
Abstract
Linear optical elements are pivotal instruments in the manipulation of classical and quantum states of light. Recent progress in integrated quantum photonic technology enabled the implementation of large numbers of such elements on chip, in particular passively stable interferometers. However, it is a challenge to characterize the optical transformation of such a device as the individual optical elements are not directly accessible. Thus only an effective overall transformation can be recovered. Here we present a reconstruction approach based on a global optimization of element parameters and compare it to two prominently used approaches. We numerically evaluate their performance for networks up to 14 modes and various levels of error on the primary data.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Linear optical quantum computing has attracted major attention since Knill, Laflamme and Milburn have introduced a scheme for efficient quantum computation in 2001 [1]. Notwithstanding tremendous technological progress, the experimental realization of such computers is still challenging with steep requirements for the generation, manipulation and detection of the quantum states of light. In the last decade, integrated quantum photonics [2] has become central to the technological progress by providing the means to miniaturize and mass fabricate vital components, such as quantum light sources [3–6], quantum storage devices [7, 8] and highly efficient photon detection on chip [9–12]. Of particular importance is the manipulation of the quantum states of light via linear optical networks (LONs). Here, integrated quantum photonics enabled the fabrication of LONs with unprecedented levels of interferometric complexity. The inventory includes optical elements, facilitating either fixed [13–17] or tunable [18–21] single-qubit transformations but also novel hybride elements [22]. Arranging several of these elements allows fabrication of miniaturized versions of logic gates which are essential in quantum information processing. Those gates resemble small to medium scale interferometers and are either tailored to perform a particular task or can be reconfigured for a variety of tasks [13, 15, 20, 21]. Here, the physical encoding scheme, e.g. a dual-rail polarization encoding, determines how these gates, unitary matrices acting on logical qubits, must be compiled from different optical elements. Hence, the overall transformations of these LONs are required to be unitary, too. This poses a challenge for experimental realizations which are inevitably afflicted by imperfections. Here, the major contributors are on one hand losses, which render these devices non-norm preserving. On the other hand fabrication imperfections stemming from the production itself cause deviations between an initially targeted transformation and the implemented one. Obtaining precise knowledge of an optical transformation at hand therefore is important and serves multiple purposes: it allows theoretical modeling of an experiment and allocation of the error budget to different sources of error. More important, identifying deviations or even defective optical elements is essential for troubleshooting experiments and improving future versions of an optical circuit. The ability to construct high-fidelity gate operations becomes a stringent requirement when circuits are scaled up beyond proof of principle implementations [23]. Since all waveguides are embedded into a bulk material, only the input and output ports and therefore the overall transformation is directly accessible. To acquire knowledge of such an overall transformation one can use different approaches relying on quantum resources [24–28] or classical resources [29–32]. The majority of these techniques fall in the category of quantum process tomography ('QPT'). While QPT is well established in quantum science, it faces challenges when applied to large networks due to quickly growing resource costs. Alternative techniques, reconstructing a transition matrix [31] or a unitary matrix description [28] of a LON, became prominent in the context of Boson sampling [33–37]. These methods scale more favorably with respect to the required measurements when compared to QPT, and reconstruct matrix descriptions of LONs omitting global phases at the input and output ports. Methods which rely on light that is scattered out of the LON are not further considered as the technique relies on loss that compromises the guiding properties of the whole structure [35].
Here, we present a new approach to characterize the transformation implemented by LONs. We choose to enforce unitarity from the start by parametrizing the LONs as interferometers composed of beam splitters and phase shifters [38]. The reconstructed unitary matrices are then obtained by optimizing the beam splitting ratios and phase shifts to best explain a set of data sensed via probe states injected into the network. We utilize a data set composed of two-photon interference visibilities [39], rendering the procedure insensitive to input and output loss. In this way both afore mentioned purposes of network reconstruction are fulfilled simultaneously; generating a description to model experimental data and gathering knowledge about the transformation of individual optical elements. Our method is a departure from the strategy of related approaches [27, 31], which aim to reconstruct transition matrices, or do so in a first step [28, 40]. Whereas transition matrices are sufficient to characterize a LON and to model experimental results, they do not allow to identify deviations of individual elements directly. Here a indirect route via a polar decomposition [28, 40] and subsequent decomposition into individual elements must be chosen. The identification of faulty elements through a decomposition procedure requires LONs exhibiting a non-redundant layout, e.g. Reck et al type networks.
2. Different approaches to reconstruction
In the following we will compare three approaches to LON characterization. 'Brisbane' [31] and 'Bristol' [28]1 were chosen for their frequent usage in experiments relying on integrated LONs. Our approach, subsequently labeled 'Vienna', is formalizing ideas developed in [36, 41]. Similar to [40, 42], an over-complete set of primary data can be used to increase reconstruction fidelities, although we find the effect to be minor (see figure 2). In the following, primary data is referring to data sensed for reconstruction purposes in any of the approaches.

