


Abstract
We analyze feature learning in infinite-width neural networks trained with gradient flow through a self-consistent dynamical field theory. We construct a collection of deterministic dynamical order parameters which are inner-product kernels for hidden unit activations and gradients in each layer at pairs of time points, providing a reduced description of network activity through training. These kernel order parameters collectively define the hidden layer activation distribution, the evolution of the neural tangent kernel (NTK), and consequently, output predictions. We show that the field theory derivation recovers the recursive stochastic process of infinite-width feature learning networks obtained by Yang and Hu with tensor programs. For deep linear networks, these kernels satisfy a set of algebraic matrix equations. For nonlinear networks, we provide an alternating sampling procedure to self-consistently solve for the kernel order parameters. We provide comparisons of the self-consistent solution to various approximation schemes including the static NTK approximation, gradient independence assumption, and leading order perturbation theory, showing that each of these approximations can break down in regimes where general self-consistent solutions still provide an accurate description. Lastly, we provide experiments in more realistic settings which demonstrate that the loss and kernel dynamics of convolutional neural networks at fixed feature learning strength are preserved across different widths on a image classification task.
Export citation and abstract BibTeX RIS
1. Introduction
Deep learning has emerged as a successful paradigm for solving challenging machine learning and computational problems across a variety of domains [1, 2]. However, theoretical understanding of the training and generalization of modern deep learning methods lags behind current practice. Ideally, a theory of deep learning would be analytically tractable, efficiently computable, capable of predicting network performance and internal features that the network learns, and interpretable through a reduced description involving desirably initialization-independent quantities.
Several recent theoretical advances have fruitfully considered the idealization of wide neural networks, where the number of hidden units in each layer is taken to be large. Under certain parameterization, Bayesian neural networks and gradient descent (GD) trained networks converge to gaussian processes (NNGPs) [3–5] and neural tangent kernel (NTK) machines [6–8] in their respective infinite-width limits. These limits provide both analytic tractability as well as detailed training and generalization analysis [9–16]. However, in this limit, with these parameterizations, data representations are fixed and do not adapt to data, termed the lazy regime of NN training, to contrast it from the rich regime where NNs significantly alter their internal features while fitting the data [17, 18]. The fact that the representation of data is fixed renders these kernel-based theories incapable of explaining feature learning, an ingredient which is crucial to the success of deep learning in practice [19, 20]. Thus, alternative theories capable of modeling feature learning dynamics are needed.
Recently developed alternative parameterizations such as the mean field [21] and the  [22] parameterizations allow feature learning in infinite-width NNs trained with GD. Using the tensor programs (TPs) framework, Yang and Hu identified a stochastic process that describes the evolution of preactivation features in infinite-width
[22] parameterizations allow feature learning in infinite-width NNs trained with GD. Using the tensor programs (TPs) framework, Yang and Hu identified a stochastic process that describes the evolution of preactivation features in infinite-width  NNs [22]. In this work, we study an equivalent parameterization to
NNs [22]. In this work, we study an equivalent parameterization to  with self-consistent dynamical mean field theory (DMFT) and recover the stochastic process description of infinite NNs using this alternative technique. In the same large width scaling, we include a scalar parameter γ0 that allows smooth interpolation between lazy and rich behavior [17]. We provide a new computational procedure to sample this stochastic process and demonstrate its predictive power for wide NNs.
with self-consistent dynamical mean field theory (DMFT) and recover the stochastic process description of infinite NNs using this alternative technique. In the same large width scaling, we include a scalar parameter γ0 that allows smooth interpolation between lazy and rich behavior [17]. We provide a new computational procedure to sample this stochastic process and demonstrate its predictive power for wide NNs.
Our novel contributions in this paper are the following:
- (i)We develop a path integral formulation of gradient flow dynamics in infinite-width networks in the feature learning regime. Our parameterization includes a scalar parameter γ0 to allow interpolation between rich and lazy regimes and comparison to perturbative methods.
- (ii)Using a stationary action argument, we identify a set of saddle point equations that the kernels satisfy at infinite-width, relating the stochastic processes that define hidden activation evolution to the kernels and vice versa. We show that our saddle point equations recover at
 , from an alternative method, the same stochastic process obtained previously with TPs [22].
, from an alternative method, the same stochastic process obtained previously with TPs [22]. - (iii)We develop a polynomial-time numerical procedure to solve the saddle point equations for deep networks. In numerical experiments, we demonstrate that solutions to these self-consistency equations are predictive of network training at a variety of feature learning strengths, widths and depths. We provide comparisons of our theory to various approximate methods, such as perturbation theory.

Code to reproduce our experiments can be found on our Github.
1.1. Related works
A natural extension to the lazy NTK/NNGP limit that allows the study of feature learning is to calculate finite width corrections to the infinite-width limit. Finite width corrections to Bayesian inference in wide networks have been obtained with various perturbative [23–29] and self-consistent techniques [30–33]. In the GD based setting, leading order corrections to the NTK dynamics have been analyzed to study finite width effects [27, 34–36]. These methods give approximate corrections which are accurate provided the strength of feature learning is small. In very rich feature learning regimes, however, the leading order corrections can give incorrect predictions [37, 38].
Another approach to studying feature learning is to alter NN parameterization in gradient-based learning to allow significant feature evolution even at infinite-width, the mean field limit [21, 39]. Works on mean field NNs have yielded formal loss convergence results [40, 41] and shown equivalences of gradient flow dynamics to a partial differential equation (PDE) [42–44].
Our results are most closely related to a set of recent works which studied infinite-width NNs trained with GD using the TPs framework [22]. We show that our discrete time field theory at unit feature learning strength  recovers the stochastic process which was derived from TP. The stochastic process derived from TP has provided insights into practical issues in NN training such as hyper-parameter search [45]. Computing the exact infinite-width limit of GD has exponential time requirements [22], which we show can be circumvented with an alternating sampling procedure. A projected variant of GD training has provided an infinite-width theory that could be scaled to realistic datasets like CIFAR-10 [46]. Inspired by Chizat and Bach's work on mechanisms of lazy and rich training [17], our theory interpolates between lazy and rich behavior in the mean field limit for varying γ0 and allows comparison of DMFT to perturbative analysis near small γ0. Further, our derivation of a DMFT action allows the possibility of pursuing finite width effects.
recovers the stochastic process which was derived from TP. The stochastic process derived from TP has provided insights into practical issues in NN training such as hyper-parameter search [45]. Computing the exact infinite-width limit of GD has exponential time requirements [22], which we show can be circumvented with an alternating sampling procedure. A projected variant of GD training has provided an infinite-width theory that could be scaled to realistic datasets like CIFAR-10 [46]. Inspired by Chizat and Bach's work on mechanisms of lazy and rich training [17], our theory interpolates between lazy and rich behavior in the mean field limit for varying γ0 and allows comparison of DMFT to perturbative analysis near small γ0. Further, our derivation of a DMFT action allows the possibility of pursuing finite width effects.
Our theory is inspired by self-consistent DMFT from statistical physics [47–53]. This framework has been utilized in the theory of random recurrent networks [54–59], tensor PCA [60, 61], phase retrieval [62], and high-dimensional linear classifiers [63–66], but has yet to be developed for deep feature learning. By developing a self-consistent DMFT of deep NNs, we gain insight into how features evolve in the rich regime of network training, while retaining many pleasant analytic properties of the infinite-width limit.
2. Problem setup and definitions
Our theory applies to infinite-width networks, both fully-connected and convolutional. For notational ease we will relegate convolutional results to later sections. For input  , we define the hidden pre-activation vectors
, we define the hidden pre-activation vectors  for layers
for layers  as
as

where  are the trainable parameters of the network and φ is a twice differentiable activation function. Inspired by previous works on the mechanisms of lazy gradient based training, the parameter γ will control the laziness or richness of the training dynamics [17, 18, 22, 42]. Each of the trainable parameters are initialized as Gaussian random variables with unit variance
are the trainable parameters of the network and φ is a twice differentiable activation function. Inspired by previous works on the mechanisms of lazy gradient based training, the parameter γ will control the laziness or richness of the training dynamics [17, 18, 22, 42]. Each of the trainable parameters are initialized as Gaussian random variables with unit variance  . They evolve under gradient flow
. They evolve under gradient flow  . The choice of learning rate γ2 causes
. The choice of learning rate γ2 causes  to be independent of γ. To characterize the evolution of weights, we introduce back-propagation variables
to be independent of γ. To characterize the evolution of weights, we introduce back-propagation variables

where  is the pre-gradient signal.
is the pre-gradient signal.
The relevant dynamical objects to characterize feature learning are feature and gradient kernels for each hidden layer  , defined as
, defined as

From the kernels  , we can compute the NTK
, we can compute the NTK
 [6] and the dynamics of the network function fµ
[6] and the dynamics of the network function fµ

where we define base cases  . In prior work,
. In prior work,  were termed forward and backward kernels and were theoretically computed at initialization and empirically measured through training [67]. Our DMFT will provide exact formulas for these kernels throughout the full dynamics of feature learning. We note that the above formula holds for any data point µ which may or may not be in the set of P training examples. The above expressions demonstrate that knowledge of the temporal trajectory of the NTK on the t = s diagonal gives the temporal trajectory of the network predictions
were termed forward and backward kernels and were theoretically computed at initialization and empirically measured through training [67]. Our DMFT will provide exact formulas for these kernels throughout the full dynamics of feature learning. We note that the above formula holds for any data point µ which may or may not be in the set of P training examples. The above expressions demonstrate that knowledge of the temporal trajectory of the NTK on the t = s diagonal gives the temporal trajectory of the network predictions  .
.
Following prior works on infinite-width networks [18, 21, 22, 40], we study the mean field limit

As we demonstrate in the appendices  . The
. The  limit recovers the static NTK limit [6]. We discuss other scalings and parameterizations in appendix
limit recovers the static NTK limit [6]. We discuss other scalings and parameterizations in appendix  -parameterization and TP analysis of [22], showing they have identical feature dynamics in the infinite-width limit. We also analyze the effect of different hidden layer widths and initialization variances in the appendix D.8. We focus on equal widths and NTK parameterization (as in equation (1)) in the main text to reduce complexity.
-parameterization and TP analysis of [22], showing they have identical feature dynamics in the infinite-width limit. We also analyze the effect of different hidden layer widths and initialization variances in the appendix D.8. We focus on equal widths and NTK parameterization (as in equation (1)) in the main text to reduce complexity.
3. Self-consistent DMFT
Next, we derive our self-consistent DMFT in a limit where  . Our goal is to build a description of training dynamics purely based on representations, and independent of weights. Studying feature learning at infinite-width enjoys several analytical properties:
. Our goal is to build a description of training dynamics purely based on representations, and independent of weights. Studying feature learning at infinite-width enjoys several analytical properties:
- The kernel order parameters concentrate over random initializations but are dynamical, allowing flexible adaptation of features to the task structure.
- In each layer , each neuron's preactivation and pregradient become i.i.d. draws from a distribution characterized by a set of order parameters .
- The kernels are defined as self-consistent averages (denoted by ) over this distribution of neurons in each layer and .








The next section derives these facts from a path-integral formulation of gradient flow dynamics.
3.1. Path integral construction
Gradient flow after a random initialization of weights defines a high dimensional stochastic process over initalizations for variables  . Therefore, we will utilize DMFT formalism to obtain a reduced description of network activity during training. For a simplified derivation of the DMFT for the two-layer (L = 1) case, see appendix D.2. Generally, we separate the contribution on each forward/backward pass between the initial condition and gradient updates to weight matrix
. Therefore, we will utilize DMFT formalism to obtain a reduced description of network activity during training. For a simplified derivation of the DMFT for the two-layer (L = 1) case, see appendix D.2. Generally, we separate the contribution on each forward/backward pass between the initial condition and gradient updates to weight matrix  , defining new stochastic variables
, defining new stochastic variables  as
as

We let Z represent the moment generating functional (MGF) for these stochastic fields

which requires, by construction the normalization condition ![$Z[\{\boldsymbol{0},\boldsymbol{0} \}] = 1$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn35.gif) . We enforce our definition of
. We enforce our definition of  using an integral representation of the delta-function. Thus for each sample
using an integral representation of the delta-function. Thus for each sample ![$\mu \in [P]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn37.gif) and each time
and each time  , we multiply Z by
, we multiply Z by

for
χ
and the respective expression for
ξ
. After making such substitutions, we perform integration over initial Gaussian weight matrices to arrive at an integral expression for Z, which we derive in the appendix D.4. We show that Z can be described by set of order-parameters 


where S is the DMFT action and  is a single-site MGF, which defines the distribution of fields
is a single-site MGF, which defines the distribution of fields  over the neural population in each layer. The order parameters A and B are related to the correlations between feedforward and feedback signals. We provide a detailed formula for
over the neural population in each layer. The order parameters A and B are related to the correlations between feedforward and feedback signals. We provide a detailed formula for  in appendix D.4 and show that it factorizes over different layers
in appendix D.4 and show that it factorizes over different layers  . Each of the single site MGFs has the form
. Each of the single site MGFs has the form

where  is a single-site Hamiltonian that depends on the order parameters and defines the probability density over fields
is a single-site Hamiltonian that depends on the order parameters and defines the probability density over fields  . We introduce the single site average
. We introduce the single site average
 of observable O
of observable O

