
Abstract
Following an initial report, there have been multiple replications of an association of alcohol dependence (AD) to markers within a haplotype block that includes the 3′-half of the gene encoding the GABAA α-2 subunit (GABRA2), on chromosome 4p. We examined the intergenic extent of this haplotype block and the association to AD of markers in the adjacent 5′ haplotype block in GABRG1, which encodes the GABAA receptor γ-1 subunit. We genotyped 15 single nucleotide polymorphisms in the GABRG1-GABRA2 interval as well as at 34 ancestry informative markers in three samples: 435 AD and 635 screened control subjects from Connecticut and 812 participants from a multicenter AD treatment trial. We observed two large haplotype blocks in the GABRG1-GABRA2 intergenic interval with a region of increased recombination midway between the two genes. Markers in the two haplotype blocks were in moderate linkage disequilibrium. Compared with markers in the GABRA2 haplotype block, markers in the 5′ GABRG1 haplotype showed greater allelic, genotypic and haplotypic association with AD in European Americans from both AD samples. Logistic regression analysis indicated that genetic elements in the GABRG1 haplotype block likely contribute to AD risk in an additive manner, whereas those in the GABRA2 haplotype block may act in a dominant manner in relation to risk of AD.
Similar content being viewed by others
INTRODUCTION
Alcohol dependence (AD (MIM 103780)) is a common psychiatric disorder, recently estimated to affect 3.8% of the adult US population during a 1-year period (Grant et al, 2004). A variety of adverse consequences are associated with AD, including medical, social and legal problems (Caetano and Cunradi, 2002). Based on heritability estimates ranging from 0.52 to 0.64 (Kendler, 2001), considerable efforts have been made to identify genes that increase risk for the disorder.
Genomewide linkage scans implicated a region on chromosome 4p12 that harbors a cluster of four genes encoding GABAA receptor subunits (γ-1, α-2, α-4, and β-1) (Long et al, 1998; Reich et al, 1998). As GABAA receptors have been implicated in biological processes related to the acute and chronic effects of alcohol (Koob, 2004; Krystal et al, 2006), the GABAA receptor genes at 4p12 are both positional and functional candidates for AD risk. Fine mapping of markers in the chromosome 4p GABAA receptor gene cluster in relation to AD involved a study of 69 single nucleotide polymorphisms (SNPs) in multiplex families from the Collaborative Study on the Genetics of Alcoholism (COGA) (Edenberg et al, 2004). These investigators found significant associations for multiple markers in the gene encoding the GABAA α-2 subunit (GABRA2 (MIM 137140)) and for a single marker in the adjacent GABRG1 (MIM 137166) gene, which encodes the GABAA γ-1 subunit. There was no evidence of association with other members of the gene cluster. This association to GABRA2 was subsequently evaluated in three independent samples of subjects of European ancestry (Covault et al, 2004; Lappalainen et al, 2005; Fehr et al, 2006), and in each sample an association of AD with a haplotype block spanning the central and 3′-regions of GABRA2 was observed.
Two other clusters of genes encoding GABAA subunits, located on chromosomes 5 and 15, have been examined for association to AD in other studies. Results for markers in the GABAA gene cluster containing genes for β-2, α-6, α-1, and γ-2 subunits on chromosome 5q have been mixed, with association reported in some samples (Loh et al, 2000; Radel et al, 2005), but not others (Sander et al, 1999; Dick et al, 2005). Fine mapping of a GABAA gene cluster containing genes for the α-5, β-3, and γ-3 subunits on chromosome 15q showed modest evidence of haplotypic association to AD for SNPs in GABRG3, encoding the γ-3 subunit (Dick et al, 2004).
The present study extends the findings of association of AD to the chromosome 4 GABAA gene cluster by examining the intergenic extent of the GABRA2 3′-region haplotype block associated with AD and by examining markers in the adjacent haplotype block in the 5′-region of GABRG1. We observed a stronger association of GABRG1 5′-upstream markers with AD in both study samples compared with markers in the GABRA2 haplotype block.
MATERIALS AND METHODS
Subjects
Connecticut AD subjects (372 non-Hispanic Caucasians of European decent (EA) and 63 African-Americans (AA)) were recruited as part of ongoing studies of the genetics of AD or from clinical trials for the treatment of AD at the University of Connecticut Health Center (UCHC), Farmington, CT and the VA Connecticut Healthcare Center (VA-CT), West Haven, CT. Controls from CT (535 EA and 100 AA) were recruited by advertisement in the greater Hartford, CT area. Psychiatric diagnoses were made using the Structured Clinical Interview for DSM-III-R or DSM-IV (SCID) (First et al, 1997) or the Semi-Structured Assessment for Drug Dependence and Alcoholism (SSADDA) (Pierucci-Lagha et al, 2005). All controls were screened using the SCID or the SSADDA to exclude individuals with an alcohol or drug use disorder, or other major Axis I psychiatric disorder. Subjects were paid for their participation and all provided written, informed consent to participate in study protocols that were approved by the institutional review boards at UCHC, Yale University School of Medicine, and/or VA-CT. The diagnosis of AD for Project MATCH subjects (727 EA and 85 AA) was made using the Computerized Diagnostic Interview for DSM-IV (Blouin et al, 1988; American Psychiatric Association, 1994). For both the CT and Project MATCH samples, analysis was limited to self-identified AA and EA subjects. For analysis of AA subjects, we pooled AD subjects from the CT (n=63) and Project MATCH (n=85) samples.
