
Abstract
X-ray absorption spectroscopy (XAS) is a well-established method for in-depth characterization of electronic structure. In practice hundreds of energy-points should be sampled during the measurements, and most of them are redundant. Additionally, it is also tedious to estimate reasonable parameters in the atomic Hamiltonians for mechanistic understanding. We implement an Adversarial Bayesian optimization (ABO) algorithm comprising two coupled BOs to automatically fit the many-body model Hamiltonians and to sample effectively based on active learning (AL). Taking NiO as an example, we find that less than 30 sampling points are sufficient to recover the complete XAS with the corresponding crystal field and charge transfer models, which can be selected based on intuitive hypothesis learning. Further applications on the experimental XAS spectra reveal that less than 80 sampling points give reasonable XAS and reliable atomic model parameters. Our ABO algorithm has a great potential for future applications on automated physics-driven XAS analysis and AL sampling.
Similar content being viewed by others

Introduction
X-ray absorption spectroscopy (XAS) is an important experimental technique used in the investigation of material properties, where a large number of sampling points are required to capture the fine details and the experimental data needs to be analyzed based on atomic Hamiltonians with undetermined parameters1,2. Various methods have been used to interpret XAS, including density functional theory (DFT)3,4, semi-empirical multiplet models5,6, and DFT combined with dynamical mean-field theory (DFT + DMFT)7. The DFT-based methods are capable of capturing the crystalline environment of the active ions but limited to tackle the complications arising from the correlation effects. The DFT + DMFT calculations simultaneously account for the chemical realism and correlation effects, where the XAS spectra are evaluated by solving the corresponding Anderson impurity models (AIMs)8. Unfortunately, the DFT + DMFT calculations require a large amount of computational time and resources, thus are usually performed off-site by experts.
In contrast, the semi-empirical methods based on atomic Hamiltonians consider the essential parameterized interactions such as the Coulomb interaction, spin-orbit coupling, crystal fields, charge transfer and broadening parameters, resulting in transparent mechanistic understandings of XAS9,10,11. For instance, the crystal field multiplet (CFM) theory and charge transfer multiplet (CTM) theory constitute two popular models in understanding and simulating experimental XAS of transition metal (TM) oxides. CFM describes the atomic interaction with the surrounding ligands as a perturbation using the effective electric fields12, however, the neglection of covalency makes it challenging to describe the crystal field splitting. In contrast, the CTM model takes metal-ligand charge transfer into consideration. Sugano and Shulman devised molecular orbital (MO) model to calculate the ligan-field parameters and got good consistency with experimental results13. Moreover, Fujimori and Minami used the cluster model considering strong 3d correlations and 3d-ligand orbital hybridization to improve the interpretability of multiplet ligand-field theory (MLFT) for the valence-band photoemission14,15. In order to extrapolate MLFT further to understand band gaps and broad satellite peaks in XAS of transition metals, Gunnarsson, van der Laan and Zaanen took the large ligand hole bandwidth into the account by employing the Anderson impurity Hamiltonian16,17,18,19.
Another practical challenge is how to perform efficient sampling during the experimental measurements. A homogeneous energy grid with several hundreds of measurements within a specific energy range is often needed, which is inefficient and resource-costly. The quality of the spectrum varies depending on the choice of sampling points. One way out is the so-called design of experiments (DoE)20, which focuses on selecting the input variables of experiments which have significant effects on experiments’ target value, and examining how to choose the best combination of independent variables. However, a good number of sampling points are still needed in order to obtain a spectrum with a sufficient signal-to-noise ratio. With the help of machine learning (ML), DoE has undergone a transformation. Several ML-based methods have been applied to the prediction and design of spectroscopy experiments21,22,23. Nevertheless, collecting the needed data for ML still requires a lot of effort. The active-learning (AL) method based on Bayesian analysis can be applied to reduce the required sampling data, where the posterior mean and variance of the parameter space can be calculated using the Gaussian process (GP) based on the prior distribution function24. Mostly, AL stops once the desired level of performance is achieved25, which can be applied to spectroscopic experiments to design appropriate stopping criteria. For instance, the decision to stop the measurements can be made by estimating the physical parameters to determine the validity of the current experimental results26,27. However, such parameter assessments often require comparisons between the experimental and theoretical spectra, which are usually not available during the experiments. Furthermore, automatic stopping criteria based on the generalization error analysis have now been applied to spectral AL to circumvent this complex parametric analysis process23. While such a combination of active learning and stopping criterion can effectively reduce the number of sampling points, the absence of supports based on theoretical models reduces the reliability of AL to extract points of importance. Hence, there is a strong impetus to develop a physics-driven stopping criterion for efficient experimental samplings in XAS.
