
Abstract
Ground subsidence caused by natural factors, including groundwater, has been extensively researched. However, there have been few studies on ground sink caused mainly by artifacts, including underground pipelines in urban areas. This paper proposes a method of predicting ground sink susceptibility caused by underground pipelines. Underground pipeline data, drilling data, and 77 points of ground sink occurrence were collected for five 1 × 1 km urban areas. Furthermore, three ground sink conditioning factors (GSCFs) (pipe deterioration, diameter, and length) were identified by correlation analysis. Pipe deterioration showed the highest correlation with ground sink occurrence, followed by pipe length and pipe diameter in that order. Next, four machine learning methods [multinomial logistic regression (MLR), decision tree (DT) classifier, random forest (RF) classifier, and gradient boosting (GB) classifier] were applied. The results show that GB classifier had the highest accuracy of 0.7432, whereas the accuracy of RF classifier was 0.7407; thus, GB classifier was not significantly more accurate. RF classifier showed the highest reliability (0.84, 0.70, 0.87) according to the area under the receiver operating characteristic (AUC–ROC) curve. Ground sink susceptibility maps (GSSMs) of the five regions in an urban area were created using RF classifier, which performed the best overall.
Similar content being viewed by others
Introduction
Ground sink is a geological disaster with various causes. It has caused large amounts of damage in urban areas, for example, Seoul1, Jeong-am2, Beijing3, Lazio4, Al Ain5, and Perak6. In South Korea, 169 ground sinks occurred in the past seven years in Seoul7, and 3328 ground sinks reportedly occurred between 2010 and 20148. However, most of the accidents that occurred in South Korea were caused by artifacts rather than sinkholes resulting from natural factors, and the term “sinkhole” is often misused. Ground sink is an academic term for a phenomenon in which the surface collapses very rapidly for several reasons and exhibits local movement downward, as defined by the Ministry of Land, Infrastructure and Transport9. Phenomena similar to ground sink include ground subsidence, in which the ground slowly sinks for a long time because of natural or artificial factors, and sinkholes, where layers such as limestone, gypsum, and rock salt are lost and collapse owing to chemical effects9. Sinkholes, which are often confused with ground sinks, are related mainly to the composition of limestone in the ground as well as groundwater movement. Cavities are generated as the limestone layer is eroded by groundwater, which eventually causes the cavities to collapse4,10. Factors that can cause ground sink include groundwater exploitation, irrigation, mining, and subway development2,3,5,11. Ground sink that occurs outside of urban areas generally does not cause extensive damage. However, when ground sink occurs in an urban area, infrastructure such as underground utilities, roads, bridges, and railways can be damaged, possibly causing environmental, social, and economic harm12.
Many studies have used machine learning algorithms to predict ground subsidence. For example, Taheri et al.11 used four Bayes-based machine learning algorithms. They reported that water level decline and the penetration of deep wells into karst aquifers are the most important conditioning factors (CFs). Arabameri et al.13 used three machine learning algorithms, i.e., an artificial neural network (ANN), bagging, and ANN-bagging. They reported that groundwater drawdown, ground use and ground cover, elevation, and lithology are the most important CFs.
Many studies have analyzed natural factors using mainly topographic or geological factors such as altitude, slope, slope aspect, curvature, fault, and ground use. Some studies have considered anthropogenic factors, including groundwater exploitation, ground use, roads, and subways. Among these factors, groundwater exploitation significantly affects ground sink. For example, Xu et al.14 investigated the ground sink CFs (GSCFs) of urban areas in Shanghai, China, and revealed that groundwater level decline, the construction of underground structures, building load, and dynamic load were related to ground sink. However, this study was limited as it considered only building foundations and rail tunnels as underground structures. Underground pipelines such as water pipes, sewer pipes, underground power pipes, natural gas pipelines, heat pipes, and communication lines did not receive sufficient attention.
As shown by these examples, topographic or geological factors have been used for susceptibility prediction and helped predict sinkholes or ground subsidence caused by natural factors. In Korea, the Samcheok and Yeongwol areas of Gangwon-do are underlain by limestone; thus, sinkholes may occur. Most of Seoul, an urban area, is underlain by granite and gneiss; thus, sinkholes are unlikely15. Instead, ground sink frequently occurs in urban areas. The Ministry of Environment reported that ground sinks in Korean cities were caused mainly by water and sewer pipes16. Specifically, 83.2% of the 3,328 ground sinks that occurred between 2010 and 2014 in Seoul were found to result from water and sewer pipes8. In light of this finding, this study aims to develop a machine learning model that determines the susceptibility to ground sink due to underground pipelines by analyzing the correlation between underground pipeline data and ground sink in urban areas.
