
Abstract
A long-standing goal of machine-learning-based protein engineering is to accelerate the discovery of novel mutations that improve the function of a known protein. We introduce a sampling framework for evolving proteins in silico that supports mixing and matching a variety of unsupervised models, such as protein language models, and supervised models that predict protein function from sequence. By composing these models, we aim to improve our ability to evaluate unseen mutations and constrain search to regions of sequence space likely to contain functional proteins. Our framework achieves this without any model fine-tuning or re-training by constructing a product of experts distribution directly in discrete protein space. Instead of resorting to brute force search or random sampling, which is typical of classic directed evolution, we introduce a fast Markov chain Monte Carlo sampler that uses gradients to propose promising mutations. We conduct in silico directed evolution experiments on wide fitness landscapes and across a range of different pre-trained unsupervised models, including a 650 M parameter protein language model. Our results demonstrate an ability to efficiently discover variants with high evolutionary likelihood as well as estimated activity multiple mutations away from a wild type protein, suggesting our sampler provides a practical and effective new paradigm for machine-learning-based protein engineering.
Export citation and abstract BibTeX RIS
1. Introduction
Engineering proteins to improve their productivity or catalyze new reactions requires scientists to navigate the complex landscape mapping a protein's amino acid sequence to its structure and function (Li et al
2020). Directed evolution is a classic approach inspired by natural evolution where random mutations to a protein's sequence are screened in a wet lab until higher-performing variants are found, at which point the process repeats starting from these variants (Kuchner and Arnold 1997). However, this becomes impractical when proteins cannot be assessed in a high-throughput fashion. The simplest approach, brute force search, is limited in practice to variants with one or two mutations. For a protein with 400 amino acids, there are  ways to make five single substitutions assuming the standard vocabulary of 20 amino acids. It is also remarkably difficult to find proteins with improved function. Most of protein space is non-functional and beneficial mutations are rare (Arnold 1998).
ways to make five single substitutions assuming the standard vocabulary of 20 amino acids. It is also remarkably difficult to find proteins with improved function. Most of protein space is non-functional and beneficial mutations are rare (Arnold 1998).
As supervised machine learning (ML) methods for protein function prediction from primary sequence improve (Dallago et al 2021, Hsu et al 2022), machine-learning-based directed evolution has emerged, which offers a way to judiciously propose candidates for screening that ultimately reduces time spent in the wet lab (Yang et al 2019, Biswas et al 2021, Wu et al 2021). Our work is concerned with improving the variant proposal step by increasing the chance of discovering a mutation that improves a target property of a known 'wild type' (WT) protein (figure 1(a)). We argue that the promising performance of recent unsupervised sequence models at mutation effect prediction (Meier et al 2021, Hsu et al 2022, Weinstein et al 2022) has motivated a reconsideration of simple black-box optimization algorithms for searching sequence space. Black-box algorithms are appealing due to their simplicity, flexibility, compatibility with discrete spaces, and use of interpretable mutation operators. They offer a way to mix and match unsupervised and supervised models for proposing variants without requiring any model fine-tuning or re-training, i.e. in a 'plug and play' manner. Combining both types of models is generally advantageous. While unsupervised models learn information that can steer search away from adversarial inputs which fool supervised models due to overestimation errors (Szegedy et al 2014), supervised models learn specific information about beneficial mutations gleaned from assay-labeled data. However, black-box algorithms tend to be extremely inefficient at searching for variants with improved fitness. A practical plug and play framework for searching protein sequence space has remained elusive due to the difficulty of fast search in discrete, high-dimensional spaces.

Figure 1. (a) Illustration of the machine-learning-based directed evolution pipeline. This paper proposes a plug and play sampler for proposing variants of improved fitness near a wild-type (WT) protein for each design round. (b) We flexibly compose unsupervised and supervised protein sequence models as a product of experts distribution and derive a fast gradient-based discrete MCMC sampler to efficiently sample from this distribution. A product of experts places its probability mass at the intersection of the expert distributions. The key idea of gradient-based discrete MCMC is to bias the mutation proposal distribution towards promising mutations within a local neighborhood around the current variant. Then, to avoid enumerating all mutations in this neighborhood, the proposal is approximated with a first-order Taylor series. An example MCMC trajectory of single point mutations starting from the WT is shown.
Download figure:
Standard image High-resolution imageThis paper fills that gap by introducing plug and play directed evolution (PPDE), a practical plug and play sampling framework for the efficient discovery of functional variants directly in discrete protein space. PPDE flexibly combines unsupervised and supervised models with a product of experts distribution (Hinton 2002)  . Combining both types of protein models in this manner encourages variants to have both high sequence likelihood and high predicted function (e.g. activity). To sample efficiently from the high-dimensional, discrete, and unnormalized distribution p(x), we derive a fast Markov chain Monte Carlo (MCMC) sampler that uses gradients of p(x) to propose mutations. See figure 1(b) for a visual depiction the sampler. PPDE nearly maintains all of the flexibility of black-box algorithms—it only has to additionally assume that p(x) is differentiable at each discrete point of protein space. We theoretically characterize the efficiency of this sampler and empirically show that our framework works with a variety of pre-trained models without using continuous relaxations and without model retraining or fine-tuning. Although our formulation can be applied to a broad class of biological sequence design tasks, we focus on proteins due to the current widespread availability of pre-trained models.
. Combining both types of protein models in this manner encourages variants to have both high sequence likelihood and high predicted function (e.g. activity). To sample efficiently from the high-dimensional, discrete, and unnormalized distribution p(x), we derive a fast Markov chain Monte Carlo (MCMC) sampler that uses gradients of p(x) to propose mutations. See figure 1(b) for a visual depiction the sampler. PPDE nearly maintains all of the flexibility of black-box algorithms—it only has to additionally assume that p(x) is differentiable at each discrete point of protein space. We theoretically characterize the efficiency of this sampler and empirically show that our framework works with a variety of pre-trained models without using continuous relaxations and without model retraining or fine-tuning. Although our formulation can be applied to a broad class of biological sequence design tasks, we focus on proteins due to the current widespread availability of pre-trained models.
A summary of our contributions:
- We introduce a plug and play sampling framework that enables mixing and matching various unsupervised and supervised protein models without model re-training or fine-tuning.
- We demonstrate a novel application of gradient-based discrete MCMC for conducting search with a product of experts distribution.
- We conduct rigorous in silico directed evolution experiments on three target proteins with partially characterized wide (
 2 mutation) fitness landscapes. Our results provide strong evidence that our sampler offers a practical and effective approach for ML-based directed evolution beyond brute force and random search.
2 mutation) fitness landscapes. Our results provide strong evidence that our sampler offers a practical and effective approach for ML-based directed evolution beyond brute force and random search.