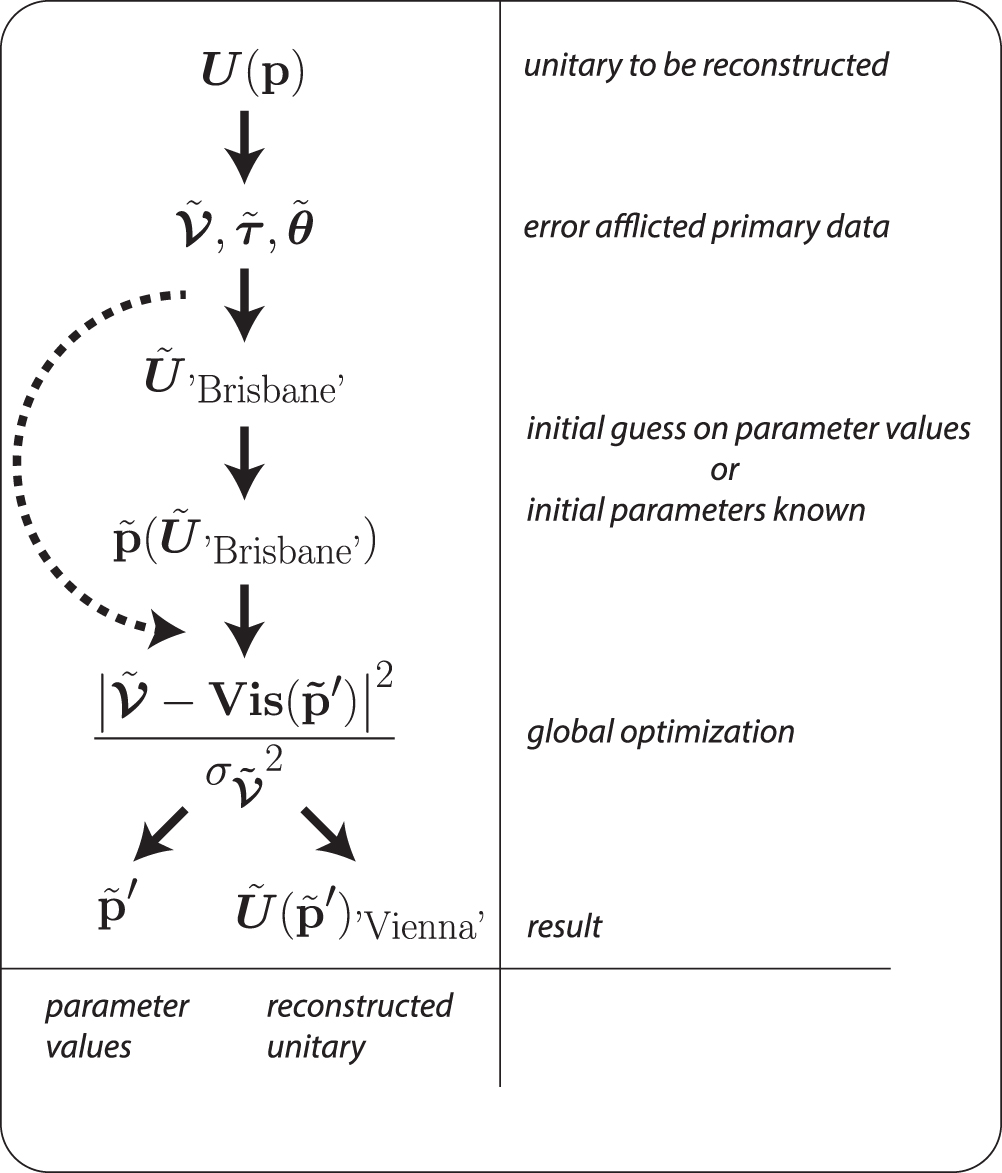
Figure 1. Flowchart for 'Vienna'. Primary data  from a LON described by the unitary matrix
from a LON described by the unitary matrix  is measured. In general this data will be error afflicted denoted by the tilde. The layout and initial parameters
is measured. In general this data will be error afflicted denoted by the tilde. The layout and initial parameters  are either known from fabrication (dashed arrow) or are obtained by a reconstruction step, e.g. 'Brisbane'. These initial parameters are now subjected to a global optimization using an, in the best case over-complete, set of primary data. Here the output yields both, the reconstructed unitary
are either known from fabrication (dashed arrow) or are obtained by a reconstruction step, e.g. 'Brisbane'. These initial parameters are now subjected to a global optimization using an, in the best case over-complete, set of primary data. Here the output yields both, the reconstructed unitary  and the parameters of the individual building blocks
and the parameters of the individual building blocks  .
.
Download figure:
Standard image High-resolution image
Figure 2. Comparison of the reconstruction performance obtained with the different approaches, 'Vienna', 'Brisbane', and 'Bristol'. 'Vienna reduced' denotes a variant of 'Vienna' utilizing a smaller set of primary data (see appendix  . (a) and (b) Intersect, indicated by the dashed gray boxes.
. (a) and (b) Intersect, indicated by the dashed gray boxes.
Download figure:
Standard image High-resolution imageThe three compared approaches differ in their strategy to characterize a LON. 'Bristol' and 'Brisbane' first reconstruct the individual matrix entries of a scattering description and then require a polar decomposition step to recover the closest unitary matrix. Both utilize a sufficient set of data for this purpose and in the following we refer to this strategy as a passive approach. In contrast 'Vienna' follows an active approach utilizing a larger set of primary data in a global optimization routine which already implements the unitary constrains from the beginning.
The approach 'Brisbane' aims to reconstruct a description of a black-box linear optical network from a sufficient set of primary data generated with coherent probe states. This data is then mapped one to one unto a scattering matrix representation  without the need to apply any further algorithms. The scattering matrix
without the need to apply any further algorithms. The scattering matrix  represents a submatrix of a larger unitary matrix
represents a submatrix of a larger unitary matrix  , where the additional modes of
, where the additional modes of  correspond to loss modes. Hence, the task of loss modeling translates to the task of finding a loss matrix that couples the interferometer modes of
correspond to loss modes. Hence, the task of loss modeling translates to the task of finding a loss matrix that couples the interferometer modes of  to the loss modes of
to the loss modes of  . This necessarily includes input and output loss terms, as the approach processes transition amplitude data. 'Brisbane' covers the case of mode-dependent input loss in the following way: the loss term for each input mode k is directly given by the ratio between the total power exiting the LON and the power injected into mode k. Subsequently the input loss is modelled by virtual beam splitters, where the square root of the loss terms corresponds to the transmittivity of the virtual beam splitters. Note that such a loss modeling works only in the case when the mode-dependent output loss of the network is zero. In general, loss inside a network cannot be parametrized this way and thus it remains unclear how a more evolved loss modeling can be included in 'Brisbane'. Hence, only a partially loss modeling scattering description
. This necessarily includes input and output loss terms, as the approach processes transition amplitude data. 'Brisbane' covers the case of mode-dependent input loss in the following way: the loss term for each input mode k is directly given by the ratio between the total power exiting the LON and the power injected into mode k. Subsequently the input loss is modelled by virtual beam splitters, where the square root of the loss terms corresponds to the transmittivity of the virtual beam splitters. Note that such a loss modeling works only in the case when the mode-dependent output loss of the network is zero. In general, loss inside a network cannot be parametrized this way and thus it remains unclear how a more evolved loss modeling can be included in 'Brisbane'. Hence, only a partially loss modeling scattering description  , which is closer to the unitary description
, which is closer to the unitary description  than the matrix
than the matrix  , can be found via this method.
, can be found via this method.
Experimental environments exhibiting loss as detailed above cause  to be noticeably non-unitary and necessitate a polar decomposition if the closest unitary description
to be noticeably non-unitary and necessitate a polar decomposition if the closest unitary description  is to be obtained. This polar decomposition can introduce further error dependent on the size of the interferometer under test [43].
is to be obtained. This polar decomposition can introduce further error dependent on the size of the interferometer under test [43].
Up to the deviations introduced by the polar decomposition the entries of  reconstructed via this procedure are identical to the primary data generated. This self-consistency proves to be challenging when assessing the fidelity and the uncertainty of a reconstructed matrix in the presence of measurement errors. The complete set of single-input data and phase data is already used to fix the real entries and phases of
reconstructed via this procedure are identical to the primary data generated. This self-consistency proves to be challenging when assessing the fidelity and the uncertainty of a reconstructed matrix in the presence of measurement errors. The complete set of single-input data and phase data is already used to fix the real entries and phases of  . To obtain realistic error estimations for the individual entries of
. To obtain realistic error estimations for the individual entries of  or
or  , the various error sources need to be studied in detail, including calibration uncertainty of the detector efficiencies and uncertainties introduced by fiber mating and coupling to a waveguide. Opposed to more complex algorithmic approaches like 'Bristol' or 'Vienna', the sensed data cannot be used to generate a quantifier for reconstruction success. An additional set of data generated by different means than coherent states is required for this purpose, e.g. a set of two-photon interference visibilities as done in [31].
, the various error sources need to be studied in detail, including calibration uncertainty of the detector efficiencies and uncertainties introduced by fiber mating and coupling to a waveguide. Opposed to more complex algorithmic approaches like 'Bristol' or 'Vienna', the sensed data cannot be used to generate a quantifier for reconstruction success. An additional set of data generated by different means than coherent states is required for this purpose, e.g. a set of two-photon interference visibilities as done in [31].
The approach 'Bristol' aims to reconstruct a unitary description of a black-box linear optical network from a set of primary data, which in this case is generated via quantum probe states. The magnitude of each phase is sensed via a visibility of a non-classical two-photon interference but the sign of the phase needs to be calculated in relation to the other phases such that unitary constraints are obeyed. Note that a phase sensed this way is not a direct phase measurement like in the approach 'Brisbane'. Furthermore the visibility of each non-classical interference is also modified by the four contributing real entries  of the scattering matrix, with j and k labeling the output and input modes, respectively. These transition amplitudes are calculated in a fashion insensitive to mode-dependent input and output loss: the loss terms drop out by relating all input and output single-photon count rates to each other. Therefore each entry of the reconstructed matrix,
of the scattering matrix, with j and k labeling the output and input modes, respectively. These transition amplitudes are calculated in a fashion insensitive to mode-dependent input and output loss: the loss terms drop out by relating all input and output single-photon count rates to each other. Therefore each entry of the reconstructed matrix,  , becomes dependent on the whole set of primary data. All
, becomes dependent on the whole set of primary data. All  and
and  are recovered by solving a linear system of nonlinear equations. Again the closest unitary matrix,
are recovered by solving a linear system of nonlinear equations. Again the closest unitary matrix,  , can be found by applying a polar decomposition. Whereas the method is insensitive to loss at the input and output ports of a LON, it is sensitive to mode-dependent propagation loss. The latter introduces systematic error in the algorithm, already before applying the polar decomposition. (Further detail on the influence of mode-dependent propagation loss for all three reconstruction approaches is given in appendix
, can be found by applying a polar decomposition. Whereas the method is insensitive to loss at the input and output ports of a LON, it is sensitive to mode-dependent propagation loss. The latter introduces systematic error in the algorithm, already before applying the polar decomposition. (Further detail on the influence of mode-dependent propagation loss for all three reconstruction approaches is given in appendix
Our new approach 'Vienna' aims to reconstruct the unitary matrix descriptions  of a LON via a global optimization of optical element parameters,
of a LON via a global optimization of optical element parameters,  , which is visualized in figure 1 as a flowchart. For purpose-built networks, e.g. quantum logic gates, the physical layout of the optical elements and their target parameters are defined by the encoding scheme and type of gate. If they are sufficiently precise, these target parameters can serve as initial guesses for
, which is visualized in figure 1 as a flowchart. For purpose-built networks, e.g. quantum logic gates, the physical layout of the optical elements and their target parameters are defined by the encoding scheme and type of gate. If they are sufficiently precise, these target parameters can serve as initial guesses for  and therefore as the starting parameters in the optimization routine. Black-box m × m LONs can be represented by an arrangement of
and therefore as the starting parameters in the optimization routine. Black-box m × m LONs can be represented by an arrangement of  beam splitters and
beam splitters and  phase shifters [38] (see the appendix for a sketch). In our approach it is sufficient to obtain just one representation of the physical network decomposed in such a way. However, without any knowledge of the starting values the minimization of the
phase shifters [38] (see the appendix for a sketch). In our approach it is sufficient to obtain just one representation of the physical network decomposed in such a way. However, without any knowledge of the starting values the minimization of the  -dimensional landscapes is prone to converge into some local minimum only. Hence the starting values need to be obtained by different means. Here we utilize one of the passive reconstruction approaches and find that the approach 'Brisbane' is better suited for this purpose than the approach 'Bristol'. Note that both approaches lead to reconstructed unitaries that are equivalent to the unitary decomposed via the Reck et al scheme modulo diagonal phase matrices. These diagonal phase matrices do not affect the extraction of the starting parameters [44]. To reconstruct
-dimensional landscapes is prone to converge into some local minimum only. Hence the starting values need to be obtained by different means. Here we utilize one of the passive reconstruction approaches and find that the approach 'Brisbane' is better suited for this purpose than the approach 'Bristol'. Note that both approaches lead to reconstructed unitaries that are equivalent to the unitary decomposed via the Reck et al scheme modulo diagonal phase matrices. These diagonal phase matrices do not affect the extraction of the starting parameters [44]. To reconstruct  a set of primary data,
a set of primary data,  , is recorded, where
, is recorded, where  denotes the full set of two-photon interference visibilities and
denotes the full set of two-photon interference visibilities and  and
and  denote the full set of normalized transition amplitudes and relative phases sensed via coherent states, respectively2
. This data will be in general error afflicted indicated by the tilde.
denote the full set of normalized transition amplitudes and relative phases sensed via coherent states, respectively2
. This data will be in general error afflicted indicated by the tilde.  are only used in the case of black-box networks to obtain the initial starting parameters for the global optimization. Finally, a global cost function using an over-complete set of two-photon interference visibilities,
are only used in the case of black-box networks to obtain the initial starting parameters for the global optimization. Finally, a global cost function using an over-complete set of two-photon interference visibilities,  , is minimized to obtain optimal reconstructed parameters
, is minimized to obtain optimal reconstructed parameters  . These automatically yield the reconstructed unitary
. These automatically yield the reconstructed unitary  . Optimizing a global cost function comes with an additional advantage: the minimum of that function can act as an direct estimator for the success of the reconstruction and is in our case identical to the
. Optimizing a global cost function comes with an additional advantage: the minimum of that function can act as an direct estimator for the success of the reconstruction and is in our case identical to the  [45], allowing further statistical interpretation. We choose to utilize just two-photon interference visibilities for the reconstruction of
[45], allowing further statistical interpretation. We choose to utilize just two-photon interference visibilities for the reconstruction of  . These visibilities are insensitive to input and output loss, thus
. These visibilities are insensitive to input and output loss, thus  represents a unitary description modulo loss matrices at the input and output. The parameters of these loss matrices can be easily recovered by using loss sensitive data such as transition amplitude data,
represents a unitary description modulo loss matrices at the input and output. The parameters of these loss matrices can be easily recovered by using loss sensitive data such as transition amplitude data,  , and solving a system of linear equations utilizing the reconstructed description
, and solving a system of linear equations utilizing the reconstructed description  .
.
3. Results
We compare the reconstruction results for the different approaches 'Brisbane', 'Bristol' and 'Vienna' numerically for fully coupled m × m networks in the presence of perturbance on the primary data. To quantify the performance of the different approaches the fidelity between the initially generated Haar-random unitary matrix,  , and the reconstructed unitary matrix
, and the reconstructed unitary matrix  is calculated. We consider m × m networks with
is calculated. We consider m × m networks with  , where μ labels the reconstruction approach and σ denotes the level of perturbance on the primary data (see appendix
, where μ labels the reconstruction approach and σ denotes the level of perturbance on the primary data (see appendix  . An average unitary description,
. An average unitary description,  , is obtained after 120 iterations with
, is obtained after 120 iterations with  denoting its standard deviation. We use the fidelity measure,
denoting its standard deviation. We use the fidelity measure,