This study proposes a method of identifying underground pipeline data correlated with ground sink and using machine learning to evaluate ground sink susceptibility. The proposed method has six steps: extraction of underground pipeline data attributes, data preprocessing, correlation analysis and significance evaluation, selection of GSCFs, susceptibility evaluation using machine learning, and validation. Finally, areas susceptible to ground sink are visualized by generating ground sink susceptibility maps (GSSMs).
The contributions of this study are as follows. First, datasets were constructed using points of ground sink occurrence, underground pipeline data, and drilling data. The points of ground sink occurrence were used as labels. Attributes that were estimated to be related to ground sink were extracted from the underground pipeline and drilling data. Datasets were constructed using both the labels and attributes. Second, this study focused on the impact of underground pipelines on ground sink. It was assumed that underground pipelines had a greater impact on ground sink in urban areas. Therefore, ground sink was evaluated using underground pipeline data.
This manuscript is organized as follows. “Study area” describes the natural and underground pipeline characteristics of the study area. “Data” explains the underground pipeline data, which were used as the raw data, and GSCFs. “Methods” describes the overall process in terms of correlation and significance, the machine learning model, accuracy evaluation, and validation. “Results” discusses the accuracy of the model and the GSSMs it was used to generate. Finally, “Conclusion” presents the conclusions.
Study area
In this study, an urban area in South Korea where ground sink occurs frequently was selected to analyze the impact of ground sink generation by pipelines built under the urban area and evaluate the susceptibility. The urban area is a large city with a population exceeding one million and is considered to have a high risk of ground sink caused by underground pipelines because of its high concentration of underground pipelines. We selected five locations (A, B, C, D, and E) at which large ground sinks have occurred and then constructed underground pipeline data for areas 1 × 1 km in size, which were used for analysis. The data provision agreement makes it difficult to reveal the study area where the data were extracted. The key contribution of this study is the development of a machine learning model that uses underground pipeline data to classify ground sink susceptibility; the pipe type, pipe length, and pipe deterioration are more important factors in ground sink than the specific area. Therefore, the results of the study can be reported clearly even if the study area is not identified precisely.
Data
Raw data
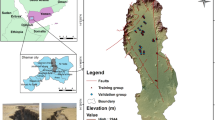
Points of ground sink occurrence, underground pipeline data, and drilling data were used as the raw data. The points of ground sink are described using the X and Y coordinates, address, cause of ground sink, and recovery status of each location. The 77 points of ground sink occurrence in A, B, C, D, and E are shown in Fig. 1.

Points of ground sink occurrence.
The underground pipeline data consist of data concerning water pipes, sewer pipes, underground power pipes, natural gas pipelines, heat pipes, and communication lines. The data contain geographic feature symbols, administrative region codes, management agency codes, and the installation date, diameter, material, and depth of each pipe.
The drilling data include borehole name, X and Y coordinates, groundwater depth, ground layer start and end depths, ground layer thickness, ground layer name, Unified Soil Classification System (USCS) class, and soil color. The drilling data contain information about the ground layer from the surface to the drilling end point. The soils were classified into 18 types according to the USCS.
Selection of ground sink conditioning factors
Ground sink is related to groundwater level decline, underground utilities, and building load14. According to a report on urban areas, water and sewer pipe damage is among the major causes of ground sink9,17. This study used CFs related to pipelines as well as the attributes of underground pipeline data that have been used in previous studies. Geotechnical data were selected as the geological factor, and the pipe deterioration, pipe diameter, and pipe length were selected as the GSCFs. The data were initially analyzed assuming that pipe depth also affects ground sink. However, the analysis showed that pipe depth was not a meaningful characteristic because most pipelines were located with 3 m of the surface. Water pipes, sewer pipes, underground power pipes, natural gas pipelines, heat pipes, and communication lines associated with underground pipelines were considered as pipelines. The factors were selected according to the literature and expert knowledge. The selected factors are summarized as follows. First, the study area was divided into 100 \(\times\) 100 m grids and split into 500 cells. Then the values of the selected factors were extracted or calculated for each cell. The results are shown in Fig. 2.


Ground sink conditioning factors.