2. Related work
Black-box approaches to directed evolution: A popular paradigm for ML-based directed evolution has been to learn a surrogate for the sequence-to-function landscape from a small labeled dataset and then to use a black-box optimizer or sampler such as an evolutionary algorithm or simulated annealing to search for mutants (Hansen and Ostermeier 1996, Angermüller et al 2020, Sinai et al 2020, Biswas et al 2021). Black-box approaches are plug and play in that they can easily combine unsupervised and supervised protein models without any model fine-tuning or re-training. Navigating the high-dimensional discrete space is approached by either using a random walk, which is highly inefficient, or by using gradient ascent via a continuous relaxation of the space, which can bias the search process towards poor local optima. These are the main baselines for our method and will be described in more detail in section 5. Reinforcement learning (RL) has also been used as a black-box optimization framework for training autoregressive models to generate high-fitness variants (Angermueller et al 2019). However, this approach has less flexibility than plug and play methods, in that it does not support easy mixing of unsupervised pre-trained models with the learned RL policy.
Protein design by generative modeling: An alternative to directed evolution is to cast protein design as inference, i.e. fitting a conditional generative model to assay-labeled proteins showing high activity (Brookes and Listgarten 2018, Gupta and Zou 2018, Brookes et al 2019, Fannjiang and Listgarten 2020, Jain et al 2022, Zhang et al 2022a). Since high performing variants are rare, this task amounts to density estimation of a rare event which is a difficult statistical inference problem in its own right. Another popular alternative is latent space optimization, in which gradient ascent is performed on a surrogate function trained directly in the latent space of a generative model. These generative models use regularization to shape their latent space favorably so that optimization remains constrained to the manifold of viable proteins (Killoran et al 2017, Gomez-Bombarelli et al 2018, Kumar and Levine 2020, Linder et al 2020, Chan et al 2021, Trabucco et al 2021, Castro et al 2022). The deep manifold sampler (Gligorijevic et al 2021) more explicitly constrains optimization by alternating between steps of gradient ascent and re-projection of a noised version of the sequence onto the latent space of a custom denoising autoencoder (DAE). Our plug and play approach works with a variety of unsupervised models and can combine multiple such models if desired.
At the expense of trust in candidate proteins, unconditional generative models can also be used to hallucinate proteins from distant, unexplored regions of protein space. For example, training a generative model on sequences from a target protein family has been used to generate functional variants (Costello and Martin 2019, Hawkins-Hooker et al 2021, Shin et al 2021). Unconditional sampling from protein language models trained on unaligned (Madani et al 2020, Rives et al 2021, Ferruz et al 2022, Hesslow et al 2022, Lin et al 2022, Nijkamp et al 2022, Yang et al 2022) and aligned (Rao et al 2021, Notin et al 2022) sequences has recently been explored. While this is a promising new direction for protein engineering, our focus is on directed evolution from known proteins.
Plug and play text generation: Controlled generation of text has similarly been approached by combining pre-trained unsupervised models (e.g. large language models) and supervised models (e.g. sentiment classifiers) as a discrete product of experts (Holtzman et al 2018, Dathathri et al 2020, Qin et al 2022). Unlike controlled text generation, where the goal is to guide a sampling process to transform a sentence by altering entire words and phrases, directed evolution seeks to accumulate a few precise changes to an initial sequence by modifying a small number of amino acids (i.e. individual characters). Moreover, plug and play approaches for controlled text generation intentionally avoid solving a combinatorial search problem by instead restricting the class of suitable unsupervised experts to left-to-right autoregressive language models. This enables the use of sequential sampling algorithms such as left-to-right beam search decoding. Our use of gradient-based discrete MCMC for PPDE allows us to efficiently search the combinatorial space of mutations near the WT protein and to use a more general class of unsupervised experts that includes orderless protein sequence models which capture epistatic relationships between any pair of amino acids. The Metropolis-adjusted Langevin algorithm (MALA) used for plug and play image generation (Nguyen et al 2017) is a simple gradient-based MCMC sampler for continuous spaces, and is closely related to locally-balanced discrete MCMC (Sun et al 2022a, Zhang et al 2022b). Therefore, we use MALA with a hand-crafted continuous relaxation as a baseline for plug and play sampling from discrete product of experts in our experiments.
3. Background
Before presenting our sampler, we define our search problem, briefly review Metropolis–Hastings (MH) MCMC, and introduce gradient-based discrete MCMC, a class of MH samplers able to efficiently explore high-dimensional discrete distributions.
Problem definition: The variant proposal step of directed evolution involves searching for mutations that improve one or more target properties of a given WT protein. This search problem is formally defined over discrete protein sequences  ,
,  , of length L with each xi
taking on a value in a vocab of size V (typically V = 20 for the 20 standard amino acids). We assume that each xi
is one-hot encoded. The search is initialized at the WT protein xWT and terminates when a predefined condition is met (e.g. a maximum allowable number of search steps is reached).
, of length L with each xi
taking on a value in a vocab of size V (typically V = 20 for the 20 standard amino acids). We assume that each xi
is one-hot encoded. The search is initialized at the WT protein xWT and terminates when a predefined condition is met (e.g. a maximum allowable number of search steps is reached).
MH: The MH algorithm (Metropolis et al
1953, Hastings 1970) defines the following algorithm for drawing samples from a distribution over protein variants p(x). Let f(x) be the unnormalized log probability of x such that  where
where  is a normalizing constant. Given the current state x, draw a candidate next state xʹ from proposal distribution
is a normalizing constant. Given the current state x, draw a candidate next state xʹ from proposal distribution  . Accept the proposed state with probability
. Accept the proposed state with probability

otherwise reject the transition and stay at x. This probabilistic acceptance/rejection criterion is desirable since it provides MH samplers with theoretical convergence guarantees and does not contain any hyperparameters, simplifying the implementation of MH in practice.
Gradient-based discrete MCMC: Uninformed MH proposals such as the uniform distribution are often inefficient for sampling from high-dimensional discrete distributions since candidate states xʹ are proposed 'blindly'. In general, the efficiency of MH is highly dependent on the choice of proposal distribution. MH with locally-balanced informed proposals (Zanella 2020) use distributions of the form

where  is an indicator function. The key idea is to bias the proposal distribution towards local state transitions within a neighborhood
is an indicator function. The key idea is to bias the proposal distribution towards local state transitions within a neighborhood  that incur an increase in likelihood. We take the square root of the exponential in this proposal as the choice of local balancing function
that incur an increase in likelihood. We take the square root of the exponential in this proposal as the choice of local balancing function  . This function 'balances' the acceptance and rejection probabilities in the local neighborhood
. This function 'balances' the acceptance and rejection probabilities in the local neighborhood  to achieve a high acceptance rate. The square root
to achieve a high acceptance rate. The square root  was empirically validated as a good default option in Zanella (2020). Since enumerating all local moves in
was empirically validated as a good default option in Zanella (2020). Since enumerating all local moves in  in a discrete high-dimensional spaces is infeasible, an efficient alternative is available for functions f(x) whose gradient can be evaluated at the discrete state x (Grathwohl et al
2021). A gradient-based locally-balanced informed proposal is the first-order Taylor-series approximation of equation (1) around x:
in a discrete high-dimensional spaces is infeasible, an efficient alternative is available for functions f(x) whose gradient can be evaluated at the discrete state x (Grathwohl et al
2021). A gradient-based locally-balanced informed proposal is the first-order Taylor-series approximation of equation (1) around x:

When  is the 1-Hamming ball, this proposal amounts to a tempered softmax over single changes to one dimension of x. One forward pass and one backwards pass is required to compute the forward
is the 1-Hamming ball, this proposal amounts to a tempered softmax over single changes to one dimension of x. One forward pass and one backwards pass is required to compute the forward  and reverse
and reverse  approximate proposals.
approximate proposals.
A concern with this sampler is that it is susceptible to getting trapped in poor local optima since it cannot perform large jumps across the search space at each step of MCMC (Sun et al
2022b). One way to address this is to increase the Hamming window size, U, to U > 1. While this enables the sampler to propose changes to multiple dimensions of x simultaneously, it also incurs a large increase in computation since  now contains
now contains  states to evaluate. Alternatively, a path proposal sequentially samples
states to evaluate. Alternatively, a path proposal sequentially samples  single changes to apply to the current state x (Sun et al
2022b). For example, if x is the sequence 'AAA', then a sampled path of length 3 could look like 'AAA'
single changes to apply to the current state x (Sun et al
2022b). For example, if x is the sequence 'AAA', then a sampled path of length 3 could look like 'AAA'  'AAB'
'AAB'  'AAC'
'AAC'  'ABC'.
'ABC'.
The approximate path proposal distribution starting at  is
is

The rth path state xr
is sampled from  . The sampler decides whether to accept or reject the terminal path state
. The sampler decides whether to accept or reject the terminal path state  (e.g. 'ABC'), i.e. the accumulation of all R changes applied to x. The reverse proposal
(e.g. 'ABC'), i.e. the accumulation of all R changes applied to x. The reverse proposal  is computed using the gradient at the terminal state
is computed using the gradient at the terminal state  and the reversed sequence of states
and the reversed sequence of states  . The number of forward and backwards passes required to compute the forward and reverse path proposals is still two. In the next section, we will introduce and characterize a gradient-based path proposal for product of experts distributions.
. The number of forward and backwards passes required to compute the forward and reverse path proposals is still two. In the next section, we will introduce and characterize a gradient-based path proposal for product of experts distributions.
4. PPDE
Our approach for proposing mutations that improve a target property of the WT protein is to sample from a distribution constructed by combining unsupervised and supervised sequence models without using any continuous relaxations, model re-training, or fine-tuning. This distribution places its probability mass on proteins that have both high evolutionary density f(x) (i.e. high likelihood of being a naturally occurring protein) and high predicted function g(x) (e.g. activity or stability) by taking the product of multiple pre-trained 'expert' distributions:

Each  is an unsupervised model, each
is an unsupervised model, each  is a supervised model, and
is a supervised model, and

is the unknown normalizing constant. Typically,  has been trained to do density estimation on unlabeled yet aligned sequences (e.g. a collection of evolutionarily related sequences provided by a multiple sequence alignment (MSA)) or unaligned sequences. While in this work we assume the
has been trained to do density estimation on unlabeled yet aligned sequences (e.g. a collection of evolutionarily related sequences provided by a multiple sequence alignment (MSA)) or unaligned sequences. While in this work we assume the  are an ensemble of nonlinear models trained to regress activity from a labeled dataset of mutants, this formulation can easily be extended to the multi-objective case where, for e.g. g1 predicts activity and g2 predicts stability.
are an ensemble of nonlinear models trained to regress activity from a labeled dataset of mutants, this formulation can easily be extended to the multi-objective case where, for e.g. g1 predicts activity and g2 predicts stability.
The unsupervised experts  act as a soft constraint that keeps the sampler near regions of high evolutionary density and away from, e.g. adversarial local optima of the supervised models. Examples of unsupervised models that provide an evolutionary density score include the EVmutation Potts model (Hopf et al
2017), the ESM protein masked language models (Rives et al
2021, Lin et al
2022), DAEs, energy based models (EBMs), autoregressive protein language models (e.g. ProGen2 (Nijkamp et al
2022)), and normalizing flows (non-exhaustive list). The supervised expert
act as a soft constraint that keeps the sampler near regions of high evolutionary density and away from, e.g. adversarial local optima of the supervised models. Examples of unsupervised models that provide an evolutionary density score include the EVmutation Potts model (Hopf et al
2017), the ESM protein masked language models (Rives et al
2021, Lin et al
2022), DAEs, energy based models (EBMs), autoregressive protein language models (e.g. ProGen2 (Nijkamp et al
2022)), and normalizing flows (non-exhaustive list). The supervised expert  acts as a soft constraint that guides sampling towards proteins that have high activity, where
acts as a soft constraint that guides sampling towards proteins that have high activity, where  assigns high probability to sequences with high activity. The hyperparameter
assigns high probability to sequences with high activity. The hyperparameter  allows us to balance the contribution of the unsupervised and supervised experts; for example, we can emphasize the 'realism' of the protein (the evolutionary density) by setting λ to 0. However, recent evidence indicates that evolutionary density scores also positively correlate with protein fitness in a 'zero-shot' manner (i.e. without using any labels) (Meier et al
2021, Hsu et al
2022, Weinstein et al
2022).
allows us to balance the contribution of the unsupervised and supervised experts; for example, we can emphasize the 'realism' of the protein (the evolutionary density) by setting λ to 0. However, recent evidence indicates that evolutionary density scores also positively correlate with protein fitness in a 'zero-shot' manner (i.e. without using any labels) (Meier et al
2021, Hsu et al
2022, Weinstein et al
2022).
4.1. Product of experts gradient-based discrete MCMC
Sampling from the product of experts (equation (4)) is difficult since the normalization constant Z is assumed unknown and is intractable to compute in practice. Although we have a good initialization for an MCMC sampler—xWT, the WT protein of verified viability—traditional MCMC based on random walk exploration is too inefficient to discover variants with high predicted activity in reasonable time.
Our solution is to use fast gradient-based discrete MCMC. We need only additionally assume that each expert is a continuous function that is differentiable at each discrete  (e.g. as is the case when the experts are neural networks). In detail, assume we have M continuously differentiable unsupervised experts and N continuously differentiable supervised experts. During each step of MCMC, we use the gradients of the M + N experts to approximate the change in product of experts likelihood due to making R point mutations to the current protein variant. This allows us to bias the proposal distribution towards the most promising R mutations. The gradient-based Taylor approximation of our MCMC proposal for
(e.g. as is the case when the experts are neural networks). In detail, assume we have M continuously differentiable unsupervised experts and N continuously differentiable supervised experts. During each step of MCMC, we use the gradients of the M + N experts to approximate the change in product of experts likelihood due to making R point mutations to the current protein variant. This allows us to bias the proposal distribution towards the most promising R mutations. The gradient-based Taylor approximation of our MCMC proposal for  with path length
with path length  is
is  , where
, where

We use this path proposal to sample R single amino acid substitutions, which we apply to the current variant  at each step of MCMC. The terminal state of the path
at each step of MCMC. The terminal state of the path  is the variant that results from the accumulation of the R substitutions. To avoid computing extra forward and backwards passes through the product of experts for the intermediate path proposals
is the variant that results from the accumulation of the R substitutions. To avoid computing extra forward and backwards passes through the product of experts for the intermediate path proposals  , following Sun et al (2022b) we re-use the gradient taken with respect to the path origin x0 instead of recomputing gradients at intermediate states. The same is done for the reverse path proposals
, following Sun et al (2022b) we re-use the gradient taken with respect to the path origin x0 instead of recomputing gradients at intermediate states. The same is done for the reverse path proposals  with respect to the terminal state xR
. In the next section, we characterize the efficiency of our sampler to understand how composing Taylor approximations for multiple experts affects the theoretical convergence rate.
with respect to the terminal state xR
. In the next section, we characterize the efficiency of our sampler to understand how composing Taylor approximations for multiple experts affects the theoretical convergence rate.
Algorithm 1 shows pseudo-code for our fast MCMC sampler for plug and play directed evolution of proteins. The sampler follows the basic structure of MH MCMC. At each sampler step, we first compute the forward path proposal distribution  which we use to sample the proposed protein xʹ. Then, we compute the reverse path proposal distribution
which we use to sample the proposed protein xʹ. Then, we compute the reverse path proposal distribution  . We use these distributions to compute an acceptance criterion for determining whether to accept or reject xʹ, after which the process repeats until termination (e.g. a predetermined number of MCMC steps is reached).
. We use these distributions to compute an acceptance criterion for determining whether to accept or reject xʹ, after which the process repeats until termination (e.g. a predetermined number of MCMC steps is reached).
| Algorithm 1. Plug and Play Directed Evolution (PPDE). |
|---|
| input one-hot encoded wild-type protein xWT , unsupervised experts fi , supervised experts gj , scale λ, max path length U |
output evolved protein 
|
| while still searching do |
define
 , ,  , , 
|
| // compute the forward path proposal distribution |
sample path length 
|
for
 do
do
|

|

|
// sample a single amino acid substitution and apply it to 
|

|
| end for |
for
 do
do
|


|
| end for |
| // accept xʹ with probability |

|
| end while |
4.2. Sampler analysis
Since we are using a gradient-based approximation of the product of experts proposal distribution, a natural question is whether this approximation reduces the sample efficiency of our sampler. It turns out that the choice of unsupervised and supervised experts plays a key role in determining the theoretical sampler efficiency. In particular, the following corollary to theorem 3 from Sun et al (2022b) relates the smoothness of each expert's gradient to our sampler's ability to efficiently explore protein space. Corollary 1.
corollary Assume λ = 1, each expert hi
is differentiable,  is Ki
-Lipschitz, the max path length is U, and a 1-Hamming ball neighborhood
is Ki
-Lipschitz, the max path length is U, and a 1-Hamming ball neighborhood  . Let
. Let  and
and  be the Markov transition kernels induced by our sampler with the product of experts proposal
be the Markov transition kernels induced by our sampler with the product of experts proposal  and with its approximation
and with its approximation  , respectively. These transition kernels are related by
, respectively. These transition kernels are related by

See appendix
remark This result bounds the efficiency of the sampler by a product of exponential functions of each expert's gradient's Lipschitz constant Ki . This means that if just one expert has a gradient with a large Lipschitz constant (e.g. the unsupervised experts are highly nonlinear protein language models), it is possible that this expert greatly reduces the overall efficiency of the sampler. For supervised experts (possibly an ensemble), which are typically shallow neural networks whose gradients have small Lipschitz constants, we can expect that the first-order approximation will not greatly reduce the sampler's efficiency. However, equation (6) is a fairly loose bound. We will empirically compare how the sampler fares with different types of experts in practice (see section 5.2.3).
5. Experiments
In this section, we present the results of multiple synthetic experiments. First, we validate that our proposed sampler is able to discover a diverse set of good optima for product of experts distributions in high-dimensional discrete spaces using a toy MNIST-based task. Then, with a realistic in silico directed evolution experimental setup, we characterize advantages of combining unsupervised and supervised models and compare our sampler with appropriate baseline plug and play algorithms. The baselines are:
-
Simulated annealing: This is a simple random-mutation-based MCMC-style algorithm from Biswas et al (2021) for sampling from the global optimum of a discrete Boltzmann distribution with temperature T and . We apply this to sample from our product of experts (equation (4)). At each sampling step, a new sequence is proposed by randomly sampling uniformly sampled amino acid substitutions with rate . Proposed variants are accepted with probability with T annealed over time to encourage the sampler to become more exploitative. Variants with higher are always accepted whereas sequences that decrease are accepted with a probability proportional to the difference scaled by the temperature.
-
Random sampling: We provide a simple baseline that does not use search but rather uniformly samples variants around the WT protein, with aims of quantifying the advantage of using search to accumulate multiple promising mutations. Given a budget of N variants, we use the same mutation proposal algorithm as simulated annealing to sample and apply a single mutation (which could consist of multiple amino acid substitutions) to the WT. After sampling N such variants, we sort them by and return the top K.
-
MALA-approx: This baseline employs a continuous relaxation of discrete protein space to use stochastic gradient-based continuous optimization inspired by Nguyen et al (2017). During each step, MALA-approx
samples where ε is a step size and is a straight-through estimate of the gradient (Bengio et al
2013) of the product of experts with respect to the current relaxed variant. The continuous relaxation is based on a temperature-controlled relaxation of categorical variables to continuous vectors on the simplex (Jang et al
2016, Maddison et al
2016) with temperature τ. That is, we interpret each sequence position of protein x to be a rounded sample from a relaxed categorical distribution. We run this sampler in 'logit space' of these distributions since the support of logit space extends across the entire real line, whereas enforcing valid probability distributions at each sequence position would require solving a difficult constrained optimization problem. Given the one-hot WT protein xWT, the sampler is initialized at logit values given by a convex combination of a uniform distribution over all amino acids and the WT: . To round to discrete values for evaluating ), we sample from the relaxed categorical distributions with logits and then take the argmax at each sequence position.
-
CMA-ES: The CMA-ES algorithm (Hansen and Ostermeier 1996) is a powerful evolutionary strategies optimizer that accelerates search by maintaining an estimate of higher order relational statistics between each dimension of the search space. This algorithm is designed for continuous spaces with tens or hundreds of dimensions to eventually concentrate around the global optimum. It iteratively updates a Gaussian distribution (both mean and full covariance matrix) by sampling and evaluating a population of candidates. Like MALA-approx
, it requires using a continuous relaxation of protein space. Simply, we 'flatten' a one-hot protein x into a vector of dimension LV which we then re-interpret as a continuous vector in . To undo this relaxation, we reshape the vector into a length L sequence and interpret the V entries at each sequence position as scores, i.e. we take the argmax.