which is normalized by the number of modes, m, such that it is insensitive to the network size. Here,  denotes the trace norm. For given
denotes the trace norm. For given  the resulting fidelity histograms are fitted with Weibull distributions centered around the most probable value,
the resulting fidelity histograms are fitted with Weibull distributions centered around the most probable value,  (see appendix
(see appendix  , the distances between the most probable fidelity and the two fidelities where the maximum probability decreased to
, the distances between the most probable fidelity and the two fidelities where the maximum probability decreased to  are used. The most probable fidelities and their respective uncertainties for 200 different combinations of network size and perturbance on the primary data are recovered for each of the reconstruction approaches. Figure 2 shows a representative example, once for 12 × 12 networks and variable error on the primary data, σ, and once for an error of
are used. The most probable fidelities and their respective uncertainties for 200 different combinations of network size and perturbance on the primary data are recovered for each of the reconstruction approaches. Figure 2 shows a representative example, once for 12 × 12 networks and variable error on the primary data, σ, and once for an error of  and variable network size. Clear differences between the approaches can be observed with respect to the overall performance, the scaling and the dispersive behavior. Such differences must be attributed to specifics of the reconstruction algorithms as all approaches reconstruct the same unitaries
and variable network size. Clear differences between the approaches can be observed with respect to the overall performance, the scaling and the dispersive behavior. Such differences must be attributed to specifics of the reconstruction algorithms as all approaches reconstruct the same unitaries  .
.
The approach 'Brisbane' shows high reconstruction fidelities with low dispersion which scale linearly with the error, σ, on the primary data (figure 2(a)). Here, an upper bound to the deviation of the reconstructed unitaries,  , from the initial one,
, from the initial one,  , in the Frobenius norm can be even given analytically:
, in the Frobenius norm can be even given analytically:

Where  and
and  denote the reconstructed matrix before applying a polar decomposition and its condition number, respectively. Hence the deviation,
denote the reconstructed matrix before applying a polar decomposition and its condition number, respectively. Hence the deviation,  , stems from the polar decomposition, which in turn is due to the errors of the primary data that contribute in first order approximation as
, stems from the polar decomposition, which in turn is due to the errors of the primary data that contribute in first order approximation as  , where
, where  . The data shown in figure 2(b) indicates, that the performance of the approach 'Brisbane' is only slightly affected by the network size.
. The data shown in figure 2(b) indicates, that the performance of the approach 'Brisbane' is only slightly affected by the network size.
The reconstruction fidelities yielded with the approach 'Bristol' are dominated by a (sub)exponential decay, both as a function of the error on the primary data and the network size. This also leads to a highly dispersive behavior which is reflected in the comparably large error bars in figure 2. While the exponential decay is already observed in the original publication [28], this just represents a phenomenological fit to the data. We conjecture that on one hand this scaling originates from the additional matrix inversion that has to be taken into account when the transition amplitudes are calculated. On the other hand, the primary data undergoes a more complex algebraic transformation, which, dependent on the noise of the primary data, can cause unfavourable amplification of perturbations.
Reconstructing the unitary description of unknown m × m networks via the approach 'Vienna' or 'Vienna reduced' works with highest fidelity and minimal uncertainty. Here, 'Vienna reduced' denotes a variant of 'Vienna' utilizing a smaller set of primary data (see appendix
4. Discussion
Precise knowledge about the optical transformation of LONs is a requirement for the validation of experimental results against theoretical predictions in numerous experiments [20, 46–48]. For this purpose, the optical transformations can be given either in terms of scattering descriptions or unitary transformations, where the latter allow a decomposition into individual building blocks. Hence the element parameters for each optical element in the LON can be obtained. From a technological point of view this is beneficial as it enables the localization of erroneous elements. Here we present a new approach, 'Vienna', and compare it to two prominently used approaches, 'Brisbane' and 'Bristol'. We investigate all approaches for the regime of zero mode-dependent loss and quantify the differences in reconstruction performance of unitary descriptions via an extensive numerical evaluation: more than 105 m × m black-box networks are sampled for distinct m from primary data exhibiting various levels of perturbance. The results substantiate that the direct implementation of the unitary constraints, as done in the approach 'Vienna', are of advantage for highest reconstruction fidelities. Two-photon interference visibilities play a unique role as they are a priori insensitive to input and output loss and allow to obtain over-complete sets of primary data, which are beneficial for highest reconstruction precision.
Acknowledgments
We acknowledge Valentin Stauber and Frank Verstraete for technical assistance with the numerical evaluation. The authors thank Borivoje Dakic and Si-Hui Tan for helpful discussions. CS acknowledges support from a DAAD Jahresstipendium. MT, CS, and PW acknowledge support from the European Commission with the project EQuaM—Emulators of Quantum Frustrated Magnetism (No. 323714), GRASP -Graphene-Based Single-Photon Nonlinear Optical Devices (No. 613024), PICQUE—Photonic Integrated Compound Quantum Encoding (No. 608062), and QUCHIP—Quantum Simulation on a Photonic Chip (No. 641039), the Vienna Center for Quantum Science and Technology (VCQ), and the Austrian Science Fund (FWF) with the projects PhoQuSi Photonic Quantum Simulators (Y585-N20) and the doctoral programme CoQuS Complex Quantum Systems, the Vienna Science and Technology Fund (WWTF) under Grant No. ICT12-041, and the Air Force Office of Scientific Research, Air Force Material Command, United States Air Force, under Grant No. FA9550-1-6-1-0004. The authors declare that they have no competing financial interests.
Appendix A. Numerical evaluation of the different approaches in the lossless case:
To quantify the performance of the different reconstruction approaches a fidelity between the initially generated Haar-random unitary matrix,  , and the reconstructed unitary matrix
, and the reconstructed unitary matrix  is calculated. Here μ denotes the reconstruction approach and σ the level of perturbance on the primary data. For each network size, 120 Haar-random unitary matrices are generated (labeled by j) to ensure that random properties of a jth unitary, e.g. symmetry, do not lead to biased results. For 'Bristol' always j = 1000 matrices are sampled due to the dispersed results. Subsequently the full set of primary data,
is calculated. Here μ denotes the reconstruction approach and σ the level of perturbance on the primary data. For each network size, 120 Haar-random unitary matrices are generated (labeled by j) to ensure that random properties of a jth unitary, e.g. symmetry, do not lead to biased results. For 'Bristol' always j = 1000 matrices are sampled due to the dispersed results. Subsequently the full set of primary data,  , is computed from each
, is computed from each  , where
, where  ,
,  , and
, and  denote the sets of two-photon visibilities, transmission intensities and phases sensed via coherent states, respectively. Under experimental conditions the primary data sets would be afflicted by statistic and systematic noise. We mimic this by perturbing the primary data sets with noise drawn from a normal distribution
denote the sets of two-photon visibilities, transmission intensities and phases sensed via coherent states, respectively. Under experimental conditions the primary data sets would be afflicted by statistic and systematic noise. We mimic this by perturbing the primary data sets with noise drawn from a normal distribution  of standard deviation σ centered around zero. The perturbed primary data distributions are given as
of standard deviation σ centered around zero. The perturbed primary data distributions are given as  and 20 different values of σ are sampled in
and 20 different values of σ are sampled in  steps from
steps from  to
to  . Note that for the phase data,
. Note that for the phase data,  , absolute perturbances were chosen. Eventually the unitary descriptions are calculated via a Monte Carlo method drawing the data required for each reconstruction approach, μ, randomly from
, absolute perturbances were chosen. Eventually the unitary descriptions are calculated via a Monte Carlo method drawing the data required for each reconstruction approach, μ, randomly from  . An average unitary description,
. An average unitary description,  , is obtained after 120 iterations with
, is obtained after 120 iterations with  denoting its standard deviation. This way errors are estimated via an identical procedure, independent of whether an analytic error propagation method is available or not. Finally the fidelity (see equation (1)) for each of the
denoting its standard deviation. This way errors are estimated via an identical procedure, independent of whether an analytic error propagation method is available or not. Finally the fidelity (see equation (1)) for each of the  reconstructed unitaries is computed.
reconstructed unitaries is computed.
A subset of the computed data is shown in figure 3(b), visualized as a two-dimensional histogram for m = 4 and  . Here the data points along one row, i.e. for a given perturbance σ, are composed of j = 1000 instead of j = 120 fidelities, for visualization purposes only. The absolute frequencies for a given σ can be associated with a probability distribution of a certain width, where the highest peak represents the most probable fidelity. For small perturbances σ those distributions will be in general sharp but asymmetric, whereas for larger σ dispersed and more symmetric distributions are found. To capture all but the most dispersed results we chose to fit them with a Weibull distribution centered around the most probable value,
. Here the data points along one row, i.e. for a given perturbance σ, are composed of j = 1000 instead of j = 120 fidelities, for visualization purposes only. The absolute frequencies for a given σ can be associated with a probability distribution of a certain width, where the highest peak represents the most probable fidelity. For small perturbances σ those distributions will be in general sharp but asymmetric, whereas for larger σ dispersed and more symmetric distributions are found. To capture all but the most dispersed results we chose to fit them with a Weibull distribution centered around the most probable value,  . As an error measure,
. As an error measure,  , the distances between the most probable fidelity and the two fidelities where the maximum probability decreased to
, the distances between the most probable fidelity and the two fidelities where the maximum probability decreased to  are used.
are used.

