or employ only a few qubits. This contribution suggests modifying the encoding strategies in [15] to increase the growth of the Fourier bases in a QNN from linear in the number of qubits/number of repetitions to exponential. The proposed encoding is constructed by decomposing large unitary generators into local Pauli-Z rotations. This improves the expressivity of the QNNs without requiring additional qubits or encoding repetitions. The increased expressivity is a product of eliminating the encoding degeneracies of the quantum kernel, making efficient use of the available Hilbert space by assigning a unique wavevector to each of its dimensions. However, such encodings could introduce a greater risk of limiting the model's Fourier accessibility 4 .
Section 2 provides a review of how angle-embedded QNNs approximate their input distributions by fitting to them a truncated Fourier. Specifically, section 2 reviews the linear encoding architectures and how their number of Fourier bases grow linearly with the number of repetitions—sequential linear in section 2.1—as well as the number of qubits—parallel linear in section 2.2. Then, section 3 introduces the same two architectures but slightly modified to represent an exponentially-growing number of Fourier bases. To use these architectures in practice, section 3.3 compares the training performance of these architectures and shows that the parallel exponential has a superior training performance to the other architectures on a synthetic, one-dimensional dataset. Finally, section 3.4 critically evaluates the work and suggests areas for future investigation.
2. Background review—linear architectures
As discussed in [15], all quantum neural networks that use angle embedding
5
as their encoding strategy produces a truncated Fourier series approximation to the dataset. Schuld et al [15] also specifically explored two families of architectures of quantum neurons: a single-qubit architecture with a series of sequential  gates and a multi-qubit architecture with parallel
gates and a multi-qubit architecture with parallel  encoding gates. In this section, the results and the architectures introduced in [15] are explored in depth in section 3. Two alternative QNN architectures are presented with the capability of achieving an exponentially higher Fourier expressivity for the same number of gates.
encoding gates. In this section, the results and the architectures introduced in [15] are explored in depth in section 3. Two alternative QNN architectures are presented with the capability of achieving an exponentially higher Fourier expressivity for the same number of gates.
Consider a quantum neuron that maps a real feature  onto the quantum circuit via a parametric gate
onto the quantum circuit via a parametric gate  . In most common architectures, the only parametric gates are single qubit rotations
. In most common architectures, the only parametric gates are single qubit rotations  . For this work, the Pauli-Z generated rotations are used without any loss of generality
. For this work, the Pauli-Z generated rotations are used without any loss of generality  ,
6
then the embedding gate takes a simple form
,
6
then the embedding gate takes a simple form  . In general, the dependence of the expected value of any observable on the parameter x is then given by
. In general, the dependence of the expected value of any observable on the parameter x is then given by

with some complex parameters c0 and c1, which depend on the rest of the circuit and the measurements.
This expected value is a function of the feature x with a very simple Fourier series. The data re-uploading method [16] is a natural way to construct neurons that give rise to richer Fourier series. These are architectures where several parametric gates depend on the same x. It is the most straightforward to consider gates that have a hardwired dependence on the feature 7 . In particular, such that the expected value of any observable takes the form of a discrete Fourier series

where θ the variational parameters and  with
with  for real observables. In sections 2.1 and 2.2, two architectures exhibited in [15] are reviewed. The Fourier expressivities of these architectures are of particular interest, that is, the list of wavenumbers
for real observables. In sections 2.1 and 2.2, two architectures exhibited in [15] are reviewed. The Fourier expressivities of these architectures are of particular interest, that is, the list of wavenumbers  appearing in the exponents in equation (1).
appearing in the exponents in equation (1).
2.1. Sequential linear
The single-qubit sequential linear method uses repetitions of the same single-qubit encoding gate S(x) interlaced in-between trainable variational layers. Figure 1(a) shows this implementation with generalized variational gates. Since the eigenvalues of each unitary are  , it is straightforward to observe (see, e.g. appendix A.1) that after n encoding layers, the expected value of any observable takes the form
, it is straightforward to observe (see, e.g. appendix A.1) that after n encoding layers, the expected value of any observable takes the form

Thus, the repetitions have an additive effect such that for n repetitions, the final list becomes  . Each of the wavenumbers in the list gives rise to a sinusoidal term with the same frequency. Therefore, for n repetitions of the encoding
. Each of the wavenumbers in the list gives rise to a sinusoidal term with the same frequency. Therefore, for n repetitions of the encoding  , n distinct Fourier bases are generated.
, n distinct Fourier bases are generated.