Pipe deterioration
The pipe installation year was among the attributes of underground pipelines used to indicate deterioration. Data for the period 1972 to 2017 were used, and pipes installed 30 years ago or more were determined to have deteriorated. According to “Service life of buildings etc.” (related to Subparagraph 1 of Paragraph 1 of Article 19) of the enforcement rules of the Local Public Enterprises Act, the service life of stainless steel, cast iron, and steel pipes is 30 years; that of galvanized steel pipes is 10 years, and those of other pipes are 20 to 30 years. Therefore, pipelines installed before 1992 were grouped into one category. In addition, the data for pipelines less than 30 years old were discretized to improve the machine learning prediction accuracy18. To prevent information loss during discretization, the learning results were compared after discretization was performed by dividing the data into 5- and 10-year intervals. Seven 5-year categories were obtained: 1972–1991, 1992–1996, 1997–2001, 2002–2006, 2007–2011, 2012–2016, and 2017. The four 10-year categories were 1972–1991, 1992–2001, 2002–2011, and 2012–2017. After the study area was divided into 500 cells in 100 × 100 m grids, the pipe length for each category was calculated for each cell and discretized into 100 m units. The results are shown in Fig. 2a.
Pipe diameter
The pipe diameter was selected from the attributes of the underground pipeline data. The pipe diameters were divided into four categories: 0–100 mm, 100–500 mm, 500–1000 mm, and 1000–2400 mm. After the study area was divided into 500 cells in 100 \(\times\) 100 m grids, the pipe length for each pipe diameter category was calculated for each cell and discretized into 100 m units. The results are shown in Fig. 2b.
Pipe length
The pipe length was selected from the attributes of the underground pipeline data. Among the six types of underground pipelines, heat pipes were excluded because they had a negative correlation. Two methods were used to divide the category of pipeline length. First, the pipes were divided into five categories: water pipes, sewer pipes, underground power pipes, natural gas pipelines, and communication lines. Second, they were classified by material into group 1 (water pipes, natural gas pipelines), group 2 (underground power pipes, communication lines), and group 3 (sewer pipes). After the study area was divided into 500 cells in 100 \(\times\) 100 m grids, the pipe length category for each cell was calculated. The pipe length was discretized into 100 m units. The results are shown in Fig. 2c.
Geotechnical data
The X and Y coordinates of each borehole, ground layer start and end depths, ground layer thickness, and USCS class, which are attributes related to drilling data, were used as geotechnical data. The drilling data were visualized in 3D using ArcGIS software (Fig. 3)19. The soils were classified into 18 types according to the USCS and arranged in the vertical direction (Table 1). Next, the geotechnical data of the study area were estimated using geostatistical interpolation by the Empirical Bayesian kriging 3D feature in ArcGIS. The estimated result was imported into a voxel layer. After the study area was divided into 500 cells in 100 \(\times\) 100 m grids, the volume ratio of each soil type was calculated for each cell. The geotechnical data were analyzed down to the bedrock layer. The results showed that the bedrock layer is located at a depth of approximately 20 m. The volume ratio of each soil type was analyzed to depths of 20 m from the surface (Table 2). The geotechnical data were classified into five categories according to the permeability coefficient (Table 1). The results are shown in Fig. 2d.

Drilling data visualized in ArcGIS.
Methods
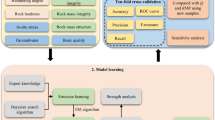
This study conducted analyses in 1 \(\times\) 1 km areas labeled A, B, C, D, and E. The 500 cells obtained by dividing these five areas into 100 \(\times\) 100 m grids were analyzed. The flow chart in Fig. 4 illustrates the process. The underground pipeline and drilling data were used as raw data. From them, the deterioration, pipe diameter, pipe length, and geotechnical data for each type of pipe were extracted and used as input data. The training dataset was generated using the number of ground sinks and four GSCFs.

Flow chart of analysis.
The sliding window method20 was used for correlation analysis and machine learning. Window sizes of 100 \(\times\) 100 m, 200 \(\times\) 200 m, and 300 \(\times\) 300 m were used. The division into susceptibility classes was based on the number of ground sinks. When the window size was 100 \(\times\) 100 m, the susceptibility classes were divided into three levels: 0, 1, and 2–5. For the 200 \(\times\) 200 m window, they were divided into three levels: 0, 1, and 2–8 or four levels: 0, 1, 2–4, and 5–8. When the window was 300 \(\times\) 300 m, they were divided into five levels: 0, 0.5, 1–1.5, 2–2.5, and 3–7.
Correlation analysis was performed after the datasets were divided. The correlation was calculated by standardizing the covariance between the number of ground sinks and GSCFs. Furthermore, the p-value was calculated after correlation analysis to determine the significance of the result.
The GSCFs were selected by correlation analysis and used as inputs to the machine learning model. When the data were input to the model, they were divided into training and test datasets at an 8:2 ratio using the fivefold cross-validation method, StratifiedKFold. After the data were divided, machine learning was performed using the training dataset. Multinomial logistic regression (MLR), decision tree (DT) classifier, random forest (RF) classifier, and gradient boosting (GB) classifier were used.