In the next section, we express the DMFT saddle-point equations defining  in terms of such single site averages.
in terms of such single site averages.
3.2. Deriving the DMFT equations from the path integral saddle point
As  , the moment-generating function Z is exponentially dominated by the saddle point of S. The equations that define this saddle point also define our DMFT. We thus identify the kernels that render S locally stationary (
, the moment-generating function Z is exponentially dominated by the saddle point of S. The equations that define this saddle point also define our DMFT. We thus identify the kernels that render S locally stationary ( ). The most important equations are those which define
). The most important equations are those which define 

where  denotes an average over the stochastic process induced by
denotes an average over the stochastic process induced by  , which is defined below
, which is defined below

where we define base cases  and
and  ,
,  . We see that the fields
. We see that the fields  , which represent the single site preactivations and pre-gradients, are implicit functionals of the mean-zero Gaussian processes
, which represent the single site preactivations and pre-gradients, are implicit functionals of the mean-zero Gaussian processes  which have covariances
which have covariances  . The other saddle point equations give the linear response functions
. The other saddle point equations give the linear response functions

which arise due to dependence between the feedforward and feedback signals. We note that, in the lazy limit  , the fields approach Gaussian processes
, the fields approach Gaussian processes  ,
,  . Lastly, the final saddle point equations
. Lastly, the final saddle point equations  imply that
imply that  . The full set of equations that define the DMFT are given in appendix D.7.
. The full set of equations that define the DMFT are given in appendix D.7.
This theory is easily extended to more general architectures such as networks with varying widths by layer (appendix D.8), trainable bias parameter (appendix  ) output channels (appendix
) output channels (appendix  scheme of Yang and Hu [22].
scheme of Yang and Hu [22].
4. Solving the self-consistent DMFT
The saddle point equations obtained from the field theory discussed in the previous section must be solved self-consistently. By this we mean that, given knowledge of the kernels, we can characterize the distribution of  , and given the distribution of
, and given the distribution of  , we can compute the kernels [64, 68]. In appendix
, we can compute the kernels [64, 68]. In appendix  , from which any network observable can be computed as we discuss in appendix
, from which any network observable can be computed as we discuss in appendix  at the end of training and the sample-trace of these kernels through time. Additionally, we compare the kernels of finite width N network to the DMFT predicted kernels using a cosine-similarity alignment metric
at the end of training and the sample-trace of these kernels through time. Additionally, we compare the kernels of finite width N network to the DMFT predicted kernels using a cosine-similarity alignment metric  . Additional examples are shown in appendix figures A1 and A2.
. Additional examples are shown in appendix figures A1 and A2.

Figure 1. Neural network feature learning dynamics is captured by self-consistent dynamical mean field theory (DMFT). (a) Training loss curves on a subsample of P = 10 CIFAR-10 training points in a depth 4 (L = 3, N = 2500) tanh network ( ) trained with MSE. Increasing γ0 accelerates training. (b), (c) The distribution of preactivations at the beginning and end of training matches predictions of the DMFT. (d) The final
) trained with MSE. Increasing γ0 accelerates training. (b), (c) The distribution of preactivations at the beginning and end of training matches predictions of the DMFT. (d) The final  (at t = 100) kernel order parameters match the finite width network. (e) The temporal dynamics of the sample-traced kernels
(at t = 100) kernel order parameters match the finite width network. (e) The temporal dynamics of the sample-traced kernels  matches experiment and reveals rich dynamics across layers. (f) The alignment
matches experiment and reveals rich dynamics across layers. (f) The alignment  , defined as cosine similarity, of the kernel
, defined as cosine similarity, of the kernel  predicted by theory (DMFT) and width N networks for different N but fixed
predicted by theory (DMFT) and width N networks for different N but fixed  . Errorbars show standard deviation computed over 10 repeats. Around
. Errorbars show standard deviation computed over 10 repeats. Around  DMFT begins to show near perfect agreement with the NN. (g)–(i) The same plots but for the gradient kernel
DMFT begins to show near perfect agreement with the NN. (g)–(i) The same plots but for the gradient kernel  . Whereas finite width effects for
. Whereas finite width effects for  are larger at later layers
are larger at later layers  since variance accumulates on the forward pass, fluctuations in
since variance accumulates on the forward pass, fluctuations in  are large in early layers.
are large in early layers.
Download figure:
Standard image High-resolution image| Algorithm 1. Alternating Monte–Carlo solution to saddle point equations. |
|---|
Data:
 , Initial Guesses , Initial Guesses  , ,  , Sample count , Sample count  , Update Speed β , Update Speed β
|
Result: Final Kernels  , ,  , Network predictions through training , Network predictions through training 
|
1  , ,  |
| 2 while Kernels Not Converged do |
3 From  compute compute  and solve and solve  4
4  |
5 while
 do
do
|
6 Draw  samples samples  , ,  |
7 Solve equation (13) for each sample to get  |
8 Compute new  estimates: estimates: |
9 ![$\tilde\Phi_{\mu\alpha}^{\ell}(t,s) = \frac{1}{\mathcal S} \sum_{n \in [\mathcal S]} \phi(h_{\mu,n}^{\ell}(t) ) \phi(h_{\alpha,n}^{\ell}(s))$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn223.gif) , , ![$\tilde{G}_{\mu\alpha}^{\ell}(t,s) = \frac{1}{\mathcal S} \sum_{n \in [\mathcal S]} g^{\ell}_{\mu,n}(t) g^{\ell}_{\alpha,n}(s) $](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn224.gif) |
10 Solve for Jacobians on each sample  |
11 Compute new  estimates: estimates: |
12 ![$\tilde{\boldsymbol{A}}^{\ell} = \frac{1}{\mathcal S} \sum_{n \in [\mathcal S]} \frac{\partial \phi(\boldsymbol{h}_{n}^{\ell})}{\partial \boldsymbol{r}^{\ell \top}_n} \ , \tilde{\boldsymbol{B}}^{\ell-1} = \frac{1}{\mathcal S} \sum_{n \in [\mathcal S]} \frac{\partial \boldsymbol{g}_n^{\ell}}{\partial \boldsymbol{u}^{\ell\top}_n}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn227.gif) |
13  |
| 14 end |
15  |
16 while
 do
do
|
17 Update feature kernels:  , ,  |
18 if
 then
then
|
19 Update 
|
| 20 end |
21 
|
| 22 end |
| 23 end |
24 return

|
4.1. Deep linear networks: closed form self-consistent equations
Deep linear networks ( ) are of theoretical interest since they are simpler to analyze than nonlinear networks but preserve nontrivial training dynamics and feature learning [23, 25, 32, 69–73]. In a deep linear network, we can simplify our saddle point equations to algebraic formulas that close in terms of the kernels
) are of theoretical interest since they are simpler to analyze than nonlinear networks but preserve nontrivial training dynamics and feature learning [23, 25, 32, 69–73]. In a deep linear network, we can simplify our saddle point equations to algebraic formulas that close in terms of the kernels  ,
,  [22]. This is a significant simplification since it allows the solution of the saddle point equations without a sampling procedure.
[22]. This is a significant simplification since it allows the solution of the saddle point equations without a sampling procedure.
To describe the result, we first introduce a vectorization notation ![$\boldsymbol{h}^{\ell} = \text{Vec}\{h_{\mu}^{\ell}(t) \}_{\mu\in [P], t \in \mathbb{R}_+}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn85.gif) . Likewise we convert kernels
. Likewise we convert kernels ![$\boldsymbol{H}^{\ell} = \text{Mat}\{H^{\ell}_{\mu\alpha}(t,s) \}_{\mu,\alpha \in [P], t,s \in \mathbb{R}_+}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn86.gif) into matrices. The inner product under this vectorization is defined as
into matrices. The inner product under this vectorization is defined as  . In a practical computational implementation, the theory would be evaluated on a grid of T time points with discrete time GD, so these kernels
. In a practical computational implementation, the theory would be evaluated on a grid of T time points with discrete time GD, so these kernels  would indeed be matrices of the appropriate size. The fields
would indeed be matrices of the appropriate size. The fields  are linear functionals of independent Gaussian processes
are linear functionals of independent Gaussian processes  , giving
, giving  . The matrices
. The matrices  and
and  are causal integral operators which depend on
are causal integral operators which depend on  and
and  respectively which we define in appendix
respectively which we define in appendix

Examples of the predictions obtained by solving these systems of equations are provided in figure 2. We see that these DMFT equations describe kernel evolution for networks of a variety of depths and that the change in each layer's kernel increases with the depth of the network.

Figure 2. Deep linear network with the full DMFT. (a) The train loss for NNs of varying L. (b) For a  NN, the kernels
NN, the kernels  at the end of training compared to DMFT theory on P = 20 datapoints. (c) Average displacement of feature kernels for different depth networks at same γ0 value. For equal values of γ0, deeper networks exhibit larger changes to their features, manifested in lower alignment with their initial t = 0 kernels
H
. (d) The solution to the temporal components of the
at the end of training compared to DMFT theory on P = 20 datapoints. (c) Average displacement of feature kernels for different depth networks at same γ0 value. For equal values of γ0, deeper networks exhibit larger changes to their features, manifested in lower alignment with their initial t = 0 kernels
H
. (d) The solution to the temporal components of the  and
and  kernels obtained from the self-consistent equations.
kernels obtained from the self-consistent equations.
Download figure:
Standard image High-resolution imageUnlike many prior results [69–72], our DMFT does not require any restrictions on the structure of the input data but holds for any  . However, for whitened data
. However, for whitened data  we show in appendix F.1.1, appendix F.2 that our DMFT learning curves interpolate between NTK dynamics and the sigmoidal trajectories of prior works [69, 70] as γ0 is increased. For example, in the two layer (L = 1) linear network with
we show in appendix F.1.1, appendix F.2 that our DMFT learning curves interpolate between NTK dynamics and the sigmoidal trajectories of prior works [69, 70] as γ0 is increased. For example, in the two layer (L = 1) linear network with  , the dynamics of the error norm
, the dynamics of the error norm  takes the form
takes the form  where
where  . These dynamics give the linear convergence rate of the NTK if
. These dynamics give the linear convergence rate of the NTK if  but approaches logistic dynamics of [70] as
but approaches logistic dynamics of [70] as  . Further,
. Further,  only grows in the
only grows in the  direction with
direction with  . At the end of training
. At the end of training ![$\boldsymbol{H}(t) \to \mathbf{I} + \frac{1}{y^2}[\sqrt{1+\gamma_0^2 y^2}-1] \boldsymbol{y}\boldsymbol{y}^{\top}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn111.gif) , recovering the rank one spike which was recently obtained in the small initialization limit [74]. We show this one dimensional system in figure A3.
, recovering the rank one spike which was recently obtained in the small initialization limit [74]. We show this one dimensional system in figure A3.
4.2. Feature learning with L2 regularization
As we show in appendix  . If neural network is homogenous in its parameters so that
. If neural network is homogenous in its parameters so that  (examples include networks with linear, ReLU, quadratic activations), then the final network predictor is a kernel regressor with the final NTK
(examples include networks with linear, ReLU, quadratic activations), then the final network predictor is a kernel regressor with the final NTK ![$\lim_{t\to\infty} f(\boldsymbol{x},t) = \boldsymbol{k}(\boldsymbol{x})^{\top} [ \boldsymbol{K} + \lambda \kappa \mathbf{I}]^{-1} \boldsymbol{y}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn114.gif) where
where  is the final-NTK,
is the final-NTK, ![$[\boldsymbol{k}(\boldsymbol{x})]_{\mu} = K(\boldsymbol{x},\boldsymbol{x}_{\mu})$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn116.gif) and
and ![$[\boldsymbol{K}]_{\mu\alpha} = K(\boldsymbol{x}_{\mu},\boldsymbol{x}_{\alpha})$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn117.gif) . We note that the effective regularization λκ increases with depth L. In NTK parameterization, weight decay in infinite width homogenous networks gives a trivial fixed point
. We note that the effective regularization λκ increases with depth L. In NTK parameterization, weight decay in infinite width homogenous networks gives a trivial fixed point  and consequently a zero predictor f → 0 [75]. However, as we show in figure 3, increasing feature learning γ0 can prevent convergence to the trivial fixed point, allowing a non-zero fixed point for
and consequently a zero predictor f → 0 [75]. However, as we show in figure 3, increasing feature learning γ0 can prevent convergence to the trivial fixed point, allowing a non-zero fixed point for  even at infinite width. The kernel and function dynamics can be predicted with DMFT. The fixed point is a nontrivial function of the hyperparameters
even at infinite width. The kernel and function dynamics can be predicted with DMFT. The fixed point is a nontrivial function of the hyperparameters  .
.

