
Abstract
Protein quality assessment (QA) has played an important role in protein structure prediction. We developed a novel single-model quality assessment method–Qprob. Qprob calculates the absolute error for each protein feature value against the true quality scores (i.e. GDT-TS scores) of protein structural models and uses them to estimate its probability density distribution for quality assessment. Qprob has been blindly tested on the 11th Critical Assessment of Techniques for Protein Structure Prediction (CASP11) as MULTICOM-NOVEL server. The official CASP result shows that Qprob ranks as one of the top single-model QA methods. In addition, Qprob makes contributions to our protein tertiary structure predictor MULTICOM, which is officially ranked 3rd out of 143 predictors. The good performance shows that Qprob is good at assessing the quality of models of hard targets. These results demonstrate that this new probability density distribution based method is effective for protein single-model quality assessment and is useful for protein structure prediction. The webserver of Qprob is available at: http://calla.rnet.missouri.edu/qprob/. The software is now freely available in the web server of Qprob.
Similar content being viewed by others

Introduction
The number of protein sequences has grown exponentially during the last few decades because of the wide application of high-throughput next-generation sequencing technologies1. This ensures the importance of computational methods in bioinformatics and computational biology that are much cheaper and faster than experimental methods2 for annotating the structure and function of these protein sequences2,3,4,5,6,7,8. A lot of progress has been made recently for protein structure prediction in terms of both template-based modeling and template-free modeling assisted by the Critical Assessment of Techniques for Protein Structure Prediction (CASP).
During the prediction of protein structure, one important task is protein model quality assessment. The model quality assessment problem can be defined as ranking structure models of a protein without knowing its native structure, which is commonly used to rank and select many alternative decoy models generated by modern protein structure prediction methods. In general, there are two different kinds of protein quality assessment (QA) methods: single-model quality assessment9,10,11,12,13,14 and consensus model quality assessment15,16,17. According to the previous CASP experiments, the consensus quality assessment methods usually perform better than the single-model quality assessment methods, especially when there is a good consensus in the model pool. However, it is also known that the consensus quality assessment may fail badly when there are a large portion of low-quality models in the model pool that are similar to each other9. Moreover, consensus quality assessment methods are very slow when there are more than tens of thousands of models to assess. Therefore, more and more single-model methods are developed to address these problems. Currently, most single-model methods use the evolution information18, residue environment compatibility19, structural features and physics-based knowledge11,12,13,14,20,21,22 as features to assess model quality. Some hybrid methods also try to combine the single-model and consensus methods to achieve good performance2,4. In the work, we develop a single-model QA method (Qprob) that combines structural, physicochemical and energy features extracted from a single model to improve protein model quality assessment. To the best of our knowledge, Qprob is the first method that estimates the errors of these features and integrates them by probability density functions to assess model quality assessment.
Specifically, we benchmarked four protein energy scores in combination with seven physicochemical and structural features. We quantify the effectiveness of these features on the PISCES23 database and calibrate their weights for combination. The probability density function of the errors between predicted quality scores and real GDT-TS scores for each feature is generated, assuming that the error between each predicted score and the real score roughly obeys the normal distribution. By combining the probability density distributions of all features, we can predict the global quality score of a model. The performance of Qprob is similar to the state-of-the-art single-model performance during the blind CASP11 experiment, which demonstrates the effectiveness of the probability density distribution based quality assessment methods.
The paper is organized as follows. In the Methods Section, we describe each feature and the calculation of the global quality assessment score in detail. In the Result Section, we report the performance of our method in the CASP11 experiment. In the Discussion Section, we summarize the results and conclude with the direction of future works.
Results
Feature normalization results
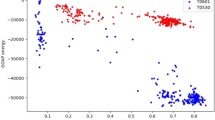
We use 11 feature scores in total in our method and there is no need to do normalization for most of them. However, some features, especially the energy scores are dependent on the sequence length and not in the range of 0 and 1. So we need to normalize these scores before using them. We use PISCES database to benchmark and normalize three scores (DFIRE2 score, RWplus score and RF_CB_SRS_OD score) to remove length dependency. The sequence identity cutoff between any two sequences in the PISCES database is 20%, the resolution cutoff of structure is 1.8 Angstroms and the R-factor cutoff of structure is 0.25. Figure 1 shows the plot of the three original energy scores (DFIRE2, RWplus and RF_CB_SRS_OD scores) versus protein length. We use linear regression to fit the energy score with the protein length (see the linear line in Fig. 1). The following linear function formula describes the relationship between protein sequence length and the energy score:

The relationship of three energy scores (DFIRE2, RWplus and RF_CB_SRS_OD scores) and sequence length on PISCES database.

