

Abstract
We present the construction of an image similarity retrieval engine for the morphological classification of galaxies using the Convolutional AutoEncoder (CAE). The CAE is trained on 90,370 preprocessed Sloan Digital Sky Survey galaxy images listed in the Galaxy Zoo 2 (GZ2) catalog. The visually similar output images returned by the trained CAE suggest that the encoder efficiently compresses input images into latent features, which are then used to calculate similarity parameters. Our Tool for Searching a similar Galaxy Image based on a Convolutional Autoencoder using Similarity (TSGICAS) leverages this similarity parameter to classify galaxies' morphological types, enabling the identification of a wider range of classes with high accuracy compared to traditional supervised ML techniques. This approach streamlines the researcher's work by allowing quick prioritization of the most relevant images from the latent feature database. We investigate the accuracy of our automatic morphological classifications using three galaxy catalogs: GZ2, Extraction de Formes Idéalisées de Galaxies en Imagerie (EFIGI), and Nair & Abraham (NA10). The correlation coefficients between the morphological types of input and retrieved galaxy images were found to be 0.735, 0.811, and 0.815 for GZ2, EFIGI, and NA10 catalogs, respectively. Despite differences in morphology tags between input and retrieved galaxy images, visual inspection showed that the two galaxies were very similar, highlighting TSGICAS's superior performance in image similarity search. We propose that morphological classifications of galaxies using TSGICAS are fast and efficient, making it a valuable tool for detailed galaxy morphological classifications in other imaging surveys.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Galaxy morphologies can provide critical information regarding galaxy research because galaxy morphology is related to galaxy properties, evolutionary history, dynamical features, and stellar populations. The galaxies were first classified morphologically by Hubble (1926) via visual assessments. Subsequently, de Vaucouleurs (1959) divided the Hubble system's morphological classes and proposed a modified Hubble system. In recent decades, the size of galaxy image data sets has increased considerably with the releases of large sky survey projects, such as the Sloan Digital Sky Survey (SDSS; York et al. 2000). With the development of computational power, nonparametric galaxy morphological classification methods, such as the concentration, asymmetry, smoothness/clumpiness systems, Gini coefficients, and M20, were developed (Abraham et al. 2003; Conselice 2003; Lotz et al. 2004; Law et al. 2007). These methods are free from subjective bias, but they have limitations in detail classifying galaxy morphologies such as the Hubble system. Therefore, visual classification is still employed in most galaxy morphological classification.
Galaxy Zoo 2 (GZ2) project (Lintott et al. 2008, 2011; Willett et al. 2013) is representative citizen science, wherein amateurs quickly classify galaxies by answering a series of galaxy image-related questions. GZ2 successfully analyzed large-scale galaxy morphology data. Despite the successful implementation of the GZ2 project, the sheer volume of data from potential large-scale astronomical surveys (The Rubin Observatory LSST Camera (LSSTCam), James Webb Space Telescope, and Square Kilometer Array) may significantly extend the time required for the classification spanning decades or even centuries, and necessitate the use of alternative classification methods. The classification method using Machine Learning (ML) is one of the crucial alternatives in large astronomical data set analysis. Therefore, the use of ML techniques in large astronomical data set analysis is crucial.
ML-based computational tools were introduced by Fukushima (1975, 1980) and Fukushima et al. (1983). ML was developed to suit multiple applications, including the earlier astronomical investigations (Odewahn et al. 1992; Weir et al. 1995). The enhancement of computational power and ML methodologies has led to the emergence of ML as an important astronomical research tool. Supervised ML (SML) approaches have been applied in galaxy morphological classification (Maehoenen & Hakala 1995; Naim et al. 1995; Lahav et al. 1996; Ball et al. 2004; Huertas-Company et al. 2008, 2009, 2011, 2015, 2018; Shamir 2009; Dubath et al. 2011; Polsterer et al. 2012; Dieleman et al. 2015; Beck et al. 2018; Sreejith et al. 2018; Walmsley et al. 2019; Cheng et al. 2020b).
Convolutional Neural Networks (CNNs) have been utilized in image-related studies because of their unique ability to store image location information in their layers, in contrast to the traditional Multi-layer Perceptron approach. Using ImageNet data in CNN-based models (Deng et al. 2009) has shown higher accuracy than traditional manual classification tools. Therefore, CNNs have been employed for galaxy morphological classification. CNN-based SML relies heavily on the availability of labeled data sets, as it mimics human perception by training models with human-labeled data. It can accurately classify the galaxies (de la Calleja & Fuentes 2004; Khalifa et al. 2017; Cavanagh et al. 2021; Cheng et al. 2021a). However, the labeled data sets with sufficient quantity and quality are required to apply them to future surveys (Ghosh et al. 2020; Vega-Ferrero et al. 2021; Cheng et al. 2023).
One of the critical advantages of Unsupervised Machine Learning (UML) approaches is that they do not rely on labeled training data sets, making the acquisition of training data much more straightforward. These techniques have been successfully applied to classify celestial bodies such as galaxies by extracting features such as spiral arm patterns, bulges, and disk shapes (Hocking et al. 2018; Ralph et al. 2019; Cheng et al. 2020a, 2021b). This method allows the grouping of galaxies with similar morphological characteristics, making it easier to label their morphology.
With the remarkable development of ML, a novel technique has been developed for effectively compressing image features used for similar image searches in the industry (e.g., face recognition on Facebook). An autoencoder, as described by Rumelhart et al. (1986), is a type of UML network utilized for feature extraction from input images. The encoder component employs convolutional layers to generate latent features, which are then reconstructed by the decoder into an output image of the same size. The training continues until a low residual between the input and output images is achieved. The latent features generated by the encoder encapsulate essential features of the input image, including morphological parameters in the case of galaxy images. Since the proximity of latent features between two images indicates their similarity, these latent features can be utilized to compare and retrieve similar images effectively.
If a database of latent features is constructed with galaxy images of known morphological types, classification can be performed by adopting the morphological types of similar images retrieved from the database. This method is more effective than conventional morphological parameters (concentration, asymmetry, smoothness/clumpiness systems, Gini coefficients, M20, etc.) because the encoder can identify the image features more effectively. Similarity search has been applied in various astronomical studies, including galaxy morphology research, such as (Walmsley et al. 2022), which focuses on the Galaxy Zoo projects. Moreover, anomaly detection studies, like (Storey-Fisher et al. 2021), can also be considered as similarity search applications in a broader sense. As the Convolutional AutoEncoder (CAE) extracted the latent features of galaxy images regardless of the labels, it does not require re-training upon morphological types switch, unlike the SML.
While the conventional morphological system (like the Hubble system) classifies galaxies into more than ten morphological classes, most ML-based system classifies them into four or five morphological types (Gauci et al. 2010; Cavanagh et al. 2021). We developed the Tool for Searching similar Galaxy Image based on a Convolutional Autoencoder using Similarity (TSGICAS), which can distinguish more than ten morphological types.
The remainder of this paper is organized as follows. Section 2 describes the model training data sets and the preprocessing method. Section 3 describes the CAE's algorithm, training, validation of similar image searching methods, the encoder's latent feature extraction, and database creation methods. Section 4 describes morphological classifications for three galaxy catalogs. Section 5 discusses model improvement. Section 6 presents a summary and conclusions.
2. Data and Preprocessing
In modern observational astronomy, numerous survey projects have generated extensive open-source data. This data is primarily machine readable and has been standardized for scientific analysis, making it suitable for machine learning applications. The SDSS, a representative astronomical survey, is a large-scale optical survey project that provides the largest and highest-quality photometric and spectroscopic data. Our objective is to classify galaxy morphological types based on the conventional Hubble classification. To achieve this using TSGICAS, it is essential to know the morphological types of retrieved galaxies. Therefore, we adopted galaxy morphologies from three morphological catalogs: GZ2, Extraction de Formes Idealisees de Galaxies en Imagerie (EFIGI; Baillard et al. 2011) and NA10 (Nair & Abraham 2010). In the GZ2 catalog, a representative citizen science project, the galaxy morphologies are classified by a statistical method to minimize the amateur classifier's subjective influence. The EFIGI and NA10 catalogs were classified by a small number of expert astronomers via their own subjective classification but exhibited consistent classifications
2.1. Morphology Catalogs and Training Data
The GZ2 morphological classification decision tree was created using the "tuning fork" approach (Hubble 1926). The decision tree contained 11 questions and 37 responses. The classification followed the question order and the highest vote fractions. The smooth elliptical galaxies (E) were categorized into Er (round), Ei (in between), and Ec (cigar-shaped). The spiral galaxies with an arm structure or disk shape were divided into spiral galaxies with bars (SB) and without (S), respectively. The SB and S were further classified into a (dominant), b (obvious), c (just noticeable), and d (no bulge), following their size of the bulge. Their spiral arm and winding patterns were not considered. We reduced the 678 GZ2 morphological classes into 12 classes by excluding the detailed features, such as merging, disturbance, and irregularity (Table 1). The EFIGI (Baillard et al. 2011) samples contained the morphological types for 4458 galaxies (z ≲ 0.05). The EFIGI cataloged bright (−23 < Mg < −13) galaxies for reliable classification. A group of eleven experts followed RC3-like definitions (Third Reference Catalog of Bright Galaxies; de Vaucouleurs 1963) and Hubble classification (EFIGI Hubble sequence; see Table 1 of Baillard et al. 2011) to determine 18 morphological types. NA10 contained 14,034 galaxies in SDSS DR4 at 0.01 < z < 0.1 with g < 16 mag. NA10 contained 14 morphological types that followed RC3-like classification (see Table 1 of Nair & Abraham 2010).
Table 1. Adopted Morphological Types for GZ2 in this Study
| Morphology | Description |
|---|---|
| Er | Elliptical, smooth and completely rounded |
| Ei | Elliptical, smooth and in between roundness |
| Ec | Elliptical, smooth and cigar shaped |
| Edge on | Edge on |
| Sa | Spiral, no bar, dominant bulge |
| Sb | Spiral, no bar, obvious bulge |
| Sc | Spiral, no bar, just noticeable bulge |
| Sd | Spiral, no bar, no bulge |
| SBa | Spiral, bar, dominant bulge |
| SBb | Spiral, bar, obvious bulge |
| SBc | Spiral, bar, just noticeable bulge |
| SBd | Spiral, bar, no bulge |
Download table as: ASCIITypeset image
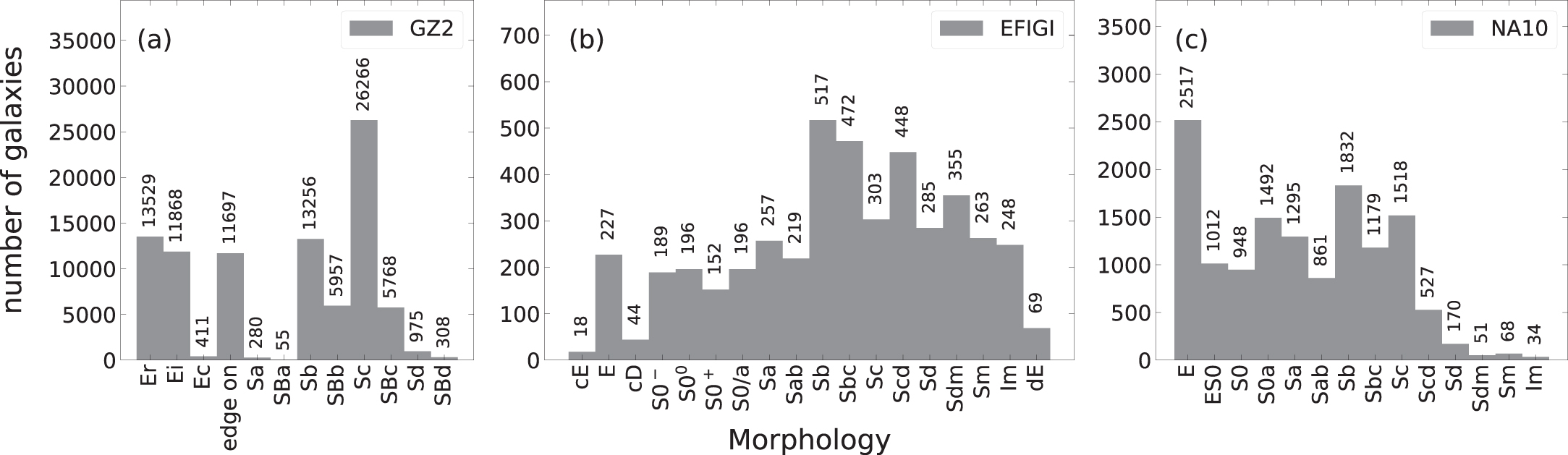
Figure 1 shows the morphological distribution of galaxies in the GZ2, NA10, and EFIGI catalogs. The GZ2 catalog has a significantly higher proportion of Sc-type spiral galaxies than Sa- and Sd-type galaxies. This is not the case for the NA10 and EFIGI catalogs. This suggests that the distribution of galaxy types in the GZ2 catalog may be affected by factors such as the expertise of the classifiers. For example, non-expert classifiers may be more likely to classify galaxies as Sc-type due to the compromise effect, which occurs when classifiers are unsure of the correct type and choose a more common type. This could lead to an underrepresentation of Sa- and Sd-type galaxies in the GZ2 catalog. On the other hand, the EFIGI catalog exhibits a more balanced distribution of morphological types, except the relatively rare cE and cD types (Figure 1(b)). In contrast, the NA10 catalog has a notably lower proportion of irregular galaxy morphologies (Sd, Sdm, Sm, and Im) than the EFIGI catalog (Figure 1(c)).