The susceptibility was evaluated by classifying the number of ground sinks, which is a machine learning prediction, by level. The susceptibility evaluation result was verified using the area under the receiver operating characteristic (AUC-ROC). In addition, GSSMs based on the susceptibility evaluation were generated.
Correlation and significance
Correlations and significance can be identified by calculating the covariance, correlation, and p-value between the factors estimated by the GSCFs and the number of ground sinks.
Covariance is a linear function that indicates the correlation between two variables. Positive and negative covariance indicate positive and negative correlations, respectively. If the covariance is 0, x and y are independent variables with no correlation. The covariance is defined as the expected values of x and y multiplied by the deviation of x and y. It can be expressed as follows21:
The covariance is generally not considered to be useful for correlation analysis because the value varies with the magnitude of the measured values of x and y. Thus, the correlation coefficient \({r}_{xy}\) can be obtained by dividing the covariance by the standard deviations of x and y, \({s}_{x}\) and \({s}_{y}\). The correlation coefficient ranges from − 1 to 1 and is expressed as follows21:
The p-value was used for significance testing. It represents the probability that an extreme sample mean is observed during sampling, assuming that the null hypothesis is true. If the p-value is below the threshold, the null hypothesis is rejected, and the alternative hypothesis is adopted22. The significance threshold was set to P ≤ 0.00523.
Machine learning model
Multinomial logistic regression
Logistic regression is an algorithm that, despite its name, can be used for both regression and classification. When used for binary classification, logistic regression calculates the probability of belonging to each category as a value between 0 and 1 using a sigmoid function and predicts that an item belongs to the category if a specific probability is exceeded. In addition, logistic regression calculates the probability of belonging to each category when there are multiple categories. MLR is an extension of logistic regression in which there are three or more dependent variables24. It is implemented using the soft-max function. The level of ground sink is determined according to the number of ground sinks and used as a dependent variable. GSCFs are also used as independent variables. The probability of belonging to a category y is \({\text{P}}\left({\text{y}}\right){=}{\overrightarrow{\text{w}}}^{\text{T}}\overrightarrow{\text{x}}\). Here \(\overrightarrow{\text{w}}\) is a weight, and \(\overrightarrow{\text{x}}\) is an input feature value. This probability can be expressed using the log probability as \({\text{log}}\left({\text{P}}\left({\text{y}} \, {=} \, {\text{i}}\right)\right) {=} \, {\overrightarrow{\text{w}}}^{\text{T}}\overrightarrow{\text{x}} \, - \, {\text{log}}{\text{Z}}\). Because the sum of the calculated probabilities of belonging to each category must be 1, Z can be calculated as shown in Eqs. (3) and (4). The probability of belonging to each category is then expressed as Eq. (5)25,26.
Decision tree classifier
DT classifier is a multistage decision-making method characterized by the identification of class membership using one or more decision functions continuously. It has a flow-chart-like tree structure that typically consists of a root node, a number of interior nodes, and a number of terminal nodes. The first and last nodes are called the root and nodes, respectively. Nodes that can no longer be divided into smaller groups are called terminal nodes27,28. A parent node generally branches into two child nodes such that the child nodes are purer than the parent node. The Gini index and entropy index are typically used to measure the impurity. Branching is performed by finding a branch condition under which the information gain, which is the difference in impurity between the parent and child nodes, is maximized. It proceeds in this way until the impurity is zero29. This algorithm is the most widely used because it is easier to implement and understand than other classification algorithms.
Random forest classifier
RF classifier is a method that compensates for the disadvantages of the DT classifier. Overfitting occurs when learning is performed until the impurity becomes zero in the DT classifier. To solve this problem, we use the RF classifier, an ensemble technique that combines tree classifiers. Each classifier is generated randomly. When the input data are given, the most frequently selected category is chosen after each classifier is applied30. RF classifier uses the Gini index as a measure of attribute selection. Here, the Gini index is used to measure the impurity of attributes for each category. If a random selection from training set T belongs to the category Ci, the Gini index is expressed as follows31:
Here, \(f({C}_{j}, T)/\left|T\right|\) is the probability that the selected case belongs to category Ci.