In this work, we propose an ABO algorithm, comprising automated parameter fitting to obtain the atomic Hamiltonians and efficient AL-based sampling. Taking NiO as an example with theoretical XAS obtained using Quanty9, we demonstrate that both CFM and CTM models with up to 15 parameters can be constructed, while keeping the number of sampling points at the order of 30. To identify the dominant physical processes, hypothesis learning can be done, which can distinguish the CFM and CTM models depending on the standard real spectrum (the ground truth in ML). It is further revealed that our ABO algorithm can be applied on the real experimental data, providing a valuable solution to the currently time-consuming XAS measurements and analysis.
Results
Fitting CFM with active-learning sampling
Keeping in mind that the goal of the ABO algorithm is to reach the standard real spectrum with as few sampling points as possible. Starting with the CFM model, there are 9 independent parameters, including the Coulomb interaction \(F_{dd}^2\), \(F_{dd}^4\), \(F_{pd}^2\), \(G_{pd}^1\), \(G_{pd}^3\), the crystal splitting \(10D_q\), the spin–orbital coupling strength of the Ni 2p and 3d orbitals \(\xi _{2p}\), \(\xi _{3d}\), and the exchange magnetic field \(B_{ex}\). The Slater integral \(F_{dd}^0\) is related to U by
and \(F_{pd}^0\) is related to \(U_{pd}\) by
Note that as the total number of electrons is conserved in CFM, U and \(U_{pd}\) can be dropped out, i.e., \(U = U_{pd} = 0\).
To demonstrate the efficacy and robustness of the ABO algorithm, it is first applied to the Ni2+ L2,3 edge of the XAS curve produced by the 9-parameter CFM. We note that the L2,3 XAS spectra have been already well reproduced using crystal field-based models for NiO28. In order to reduce the dimension of the problem, \(F_{dd}^4\) is fixed based on the feature importance (FI) analyze for all 9 parameters (cf. Supplementary Fig. 1). Figure 1 shows the snapshots obtained based on the ABO algorithm with 3, 19, and 27 sampling points (Fig. 1a to c). For an initial dataset consisting of three random points (Fig. 1a), it is observed that the resulting XAS (red curve) obtained using the Hamiltonian from fBO has a big difference compared to the theoretical standard real XAS curve (black curve). This suggests that due to insufficient sampling points, the Hamiltonian fitting suffers from an extremely non-convex problem, and the resulting CFM model is trapped in one of many possible local minima. However, such an inaccurate Hamiltonian can still be applied to predict the next sampling point in sBO by evaluating the deviation from the theoretical standard real XAS curve. In follow-up iterations, CFM gets substantially improved and the non-convexity is tremendously reduced, reaching the theoretical standard real XAS curve expeditiously (Fig. 1d). With 19 sampling points as shown in Fig. 1b, the algorithm is able to recover the shape of the XAS curve and reproduce the fine structures besides peaks and valleys. Further sampling up to 27 points allows the ABO algorithm to well reproduce the theoretical standard real XAS curve, with the corresponding parameters in CFM converged nicely (cf. Supplementary Table 3).

The fitting results of the CFM model for differnet sampling points: a three sampling points (Step 1); b 19 sampling points (Step 17); c 27 sampling points (Step 25); d CFM XAS curve convergence, with the colored dots denote in order the results of Fig. 1a to c. The upper panels in (a)-(c) show the fitted results of fBO, where the black curve denotes the standard real values of the unknown XAS curves, the black dots are the already measured points, the red curve is the fitted result based on current sampled points using the fBO fitting, and the magenta cross is the point to be measured in the next round, which is determined by sBO. In the lower panels are the standardized prediction of sBO, where the black dots denote the GP predicted loss with the blue-shaded regions denoting the uncertainties. The parameter comparison for the listed steps is shown in Supplementary Table 4.