Figure 1. Galaxy morphology distributions of GZ2 (a), EFIGI (b), and NA10 (c). The number of galaxies for each type is denoted at the top of each bar.
Download figure:
Standard image High-resolution imageIdentifying the detailed structural features (e.g., spiral arm, bar, and bulge) and accurate morphological classification from a low-spatial resolution galaxy image is challenging. Also, the absolute number and variety of images are very important to train the model. Therefore, we employed the second phase of GZ2 (Willett et al. 2013), which listed high-spatial resolution galaxy images to determine the galaxy morphologies visually.
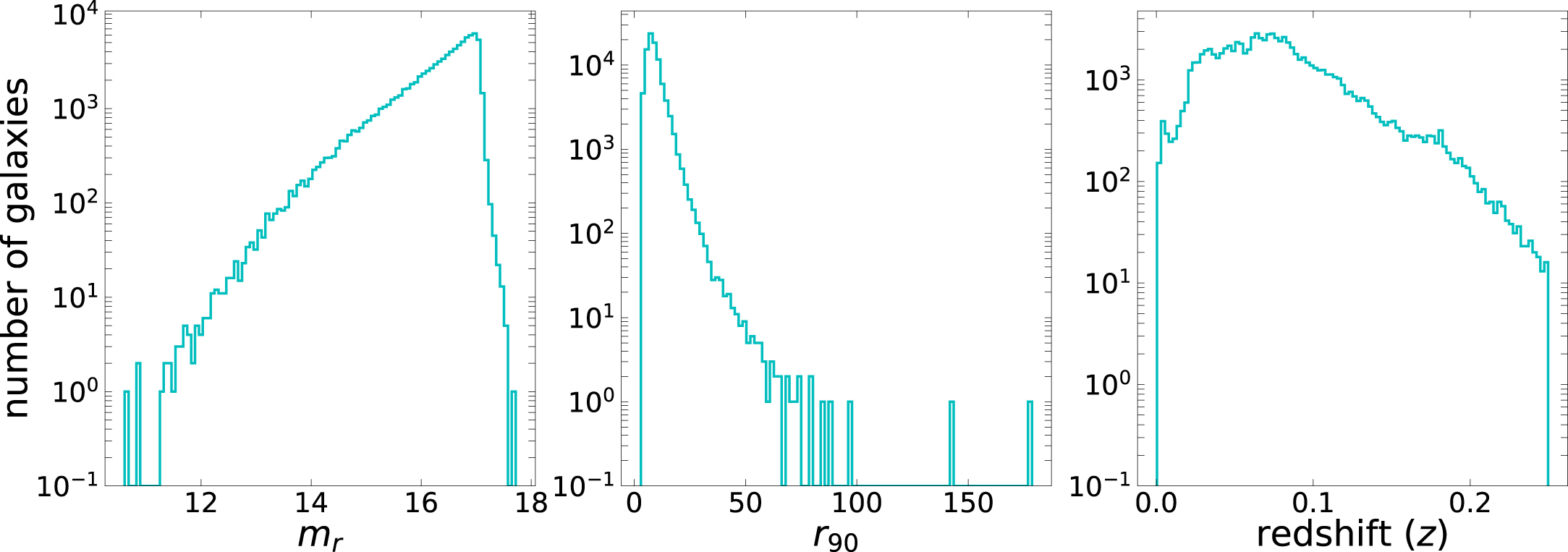
Galaxy image samples listed in GZ2 were obtained from SDSS Data Release 7 (Abazajian et al. 2009), and the target galaxies were selected from the SDSS primary galaxy samples (Strauss et al. 2002). The selection criteria for galaxies in the GZ2 project are defined as follows: apparent magnitude (mr ) less than 17 mag (or less than 17.77 mag for Stripe82, Willett et al. 2013) and a Petrosian radius (r90) greater than 3'', with a redshift (z) between 0.0005 and 0.25 (Figure 2). The total number of galaxies in GZ2 is 304,122. A total of 243,500 images exhibit spectroscopic redshift and reliable morphology. The images with flag 7 = 1 and classified as either E (smooth) or S (features or disk) galaxies were selected. The galaxy images contaminated by bright stars and unreliable background measurements were excluded. A total of 90,370 (25,808 and 64,562, for E and S galaxies, respectively) galaxy images were finally selected for ML.