Gradient boosting classifier
GB classifier also compensates for the disadvantages of the DT classifier. Like RF classifier, it uses ensemble techniques, but it differs in that classifiers are formed sequentially considering the error of the previous classifier. It uses GB, a process that improves classifiers by weighting them. First, an appropriate loss function is selected, and then DT classifier is used as a weak classifier. Finally, the weak classifiers are added sequentially in the direction of decreasing loss function. A classifier that has combined weak classifiers is called a strong classifier26. The algorithm can be derived as shown in Eqs. (7), (8), (9), (10), and (11) in Algorithm 1 for input training set \({{{(}{\text{y}}_{\text{i}}, {\text{x}}_{\text{i}}{)}}}_{1}^{\text{N}}\) and differentiable loss function \({\text{L}}{(}{\text{y}}, {\text{F}}{(}{\text{x}}{))}\), where the number of repetitions is m = 1, 2,\(\cdots\), M32.
Algorithm 1. Gradient boosting classifier algorithm.
-
1.
Initialize model with a constant value:
$${\text{F}}_{0}\left({\text{x}}\right){=}{{\text{arg}}{\text{min}}}_{\rho}{\sum }_{{\text{i}}= {1} }^{\text{N}}{\text{L}}{(}{\text{y}}_{\text{i}}, \rho {)}$$(7) -
2.
For m = 1 to M:
-
a.
Compute the so-called negative gradient:
$${\widetilde{\text{y}}}_{\text{i}} \, {=}\text{ } - {\left[\frac{{\partial}{\text{L}}\left({\text{y}}_{\text{i}}{, }{\text{F}}\left({\text{x}}_{\text{i}}\right)\right)}{\partial {\text{F}}\left({\text{x}}_{\text{i}}\right)}\right]}_{{\text{F}}\left({\text{x}}\right) {=}{\text{F}}_{{\text{m}}-{1}}\left({\text{x}}\right)}{, } \, \text{for } \,\, {\text{i}} \, {=} \, {1, }{\text{N}}$$(8) -
b.
Fit \(h(x;a)\) to the negative gradient:
$${\text{a}}_{\text{m}} \, {=}{{\text{arg}}{\text{min}}}_{ \alpha {, } \beta }{\sum }_{{\text{i}}= {1} }^{\text{N}}{{[}{\widetilde{\text{y}}}_{\text{i}} {- } \beta \text{h}{(}{\text{x}}_{\text{i}}{; }{\text{a}}{)]}}^{2}$$(9) -
c.
Compute the multiplier \({\rho}_{\text{m}}\) by solving the following single-parameter optimization problem:
$${\rho}_{\text{m}} {=}{{\text{arg}}{\text{min}}}_{\rho}{\sum }_{{\text{i}}= \text{1} }^{\text{N}}{\text{L}}{(}{\text{y}}_{\text{i}}{, }{\text{F}}_{{\text{m}}-{1}}\left({\text{x}}_{\text{i}}\right) \, {+} \, \rho \text{h}{(}{\text{x}}_{\text{i}}{;}{\text{a}}_{\text{m}}{))}$$(10) -
d.
Update the model:
$${\text{F}}_{\text{m}}\left({\text{x}}\right) \, {=} \, {\text{F}}_{{\text{m}}-{1}}\left({\text{x}}\right) \, {+} \, {\rho}_{\text{m}}{{\text{h}}}_{\text{m}}{(}{\text{x}}{)}$$(11) -
3.
Output \({\text{F}}_{\text{M}}\left({\text{x}}\right)\)
Accuracy evaluation and validation: AUC–ROC
The AUC–ROC was used to validate the results of the machine learning model. It is often used in machine learning33 and ground subsidence prediction11,13,34. The ROC curve uses the confusion matrix to check whether classification was performed correctly. Whether the actual classification result agrees with the inferred result is determined as shown in Fig. 533,35.

Confusion matrix.
The accuracy, sensitivity, and specificity can be calculated using Eqs. (12), (13), and (14), respectively, and the confusion matrix33.
The ROC curve refers to the sensitivity graph for 1-specificity, which starts from the origin (0, 0) and ends at (1, 1). For model validation, the AUC of the ROC curve was used. An AUC-ROC value of 1 indicates perfect classification, and a value of 0.5 indicates that classification was not realized35.
Results
Correlation analysis
Correlation analysis was performed by calculating the covariance, correlation, and p-value between the number of ground sinks and GSCFs. It was applied to the deterioration, pipe diameter, pipe length, and geotechnical data using the sliding window method according to the window size and susceptibility classes. The correlation was considered to be distinct if the value was between 0.3 and 0.7, and a strong positive correlation was considered to exist if it was between 0.7 and 1. The result was considered significant for p < 0.005.
The deterioration obtained using 5- and 10-year units was compared. The results are shown in Table 3. The 10-year analysis generally showed a higher positive correlation. In the 5-year analysis, when the deterioration was low, the results tended not to be significant. The 10-year analysis results were all significant. The best result was obtained when the window size was 200 \(\times\) 200 m.