L is the protein sequence length. Based on these linear relationships, to normalize these scores into the range of 0 and 1, we use the following formula:

PDfire score is the predicted DFIRE2 score, PRW plus score is the predicted RWplus score and PRF_CB_SRS_OD score is the predicted RF_CB_SRS_OD score. PDfire score is set to the range of −1.971*L and 0, PRW plus score is set to the range of −232.6*L and 0 and PRF_CB_SRS_OD score is set to the range of 0.4823*L-300 and 700 based on the benchmark of all scores in CASP9 targets so that most of models are in this range.
Feature error estimation results
We use each of 11 feature scores including three normalized energy scores to predict the quality score of the models of CASP9 targets and the difference between predicted score and real GDT-TS score for each model is used estimate the probability of the error of each feature. Figure 2 shows the probability density distribution of all 11 features, respectively. The x-axis is the error between predicted score and real GDT-TS score and the y-axis is the probability density distribution of the error. The mean and standard deviation is also listed in the figures. We use a normal distribution to fit these errors. According to the results, ModelEvaluator score has the mean −0.0219, which is the closest to the real average GDT-TS score. In addition, it has the minimum standard deviation, which suggests it is the most stable feature for evaluating the global model quality. In contrast, the Euclidean compact score has the maximum absolute mean error (0.4119), showing it is most different from the real GDT-TS score.