Figure 3. (a) Flowchart for the numerical method used to evaluate the different reconstruction approaches. (b) Frequency histogram of fidelities obtained in the case that the reconstruction approach 'Brisbane' is applied to 4 × 4 networks. The fidelity axis is divided into 50 bins ranging from 0.95 to 1, whereas the perturbance on the primary data, σ, ranges from  to
to  in
in  steps. For illustration purposes the sampling size is increased from 120 to 1000 4 × 4 Haar random unitaries for each σ.
steps. For illustration purposes the sampling size is increased from 120 to 1000 4 × 4 Haar random unitaries for each σ.
Download figure:
Standard image High-resolution imageProbability distributions
For the lossless case discussed above, Weibull distributions are used to extract the most probable fidelity,  , and the
, and the  errors of the fidelity,
errors of the fidelity,  . The Weibull distribution is given as
. The Weibull distribution is given as

with λ and k the scale and shape parameter, respectively.
Appendix B. The generation of primary data:
An m-mode linear optical scattering network can imprint new amplitude and phase information on an impinging light field (see figure 4). Whereas a large class of classical and quantum light fields can be used with the integrated optical networks considered here, their main application lies in the manipulation of coherent states or single photon Fock-states. Likewise, both states of light are suited as probe states to sense the transition-amplitudes or phases imprinted by the network. In the case that the light source used for characterization differs from the light source used in an experiment care has to be taken that the physical properties, especially the frequency and frequency bandwidth, are kept identical. When injected into a single input port k of a network, both coherent- and single-photon Fock-states allow to sense the transition amplitude  of a specific matrix entry
of a specific matrix entry  with j denoting an output mode4
However, intensities measured in this way will be affected by loss, coupling and detection efficiencies. Rudimentary techniques to directly measure input loss [31] work only in the case of zero output loss. Alternatively input and output loss can be traced out during the reconstruction process [28]. While this procedure is under ideal conditions loss-insensitive, the required algebraic transformations may even amplify error stemming from the primary data. Thus loss still presents a major problem when sensing transition-amplitudes and is best dealt with by careful calibration of e.g. detector efficiencies. This way a complete and reasonably accurate set of m2 real entries of any m × m unitary can be sensed if mode-dependent propagation loss plays a secondary role.
with j denoting an output mode4
However, intensities measured in this way will be affected by loss, coupling and detection efficiencies. Rudimentary techniques to directly measure input loss [31] work only in the case of zero output loss. Alternatively input and output loss can be traced out during the reconstruction process [28]. While this procedure is under ideal conditions loss-insensitive, the required algebraic transformations may even amplify error stemming from the primary data. Thus loss still presents a major problem when sensing transition-amplitudes and is best dealt with by careful calibration of e.g. detector efficiencies. This way a complete and reasonably accurate set of m2 real entries of any m × m unitary can be sensed if mode-dependent propagation loss plays a secondary role.