Figure 2. Distribution of mr (left), r90 (middle), and redshift (right) of the 90,370 selected galaxies from GZ2.
Download figure:
Standard image High-resolution image2.2. Data Preprocessing
We downloaded the gri galaxy images in FITS format from SDSS. The images were photometrically preprocessed, and the background was subtracted. We applied a preprocessing of the images for ML as follows.
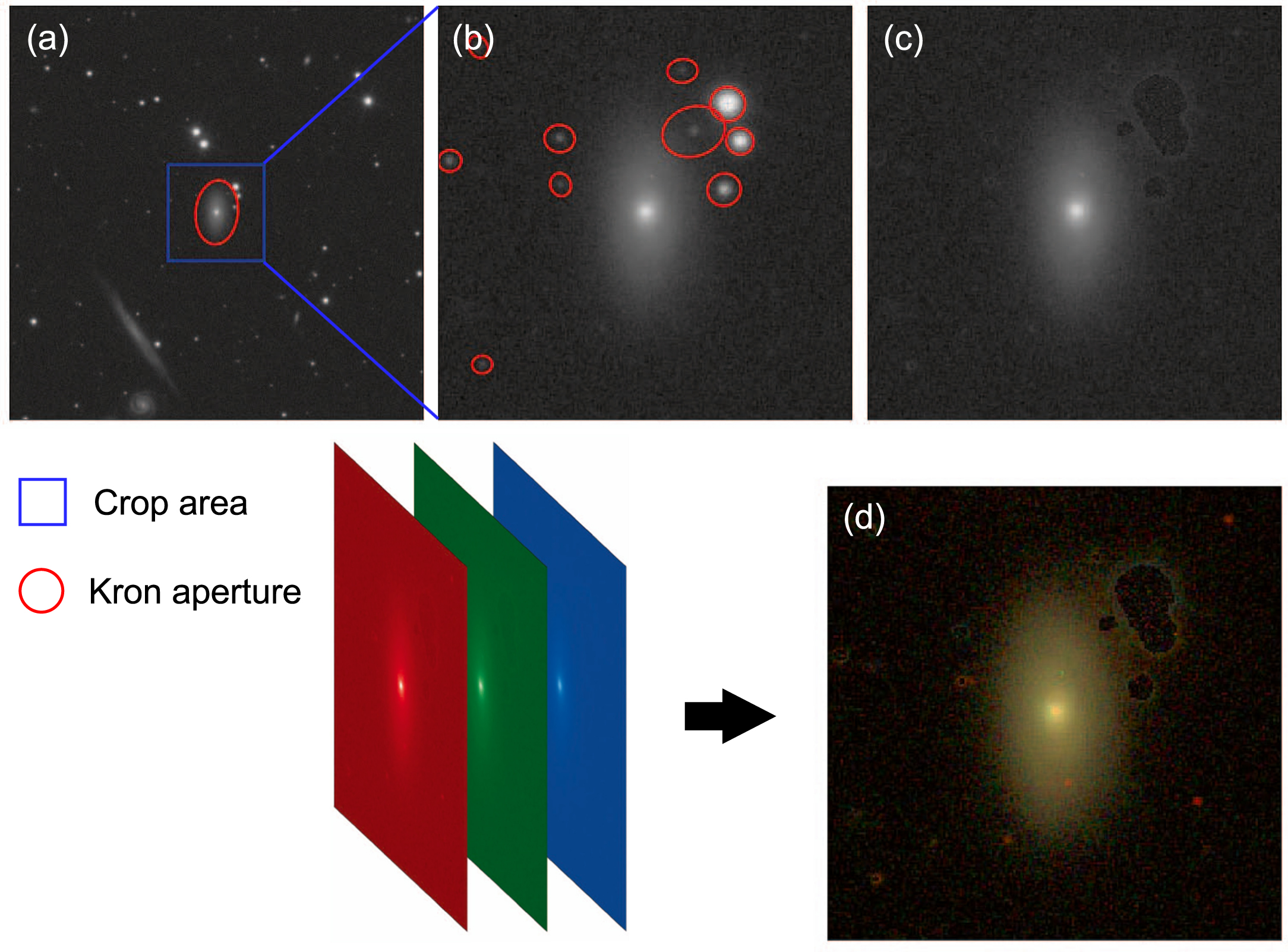
The target galaxy was located in the downloaded image's center. The image was cropped up to three times the target galaxy's Kron radius (Figures 3(a), (b)). The kron radius was calculated from the r-band image using the Astropy photutils package (Bradley et al. 2016). The galaxy's apparent size ratio to the input image size was kept constant. All the other non-target objects identified by the Python photutils package in the image were masked by filling randomly selected background values (Figures 3(b), (c)). Since ML requires fixed-sized images, the images were converted to 256 × 256 pixel size using the PyTorch Torchvision library (Paszke et al. 2019).