Figure 3. Width N = 1000 ReLU networks trained with L2 regularization have nontrivial fixed point in DMFT limit ( ). (a) Training loss dynamics for a L = 1 ReLU network with λ = 1. In
). (a) Training loss dynamics for a L = 1 ReLU network with λ = 1. In  limit the fixed point is trivial
limit the fixed point is trivial  . The final loss is a decreasing function of γ0. (b) The final kernel is more aligned with target with increasing γ0. Networks with homogenous activations enjoy a representer theorem at infinite-width as we show in appendix
. The final loss is a decreasing function of γ0. (b) The final kernel is more aligned with target with increasing γ0. Networks with homogenous activations enjoy a representer theorem at infinite-width as we show in appendix
Download figure:
Standard image High-resolution image5. Approximation schemes
We now compare our exact DMFT with approximations of prior work, providing an explanation of when these approximations give accurate predictions and when they break down.
5.1. Gradient independence ansatz
We can study the accuracy of the ansatz  , which is equivalent to treating the weight matrices
, which is equivalent to treating the weight matrices  and
and  which appear in forward and backward passes respectively as independent Gaussian matrices. This assumption was utilized in prior works on signal propagation in deep networks in the lazy regime [76–80]. A consequence of this approximation is the Gaussianity and statistical independence of
which appear in forward and backward passes respectively as independent Gaussian matrices. This assumption was utilized in prior works on signal propagation in deep networks in the lazy regime [76–80]. A consequence of this approximation is the Gaussianity and statistical independence of  and
and  (conditional on
(conditional on  ) in each layer as we show in appendix
) in each layer as we show in appendix  (the static kernel regime) since
(the static kernel regime) since  or around initialization t ≈ 0 but begins to fail at larger values of
or around initialization t ≈ 0 but begins to fail at larger values of  (figures 4 and A4).
(figures 4 and A4).

Figure 4. Comparison of DMFT to various approximation schemes in a L = 5 hidden layer, width N = 1000 linear network with  and P = 100. (a) The loss for the various approximations do not track the true trajectory induced by gradient descent in the large γ0 regime. (b), (c) The feature kernels
and P = 100. (a) The loss for the various approximations do not track the true trajectory induced by gradient descent in the large γ0 regime. (b), (c) The feature kernels  across each of the L = 5 hidden layers for each of the theories is compared to a width 1000 neural network. Again, we plot the sample-traced dynamics
across each of the L = 5 hidden layers for each of the theories is compared to a width 1000 neural network. Again, we plot the sample-traced dynamics  . (d) The alignment of
. (d) The alignment of  compared to the finite NN
compared to the finite NN  averaged across
averaged across  for varying γ. The predictions of all of these theories coincide in the
for varying γ. The predictions of all of these theories coincide in the  limit but begin to deviate in the feature learning regime. Only the nonperturbative DMFT is accurate over a wide range of γ0.
limit but begin to deviate in the feature learning regime. Only the nonperturbative DMFT is accurate over a wide range of γ0.
Download figure:
Standard image High-resolution image5.2. Small-feature learning perturbation theory at infinite-width
In the  limit, we recover static kernels, giving linear dynamics identical to the NTK limit [6]. Corrections to this lazy limit can be extracted at small but finite γ0. This is conceptually similar to recent works which consider perturbation series for the NTK in powers of
limit, we recover static kernels, giving linear dynamics identical to the NTK limit [6]. Corrections to this lazy limit can be extracted at small but finite γ0. This is conceptually similar to recent works which consider perturbation series for the NTK in powers of  [27, 28, 35] (though not identical, see [81] for finite N effects in mean-field parameterization). We expand all observables
[27, 28, 35] (though not identical, see [81] for finite N effects in mean-field parameterization). We expand all observables  in a power series in γ0, giving
in a power series in γ0, giving  and compute corrections up to
and compute corrections up to  . We show that the
. We show that the  and
and  corrections to kernels vanish, giving leading order expansions of the form
corrections to kernels vanish, giving leading order expansions of the form  and
and  (see appendix P.2). Further, we show that the NTK has relative change at leading order which scales linearly with depth
(see appendix P.2). Further, we show that the NTK has relative change at leading order which scales linearly with depth  , which is consistent with finite width effective field theory at
, which is consistent with finite width effective field theory at  [26–28] (appendix P.6). Further, at the leading order correction, all temporal dependencies are controlled by
[26–28] (appendix P.6). Further, at the leading order correction, all temporal dependencies are controlled by  functions
functions  and
and  , which is consistent with those derived for finite width NNs using a truncation of the neural tangent hierarchy [27, 34, 35]. To lighten notation, we focus our main text comparison of our non-perturbative DMFT to perturbation theory in the deep linear case. Full perturbation theory is in appendix P.2.
, which is consistent with those derived for finite width NNs using a truncation of the neural tangent hierarchy [27, 34, 35]. To lighten notation, we focus our main text comparison of our non-perturbative DMFT to perturbation theory in the deep linear case. Full perturbation theory is in appendix P.2.
Using the timescales derived in the previous section, we find that the leading order correction to the kernels in infinite-width deep linear network have the form

We see that the relative change in the NTK  , so that large depth L networks exhibit more significant kernel evolution, which agrees with other perturbative studies [25, 27, 35] as well as the nonperturbative results in figure 2. However at large γ0 and large L, this theory begins to break down as we show in figure 4.
, so that large depth L networks exhibit more significant kernel evolution, which agrees with other perturbative studies [25, 27, 35] as well as the nonperturbative results in figure 2. However at large γ0 and large L, this theory begins to break down as we show in figure 4.
6. Feature learning dynamics is preserved across widths
Our DMFT suggests that for networks sufficiently wide for their kernels to concentrate, the dynamics of loss and kernels should be invariant under the rescaling  , which keeps γ0 fixed. To evaluate how well this idea holds in a realistic deep learning problem, we trained convolutional neural networks (CNNs) of varying channel counts N on two-class CIFAR classification [82]. We tracked the dynamics of the loss and the last layer
, which keeps γ0 fixed. To evaluate how well this idea holds in a realistic deep learning problem, we trained convolutional neural networks (CNNs) of varying channel counts N on two-class CIFAR classification [82]. We tracked the dynamics of the loss and the last layer  kernel. The results are provided in figure 5. We see that dynamics are largely independent of rescaling as predicted. Further, as expected, larger γ0 leads to larger changes in kernel norm and faster alignment to the target function y, as was also found in [83]. Consequently, the higher γ0 networks train more rapidly. The trend is consistent for width N = 250 and N = 500. More details about the experiment can be found in appendix C.2 and figure A5.
kernel. The results are provided in figure 5. We see that dynamics are largely independent of rescaling as predicted. Further, as expected, larger γ0 leads to larger changes in kernel norm and faster alignment to the target function y, as was also found in [83]. Consequently, the higher γ0 networks train more rapidly. The trend is consistent for width N = 250 and N = 500. More details about the experiment can be found in appendix C.2 and figure A5.

Figure 5. The dynamics of a depth 5 (L = 4 hidden) CNNs trained on first two classes of CIFAR (boat vs plane) exhibit consistency for different channel counts  for fixed
for fixed  . (a) We plot the test loss (MSE) and (b) test classification error. Networks with higher γ0 train more rapidly. Time is measured in every 100 update steps. (c) The dynamics of the last layer feature kernel
. (a) We plot the test loss (MSE) and (b) test classification error. Networks with higher γ0 train more rapidly. Time is measured in every 100 update steps. (c) The dynamics of the last layer feature kernel  , shown as alignment to the target function. As predicted by the DMFT, higher γ0 corresponds to more active kernel evolution, evidenced by larger change in the alignment.
, shown as alignment to the target function. As predicted by the DMFT, higher γ0 corresponds to more active kernel evolution, evidenced by larger change in the alignment.
Download figure:
Standard image High-resolution image7. Discussion
We provided a unifying DMFT derivation of feature dynamics in infinite networks trained with gradient based optimization. Our theory interpolates between lazy infinite-width behavior of a static NTK in  and rich feature learning. At
and rich feature learning. At  , our DMFT construction agrees with the stochastic process derived previously with the TPs framework [22]. Our saddle point equations give self-consistency conditions which relate the stochastic fields to the kernels. These equations are exactly solveable in deep linear networks and can be efficiently solved with a numerical method in the nonlinear case. Comparisons with other approximation schemes show that DMFT can be accurate at a much wider range of γ0. We believe our framework could be a useful perspective for future theoretical analyses of feature learning and generalization in wide networks.
, our DMFT construction agrees with the stochastic process derived previously with the TPs framework [22]. Our saddle point equations give self-consistency conditions which relate the stochastic fields to the kernels. These equations are exactly solveable in deep linear networks and can be efficiently solved with a numerical method in the nonlinear case. Comparisons with other approximation schemes show that DMFT can be accurate at a much wider range of γ0. We believe our framework could be a useful perspective for future theoretical analyses of feature learning and generalization in wide networks.
Though our DMFT is quite general in regards to the data and architecture, the technique is not entirely rigorous and relies on heuristic physics techniques. Our theory holds in the  and may break down otherwise; other asymptotic regimes (such as
and may break down otherwise; other asymptotic regimes (such as  , etc) may exhibit phenomena relevant to deep learning practice [32, 84]. Indeed, many experiements find that finite width effects appear to grow dynamically during learning (with T and P) and hinder the performance of models [45, 81, 85, 86]. The computational requirements of our method, while smaller than the exponential time complexity for exact solution [22], are still significant for large
, etc) may exhibit phenomena relevant to deep learning practice [32, 84]. Indeed, many experiements find that finite width effects appear to grow dynamically during learning (with T and P) and hinder the performance of models [45, 81, 85, 86]. The computational requirements of our method, while smaller than the exponential time complexity for exact solution [22], are still significant for large  . In table 1, we compare the time taken for various theories to compute the feature kernels throughout T steps of GD. For a width N network, computation of each forward pass on all P data points takes
. In table 1, we compare the time taken for various theories to compute the feature kernels throughout T steps of GD. For a width N network, computation of each forward pass on all P data points takes  computations. The static NTK requires computation of
computations. The static NTK requires computation of  entries in the kernel which do not need to be recomputed. However, the DMFT requires matrix multiplications on PT × PT matrices giving a
entries in the kernel which do not need to be recomputed. However, the DMFT requires matrix multiplications on PT × PT matrices giving a  time scaling. Future work could aim to improve the computational overhead of the algorithm, by considering data averaged theories [64] or one pass SGD [22]. Alternative projected versions of GD have also enabled much better computational scaling in the evaluation of the theoretical predictions [46], allowing evaluation on full CIFAR-10.
time scaling. Future work could aim to improve the computational overhead of the algorithm, by considering data averaged theories [64] or one pass SGD [22]. Alternative projected versions of GD have also enabled much better computational scaling in the evaluation of the theoretical predictions [46], allowing evaluation on full CIFAR-10.
Table 1. Computational requirements to compute kernel dynamics and trained network predictions on P points in a depth N neural network on a grid of T time points trained with P data points for various theories. DMFT is faster and less memory intensive than a width N network only if  . It is more computationally efficient to compute full DMFT kernels than leading order perturbation theory when
. It is more computationally efficient to compute full DMFT kernels than leading order perturbation theory when  . The expensive scaling with both samples and time are the cost of a full-batch non-perturbative theory of gradient based feature learning dynamics.
. The expensive scaling with both samples and time are the cost of a full-batch non-perturbative theory of gradient based feature learning dynamics.
| Requirements | Width-N NN | Static NTK | Perturbative | Full DMFT |
|---|---|---|---|---|
| Memory for kernels |

|

|

|

|
| Time for kernels |

|

|

|

|
| Time for final outputs |

|

|

|

|
Since the first appearance of our work in conference proceedings [87], we have extended our DMFT technique beyond GD-based training on a loss function to study the dynamics of other, more biologically-plausible learning rules such as feedback alignment and Hebbian learning [88]. Such rules follow updates with pseudo-gradient fields  which provide a bioplausible approximation to the true backprogagation signals. In this case, the key order parameters to consider are the feature kernels
which provide a bioplausible approximation to the true backprogagation signals. In this case, the key order parameters to consider are the feature kernels  and the gradient-pseudogradient correlators
and the gradient-pseudogradient correlators  . Successful feature learning enhances the gradient-pseudogradient alignment measured with
. Successful feature learning enhances the gradient-pseudogradient alignment measured with  . As in the present work, the kernels
. As in the present work, the kernels  and the distribution of preactivations and pregradients are related self-consistently at infinite width.
and the distribution of preactivations and pregradients are related self-consistently at infinite width.
It remains an open question how much deep learning phenomena can be captured by this infinite width feature learning limit of network dynamics. A recent empirical study analyzed the loss dynamics, individual network logits, and internal feature kernels and preactivation distributions of networks trained at different widths, finding that for simple tasks like CIFAR-10, networks across widths exhibit consistency across these observables in the mean field/µ parameterization [86]. However, for harder tasks such as ImageNet or token prediction on the C4 dataset, wider networks exhibit distinct dynamics, often training faster and updating features more rapidly. The differences across widths in performance and learned representations motivates the development of theoretical methods beyond the mean-field analysis presented here, which can characterize finite size effects on learning dynamics in the feature learning regime [28, 29, 81].
Acknowledgments
This work was supported by NSF Grant DMS-2134157 and an award from the Harvard Data Science Initiative Competitive Research Fund. B B acknowledges additional support from the NSF-Simons Center for Mathematical and Statistical Analysis of Biology at Harvard (Award #1764269) and the Harvard Q-Bio Initiative.
We thank Jacob Zavatone-Veth, Alex Atanasov, Abdulkadir Canatar, and Ben Ruben for comments on this manuscript as well as Greg Yang, Boris Hanin, Yasaman Bahri, and Jascha Sohl-Dickstein for useful discussions.
Appendix A: Additional figures