We use multiple metrics to compare samplers that measure not only activity but also whether designed proteins are evolutionarily plausible. Our results provide strong evidence that combining unsupervised evolutionary models with supervised models produces variants more likely to appear in nature and with higher fitness, especially when using unsupervised models fit on aligned sequences. Moreover, we find that composing multiple unsupervised models trained on aligned and unaligned sequences has the best performance. We also verify that, by and large, our gradient-based discrete MCMC sampler for product of experts achieves better sampling performance than the random-walk-based and evolutionary-strategies-based baselines.
5.1. MNIST-Sum
Before we present results on ML-based directed evolution, we evaluate the samplers on a toy search problem where optimized designs are easy to interpret.
Setup: We construct a binary MNIST task that emulates a typical ML-based directed evolution problem. We are given two binary MNIST images x1 and x2 where x2 is the WT image. Each image is treated as a length L = 784 one-hot sequence where  . The goal is to evolve x2, keeping x1 fixed, to maximize the sum of the two digits (figure 2). Here, the equivalent of an amino acid substitution is flipping a binary pixel. This task is difficult for methods that optimize in discrete space, since flipping most pixels causes the image to 'fall off' the underlying low dimensional manifold of MNIST digits. To obtain supervised experts
. The goal is to evolve x2, keeping x1 fixed, to maximize the sum of the two digits (figure 2). Here, the equivalent of an amino acid substitution is flipping a binary pixel. This task is difficult for methods that optimize in discrete space, since flipping most pixels causes the image to 'fall off' the underlying low dimensional manifold of MNIST digits. To obtain supervised experts  for a product of experts
for a product of experts  (equation (4)), we use a labeled dataset of 50 K pairs of binary MNIST digits with sum
(equation (4)), we use a labeled dataset of 50 K pairs of binary MNIST digits with sum  (the 'assay-labeled proteins') to train an ensemble of three shallow siamese ConvNets that regresses the sum
(the 'assay-labeled proteins') to train an ensemble of three shallow siamese ConvNets that regresses the sum  . We then use an unlabeled datasest of 50 K binary MNIST images (the 'unlabeled protein database', such as UniRef) to train a deep EBM and to train a DAE for unsupervised experts
. We then use an unlabeled datasest of 50 K binary MNIST images (the 'unlabeled protein database', such as UniRef) to train a deep EBM and to train a DAE for unsupervised experts  (see appendix for model details).
(see appendix for model details).

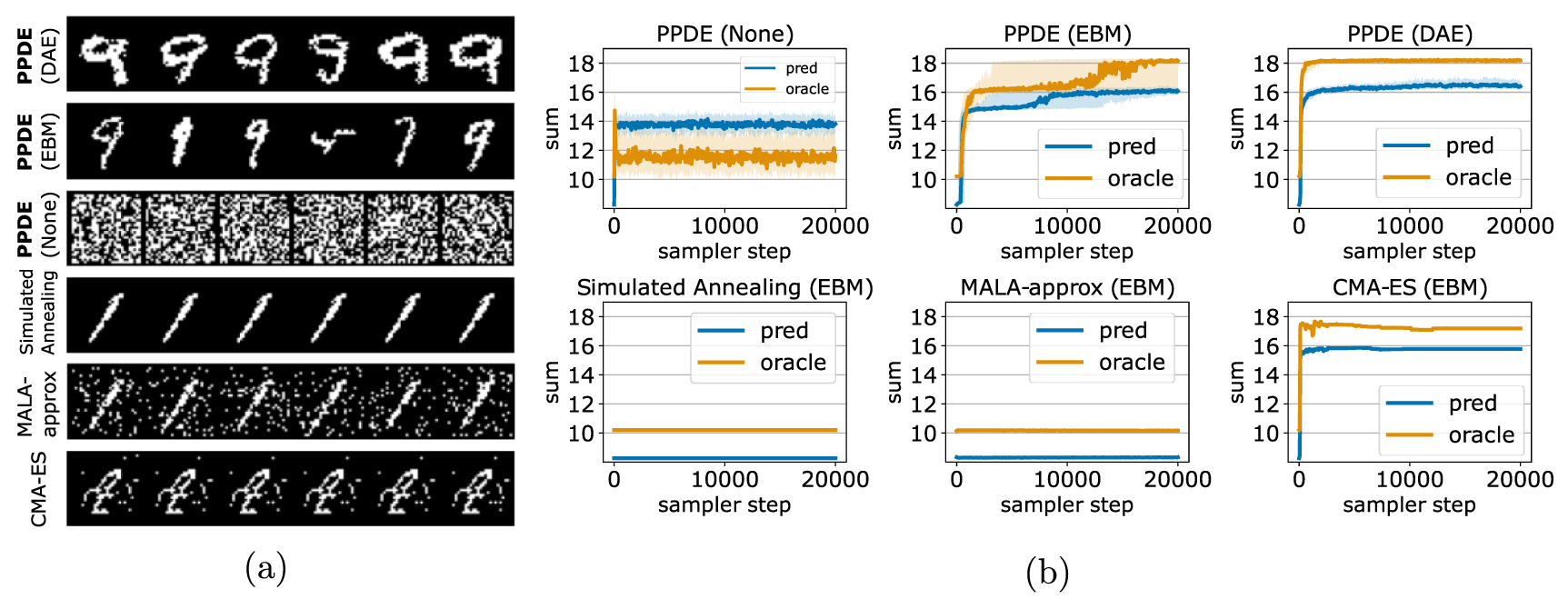
Figure 2. MNIST-Sum: the objective is to evolve the wild type image (right) to maximize the sum of the two digits.
Download figure:
Standard image High-resolution imagePPDE is compared against simulated annealing, MALA-approx
, and CMA-ES. All methods use a single EBM unsupervised expert and an ensemble of three -convolutional neural networks (CNNs) as supervised experts. To examine the importance of the unsupervised expert, we run PPDE with only supervised experts (PPDE (None) or PPDE (supervised only)). We then highlight PPDE's plug and play ability by running it with an EBM expert (PPDE (EBM)) and then swapping it out for a DAE expert (PPDE (DAE)) without performing any further fine-tuning or re-training. Key hyperparameters for each sampler are tuned on the digit pair  (which has maximum sum 10 since x2 is evolved while x1 is held fixed) for 10 K steps. We test each sampler on the out-of-distribution image pair
(which has maximum sum 10 since x2 is evolved while x1 is held fixed) for 10 K steps. We test each sampler on the out-of-distribution image pair  with maximum possible sum 18. In this case, 'solving' the task is equivalent to evolving the WT '1' digit into a '9'. Each method evolves a population of size 128 and each sample in the population is optimized for a budget of 20 K steps. To estimate 'ground truth' sums for optimized image pairs, we train an ensemble of three siamese ConvNets to near perfect accuracy on pairs of digits whose sums are
with maximum possible sum 18. In this case, 'solving' the task is equivalent to evolving the WT '1' digit into a '9'. Each method evolves a population of size 128 and each sample in the population is optimized for a budget of 20 K steps. To estimate 'ground truth' sums for optimized image pairs, we train an ensemble of three siamese ConvNets to near perfect accuracy on pairs of digits whose sums are  .
.
Results: The qualitative and quantitative results in figure 3 show that composing the supervised experts with an unsupervised expert (the EBM or the DAE) is necessary to solve the task; otherwise, the PPDE sampler is unable to avoid adversarial inputs and each run of the sampler converges to white noise images. We also observe that PPDE samples a highly diverse population of digits with noticeable semantic differences. We see that PPDE (DAE) outperforms PPDE (EBM), which we suspect could be caused by the DAE's gradients being more informative due to its denoising training objective. Simulated annealing and MALA-approx fail in this high-dimensional space due to the difficulty of using random walks to find search directions that increase the product of experts probability. CMA-ES is outperformed by PPDE despite its use of covariance information to accelerate search in high-dimensional spaces. PPDE's evolved images are considerably more realistic than those produced by CMA-ES. We also observe that on this task, CMA-ES produces images that show low semantic diversity (the images differ at the pixel-level but the by and large look highly similar). We speculate that PPDE gains an advantage over CMA-ES by using gradients to select which pixels to mutate instead of approximate high-order statistics.