Figure 1d shows the convergence indicated by the loss function plotted with respect to the number of sampling points, where the loss function is defined as the average deviation between all points on the prediction and the theoretical standard real XAS curve. Correspondingly, the convergence of model parameters is shown in Supplementary Fig. 3, with the intermediate parameters and the real parameters for the theoretical standard real XAS listed in Supplementary Table 3. It is observed that \(G_{pd}^3\) and \(F_{pd}^2\) have relative larger deviation of, respectively, 2.07% and 1.15% compared to the other parameters, which can be attributed to the less FI for such parameters (see Supplementary Discussion).
Fitting CTM model with active-learning sampling
To further explore the capability of the ABO algorithm, it is applied to the more sophisticated CTM model, which considers the charge transfer effects. CTM for NiO has in total 15 input parameters, including the Coulomb interaction parameters \(U_{dd}\), \(U_{pd}\), \(F_{dd}^2\), \(F_{dd}^4\), \(F_{pd}^2\), \(G_{pd}^1\), \(G_{pd}^3\), the charge transfer energy ∆, the crystal field splittings corresponding to Ni 3d and ligand orbitals \(10D_q\), \(10D_{qL}\), the hopping integral between O-2p and Ni-3d orbitals of \(t_{2g}\) and \(e_g\) symmetry \(V_{t_{2g}}\), \(V_{e_g}\), the spin–orbital coupling strength of Ni-2p and 3d orbitals \(\xi _{2p}\), \(\xi _{3d}\), and the exchange magnetic field \(B_{ex}\). We adapt the algorithm by giving the physical preconditions to reduce the difficulty of high-dimensional fitting. The adapted ABO algorithm was then straightforwardly applied to fit the XAS curves simulated using the CTM model.
The results are shown in Fig. 2. Initial random sampling points are helpful to get a reasonable starting model as we observed for CFM, thus for CTM 10 initial points (Fig. 2a) are used in order to get a rough estimation of the overall data distribution. This helps significantly with the convergence, in comparison with only one initial point as shown in Supplementary Fig. 4. And as illustrated in Fig. 2b, 23 sampling points are already enough for the ABO algorithm to capture the essential features such as peaks and satellites. Interestingly, as shown in Fig. 2c, we find that the ABO algorithm can identify the critical regions and keep on improving its accuracy therein, though the fitted curves and used parameter values are already very close to the theoretical standard real spectrum. The convergence of the model parameters is depicted in Supplementary Fig. 4d, and the final fitted parameters are summarized in Supplementary Table 5. There are four parameters with larger deviations, i.e., \(V_{t2g}\), \(10D_q\), \(10D_{qL}\) and \(B_{ex}\) (with 3.01%, 2.83%, 2.24% and 2.11% deviations, respectively). According to the FI analysis (see Supplementary Discussion), such parameters have relatively less significant FI, thus the sensitivity of the final results with respect to such parameters is marginal. Moreover, the distribution of the selected sampling points covers mostly the regions containing important information on the theoretical standard real spectrum, e.g., the peaks, satellites, and the splitting. This confirms the robustness of our ABO algorithm, i.e., the adversarial algorithm can dynamically allocate the sampling region to improve the XAS while continuously improving the parameter fitting for the atomic Hamiltonian.

The fitting results of the CTM model for differnet sampling points: a 10 sampling points (Step 1); b 23 sampling points (Step 14); c Final fitting results using 44 sampling points (Step 35); d CTM XAS curve convergence, with the colored dots denote in order the results of Fig. 2a to c. The parameter comparison for listed steps is shown in Supplementary Table 6.