Demographic and clinical characteristics of the participant sample are listed in Table 1. For both EA and AA samples, the control groups were significantly younger than the AD groups and included more female subjects. Similar to other samples, AD subjects had a moderate prevalence of affective/anxiety disorders, lifetime diagnosis of cocaine or opioid dependence (lifetime drug dependence diagnoses were not available for the Project MATCH sample) or antisocial personality disorder. Among the CT EA subjects, 294 controls (55%) and 264 alcoholics (71%) were examined in our prior association study of GABRA2 SNPs A-H (Covault et al, 2004).
Genotyping
GABRG1 and GABRA2 SNPs were genotyped using a closed-tube fluorescent TaqMan 5′-nuclease allelic discrimination assay using MGB-probes and primers designed using Primer Express v2.0 software (Applied Biosystems Inc. (ABI), Foster City, CA). Fluorescence plate reads and genotype calls were made using ABI 7700 and 7500 Sequence Detection Systems. Ten nanograms of genomic DNA was PCR amplified in 96-well plates using a 10 μl reaction volume for 40 cycles at 94°C for 15 s followed by 60°C for 60 s. Repeat genotyping was carried out for 16% of samples with an observed error rate of 0.5%. PCR amplifications failed or provided ambiguous genotype results from 1.5% of reactions (1.7% controls, 3.4% CT cases and 0.4% Project MATCH cases). To estimate genetic ancestry proportions for each subject, DNA samples were also genotyped using a panel of 34 short tandem repeat ancestry informative markers: CSF1PO, D2S1338, D3S1358, D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D19S433, D21S11, FGA, TH01, TPO-9, vWA, D17S799, D1S196, D7S640, D8S1827, D7S657, D22S274, D5S407, D2S162, D10S197, D11S935, D9S175, D5S410, D7S2469, D16S3017, D10S1786, D15S1002, D6S1610, D1S2628, D12S352 as described previously (Stein et al, 2004; Luo et al, 2005; Yang et al, 2005).
Genotype distributions were in Hardy–Weinberg equilibrium (HWE) for all 15 SNPs for each of the three EA groups (controls: mean p=0.55, range 0.22–1.0; CT AD subjects: mean p=0.48, range 0.06–1.0; Project MATCH AD subjects: mean p=0.48, range 0.15–1.0). For the AA groups, genotype distributions were consistent with HWE expectations for all but two markers in the control group (mean p=0.41, range 0.04–1.0; rs1440133 (SNP7), p=0.04, and rs529826 (SNP C), p=0.04) and two markers in the AD group (mean p=0.63, range 0.04–1.0; rs534459 (SNP B), p=0.04, and rs529826 (SNP C), p=0.04).
Data Analysis
Diagnostic groups were compared on age using ANOVA and on sex and allele frequencies using 2 × 2 contingency tables and the χ2 test. Linkage disequilibrium (LD) plots, haplotype blocks, allele frequencies, tests of HWE, and haplotype frequencies for each population and diagnostic group were generated using the software program Haploview v3.32 (Barrett et al, 2005). Best-estimate haplotype pairs for each subject were generated using PHASE v2.1.1 software, which incorporates a Bayesian statistical method for reconstructing estimated haplotypes from population data (Stephens et al, 2001; Stephens and Donnelly, 2003). Haplotype pairs were generated separately for AA and EA populations. The software program STRUCTURE v2.1 (Pritchard et al, 2000; Falush et al, 2003) was used to generate estimates of the proportion of African vs European genetic ancestry for each subject based on genotype results from the 34 ancestry informative markers. Simulations used 100 000 burn-ins followed by 500 000 runs and a population parameter K=2. Estimated haplotype frequencies were compared for alcoholics vs controls and AA vs EA controls using a series of 2 × 2 contingency tables for each haplotype compared to the sum of all other haplotypes. The odds ratio (OR) is reported as a measure of effect size. Binary logistic regression analysis was used to control for age, sex, and the proportion of EA genetic ancestry in determining a corrected OR for AD as a function risk haplotype. Statistical analysis was carried out using SPSS software v14.0.