Figure 3. Data preprocessing method. (a) The downloaded image depicts the target galaxy in the red ellipse. The blue square depicts three times the kron radius along the semimajor axis. (b) The cropped image depicts the non-target objects in the red ellipses. (c) The cropped image depicts the masked non-target objects. (d) RGB color image.
Download figure:
Standard image High-resolution imageWith the cropped and masked gri images, RGB color images were created using make_lupton_rgb, a subpackage of astropy.visualization. The color images were rendered by 0.5 linear stretch and 10 asinh softening to match the SDSS color images. The g-, r-, and i-band fluxes were multiplied by 1.1, 1, and 0.79, respectively (Figure 3(d)) to convert them into RGB color images. The pixel values were normalized between 0 and 255.
3. Methods
3.1. Autoencoder Architecture
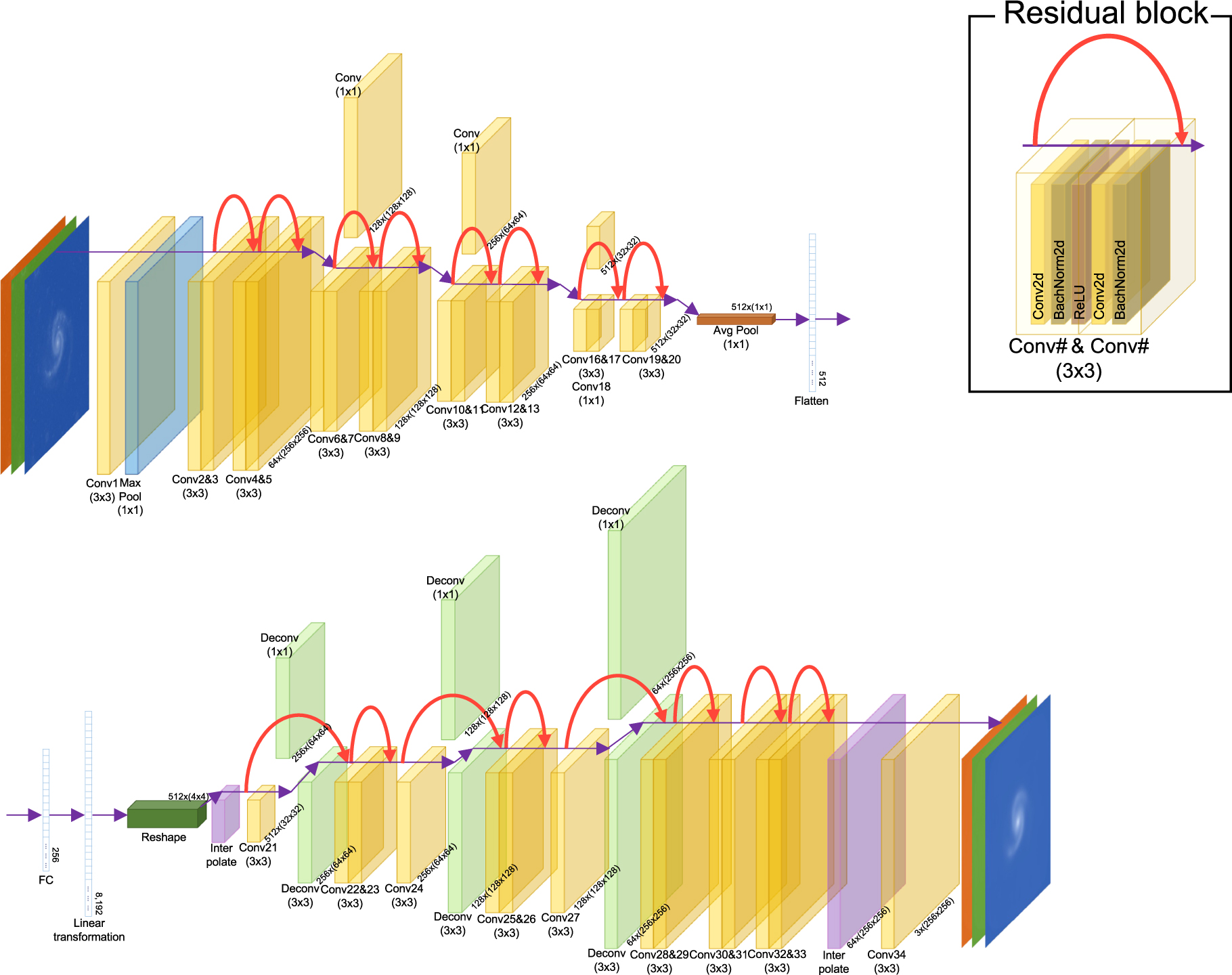
We utilized the CAE, composed of an encoder and decoder, to minimize the difference between input and output images through the optimization of neural weights and biases in the fully connected and convolutional layers. The encoder adopts the residual neural networks-18 (ResNet-18; He et al. 2015), which is composed of a convolutional layer, eight residual blocks, and a fully connected layer (Figure 4). The residual block consists of two convolutional layers, followed by a batch normalization and rectified linear unit activation function for each convolutional layer (Zeiler & Fergus 2013). The gradient vanishing problem is reduced by residual learning, using a skip connection for each residual block (He et al. 2015). As the 256 × 256 × 3 input images were sequentially passed through the convolution layers and residual blocks, they were transformed into 32 × 32 × 512 images. A total of 512 latent features were extracted via adaptive average pooling.

Figure 4. Schematic of our convolutional autoencoder adopting ResNet-18. The sizes of the image are denoted below each layer.
Download figure:
Standard image High-resolution imageThe decoder architecture was an apparent reversal of the encoder's architecture. The decoder was composed of one convolution layer and eight residual blocks. The encoder's 512 latent features output as input to the decoder. The decoder's input images were converted into 256 vectors as the fully connected layers. Linear transformation and reshaping resulted in 4 × 4 × 512 images, which were subsequently expanded by interpolation to 32 × 32 × 512. The images were passed through the residual block composed of the convolutional and de-convolutional layers and a three-convolution layer block, followed by the seventh and eighth blocks composed only of the convolutional layers. The images were passed through a convolution layer to convert them into the inputted image dimensions, 256 × 256 × 3.
3.2. Training and Validation
The source code was written in Python. Pytorch and Pytorch Lightning (Falcon et al. 2020) were used for the back-ends. The training loop was processed in Pytorch Lightning. Experiments and training were performed on four multi-NVIDIA TITAN RTX D6 graphic processing units (GPUs) with 24 GB RAM and CUDA-11.4. A total of 90,370 images were divided into training, validation, and test data sets in the 3:1:1 ratio. We adopted batch size (42), learning rate (0.0001), loss function (mean squared error; MSE), and optimizer (Adaptive Moment Estimation; Adam) parameters for the training and validation. For additional options, we used imbalanced data set sampler 8 to contain balanced morphological types in each batch. Furthermore, the images are randomly rotated 9 before being used as input for each training iteration to reduce dependence on position angle.
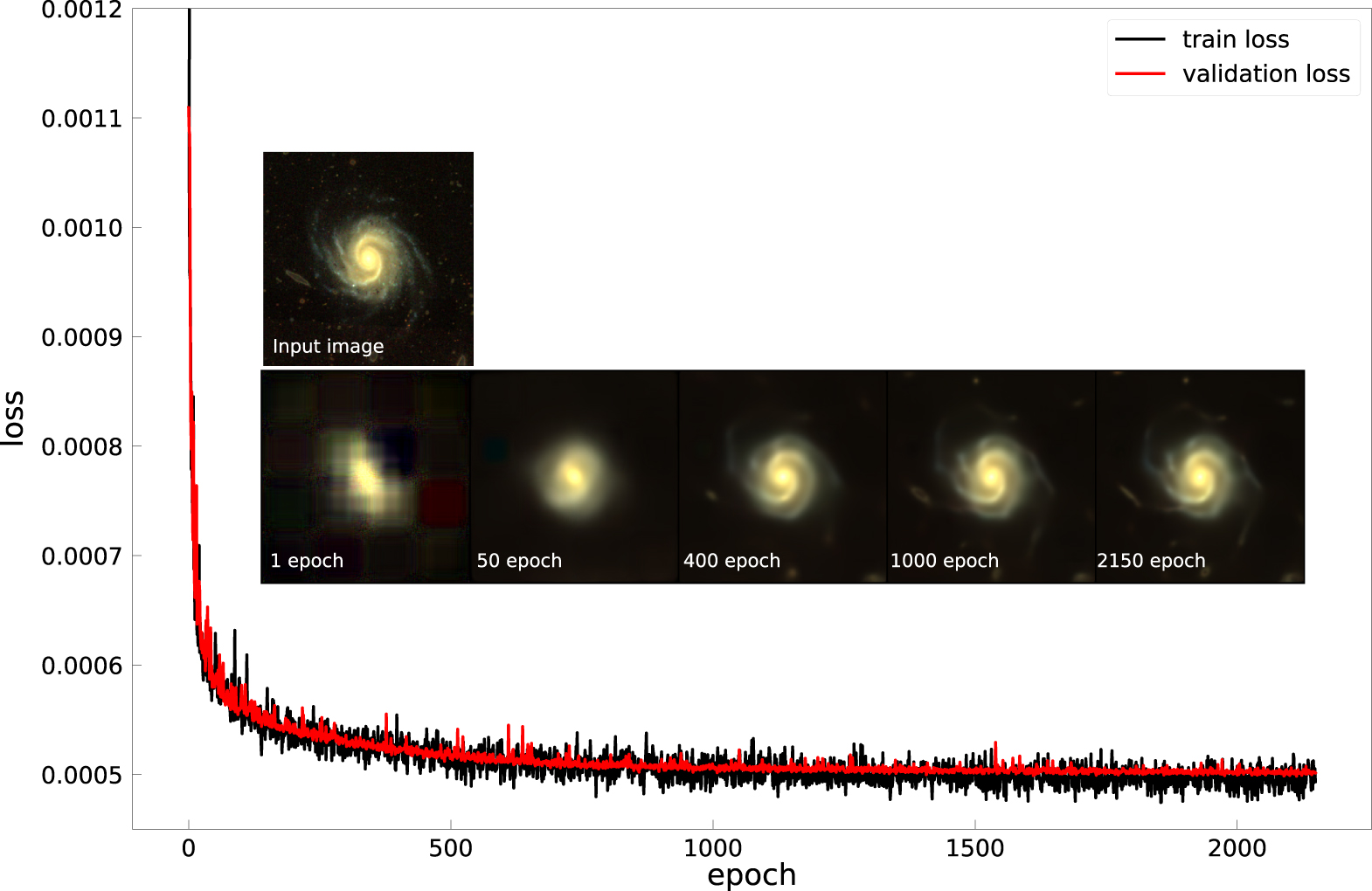
Figure 5 depicts the training and validation loss, which decreased during the training progresses but did not decrease dramatically after a thousand epochs. Thus, we stopped the training at the 2150th epoch and adopted the final training as the final CAE model. We compare the input and the output images at a given epoch in inset images.