Figure A1. Self-consistent DMFT reproduces two layer (L = 1 hidden layer, width N = 2000) ReLU NN's preactivation density, loss dynamics and learned kernel. (a) The loss is obtained by taking saddle point results for  and calculating the NTK's dynamics. The
and calculating the NTK's dynamics. The  limit is governed by a static NTK, while the
limit is governed by a static NTK, while the  network exhibits kernel evolution and accelerated training. (b) We plot the preactivation h distribution for neurons in the hidden layer of the trained NN against the theoretical densities defined by
network exhibits kernel evolution and accelerated training. (b) We plot the preactivation h distribution for neurons in the hidden layer of the trained NN against the theoretical densities defined by ![$\mathcal Z[\Phi,G]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn190.gif) . For small γ0, the final distribution is approximately Gaussian, but becomes non-Gaussian, asymmetric, and heavy tailed for large γ0. The DMFT estimate of the distribution is noisy due to the finite sampling error. (c) The pre-gradient distribution p(z) in the trained network has larger final variance for large γ0. (d), (e) The final
. For small γ0, the final distribution is approximately Gaussian, but becomes non-Gaussian, asymmetric, and heavy tailed for large γ0. The DMFT estimate of the distribution is noisy due to the finite sampling error. (c) The pre-gradient distribution p(z) in the trained network has larger final variance for large γ0. (d), (e) The final  are accurately predicted by the field theory and exhibit a block structure that increases with γ0 due to feature learning.
are accurately predicted by the field theory and exhibit a block structure that increases with γ0 due to feature learning.
Download figure:
Standard image High-resolution image
Figure A2. Self-consistent DFT reproduces loss dynamics, and kernels through time in a L = 3 tanh network. (a) The loss when training on synthetic data is obtained by taking saddle point results for  and calculating the NTK's dynamics. The
and calculating the NTK's dynamics. The  limit is governed by a static NTK, while the
limit is governed by a static NTK, while the  network exhibits kernel evolution and accelerated training. Solid lines are a N = 2000 NN and dashed lines are from solving DMFT equations. (b), (c) The final learned kernels Φ (b) and G (c) are accurately predicted by the field theory and exhibits block structure due to clustering by class identity. (d) The temporal components of
network exhibits kernel evolution and accelerated training. Solid lines are a N = 2000 NN and dashed lines are from solving DMFT equations. (b), (c) The final learned kernels Φ (b) and G (c) are accurately predicted by the field theory and exhibits block structure due to clustering by class identity. (d) The temporal components of  reveals nontrivial dynamical structure.
reveals nontrivial dynamical structure.
Download figure:
Standard image High-resolution image
Figure A3. Error and kernel dynamics obtained by solving a one-dimensional ODE system for a depth-2 linear network. (a)  error dynamics from appendix F.1.1 allows one to solve for
error dynamics from appendix F.1.1 allows one to solve for  by solving a one-dimensional ODE at each value of γ0. The learning curves interpolate between exponential convergence at small γ0 and logistic sigmoidal trajectories at large γ0. (b) The projection of the kernel
by solving a one-dimensional ODE at each value of γ0. The learning curves interpolate between exponential convergence at small γ0 and logistic sigmoidal trajectories at large γ0. (b) The projection of the kernel  along the task relevant subspace
along the task relevant subspace  .
.
Download figure:
Standard image High-resolution image
Figure A4. Gradient independence fails to characterize feature learning dynamics in networks with L > 1 and large γ0. (a) Loss curves for deep linear networks predicted under gradient independence ansatz for  . (b) The predicted and experimental feature kernels
. (b) The predicted and experimental feature kernels  for the L = 5 hidden layer network demonstrate that gradient independence underestimates the size of kernel adaptation.
for the L = 5 hidden layer network demonstrate that gradient independence underestimates the size of kernel adaptation.
Download figure:
Standard image High-resolution image
Figure A5. Repeating the experiment of figure 5 with depth 7 (L = 6 hidden layer) CNN trained on two class CIFAR over a wide range of γ0 with  . We find consistent agreement of loss and prediction dynamics across widths but finite size effects become more significant when computing feature kernels of deeper layers. We note that, while higher γ0 is associated with faster convergence, the final test accuracy for this model is roughly insensitive to choice of γ0.
. We find consistent agreement of loss and prediction dynamics across widths but finite size effects become more significant when computing feature kernels of deeper layers. We note that, while higher γ0 is associated with faster convergence, the final test accuracy for this model is roughly insensitive to choice of γ0.
Download figure:
Standard image High-resolution imageAppendix B: Algorithmic implementation
The alternating sample-and-solve procedure we develope and describe below for nonlinear networks is based on numerical recipes used in the dynamical mean field simulations in computational physics [68]. The basic principle is to leverage the fact that, conditional on kernels, we can easily draw samples  from their appropriate GPs. From these sampled fields, we can identify the kernel order parameters by simple estimation of the appropriate moments.
from their appropriate GPs. From these sampled fields, we can identify the kernel order parameters by simple estimation of the appropriate moments.
The parameter β controls the recency weighting of the samples obtained at each iteration. If β = 1, then the rank of the kernel estimates is limited to the number of samples  used in a single iteration, but with β < 1 smaller sample sizes
used in a single iteration, but with β < 1 smaller sample sizes  can be used to still obtain accurate results. We used β = 0.6 in our deep network experiments. Convergence is usually achieved in around ∼15 steps for a depth 4 (L = 3 hidden layer) network such as the one in figures 1 and A2.
can be used to still obtain accurate results. We used β = 0.6 in our deep network experiments. Convergence is usually achieved in around ∼15 steps for a depth 4 (L = 3 hidden layer) network such as the one in figures 1 and A2.
Appendix C: Experimental details
All NN training is performed with a Jax GD optimizer [89] with a fixed learning rate.
C.1. MLP experiments
For the MLP experiments, we perform full batch GD. Networks are initialized with Gaussian weights with unit standard deviation  . The learning rate is chosen as
. The learning rate is chosen as  for a network of width N. The hidden features
for a network of width N. The hidden features  are stored throughout training and used to compute the kernels
are stored throughout training and used to compute the kernels  . These experiments can be reproduced with the provided jupyter notebooks on our Github.
. These experiments can be reproduced with the provided jupyter notebooks on our Github.
C.2. CNN experiments on CIFAR-10
We define a depth-L CNN model with ReLU activations and stride 1, which is implemented as a pytree of parameters in JAX [89]. We apply global average pooling in the final layer before a dense readout layer. The code to initialize and evaluate the model is provided on our Github in the file titled scratch_cnn_expt.ipynb.
After constructing a CNN model, we train using MSE loss with the base learning rate  , batch size 250. The learning rate passed to the optimizer is thus
, batch size 250. The learning rate passed to the optimizer is thus  . We optimize the loss function which is scaled appropriately as
. We optimize the loss function which is scaled appropriately as  . Throughout training, we compute the last layer's embedding
. Throughout training, we compute the last layer's embedding  on the test set to calculate the alignment
on the test set to calculate the alignment  . Training is performed on 4 NVIDIA GPUs. Training a L = 3 network of width 500 takes roughly 1 h.
. Training is performed on 4 NVIDIA GPUs. Training a L = 3 network of width 500 takes roughly 1 h.
Appendix D: Derivation of self-consistent dynamical field theory
In this section, we introduce the dynamical field theory setup and saddle point equations. The path integral theory we develop is based on the Martin–Siggia–Rose–De Dominicis–Janssen (MSRDJ) framework [47], of which a useful review for random recurrent networks can be found here [54]. Similar computations can be found in recent works which consider typical behavior in high-dimensional classification on random data [63, 64].
D.1. Deep network field definitions and scaling
As discussed in the main text, we consider the following wide network architecture parameterized by trainable weights  , giving network output fµ
defined as
, giving network output fµ
defined as

Using gradient flow with learning rate η on cost  for loss function, we introduce functions
for loss function, we introduce functions  and η for learning rate, and gradient flow induces the following dynamics
and η for learning rate, and gradient flow induces the following dynamics

Since  is
is  at initialization, it is clear that to have
at initialization, it is clear that to have  evolution of the network output at initialization we need
evolution of the network output at initialization we need  . With this scaling, we have the following
. With this scaling, we have the following

Now, to build a valid field theory, we want to express everything in terms of features  rather than parameters
θ
and we will define the following gradient features
rather than parameters
θ
and we will define the following gradient features  which admit the recursion and base case
which admit the recursion and base case

We define the pre-gradient field  so that
so that  . From these quantities, we can derive the gradients with respect to parameters
. From these quantities, we can derive the gradients with respect to parameters

which allows us to compute the NTK in terms of these features

where  is the input Gram matrix. We see that the NTK can be built out of the following primitive kernels
is the input Gram matrix. We see that the NTK can be built out of the following primitive kernels

We utilize the parameter space dynamics to express  in terms of the
in terms of the  fields
fields

Using the field recurrences  we can derive the following recursive dynamics for the features
we can derive the following recursive dynamics for the features

In the above, we implicitly utilize the base cases for the feature kernels  and
and  . We also introduced the following random fields
. We also introduced the following random fields  which involve the random initial conditions
which involve the random initial conditions

We observe that the dynamics of the hidden features is controlled by the factor  . If
. If  then we recover static NTK in the limit as
then we recover static NTK in the limit as  . However, if
. However, if  then we obtain
then we obtain  evolution of our features and we reach a new rich regime. We choose the scaling
evolution of our features and we reach a new rich regime. We choose the scaling  for our field theory so that
for our field theory so that  will give a feature learning network.
will give a feature learning network.
D.2. Warmup: DMFT for one hidden layer NN
In this section, we provide a warmup problem of a L = 1 hidden layer network which allows us to illustrate the mechanics of the MSRDJ formalism. A more detailed computation can be found in the next section. Though many of the interesting dynamical aspects of the deep network case are missing in the two layer case, our aim is to show a simple application of the ideas. The fields of interest are  and
and  . Unlike the deeper
. Unlike the deeper  case, both of these fields are time invariant since
case, both of these fields are time invariant since  does not vary in time. These random fields provide initial conditions for the preactivation and pre-gradient fields
does not vary in time. These random fields provide initial conditions for the preactivation and pre-gradient fields  , which evolve according to
, which evolve according to

where the network predictions evolve as ![$\frac{\partial}{\partial t} f_{\mu}(t) = \sum_{\alpha} [\Phi_{\mu\alpha}(t,t) + G_{\mu\alpha}(t,t) K^x_{\mu\alpha} ] \Delta_{\alpha}(t)$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn278.gif) for kernels
for kernels  and
and  . At finite N, the kernels
. At finite N, the kernels  will depend on the random initial conditions
will depend on the random initial conditions  , leading to a predictor fµ
which varies over initializations. If we can establish that the kernels
, leading to a predictor fµ
which varies over initializations. If we can establish that the kernels  concentrate at infinite-width
concentrate at infinite-width  , then
, then  are deterministic. We now study the moment generating function for the fields
are deterministic. We now study the moment generating function for the fields

To perform the average over  , we enforce the definition of
, we enforce the definition of  with delta functions
with delta functions

Though this step may seem redundant in this example, it will be very helpful in the deep network case, so we pursue it for illustration. After mulitplying by these factors of unity and performing the Gaussian integrals, we obtain

We now aim to enforce the definitions of the kernel order parameters with delta functions

where the fields  are regarded as functions of
are regarded as functions of  (see equation (D.11)) and the
(see equation (D.11)) and the  integrals run over the imaginary axis
integrals run over the imaginary axis  . After this step, we can write
. After this step, we can write

where the DMFT action ![$S[\Phi,\hat{\Phi},G,\hat{G}]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn292.gif) is
is  and has the form
and has the form

The single site moment generating function ![$\mathcal Z[j,v]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn294.gif) arises from the factorization of the integrals over N different fields in the hidden layer and takes the form
arises from the factorization of the integrals over N different fields in the hidden layer and takes the form

where, again, we must regard  as functions of
as functions of  . The variables in the above are no longer vectors in
. The variables in the above are no longer vectors in  but rather are scalars. We can write
but rather are scalars. We can write ![$\mathcal Z[j,v] = \int \prod_{\mu} \mathrm{d}\chi_{\mu} \mathrm{d}\hat{\chi}_{\mu} \mathrm{d}\xi \mathrm{d}\hat{\xi} \exp\left( - \mathcal{H}[\{\chi_{\mu},\hat\chi_{\mu}\},\xi,\hat\xi, j, v] \right)$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn298.gif) where
where  is the logarithm of the integrand above. Since the full MGF takes the form
is the logarithm of the integrand above. Since the full MGF takes the form ![$Z \propto \int \mathrm{d}\Phi \mathrm{d}\hat\Phi \mathrm{d}G\mathrm{d}\hat{G} \exp\left( N S[\Phi,\hat\Phi,G,\hat G] \right)$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn300.gif) , characterization of the
, characterization of the  limit requires one to identify the saddle point of S, where
limit requires one to identify the saddle point of S, where  for any variation of these four order parameters.
for any variation of these four order parameters.

where the ith single site average  of an observable
of an observable  is defined as
is defined as

Since  the single site MGF reveals that the initial fields are independent Gaussians
the single site MGF reveals that the initial fields are independent Gaussians  and
and  . At zero source
. At zero source  , all single site averages
, all single site averages  are equivalent and we may merely write
are equivalent and we may merely write  , where
, where  is the average over the single site distributions for
is the average over the single site distributions for  .
.
D.2.1. Final L = 1 DMFT equations.
Putting all of the saddle point equations together, we arrive at the following DMFT

We see that for L = 1 networks, it suffices to solve for the kernels on the time-time diagonal. Further in this two layer case  are independent and do not vary in time. These facts will not hold in general for
are independent and do not vary in time. These facts will not hold in general for  networks, which requires a more intricate analysis as we show in the next section.
networks, which requires a more intricate analysis as we show in the next section.
D.3. Path integral formulation for deep networks
As discussed in the main text, we study the distribution over fields by computing the moment generating functional for the stochastic processes 