RESULTS
We genotyped 15 SNPs (average inter-marker interval of 20 530 bp, range 6598–39 849 bp) extending 287 400 bp in the GABRG1-GABRA2 region of chromosome 4 in a sample of 1634 self-identified EA and 248 AA subjects, Table 1, comprising AD and control subjects from Connecticut (CT) and a sample of AD subjects from Project MATCH, an NIAAA-sponsored, multicenter clinical trial conducted at 10 sites throughout the US. That study sought to identify predictors of response to three psychotherapeutic treatments for alcoholism (Project MATCH Research Group, 1998). Table 2 lists the primers, MGB-probes and annealing-extension temperatures used to examine the 15 GABRG1-GABRA2 region SNPs. The trivial names for the SNPs examined in GABRA2 (SNPs A–H) are the same as were used previously (Covault et al, 2004); the additional seven SNPs in the intergenic and 5′-region of GABRG1 are numbered 1–7.
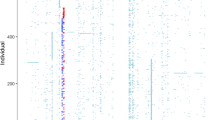
Two main haplotype blocks were observed in EA controls (Figure 1a). One was a 94 kb region that included SNP markers 2–6 and extended from GABRG1 intron 2–62 000 bp 5′ of the GABRG1 transcript start site. The second haplotype block extended 137 kb and included SNP marker 7 (50 000 bp 3′ from the 3′UTR of the GABRA2 transcript) and the seven adjacent SNP markers A–G (ending in GABRA2 intron 3), which we had previously identified as being in high LD with one another (Covault et al, 2004). The LD plot and haplotype block structure for AA subjects was similar to EA subjects regarding the presence of a region of increased recombination in the 14 kb interval between SNPs 6 and 7 (Figure 1b). Among AAs, SNPs 3–6 were in high LD with one another in the GABRG1 block and in the GABRA2 haplotype block region SNP 7 and A–E showed high LD. The LD plot and haplotype block structure for AD subjects paralleled those for the controls of their respective racial group (data not shown).

LD plot from Haploview 3.32 for EA control subjects (a) compared with that for AA control subjects (b). Pairwise SNP ∣D′∣ values (× 100) of linkage are shown together with haplotype blocks identified using the four-gamete rule. Marker pairs in complete LD are indicated by an empty box. Darkened blocks indicate SNP pairs without evidence of extensive recombination (ie 4-gamete rule for haplotype block characterization with one (or two) 2-SNP haplotypes having a frequency <0.02).
GABRG1 allele and genotype frequencies for the three EA groups and the two AA groups are shown in Table 3. Among EAs, all SNPs in the GABRG1 haplotype block (SNPs 2–6) showed significant association (nominal p<0.05) with AD for both allele and genotype frequencies in both the CT and Project MATCH samples. The strongest association (p=0.001) was observed for SNPs 4 and 5 in the 5′-upstream region of the gene. GABRA2 allele and genotype frequencies (SNP7 and SNPs A–H) are shown in Table 4. For the GABRA2 haplotype block region, the three SNPs closest to GABRG1 (ie SNPs 7, A, and B) showed modest allelic and genotypic association with AD in the CT EA sample (p=0.009–0.016 for allelic association), whereas SNPs D–G showed less evidence of association (p=0.021–0.032). In parallel with the CT sample, MATCH EA alcoholics showed a nonsignificantly higher prevalence than controls of the minor allele for each SNP in the 3′ GABRA2 haplotype block (p=0.083–0.167). None of the 15 markers showed allelic association with AD in the AA sample. Allele frequencies in the controls differed significantly by racial population for 13 of the 15 SNPs (Tables 3 and 4, right-hand column).
Haplotype frequencies for the two major haplotype blocks in the GABRG1-GABRA2 interval were estimated using markers defining the slightly shorter core of each block based on the haplotype structure for AAs (Figure 1). Four markers (SNPs 3–6) were used to define the GABRG1 haplotype block and six markers (SNPs 7 and A–E) for the GABRA2 haplotype block. Estimated haplotype frequencies were compared with the sum of all other haplotypes for alcoholics vs controls and for AA vs EA controls using a series of 2 × 2 contingency tables (Tables 5 and 6). Among EAs, two haplotypes comprised >90% of chromosomes for the GABRG1 haplotype block and >95% of chromosomes for GABRA2. AA subjects had a third common haplotype for both haplotype blocks. Haplotype frequencies differed significantly between EA and AA controls. For GABRG1, there was a significantly greater frequency of the ATCC haplotype in AD than controls in both EA groups (Δ=0.078 in CT EA cases, p<0.001; 0.064 in MATCH EA cases, p=0.002), but this did not reach significance in AA cases (Δ=0.059). For the 6-SNP GABRA2 3′-region haplotype, there was a nonsignificantly greater frequency of the AGACTC minor haplotype in EA alcoholics than controls (Δ=0.046 in CT cases, p=0.052 and 0.028 in MATCH cases, p=0.20). The frequency of the GABRA2 AGACTC minor haplotype did not differ by diagnosis among AAs.