Figure 1. The four general circuits under analysis in this paper. In the exponential architectures, the first encoding is kept the same, and the subsequent encoding gates are multiplied by the coefficients in equation (6). The parallel circuits have a CNOT layer at the end to ensure that all qubits are cooperating in the training by propagating the π-measurement through all quantum wires.
Download figure:
Standard image High-resolution image2.2. Parallel linear
In the parallel setting, the single-qubit encoding gates are applied in parallel on separate qubits—see figure 1(c). Similarly to the sequential encoding, for n parallel rotations n Fourier bases are produced. This is due to the commutativity between the parallel rotations as they act on separate qubits. The generator  becomes:
becomes:

where q is the qubit index, r indicates the total number of qubits, and  is the Pauli-Z matrix applied to the
is the Pauli-Z matrix applied to the  qubit. In appendix A.2, it is shown that
qubit. In appendix A.2, it is shown that  —being a square matrix of dimensions 2r
—has
—being a square matrix of dimensions 2r
—has  unique eigenvalues. This suggests a high degree of degeneracy in its eigenspectrum. As before, subtracting these values from themselves yields a list of wavenumbers ranging from −r to r generating r Fourier bases.
unique eigenvalues. This suggests a high degree of degeneracy in its eigenspectrum. As before, subtracting these values from themselves yields a list of wavenumbers ranging from −r to r generating r Fourier bases.
2.3. Redundancy
Both in the sequential and parallel linear architectures, there is a lot of redundancy in how the feature is encoded into the circuit. This is the easiest to see for the parallel architecture, where most of the eigenvalues of  are largely degenerate as the encoding commutes with qubit permutations.
are largely degenerate as the encoding commutes with qubit permutations.
3. Results—exponential architectures
In this section, two new families of architectures are suggested that can encode an exponential number of Fourier bases for a given number of repetitions/parallel encodings. The basis of this generalization is to modify each 'subsequent' appearance of the encoding gate in the circuit by a re-scaling of the generator  with an integer m. Keeping the factors m integer guarantees that this procedure results in a discrete Fourier series in the form of equation (1).
with an integer m. Keeping the factors m integer guarantees that this procedure results in a discrete Fourier series in the form of equation (1).
3.1. Sequential exponential
It was shown in section 2.1 that the wavenumbers created in the linear models are highly degenerate. By modifying the circuit encoding, this degeneracy can be reduced, resulting in adding new wavenumbers to the list. This is accomplished by altering the generators in the individual encoding layers. In the linear case, the diagonal elements of the generator λi
always belonged to the list  , but could be altered by scaling the generator
, but could be altered by scaling the generator  in each layer. In practice, this is achieved by scaling the embedded data x and mathematically associating it with the generator. The resultant function becomes
in each layer. In practice, this is achieved by scaling the embedded data x and mathematically associating it with the generator. The resultant function becomes

where  for
for  .
8
In this work, al
scales as follows
.
8
In this work, al
scales as follows  . The motivation behind this choice is the sum of powers of 2,
. The motivation behind this choice is the sum of powers of 2,  , where the largest wavenumber possible, 2n
, is obtained by taking all the positive contributions from the list of eigenvalues, i.e.
, where the largest wavenumber possible, 2n
, is obtained by taking all the positive contributions from the list of eigenvalues, i.e.  . Next, one can switch the signs of the positive values to negative starting from the smallest term to produce all integers from
. Next, one can switch the signs of the positive values to negative starting from the smallest term to produce all integers from  to 2n
. This generates 2n
Fourier frequencies. Figure 1(b) shows a quantum circuit encoded using the sequential exponential strategy with 2 layers. Appendix
to 2n
. This generates 2n
Fourier frequencies. Figure 1(b) shows a quantum circuit encoded using the sequential exponential strategy with 2 layers. Appendix
3.2. Parallel exponential
To perform this extension, it is appropriate to proceed with a two-qubit example. The parallel linear method described in section 2.2 produces the generator:

This matrix has three unique eigenvalues,  , and when subtracted from itself—yielding wavenumbers
, and when subtracted from itself—yielding wavenumbers  —it can produce 2 Fourier bases with frequencies
—it can produce 2 Fourier bases with frequencies  . One could generate a matrix with more unique values. For example,
. One could generate a matrix with more unique values. For example,

is a generator with four unique eigenvalues that generate nine wavenumbers  . This generator can be constructed using the quantum circuit shown in figure 1(d). In this case, a
. This generator can be constructed using the quantum circuit shown in figure 1(d). In this case, a  generator is employed. This is decomposed into two
generator is employed. This is decomposed into two  generators, one using the group parameter, x, and the other 3x. This can be generalized to n qubits as one can extend the matrix for larger numbers of qubits, i.e. for n qubits
generators, one using the group parameter, x, and the other 3x. This can be generalized to n qubits as one can extend the matrix for larger numbers of qubits, i.e. for n qubits  would be a diagonal matrix starting from
would be a diagonal matrix starting from  up to
up to  , producing 2n
Fourier bases. The quantum circuit associated with this generator is an application of Pauli-Z rotations of x with frequencies increasing in the following way:
, producing 2n
Fourier bases. The quantum circuit associated with this generator is an application of Pauli-Z rotations of x with frequencies increasing in the following way:

where n is the number of qubits. Note the similarities between the sequential and parallel encodings and their symmetries in how the circuits are constructed. One also recognizes similarities between the parallel encoding and Kitaev's quantum phase estimation algorithm [33], albeit in this case, x is a classical feature.
This can be significantly more expressive than the parallel linear method. Still, this advantage needs to be accompanied by Fourier accessibility. If the Fourier values of these newly-acquired bases cannot be altered, there would be no advantage in pursuing this setting. Section 3.3 shows a significant advantage in using parallel exponential encoding in a simple toy example.
3.3. Training
In this section, the training performance of these four architectures on a simple dataset is compared. Each architecture is trained to reproduce a one-dimensional top-hat function using the variational layers shown in figure 2. Figure 3 shows the ground truth, as well as the fitting performances of these architectures, and figure 4, shows their training performance. It is clear that the parallel exponential architecture fits a closer function to the ground truth, and in contrast, the sequential exponential architecture has the worst performance of all models. Furthermore, the Fourier decompositions of the models in figure 5 show that exactly two Fourier terms are accessed by the linear architectures and four by the exponential ones. Additionally, figure 6 demonstrates the performance of the parallel exponential architecture on a trapped ion quantum processor. The IonQ implements a high-fidelity gate-based quantum processing unit through a process known as laser pumping trapped-ions explained in [36]. The hardware was shown to be one of the most accurate in recent benchmarking tests [37]. We specifically used the hardware introduced in [38] with a single-qubit fidelity of 0.997 and a two-qubit fidelity of 0.9725. The code implementation was done through Amazon Web Services Braket, and the process of the forward pass for 100 data points took four hours and 11 minutes due to the delays and queuing times. It can be observed that the low number of shots is the dominant source of noise here, and higher shot counts could yield a smoother curve that is closer to the simulator. It is noteworthy that even though the superconductor-based QPUs were not tested here, they are expected to produce a similar result if they match the single- and two-qubit gate fidelity rates.