The correlation analysis results for pipe diameter are shown in Table 4. The best results were obtained using the 200 × 200 m window. A positive correlation was observed in the pipe diameter range of 0–1000 mm; by contrast, no correlation appeared at 1000–2400 mm.
The correlation analysis for pipe length was first performed for six types of underground pipelines: water pipes, sewer pipes, underground power pipes, natural gas pipelines, and communication lines. Heat pipes were excluded from further analysis because they were found to have a negative correlation, which was very small. The results for the other five types of underground pipelines of similar materials are summarized in Table 5. The positive correlations for pipes of similar materials was higher than that for different types of underground pipelines. The result for the 200 \(\times\) 200 m windows was the best.
The geotechnical data of soils classified into 18 types according to the USCS were analyzed. The volume ratios were analyzed according to soil type from the surface to depths of 10, 15, and 20 m. The results are summarized in Table 6. There was no correlation whatsoever; the values were between − 0.3 and 0.3 in every category. Therefore, the geotechnical data were not classified as a GSCF.
The correlation analysis indicated that the best results for pipe deterioration, pipe diameter, and pipe length were obtained when the window size was 200 \(\times\) 200 m. A comparison of susceptibility levels of 3 and 4 revealed little effect on correlation. A comparison of the average correlation when the window size was 200 × 200 m showed that pipe length had the highest value of 0.5042, followed by pipe deterioration (0.4419) and pipe diameter (0.3556). In the USCS analysis, no positive correlation was found, with correlation values of − 0.3 to 0.3 in all categories.
Model result
Machine learning was performed using MLR, DT classifier, RF classifier, and GB classifier for 16 cases, as shown in Table 7. Five-fold cross validation was performed using StratifiedKFold. The results are shown in Table 8.
Comparisons of the accuracy of each model showed that DT classifier had the lowest accuracy, whereas RT and GB classifier had the highest accuracy. The accuracy was lowest when the window size was 300 \(\times\) 300 m and highest when it was 100 \(\times\) 100 m. The the highest accuracy was obtained for dataset 11, where the window size was 100 \(\times\) 100 m. However, at this window size, there was no actual classification accuracy because of overfitting to susceptibility classes with 0 accidents. Therefore, the results of datasets 1–8, with a window size of 200 \(\times\) 200 m, were used.
The accuracy of the machine learning models for the training and test datasets was 0.7475 and 0.7333 for MLR, 0.7414 and 0.7037 for DT classifier, 0.7630 and 0.7407 for RF classifier, and 0.7932 and 0.7432 for GB classifier, respectively. The highest accuracy was obtained when GB classifier was used for dataset 6. Table 9 shows the hyperparameters used for training.
Model validation results
The model was validated using AUC-ROC. The validation results for each machine learning model are shown in Fig. 6. After the ground sink susceptibility was identified as low, moderate, or high, the classification performance by category was evaluated. The AUC-ROC results were (0.83, 0.66, 0.87) for MLR, (0.80, 0.65, 0.81) for DT classifier, (0.84, 0.70, 0.87) for RF classifier, and (0.84, 0.67, 0.86) for GB classifier. Among the four models, RF and DT classifier had the highest and lowest AUC-ROC, respectively.

AUC–ROC: (a) MLR, (b) DT classifier, (c) RF classifier, (d) GB classifier.
Ground sink susceptibility maps
GSSMs were created using RF classifier. The machine learning model using GB classifier had a higher accuracy than that using RF classifier; however, the difference in accuracy was very small (0.0025). The GSSMs were created using RF classifier because of its greater reliability according to the AUC-ROC. The GSSMs are shown in Fig. 7. The ground sink susceptibility is expressed as very high, high, moderate, low, and very low. In the GSSMs, very low and very high risks are indicated by white and black, respectively. The most susceptible areas were A, B, and E, whereas C and D were generally safe. For A, B, and E, susceptibilities were predicted as close to very high in the lower right area in A, a diagonal area across B, and the upper center of E, where many ground sinks occurred. However, in areas C and D, where few ground sinks occurred, the susceptibilities were predicted to be very low or incorrectly predicted.

Ground sink susceptibility maps.
The GSSM creation process has several limitations and could be improved in several ways. The GSSMs have a low resolution because areas A, B, C, D, and E were divided into 100 cells each. The resolution could be improved if the areas were divided into a larger number of cells. However, if more cells were used, the cell size would decrease; thus, the number of ground sinks in each cell may be < 1. In this case, only two levels of susceptibility would be evaluated; thus, 100 \(\times\) 100 m cells were used. To improve the resolution, it would be necessary to use data across a larger area or consider pixel-unit analysis by using a deep learning model based on a convolutional neural network (CNN).