Figure 5. Training and validation losses as a function of epoch in the CAE. The insets depict the input and output images from the CAE at indicated epochs.
Download figure:
Standard image High-resolution imageFigure 6 depicts the input image (test data set; top line of each panel), the output image (middle line of each panel), and the residual image (bottom line of each panel) for evaluating the accuracy of the final CAE. The input and output images appeared similar, although the output images were slightly smoother. None of the galaxy shapes or features remained in the residual images, regardless of their morphological types. The median and standard deviation of the mean pixel values for the residual images of all test data sets were 0.0181 and 0.003, respectively. It means that the model's encoder effectively captures the essential features of the input images.

Figure 6. Top, middle, and bottom line depict the test sample images, output image reconstructed by the CAE, and the residuals, respectively.
Download figure:
Standard image High-resolution image3.3. Database of Latent Features
The final CAE successfully reproduced the output galaxy images from the input galaxy images, suggesting that the 512 latent features extracted by the encoder output contain galaxy morphological features. Before creating the latent features, we must make a position angle of 90° for all input galaxy images (see Figure 7) to prevent the position angle dependency on searching similar galaxy images where the original position angle was determined by SouceCatalog class of Photoutils package. The objective of randomly rotating images during training differs from maintaining a fixed position angle for similarity in morphological classification. The model is intended to be insensitive to the galaxy's orientation, but to identify similar images, the position angle must be controlled. The encoder created the latent feature databases from GZ2 (90,370), EFIGI (4458), and NA10 (14,034) input galaxy images.

Figure 7. Example of rotating the position angle of 90° before constructing DB.
Download figure:
Standard image High-resolution image3.4. Similar Image Retrieval
The traditional morphological classification relies on limited non-parametric features, such as concentration, asymmetry, density, Gini coefficient, and M20, to represent galaxy structures in input images. However, these few features may not fully capture the complexity of galaxy images. A more comprehensive set of galaxy image parameters is needed to identify similar galaxy images accurately. Therefore, we employed 512 latent features as the galaxy morphological parameters.
With a given target galaxy, a similarity parameter (Sp) was defined to retrieve a similar galaxy from the database (Figure 8)




Figure 8. Schematic showing the similarity parameter calculation. The top and bottom panels display the encoder output and the galaxies with different similarity levels, respectively.
Download figure:
Standard image High-resolution imageTj , Dij , and Bj are the jth latent feature of the target galaxy, of the ith database-listed galaxy, and of the background of the target galaxy image, respectively. We designate the Euclidean norm (EN) for each galaxy listed in the database as ENgal,i , and for the background image of the target galaxy as ENback. The background images were created by randomly selecting the region outside the objects in the target galaxy image.
A similar galaxy was determined as a database galaxy with the highest similarity parameter (H-similarity). It should be noted that if the similarity is 100% (meaning the exact same galaxy image as the target image in the database), we choose the galaxy with the second-highest similarity parameter.
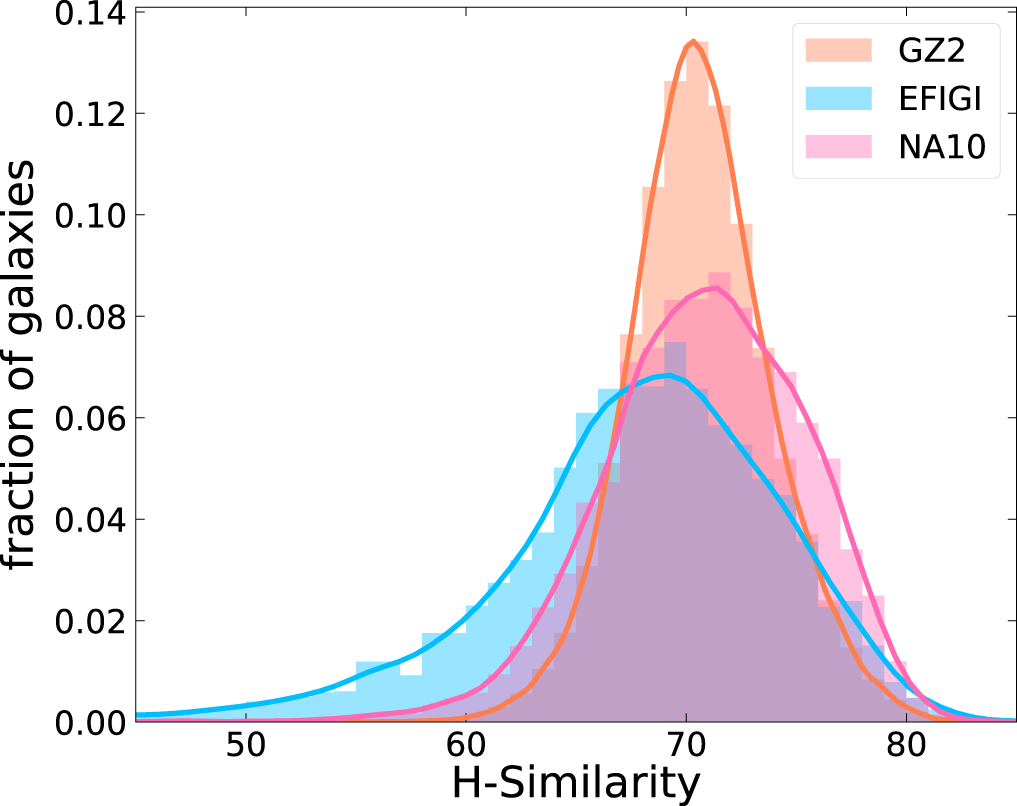
The H-similarity is calculated for all galaxies in each catalog for a given target galaxy. Therefore, the number of the H-similarity values calculated for a target galaxy equals the number of galaxies in each catalog. Figure 9 depicts the distribution of H-similarity for each catalog. In the comparison of the three catalogs, both GZ2 (70.6% ± 3.25%) and NA10 (70.8% ± 4.62%) show slightly higher average H-similarity scores than EFIGI (67.7% ± 6.88%). Notably, the H-similarity score distribution in the EFIGI catalog is skewed toward lower scores. This may be due to the smaller size of the EFIGI catalog, which decreases the probability of finding high-similarity pairs, and the lower fraction of early-type galaxies in the EFIGI catalog, which tend to have higher H-similarity scores (see Section 4.1). Further, if the H-similarity of the target galaxy is less than one sigma from the average of the H-similarity in each catalog, it is decided that there is no similar image in the database. It should be noted that some galaxies with low H-similarity might have complex structures that make it difficult to find similar galaxies in the database.