Figure 3. MNIST-Sum results: (a) random samples from the optimized digit populations. The samples from PPDE (DAE) have the highest diversity and also closely resemble MNIST images of a '9'. PPDE (None) does not use an unsupervised expert which causes sampler trajectories to become trapped in adversarial regions of the space where samples resemble white noise. The random mutation proposals employed by simulated annealing and MALA-approx cause these samplers to fail due to the high-dimensionality of the space. CMA-ES's samples have low diversity yet converge onto a population of images that somewhat resemble a '9'. (b) The supervised experts' predicted sum (orange) vs. the oracle's predicted sum (blue) for the sampler trajectories. Each line plot is the 70th percentile sum with the shaded region showing the 50th and 90th percentiles. PPDE (DAE) reliably maximizes the sum of the digits ('18') as measured by the oracle model.
Download figure:
Standard image High-resolution image5.2. In silico directed evolution
Datasets: We use three benchmark proteins with partially characterized wide fitness landscapes and MSAs from Hsu et al (2022) for in silico directed evolution experiments: the poly(A)-binding protein (PABP) dataset of variants measuring binding activity (95 residues, each variant has  2 mutations), the ubiquitination factor E4B (UBE4B) protein dataset measuring ligase activity (103 residues, each variant has
2 mutations), the ubiquitination factor E4B (UBE4B) protein dataset measuring ligase activity (103 residues, each variant has  6 mutations), and green fluorescent protein (GFP) dataset measuring fluorescence (238 residues, each variant has
6 mutations), and green fluorescent protein (GFP) dataset measuring fluorescence (238 residues, each variant has  15 mutations). To emulate a realistic protein engineering setup with reasonable amounts of data for training our supervised experts g(x), we use the '2-vs-rest' mutation train/test split as suggested in Dallago et al (2021)—that is, after splitting each dataset 80/20, we keep only sequences with two or fewer mutations for training and subsample 10% of these. For PABP, both the train and test sets only have variants with at most two mutations. This amounts to 3 K sequences for PABP, 2 K for UBE4B, and 1 K for GFP.
15 mutations). To emulate a realistic protein engineering setup with reasonable amounts of data for training our supervised experts g(x), we use the '2-vs-rest' mutation train/test split as suggested in Dallago et al (2021)—that is, after splitting each dataset 80/20, we keep only sequences with two or fewer mutations for training and subsample 10% of these. For PABP, both the train and test sets only have variants with at most two mutations. This amounts to 3 K sequences for PABP, 2 K for UBE4B, and 1 K for GFP.
Metrics: Quantitative evaluation of optimized variants involves measuring the activity (log fitness), the likelihood to appear in nature (evolutionary density), population diversity, and ability to explore the fitness landscape around the WT (average number of mutations per variant). To compute log fitness, we take inspiration from model-based optimization benchmarks (Trabucco et al
2022) and simulate an expensive wet lab verification with a powerful 'oracle' model that we train with 80% of all variants (with all numbers of mutations) for each protein. Log fitness is scored relative to WT with the Augmented EVmutation Potts model from Hsu et al (2022) as the oracle. To compute an evolutionary density score relative to WT, we use a different transformer, the MSA Transformer (Rao et al
2021), conditioned on 500 randomly subsampled sequences from each MSA. For both log fitness and evolutionary density, positive values mean the variant outscored the WT while negative values are worse than WT. We run each sampler 128 times for 10 K steps each, initialized at the WT, and select the sample with the maximum  per run for the final population. As plug and play baselines we again use simulated annealing, CMA-ES, and MALA-approx
, as well as random sampling.
per run for the final population. As plug and play baselines we again use simulated annealing, CMA-ES, and MALA-approx
, as well as random sampling.
Experts: We use the EVmutation Potts and ESM2 family of protein language models as pre-trained unsupervised experts. All baselines use a single Potts expert and are directly compared with PPDE (Potts). Unless stated otherwise, we use the 150 M parameter version of ESM2. We also run our sampler with both Potts and ESM2 (i.e. we take the sum of the Potts and ESM2 evolutionary density scores) (PPDE (Potts+ESM2)). For the supervised expert we use an ensemble of three shallow CNNs introduced as a baseline in Dallago et al (2021) which regress activity directly from one-hot encoded proteins. See the appendix for architecture details and details on how we implement the evolutionary density scoring for the Potts and protein language model scoring functions.
Choosing λ: Multiplying the supervised experts with the hyperparameter  trades off how much the unsupervised and supervised experts influence which variants are sampled from the product of experts distribution. A larger value for λ inflates the supervised expert scores which causes the sampler to have more confidence in variants with high predicted activity. We use a simple heuristic to select λ for the three benchmark proteins and for each of the Potts and ESM2 unsupervised experts. The heuristic roughly assigns equal emphasis to the unsupervised and supervised expert scores. In detail, we estimate the {min, max, mean} statistics of expert scores computed from a small representative sample of labeled protein variants and then picks λ such that the statistics for the supervised expert scores are close to those of the unsupervised expert scores. We sample 100 protein variants from the training set that have lower activity than WT and 100 proteins with higher activity higher than WT and then evaluate the {min, max, mean} of the unsupervised expert scores and
trades off how much the unsupervised and supervised experts influence which variants are sampled from the product of experts distribution. A larger value for λ inflates the supervised expert scores which causes the sampler to have more confidence in variants with high predicted activity. We use a simple heuristic to select λ for the three benchmark proteins and for each of the Potts and ESM2 unsupervised experts. The heuristic roughly assigns equal emphasis to the unsupervised and supervised expert scores. In detail, we estimate the {min, max, mean} statistics of expert scores computed from a small representative sample of labeled protein variants and then picks λ such that the statistics for the supervised expert scores are close to those of the unsupervised expert scores. We sample 100 protein variants from the training set that have lower activity than WT and 100 proteins with higher activity higher than WT and then evaluate the {min, max, mean} of the unsupervised expert scores and  {min, max, mean} of the supervised expert scores for
{min, max, mean} of the supervised expert scores for  . When using the Potts unsupervised expert we use
. When using the Potts unsupervised expert we use  and when using the ESM2 expert we use
and when using the ESM2 expert we use  for the PABP, UBE4B, and GFP proteins, respectively. Less manual approaches that tune λ over a grid of values or learn
λ over a held-out validation set of labeled variants could be used instead if desired (Holtzman et al
2018).
for the PABP, UBE4B, and GFP proteins, respectively. Less manual approaches that tune λ over a grid of values or learn
λ over a held-out validation set of labeled variants could be used instead if desired (Holtzman et al
2018).
5.2.1. Main results
Figure 4 shows the 80th percentile metrics for each evolved population colored by the population's average number of mutations. The 50th and 100th percentile results for all samplers are provided in a table in the appendix (table 2). Diversity scores are in table 1. We make the following observations.