Conclusion
Ground sink in urban areas causes considerable environmental, social, and economic damage by destroying infrastructure. This study investigated the effects of the construction and operation of underground pipelines on ground sink in an urban area. For the study, the ground sink susceptibility in 1 \(\times\) 1 km areas in an urban area in South Korea was evaluated using MLR, DT classifier, RF classifier, and GB classifier. The machine learning model was trained with GSCFs using fivefold cross validation by StratifiedKFold. Correlation analysis showed a low correlation between heat pipes and geotechnical data. Therefore, they were not included in the machine learning model because they did not seem to affect ground sink. A comparison of the average correlation values, the pipe length had the highest correlation (0.5042), followed by pipe deterioration (0.4419) and pipe diameter (0.3556). Among the four machine learning models, GB classifier showed the highest accuracy, whereas DT classifier showed the lowest accuracy. The difference in accuracy between GB classifier and RF classifier was not significant. However, when the models were verified using the AUC–ROC, RF classifier had the highest AUC, whereas DT classifier had the lowest AUC. A GSSM was created using RF classifier, which had high accuracy and reliability. Overall, the probability of ground sink was high in areas A, B, and E.
This study has the following limitations. The data used covered five 1 \(\times\) 1 km areas; therefore, the data were often biased because of the small study area. Data changes during preprocessing are another limitation as it was found that the original data were not accurately represented as a result of data discretization and integer encoding. Because the study area was divided into 100 \(\times\) 100 m grid units during machine learning, the locations of points at which ground sink occurred were not accurately reflected.
As demonstrated by Ministry of Environment data8 and previous studies8,16, ground sinks were generated mainly by underground pipelines. It has been found experimentally that in urban areas, the pipe type, pipe deterioration, and pipe length were significantly correlated with the frequency of ground sink. However, to improve the prediction accuracy of the model that determines the susceptibility to ground sink, it is necessary to consider not only human artifacts but also natural factors. Therefore, we plan to study an evaluation model that considers the effects of natural factors as well as underground pipes on ground sink. Furthermore, when evaluating the ground sink susceptibility, we will reduce the impact of preprocessing by applying a deep learning model based on a CNN, and thus use raw data without preprocessing.
Data availability
The data that support the findings of this study are available from the Korea Institute of Civil Engineering and Building Technology, but the availability of these data, which were used under license for the current study, is limited, and thus they are not publicly available. Data are, however, available from the corresponding author upon reasonable request and with permission from the Korea Institute of Civil Engineering and Building Technology.
References
Fadhillah, M. F., Achmad, A. R. & Lee, C. W. Integration of InSAR time-series data and GIS to assess land subsidence along subway lines in the Seoul metropolitan area, South Korea. Remote Sens. 12, 3505 (2020).
Tien Bui, D. et al. Land subsidence susceptibility mapping in South Korea using machine learning algorithms. Sensors (Basel) 18, 2464 (2018).
Zhou, C. et al. Quantifying the contribution of multiple factors to land subsidence in the Beijing Plain, China with machine learning technology. Geomorphology 335, 48–61 (2019).
Ciotoli, G. et al. Sinkhole susceptibility, Lazio region, central Italy. J. Maps 12, 287–294 (2016).
Elmahdy, S. I., Mohamed, M. M., Ali, T. A., Abdalla, J. E. & Abouleish, M. Land subsidence and sinkholes susceptibility mapping and analysis using random forest and frequency ratio models in Al Ain, UAE. Geocarto Int. 37, 315–331 (2022).
Pradhan, B., Abokharima, M. H., Jebur, M. N. & Tehrany, M. S. Land subsidence susceptibility mapping at Kinta Valley (Malaysia) using the evidential belief function model in GIS. Nat. Hazards 73, 1019–1042 (2014).
Hwang, Y. 169 sinkholes formed in Seoul over past 7 years. in Yonhap News Agency. https://en.yna.co.kr/view/AEN20220124007700315 (2022).
Bae, Y. S., Kim, K. T. & Lee, S. Y. The road subsidence status and safety improvement plans. J. Korea Acad. Ind. Coop. Soc. 18, 545–552 (2017).
Ministry of Land, Infrastructure and Transport. Ground Settlement (Sink) Safety Management Manual. (2015).
Edmonds, C. N., Green, C. P. & Higginbottom, I. E. Subsidence hazard prediction for limestone terrains, as applied to the English Cretaceous Chalk. in EGSP (Engineering Geology Special Publications, 1987). Vol. 4. 283–293 (Geological Society, 1987).