Moments of these stochastic fields can be computed through differentiation of Z near zero-source

To perform the average over the initial parameters, we enforce the definition of the fields  ,
,  , by inserting the following terms in the definition of
, by inserting the following terms in the definition of ![$Z[\{\boldsymbol{j},\boldsymbol{v}\}]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn318.gif) so we may more easily perform the average over weights
so we may more easily perform the average over weights  . We enforce these definitions with an integral representation of the Dirac-Delta function
. We enforce these definitions with an integral representation of the Dirac-Delta function  . We note that we are implicitly working in the Ito scheme, where factors of Jacobian determinants are equal to one [54, 90, 91] (we note that
. We note that we are implicitly working in the Ito scheme, where factors of Jacobian determinants are equal to one [54, 90, 91] (we note that  does not causally depend on
does not causally depend on  and
and  does not causally depend on
does not causally depend on  ). Applying this to fields
). Applying this to fields  , we have
, we have

where  are understood to be stochastic processes which are causally determined by the
are understood to be stochastic processes which are causally determined by the  fields, in the sense that
fields, in the sense that  only depends on
only depends on  for s < t. We thus have an expression of the form
for s < t. We thus have an expression of the form

Since  are all Gaussian random variables, these averages can be performed quite easily, yielding
are all Gaussian random variables, these averages can be performed quite easily, yielding

D.4. Order parameters and action definition
We define the following order parameters which we will show concentrate in the  limit
limit

The NTK only depends on  so from these order parameters, we can compute the function evolution. The parameter
so from these order parameters, we can compute the function evolution. The parameter  arises from the coupling of the fields across a single layer's initial weight matrix
arises from the coupling of the fields across a single layer's initial weight matrix  . We can again enforce these definitions with integral representations of the Dirac-delta function. For each pair of samples
. We can again enforce these definitions with integral representations of the Dirac-delta function. For each pair of samples  and each pair of times
and each pair of times  , we multiply by
, we multiply by

for all  and analogously
and analogously

for  . After introducing these order parameters into the definition of the partition function, we have a factorization of the integrals over each of the N sites in each hidden layer. This gives the following partition function
. After introducing these order parameters into the definition of the partition function, we have a factorization of the integrals over each of the N sites in each hidden layer. This gives the following partition function


We thus see that the action S consists of inner-products between order parameters  and their duals
and their duals  as well as a single site MGF
as well as a single site MGF ![$\mathcal{Z}[\{\Phi, \hat\Phi, G,\hat G, A, B , j, v\}]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn341.gif) , which is defined as
, which is defined as

D.5. Saddle point equations
Since the integrand in the moment generating function Z takes the form ![$e^{N S[\{\Phi,\hat\Phi,G,\hat G, A, B\}]}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn342.gif) , the
, the  limit can be obtained from saddle point integration, also known as the method of steepest descent [92]. This consists of finding order parameters
limit can be obtained from saddle point integration, also known as the method of steepest descent [92]. This consists of finding order parameters  which render the action S locally stationary. Concretely, this leads to the following saddle point equations.
which render the action S locally stationary. Concretely, this leads to the following saddle point equations.

We use the notation  to denote an average over the self-consistent distribution on fields induced by the single-site moment generating function
to denote an average over the self-consistent distribution on fields induced by the single-site moment generating function  at the saddle point. Concretely if
at the saddle point. Concretely if ![$\mathcal Z = \int \mathrm{d}\chi \mathrm{d}\xi \mathrm{d}\hat\chi \mathrm{d}\hat\xi \exp ( - \mathcal H[\chi, \xi ,\hat\chi, \hat\xi] )$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn347.gif) then the single-site self-consistent average of observable
then the single-site self-consistent average of observable ![$O([\chi, \xi ,\hat\chi, \hat\xi])$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn348.gif) is defined as
is defined as

To calculate the averages of the dual variables such as  , it will be convenient to work with vector and matrix notation. We let
, it will be convenient to work with vector and matrix notation. We let ![$\boldsymbol{\chi}^{\ell} = \text{Vec}\{\chi_{\mu}^{\ell}(t) \}_{\mu\in[P], t\in \mathbb{R}_+}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn350.gif) represent the vectorization of the stochastic process over different samples and times and define the dot product between two of these vectors as
represent the vectorization of the stochastic process over different samples and times and define the dot product between two of these vectors as  . We also apply this procedure on the kernels so that
. We also apply this procedure on the kernels so that ![$\boldsymbol{\Phi} = \text{Mat}\{\Phi_{\mu\alpha}(t,s)\}_{\mu\alpha \in [P], t,s \in \mathbb{R}_+}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn352.gif) . Matrix vector products take the form
. Matrix vector products take the form ![$[\boldsymbol{A} \boldsymbol{b}]_{\mu,t} = \int_0^{\infty} \mathrm{d}s \sum_{\alpha} A_{\mu\alpha}(t,s) b_{\alpha}(s)$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn353.gif) . We can obtain the behavior of
. We can obtain the behavior of  in terms of primal fields
in terms of primal fields  by insertion of a dummy source
u
into the effective partition function.
by insertion of a dummy source
u
into the effective partition function.

Similarly, we can obtain the equation for  by inserting a dummy source
r
and differentiating near zero source
by inserting a dummy source
r
and differentiating near zero source

As we will demonstrate in the next subsection, these correlators must vanish. Lastly, we can calculate the remaining correlators in terms of primal variables

D.6. Single site stochastic process: Hubbard trick
To get a better sense of this distribution, we can now simplify the quadratic forms appearing in  using the Hubbard trick [93], which merely relates a Gaussian function to its Fourier transform.
using the Hubbard trick [93], which merely relates a Gaussian function to its Fourier transform.

Applying this to the quadratic forms in the single-site MGF  , we get
, we get

Next, we integrate over all  variables which yield Dirac-delta functions
variables which yield Dirac-delta functions

To remedy the notational asymmetry, we redefine  as its transpose
as its transpose  . The presence of these delta-functions in the MGF
. The presence of these delta-functions in the MGF  indicate the constraints
indicate the constraints  and
and  . We can thus return to the
. We can thus return to the  and
and  saddle point equations and verify that these order parameters vanish
saddle point equations and verify that these order parameters vanish

since  . Following an identical argument,
. Following an identical argument,  . After this simplification, the single site MGF takes the form
. After this simplification, the single site MGF takes the form

The interpretation is thus that  are sampled independently from their respective Gaussian processes and the fields
are sampled independently from their respective Gaussian processes and the fields  and
and  are determined in terms of
are determined in terms of  . This means that we can apply Stein's Lemma (integration by parts) [94] to simplify the last two saddle point equations
. This means that we can apply Stein's Lemma (integration by parts) [94] to simplify the last two saddle point equations

D.7. Final DMFT equations
We can now close this stochastic process in terms of preactivations  and pre-gradients
and pre-gradients  . To match the formulas provided in the main text, we rescale
. To match the formulas provided in the main text, we rescale  and
and  , which makes it clear that the non-Gaussian corrections to the
, which makes it clear that the non-Gaussian corrections to the  fields are
fields are  . After this rescaling, we have the following complete DMFT equations.
. After this rescaling, we have the following complete DMFT equations.
The base cases in the above equations are that  and
and  and
and  . From the above self-consistent equations, one obtains the NTK dynamics and consequently the output predictions of the network with
. From the above self-consistent equations, one obtains the NTK dynamics and consequently the output predictions of the network with ![$\frac{\partial f_{\mu}}{\partial t} = \sum_{\alpha} \Delta_{\alpha}(t) \left[ \sum_{\ell} G^{\ell+1}_{\mu\alpha}(t,t) \Phi^{\ell}_{\mu\alpha}(t,t) \right]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn382.gif) .
.
D.8. Varying network widths and initialization scales
In this section, we relax the assumption of network widths being equal while taking all widths to infinity at a fixed ratio. This will allow us to analyze the influence of bottlenecks on the dynamics. We let  represent the width of layer
represent the width of layer  . Without loss of generality, we can choose that
. Without loss of generality, we can choose that  and proceed by defining order parameters in the usual way
and proceed by defining order parameters in the usual way

Since  , the variable
, the variable  as desired. We extend this definition to each layer as before
as desired. We extend this definition to each layer as before  which again satisfies the recursion
which again satisfies the recursion

Now, we need to calculate the dynamics on weights 

Using our definition of the kernels and the  fields
fields

We also find the usual formula for the NTK

Now, as before, we need to consider the distribution of  fields. We assume
fields. We assume  . This requires computing integrals like
. This requires computing integrals like

where  . The action thus takes the form
. The action thus takes the form

where the zero-source MGF for layer  has the form
has the form

The saddle point equations give

where  . We redefine
. We redefine  . To take the
. To take the  limit of the field dynamics, again use
limit of the field dynamics, again use  . The field equations take the form
. The field equations take the form

We thus find that the evolution of the scalar fields in a given layer is set by the parameter  , indicating that relatively wider layers evolve less and contribute less of a change to the overall NTK. This definition for
, indicating that relatively wider layers evolve less and contribute less of a change to the overall NTK. This definition for  is non-ideal to extract intuition about bottlenecks since
is non-ideal to extract intuition about bottlenecks since  and
and  . To remedy this, we redefine
. To remedy this, we redefine  . With this choice, we have
. With this choice, we have

where  do not have a leading order scaling with
do not have a leading order scaling with  or
or  respectively. Under this change of variables, it is now apparent that a very wide layer
respectively. Under this change of variables, it is now apparent that a very wide layer  , where
, where  is small, the fields
is small, the fields  become well approximated by the Gaussian processes
become well approximated by the Gaussian processes  , albeit with evolving covariances
, albeit with evolving covariances  respectively. In a realistic CNN architecture where the number of channels increases across layers, this result would predict that more feature learning and deviations from Gaussianity to occur in the early layers and the later layers to be well approximated as Gaussian fields
respectively. In a realistic CNN architecture where the number of channels increases across layers, this result would predict that more feature learning and deviations from Gaussianity to occur in the early layers and the later layers to be well approximated as Gaussian fields  with temporally evolving covariances for
with temporally evolving covariances for  . We leave evaluation of this prediction to future work.
. We leave evaluation of this prediction to future work.
Appendix E: Two-layer networks
In a two-layer network, there are no
A
or
B
order parameters, so the fields χ1 and ξ1 are always independent. Further, χ1 and ξ1 are both constant throughout training dynamics. Thus we can obtain differential rather than integral equations for the stochastic fields  which are
which are

where the average is taken over the random initial conditions  and
and  . An example of the two-layer theory for a ReLU network can be found in appendix figure A1. In this two-layer setting, a drift PDE can be obtained for the joint density of preactivations and feedback fields
. An example of the two-layer theory for a ReLU network can be found in appendix figure A1. In this two-layer setting, a drift PDE can be obtained for the joint density of preactivations and feedback fields 

which is a zero-diffusion feature space version of the PDE derived in the original two-layer mean field limit of neural networks [21, 42, 43].
Appendix F: Deep linear networks
In the deep linear case, the  fields are independent of sample index µ. We introduce the kernel
fields are independent of sample index µ. We introduce the kernel  . The field equations are
. The field equations are

Or in vector notation  and
and  where
where

Using the formulas which define the fields, we have

The saddle point equations can thus be written as

We solve these equations by repeatedly updating  , using equation (F.4) and the current estimate of
, using equation (F.4) and the current estimate of  . We then use the new
. We then use the new  to recompute
to recompute  and
and  , calculating
, calculating  and then recomputing
and then recomputing  . This procedure usually converges in approximately five to ten steps.
. This procedure usually converges in approximately five to ten steps.
F.1. Two-layer linear network
As we saw in appendix E, the field dynamics simplify considerably in the two-layer case, allowing the description of all fields in terms of differential equations. In a two-layer linear network, we let  represent the hidden activation field and
represent the hidden activation field and  represent the gradient
represent the gradient

The kernels  and
and  thus evolve as
thus evolve as

It is easy to verify that the network predictions on the P training points are  . Thus the dynamics of
. Thus the dynamics of  and
and  close
close

where the initial conditions are  ,
,  and
and  . These equations hold for any choice of data
. These equations hold for any choice of data  .
.
F.1.1. Whitened data in two-layer linear network.
For input data which is whitened where  , then the dynamics can be simplified even further, recovering the sigmoidal curves very similar to those obtained under a special initialization [69, 70, 72, 74]. In this case we note that the error signal always evolves in the
y
direction,
, then the dynamics can be simplified even further, recovering the sigmoidal curves very similar to those obtained under a special initialization [69, 70, 72, 74]. In this case we note that the error signal always evolves in the
y
direction,  , and that
H
only evolves in a rank one direction
, and that
H
only evolves in a rank one direction  direction as well. Let
direction as well. Let  . Let
. Let  represent the norm of the target vector, then the relevant scalar dynamics are
represent the norm of the target vector, then the relevant scalar dynamics are

Now note that, at initialization  and that
and that  . Thus, we have an automatic balancing condition
. Thus, we have an automatic balancing condition  for all
for all  and the dynamics reduce to two variables
and the dynamics reduce to two variables

We note that this system obeys a conservation law which constrains  to a hyperbola
to a hyperbola