The probability density distributions for the error estimation of all 11 feature scores.
Global quality assessment results
Qprob was blindly tested on CASP11 as MULTICOM-NOVEL server and was used for the human tertiary structure predictor MULTICOM. MUTLCIOM is officially ranked 3rd out of 143 predictors according to the total scores of the first models predicted. According to the analysis result by removing each QA method from MULTICOM, the removal of Qprob causes the biggest decrease in the average Z-score of top one models selected by MULTICOM method (Z-score from 1.364 to 1.321)2,4, showing Qprob makes big contribution to MUTLCOM. Our method is one of the best single-model QA method based on the CASP official evaluation24 and our own evaluations reported in Tables 1 and 2.
Table 1 depicts the per-target average correlation, average GDT-TS loss, average spearman’s correlation and average kendall tau correlation of our method Qprob and other pure single-model QA methods on Stage 1 (sel20) CASP11 datasets. These scores are calculated by comparing the model quality scores predicted by each of these methods with the real model quality scores. We also report the p-value of the pairwise Wilcoxon signed ranked sum test for the difference of loss/correlation between Qprob and other pure single-model QA methods. The method in the table are ordered by the average GDT-TS loss (the difference of GDT-TS score of the best model and predicted top 1 model) that assess a method’s capability of selecting good models. According to Table 1, Qprob is ranked third based on the average GDT-TS loss on Stage 1 CASP11 datasets. According to 0.01 significant threshold of p-value, there is no significant difference between Qprob and the two state-of-the-art QA methods ProQ2 and ProQ2-refine in terms of both correlation and loss. The difference on average Spearman’s correlation and Kendall tau correlation is also small between Qprob and the other two top performing methods. Other than CASP11 QA server predictors, we also compare Qprob with five single-model QA scores that are highlighted in bold in Table 1. The five scores are ModelEvaluator score, Dope score, DFIRE2 score, RWplus score and RF_CB_SRS_OD score. The result shows Qprob performs better than these scores in terms of both correlation and loss. Moreover, the difference of correlation between Qprob and four QA scores (Dope score, DFIRE2 score, RWplus score and RF_CB_SRS_OD score) is significant and the difference of loss between Qprob and three QA scores (DFIRE2 score, RWplus score and RF_CB_SRS_OD score) is significant according to 0.01 significance threshold. Finally, we also calculate the performance of the baseline consensus QA method DAVIS_consensus whose correlation and loss is 0.798 and 0.052 respectively. Not surprisingly, the performance of our single-model method Qprob is worse than DAVIS_consensus method and the difference is significant. The p-value of difference in correlation and loss is 1.4e-12 and 1.6e-4 respectively. The difference is more significant between Qprob and the start-of-the-art consensus QA method Pcons-net25 whose correlation and loss is 0.811 and 0.024, with p-value 1.93e-14 and 1.61e-6 respectively.
We also evaluate the performance of Qprob and other QA methods on Stage2 (top150) CASP11 datasets in Table 2. Each target in the Stage 2 CASP11 data has about 150 models. Qprob ranked second among all pure single-model QA methods based on the average loss metric. The difference between Qprob and ProQ2 is not significant in terms of both correlation and loss, i.e., p-value is 0.2387 and 0.8636 respectively, showing Qprob achieved close to state-of-the-art model selection ability. Comparing Qprob with five scores (ModelEvaluator score, Dope score, DFIRE2 score, RWplus score and RF_CB_SRS_OD score), the difference of correlation between Qprob and four scores (ModelEvaluator score, Dope score, DFIRE2 score and RWplus score) is significant and the difference of loss between Qprob and two scores (DFIRE2 score and RF_CB_SRS_OD score) is significant according to p-value threshold 0.01. In addition, we also compare the performance of Qprob with baseline consensus method DAVIS_consensus on Stage2 (top150) CASP11 datasets. The per-target average correlation of DAVIS_consensus is 0.57, which is better than Qprob (with correlation 0.381). The difference of correlation is significant according to p-value 6.14e-4. However, the per-target loss of Qprob (i.e. 0.068) is better than DAVIS_consensus (i.e. 0.073). Although the difference of loss is not very significant (p-value 0.11), this shows Qprob performs at least as well as the consensus method on Stage2 CASP11 datasets. Moreover, compared with the top performing consensus QA method Pcons-net loss (i.e. 0.049), the difference of loss between Qprob and Pcons-net is still not very significant (p-value 0.19). To illustrate the model selection ability of the QA methods on hard targets whose model pool contains mostly low quality models, we evaluate the performance of Qprob and several top performing single-model/consensus QA methods on the template free CASP11 targets. We calculate the summation of Z-score for the top 1 model selected by each QA method. The result is shown in Fig. 3. Figure 3A shows the performance of each method on Stage 1 of CASP11 datasets. The single-model QA methods are in bold. The consensus QA methods have relatively better performance, where, the baseline pairwise method DAVIS_consensus gets the highest Z-score. Figure 3B shows the performance of each QA method on Stage 2 of CASP11 datasets. It is very interesting to see that the single-model QA methods have relatively better performance than consensus QA methods. Especially, our method Qprob and VoromQA have the highest Z-score comparing with other single QA methods. Another interesting finding is the pairwise method DAVIS_consensus has Z-score around 0, suggesting its performance is close to a random predictor. These results demonstrate the value of single-model QA method in selecting models of hard targets. The hybrid method MULTICOM-CONSTRUCT that combines both single-model and consensus methods ranks third, showing the combination of the two kinds of methods is also quite useful for model selection.