Figure 4.
In silico directed evolution 80th percentile results. Positive log fitness and evolutionary (evo.) density scores are better than the WT while negative values are worse than WT. The red dashed lines intersect at WT performance  . Each sampler is colored by the average number of mutations per variant (higher is better). On PABP (left), PPDE (Potts+ESM2) and PPDE (Potts only) (arrows) achieve the highest evo. density and log fitness—both better than WT—and with relatively high numbers of mutations. On UBE4B (center), PPDE (Potts) and PPDE (Potts only) (arrows) appear to best trade off evo. density, log fitness, and mutation count. PPDE (ESM2) achieves the best log fitness but with slightly worse evo. density scores. On GFP (right), only PPDE (Potts) and PPDE (Potts+ESM2) (arrows) discover samples with log fitness better than WT. CMA-ES is omitted for viewing clarity due to outlier results on UBE4B (log fitness: 2.54, evo. density:
. Each sampler is colored by the average number of mutations per variant (higher is better). On PABP (left), PPDE (Potts+ESM2) and PPDE (Potts only) (arrows) achieve the highest evo. density and log fitness—both better than WT—and with relatively high numbers of mutations. On UBE4B (center), PPDE (Potts) and PPDE (Potts only) (arrows) appear to best trade off evo. density, log fitness, and mutation count. PPDE (ESM2) achieves the best log fitness but with slightly worse evo. density scores. On GFP (right), only PPDE (Potts) and PPDE (Potts+ESM2) (arrows) discover samples with log fitness better than WT. CMA-ES is omitted for viewing clarity due to outlier results on UBE4B (log fitness: 2.54, evo. density:  ) and GFP (log fitness: −1.13, evo. density:
) and GFP (log fitness: −1.13, evo. density:  ). Best viewed in color.
). Best viewed in color.
Download figure:
Standard image High-resolution imageTable 1. Population diversity (% of variants that are unique).
| Random search | Simulated annealing | MALA-approx | CMA-ES | PPDE (Potts only) | PPDE (Super. only) | PPDE (Potts) | PPDE (ESM2) | PPDE (Potts+ESM2) | |
|---|---|---|---|---|---|---|---|---|---|
| PABP | 32.8 | 28.9 | 28.9 | 0.8 | 85.2 | 60.2 | 65.6 | 63.1 | 85.2 |
| UBE4B | 7.0 | 4.7 | 6.2 | 3.1 | 12.5 | 18.8 | 18.8 | 36.5 | 31.3 |
| GFP | 9.4 | 3.9 | 9.4 | 92.2 | 8.6 | 59.4 | 22.7 | 92.9 | 21.9 |
Table 2. 50th (100th) percentile scores. Population size is 128. Across all three proteins, PPDE (Potts) and PPDE (Potts+ESM2) in particular discover variants with higher predicted fitness and average # of mutations than Random search, Simulated annealing, and MALA-approx
. Out of the samplers using the Potts expert, PPDE (Potts) achieves the highest evolutionary density scores on PABP. We suspect that the slightly lower 50th percentile evolutionary density scores compared to the baselines (except CMA-ES) on the more challenging UBE4B and GFP proteins are in part due to PPDE discovering variants with more average mutations ( mutations vs.
mutations vs.  mutation per variant) and higher fitness. The 100th percentile performance of PPDE (Potts+ESM2) shows impressively high log fitness and evolutionary density, however. CMA-ES sampler had inconsistent performance across the three proteins—it finds variants with high numbers of mutations (
mutation per variant) and higher fitness. The 100th percentile performance of PPDE (Potts+ESM2) shows impressively high log fitness and evolutionary density, however. CMA-ES sampler had inconsistent performance across the three proteins—it finds variants with high numbers of mutations ( ) but low evolutionary density scores (3.47 on PABP, −94.76 on UBE4B and −62.43 on GFP compared to 6.92, −4.79, and −5.98 for PPDE (Potts)). It finds just one protein variant for PABP that is 17 mutations from WT with an evolutionary density score of 3.47, and it seems to have significant difficulty with the larger proteins UBE4B and GFP; e.g. on GFP the average 50th percentile log fitness is −2.50 compared to −0.04 for PPDE. We conclude that CMA-ES can be recommended for use only when a single protein variant is desired and the length of the protein is relatively small (e.g.
) but low evolutionary density scores (3.47 on PABP, −94.76 on UBE4B and −62.43 on GFP compared to 6.92, −4.79, and −5.98 for PPDE (Potts)). It finds just one protein variant for PABP that is 17 mutations from WT with an evolutionary density score of 3.47, and it seems to have significant difficulty with the larger proteins UBE4B and GFP; e.g. on GFP the average 50th percentile log fitness is −2.50 compared to −0.04 for PPDE. We conclude that CMA-ES can be recommended for use only when a single protein variant is desired and the length of the protein is relatively small (e.g.  95 residues).
95 residues).
Log fitness  (Augmented EVmutation) (Augmented EVmutation) | Evolutionary density  (MSA Transformer) (MSA Transformer) | Exploration (mean±std # muts) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Potts expert | PABP | UBE4B | GFP | PABP | UBE4B | GFP | PABP | UBE4B | GFP |
| PPDE | 0.27(0.86) | 0.39(1.18) | −0.04(0.24) | 6.92(13.43) | −4.79(−2.14) | −5.98(−0.76) | 3.5 ± 0.9 | 2.7 ± 0.6 | 2.0 ± 0.3 |
| Random search | 0.09(0.82) | −0.19(0.34) | −0.04(0.04) | 4.26(6.87) | −1.09(2.46) | −0.11(−0.11) | 1.3 ± 0.5 | 1.1 ± 0.3 | 1.0 ± 0.2 |
| Sim. annealing | 0.09(0.44) | −0.19(0.28) | −0.04(0.10) | 3.55(8.63) | −0.94(2.70) | −5.89(−0.99) | 1.3 ± 0.5 | 1.0 ± 0.2 | 1.0 ± 0.1 |
| MALA−approx | 0.09(0.56) | −0.19(0.58) | −0.04(0.10) | 2.25(5.14) | −0.89(1.54) | −6.74(−1.88) | 1.3 ± 0.5 | 1.03 ± 0.2 | 1.03 ± 0.2 |
| CMA−ES | 1.37(1.37) | 2.54(2.54) | −2.50(−0.15) | 3.47(3.47) | −94.76(0.0) | −62.43(0.0) | 17.0 ± 0 | 15.5 ± 6.2 | 10.2 ± 9.4 |
| Unsupervised expert | |||||||||
| Potts only | 0.70(1.47) | 0.12(0.99) | −0.18(0.21) | 9.17(18.54) | −4.24(−2.68) | −1.88(−1.59) | 4.7 ± 1.2 | 2.6 ± 0.5 | 1.2 ± 0.4 |
| Supervised only | 0.14(0.44) | 1.66(5.26) | −0.23(0.14) | −2.56(0.48) | −6.83(−6.29) | −9.28(−2.13) | 1.9 ± 0.8 | 1.3 ± 0.7 | 1.7 ± 0.8 |
| ESM2 | 0.14(0.63) | 1.66(5.56) | −5.55(0.16) | −2.38(5.56) | −6.58(−3.83) | −126.82(5.90) | 2.9 ± 1.3 | 2.2 ± 2.2 | 14.9 ± 12.6 |
| Potts+ESM2 | 0.44(1.48) | 1.30(3.33) | −0.04(0.33) | 9.12(19.34) | −13.6(1.98) | −7.17(8.11) | 5.3 ± 1.8 | 4.3 ± 0.7 | 2.1 ± 0.3 |
Diversity: Across all three proteins, PPDE-based samplers achieve the best diversity (highest percentage of unique variants), implying superior exploration of good optima around the WT protein.
Evolutionary density, log fitness, and mutation counts: Out of the samplers using the Potts unsupervised expert, PPDE (Potts) discovers variants with higher log fitness and average number of mutations than random search, simulated annealing, and MALA-approx
. In terms of evolutionary density, PPDE (Potts) achieves the highest scores on PABP, and on the more challenging UBE4B and GFP proteins, we suspect that the slightly lower 80th percentile evolutionary density scores compared to the baselines (except for CMA-ES, which scored poorly) are in part due to PPDE discovering variants with higher average mutations ( mutations vs.
mutations vs.  mutation for the baselines) and higher log fitness. We found that the CMA-ES sampler had inconsistent performance across the three proteins. Among samplers using the Potts unsupervised expert, it achieves the highest fitness scores on two proteins (PABP and UBE4B), but does so with diversity scores of 0.8% and 3.1% compared to 85.2% and 12.5% for PPDE (Potts) (table 1). CMA-ES finds variants with high numbers of mutations (
mutation for the baselines) and higher log fitness. We found that the CMA-ES sampler had inconsistent performance across the three proteins. Among samplers using the Potts unsupervised expert, it achieves the highest fitness scores on two proteins (PABP and UBE4B), but does so with diversity scores of 0.8% and 3.1% compared to 85.2% and 12.5% for PPDE (Potts) (table 1). CMA-ES finds variants with high numbers of mutations ( ) but low evolutionary density scores (50th percentile scores of 3.47 on PABP, −94.76 on UBE4B and −62.43 on GFP compared to 6.92, −4.79, and −5.98 for PPDE; see table 2). It finds just one protein variant for PABP that is 17 mutations from WT with an evolutionary density score of 3.47, and it seems to have significant difficulty with the larger proteins UBE4B and GFP; e.g. on GFP the average 50th percentile log fitness is −2.50 compared to −0.04 for PPDE. Figure 5 shows sampler trajectories, with which we see that across all three proteins, PPDE is the superior approach for efficiently sampling from the high-dimensional discrete product of experts distributions. We see here again that CMA-ES performs worse as the protein sequence length and fitness landscape complexity increases. It appears that a major limitation of CMA-ES is its continuous relaxation, which projects each sequence in the population to a variant far from the WT. For GFP, the population average product of experts probability starts and stays around
) but low evolutionary density scores (50th percentile scores of 3.47 on PABP, −94.76 on UBE4B and −62.43 on GFP compared to 6.92, −4.79, and −5.98 for PPDE; see table 2). It finds just one protein variant for PABP that is 17 mutations from WT with an evolutionary density score of 3.47, and it seems to have significant difficulty with the larger proteins UBE4B and GFP; e.g. on GFP the average 50th percentile log fitness is −2.50 compared to −0.04 for PPDE. Figure 5 shows sampler trajectories, with which we see that across all three proteins, PPDE is the superior approach for efficiently sampling from the high-dimensional discrete product of experts distributions. We see here again that CMA-ES performs worse as the protein sequence length and fitness landscape complexity increases. It appears that a major limitation of CMA-ES is its continuous relaxation, which projects each sequence in the population to a variant far from the WT. For GFP, the population average product of experts probability starts and stays around  . We conclude that CMA-ES can be recommended for use only when a single protein variant is desired and the length of the protein is relatively small (e.g.
. We conclude that CMA-ES can be recommended for use only when a single protein variant is desired and the length of the protein is relatively small (e.g.  95 residues).
95 residues).