Figure 4. Classical and quantum probe states for transition amplitude and phase sensing. Sensing the properties of linear optical interferometers is best understood by considering 2 × 2 scattering submatrices of a larger interferometer. Here, both classical, (a) and (c), and quantum, (b) and (d), states of light can be used to sense information about the implemented amplitude and phase transformation. (a) Coherent states and (b) single-photon Fock-states injected into one mode of the network allow measurement of the transmission and reflection intensity  and
and  (shown in red). Repeating the measurement via a second input port (shown in blue) allows a loss-insensitive splitting parameter to be derived. Probing of non-global phases relies on interferometry which allows such phases to be extracted from intensity measurements. (c) A coherent state is distributed among two input modes and the relative phase φ is e.g. linearly modulated with frequency ω. Here the phase
(shown in red). Repeating the measurement via a second input port (shown in blue) allows a loss-insensitive splitting parameter to be derived. Probing of non-global phases relies on interferometry which allows such phases to be extracted from intensity measurements. (c) A coherent state is distributed among two input modes and the relative phase φ is e.g. linearly modulated with frequency ω. Here the phase  of the interferometer manifests as the relative phase of the recorded intensity pattern. (d) In the case of 2 × 2 scattering submatrices the Hong–Ou–Mandel dip can be utilized to sense the phase
of the interferometer manifests as the relative phase of the recorded intensity pattern. (d) In the case of 2 × 2 scattering submatrices the Hong–Ou–Mandel dip can be utilized to sense the phase  via the visibility
via the visibility  of the two-photon interference curve, as these 2 × 2 scattering submatrices are in general non-unitary. In contrast, monolithic 2 × 2 blocks, i.e. a beam splitter, are unitary and hence the visibility is only affected by the splitting ratio.
of the two-photon interference curve, as these 2 × 2 scattering submatrices are in general non-unitary. In contrast, monolithic 2 × 2 blocks, i.e. a beam splitter, are unitary and hence the visibility is only affected by the splitting ratio.
Download figure:
Standard image High-resolution imageTo sense the phases of a linear optical network coherent states can be distributed among two input modes k and l,  [31]. It is sufficient to choose l = 1 and subsequently measure the different input combinations
[31]. It is sufficient to choose l = 1 and subsequently measure the different input combinations  . Modulating the phase φ of this two-mode state at a frequency ω results in output intensities in all coupled output modes that are subjected to the modulation frequency ω albeit featuring a relative phase shift
. Modulating the phase φ of this two-mode state at a frequency ω results in output intensities in all coupled output modes that are subjected to the modulation frequency ω albeit featuring a relative phase shift  between output modes. These relative phase shifts correspond to the phases
between output modes. These relative phase shifts correspond to the phases  of the unitary matrix entry
of the unitary matrix entry  with all
with all  for
for  and an arbitrary sign for
and an arbitrary sign for  . Omitting the intensities and only recording this relative phase renders the measurement insensitive to mode-dependent input and output loss.
. Omitting the intensities and only recording this relative phase renders the measurement insensitive to mode-dependent input and output loss.
Experimentally the modulation ω can be realized through a piezo actuated mirror, a delay line or similar devices. Since coupling to integrated devices is predominantly implemented with fiber arrays the phase φ and modulation with frequency ω will be affected by fluctuations caused by temperature or vibrations [49, 50]. Care has to be taken that such noise is kept below a threshold which still allows a ω-periodicity in the output signal to be identified. In general the error can be largely minimized by utilizing a modulation frequency ω that is well separated from the frequency of the noise in the laboratory.
An alternative technique to sense the phase information utilizes the non-classical interference of two photons [39]. It can be shown [28, 42] that the extend of this quantum effect, the visibility of the resulting interference curve, is sensitive to the phases  of the interferometric network. Only the special case of a 2 × 2 device is phase-insensitive, owed to the unitary scattering submatrix. In general phase-sensitive probe states are also transition-amplitude sensitive and are therefore sufficient to generate all primary data needed to reconstruct the unitary description of a linear optical network. Remarkably, the visibilities obtained via two-photon interferences are insensitive to input and output loss. In contrast, sensing transition-amplitudes with two-mode coherent states generates the same problems as measuring transition amplitudes directly.
of the interferometric network. Only the special case of a 2 × 2 device is phase-insensitive, owed to the unitary scattering submatrix. In general phase-sensitive probe states are also transition-amplitude sensitive and are therefore sufficient to generate all primary data needed to reconstruct the unitary description of a linear optical network. Remarkably, the visibilities obtained via two-photon interferences are insensitive to input and output loss. In contrast, sensing transition-amplitudes with two-mode coherent states generates the same problems as measuring transition amplitudes directly.
Experimentally, non-classical interference visibility measurements are ideally implemented using a pure, separable bi-photon state, where each photon is injected into its own interferometer mode. Subsequently the distinguishability of the two photons is scanned, e.g. by altering the relative temporal delay  between the photons. Given that coupling to waveguides and propagation in waveguides is not lossless and that detection efficiency of e.g. avalanche photo diodes is limited, measurement times exceed those of coherent probe-states. Imperfections in the probe-state generation are the major contributes to systematic errors and affect the quality of the measured visibility. Using an involved modeling contributions from spectral mismatch and spectral correlations, background noise and drift in the coupling can be taken into account. Thus the accuracy of the extracted visibilities can be increased and errors minimized to
between the photons. Given that coupling to waveguides and propagation in waveguides is not lossless and that detection efficiency of e.g. avalanche photo diodes is limited, measurement times exceed those of coherent probe-states. Imperfections in the probe-state generation are the major contributes to systematic errors and affect the quality of the measured visibility. Using an involved modeling contributions from spectral mismatch and spectral correlations, background noise and drift in the coupling can be taken into account. Thus the accuracy of the extracted visibilities can be increased and errors minimized to  . Complete sampling of all accessible visibilities,
. Complete sampling of all accessible visibilities,  for a m × m network has several algorithmic and statistic advantages and can be reduced to
for a m × m network has several algorithmic and statistic advantages and can be reduced to  measurement runs if a sufficient number of detectors is available. In many quantum optical experiments generating the data via the non-classical interference of two photons has the additional benefit that the apparatus required for characterization of the network is a subset of the whole experimental apparatus and the procedure works 'in situ'.
measurement runs if a sufficient number of detectors is available. In many quantum optical experiments generating the data via the non-classical interference of two photons has the additional benefit that the apparatus required for characterization of the network is a subset of the whole experimental apparatus and the procedure works 'in situ'.
Appendix C. Size of the primary data set and resource cost:
Through technological progress the number of fully coupled modes supported by integrated circuits is growing and consequently, so is the size of the primary data sets required to characterize their unitary transformations. Thus a manageable size of these data sets is becoming an important criterion for evaluating different reconstruction approaches. Here, fully coupled interferometers represent the most general case. The lower bound of required data points is quantified by the number  of spherical coordinates that parametrize such a m × m network, with the spherical coordinates corresponding to the beam splitting ratios and phase shifts of Reck et al [38]. Note that both, 'Bristol' and 'Brisbane' aim to reconstruct the
of spherical coordinates that parametrize such a m × m network, with the spherical coordinates corresponding to the beam splitting ratios and phase shifts of Reck et al [38]. Note that both, 'Bristol' and 'Brisbane' aim to reconstruct the  matrix entries directly, hence a set of nmin data points is insufficient. The approaches 'Bristol' and 'Brisbane' utilize sufficient data sets that are close to this lower bound and consist of m2 transition amplitudes and
matrix entries directly, hence a set of nmin data points is insufficient. The approaches 'Bristol' and 'Brisbane' utilize sufficient data sets that are close to this lower bound and consist of m2 transition amplitudes and  data points to recover the non-trivial phases. In the case of 'Bristol' additional
data points to recover the non-trivial phases. In the case of 'Bristol' additional  two-photon visibilities are required to determine the sign of the phases. We chose the upper bound of primary data to be the over-complete set of all two-photon interference visibilities,
two-photon visibilities are required to determine the sign of the phases. We chose the upper bound of primary data to be the over-complete set of all two-photon interference visibilities,  . This set of data can be efficiently recorded given todays bright single photon sources [51] but can be in principle expanded to even higher order correlation functions. Likewise the m2 transition amplitudes represent a non-redundant set of data to expand nfull. Since the transition amplitudes are loss afflicted they are not used in the global optimization routine of 'Vienna'. Only in the case that 'Vienna' is applied to black-box networks the m2 transition amplitudes and
. This set of data can be efficiently recorded given todays bright single photon sources [51] but can be in principle expanded to even higher order correlation functions. Likewise the m2 transition amplitudes represent a non-redundant set of data to expand nfull. Since the transition amplitudes are loss afflicted they are not used in the global optimization routine of 'Vienna'. Only in the case that 'Vienna' is applied to black-box networks the m2 transition amplitudes and  relative phases are needed to extract the starting parameters for the global optimization. Furthermore this global optimization allows for an adaptive strategy; best reconstruction accuracy is achieved using the full over-complete set of data. Alternatively, a reduced set of data, the set of all possible two-photon interference visibilities that can be generated when one photon is always inserted into input port one and the second photon into input port
relative phases are needed to extract the starting parameters for the global optimization. Furthermore this global optimization allows for an adaptive strategy; best reconstruction accuracy is achieved using the full over-complete set of data. Alternatively, a reduced set of data, the set of all possible two-photon interference visibilities that can be generated when one photon is always inserted into input port one and the second photon into input port  , can be used. This results in a reduced set of
, can be used. This results in a reduced set of  visibilities which always suffices to reconstruct m × m networks with
visibilities which always suffices to reconstruct m × m networks with  modes. In the following we will refer to the reconstruction approach 'Vienna' utilizing a reduced set of primary data as 'Vienna reduced'.
modes. In the following we will refer to the reconstruction approach 'Vienna' utilizing a reduced set of primary data as 'Vienna reduced'.
A second number, the required measurement runs to generate the primary data set, can be regarded as the experimentally more relevant parameter. We list this parameter for the reconstruction approaches compared here in the limit that every output mode is coupled to an individual detector in table 1. Now, all output events for a given input combination can be recorded in parallel, thus the number of required measurements corresponds to the required input combinations that need to be consecutively aligned in a laboratory. For instance, the m2 transition amplitude data can be acquired in m measurement runs and the  two-photon interference visibilities in
two-photon interference visibilities in  measurement runs.
measurement runs.
Table 1. Size of the primary data set and minimal number of measurements for different reconstruction approaches.
| 'Brisbane' | 'Bristol' | 'Vienna' | 'Viennablack-box' | |
|---|---|---|---|---|
| Minimal primary data used |

|

|

|

|
| Required number of measurement runs with sufficient detectors |

|

|

|

|
| Maximal available primary data |

|

|

|

|
| Required number of measurement runs with sufficient detectors |

|

|

|

|
The three compared unitary reconstruction approaches differ significantly in the minimal and maximal set of primary data available for the reconstruction algorithms. For 'Brisbane' the minimal and maximal set of data are identical. Whereas a larger primary data set is more costly to generate experimentally this expense is justified if the data can be used to increase the accuracy of the reconstructed description. The required number of measurement runs is given in the limit that each output mode is covered by its own detector and can be regarded as the experimentally more relevant quantity. Here 'Vienna' is referring to a reconstruction of a structure with known layout and starting values, while 'Viennablack-box' refers to a black-box network. The minimal primary data set required for the approach 'Bristol' presents a special case. Here the amount of data is constituted by the m2 transition amplitudes and the and the (m − 1)2 and (m − 1)2 − 1 two-photon visibilities to recover the absolute values and signs of the phases, respectively. In the case of sufficient detectors the transition amplitudes can be sensed in m measurement runs and the two-photon visibilities to recover the absolute value of the phases in m − 1 measurement runs. To fix the sign of the phases additional m − 2 measurement runs are necessary.
Appendix D. The influence of loss:
Loss can be a major factor in experiments using integrated optical circuits. In the case of direct laser-written networks propagation loss of  and coupling loss of
and coupling loss of  are typical values [22, 52]. If these losses are mode-independent, however, they just represent a global loss term that commutes with the optical transformation of a LON. In contrast, mode-dependent losses cause deviations in a targeted optical transformation. Characterizing mode-dependent losses thus becomes important when reconstructing the optical transformation of a LON. Here, we distinguish between the case of mode-dependent loss at the input and output ports and the case of mode-dependent propagation loss. In the first case, loss can always be separated from the transformation of a LON and be described by loss matrices containing virtual beam splitters. For a m × m LON this translates to m additional parameters modeling input loss and m additional parameters modeling output loss, the
are typical values [22, 52]. If these losses are mode-independent, however, they just represent a global loss term that commutes with the optical transformation of a LON. In contrast, mode-dependent losses cause deviations in a targeted optical transformation. Characterizing mode-dependent losses thus becomes important when reconstructing the optical transformation of a LON. Here, we distinguish between the case of mode-dependent loss at the input and output ports and the case of mode-dependent propagation loss. In the first case, loss can always be separated from the transformation of a LON and be described by loss matrices containing virtual beam splitters. For a m × m LON this translates to m additional parameters modeling input loss and m additional parameters modeling output loss, the  and
and  of figure 5, respectively. The unitary matrix of the LON expanded by the 2 m loss modes now reads as
of figure 5, respectively. The unitary matrix of the LON expanded by the 2 m loss modes now reads as