Figure 2. Variational gates used in single—(a) and two-qubit (b) experiments.
Download figure:
Standard image High-resolution image
Figure 3. The QNNs fit the best possible truncated Fourier series on the top-hat function. The parallel exponential architecture provides the best fit. Even though the sequential exponential architecture has access to the same four Fourier frequencies, it fails to access all of them efficiently, and as a result, it performs sub-optimally. The linear architectures perform similarly to each other, potentially arising from their high Fourier accessibility to the two Fourier frequencies that they can represent.
Download figure:
Standard image High-resolution image
Figure 4. Training losses indicate a training advantage for the parallel exponential, and the sequential exponential architecture performs only marginally better than the linear architectures. The training was done on QMware hardware [34] using the PennyLane Python package [35]. The Adam optimizer minimises a mean squared loss function with a learning rate of  = 0.1 and with uniformly-distributed parameters
= 0.1 and with uniformly-distributed parameters ![$\theta \in [0,2\pi]$](https://content.cld.iop.org/journals/2632-2153/4/3/035036/revision2/mlstace757ieqn41.gif) .
.
Download figure:
Standard image High-resolution image
Figure 5. Fourier decomposition of the four architectures after training to fit the top-hat function. The linear architectures can only access two Fourier frequencies, whereas the exponential ones can access four.
Download figure:
Standard image High-resolution image
Figure 6. The parallel exponential fit to the top-hat function on a simulator vs on the IonQ Harmony quantum processor. The noisy solid line evaluates this network for 100 equally-spaced points using 100 shots of this device.
Download figure:
Standard image High-resolution image3.4. Critical evaluation
While the results for the parallel exponentials are encouraging, it is equally important to understand the limitations of this approach. Firstly, while the exponential growth in the number of Fourier frequencies is evident, this is not the higher limit of Fourier frequency growth. Schuld et al [15] showed that for L repetitions of an encoding gate with a Hilbert space of dimension d, there is an upper limit to this growth of the form

where K is the number of Fourier frequencies. This suggests a potential for square-exponential growth, whereas the method discussed in this work only grows exponentially. In appendix
Secondly, it is important to emphasize that the two parallel architectures are the same, with a minor multiplicative factor added in the exponential case. Training them for a fixed number of epochs requires the same computational resources. However, adding more Fourier bases by eliminating the network's degeneracy could result in under-parameterised models. Therefore, it is often necessary to parameterise the exponential architectures more heavily than the linear ones, indirectly affecting the required resources. Every Fourier frequency requires two degrees of freedom (real-valued parameters), and an exponentially-growing Fourier space requires the resources to grow exponentially, too. These resources could include the classical memory required to store the parameters or the classical optimizer that needs to calculate the gradient for these parameters. And lastly, extending this to many qubits will still result in barren plateaus.
4. Conclusion and future work
This work suggested two new families of QNN architectures, dubbed sequential and parallel exponential circuits that provided an exponentially growing Fourier space. It was demonstrated that the former struggled with accessing these frequencies but also that the latter showed an advantage in approximating a top-hat function.
Future work could focus on a quantitative understanding of the Fourier accessibility of these networks, such that the optimal variational parameterisation could be chosen for a specific problem. Another possible direction for future work is to depart from hardwired encoding gates. A natural elementary step in this direction is to consider single-qubit gates of the form  , where the scaling factor wi
is an independent scalar trainable parameter for each occurrence of the encoding gate in the circuit. In this case, the final wavevectors k are linear combinations of the parameters wi
that can be potentially trained efficiently. As an added note, the parallel exponential encoding introduced in this work for up to two qubits coincides with the commendable work in [39]. This paper came to our attention after we had released the preprint, and we recognise that the parallel exponential architecture bears resemblance to the Trenary encoding both for the two-qubit case and in the type of growth in Fourier terms, albeit with different scaling strategies. Furthermore, [40] follows a similar example and creates this architecture for an optical setup.
, where the scaling factor wi
is an independent scalar trainable parameter for each occurrence of the encoding gate in the circuit. In this case, the final wavevectors k are linear combinations of the parameters wi
that can be potentially trained efficiently. As an added note, the parallel exponential encoding introduced in this work for up to two qubits coincides with the commendable work in [39]. This paper came to our attention after we had released the preprint, and we recognise that the parallel exponential architecture bears resemblance to the Trenary encoding both for the two-qubit case and in the type of growth in Fourier terms, albeit with different scaling strategies. Furthermore, [40] follows a similar example and creates this architecture for an optical setup.
Data availability statement
All data that support the findings of this study are included within the article (and any supplementary files).
Appendix A: Fourier estimation of the linear architectures
A.1. Sequential linear
To see the extraction of the Fourier modes more explicitly, one can write the function represented by this circuit as the expectation value of a measurement operator M:


Writing this in tensor notation yields

where  and the index summation convention is employed. We can simplify this expression further by employing
and the index summation convention is employed. We can simplify this expression further by employing

where  represents the eigenvalues of
represents the eigenvalues of  . This simplifies our function:
. This simplifies our function:

This means that for every combination of  , the QNN produces a wave-front with a wavenumber
9
, the QNN produces a wave-front with a wavenumber
9
 where
where  . Note that for n repetitions of this encoding, one obtains
. Note that for n repetitions of this encoding, one obtains  combinations for k, but this also includes a high level of degeneracy for each resultant wavenumber. Specifically, [17] showed that the degeneracy of the wavenumber of this circuit is given by
combinations for k, but this also includes a high level of degeneracy for each resultant wavenumber. Specifically, [17] showed that the degeneracy of the wavenumber of this circuit is given by  for the wavenumbers
for the wavenumbers  . Keeping this in mind, one can rewrite equation (A4) as
. Keeping this in mind, one can rewrite equation (A4) as



where cm
are complex coefficients and  .
.
A.2. Parallel linear
A parallel linear encoding consists of a two-qubit system where a Pauli-Z rotation of x is applied to each qubit. This means that two encodings are to be considered: the first encoding considers only the rotation applied to the first qubit making its encoding generator  and the second
and the second  :
:

Since the gates are applied to separate qubits, the generators commute with each other, and since the group parameters applied to each gate are the same, the elements of the encoding matrix can be written as:

where  is the combined generator, and δ is the Kronecker delta which acts as the identity matrix in index notation. Using this expression, one could write
is the combined generator, and δ is the Kronecker delta which acts as the identity matrix in index notation. Using this expression, one could write

Similarly to the calculations in appendix A.1, this generator provides us with a list of eigenvalues  , which, when subtracted from itself yields 2 Fourier frequencies and five wavenumbers
, which, when subtracted from itself yields 2 Fourier frequencies and five wavenumbers  . This calculation can be generalised to any number of qubits, and Fourier frequencies increase linearly with the number of qubits.
. This calculation can be generalised to any number of qubits, and Fourier frequencies increase linearly with the number of qubits.
Appendix B: The derivation for the exponential architectures
B.1. Sequential exponential
Starting from equation (A4), one can scale the sequential features, x, by a series of scaling factors  to effectively modify the group generator
to effectively modify the group generator  of each layer l to obtain
of each layer l to obtain

where  is the new effective list of eigenvalues. For n encoding layers, this work employs:
is the new effective list of eigenvalues. For n encoding layers, this work employs:

where n − 1 is due to counting from 0. This parameterisation results in wavenumbers  . By choosing the i's and j's such that
. By choosing the i's and j's such that  and
and  , the largest
, the largest  is obtained. Symmetrically, the minimal k is
is obtained. Symmetrically, the minimal k is  , and every whole number between can be created by first flipping from small to large all
, and every whole number between can be created by first flipping from small to large all  to arrive at k = 0, and then perform the same on
to arrive at k = 0, and then perform the same on  to arrive at the other extreme of the spectrum. The final list of wavenumbers is an equidistant list of size
to arrive at the other extreme of the spectrum. The final list of wavenumbers is an equidistant list of size  ,
,  , which grows exponentially in the number of encodings n.
, which grows exponentially in the number of encodings n.
B.2. Parallel exponential
The parallel exponential encoding in the two-qubit limit consists of Pauli-Z rotations of x and 3x applied to, respectively, the first and the second qubits. This encoding will use the same generators as equation (A8) whose purpose is to be multiplied by the rotation angles, x or 3x here, and then exponentiated, i.e.  .
.  can absorb the scalar 3 to produce:
can absorb the scalar 3 to produce:

where  remains unchanged. As the rotation angles are now equal—both are now simply x—one could add the generators to obtain:
remains unchanged. As the rotation angles are now equal—both are now simply x—one could add the generators to obtain:

This generator produces the eigenvalue list  and by subtracting this list from itself, one can obtain the list of wavenumbers
and by subtracting this list from itself, one can obtain the list of wavenumbers  , a list of exponential growth with the number of qubits.
, a list of exponential growth with the number of qubits.
Appendix C: Constraints of the sequential exponential
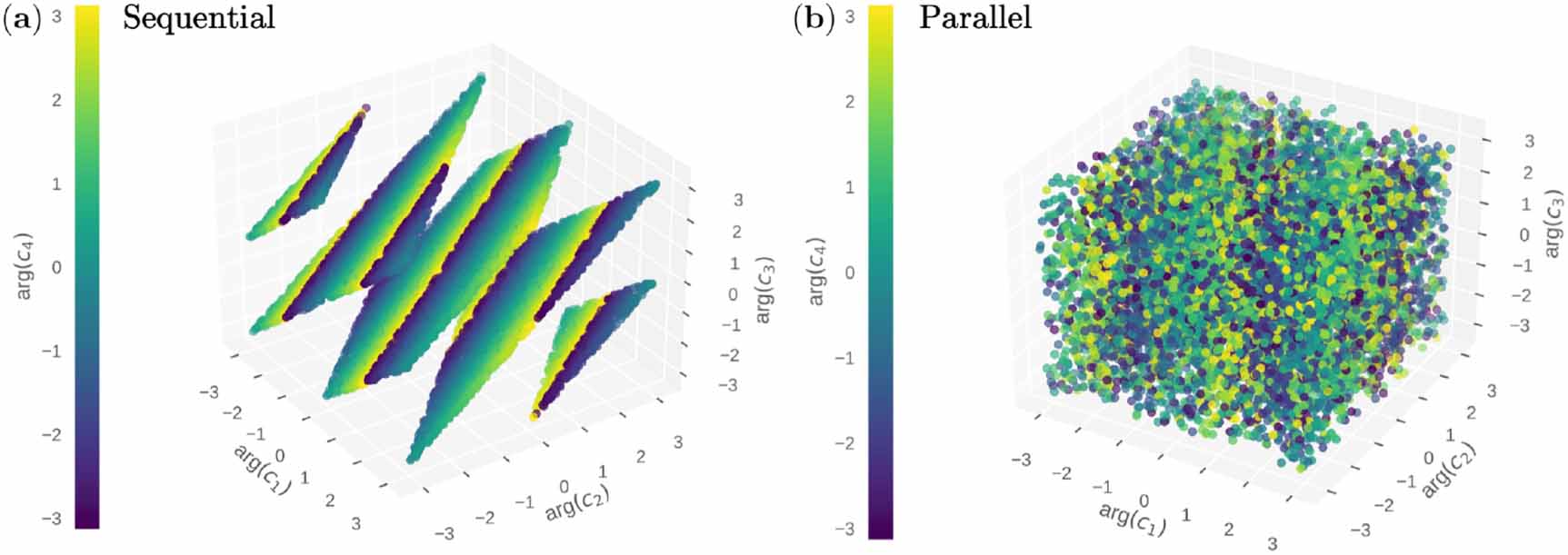
In section 3.3, it was shown that both sequential and parallel exponential architectures represented four Fourier frequencies. However, the latter achieved a lower training loss and a better fit for the top-hat function. This is due to the reduced Fourier accessibility of the sequential architecture, meaning it lacks the freedom to achieve any desired point in the Fourier space. The models with four Fourier frequencies are realised in a nine-dimensional space that includes c0 and the real and imaginary values of ci . Each realisation of the trainable parameters of the quantum circuit produces a 9-dimensional array creating a point in this 9-dimensional space. Realising these two architectures many times makes it possible to analyse the geometry of the Fourier space for each architecture. Still, for manual observation, finding an efficient way to reduce this dimensionality to three dimensions (or four with colour) is essential. Figure 7 shows a choice for this dimensionality reduction by investigating the arguments of the complex Fourier coefficients, which, based on equation (A7), represent the phases of the co-sinusoidal terms. These show that the sequential exponential architecture is dramatically constrained in the collection of phases it can represent and that the parallel exponential is unconstrained in this way.