Automatic model selection
An interesting question is whether an appropriate atomic model can be automatically identified, as recently demonstrated on model selection and information fusion29 and hypothesis learning30. To verify this, we integrate both CFM and CTM models starting with a theoretical standard real spectrum obtained based on either CFM or CTM, and let the ABO algorithm to automatically determine which model should be used. Since the CTM model includes all parameters of CFM model, which means it in principle can fully recover the theoretical standard real spectrum of the CFM model by setting the common parameters the same and keeping the rest parameters of ligand field to be 0. So, in our test, in order to allow the two models to be distinguished from each other, we applied different peak broadening methods on different models to ensure that the final generated XAS spectrum have different shapes. To avoid the initial arbitrariness, five random points are used to train preliminary models. The follow-up convergence behaviors are shown in Fig. 3a, b, for CFM and CTM theoretical standard real spectrum, respectively. Obviously, there is already a clear distinguishment for the CFM and CTM models within 22 iterations, i.e., 22 more sampling points, as measured by the deviations between Loss_CFM and Loss_CTM. That is, the ABO algorithm can easily distinguish the model Hamiltonians and select the correct one based on the experimental data. For instance, in Fig. 3a with a CFM theoretical standard real spectrum, the ABO algorithm using a CTM Hamiltonian can have comparable performance as CFM for less than 7 sampling points (i.e., up to two steps plus the initial five random points). As the number of iterations keeps increasing, the results obtained using the CTM Hamiltonian deviate more from the theoretical standard real spectrum in the beginning and then decrease to a constant level. Therefore, we suspect that by training several models in parallel, the important physics for a material system can be automatically identified, e.g., whether the charge transfer processes play an important role. It is noted that the model selection can be performed in a more reliable way by evaluating the Bayes factors31, which will be saved for future study.

The loss comparation of the CFM and CTM model fBO fitting using different theoretical standard real spectrum: a CFM theoretical standard real spectrum; b CTM theoretical standard real spectrum.
Experimental curve fitting based on the CTM model
After demonstrating that the ABO algorithm works on the theoretically generated standard real XAS, we turn now to find out its performance on the experimental data. According to ref. 9, the charge transfer processes are critical for NiO, thus CTM is more appropriate to describe the underlying physics in NiO and we consider only CTM here. Starting from the experimental XAS results28, we firstly fit the CTM model parameters with 12 random sampling points in order to avoid local minima and possible sampling bias. The results of ABO fitting are shown in Fig. 4. The comparison between all the parameters is shown in Supplementary Discussion, Supplementary Fig. 5, and the convergence plots of the case starting with only one initial points is shown in Supplementary Fig. 6.

The fitting results of the experimental XAS spectrum for different sampling points: a 13 sampling points (Step 1); b 21 sampling points (Step 9); c 36 sampling points (Step 24); d 64 sampling points (Step 52); e 79 sampling points (Step 67); f the convergence of the fitted XAS curve in comparison with the experimental curve, with the colored dots denote in order the results of Fig. 4a to e; g the comparison of the ABO fitted XAS curve, the experimental curve, and the reference curve.
As shown in Fig. 4a, because of the relatively large initial sample set, the shape of fitted curve is already closer to the experimental XAS, in particular for the L2 edge but not the L3 and satellite peaks. Figure 4b to e depict the follow-up optimization snapshots. Between Fig. 4b, c, it is observed that the sampling points are clustered between 872 and 876 eV, trying to improve the fitting for the L2 edge. This suggests our ABO algorithm can focus on the most problematic points where the physical model can get most potentially improved. In particular, after a few attempts without improvements, the region between 872 and 876 eV is abandoned and the ABO algorithm begins to explore the L3 peak regions centered at 853.3 eV, as clearly marked by the suggested sampling points in Fig. 4c–e. This can be attributed to the fact that the covariance for sampling points between 872 and 876 eV becomes smaller due to the accumulation of points in the region. Although the loss in this region is still large, the ABO algorithm prefers to explore other regions that can help improve the results, e.g., the peak regions where the deviations are still large. Therefore, the ABO algorithm can progressively optimize the results on its own if a sufficient number of iterations is allowed, as evidenced by the step descending convergence behavior around the 40-th step (Fig. 4f).