Figure 9. Distribution of the H-similarity of each morphology catalog.
Download figure:
Standard image High-resolution image4. Morphological Classification
After training CAE and finding a similar galaxy in the database, we classified the morphology of the target galaxy, adopting the similar galaxy's morphological type. The morphological types in the database have come from GZ2, EFIGI, and NA10 catalogs.
4.1. H-similarity by Morphology
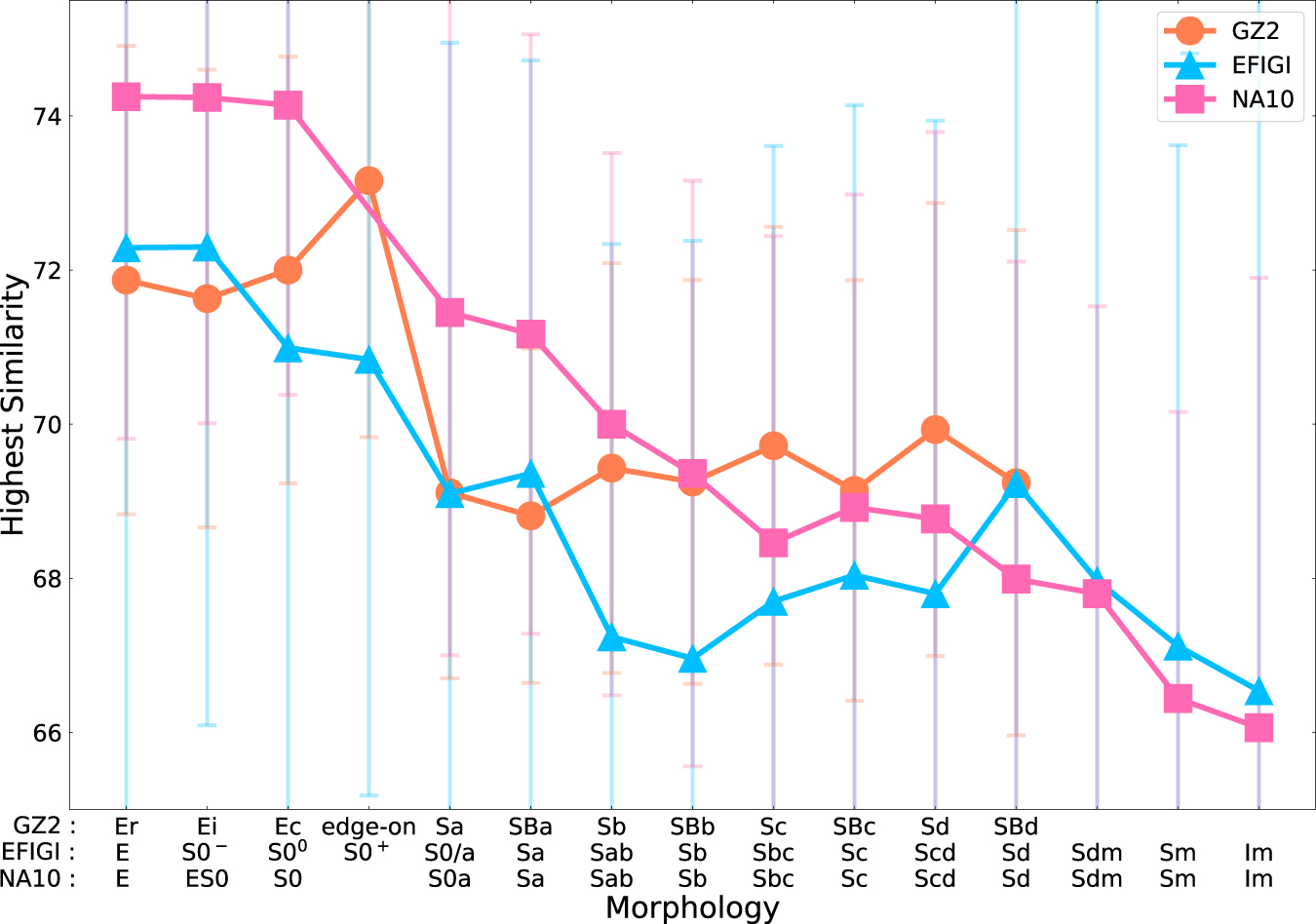
Figure 10 depicts the galaxy morphologies of the retrieved galaxies and similarity indices. Simple-structure galaxies, such as elliptical or edge-on galaxies, exhibited larger H-similarity values. The H-similarity decreased as the structural complexity of galaxies increased, such as face-on late-type galaxies. Figure 11 shows the H-similarity as a function of the galaxy morphology for each catalog. The average of the H-similarity value decreases from early- to late-type as the internal structure becomes complex, suggesting that the structural features (e.g., bulge, arms, bars, rings) and the constituent properties (e.g., dust, star-forming region) of the early- and late-type galaxies affect their similarity.