The summation of Z-score for the top 1 models selected by each method.
Discussion
In this paper, we introduce a novel single-model QA method Qprob. Different from other single-model QA methods, Qprob estimates the prediction error estimation of several different physicochemical, structural and energy feature scores and use the combination of probability density distribution of the errors for the global quality assessment. We blindly tested our method in the CASP11 experiment and it was ranked as one of the best single-model QA method based on the CASP official evaluation and our own evaluations. In particular, the good performance of our method on template free targets demonstrates its good capability of selecting models for hard targets. Furthermore, the method made valuable contribution to our MULTICOM human tertiary structure predictor-one of the best human predictors among all server and human predictors in CASP11. These results demonstrate the broad application of our method in model selection and protein structure prediction.
Methods
In this section, we describe the calculation of 11 features, how to generate the probability density distributions of the prediction errors of these features and how to combine these features for protein model quality assessment.
Feature generation
Our method uses structural/sequence features extracted from a structural model and its protein sequence, physicochemical characteristic of the structural model21 and four energy scores for predicting the global quality score of the model. The features include:
-
1
The RF_CB_SRS_OD score11 is an energy score for evaluating the protein structure based on statistical distance dependent pairwise potentials. The score is normalized into the range of 0 and 1(see the normalization protocol in the Result section).
-
2
The secondary structure similarity score is calculated by comparing the secondary structure predicted by Spine X26 from a protein sequence and those of a model parsed by DSSP27.
-
3
The secondary structure penalty percentage score is calculated by the following formula:

FH is the total number of predicted helix residues matching with the one parsed by DSSP. FS is the total number of predicted beta-sheet residues matching with the ones parsed by DSSP. N is the sequence length.
-
4
The Euclidean compact score is used to describe the compactness of a protein model. It is calculated by the following formula:

i and j is the index of any two amino acids and Eucli(i, j) is the Euclidean distance of amino acid i and j in the structural model.
-
5
The surface score for exposed nonpolar residues describes the percentage of exposed area of the nonpolar residues and is calculated as follows:

Si is the exposed area of residue i parsed by DSSP and SEi is the exposed area of nonpolar residue i. The SEi is set to 0 if residue i is polar.
-
6
The exposed mass score describes the percentage of mass of exposed residues and is calculated as follows:

Si is the exposed area of residue i parsed by DSSP, STNi is the total area of nonpolar residue i and Mi is the total mass of residue i.
-
7
The exposed surface score describes the percentage of area of the residues exposed and is calculated as follows:

STi is the total area of residue i parsed by DSSP and Si is the exposed area of residue i.
-
8
The solvent accessibility similarity score is calculated by comparing solvent accessibility predicted SSpro428 from the protein sequence and those of a model parsed by DSSP27.
-
9
The RWplus score12 is an energy score evaluating protein models based on distance-dependent atomic potential. The score is normalized to the range of 0 and 1.
-
10
The ModelEvaluator score13 is a score evaluating protein models based on structural features and support vector machines.
-
11
The Dope score14 is an energy score evaluating protein models based on the reference state of non-interacting atoms in homogeneous sphere. The score is normalized to the range of 0 and 1.





Feature errors estimation
We calculate all feature scores for the models of 99 CASP9 targets, which in total have 22016 models. The feature error is calculated for each model using the following formula:

FEi,j is the error estimate of feature i on model j, Fi,j is the predicted score of feature i on model j and Rj is the real GDT-TS score of model j. Based on these errors, we calculate the mean Mi and standard deviation SDi for each feature i as follows:

i is in the range of 1 and 11 which represent all 11 features. N is the total number of models.
The feature error estimation statistics (mean and standard deviation of each feature) is used for global model quality score assessment.
Feature weight estimation
We use a method similar to EM algorithm for estimating the weight of each feature for combination. The weight for each feature is used to adjust the feature distributions. The algorithm has three steps as following:
-
1
Initialization: Randomly assign a weight to each feature. The weight value is chosen from the range −0.8 to 0.8 with the step size of 0.01 and assign the minimum average GDT-TS loss (Min-Loss) to 1.
-
2
Expectation step: calculating the per-target average loss using the current weight value set W benchmarked on CASP9 targets.
-
3
Maximization step: trying different weight values for feature i while fixing the weight of all other features. For each weight w for feature i, get the average GDT-TS loss from step 2 and updating the Min-Loss (the minimum loss) if it is less than the current value of Min-Loss. The current weight value set W is updated if a new weight w of features i that lowers the loss is found. Repeat step 3 for the next feature i + 1 until all the features are used. And repeat the process until the current weight value set W is not changed.
After applying this algorithm on the CASP9 dataset, we obtain a weight value set W which has the minimum average GDT-TS loss. The best weights for 11 features are: [0.03, 0.09, 0.04, 0.08, 0.08, 0.01, 0.03, 0.10, 0.00, 0.09, −0.02].
Model quality assessment based on probability density function
Given a protein model, we first calculate feature score Prei for each feature i (i is in the range [1 and 11]). And then we calculate the adjusted score (an estimation of the real score) by Adjust_prei = prei-Mi, while the mean Mi and standard deviation SDi of each feature i has been calculated in the feature errors estimation as described above. We use the following probability density function of global quality Xi for each feature i (the mean is Adjust_prei and standard deviation is SDi) to quantify the predicted global quality score Xi:

We normalize the probability score to convert it into the range of 0 and 1 with the following formula:

The final global quality score is calculated by combining all 11 normal distributions from each feature prediction. Given a value X in the range of 0 and 1, we calculate the combined probability score as follows:

The value X that has the maximum combined probability score P_combine(X) is assigned as the global quality score for the model. Here, Wi is the weight of feature i.
Additional Information
How to cite this article: Cao, R. and Cheng, J. Protein single-model quality assessment by feature-based probability density functions. Sci. Rep. 6, 23990; doi: 10.1038/srep23990 (2016).
References
Li, J., Cao, R. & Cheng, J. A large-scale conformation sampling and evaluation server for protein tertiary structure prediction and its assessment in CASP11. BMC bioinformatics 16, 337 (2015).
Cao, R., Bhattacharya, D., Adhikari, B., Li, J. & Cheng, J. Large-scale model quality assessment for improving protein tertiary structure prediction. Bioinformatics 31, i116–i123 (2015).
Wang, Z., Cao, R. & Cheng, J. Three-level prediction of protein function by combining profile-sequence search, profile-profile search and domain co-occurrence networks. BMC bioinformatics 14, S3 (2013).
Cao, R., Bhattacharya, D., Adhikari, B., Li, J. & Cheng, J. Massive integration of diverse protein quality assessment methods to improve template based modeling in CASP11. Proteins: Structure, Function and Bioinformatics, doi: 10.1002/prot.24924 (2015).
Cao, R. & Cheng, J. Integrated protein function prediction by mining function associations, sequences and protein-protein and gene-gene interaction networks. Methods 93, 84–91 (2016).
Cao, R. & Cheng, J. Deciphering the association between gene function and spatial gene-gene interactions in 3D human genome conformation. BMC genomics 16, 880 (2015).
Adhikari, B., Bhattacharya, D., Cao, R. & Cheng, J. CONFOLD: Residue-residue contact-guided ab initio protein folding. Proteins: Structure, Function and Bioinformatics 83, 1436–1449 (2015).
Li, J. et al. The MULTICOM protein tertiary structure prediction system. Protein Structure Prediction 1137, 29–41, doi: 10.1007/978-1-4939-0366-5_3 (2014).
Cao, R., Wang, Z. & Cheng, J. Designing and evaluating the MULTICOM protein local and global model quality prediction methods in the CASP10 experiment. BMC structural biology 14, 13 (2014).
Cao, R., Wang, Z., Wang, Y. & Cheng, J. SMOQ: a tool for predicting the absolute residue-specific quality of a single protein model with support vector machines. BMC bioinformatics 15, 120 (2014).
Rykunov, D. & Fiser, A. Effects of amino acid composition, finite size of proteins and sparse statistics on distance-dependent statistical pair potentials. Proteins: Structure, Function and Bioinformatics 67, 559–568 (2007).
Zhang, J. & Zhang, Y. A novel side-chain orientation dependent potential derived from random-walk reference state for protein fold selection and structure prediction. PLos One 5, e15386, doi: 10.1371 (2010).
Wang, Z., Tegge, A. N. & Cheng, J. Evaluating the absolute quality of a single protein model using structural features and support vector machines. Proteins 75, 638–647, doi: 10.1002/prot.22275 (2009).
Shen, M. y. & Sali, A. Statistical potential for assessment and prediction of protein structures. Protein Science 15, 2507–2524 (2006).
McGuffin, L. The ModFOLD server for the quality assessment of protein structural models. Bioinformatics 24, 586–587 (2008).
Wang, Q., Vantasin, K., Xu, D. & Shang, Y. MUFOLD-WQA: a new selective consensus method for quality assessment in protein structure prediction. Proteins 79, 185–195 (2011).
McGuffin, L. & Roche, D. Rapid model quality assessment for protein structure predictions using the comparison of multiple models without structural alignments. Bioinformatics 26, 182–188 (2010).