Although a perfect agreement between the model-derived XAS and experimental standard real spectrum cannot be achieved, detailed analysis reveals that the ABO algorithm can be applied to construct a reasonable Hamiltonian by active-learning sampling the experimental XAS. Unlike the previous convergence plots using the curves generated by CFM and CTM as the standard real spectrum where the loss drops rapidly, for the experimental standard real spectrum, the loss function converges slowly and eventually shows an oscillating behavior after 40 iterations (Fig. 4f and Supplementary Fig. 5, indicating there are more than one solution which cannot be distinguished by varying the current set of parameters. We identify three models with distinct parameters characterizing the oscillating region, with the resulting parameters summarized in Supplementary Table 7. Correspondingly, it is observed that there are four most diverged parameters (i.e., \(U_{dd}\), \(U_{pd}\), and \(F_{dd}^2\), \(F_{dd}^4\)) among such models (the detailed convergence behaviors of these parameters are shown in Supplementary Fig. 5). The Slater integrals \(F_{dd}^2\) and \(F_{dd}^4\) are the integrals over the radial wave functions in the electron-electron interaction (the details can be found in the Supplementary Methods and can be calculated in the Hartree-Fock approximation on a free ion using Cowan’s code32. Physically, \(F_{dd}^2\, >\, F_{dd}^4\) and a good approximation gives a constant ratio \(F_{dd}^4 = 0.62F_{dd}^2\) for 3d8 shells33. For the spherical part of the Coulomb repulsion parameters \(U_{dd}\) and \(U_{pd}\), their values were obtained via fitting the multiplet ligand field model to the experimental XAS spectra directly in ref. 9, which suggest that the parameters obtained by fitting the experimental results using ABO should be comparable with the reference values. However, this is not the case for some fitted parameters in the oscillation zone regarding not only \(U_{dd}\) and \(U_{pd}\), but also \(F_{dd}^2\) and \(F_{dd}^4\), thus these possibilities in the oscillation zone are ruled out. Here, we would also like to mention that due to the limitation of the adopted CTM model, it is not surprising that the parameter sets obtained by fitting the spectral shape using ABO do not always demonstrate proper physical meaning.
Based on the loss and physical reasonableness of the fitting parameters, the final result is shown in Fig. 4g. Obviously, XAS obtained from the CTM Hamiltonian fitted using our ABO algorithm exhibits good agreement with the experimental data, in good comparison with XAS obtained using the model parameters obtained by experts9. Table 1 summarizes the resulting parameters from ref. 9 and the final parameters using our ABO algorithm. For the Coulomb interaction parameters \(G_{pd}^3\), crystal field splitting \(10D_q\), hopping integral of \(e_g\) symmetry \(V_{e_g}\), and exchange magnetic field \(B_{ex}\), ABO results show relative strong deviations from the results in the literature. The reason for such deviations can be attributed to the FI of such parameters as shown in Supplementary Fig. 2. This suggests that there is a big degree of freedom in developing physical understanding of XAS, as the same experimental data can be fitted by several groups of atomic Hamiltonian parameters, entailing more detailed theoretical calculations.
Experimental curve fitting based on the CTM model with background subtraction and model constrains
Although our ABO fitted spectra are in good agreement with the experimental curve, the fitted parameter sets still shows some non-physical relations compared with the theoretical value, e.g., Veg < Vt2g. This can be attributed to the following three possible reasons: 1. The calculated spectrum using the CTM model does not include the continuum absorption background, as the background information in the experimental spectrum is not completely removed; 2. The algorithm sees only the local information, i.e., only the selected-out measurement points rather than the entire curve. The aggregation of samples caused by the non-negligible background can lead to the overweight of regions with concentrated sampling points and cause bias during the parameter fitting; 3. Greedy algorithms without physical constraints only focus on reducing the curve differences, which may give rise to overfitting and thus wrong physical relations.
Correspondingly, we update our model by restricting \(V_{eg} > V_{t2g}\), and eliminate the step edge background by fitting a two-step arctangent weighted function34,35,36 after each fBO process, and use the background-eliminated data for the sampling during the sBO process. The two-step arctangent weighted function we use is:
where A is the step height, x is the X-ray energy, u is the center of the function at the desired X-ray energy and c is the constant controlling the slope of the step. All such six parameters \({{{\mathrm{A}}}}_1,{{{\mathrm{A}}}}_2,{{{\mathrm{u}}}}_1,{{{\mathrm{u}}}}_2,{{{\mathrm{c}}}}_1,{{{\mathrm{c}}}}_2\) are fitted automatically in our Bayesian optimization loop. The updated workflow of ABO with background fitting can be found in Supplementary Fig. 7.