There was a moderate degree of LD between markers in the two haplotype blocks (r=0.51–0.59 for EA subjects and r=0.00–0.53 for AA subjects). To examine whether variation in one or the other of the two adjacent genes accounted for the association to AD, we examined the phase and pattern of linkage of the adjacent GABRG1 and GABRA2 haplotype blocks by estimating the frequency of extended haplotypes defined by the 10 SNPs from these two blocks. Table 7 lists the frequency of the most common 10-SNP haplotypes covering the larger 208 000 bp interval. The most common extended haplotype among EAs (TCTT-GAGTGT) was under represented in both of the EA alcoholic samples (Δ=0.098 in CT cases and Δ=0.059 in MATCH cases; p<0.001 and 0.002, respectively). Chromosomes with the GABRG1 risk haplotype (ATCC) were overrepresented in EA alcoholics, irrespective of the GABRA2 haplotype in both EA samples. The distortion was greatest when the less common GABRG1 risk haplotype was paired with the major GABRA2 haplotype (GAGTGT) (Δ=0.042 in CT cases, and Δ=0.044 in MATCH cases; p=0.04 and p=0.005, respectively). In contrast, the GABRA2 haplotype defined by the minor allele at each marker (AGACTC), which we previously found to be associated with AD (Covault et al, 2004), when paired with the GABRG1 non-risk haplotype (TCTT), did not differ in frequency between EA alcoholics and controls in the present analysis. A more formal restatement of this analysis is to examine the ratio in cases vs controls of the two putative risk haplotypes with each conditional on the presence of the other. Both haplotype ratios, f(AB)/f(Ab) and f(aB)/f(ab), are expected not to differ in cases and controls if the ‘A vs a’ component of the haplotype identifies a disease-associated marker and the ‘B vs b’ site represents a neutral marker, irrespective of genetic mode of inheritance (Valdes and Thomson, 1997). The χ2 test of the null hypothesis that these ratios are equivalent is rejected (p<0.01) in EA AD samples, if the GABRA2 AD-associated haplotype is considered the risk marker and the GABRG1 haplotype is considered the neutral marker. In this context, markers in the GABRA2 haplotype block do not capture all of the disease risk associated with this chromosomal region. In contrast, the null hypothesis that the ratios are equivalent is sustained (p>0.2) when the GABRG1 AD-associated haplotype block is treated as the conditional risk marker. Equivalent results were obtained examining 2-SNP haplotypes using a single representative SNP for the GABRG1 and GABRA2 blocks (eg SNPs 4 and A). These observations suggest that the allelic and haplotypic association of GABRA2 SNPs with AD in our CT sample in both this and our prior study (Covault et al, 2004) may in part be secondary to LD of these markers with risk-related variants in the adjacent GABRG1 5′-region. In AAs, although not statistically significant, the extended 10-SNP haplotype pattern was qualitatively similar to the pattern in EAs, in that there was a greater frequency of chromosomes with an extended haplotype containing the GABRG1 ATCC motif.
Significant racial population differences were observed in the allele frequencies for 13 of the 15 SNPs, as well as for the most common haplotypes for the GABRG1 and GABRA2 blocks (Tables 3, 4, 5 and 6). To evaluate population genetic stratification, we used the program STRUCTURE v2.1 (Pritchard et al, 2000; Falush et al, 2003) to generate estimates of the proportion of African vs European genetic ancestry using genotype results from a panel of 34 ancestry informative markers (Stein et al, 2004; Luo et al, 2005; Yang et al, 2005). We found no differences in the degree of EA genetic ancestry in the three EA samples (controls=0.980±0.043, CT alcoholics=0.980±0.043, and MATCH alcoholics=0.983±0.029; F(2,1631)=1.56, p=0.21). Consequently, population stratification is unlikely to be an explanation for the observed allele frequency differences between EA alcoholics and controls. Similarly, for AAs, there was no significant difference in estimated European genetic admixture for alcoholics and controls (0.084±0.149 and 0.054±0.143, respectively; F(1,246)=1.61, p=0.11).
Quantitative estimates of genetic ancestry proportion from STRUCTURE were also used as a covariate in binary logistic regression analysis (together with age and sex, which differed by diagnosis). This yielded corrected ORs for AD as a function of GABRG1 or GABRA2 AD-associated haplotype copy number as determined using PHASE. Dominant, recessive, and additive models were compared using dummy coding: 0, 1, 1; 0, 0, 1; and 0, 0.5, 1, respectively, for 0, 1 or 2 copies of the GABRG1 or GABRA2 AD-associated haplotype (ie ATCC or AGACTC, respectively). For EAs (combined MATCH and CT alcoholics), an additive genetic model provided the best fit for the GABRG1 ATCC haplotype (Table 8), with an OR=1.26 (95% CI=1.06–1.50) for one copy (ie ATCC/x) and OR=1.60 (95% CI=1.13–2.25) for two copies of the AD-associated haplotype (ie ATCC/ATCC). Qualitatively similar results were seen when age, sex, and genetic ancestry were omitted from the model. For the GABRA2 AGACTC haplotype, a dominant genetic model provided the best fit and an OR=1.39 (95% CI=1.08–1.80) for carriers. These models did not show interactive effects of haplotype with either gender or genetic ancestry proportion. Owing to the collinearity of the two risk haplotypes, we were unable simultaneously to examine the independent effects on AD risk of the GABRG1 and GABRA2 haplotype blocks. There was no evidence that the association of AD with GABRG1 or GABRA2 markers in the CT sample was due to comorbid drug dependence (relevant data were not available for Project MATCH). Considering the impact of drug dependence, ORs for the AD risk haplotypes were marginally greater (GABRG1) or unchanged (GABRA2) for subjects in the CT EA sample with no comorbid lifetime diagnosis of cocaine, opioid, or cannabis dependence compared with all CT EA alcoholics (GABRG1 additive model OR=1.35 (95% CI=1.05–1.74) vs 1.25 (95% CI=0.99–1.58) for one copy and OR=1.82 (95% CI=1.09–3.04) vs 1.56 (95% CI=0.98–2.48) for two copies of the GABRG1 risk haplotype; GABRA2 dominant model OR=1.45 (95% CI=0.99–2.14) vs 1.40 (95% CI=0.98–1.99) for carriers).