Kalman, M. & Ben-Tal, N. Quality assessment of protein model-structures using evolutionary conservation. Bioinformatics 26, 1299–1307 (2010).
Liithy, R., Bowie, J. & Eisenberg, D. Assessment of protein models with three-dimensional profiles. Nature 356, 83–85 (1992).
Ray, A., Lindahl, E. & Wallner, B. Improved model quality assessment using ProQ2. BMC bioinformatics 13, 224 (2012).
Mishra, A., Rao, S., Mittal, A. & Jayaram, B. Capturing native/native like structures with a physico-chemical metric (pcSM) in protein folding. Biochimica et Biophysica Acta (BBA)-Proteins and Proteomics 1834, 1520–1531 (2013).
Benkert, P., Biasini, M. & Schwede, T. Toward the estimation of the absolute quality of individual protein structure models. Bioinformatics 27, 343–350 (2011).
Wang, G. & Dunbrack, R. L. PISCES: a protein sequence culling server. Bioinformatics 19, 1589–1591 (2003).
Kryshtafovych, A. et al. Methods of model accuracy estimation can help selecting the best models from decoy sets: assessment of model accuracy estimations in CASP11. Proteins: Structure, Function and Bioinformatics, doi: 10.1002/prot.24919 (2015).
Wallner, B. & Elofsson, A. Identification of correct regions in protein models using structural, alignment and consensus information. Protein Sci 15, 900–913 (2009).
Faraggi, E., Zhang, T., Yang, Y., Kurgan, L. & Zhou, Y. SPINE X: improving protein secondary structure prediction by multistep learning coupled with prediction of solvent accessible surface area and backbone torsion angles. Journal of computational chemistry 33, 259–267 (2012).
Kabsch, W. & Sander, C. Dictionary of protein secondary structure: pattern recognition of hydrogen-bonded and geometrical features. Biopolymers 22, 2577–2637 (1983).
Cheng, J., Randall, A. Z., Sweredoski, M. J. & Baldi, P. SCRATCH: a protein structure and structural feature prediction server. Nucleic Acids Research 33, W72–W76 (2005).
Acknowledgements
We thank Audrey Van Leunen for checking the English grammar and to the CASP11 organizers and assessors for providing comprehensive data. The work is supported by US National Institutes of Health (NIH) grant (R01GM093123) to JC.
Author information
Authors and Affiliations
Contributions
R.C. and J.C. conceived and designed the method and the system. R.C. implemented the method, built the system and carried out the CASP experiments. R.C. and J.C. wrote the manuscript. All the authors approved the manuscript.
Ethics declarations
Competing interests
The authors declare no competing financial interests.
Rights and permissions
This work is licensed under a Creative Commons Attribution 4.0 International License. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in the credit line; if the material is not included under the Creative Commons license, users will need to obtain permission from the license holder to reproduce the material. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/
About this article

Cite this article
Cao, R., Cheng, J. Protein single-model quality assessment by feature-based probability density functions. Sci Rep 6, 23990 (2016). https://doi.org/10.1038/srep23990
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/srep23990
This article is cited by
-
MASS: predict the global qualities of individual protein models using random forests and novel statistical potentials
BMC Bioinformatics (2020)
-
Deep Learning to Predict Protein Backbone Structure from High-Resolution Cryo-EM Density Maps
Scientific Reports (2020)
-
Identification and localization of Tospovirus genus-wide conserved residues in 3D models of the nucleocapsid and the silencing suppressor proteins
Virology Journal (2019)
-
Role of solvent accessibility for aggregation-prone patches in protein folding
Scientific Reports (2018)
-
Prediction of Local Quality of Protein Structure Models Considering Spatial Neighbors in Graphical Models
Scientific Reports (2017)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