Figure 10. Examples of the retrieved galaxies with morphological types and similarity. The leftmost image depicts the target galaxy in each morphology. Subsequent images from the left depict the top three highly similar galaxies. Letters and percentages indicate the morphological type and similarity, respectively.
Download figure:
Standard image High-resolution image
Figure 11. H-similarity as a function of the morphological types in GZ2 (orange circles), EFIGI (cyan triangles), and NA10 (pink squares) catalogs. The error bars represent the standard deviations.
Download figure:
Standard image High-resolution image4.2. Predicted Morphology
4.2.1. Morphological Classification Accuracy
To evaluate the reliability of morphological classification using TSGICAS, we divided the database into the morphology-check (MC) sample (10%) and morphology-Database (MD) sample (90%) in each morphological type. We calculated the H-similarity for each MC sample within the MD samples and determined the MC sample morphology.
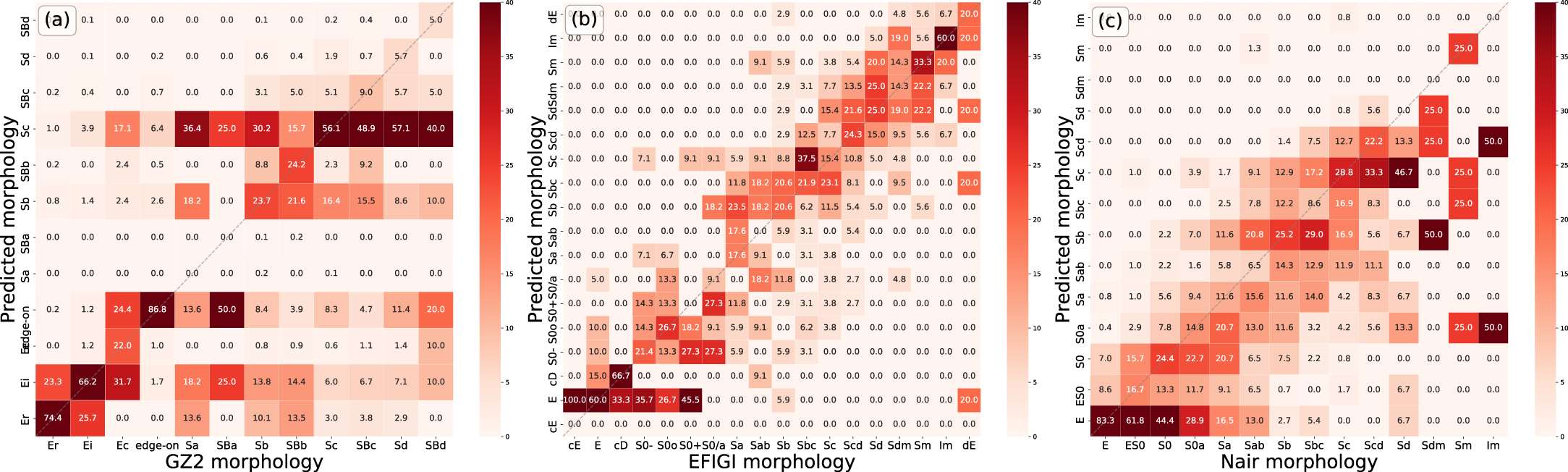
Figure 12 depicts the MC sample morphological confusion matrices for the three morphological catalogs. Our morphological classification generally predicts a reliable morphological type for the MC sample. Most of the predicted morphological and morphological types of MC samples in confusion matrices show a one-to-one correlation, although it shows some scatters. Correlation coefficients are 0.687, 0.819, and 0.784 in GZ2, EFIGI, and NA10, respectively.

Figure 12. Confusion matrices compare identified and predicted morphological types in the catalogs. The columns represent the instances of each morphological type in the catalogs, while the rows represent the instances of the predicted morphological types. The values within each matrix block represent the percentage of individuals for a given identified morphological type. The dashed line represents the perfect match between the two morphological types.
Download figure:
Standard image High-resolution imageIn the three catalogs, GZ2 samples exhibit significantly large scatters at the spiral galaxies and are biased to Sc types (Figure 12(a)). EFIGI (Figure 12(b)) and NA10 (Figure 12(c)) sample classification are comparable to the reported visual morphological classification (see Figure 19 in Baillard et al. 2011 and Figure 14 in Nair & Abraham 2010). This biased classification of GZ2 through our TSGICAS seems to result from the difficulty of visual morphological classification among Sa to Sd types by non-experts. In Figure 1, GZ2 catalog hosted a higher number of Sc galaxies than the adjacent spiral galaxies, while EFIGI and NA10 catalogs hosted comparable numbers. Figure 13 depicts an example in which similar images of Sc type have different types in GZ2. The two galaxies are indistinguishable by visual inspection, indicating that Sc type contains too many different types of galaxies. Therefore, we suspect that morphological types of Sc galaxies in GZ2 are confused mainly with the adjacent types of spiral galaxies.

Figure 13. Examples of Sc-type galaxy miss-classification in GZ2 catalog. The top and bottom rows indicate the MC sample's Sc type galaxies and the retrieved similar images. The text and percentage denote the morphology type and similarity values, respectively.
Download figure:
Standard image High-resolution imageTo investigate this issue, we randomly select a small and fixed number of samples in each morphological type to make a new MD sample. Assuming the original MD sample has a well-normalized distribution of classification accuracy, it is expected that the new MD sample will exhibit a lower variance in accuracy, indicating a higher probability of well-classified galaxy types in the new MD sample compared to the original sample. We calculated the H-similarity and determined the morphological types for the MC samples in the new MD samples. This process was iterated 400 times. For each galaxy in the MC sample, we finally determine a morphological type as a mode value of 400 predicted morphological types. This will statistically reduce the probability of being misclassified by repeatedly performing galaxy classification in the new MD with a low variance of classification accuracy.
Figure 14 presents the confusion matrices of this test. The bias of the predicted morphological type for spiral galaxies in the GZ2 catalog is lower than that of the previous confusion matrices (Figure 12). The correlation coefficients for GZ2 (0.735), EFIGI (0.811), and NA10 (0.815) catalogs are either higher or comparable with previous studies. The difficulty of morphological classification among adjacent morphological types via visual classification translates into the uncertainty of predicted morphological types by TSGICAS. As a result, GZ2 and NA10 exhibited improved results in late-type galaxies, indicating the presence of a significant number of misclassified galaxies within the spiral region. In conclusion, a well-classified morphological catalog is essential for more reliable predictions by TSGICAS.

Figure 14. Confusion matrices compare morphological types for each catalog, along with the mode value of the predicted morphological type for 400 newly generated MD samples. The values within each matrix block represent the percentage of individuals for a given identified morphological type. The dashed line represents the perfect match between the two morphological types.
Download figure:
Standard image High-resolution image4.2.2. Misclassification
To identify galaxies that were misclassified by our previous morphological classification method, we have divided the results into three categories based on the degree of misclassification: best-classification, good-classification, and miss-classification. Best-classification refers to instances where the morphological type assigned to the MC sample by our method exactly matches the true morphological type. Good-classification refers to instances where the predicted morphological type is within two adjacent types of the true type and encompasses the category of best-classification. For instance, good-classification of Sc type in the EFIGI catalog include Sb, Sbc, Sc, Scd, and Sd. Miss-classification refers to all remaining cases that are not included in the best-classification and good-classification. Our method provided the best-classification of 55.08% (GZ2), 24.44% (EFIGI), and 31.74% (NA10) and the prediction accuracies of the good-classification are 82.68% (GZ2), 74.28% (EFIGI), and 80.32% (NA10). The fractions of the miss-classification are 17.32% (GZ2), 25.72% (EFIGI), and 19.68% (NA10).
Figures 15 and 16 depict examples of good-classification galaxies for late-type and early-type galaxies, respectively. Furthermore, Figure 17 highlights that, despite being part of our definition of good-classification, early-type (Ec) galaxies were misclassified as edge-on (late-type) galaxies and vice versa. The examples in the good-classification category demonstrate that distinguishing between adjacent morphological types can be challenging even for human observers, as the MC sample and similar galaxies have different morphological types but visually similar images.