with  denoting the
denoting the  loss matrices. Still, only the original m input and output modes are experimentally accessible. Note that the data set for relative phases sensed via coherent states,
loss matrices. Still, only the original m input and output modes are experimentally accessible. Note that the data set for relative phases sensed via coherent states,  , and the the data set composed of two-photon interference visibilities,
, and the the data set composed of two-photon interference visibilities,  , are insensitive to these losses and hence directly reveal information about
, are insensitive to these losses and hence directly reveal information about  . Whereas
. Whereas  just contains information on the non-trivial phases of the interferometer but not on the transition amplitudes, the set of two-photon interference visibilities contains information on both. This is a unique feature of the latter data set and owed to the quantum nature of the interference.
just contains information on the non-trivial phases of the interferometer but not on the transition amplitudes, the set of two-photon interference visibilities contains information on both. This is a unique feature of the latter data set and owed to the quantum nature of the interference.

Figure 5. Layout of 4 × 4 interferometers following the Reck et al scheme. Tuning the splitting ratios,  , of the
, of the  beam splitters and the phase shifts,
beam splitters and the phase shifts,  , of the
, of the  phase shifters any 4 × 4 unitary can be realized. Phases at the input and output, i.e. global phases, are omitted. (a) Input and output loss can be parametrized by eight additional beam splitters,
phase shifters any 4 × 4 unitary can be realized. Phases at the input and output, i.e. global phases, are omitted. (a) Input and output loss can be parametrized by eight additional beam splitters,  and
and  , coupling to the loss modes 5–12, here indicated by the green arrows. (b) Mode-dependent propagation loss can be modelled with additional
, coupling to the loss modes 5–12, here indicated by the green arrows. (b) Mode-dependent propagation loss can be modelled with additional  beam splitters,
beam splitters,  , coupling to the loss modes 13–20, here indicated by the light brown arrows.
, coupling to the loss modes 13–20, here indicated by the light brown arrows.
Download figure:
Standard image High-resolution imageIn comparison, a direct measurement of the transition amplitudes  is always afflicted by mode-dependent input and output loss. As a consequence, the latter set of data only reveals information on a m × m submatrix of
is always afflicted by mode-dependent input and output loss. As a consequence, the latter set of data only reveals information on a m × m submatrix of  . In our notation this submatrix corresponds to the upper left m × m submatrix of
. In our notation this submatrix corresponds to the upper left m × m submatrix of  , that is spanned by the m accessible input and output ports. In general, the size of the transition amplitude data set
, that is spanned by the m accessible input and output ports. In general, the size of the transition amplitude data set  is insufficient to reconstruct all the 2m loss terms in addition to the m2 real entries directly. Therefore, the strategy used in 'Brisbane' only works if m loss parameters, either all
is insufficient to reconstruct all the 2m loss terms in addition to the m2 real entries directly. Therefore, the strategy used in 'Brisbane' only works if m loss parameters, either all  or all
or all  , can be neglected (see also body text). Alternatively, the transition amplitude data can be subjected to a reconstruction algorithm in which the loss terms drop out, as done in 'Bristol', however this necessitates unitary constraints. Although the strategy of 'Bristol' seems to be of advantage, figure 2 gives a indication that the algorithm reacts fragile to measurement error on the primary data. In comparison 'Brisbane' achieves higher reconstruction fidelities. This may change in the presence of mode-dependent input and output loss. It is an open question where the threshold of measurement error on the sensed data opposed to the level of of input and output loss lies, that would favor one over the other algorithm. Due to the processing of just two-photon interference visibilities, 'Vienna' is insensitive to input and output losses. Hence,
, can be neglected (see also body text). Alternatively, the transition amplitude data can be subjected to a reconstruction algorithm in which the loss terms drop out, as done in 'Bristol', however this necessitates unitary constraints. Although the strategy of 'Bristol' seems to be of advantage, figure 2 gives a indication that the algorithm reacts fragile to measurement error on the primary data. In comparison 'Brisbane' achieves higher reconstruction fidelities. This may change in the presence of mode-dependent input and output loss. It is an open question where the threshold of measurement error on the sensed data opposed to the level of of input and output loss lies, that would favor one over the other algorithm. Due to the processing of just two-photon interference visibilities, 'Vienna' is insensitive to input and output losses. Hence,  is directly reconstructed and the
is directly reconstructed and the  and
and  can be obtained in a separate step by solving a system of linear equations using loss afflicted data, e.g. the set of transition amplitudes
can be obtained in a separate step by solving a system of linear equations using loss afflicted data, e.g. the set of transition amplitudes  . In the case of black-box networks, however, some dependence is carried over if initial starting parameters,
. In the case of black-box networks, however, some dependence is carried over if initial starting parameters,  , are obtained via, e.g. 'Brisbane'.
, are obtained via, e.g. 'Brisbane'.
In contrast to input and output loss, mode-dependent propagation loss cannot be separated from the unitary description of a LON, as it does not commute with the optical elements that constitute the network's fundamental transformation. Instead, the unitary description needs to be expanded by additional in-circuit loss modes, subsequently labeled l. This is illustrated in figure 5(b) for the case of a 4 × 4 circuit, where the  denote the parameters of the loss modeling beam splitters. For general m × m LONs which follow the Reck et al layout this translates to
denote the parameters of the loss modeling beam splitters. For general m × m LONs which follow the Reck et al layout this translates to  additional modes. Now the unitary can be written as
additional modes. Now the unitary can be written as