Finally, based on the apparent difference in genetic mode of action of risk elements potentially represented in the two haplotype blocks, we used binary logistic regression analysis to derive corrected measures for association of individual SNPs with AD in the combined EA sample using variable coding for both additive and dominant genetic models. Figure 2 illustrates the log10 (p-value) from binary logistic regression analyses in which age, sex, and genetic ancestry were used as covariates. The strongest association with AD was seen for SNPs 4 and 5 (rs7654165 and rs10033451) in the 5′-upstream region of GABRG1 assuming an additive genetic model followed by SNPs 7, A, and B (rs1440133, rs567926, and rs534459) in the 3′region of GABRA2 assuming a dominant genetic model. This difference in the best-fit genetic model for markers in the two haplotype block regions suggests that there may be separate contributions to risk for AD by GABRG1 and GABRA2.

Negative log10 of binary logistic regression significance (p-value) for allelic association with AD after correction for age, sex, and proportion of EA genetic ancestry among all EA subjects (1099 AD and 535 controls) as a function of GABRG1 and GABRA2 SNP location assuming additive (– –□– –) or dominant (—▵—) genetic models. SNPs within each of the two haplotype blocks identified in Figure 1a for EA subjects are joined by a line. Marker positions are shown relative to the mid-point between these two haplotype blocks. Consistent with results from haplotype analysis regarding potential mode of risk transmission, individual markers in the GABRG1 haplotype block show a larger effect under an additive model, whereas those in the GABRA2 block are more consistent with a dominant genetic effect model.
DISCUSSION
The findings reported here suggest that the association of GABRA2 with AD, as reported in four independent studies (Covault et al, 2004; Edenberg et al, 2004; Lappalainen et al, 2005; Fehr et al, 2006), may be complicated by a moderate degree of LD between markers in the 3′-region of GABRA2 with those in the 5′-region of GABRG1. Although prior studies showed consistent evidence for association of AD to markers and haplotypes in the middle and 3′-region of GABRA2, the extent of the AD-associated GABRA2 haplotype block and the potential association of AD to markers in the adjacent haplotype block were not well described. Edenberg et al (2004) examined six SNPs in the adjacent GABRG1 gene (0.4 kb upstream to IVS8) and found nominal evidence for association (p=0.05) to AD for one of the markers within the 5′-region haplotype block of GABRG1, which was examined in this report. Seeking to define the extent of the GABRA2 3′-region haplotype block, we genotyped markers extending into the 5′-region of GABRG1, where we found evidence among EAs of association to AD that exceeded the evidence for allelic and haplotypic association for GABRA2. Indeed, in the Project MATCH EA sample, the distortion of allele and haplotype frequencies related to AD for GABRA2 markers was not statistically significant, whereas allele and haplotype frequencies in the haplotype block in the GABRG1 5′-region showed significant evidence of association in both EA samples. These findings were unaffected when corrections for age, sex, and ancestry proportion were included in the analysis. These results suggest that our prior reported findings of association of AD with the GABRA2 gene (Covault et al, 2004) were partly due to LD of GABRA2 markers with functional genetic variation in the adjacent GABRG1 gene.
It is of interest to note that in the three published case–control studies (Covault et al, 2004; Lappalainen et al, 2005; Fehr et al, 2006), AD was associated with the minor allele and haplotype for markers in the 3′-region of GABRA2, consistent with the findings reported here for the EA alcoholic sample from CT. In contrast, in the COGA multiplex family sample, the more common haplotype was overrepresented among alcoholics (Edenberg et al, 2004). Re-analysis of the COGA data set revealed that the association of the major allele at markers in the 3′-region of GABRA2 with AD was observed only among subjects dependent on both alcohol and drugs (Agrawal et al, 2006).