Figure 15. Examples of good-classification among the late-type galaxies. The top and bottom galaxy images in each figure represent the MC samples and retrieved similar images, respectively. Each set's first and second columns depict the 1st and 2nd adjacent morphological types, respectively. The text and percentage indicate the morphological types and similarity values, respectively.
Download figure:
Standard image High-resolution image
Figure 16. Examples of good-classification of the early-type galaxies in GZ2 catalog. The top and bottom images display the MC samples and the retrieved similar images, respectively. The text and percentage indicate the morphological types and similarity values, respectively.
Download figure:
Standard image High-resolution image
Figure 17. Example of galaxy in the good-classification category that lies on the boundary between early-type (Ec) and late-type (edge-on) galaxies in the GZ2 catalog. The top and bottom images display the MC samples and the retrieved similar images, respectively. The text and percentage indicate the morphological types and similarity values, respectively.
Download figure:
Standard image High-resolution imageExamples of the miss-classifications are presented in Figure 18. Although these galaxies are late-type, the overall color was red similar to early-type, and their spiral arm structures were fainter than that of typical spiral galaxies. Moreover, galaxies with a high degree of similarity exist even though they do not appear structurally similar. This was our encoder's limit. In these cases, the latent features appear to be biased toward photometric parameters representing the global shape or color of the galaxy rather than other parameters representing the detailed structures (etc., spiral arms, bared, rings) of the galaxy. For example, the TSGICAS prefers to determine red elliptical galaxies as similar images on red spiral galaxies with faint spiral arms since the latent features are biased to color rather than the spiral arm structure. The training image should be changed to a galaxy image with clear structures to solve this problem.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure 18. Examples of miss-classifications of late-type galaxies as early-type in each catalog. The top and bottom rows depict the MC samples and the retrieved similar images, respectively. The text and percentage indicate the morphological types and similarity values, respectively.
Download figure:
Standard image High-resolution image{kind=link}
5. Directions for Improvement
To refine our methodology, two key factors need to be addressed. First, it is crucial to provide a data set of latent features that is balanced in terms of the accurate classification of galaxy morphologies. If the data set size or its diversity is not enough, the chance of finding similar images decreases, thereby reducing the similarity of the retrieved images. Consequently, for TSGICAS to accurately classify galaxy morphology, it necessitates a balanced data set where each morphological type of galaxy is equally represented. This is especially pertinent for galaxies with more complex structures, which require a diverse range of image data. To this end, we aim to increase the number of accurately classified galaxies in morphological categories that are currently underrepresented in the data set, to at least equal the number in the most common morphology. In Figure 11, the H-similarity of late-type galaxies is lower than that of early-type galaxies. The more complex the structure of late-type galaxies, the more difficult it is to search for galaxies with high similarity. To address the limitations of insufficient data and lack of diversity, we propose a strategy centered on data augmentation using Variational Autoencoder (VAE; Kingma & Welling 2013) models. VAEs, renowned for their effectiveness in generating diverse images, provide a mechanism to adjust the variations of latent features specific to a galaxy, thereby enabling the generation of distinct yet similar images even for sparsely populated or unique galaxies. This unique capability of VAEs allows for the enrichment of our data set across all morphologies, effectively overcoming the problem of data scarcity. By incorporating VAEs into our methodology, we anticipate an enhanced ability to accurately differentiate between various galaxy morphologies, even in scenarios of limited training data.
Second, the compressed latent feature information of the galaxy images should be unbiased toward certain galaxy features. It is noted that late-type galaxies are occasionally misclassified as early-type galaxies, as seen in Figure 18. This misclassification arises predominantly due to the bias toward latent features that primarily represent overall color and shape, rather than detailed structural features like spiral arms and barred structures. To an experimental verification, we transformed galaxy images to grayscale, retrained our model, and confirmed subsequent classification changes. Approximately 47% of galaxies initially misclassified from late-type to early-type were identified as late-type galaxies using grayscale images, suggesting a significant color effect. However, the remaining 53% were still classified as early-type. This outcome highlighted another limitation of our current model—its capacity to reconstruct delicate and faint structural details, which are crucial for precise morphological categorization. The Sa-type spiral galaxies, which are structurally close to the earlier types, clearly demonstrate these limitations. Even when the Sa-type was classified through a model that using gray scale image, about 67% were still not classified as late-type. To mitigate these biases and improve the accuracy of morphological classification, our future methodology needs to incorporate more comprehensive training data. Instead of relying solely on three-channel color data, the inclusion of more specific structural features of galaxies in the training data is paramount. In the next version of TSGICAS, we will include residual images (from galaxy-profile fitting model images) in the training data set. This approach will enhance the representation of crucial structural features and reduce latent feature biases, thereby leading to a more accurate galaxy classification system.
6. Summary and Conclusions
We propose a novel and automatic galaxy morphological classification method employing the CAE and similarity indices. The CAE encoder converted the input galaxy images (256 × 256 × 3) into latent features (512) containing the morphological features. We then generated the morphological latent feature database. We compared the latent features of the database entries and the input galaxy images and calculated the similarity. Our method assigned the galaxy's morphology with the highest similarity in the database. The following briefly summarizes and concludes our key findings:
(1) Our CAE reproduces a highly similar image from an input galaxy image. The median and standard deviation of the mean pixel values for the residual images are 0.0181 and 0.003, respectively, which indicate a strong similarity between the input and reconstructed images. This suggests that the CAE effectively extracts the latent features, which include key morphological features of the input galaxy.
(2) The morphological latent feature database is constructed from galaxy images in GZ2, EFIGI, and NA10 catalogs. The entries from the EFIGI and NA10 catalogs exhibit a reliable agreement in morphological classifications, while the late-type galaxies in the GZ2 catalog are not as reliably classified. This reflects the inherent dependence of our morphological classification method, TSGICAS, on the quality of database classification. Understanding this limitation, it is important to recognize the potential ambiguities in visual classifications, as Cheng et al. (2021b) highlighted, where similar structural features could lead to varied or incorrect types. In the context of these findings, the exploration of unsupervised machine learning techniques, similar to the ones presented in Cheng et al. (2021b), could contribute to improving the accuracy and reliability of the classification database, thereby enhancing the performance of the TSGICAS system.
(3) In most cases, even though the morphological types of MC samples and retrieved similar galaxies are different, the two galaxies can not be easily discriminated by visual inspection. Therefore, the TSGICAS suggests that the two galaxies may have the same morphological type. In addition, a catalog of well-classified galaxies should be used for accurate morphological classification.
Since the encoder model of the CAE only extracts latent features from images, this classification method does not require our CAE re-learned for different morphological classification schemes for each catalog. Therefore, this method can automate the morphological classification of the tremendous amount of galaxies that will be observed in the next-generation telescopes.
The latent features of the CAE learned in this study showed a bias by color and overall shape of the galaxy (Section 4.2.2; Figure 18). In future work, we aim to improve the model by expanding the training data sets by including the residual images representing faint structures. In addition, the correlation between the latent features and photometric parameters is examined, and their relative significance would enable accurate similarity calculations. Moreover, galaxies can be classified by clustering 512 latent features regardless of the existing morphological classification schemes. This can propose a new morphological classification scheme not presented in conventional morphological types.
TSGICAS developed in this study can be used in various galaxy research and helps to easily and quickly find similar galaxies with a specific morphological type. Searching for similar images is more intuitive and efficient than the conventional classification method using photometric and/or spectroscopic parameters. In particular, similar images of realistic simulation galaxies can be found in the observational domain. As a result, it is possible to compare the physical parameters of simulations and observations directly. Also, as the latent features imparted lower significance to the image noise, the output images exhibited a higher signal-to-noise ratio than the input images (Figure 6), thereby aiding in identifying the fainter and dimmer galaxy structures.
Acknowledgments
We are grateful to the anonymous referee for helpful comments and suggestions that improved the clarity and quality of this paper. This work was supported by the National Research Foundation of Korea through grants NRF-2019R1I1A1A01061237 & NRF-2022R1C1C2005539 (S.K.), NRF-2022R1I1A1A01054555 (Y. L.), NRF-2020R1I1A1A01052358 & NRF-2021R1A2C1004117 (S.-I. H.), NRF-2019R1A2C2086290 (H.-S. K.), NRF-2022R1A2C1007721 (S.-C. R.), and NRF-2022M3K3A1093827 (H. S.).
Footnotes
- 7
The flag has a value of 1 when (a) the votes and voter turnout for each question exceeded a set threshold and when (b) the debiased vote fraction (corrected for classification bias) was 0.8 or higher. It was zero otherwise. Therefore, if the flag were 1, it would be closer to a cleaner sample.
- 8
- 9
torchivision.transforms.RandomRotation is used.