Figure 5. PPDE is most efficient at finding good optima of the high-dimensional product of experts. Cumulative maximum product of experts log probability averaged across the population (higher is better). All samplers use the same product of experts target distribution with Potts unsupervised expert (other unsupervised experts not shown for clarity of presentation). CMA-ES is not visible in (c) because the optimization starts and remains around  .
.
Download figure:
Standard image High-resolution imageSwapping unsupervised experts: Without using an unsupervised expert, PPDE discovers variants with worse evolutionary density scores than even random sampling, confirming our observations from the previous MNIST-Sum experiment that supervised experts alone are susceptible to adversarial inputs. We also examined PPDE without any supervised expert (PPDE (Potts only)) by setting λ = 0. The observation that PPDE (Potts only) achieves a higher log fitness on PABP and only slightly worse log fitness on UBE4B than PPDE (Potts) is not surprising, as recent evidence suggests unsupervised evolutionary density scores are (at least moderately) predictive of mutation effects (Meier et al 2021, Hsu et al 2022, Weinstein et al 2022). However, the sampler performance degrades significantly by all metrics on GFP. When using the ESM2 unsupervised expert, PPDE discovers variants with lower evolutionary density scores than when using the Potts. This is not altogether unexpected since the MSA Transformer, which is used to score the variants, is conditioned on the same MSA as used to fit the Potts model. Although, this result also suggests that using unsupervised experts fit to aligned sequences is more promising for ML-based directed evolution. We observe a promising compositional effect from combining unsupervised experts trained on unaligned sequences (ESM2) and aligned sequences (Potts); e.g. across all three proteins the PPDE (Potts+ESM2) sampler achieves higher 100th percentile fitness and density scores than when using the Potts or ESM2 experts alone, and increases the diversity and average number of mutations as well.
5.2.2. Qualitative results
We provide a qualitative analysis of the mutations discovered by the supervised only, simulated annealing, PPDE (Potts) and PPDE (Potts+ESM2) samplers in figure 6. Many of the variants found by PPDE tend to have the same 1–3 'highly plausible' mutations in addition to a few 'rare' mutations that show up in variants at a much lower rate.

Figure 6. Visualization of mutation site frequency. Best viewed in color and zoomed in. The marginal frequency of a mutation site is the fraction of protein variants in the population with a mutation at a particular sequence position. We visualize site frequencies as a heatmap on the 3D structure of the WT protein. For example, nearly 100% of UBE4B variants discovered by PPDE (Potts+ESM2) have a mutation at position 1145. We annotate only a few high frequency sequence positions per protein for clarity; many sequence positions with a low frequency are not annotated.
Download figure:
Standard image High-resolution image5.2.3. Comparing protein language model experts
Figure 7 highlights the ability of PPDE to successfully sample from the 35 M, 150 M, and 650 M parameter ESM2 language models without any extra fine-tuning or re-training. This flexibility makes it easy to leverage continued improvement in protein language models, or use language models fine-tuned for specific protein families. As the number of ESM2 parameters increase, we observe a trend where variants with higher predicted activity and marginally higher evolutionary density are discovered. A similar observation in Nijkamp et al (2022) also suggests that model size positively correlates with zero-shot fitness prediction on wide fitness landscapes. When directly comparing supervised only and PPDE (Potts), we can see a large improvement in evolutionary density when the Potts expert is used. ESM2, which is trained on unaligned proteins, achieves lower evolutionary density scores than the Potts, suggesting it acts as a much softer search constraint. Combining the Potts and ESM2 experts results in improving the top percentile of discovered variants compared to those found by using the Potts or ESM2 experts alone.

Figure 7. Swapping in different protein language model experts. Full populations (128 variants) colored by log fitness with the median evolutionary density annotated. We swap out different unsupervised experts for the in silico directed evolution of UBE4B using the same supervised expert. This includes a 650 M parameter protein language model (ESM2-650 M). Combining unsupervised experts trained on aligned and unaligned sequences (Potts+ESM2-150 M) discovers variants with highest density and higher predicted fitness than WT (arrow).
Download figure:
Standard image High-resolution image5.2.4. Path length sensitivity analysis
PPDE's proposal distribution samples a path of  single substitutions at each sampler step to rapidly navigate through protein space. We conducted a sensitivity analysis on the maximum path length U, where
single substitutions at each sampler step to rapidly navigate through protein space. We conducted a sensitivity analysis on the maximum path length U, where  and
and  (figure 8(c)) on the UBE4B protein. In this experiment, we found that path lengths longer than 3 did not significantly improve sampler efficiency. This is possibly because we already have a good initialization for the sampler (the WT) and short path lengths are sufficient for discovering high quality variants. It is also possible that, in our setting, the accumulation of errors from the first order Taylor approximation along a long path leads to worse sampler efficiency despite better exploration. Moreover, using a longer path length leads to discovering variants with a higher number of mutations, whose activity could be inaccurately characterized by the supervised experts.
(figure 8(c)) on the UBE4B protein. In this experiment, we found that path lengths longer than 3 did not significantly improve sampler efficiency. This is possibly because we already have a good initialization for the sampler (the WT) and short path lengths are sufficient for discovering high quality variants. It is also possible that, in our setting, the accumulation of errors from the first order Taylor approximation along a long path leads to worse sampler efficiency despite better exploration. Moreover, using a longer path length leads to discovering variants with a higher number of mutations, whose activity could be inaccurately characterized by the supervised experts.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 8. Wall clock run time comparisons using the Potts (a) and ESM2 (b) unsupervised experts. Run times are averaged over seven trials using the PABP protein, 1 K sampler steps, and a population of size 16. (c) Comparing PPDE on UBE4B with various max path lengths  where
where  .
.
Download figure:
Standard image High-resolution image{kind=link}
5.2.5. Run time comparison
We compare wall clock run times for PPDE and the baseline samplers under the Potts (figure 8(a)) and ESM2 (figure 8(b)) experts using the PABP protein, 1 K sampler steps, and a population size of 16 variants. Samplers are run on a single NVIDIA Tesla cloud GPU; see appendix for complete hardware details. CMA-ES is significantly slower than the other samplers. When using the Potts expert, PPDE's run time is relatively comparable to simulated annealing and MALA-approx . The cost of computing the gradient of ESM2 is much higher than for the Potts model, so in this setting simulated annealing (which does not use gradients) has lower run time than MALA-approx and PPDE.
6. Limitations
In this section, we discuss limitations of the proposed sampling method related to computational costs and handling insertion/deletion mutations.
Each step of the PPDE sampler requires two backwards passes—one for computing the forward proposal and one for the reverse proposal. When PPDE is used with a large protein language model whose backwards pass has a large memory footprint, this becomes a bottleneck if sufficient computing resources are unavailable. Fortunately, MCMC samplers are embarrassingly parallel. For example, with a budget of K available GPUs, we can evolve a single protein per GPU in parallel.
The wall-clock time incurred by running PPDE depends on the ability to rapidly evaluate and differentiate through the product of experts distribution. For certain classes of unsupervised experts, this is difficult. For example, evaluating the log probability of a protein with a variational autoencoder (e.g. DeepSequence (Riesselman et al 2018)) requires computing a large-sample Monte Carlo estimate of the evidence lower bound, which is highly computationally expensive.
PPDE also does not currently support inserting and deleting amino acids (indels). We necessarily assume the product of experts is locally smooth in a neighborhood around the current protein to compute our proposal distribution for MCMC. This assumption would need to still hold despite proposing length changes to the sequence. While we do not believe lack of support for indels is a fundamental limitation of the sampler, supporting indel mutations appears to be nontrivial.
7. Conclusions
In this study, we have shown how to flexibly combine unsupervised models of evolutionary density, including protein language models, and supervised models of protein function and how to efficiently sample from the resulting distribution to discover proteins that maximize a desired function while avoiding poor local optima. This strategy leverages the vast amounts of unlabeled data that are available for unsupervised (or self-supervised) pre-training to improve designed sequences, even when relatively few labelled data are available for training the fitness function. Our empirical results suggest our framework offers a practical and effective new paradigm for machine-learning-based directed evolution. Although our framework can potentially be applied to a broader range of biological sequence design tasks, we focused solely on proteins due to the variety of available pre-trained models.
Based on our findings, we recommend constructing the product of experts distribution with unsupervised experts that have been pre-trained on aligned protein sequences (e.g. MSAs) when available. We found that these models more strongly constrain search to the evolutionarily plausible mutations than unsupervised models pre-trained on unaligned protein sequences. However, combining unsupervised models of both types produced designs superior to using one or the other alone.
One important capability that we did not demonstrate is the incorporation of additional hard constraints, such as a maximum allowable number of mutations per variant or the preservation of particular regions of the WT sequence. In our framework, we can easily accomplish this by forcing the mutation proposal probabilities at the sequence positions in question to zero, which can be done by setting their logits to negative infinity in the softmax in Algorithm 1. Future work may also extend this framework to larger problems in biological design. For instance, the simultaneous engineering of several sequences in multimeric enzyme complexes, or incorporating substrate structure in evaluating the likelihood of enzyme-substrate complexes.
Acknowledgments
This work was authored by the National Renewable Energy Laboratory, operated by Alliance for Sustainable Energy, LLC, for the U.S. Department of Energy (DOE) under Contract No. DE-AC36-08GO28308. Funding provided by the U.S. Department of Energy Bioenergy Technologies Office and the Laboratory Directed Research and Development (LDRD) Program at NREL. The views expressed in the article do not necessarily represent the views of the DOE or the U.S. Government. The U.S. Government retains and the publisher, by accepting the article for publication, acknowledges that the U.S. Government retains a nonexclusive, paid-up, irrevocable, worldwide license to publish or reproduce the published form of this work, or allow others to do so, for U.S. Government purposes. This research used resources of the Oak Ridge Leadership Computing Facility at the Oak Ridge National Laboratory, which is supported by the Office of Science of the U.S. Department of Energy under Contract No. DE-AC05-00OR22725.
Data availability statement
The data that support the findings of this study are openly available at the following URL/DOI: https://github.com/pemami4911/ppde.
Appendix A: Deriving the gradient-based approximate proposal
We provide a short derivation that illustrates how to obtain a gradient-based approximate locally-balanced informed proposal (equation (2)) from the locally-balanced informed proposal of equation (1). The goal is to avoid evaluating  for all
for all  when computing the proposal distribution
when computing the proposal distribution  . The basic idea from Grathwohl et al (2021) is to assume that f is a continuously differentiable function, which allows us to approximate
. The basic idea from Grathwohl et al (2021) is to assume that f is a continuously differentiable function, which allows us to approximate  with a first-order Taylor series.
with a first-order Taylor series.
In detail, the first-order Taylor series of the function f(x) at the point a is