We observed large differences in allele frequencies for AA vs EA subjects at 13 of the 15 SNPs examined. Population differences in marker frequencies have been observed in other candidate genes related to substance use disorders (Gelernter et al, 1997, 1999; Covault et al, 2001; Luo et al, 2003; Herman et al, 2006). Such population differences highlight the need to consider population genetic stratification as a potential source of artifact in genetic association studies. Further, results from a recent gene expression microarray study noted that differences in frequency of cis-acting SNPs among ethnic groups may also be associated with significant differences in RNA expression levels of the associated genes (Spielman et al, 2007).
Limitations of our study include the lack of a sample of controls collected at each of the Project MATCH treatment sites, which required comparison of allele and haplotype frequencies for both samples of AD subjects with a common control sample recruited exclusively from Connecticut. However, we found no evidence of differences in genetic admixture between the CT and MATCH alcoholic samples. Although we observed a similar magnitude of increase in frequency of the GABRG1 risk haplotype ATCC in AA and EA subjects, our small sample of AA subjects yielded limited statistical power. The sample of female alcoholics also limited our capacity to examine with high statistical power interactive effects of sex × genotype. Finally, the lack of data on lifetime drug dependence diagnoses in the Project MATCH sample limited our ability to examine whether in the CT AD sample, the association of AD to GABRG1 markers was independent of comorbid drug dependence.
The findings from this study provide important new information regarding the likely physical location of functional genetic variants responsible for the reported association of AD to the GABAA receptor subunit gene cluster on chromosome 4p. The region of strongest association to AD that we observed includes potential regulatory regions immediately upstream of the GABRG1 gene. The markers with the strongest association, rs7654165 and rs10033451, are located 1 and 26 kb upstream of the 5′end of the GABRG1 transcript, respectively, suggesting that functional variants related to AD in this interval might alter the patterns of regional, cellular, or temporal expression of GABRG1. The γ-1 subunit is notable, in that unlike most GABAA subunits, its expression is limited to very few brain areas, including the pallidum, septum, bed nucleus of the stria terminalis and the central and medial amygdaloid nuclei (Ymer et al, 1990; Araki et al, 1992; Persohn et al, 1992; Wisden et al, 1992; Pirker et al, 2000). Other brain regions that show selective expression of γ-1 (eg hypothalamic medial preoptic area) vs γ-2 subunits (eg ventromedial nucleus of the hypothalamus) (Herbison and Fenelon, 1995; Nett et al, 1999) differ in GABAA pharmacologic properties and show opposite effects with respect to receptor modulation by anabolic steroids (Jorge-Rivera et al, 2000). Additional differences in the pharmacology of γ-1-containing receptors include an insensitivity to the benzodiazepine antagonist flumazenil (Ymer et al, 1990; Khom et al, 2006) and an increased sensitivity of γ-1-containing receptors to the neuroactive steroid allopregnanolone in transfected human embryonic kidney (HEK293) cells compared with γ-2-containing receptors (Puia et al, 1993). Pharmacologic agents that are selective for γ-1-containing GABAA receptors may be of clinical interest given the limited CNS distribution of this receptor subunit.
References
Agrawal A, Edenberg HJ, Foroud T, Bierut LJ, Dunne G, Hinrichs AL et al (2006). Association of GABRA2 with Drug Dependence in the Collaborative Study of the Genetics of Alcoholism Sample. Behav Genet 36: 640–650.
American Psychiatric Association (1994). Diagnostic and Statistical Manual of Mental Disorders, 4th edn. American Psychiatric Press: Washington, DC.
Araki T, Kiyama H, Tohyama M (1992). The GABAA receptor gamma 1 subunit is expressed by distinct neuronal populations. Brain Res Mol Brain Res 15: 121–132.
Barrett JC, Fry B, Maller J, Daly MJ (2005). Haploview: analysis and visualization of LD and haplotype maps. Bioinformatics 21: 263–265.
Blouin AG, Perez EL, Blouin JH (1988). Computerized administration of the Diagnostic Interview Schedule. Psychiatry Res 23: 335–344.
Caetano R, Cunradi C (2002). Alcohol dependence: a public health perspective. Addiction 97: 633–645.
Covault J, Gelernter J, Kranzler H (2001). Association study of cannabinoid receptor gene (CNR1) alleles and drug dependence. Mol Psychiatry 6: 501–502.
Covault J, Gelernter J, Nellissery M, Kranzler HR (2004). Allelic and haplotypic association of GABRA2 with alcohol dependence. Am J Med Genetics 129B: 104–109.
Dick DM, Edenberg HJ, Xuei X, Goate A, Hesselbrock V, Schuckit M et al (2005). No association of the GABAA receptor genes on chromosome 5 with alcoholism in the collaborative study on the genetics of alcoholism sample. Am J Med Genet B Neuropsychiatr Genet 132: 24–28.
Dick DM, Edenberg HJ, Xuei X, Goate A, Kuperman S, Schuckit M et al (2004). Association of GABRG3 with alcohol dependence. Alcohol Clin Exp Res 28: 4–9.
Edenberg HJ, Dick DM, Xuei X, Tian H, Almasy L, Bauer LO et al (2004). Variations in GABRA2, encoding the alpha 2 subunit of the GABAA receptor, are associated with alcohol dependence and with brain oscillations. Am J Hum Genet 74: 705–714.