This conservation law implies that  or that the final kernel has the form
or that the final kernel has the form ![$\lim_{t\to\infty} \boldsymbol{H}(t) = \frac{1}{y^2}[\sqrt{1 + \gamma_0^2 y^2 } -1 ] \boldsymbol{y} \boldsymbol{y}^{\top} + \mathbf{I}$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn451.gif) . The result that the final kernel becomes a rank one spike in the direction of the target function was also obtained in finite width networks in the limit of small initialization [74] and also from a normative toy model of feature learning [83]. We can use the conservation law above
. The result that the final kernel becomes a rank one spike in the direction of the target function was also obtained in finite width networks in the limit of small initialization [74] and also from a normative toy model of feature learning [83]. We can use the conservation law above  to simplify the dynamics to a one-dimensional system
to simplify the dynamics to a one-dimensional system

where  . We see that increasing γ0 provides strict acceleration in the learning dynamics, illustrating the training benefits of feature evolution. Since this system is separable, we can solve for the time it takes for the network output norm to reach output level f
. We see that increasing γ0 provides strict acceleration in the learning dynamics, illustrating the training benefits of feature evolution. Since this system is separable, we can solve for the time it takes for the network output norm to reach output level f

The NTK limit can be obtained by taking  which gives
which gives

which recovers the usual convergence rate of a linear model. The right hand side of equation (F.12) has a perturbation series in γ0
2 which converges in the disk  . The other limit of interest is the
. The other limit of interest is the  limit where
limit where

which recovers the logistic growth observed in the initialization scheme of prior works [69, 70]. The timescale τ required to learn is only  , which is much smaller than the
, which is much smaller than the  time to learn predicted from the small γ0 expansion. We note that the above leading order asymptotic behavior at large γ0 considers the DMFT initial condition
time to learn predicted from the small γ0 expansion. We note that the above leading order asymptotic behavior at large γ0 considers the DMFT initial condition  as an unstable fixed point. For realistic learning curves, one would need to stipulate some alternative initial condition such as
as an unstable fixed point. For realistic learning curves, one would need to stipulate some alternative initial condition such as  for some small
for some small  > 0 in order to have nontrivial leading order dynamics.
> 0 in order to have nontrivial leading order dynamics.
F.2. Deep linear whitened data
In this section, we examine the role of depth when linear networks are trained on whitened data. As in the two-layer case, all hidden kernels  need only be tracked in the one-dimensional task relevant subspace along the vector
y
. We let
need only be tracked in the one-dimensional task relevant subspace along the vector
y
. We let  and let
and let  . We have
. We have

Lastly, we have the simple evolution equation for the scalar error 

Vectorizing we find the following equations for the time × time matrix order parameters  , we can solve for the response functions
, we can solve for the response functions  and
and  . This formulation has the advantage that it no longer has any sample-size dependence: arbitrary sample sizes can be considered with no computational cost.
. This formulation has the advantage that it no longer has any sample-size dependence: arbitrary sample sizes can be considered with no computational cost.
Appendix G: Convolutional networks with infinite channels
The DMFT described in this work can be extended to CNNs with infinitely many channels, much in the same way that infinite CNNs have a well defined kernel limit [95, 96]. We let  represent the value of the filter at spatial displacement
represent the value of the filter at spatial displacement  from the center of the filter, which maps relates activity at channel j of layer
from the center of the filter, which maps relates activity at channel j of layer  to channel i of layer
to channel i of layer  . The fields
. The fields  are defined recursively as
are defined recursively as

where  is the spatial receptive field at layer
is the spatial receptive field at layer  . For example, a
. For example, a  convolution will have
convolution will have  . The output function is obtained from the last layer is defined as
. The output function is obtained from the last layer is defined as  . The gradient fields have the same definition as before
. The gradient fields have the same definition as before  , which as before enjoy the following recursion from the chain rule
, which as before enjoy the following recursion from the chain rule

The dynamics of each set of filters  can therefore be written in terms of the features
can therefore be written in terms of the features 

The feature space description of the forward and backward pass relations is

where  . The order parameters for this network architecture are
. The order parameters for this network architecture are

These two order parameters per layer collectively define the NTK. Following the computation in appendix D, we obtain the following field theory in the  limit:
limit:

We see that this field theory essentially multiplies the number of sample indices by the number of spatial indices  . Thus the time complexity of evaluation of this theory scales very poorly as
. Thus the time complexity of evaluation of this theory scales very poorly as  , rendering DMFT solutions very computationally intensive.
, rendering DMFT solutions very computationally intensive.
Appendix H: Trainable bias parameter
If we include a bias  in our trainable model, so that
in our trainable model, so that

then the dynamics on  induced by gradient flow is
induced by gradient flow is

Assuming that  , the dynamics of the DMFT becomes
, the dynamics of the DMFT becomes

Appendix I: Multiple output channels
We now consider network outputs on  classes. The prediction for a data point
classes. The prediction for a data point ![$\mu \in [P] $](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn489.gif) at time
at time  is
is  . As before, we define the error signal as
. As before, we define the error signal as  . For any pair of data points
. For any pair of data points  the NTK is a C × C matrix
the NTK is a C × C matrix  with entries
with entries  . From these matrices, we can compute the evolution of the predictions in the network.
. From these matrices, we can compute the evolution of the predictions in the network.

In this case, we have matrices for the backprop features  . These satisfy the usual recursion
. These satisfy the usual recursion

We can now compute the NTK for samples 

where  and
and  . Next we introduce kernels
. Next we introduce kernels  and
and  which are defined in the usual way. The corresponding field theory has the form
which are defined in the usual way. The corresponding field theory has the form

From these fields, the saddle point equations define the kernels as

This allows us to study the multi-class structure of learned representations.
Appendix J: Weight decay in deep homogenous networks
If we train with weight decay,  , in a κ-degree homogenous network (
, in a κ-degree homogenous network ( ), then the prediction dynamics satisfy
), then the prediction dynamics satisfy

This holds by the following identity  , which when evaluated at c = 1 gives
, which when evaluated at c = 1 gives  . This identity was utilized in a prior work which studied L2 regularization in the lazy regime [75]. For a L-hidden layer ReLU network
. This identity was utilized in a prior work which studied L2 regularization in the lazy regime [75]. For a L-hidden layer ReLU network  , the degree is
, the degree is  , while rectified power law nonlinearities
, while rectified power law nonlinearities  give degrees
give degrees  . We note that the fixed point of the function dynamics above gives a representer theorem with the final NTK
. We note that the fixed point of the function dynamics above gives a representer theorem with the final NTK

where ![$[\boldsymbol{k}(x)]_{\mu} = \lim_{t\to\infty }K(\boldsymbol{x},\boldsymbol{x}_{\mu}, t)$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn510.gif) and
and  . The prior work of Lewkowycz and Gur-Ar [75] considered NTK parameterization
. The prior work of Lewkowycz and Gur-Ar [75] considered NTK parameterization  . In this limit, the kernel (and consequently output function) decay to zero at large time, but if
. In this limit, the kernel (and consequently output function) decay to zero at large time, but if  , then the network converges to a nontrivial fixed point as
, then the network converges to a nontrivial fixed point as  . In the DMFT limit we can determine the final kernel by solving the following field dynamics
. In the DMFT limit we can determine the final kernel by solving the following field dynamics

We see that the contribution from initial conditions is exponentially suppressed at large time t while the second term contributes most when the system has equilibrated. We provide an example of the weight decay DMFT showing its validity in a two layer ReLU network in figure 3.
Appendix K: Bayesian/Langevin trained mean field networks
Rather than studying exact gradient flow, many works have considered Langevin dynamics (gradient flow with white noise process on the weights) of neural network training [25, 30–32, 97]. This setting is of special theoretical interest since the distribution of parameters converges at long times to a Gibbs equilibrium distribution which has a Bayesian interpretation [3, 4, 97]. The relevant Langevin equation for our mean field gradient flow is

where λ is a ridge penalty which controls the scale of parameters, and  is a Brownian motion term which has covariance structure
is a Brownian motion term which has covariance structure  . The parameter β, known as the inverse temperature controls the scale of the random Gaussian noise injected into this stochastic process. The dynamical early-time treatment of the
. The parameter β, known as the inverse temperature controls the scale of the random Gaussian noise injected into this stochastic process. The dynamical early-time treatment of the  limit will coincide with our usual DMFT while the
limit will coincide with our usual DMFT while the  will exhibit a nontrivial balance between the usual DMFT feature updates and the random Langevin noise. At late times, such a system will equilibrate to its Gibbs distribution.
will exhibit a nontrivial balance between the usual DMFT feature updates and the random Langevin noise. At late times, such a system will equilibrate to its Gibbs distribution.
K.1. Dynamical analysis
In this section we analyze the DMFT for these Langevin dynamics. First we note that the effect of regularization can be handled with a simple integrating factor

where  is the Gaussian noise for layer
is the Gaussian noise for layer  at time t. It is straightforward to verify by Ito's lemma that, under mean field parameterization, the fluctuations in
at time t. It is straightforward to verify by Ito's lemma that, under mean field parameterization, the fluctuations in  dynamics due to Brownian motion are
dynamics due to Brownian motion are  and are thus negligible in the
and are thus negligible in the  limit. Thus the evolution of the network function takes the form
limit. Thus the evolution of the network function takes the form

We can express both of these parameter contractions in feature space provided we introduce the new features  which are necessary to compute Hessian terms like
which are necessary to compute Hessian terms like ![$\frac{\partial^2 f}{\partial W_{ij}^{\ell} \partial W^{\ell}_{ij}} = N^{-3/2} \frac{\partial }{\partial W^{\ell}_{ij}} [ g_i^{\ell+1} \phi(h_j^{\ell})] = N^{-2} \ r_i \ \phi(h_j^{\ell})^2$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn525.gif) in each layer. This gives the following evolution
in each layer. This gives the following evolution

As before, we compute the next layer field  in terms of
in terms of  and
and  in terms of
in terms of 

The dependence on the initial condition through  is suppressed at long times due the regularization factor
is suppressed at long times due the regularization factor  , while the Brownian motion and gradient updates will survive in the
, while the Brownian motion and gradient updates will survive in the  limit. In addition to the usual
limit. In addition to the usual  fields which arise from the initial condition, we see that
fields which arise from the initial condition, we see that  also depend on the following fields which arise from the integrated Brownian motion
also depend on the following fields which arise from the integrated Brownian motion

Our aim is now to compute the moment generating function for the  fields which causally determine
fields which causally determine  . This MGF has the form
. This MGF has the form

We insert Dirac-delta functions in the usual way to enforce the definitions of  and then average over
and then average over  . These averages can be performed separately with the
. These averages can be performed separately with the  average giving the identical terms as derived in previous sections. We focus on the average over Brownian disorder
average giving the identical terms as derived in previous sections. We focus on the average over Brownian disorder


where we introduced the order parameter  . We will use the shorthand for the temporal prefactor in the above
. We will use the shorthand for the temporal prefactor in the above ![$C_{\lambda,\beta}(t,t^{^{\prime}}) = \frac{1}{\lambda} \exp\left( - \frac{\lambda}{\beta}(t+t^{^{\prime}}) \right) \left[ e^{2 \frac{\lambda}{\beta} \min\{t,t^{^{\prime}}\}} - 1 \right] \sim_{t,t^{^{\prime}} \to \infty} \frac{1}{\lambda} \exp\left( - \frac{\lambda}{\beta} |t-t^{^{\prime}}| \right)$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn541.gif) . We insert a Lagrange multiplier
. We insert a Lagrange multiplier  to enforce the definition of
to enforce the definition of  . After
. After

The order parameters can be determined by the saddle point equations. These equations for  are the same as before. The new equations are
are the same as before. The new equations are

Using the fact that  concentrate, we can use the Hubbard trick to linearize the quadratic terms in
concentrate, we can use the Hubbard trick to linearize the quadratic terms in  and
and  .
.