As shown in Fig. 5, compared to the previous results without removing the background, the loss (cf. Fig. 5d) in this fitted curve drops rapidly to below 12 within four iterations (i.e., with 16 sampling points) and stabilizes at around 10 in subsequent fits with no significant fluctuations. We find that the sampling points are more distributed throughput the whole energy range (Fig. 5a–c), with a tendency to accumulate in regions with fine features in the XAS spectra such as satellite peaks. This demonstrates that our ABO algorithm can explore a wide region while maintaining a high exploitation rate. And for the parameter comparison as shown Table 2, the model can get more physically reasonable parameters in fewer cycles and effectively identified stable and robust backgrounds during the experiment. The parameters with relative larger deviations are \(10D_q\) and \(10D_{qL}\). The reason of such deviations can be attributed again to the relative lower FI of such parameters as shown in Supplementary Fig. 2 for \(10D_q\) and \(10D_{qL}\). From the physical point of view, for the deviation of \(10D_q\), when measuring the L-edges in XAS, the 2p electrons are mainly excited to the eg orbitals because the t2g orbitals are fully occupied by 8 valence electrons for the Ni2+ ions. Therefore, the magnitude of \(10D_q\) is not expected to significantly affect the spectral shape, but rather that the global shift of the energy positions corresponding to the absorption peaks and the relative heights between the different peaks. As the calculated XAS spectra are shifted during the ABO process in order to fit the experiment data, only the relative heights remain as a relatively weak condition to obtain 10Dq, which can be also influenced by the values of other parameters. Last but not least, the constraints can be easily derived from DFT calculations, which will be addressed systematically in the future study. We also applied the ABO algorithm to the other material systems such as MnO and SrTiO3 (not shown), and observed that accurate curve fitting can be achieved, in particular with the physical constraints derived from DFT calculations.

The fitting results of the experimental XAS spectrum with background fitting for different sampling points: a 17 sampling points (Step 5); b 24 sampling points (Step 12); c 32 sampling points (Step 20); d the convergence of the fitted XAS curve in comparison to the experimental curve, with the colored dots denoting in order the results of Fig. 5a–c.
Discussion
Although the prediction of XAS appears to be a simple one-dimensional regression as a function of energy, it is actually a sophisticated problem, which entails physics-driven modeling. As it is demonstrated, by incorporating the physical Hamiltonian model into the fitting process, our ABO algorithm can not only predict the peak/satellite positions and fine structures of XAS, but also can automatically select and inversely construct the physical model simultaneously in an adversarial manner. Importantly, we find that the sampling efficiency using our ABO algorithm can be significantly enhanced in comparison to a stopping criterion algorithm based on Bayesian optimization as done in ref. 23. For instance, for the CFM model-derived theoretical standard real spectrum, the number of sampling points based on our ABO algorithm is 24.3% of that using a single BO with the stopping criterion being 0.025, and the corresponding ratio for the CTM model theoretical standard real spectrum is 18.8% (cf. Supplementary Table 8). That is, the physics-driven Hamiltonian obtained via fBO is essential for more effective sampling of XAS. Furthermore, the high accuracy and efficiency of our ABO algorithm can be attributed to two reasons. The first reason is that when fBO and sBO compete against each other on reducing the loss, the algorithm is actually trying to drive the sample distribution closer to the true data distribution. Such a distribution not only effectively represents the important information of the data, but also allows for a more efficient and faster fitting of the model. The second reason is that the introduction of physical models within fBO changes the prior of sBO in each iteration, this makes it possible to explore extensively while maintaining a high exploitation ratio, i.e., the high exploration rate of the fBO provides us with a wide range of possible model spectra, which leads to variations in losses between measurements and physical models. While sBO with high exploitation ratio can precisely pinpoint the maximum losses during the sampling, and thus it is able to capture the peak/satellite positions of the XAS spectra efficiently and accurately. However, it should not be overlooked that such efficient sampling is based on regression analysis of the current data using a physical model, a process that prolongs the decision-making time in the experimental process. The current version of ABO takes about 15 min per round of computation on a single-core NVIDIA Tesla T4 GPU and intel core AVX512. Depending on the complexity of the model, it usually takes between one to five rounds of calculations to find the minimum that satisfies the threshold. This shortcoming on the one hand can be partially overcome by performing batch sampling in sBO or by multi-threaded parallel fitting in fBO; on the other hand, by combining with DFT calculation, automatically pre-determining some of the parameters, the fitting process can be even faster, so that our ABO algorithm can get integrated with experimental measurements in the future. It is worth mentioning that, besides the application of the ABO approach on XAS spectrum, this approach can be easily transferred to other problems with physical properties derived based on parameterized Hamiltonians, which can be correlated with experimental measurements. For example, by employing advanced Fourier basis in ref. 37 as the physical model, our ABO can be applied to facilitate the fitting and sampling of EXAFS, which will be saved for future investigation.