Falush D, Stephens M, Pritchard JK (2003). Inference of population structure using multilocus genotype data: linked loci and correlated allele frequencies. Genetics 164: 1567–1587.
Fehr C, Sander T, Tadic A, Lenzen KP, Anghelescu I, Klawe C et al (2006). Confirmation of association of the GABRA2 gene with alcohol dependence by subtype-specific analysis. Psychiatr Genet 16: 9–17.
First MB, Spitzer RL, Gibbon M, Williams JBW (1997). Strutured Clinical Interview for DSM-IV Axis I Disorders. APA Press: Washington, DC.
Gelernter J, Kranzler H, Cubells J (1999). Genetics of two mu opioid receptor gene (OPRM1) exon I polymorphisms: population studies, and allele frequencies in alcohol- and drug-dependent subjects. Mol Psychiatry 4: 476–483.
Gelernter J, Kranzler H, Cubells JF (1997). Serotonin transporter protein (SLC6A4) allele and haplotype frequencies and linkage disequilibria in African- and European-American and Japanese populations and in alcohol-dependent subjects. Hum Genet 101: 243–246.
Grant BF, Dawson DA, Stinson FS, Chou SP, Dufour MC, Pickering RP (2004). The 12-month prevalence and trends in DSM-IV alcohol abuse and dependence: United States, 1991–1992 and 2001–2002. Drug Alcohol Depend 74: 223–234.
Herbison AE, Fenelon VS (1995). Estrogen regulation of GABAA receptor subunit mRNA expression in preoptic area and bed nucleus of the stria terminalis of female rat brain. J Neurosci 15 (3 Part 2): 2328–2337.
Herman AI, Kranzler HR, Cubells JF, Gelernter J, Covault J (2006). Association study of the CNR1 gene exon 3 alternative promoter region polymorphisms and substance dependence. Am J Med Genet B Neuropsychiatr Genet 141B: 499–503.
Jorge-Rivera JC, McIntyre KL, Henderson LP (2000). Anabolic steroids induce region- and subunit-specific rapid modulation of GABA(A) receptor-mediated currents in the rat forebrain. J Neurophysiol 83: 3299–3309.
Kendler KS (2001). Twin studies of psychiatric illness: an update. Arch Gen Psychiatry 58: 1005–1014.
Khom S, Baburin I, Timin EN, Hohaus A, Sieghart W, Hering S (2006). Pharmacological properties of GABAA receptors containing gamma1 subunits. Mol Pharmacol 69: 640–649.
Koob GF (2004). A role for GABA mechanisms in the motivational effects of alcohol. Biochem Pharmacol 68: 1515–1525.
Krystal JH, Staley J, Mason G, Petrakis IL, Kaufman J, Harris RA et al (2006). Gamma-aminobutyric acid type A receptors and alcoholism: intoxication, dependence, vulnerability, and treatment. Arch Gen Psychiatry 63: 957–968.
Lappalainen J, Krupitsky E, Remizov M, Pchelina S, Taraskina A, Zvartau E et al (2005). Association between alcoholism and gamma-amino butyric acid alpha2 receptor subtype in a Russian population. Alcohol Clin Exp Res 29: 493–498.
Loh EW, Higuchi S, Matsushita S, Murray R, Chen CK, Ball D (2000). Association analysis of the GABA(A) receptor subunit genes cluster on 5q33–34 and alcohol dependence in a Japanese population. Mol Psychiatry 5: 301–307.
Long JC, Knowler WC, Hanson RL, Robin RW, Urbanek M, Moore E et al (1998). Evidence for genetic linkage to alcohol dependence on chromosomes 4 and 11 from an autosome-wide scan in an American Indian population. Am J Med Genet 81: 216–221.
Luo X, Kranzler HR, Zhao H, Gelernter J (2003). Haplotypes at the OPRM1 locus are associated with susceptibility to substance dependence in European-Americans. Am J Med Genet B Neuropsychiatr Genet 120: 97–108.
Luo X, Kranzler HR, Zuo L, Yang BZ, Lappalainen J, Gelernter J (2005). ADH4 gene variation is associated with alcohol and drug dependence: results from family controlled and population-structured association studies. Pharmacogenet Genomics 15: 755–768.
Nett ST, Jorge-Rivera JC, Myers M, Clark AS, Henderson LP (1999). Properties and sex-specific differences of GABAA receptors in neurons expressing gamma1 subunit mRNA in the preoptic area of the rat. J Neurophysiol 81: 192–203.
Persohn E, Malherbe P, Richards JG (1992). Comparative molecular neuroanatomy of cloned GABAA receptor subunits in the rat CNS. J Comp Neurol 326: 193–216.
Pierucci-Lagha A, Gelernter J, Feinn R, Cubells JF, Pearson D, Pollastri A et al (2005). Diagnostic reliability of the Semi-structured Assessment for Drug Dependence and Alcoholism (SSADDA). Drug Alcohol Depend 80: 303–312.