By subtracting f(a) from both sides, we get

To arrive at the gradient-based proposal, suppose a is the current state of our MCMC sampler and let x be any point in the neighborhood of a,  . When we plug in our first-order approximation,
. When we plug in our first-order approximation,

Appendix B: Proof of corollary 1
The basic idea of the proof is to use the triangle inequality to obtain a bound on the approximation error of a sum of experts which assumes that each expert has sufficiently smooth gradients. Definition.
definition A function  has K-Lipschitz continuous gradient when
has K-Lipschitz continuous gradient when

for all  .
.
For convenience, we reproduce a pertinent result here from Nesterov (1998) (Lemma 1.2.3). Lemma 1.2.3.
lemma Nesterov (1998) If
 has an L-Lipschitz gradient, then for any
has an L-Lipschitz gradient, then for any
 we have:
we have:

Lemma B.1.
lemma For functions f and g with Kf
-Lipschitz and Kg
-Lipschitz gradients respectively, the sum-composition  has
has  -Lipschitz gradient.
-Lipschitz gradient.
proof By the triangle inequality:

Lemma B.2.
lemma Suppose fi
,  are functions with Ki
-Lipschitz gradient. Then for any
are functions with Ki
-Lipschitz gradient. Then for any  we have
we have

Proof.
proof Let  where each fi
,
where each fi
,  has Ki
-Lipschitz gradient. By lemma B.1 we can see that g has a
has Ki
-Lipschitz gradient. By lemma B.1 we can see that g has a  -Lipschitz gradient. Then lemma B.2 follows immediately by applying lemma 1.2.3 from Nesterov (1998) to g.
-Lipschitz gradient. Then lemma B.2 follows immediately by applying lemma 1.2.3 from Nesterov (1998) to g.
The proof of corollary 1 proceeds by bounding the approximation error between two consecutive states  and
and  in a path of length
in a path of length  . For simplicity we assume
. For simplicity we assume  is the 1-Hamming ball, i.e.
is the 1-Hamming ball, i.e.  .
.
For  which has
which has  -Lipschitz gradient, lemma 2 gives us that
-Lipschitz gradient, lemma 2 gives us that

Then an upper bound for  is
is

Following similar steps, we also have

The remainder of the proof for corollary 1 exactly follows equations 64–72 in the proof of theorem 3 in Sun et al (2022b) with g(x) which has K-Lipschitz gradient.
Appendix C: Experiment details
C.1. Neural architectures
MNIST DAE: The encoder and decoder neural networks are constructed out of residual blocks, where a single block has two 3 × 3 2D Conv layers, each followed by a BatchNorm layer and Swish activation. The first Conv layer in the block uses a stride of 2 and a 1 × 1 shortcut Conv layer is added to its output. The encoder consists of one 3 × 3 2D Conv layer, followed by two blocks, then another 3 × 3 2D Conv layer, followed by a fully connected layer that projects the flattened output features into a 16-dimensional latent space. The encoder and decoder are symmetric, and the decoder is implemented with transposed Conv layers and the per-pixel output is interpreted as the logits of a Bernoulli distribution. All Conv layers use 64 channels. To train the DAE, we corrupt the input  binary MNIST image by randomly flipping p% of the pixels, where
binary MNIST image by randomly flipping p% of the pixels, where  Unif(0,15), and minimize the reconstruction error. We use the AdamW optimizer with a learning rate of
Unif(0,15), and minimize the reconstruction error. We use the AdamW optimizer with a learning rate of  to train the model for 10 K steps using a mini-batch size of 100.
to train the model for 10 K steps using a mini-batch size of 100.
MNIST EBM: This model follows the residual EBM architecture from Grathwohl et al (2021) closely. The model consists of one 3 × 3 2D Conv layer, followed by two residual blocks (the same blocks used by the DAE), and then an additional six residual blocks with all Conv layers using a stride of 1. The output features are flattened with global average pooling and then mapped to a scalar with a fully connected layer. See Grathwohl et al (2021) for details about the contrastive divergence training algorithm and training hyperparameters.
Protein ConvNet: We use the ConvNet baseline from the FLIP benchmark (Dallago et al
2021) to regress activity. This model takes in a mini-batch of one-hot encoded protein sequences of shape  , applies a 1D Conv with kernel size 5 and ReLU activation to project V to dimension L, followed by a fully connected layer to expand the feature dimension to 2 L. Then, max pooling is used to reduce the length of the sequence to 1, and a linear layer projects the feature dimension from 2 L to 1. The model is trained with AdamW optimizer with a learning rate of
, applies a 1D Conv with kernel size 5 and ReLU activation to project V to dimension L, followed by a fully connected layer to expand the feature dimension to 2 L. Then, max pooling is used to reduce the length of the sequence to 1, and a linear layer projects the feature dimension from 2 L to 1. The model is trained with AdamW optimizer with a learning rate of  using a mini-batch size of 256.
using a mini-batch size of 256.
C.2. Unsupervised expert score functions
We provide details for computing  with each type of unsupervised expert.
with each type of unsupervised expert.
MNIST DAE: For a given image x, we define f(x) to be the sum of the binary cross entropy between the input pixel and the predicted pixel logits over all pixel locations.
MNIST EBM: We use the scalar output as f(x), since it can be interpreted as an unnormalized log probability for the input. This only requires a single forward pass to compute.
Protein EVmutation Potts: We use the difference in the Potts Hamiltonian between the protein variant x and the WT such that  . The Hamiltonian for a one-hot protein x is defined as
. The Hamiltonian for a one-hot protein x is defined as

where  and
and  are the Potts parameters.
are the Potts parameters.
Protein ESM2: We use the difference in the sum of the per-amino-acid log probabilities between the protein variant x and the WT for f(x). For computational efficiency, we compute the score with a single forward pass and therefore do not use any masking of input sequence positions. In detail, for a one-hot protein x let  be the L × V matrix of logits computed by a single unmasked forward pass of ESM2. Then the score is
be the L × V matrix of logits computed by a single unmasked forward pass of ESM2. Then the score is

C.3. Hardware details
We ran our experiments on the Summit supercomputer on a single NVIDIA V100 GPU. When running with ESM2, we speed up the sampler by parallelizing the population of 128 proteins across multiple GPUs. For example, we ran each of the 128 MCMC trajectories on a separate GPU in parallel when we used the 650 M parameter ESM2 model. Wall clock run time measurements were taken after-the-fact using a single NVIDIA Tesla T4 GPU available via the Google Colab free tier.
C.4. Aligning the amino acid vocabulary across models
Not all pre-trained protein sequence models order the amino acids in their vocabulary in the same way. Also, some models, such as masked language models, have extra tokens such as <mask> beyond the standard 20 amino acids. To enable combining a diverse array of models, we first decide on a canonical ordering for the standard amino acids. For any pre-trained model that uses a different ordering than the canonical one, we pre-compute a permutation matrix that, when applied to the columns of the one-hot encoded protein x, will put the amino acids in the order which the model expects. We also pad the permuted x with extra columns of zeros if the pre-trained model has a vocabulary larger than 20.