To summarize, we implement an ABO algorithm for physics-informed active-learning sampling of XAS. Applying the algorithm on the simulation of two different theoretical standard real spectra, it is demonstrated that our algorithm not only succeeds in predicting the true curve, but also accurately predicts the parameters in the atomic Hamiltonians. Intuitive application of the ABO algorithm shows that hypothesis learning can be accomplished, so that the physically meaningful models can be automatically selected. For simulations using real experimental data, our ABO algorithm can quickly find the optimal solution of the model for the current data and select the sampling points most likely to further enhance the model accordingly, and it is able to automatically adjust the XAS spectra background and the model used to better predict the experimental data as it evolves. We believe that the ABO algorithm has a great potential for real-time applications in XAS experiments with the on-the-fly construction of physical models.
Methods
Multiplet Models
For NiO, the L2,3 edge XAS of Ni2+ can be evaluated using Quanty with model Hamiltonians based on either CFM or CTM defined as follows,
with \(H_U^{dd}\) being the on-site Coulomb repulsion between the 3d electrons of Ni, \(H_U^{pd}\) being the on-site Coulomb interaction between the Ni 2p and 3d electrons, \(H_{{{{\boldsymbol{l}}}} \cdot {{{\boldsymbol{s}}}}}^d\) and \(H_{{{{\boldsymbol{l}}}} \cdot {{{\boldsymbol{s}}}}}^p\) being the spin–orbital coupling corresponding to Ni 3d and 2p orbitals, respectively, \(H_{ex}\) being the Weiss magnetic field acting on Ni. To understand the underlying physics, such empirical parameters should be tailored so that the experimental XAS can be well reproduced, which is challenging as it is a multi-dimensional fitting problem (cf. Supplementary Methods for the complete lists of all relevant atomic parameters). For instance, CFM and CTM distinguish from each other by the excited charge dynamics, where CFM allows only excitations based on the local crystal fields (denoted by \(H_{CF}\) in Eq. (4)), whereas virtual charge transfer processes are considered between Ni-3d and ligand 2p orbitals in the CTM model (represented by \(H_{hyb}^{dL}\) in Eq. (5)). In the calculations of XAS using Quanty, the two Hamiltonians defined in Eqs. (4) and (5) were applied for both the ground states and excited states. After calculating the ground state wave function, XAS was evaluated using a Lanczos-based Green’s function method11,38:
where \(\left| {\Psi} \right\rangle\) denotes the ground state, T is the transition operator (here it represents a 2p3d dipole excitation), \(H_{CFM/CTM}^{fs}\) is the final state Hamiltonian, \(\omega\) is the energy relative to the energy of state \(\left| {\Psi} \right\rangle\), and \({{{\mathrm{{\Gamma}}}}}\) denotes the core-hole lifetime. For the specific forms of each term in Eqs. (4), (5) and (6), please refer to the Supplementary Methods. In order to acquire better fitting of the experimental data, the Gaussian broadening is usually added uniformly to mimic the broadening caused by experimental instruments while the energy-dependent Lorentzian broadening is applied to simulate the core-hole lifetime broadening.