Pirker S, Schwarzer C, Wieselthaler A, Sieghart W, Sperk G (2000). GABA(A) receptors: immunocytochemical distribution of 13 subunits in the adult rat brain. Neuroscience 101: 815–850.
Pritchard JK, Stephens M, Donnelly P (2000). Inference of population structure using multilocus genotype data. Genetics 155: 945–959.
Project MATCH Research Group (1998). Matching alcoholism treatments to client heterogeneity: treatment main effects and matching effects on drinking during treatment. J Stud Alcohol 59: 631–639.
Puia G, Ducic I, Vicini S, Costa E (1993). Does neurosteroid modulatory efficacy depend on GABAA receptor subunit composition? Receptors Channels 1: 135–142.
Radel M, Vallejo RL, Iwata N, Aragon R, Long JC, Virkkunen M et al (2005). Haplotype-based localization of an alcohol dependence gene to the 5q34 {gamma}-aminobutyric acid type A gene cluster. Arch Gen Psychiatry 62: 47–55.
Reich T, Edenberg HJ, Goate A, Williams JT, Rice JP, Van Eerdewegh P et al (1998). Genome-wide search for genes affecting the risk for alcohol dependence. Am J Med Genet 81: 207–215.
Sander T, Ball D, Murray R, Patel J, Samochowiec J, Winterer G et al (1999). Association analysis of sequence variants of GABA(A) alpha6, beta2, and gamma2 gene cluster and alcohol dependence. Alcohol Clin Exp Res 23: 427–431.
Spielman RS, Bastone LA, Burdick JT, Morley M, Ewens WJ, Cheung VG (2007). Common genetic variants account for differences in gene expression among ethnic groups. Nat Genet 39: 226–231.
Stein MB, Schork NJ, Gelernter J (2004). A polymorphism of the beta1-adrenergic receptor is associated with low extraversion. Biol Psychiatry 56: 217–224.
Stephens M, Donnelly P (2003). A comparison of bayesian methods for haplotype reconstruction from population genotype data. Am J Hum Genet 73: 1162–1169.
Stephens M, Smith NJ, Donnelly P (2001). A new statistical method for haplotype reconstruction from population data. Am J Hum Genet 68: 978–989.
Valdes AM, Thomson G (1997). Detecting disease-predisposing variants: the haplotype method. Am J Hum Genet 60: 703–716.
Wisden W, Laurie DJ, Monyer H, Seeburg PH (1992). The distribution of 13 GABAA receptor subunit mRNAs in the rat brain. I. Telencephalon, diencephalon, mesencephalon. J Neurosci 12: 1040–1062.
Yang BZ, Zhao H, Kranzler HR, Gelernter J (2005). Practical population group assignment with selected informative markers: characteristics and properties of Bayesian clustering via STRUCTURE. Genet Epidemiol 28: 302–312.
Ymer S, Draguhn A, Wisden W, Werner P, Keinanen K, Schofield PR et al (1990). Structural and functional characterization of the gamma 1 subunit of GABAA/benzodiazepine receptors. EMBO J 9: 3261–3267.
Acknowledgements
The assistance of Linda Burian, Dawn Perez, and Tracy Drzyzga in the conduct of this work and statistical consultation by Hongyu Zhao, PhD are greatly appreciated. We are also grateful to Project MATCH investigators and NIAAA for providing access to clinical data and blood samples from that multicenter study. This study was supported by NIH grants P50 AA03510, M01 RR06192, R01 AA11330, R01 AA015606, K24 AA13736, and K24 DA15105.
Author information
Authors and Affiliations
Corresponding author
Additional information
Conflicts of interest statement
None of the authors have conflicts of interest related to this work and have not had any conflict related to the work within the past 3 years.
Rights and permissions
About this article
Cite this article
Covault, J., Gelernter, J., Jensen, K. et al. Markers in the 5′-Region of GABRG1 Associate to Alcohol Dependence and are in Linkage Disequilibrium with Markers in the Adjacent GABRA2 Gene. Neuropsychopharmacol 33, 837–848 (2008). https://doi.org/10.1038/sj.npp.1301456
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1038/sj.npp.1301456
Keywords
This article is cited by
-
GABAA receptor polymorphisms in alcohol use disorder in the GWAS era
Psychopharmacology (2018)
-
α2-containing GABA(A) receptors: a requirement for midazolam-escalated aggression and social approach in mice
Psychopharmacology (2015)
-
Association of Gamma-Aminobutyric Acid A Receptor α2 Gene (GABRA2) with Alcohol Use Disorder
Neuropsychopharmacology (2014)
-
The Genetics, Neurogenetics and Pharmacogenetics of Addiction
Current Behavioral Neuroscience Reports (2014)
-
Examination of Genetic Variation in GABRA2 with Conduct Disorder and Alcohol Abuse and Dependence in a Longitudinal Study
Behavior Genetics (2014)