Figure 7. Fourier phases of the two exponential architectures: (a) sequential and (b) parallel. Each architecture was realised  times, and their arguments were calculated using the discrete Fourier transform of their outputs. We see that the sequential architecture has a restricted four-dimensional behaviour and that a linear dependence between the phases seems to exist, demonstrating a lack of Fourier accessibility. In contrast, the parallel architecture can fill the space, but still, some constraint is visible between the arg
times, and their arguments were calculated using the discrete Fourier transform of their outputs. We see that the sequential architecture has a restricted four-dimensional behaviour and that a linear dependence between the phases seems to exist, demonstrating a lack of Fourier accessibility. In contrast, the parallel architecture can fill the space, but still, some constraint is visible between the arg and arg
and arg bases.
bases.
Download figure:
Standard image High-resolution imageAppendix D: Beyond exponential growth
As in appendix A.1, to reach the final list of wavenumbers needed to subtract the eigenvalues of the Hamiltonian in pairs. This section proposes a mathematical problem leading to the highest possible Fourier series.
Problem 1. For a given  , find a list of integers
, find a list of integers  such that when subtracted from itself, it produces a new list
such that when subtracted from itself, it produces a new list  whose elements are sequential integers and, except for zero, all the elements have a degeneracy of precisely one.
whose elements are sequential integers and, except for zero, all the elements have a degeneracy of precisely one.
The problem statement produces a list of eigenvalues L from which one can make a list of wavenumbers  . After finding this list, it is crucial to check if one can create a diagonal Hamiltonian using RZ
rotations and non-parameterised gates whose diagonal elements are the numbers in L. In appendix C.3 of [41], this problem is equated to the perfect Golomb ruler where for
. After finding this list, it is crucial to check if one can create a diagonal Hamiltonian using RZ
rotations and non-parameterised gates whose diagonal elements are the numbers in L. In appendix C.3 of [41], this problem is equated to the perfect Golomb ruler where for  , this becomes impossible, and the numbers either become nonsequential or degenerate.
, this becomes impossible, and the numbers either become nonsequential or degenerate.
Footnotes
- 1
- 2
A graphical language, based on tensor networks, to analyze quantum circuits [29].
- 3
- 4
Each of these bases has a Fourier amplitude and a phase angle, which need to be altered to fit a model on the training data. However, depending on the architecture (of both the encoding layers and the trainable layers), these quantities may be limited in the values they can represent. This could significantly limit their ability to represent various functions. This will henceforth be referred to as the Fourier accessibility of the quantum architectures.
- 5
Schuld [32] explores other embedding strategies, too, such as basis embedding and amplitude embedding. This work primarily focuses on angle embedding. Nevertheless, it is worth noting that in the circuit model, all circuit parameters enter as angles at some level of the description.
- 6
Extra gates to convert between different generators can be absorbed into the variational gates—see [15].
- 7
In principle, one may also consider gates
with a variational dependence on the feature x, where the parameters fθ
are to be learned. However, this could present additional challenges related to the computation of gradients and increased number of parameters. - 8
In comparison, for linear architectures
for all l. - 9
Note that this happens at the level of the density matrices and is independent of the choice of M.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}