Using the vectorization notation, we find the interpretation that  and
and  decouple as
decouple as


As before, we make the substitutions  and
and  and arrive at the final DMFT equations
and arrive at the final DMFT equations

where the kernels are defined in the usual way. As expected, the contributions from the initial conditions  are exponentially suppressed at late time whereas the contributions from the Brownian disorder
are exponentially suppressed at late time whereas the contributions from the Brownian disorder  persist at late time.
persist at late time.
K.2. Weak feature learning, long time limit
In the weak feature learning  and long time
and long time  limit, the preactivation fields equilibrate to Gaussian processes
limit, the preactivation fields equilibrate to Gaussian processes  , which have respective covariances
, which have respective covariances  . In this long time limit, the feature kernels will be time translation invariant, e.g.
. In this long time limit, the feature kernels will be time translation invariant, e.g.  . Letting
. Letting  and
and  , we have the following recurrence for
, we have the following recurrence for 

Similarly, we can obtain  and
and  in a backward pass recursion
in a backward pass recursion

On the temporal diagonal τ = 0, these equations give the usual recursions used to compute the NNGP kernels at initialization [4], though with initialization variance  , set by the weight decay term in the Langevin dynamics. This indicates that the long time Langevin dynamics at
, set by the weight decay term in the Langevin dynamics. This indicates that the long time Langevin dynamics at  simply rescales the Gaussian weight variance based on λ. It would be interesting to explore fluctuation dissipation relationships at finite γ0 within this framework which we leave to future work.
simply rescales the Gaussian weight variance based on λ. It would be interesting to explore fluctuation dissipation relationships at finite γ0 within this framework which we leave to future work.
K.3. Equilibrium analysis
The Langevin dynamics at finite N converges (possibly in a time extensive in N) to an equilibrium distribution with several interesting properties, as was recently studied by Yang et al [97] and implicitly by Seroussi and Ringel [31] in a large sample size limit. This setting differs from the previous section where first  limit is taken, followed by a
limit is taken, followed by a  limit in the DMFT. This section, on the other hand, studies for any N, the
limit in the DMFT. This section, on the other hand, studies for any N, the  limiting equilibrium distribution. This equilibrated distribution is then analyzed in the
limiting equilibrium distribution. This equilibrated distribution is then analyzed in the  limit. The relationship between these two orders of limits remains an open problem. The equilibrium distribution over parameters
limit. The relationship between these two orders of limits remains an open problem. The equilibrium distribution over parameters  can be viewed as a Bayes posterior with log-likelihood
can be viewed as a Bayes posterior with log-likelihood  and a Gaussian prior with scale
and a Gaussian prior with scale  . In the mean field limit with
. In the mean field limit with  , we can express the density over pre-activations
, we can express the density over pre-activations  and the output predictions f. This gives
and the output predictions f. This gives

We see that ![$p(\boldsymbol{f}|\mathcal D) \propto \int \mathrm{d}\Phi \mathrm{d}\hat{\Phi} \exp\left( N S[\Phi,\hat{\Phi}] \right)$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn575.gif) where
where

Thus the predictions fµ
become nonrandom in this  limit and can be determined from the saddle point equations as in [97]. Again, letting
limit and can be determined from the saddle point equations as in [97]. Again, letting  , we find
, we find

which implies that fµ at the fixed point satisfies the following equations

The last layer's dual kernel has the form  , which we see vanishes as feature learning strength is taken to zero
, which we see vanishes as feature learning strength is taken to zero  , while for non-negligible γ0, we see that the last layer features are non-Gaussian. We thus see that the moment generating function for the last layer field has the form
, while for non-negligible γ0, we see that the last layer features are non-Gaussian. We thus see that the moment generating function for the last layer field has the form

In the  limit, the non-Gaussian component of this density vanishes. Now that we have this form, we can compute
limit, the non-Gaussian component of this density vanishes. Now that we have this form, we can compute  conditional on
conditional on  . Next, we calculate
. Next, we calculate  , giving
, giving

Again, we note that in the  limit, since
limit, since  , so that
, so that  , implying that the
, implying that the  fields are also Gaussian in this
fields are also Gaussian in this  limit. For arbitrary γ0, this recursive argument can be completed going backwards using
limit. For arbitrary γ0, this recursive argument can be completed going backwards using

For deep linear networks, the distributions are all Gaussian, allowing one to close algebraically, the saddle point equations for  [97].
[97].
Appendix L: Momentum dynamics
Standard GD often converges slowly and requires careful tuning of learning rate. Momentum, in contrast can, be stable under a wider range of learning rates and can benefit from acceleration on certain problems [98–101]. In this section we show that our field theory is still valid when training with momentum; simply altering the field definitions appropriately gives the infinite-width feature learning behavior.
Momentum uses a low-pass filtered version of the gradients to update the weights. A continuous limit of momentum dynamics on the trainable parameters  would give the following differential equations.
would give the following differential equations.

We write the expression this way so that the small time constant τ → 0 limit corresponds to classic GD. Integrating out the  variable, this gives the following weight dynamics
variable, this gives the following weight dynamics

which implies the following field evolution

We see that in the τ → 0 limit, the tʹʹ integral is dominated by the contribution at  recovering usual GD dynamics. For
recovering usual GD dynamics. For  , we see that the integral accumulates additional contributions from the past values of fields and kernels.
, we see that the integral accumulates additional contributions from the past values of fields and kernels.
Appendix M: Discrete time
Our model can also be accommodated in discrete time, though we lose the NTK as a key player in the theory (note that  requires a continuous time limit of the GD dynamics). For a discrete time analysis we let
requires a continuous time limit of the GD dynamics). For a discrete time analysis we let  and define our network function as
and define our network function as

We treat  as a potentially random variable and insert
as a potentially random variable and insert

Noting that  is involved in the definition of both
is involved in the definition of both  and
and  , we see that the average over
, we see that the average over  now takes the form
now takes the form

We extend our definition as before  . Proceeding with the calculation as usual, we find that
. Proceeding with the calculation as usual, we find that

The saddle point equations can now be analyzed. In addition to the usual order parameters, we note that  also generate saddle point equations
also generate saddle point equations

We also obtain saddle point equations for the new  order parameters.
order parameters.


which implies  and
and  . This gives the following DMFT
. This gives the following DMFT

We leave it to future work to verify that a continuous time limit of the above DMFT recovers function evolution governed by the NTK.
Appendix N: Equivalent parameterizations
In this section, we show the equivalence of our parameterization scheme with many alternatives including the  parameterization of Yang and Hu [22]. We also compare the derived stochastic processes obtained with DMFT and TPs in appendix N.6. Following Yang we use a modified variant of abc parameterization. We will assume the following parameterization and initialization
parameterization of Yang and Hu [22]. We also compare the derived stochastic processes obtained with DMFT and TPs in appendix N.6. Following Yang we use a modified variant of abc parameterization. We will assume the following parameterization and initialization

and we consider training with gradient flow dynamics

The learning rate is scaled as  with
with  . The factor of γ2 in the learning rate η ensures that
. The factor of γ2 in the learning rate η ensures that  does not depend on γ. Lastly, we will scale the Chizat and Bach feature learning parameter as
does not depend on γ. Lastly, we will scale the Chizat and Bach feature learning parameter as  . We will ultimately find that only
. We will ultimately find that only  will allow stable feature learning in the infinite width
will allow stable feature learning in the infinite width  limit.
limit.
We will now derive constraints on  which give desired large width behavior. We will identify a one-dimensional family of parameterizations which satisfy three desiderata of network training 1. finite preactivations, 2. learning in finite time, 3. feature learning.
which give desired large width behavior. We will identify a one-dimensional family of parameterizations which satisfy three desiderata of network training 1. finite preactivations, 2. learning in finite time, 3. feature learning.
N.1. Fields are
N
(1)

In this section, we identify conditions under which  have
have  entries which ensures that the kernels
entries which ensures that the kernels  are also
are also  . The base case for
h
1 gives us the following covariance of entries at initialization
. The base case for
h
1 gives us the following covariance of entries at initialization

Assuming that Kx
does not scale with N as  , we find the constraint that
, we find the constraint that  . Now that we have a condition for h1 to be
. Now that we have a condition for h1 to be  in its entries giving
in its entries giving  , we proceed with the induction step. We assume that
, we proceed with the induction step. We assume that  and we then find conditions which guarantee
and we then find conditions which guarantee  has
has  entries. The covariance at layer
entries. The covariance at layer  at initialization is
at initialization is

Since we are assuming under the inductive hypothesis that  , we identify the constraint
, we identify the constraint  . Again we see that
. Again we see that  works, but this is not the only possible scaling. Alternatively standard parameterization
works, but this is not the only possible scaling. Alternatively standard parameterization  will also preserve the
will also preserve the  scale of the features. To characterize prediction and feature dynamics, we next need to analyze the scale of the feature gradients
scale of the features. To characterize prediction and feature dynamics, we next need to analyze the scale of the feature gradients  . We start with the last layer and define
. We start with the last layer and define

which has  entries by construction. We similarly extend this definition to earlier layers
entries by construction. We similarly extend this definition to earlier layers  to see whether
to see whether  remains
remains  under its backward-pass recursion
under its backward-pass recursion

Now, letting  as in the main text, we have
as in the main text, we have

Under the inductive hypothesis that  and the previous constraint
and the previous constraint  , the z variables have
, the z variables have  variance. Overall, we can thus ensure that
variance. Overall, we can thus ensure that  if
if  for
for  and
and  .
.
N.2. Predictions evolve in
N
(1) time

As before we define the NTK be the matrix which characterizes network prediction dynamics  . We demand that this matrix be
. We demand that this matrix be  so that the network prediction evolution
so that the network prediction evolution 

where we used the usual definition of the kernels  and
and  which are
which are  under the assumptions of the previous section. We thus find the following constraints
under the assumptions of the previous section. We thus find the following constraints

Again this recovers the parameterization in the main text provided c = 0 and  and
and  . We see that for nonzero c, we need nonzero a0.
. We see that for nonzero c, we need nonzero a0.
N.3.
N
(1) feature evolution

Now, we desire that the fields  all evolve by an
all evolve by an  amount during network training, so that feature learning is stable. Under the assumption that
amount during network training, so that feature learning is stable. Under the assumption that  (see previous sections), the update equation for
(see previous sections), the update equation for  and
and  give
give

Now, noting that  and
and  , we have
, we have

where we used  . The above equation implies that
. The above equation implies that  is necessary and sufficient for
is necessary and sufficient for  feature evolution. An identical argument for the pregradient fields
feature evolution. An identical argument for the pregradient fields  gives the same constraint.
gives the same constraint.
N.4. Putting constraints together
The set of parameterizations which yield  feature evolution are those for which
feature evolution are those for which
- (i)Features are for and .
- (ii)Outputs predictions evolve in time ,
- (iii)Features have evolution .










The parameterization discussed in appendix D satisfies these with  . The quite general requirement for feature learning that
. The quite general requirement for feature learning that  indicates is that
indicates is that  for any choice of
for any choice of  as we use in the main text. This indicates that neural network prediction logits at initialization scale as
as we use in the main text. This indicates that neural network prediction logits at initialization scale as  in the feature learning infinite width limit. The set of parameterizations which meet these three requirements is one dimensional with
in the feature learning infinite width limit. The set of parameterizations which meet these three requirements is one dimensional with  , and
, and  for all layers except the first layer which has
for all layers except the first layer which has  . Our parameterization corresponds to
. Our parameterization corresponds to  . However, in the next section, we show that if one demands
. However, in the next section, we show that if one demands  raw learning rate
raw learning rate  , then the parameterization is unique and is the
, then the parameterization is unique and is the  parameterization of Yang and Hu [22].
parameterization of Yang and Hu [22].
N.5.
N
(1) raw learning rate

We are also interested in a parameterization for which we can have learning rate  which are those for which
which are those for which  . Under this constraint,
. Under this constraint,  and
and  for
for  and
and  and
and  , which corresponds to a modification of standard parameterization, with first and last layer altered with width. In a computational algorithm, the learning rate would be
, which corresponds to a modification of standard parameterization, with first and last layer altered with width. In a computational algorithm, the learning rate would be  . This is equivalent to the
. This is equivalent to the  parameterization stated in the main text of Yang and Hu [22].
parameterization stated in the main text of Yang and Hu [22].
N.6. Equivalence of DMFT at
and TP-derived stochastic process

Now that we have established that the parameterization we consider here (modified NTK parameterization) is equivalent to  , (modified standard parameterization), we will now demonstrate that the stochastic process which we obtained through a stationary action principle applied to our DMFT action S is equivalent to the stochastic process derived from the TP framework of Yang [22, 96]. Using the notation from appendix H of Yang and Hu [22], they give the following evolution equations for the preactivations in a hidden layer in one pass SGD
, (modified standard parameterization), we will now demonstrate that the stochastic process which we obtained through a stationary action principle applied to our DMFT action S is equivalent to the stochastic process derived from the TP framework of Yang [22, 96]. Using the notation from appendix H of Yang and Hu [22], they give the following evolution equations for the preactivations in a hidden layer in one pass SGD

where  is a mean zero Gaussian variable with covariance
is a mean zero Gaussian variable with covariance ![$\mathbb{E}[Z^{x_t} Z^{x_s}]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn702.gif) and
and  is a mean zero Gaussian with covariance
is a mean zero Gaussian with covariance ![$\mathbb{E}[Z^{\mathrm{d}h_t} Z^{\mathrm{d}h_s}]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn704.gif) . We can switch to the notation of this work by making the substitutions
. We can switch to the notation of this work by making the substitutions  ,
,  ,
,  ,
,  and
and ![$\mathbb{E}[ Z^{x_s} Z^{x_t} ] \to \Phi(t,s)$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn709.gif) , and so on. A summary of the full set of notational substitutions between this work and TP are summarized in table N1.
, and so on. A summary of the full set of notational substitutions between this work and TP are summarized in table N1.
Table N1. Dictionary relating the notation of the tensor programs (TP) framework [22] and this work.
| DMFT | h(t) |

| g(t) |

|

|

|

|

|
|---|---|---|---|---|---|---|---|---|
| TP |

|

|

|

|
![$\mathbb{E}[Z^{x_t} Z^{x_s}]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn720.gif)
|
![$\mathbb{E}[Z^{\mathrm{d}h_t} Z^{\mathrm{d}h_s}]$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn721.gif)
| θts | −χt |
After these substitutions are made, we see that the equations above match the one-pass SGD version of the DMFT equations in appendix M. A similar identification can be made for the backward pass. This shows that both TPs and DMFT, though alternative derivations, give identical descriptions of the stochastic processes induced by random initializations + GD in infinite neural networks.
Appendix O: Gradient independence
The gradient independence approximation treats the random initial weight matrix  as a independently sampled Gaussian matrix when used in the backward pass. We let this second matrix be
as a independently sampled Gaussian matrix when used in the backward pass. We let this second matrix be  . As before, we have
. As before, we have  , however we now define
, however we now define  . Now, when computing the moment generating function Z, the integrals over
. Now, when computing the moment generating function Z, the integrals over  and
and  factorize
factorize

We see that in this field theory, the fields  are all independent Gaussian processes
are all independent Gaussian processes  and
and  . This corresponds to making the assumption that
. This corresponds to making the assumption that  so that
so that  and
and  within the full DMFT.
within the full DMFT.
Appendix P: Perturbation theory
P.1. Small γ0 expansion
In this section we analyze the leading corrections in a small γ0 expansion of our DMFT theory. All fields at each time t are expanded in power series in γ0.