Taheri, K. et al. Sinkhole susceptibility mapping: A comparison between Bayes-based machine learning algorithms. Land Degrad. Dev. 30, 730–745 (2019).
Machowski, R., Rzetala, M. A., Rzetala, M. & Solarski, M. Geomorphological and hydrological effects of subsidence and land use change in industrial and urban areas. Land Degrad. Dev. 27, 1740–1752 (2016).
Arabameri, A. et al. A novel ensemble computational intelligence approach for the spatial prediction of land subsidence susceptibility. Sci. Total Environ. 726, 138595 (2020).
Xu, Y. S., Ma, L., Du, Y. J. & Shen, S. L. Analysis of urbanisation-induced land subsidence in Shanghai. Nat. Hazards 63, 1255–1267 (2012).
Kim, H., Lee, J. Y., Jeon, W. H. & Lee, K. K. Groundwater environment in Seoul, Republic of Korea. in Ground Environment in Asian Cities. 413–449 (Butterworth-Heinemann, 2016).
Kang, I. S. Sinkholes are here to stay. in Korea JoongAng Daily. https://koreajoongangdaily.joins.com/2014/08/27/socialAffairs/Sinkholes-are-here-to-stay/2994167.html (2014).
Lee, H. & Oh, J. Establishing an ANN-based risk model for ground subsidence along railways. Appl. Sci. 8, 1936 (2018).
Liu, H., Hussain, F., Tan, C. L. & Dash, M. Discretization: An enabling technique. Data Min. Knowl. Discov. 6, 393–423 (2002).
ESRI Inc & Pro, A.G. ESRI Inc. (Version 2.8.0). https://www.esri.com/en-us/arcgis/products/arcgis-pro/overview (2021).
Kaneda, Y. & Mineno, H. Sliding window-based support vector regression for predicting micrometeorological data. Exp. Syst. Appl. 59, 217–225 (2016).
Asuero, A. G., Sayago, A. & González, A. G. The correlation coefficient: An overview. Crit. Rev. Anal. Chem. 36, 41–59 (2006).
Hung, H. M., O’Neill, R. T., Bauer, P. & Köhne, K. The behavior of the p-value when the alternative hypothesis is true. Biometrics 53, 11–22 (1997).
Ioannidis, J. P. A. The proposal to lower P value thresholds to .005. JAMA 319, 1429–1430 (2018).
Chan, Y. H. Biostatistics 305. Multinomial logistic regression. Singap. Med. J. 46, 259–268 (2005).
Wang, Y. A multinomial logistic regression modeling approach for anomaly intrusion detection. Comput. Sec. 24, 662–674 (2005).
Weldegebriel, H. T., Liu, H., Haq, A. U., Bugingo, E. & Zhang, D. A new hybrid convolutional neural network and eXtreme gradient boosting classifier for recognizing handwritten Ethiopian characters. IEEE Access 8, 17804–17818 (2019).
Swain, P. H. & Hauska, H. The decision tree classifier: Design and potential. IEEE Trans. Geosci. Electron. 15, 142–147 (1977).
Yadav, S. K. & Pal, S. Data mining: A prediction for performance improvement of engineering students using classification. World Comput. Sci. Inf. Tech. J. 2, 51–56 (2012).
Safavian, S. R. & Landgrebe, D. A survey of decision tree classifier methodology. IEEE Trans. Syst. Man Cybern. 21, 660–674 (1991).
Breiman, L. Random Forests; UC Berkeley TR567 (University of California Berkeley, 1999).
Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 26, 217–222 (2005).
Friedman, J. H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 27, 861–874 (2006).
Oh, H. J. & Lee, S. Assessment of ground subsidence using GIS and the weights-of-evidence model. Eng. Geol. 115, 36–48 (2010).
Bewick, V., Cheek, L. & Ball, J. Statistics review 13: Receiver operating characteristic curves. Crit. Care 8, 508–512 (2004).
Funding
This research was supported by a grant from the project “Underground Utilities Diagnosis and Assessment Technology,” which was funded by the Korea Institute of Civil Engineering and Building Technology (KICT).
Author information
Authors and Affiliations
Contributions
J.H.P.: Methodology, Software, Data preparation, Writing-Original draft preparation. J.K.: Methodology, Data preparation. J.K.: Methodology, Data preparation. D.M.: Conceptualization, Methodology, Supervision, Writing-Reviewing and Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Park, J.H., Kang, J., Kang, J. et al. Machine-learning-based ground sink susceptibility evaluation using underground pipeline data in Korean urban area. Sci Rep 12, 20911 (2022). https://doi.org/10.1038/s41598-022-25237-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-25237-8
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