with m the number of accessible network-modes,  the total number of modes and
the total number of modes and  denoting the r × r input and output loss matrices. All data sets sensed for reconstruction purposes,
denoting the r × r input and output loss matrices. All data sets sensed for reconstruction purposes,  reveal information about an in general non-unitary submatrix of
reveal information about an in general non-unitary submatrix of  . In our notation, this submatrix corresponds to the upper left m × m submatrix of
. In our notation, this submatrix corresponds to the upper left m × m submatrix of  . Now, the above mentioned strategies to model loss fail. The loss terms cannot be assessed directly and error is introduced by applying unitary constrains to the non-unitary m × m submatrix.
. Now, the above mentioned strategies to model loss fail. The loss terms cannot be assessed directly and error is introduced by applying unitary constrains to the non-unitary m × m submatrix.
We numerically evaluate the exemplary case of m = 4 LONs to investigate how severe the reconstruction performance of the various approaches is offset by mode-dependent in-circuit loss. The general layout of these networks is shown in figure 5(b). Here, the input and output losses are kept zero to ensure that they do not influence the results. Thus the networks are just expanded by l = 8 in-circuit loss modes. The approaches 'Brisbane' and 'Bristol' are constructed to obtain 4 × 4 descriptions which prevents the use of the fidelity measure defined in equation (1). Hence we use an alternative measure which is experimentally motivated and constructed as the mean deviation between a point of primary data and its prediction obtained via one of the reconstructed descriptions.  quantifies the mean deviation for the normalized transition-amplitude data and
quantifies the mean deviation for the normalized transition-amplitude data and  the mean deviation for the two-photon interference visibilities (see definition below). In the limit of
the mean deviation for the two-photon interference visibilities (see definition below). In the limit of  , perfect reconstruction is achieved, a result only expected if in-circuit loss is either zero or if it can be fully recovered by an approach. One option to achieve the latter is a reconstruction of the complete
, perfect reconstruction is achieved, a result only expected if in-circuit loss is either zero or if it can be fully recovered by an approach. One option to achieve the latter is a reconstruction of the complete  unitary description, which we investigate for the approach 'Vienna'. The required starting parameters for the
unitary description, which we investigate for the approach 'Vienna'. The required starting parameters for the  and
and  used to initialize to optimization routine are extracted via the approach 'Brisbane'. All
used to initialize to optimization routine are extracted via the approach 'Brisbane'. All  are initialized at zero. The data presented in figure 6 is sampled for different levels of loss by drawing the transmittances of the loss beam splitters,
are initialized at zero. The data presented in figure 6 is sampled for different levels of loss by drawing the transmittances of the loss beam splitters,  , randomly from a uniform distribution
, randomly from a uniform distribution ![$[\cos (\epsilon ),1]$](https://content.cld.iop.org/journals/2040-8986/18/11/114002/revision1/joptaa397eieqn188.gif) . In the worst case of
. In the worst case of  , the maximum loss per beam splitter thus is
, the maximum loss per beam splitter thus is  . To sample the unitary space representative, j = 500 different 12 × 12 starting matrices are generated for each loss-interval. The general perturbance on the primary data was set to
. To sample the unitary space representative, j = 500 different 12 × 12 starting matrices are generated for each loss-interval. The general perturbance on the primary data was set to  . All reconstructed descriptions are computed in the same way as in section 3 via a Monte Carlo method with a sampling size of i = 100 (see also appendix A). The resulting frequency histograms for
. All reconstructed descriptions are computed in the same way as in section 3 via a Monte Carlo method with a sampling size of i = 100 (see also appendix A). The resulting frequency histograms for  ,
,  and the fidelity histograms in the case of 'Vienna' were fitted with Burr type XII distributions [53], as these show good overlap with the numerical data. The data points and error bars contained within figure 6 are given as the most probable value of the distributions and the distance between the most probable value and those values to the left and right where the maximum probability decreases to
and the fidelity histograms in the case of 'Vienna' were fitted with Burr type XII distributions [53], as these show good overlap with the numerical data. The data points and error bars contained within figure 6 are given as the most probable value of the distributions and the distance between the most probable value and those values to the left and right where the maximum probability decreases to  , respectively.
, respectively.

Figure 6. The influence of mode-dependent propagation loss on the reconstruction performance for 4 × 4 LONs and the different approaches 'Brisbane', 'Bristol', and 'Vienna'. The data for 'Brisbane' and 'Bristol' is offset from the data in the case of 'Vienna' for visualization purposes only. Here the general perturbance on the primary data, σ, was chosen to be  and input and output loss to be zero. The transmittances,
and input and output loss to be zero. The transmittances,  , of the eight beam splitters modeling the mode-dependent loss were drawn uniformly from the interval
, of the eight beam splitters modeling the mode-dependent loss were drawn uniformly from the interval ![$[\cos (\epsilon ),1]$](https://content.cld.iop.org/journals/2040-8986/18/11/114002/revision1/joptaa397eieqn197.gif) . Several intervals were sampled in discrete steps ranging from zero loss to
. Several intervals were sampled in discrete steps ranging from zero loss to  loss and 500 random matrices were reconstructed for each interval. The histograms were fitted with Burr type XII distributions and the error bars are given as the distance between the most probable value and those values to the left and right where the maximum probability decreases to
loss and 500 random matrices were reconstructed for each interval. The histograms were fitted with Burr type XII distributions and the error bars are given as the distance between the most probable value and those values to the left and right where the maximum probability decreases to  . (a)
. (a)  quantifies the mean deviation of the normalized transition amplitudes between the initial values and the ones obtained from the reconstructed descriptions. (b) Analogously
quantifies the mean deviation of the normalized transition amplitudes between the initial values and the ones obtained from the reconstructed descriptions. (b) Analogously  quantifies the mean deviation of the two-photon interference visibilities. Only data from the experimentally accessible 4 × 4 submatrices is considered. (c) Reconstruction fidelities for the
quantifies the mean deviation of the two-photon interference visibilities. Only data from the experimentally accessible 4 × 4 submatrices is considered. (c) Reconstruction fidelities for the  unitary matrices reconstructed via 'Vienna'.
unitary matrices reconstructed via 'Vienna'.
Download figure:
Standard image High-resolution imageAlready for the small levels of mode-dependent propagation loss considered here, all three approaches struggle to reconstruct precise unitary descriptions. This result is to be expected in the case of 'Brisbane' and 'Bristol' as the sets of data used for the reconstruction procedures originate from a non-unitary submatrix. Hence only closest unitary descriptions are reconstructed, which in turn cannot fully explain the original data sets.
The results obtained in the case of 'Vienna' need to be interpreted in a different way. Whereas the global optimization of just two-photon interference visibilities converges, as can be seen by the values for  in figure 6(b), the values obtained for
in figure 6(b), the values obtained for  show a scaling similar to the other two approaches. This indicates that the original optical element parameters for the beam splitters, phase shifters and loss beam splitters cannot be recovered with high accuracy. As a result the fidelities of the reconstructed 12 × 12 unitary matrices decrease rapidly with growing
show a scaling similar to the other two approaches. This indicates that the original optical element parameters for the beam splitters, phase shifters and loss beam splitters cannot be recovered with high accuracy. As a result the fidelities of the reconstructed 12 × 12 unitary matrices decrease rapidly with growing  . It is an open question whether a larger set of primary data including relative phase shifts
. It is an open question whether a larger set of primary data including relative phase shifts  would yield improved reconstruction results. In light of the above results mode-dependent propagation loss still presents a fundamental problem when reconstructing unitary descriptions of LONs.
would yield improved reconstruction results. In light of the above results mode-dependent propagation loss still presents a fundamental problem when reconstructing unitary descriptions of LONs.
Quality measure for the case of mode-dependent propagation loss
The quality measure  introduced in above is constructed as the difference between the full set of sensed two-photon interference visibilities and the set of predicted visibilities, obtained via a reconstructed unitary matrix. It is normalized by the maximum amount of two-photon interference visibilities,
introduced in above is constructed as the difference between the full set of sensed two-photon interference visibilities and the set of predicted visibilities, obtained via a reconstructed unitary matrix. It is normalized by the maximum amount of two-photon interference visibilities,  , that can be obtained
, that can be obtained

Similarly, the measure  quantifies the difference between the set of measured transition-amplitudes and the predicted ones via a reconstructed unitary matrix. It is normalized by the maximum amount of transition-amplitude data, m2, that can be obtained
quantifies the difference between the set of measured transition-amplitudes and the predicted ones via a reconstructed unitary matrix. It is normalized by the maximum amount of transition-amplitude data, m2, that can be obtained

In the case of  , we normalize the transition-amplitude data for each of the m measured inputs over all outputs to m unit vectors, to allow for comparison between the loss sensitive and insensitive approaches. This normalized transition amplitude data is labeled
, we normalize the transition-amplitude data for each of the m measured inputs over all outputs to m unit vectors, to allow for comparison between the loss sensitive and insensitive approaches. This normalized transition amplitude data is labeled  and defined as
and defined as

Footnotes
- 1
- 2
Throughout the numerical evaluation the transition amplitude data is normalized such that
 .
. - 3
For 'Bristol' always 103 matrices are sampled due to the dispersed results.
- 4
The recorded intensities are proportional to
with



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}