Our goal is to calculate all corrections to the kernels up to  to show that the leading correction is
to show that the leading correction is  and the subleading correction is
and the subleading correction is  . It will again be convenient to utilize the vector notation defined in appendix D.
. It will again be convenient to utilize the vector notation defined in appendix D.
We note that unlike other works on perturbation theory in wide networks, we do not attempt to characterize fluctuation effects in the kernels due to finite width, but rather operate in a regime where the kernels are concentrating and their variance is negligible. For a more thorough discussion of perturbative field theory in finite width networks, see [27, 28, 35].
P.1.1. Linear network.
The kernels in deep linear networks can be expanded in powers of γ0
2 giving a leading order correction of size  and can be computed explicitly from the closed saddle point equations. We use the symmetrizer
and can be computed explicitly from the closed saddle point equations. We use the symmetrizer  as shorthand. The leading order behavior of
as shorthand. The leading order behavior of  is independent of layer index so we find the following leading order corrections
is independent of layer index so we find the following leading order corrections

Note that ![$[\boldsymbol{C}^0 \boldsymbol{g}]_{\mu t} = \int_0^t \mathrm{d}t^{^{\prime}} \sum_{\beta} H^0_{\mu\beta}(t,t^{^{\prime}}) \Delta_{\beta}(t^{^{\prime}}) g(t^{^{\prime}}) = \sum_{\beta} K^x_{\mu\beta} \int_0^t \mathrm{d}t^{^{\prime}} \Delta_{\beta}(t^{^{\prime}}) g(t^{^{\prime}})$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn740.gif) and note that
and note that ![$[\boldsymbol{D} \boldsymbol{h}]_{t} = \int_0^t \mathrm{d}t^{^{\prime}} G^0(t,t^{^{\prime}}) \sum_{\alpha} \Delta_{\alpha}(t^{^{\prime}}) h_{\alpha}(t^{^{\prime}}) = \sum_{\alpha} \int_0^t \mathrm{d}t^{^{\prime}} \Delta_{\alpha}(t^{^{\prime}}) h_{\alpha}(t^{^{\prime}})$](https://content.cld.iop.org/journals/1742-5468/2023/11/114009/revision2/jstatad01b0ieqn741.gif) .
.

We can simplify the notation by introducing functions  and
and  .
.

Using the fact that

and utilizing the identity  , we recover the result provided in the main text.
, we recover the result provided in the main text.
P.2. Nonlinear perturbation theory
In this section, we explore perturbation theory in nonlinear networks. We start with the formula which implicitly defines  treated as vectors over samples and time
treated as vectors over samples and time

We proceed under the assumption of a power series in γ0

As before, the leading terms for  only depend on time through the functions
only depend on time through the functions  and
and  . Expanding both sides of the implicit equation for
. Expanding both sides of the implicit equation for  we have
we have

Performing a similar exercise for  , we get the following first three leading terms for
, we get the following first three leading terms for  , and we find
, and we find

As will become apparent soon, it is crucially important to identify the dependence of each of these terms on
r
. We note that  does not depend on r and
does not depend on r and  is linear in r. In the next section, we use this fact to show that
is linear in r. In the next section, we use this fact to show that  and
and  . These conditions imply that
. These conditions imply that  and
and  . As a consequence,
. As a consequence,  is linear in r and
is linear in r and  only contains even powers of r. Lastly, this implies that
only contains even powers of r. Lastly, this implies that  only contains even powers of r and
only contains even powers of r and  contains only odd powers of r.
contains only odd powers of r.
P.2.1. Leading corrections to Φ1 kernel is .

We start in the first layer where  (note that this is
(note that this is  ) and compute the expansion of Φ1 in γ0
) and compute the expansion of Φ1 in γ0

where powers and multiplications of vectors are taken elementwise. Now, note that, as promised, the terms linear in γ0 vanish since  is linear the Gaussian random variable
r
1, which is a mean zero and independent of
u
1 so an average like
is linear the Gaussian random variable
r
1, which is a mean zero and independent of
u
1 so an average like  must vanish for any function F. Thus we see that
must vanish for any function F. Thus we see that  's leading correction is
's leading correction is  .
.
We also obtain, by a similar argument, that the cubic  term vanishes. To see this, note that
term vanishes. To see this, note that  only contains odd powers of
r
1. Next,
only contains odd powers of
r
1. Next,  contains only odd powers of
r
, and
contains only odd powers of
r
, and  is cubic in
r
. Since all odd moments of a mean-zero Gaussian vanish, all averages of these terms over
r
annihilate, causing the γ0
3 terms to vanish. Thus
is cubic in
r
. Since all odd moments of a mean-zero Gaussian vanish, all averages of these terms over
r
annihilate, causing the γ0
3 terms to vanish. Thus  .
.
P.3. Forward pass induction for

We now assume the inductive hypothesis that for some  that
that

and we will show that this will imply that the next layer must have a similar expansion  . First, we note that
. First, we note that  . As before, we compute the leading terms in the expansion of
. As before, we compute the leading terms in the expansion of 

where, as before, the γ0 and γ0
3 terms vanish by the fact that odd moments of  vanish. Now, note that all averages are performed over
vanish. Now, note that all averages are performed over  , which depends on the perturbed kernel of the previous layer. How can we calculate the contribution of the correction which is due to the previous layer's kernel movement? This can be obtained easily from the following identity. Let
, which depends on the perturbed kernel of the previous layer. How can we calculate the contribution of the correction which is due to the previous layer's kernel movement? This can be obtained easily from the following identity. Let  be an arbitrary observable which depends on Gaussian fields
u
and
r
which have covariances
be an arbitrary observable which depends on Gaussian fields
u
and
r
which have covariances  and
and  (note this only requires that the linear in γ0 terms of G vanish which is easy to verify). Then
(note this only requires that the linear in γ0 terms of G vanish which is easy to verify). Then


where  . Thus, the leading order behavior of
. Thus, the leading order behavior of  can easily be obtained in terms of averages over the original unperturbed covariances
can easily be obtained in terms of averages over the original unperturbed covariances

where the trace is taken against the Hessian indices and the indices on  . This gives us the desired result by induction that for all
. This gives us the desired result by induction that for all  , we have
, we have  . We see that
. We see that  accumulates corrections from the previous layers' corrections through the forward pass recursion.
accumulates corrections from the previous layers' corrections through the forward pass recursion.
P.4. Leading corrections to GL
kernel is

The analogous argument for G L now can be provided. First note that r L is independent of u L and of γ0. Thus we can find that G L has no linear-in-γ0 term in its expansion since

each term contains only odd powers of
r
L
and odd moments of Gaussian variables vanish. After much more work, one can verify that  also must vanish since all terms contain odd powers of
r
.
also must vanish since all terms contain odd powers of
r
.

First, note that  is linear in
r
. Next, note that
is linear in
r
. Next, note that  only depends on even powers of
r
since
only depends on even powers of
r
since  . Next, we have
. Next, we have

which only depends on odd powers of
r
. Lastly, we have 

which we see only contains even powers of
r
. Thus  will be odd in
r
. Looking at the expansion for
will be odd in
r
. Looking at the expansion for  , we see that all terms are odd in
r
and so the averages vanish under the Gaussian integrals.
, we see that all terms are odd in
r
and so the averages vanish under the Gaussian integrals.
P.5. Backward pass recursion for

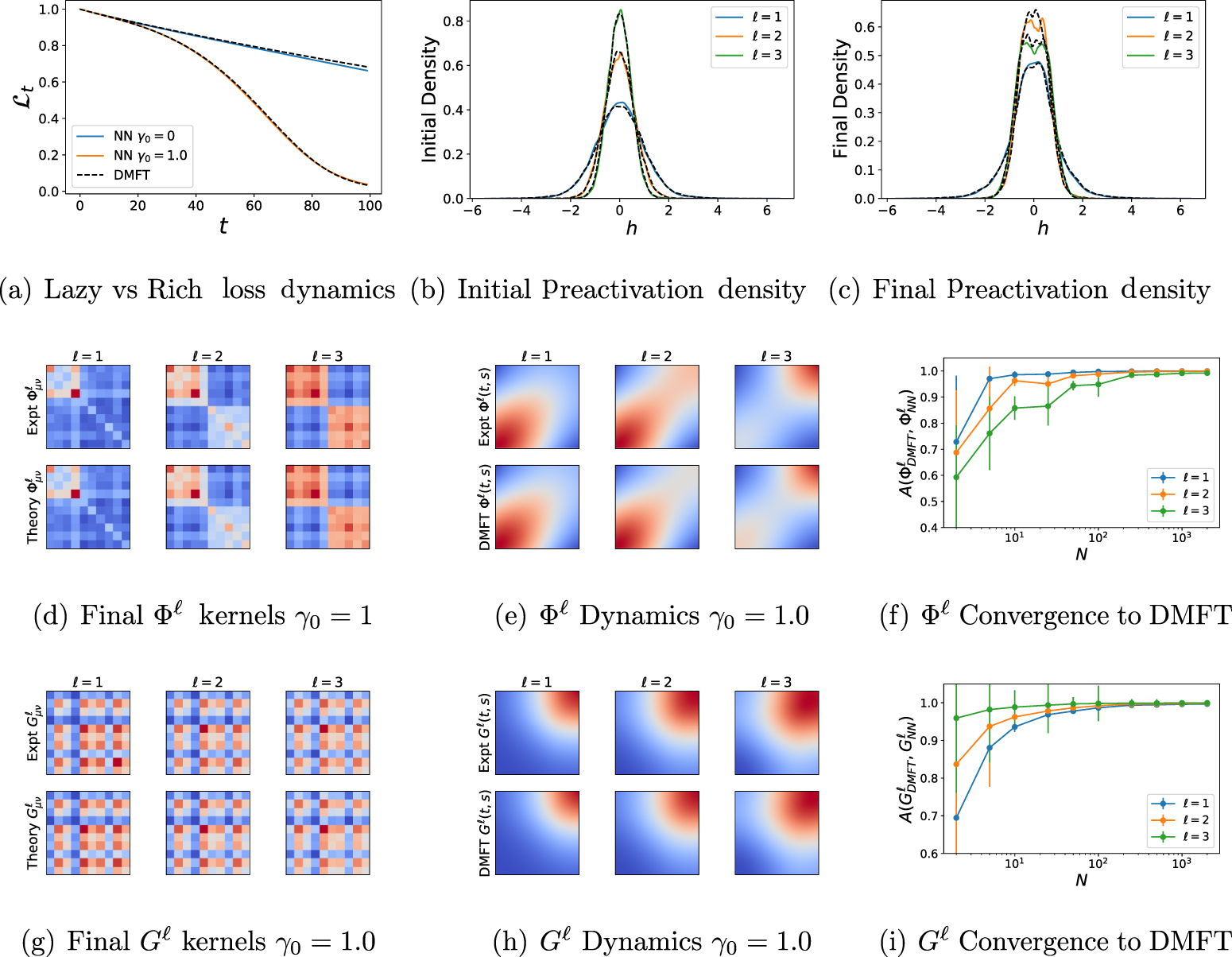{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
We can derive a similar recursion on the backward pass for  's leading order corrections. Using the same idea from the previous section, we find the following expressions
's leading order corrections. Using the same idea from the previous section, we find the following expressions

This time, we see that  accumulates corrections from succeeding layers through the backward pass recursion.
accumulates corrections from succeeding layers through the backward pass recursion.
P.6. Form of the leading corrections
We can expand the  and
and  fields around
fields around  to find the leading order corrections to each feature kernel
to find the leading order corrections to each feature kernel

The first term requires additional expansion to extract the corrections in γ0 2

where we used the fact that  which follows from the fact that
which follows from the fact that  , and
, and  . Now, expanding out term by term
. Now, expanding out term by term

We see that the corrections for the  kernels accumulate on the forward pass through the final term so
kernels accumulate on the forward pass through the final term so  . Now we will perform the same analysis for
. Now we will perform the same analysis for  .
.

We see that, through the second term, the  kernels accumulate on the backward pass so that
kernels accumulate on the backward pass so that  . As before the difficult term is the first expression which requires a full expansion of
. As before the difficult term is the first expression which requires a full expansion of  to second order
to second order

From these terms we find

Now the correction to the NTK has the form

Since each  , each of the two sums from
, each of the two sums from  gives a depth scaling of the form
gives a depth scaling of the form  . Since the original NTK has scale
. Since the original NTK has scale  , the relative change in the kernel is
, the relative change in the kernel is  . In a finite width N, network, our definition
. In a finite width N, network, our definition  would indicate that a width N network would have corrections of scale
would indicate that a width N network would have corrections of scale  in the NTK regime where
in the NTK regime where  provided the network is sufficiently wide to disregard initialization dependent fluctuations in the kernels.
provided the network is sufficiently wide to disregard initialization dependent fluctuations in the kernels.