Adversarial Bayeian Optimization algorithm
Following the idea of generative adversarial network (GAN)39 where both the generators and discriminators are trained simultaneously, we combined the multiplet Hamiltonian construction and active-learning sampling together, leading to an ABO algorithm. Similar to GAN, where a trained generator minimizes the difference between the existing and generated data and the discriminator aims to maximize it, the multiplet model fitting acts like the generator to minimize the difference between the model predicted XAS and the real XAS, whereas the active-learning sampling behaves like the discriminator to identify the next sampling points with large uncertainties measured by the loss function. Correspondingly, in our ABO algorithm, there are two coupled BO algorithms. The first one, called fitting BO (fBO), is a trust region Bayesian optimization (TuRBO) applied on our multiplet Hamiltonian to search for better parameters minimizing the difference between the theoretically predicted XAS and the real XAS values. The second one, called sampling BO (sBO), is a simple BO, which functions to select the sampling points that maximize the differences between the predicted and real XAS values. The mathematical form of ABO is expressed as:
where \(Y_{i,{{{\mathrm{Quanty}}}}}\) denotes the theoretically predicted XAS of the ith measurement obtained using the Quanty code starting from the multiplet Hamiltonian, and \(Y_{i,{{{\mathrm{experiment}}}}}\) indicates the real XAS of the ith measurement obtained either from Quanty simulations (with hidden parameters) or real experimental measurements, and N is the size of current samples set.
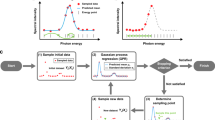
For fBO, we cannot ignore the possibility that we still may end up with a local optimum due to the high dimensionality of the fitting problem. In order to ensure that the fitting is accurate enough, we set a criterion that the loss between the predictions and the truth should be smaller than a threshold, which is defined as the average deviation between all the experiment values and its corresponding predictions. Afterwards, the resulting parameters and XAS will be fed into sBO, which will evaluate the current points and their corresponding differences, and then calculate the location of next point, which is thought to have maximum difference. The ABO workflow is shown in Fig. 6.

Starting with an arbitrary number of random initial energy points and their corresponding measured spectral values, two BO blocks are trained and updated competitively. The Fitting BO block fits the parameters of the Quanty model to identify the XAS curve that best matches the current measurements, while the Sampling BO block identifies the most likely point that could cause the fitted physical model to fail.
Bayesian optimization
Inside the ABO algorithm, we used an ExactGP and the scaled Matern52 kernel implemented in Gpytorch40 to interpolate the intensity values of sampling points of XAS by considering similarity of points and estimating the value of functions correspondingly24. Both fBO and sBO were constructed by using BoTorch41. We used GP to describe the distribution of XAS measurements. The outcomes of sampling points were first normalized to zero mean and unit variance. Assuming the observed inputs are \(X_n = \left( {x_1, \ldots ,x_n} \right)^T \in {\Bbb R}^n\) and the corresponding outcomes are \(Y_n = \left( {y_1, \ldots ,y_n} \right)^T\). The relation between the inputs and the outcomes follows the rule as \(y_i = f\left( {x_i} \right) + \sigma _i\), where \(\sigma _i\) is a Gaussian, which describes the noise distribution. The Gaussian of the previous observation and the new point can be expressed as:
where the \(K\left( {X_n,X_n} \right) + \sigma _n^2I\) is the covariance matrix between all observations with \(\sigma _n\) the estimated noise distribution during the measurement, I is an identity matrix. The kernel function used is Matern52 with a characteristic length-scale l. The twice differentiability of Matern52 makes it preferred to mimic the noise behavior in ML. However, the smoothness of the simulated function varies with respect to different dimension and location of the parameters. Thus, with a uniform l in the whole parameter space, the changes of local smoothness cannot be well described. In Gpytorch, the magnitude of the kernel is scaled by a scale factor \(\theta _{scale}\). As for the position of the parameter space, the l will be adjusted according to samples in batch and the range of Trust Region (TR) in BoTorch. This part will be explained later in the Trust Region Bayesian optimization section. Since GP is closed in the conditional action and marginalization cases, length-scale l can be optimized by maximizing the log marginal likelihood:
where:
This regression is done by Adam optimization algorithm implemented in BoTorch.
For the next energy point \(x^ \ast\), its posterior distribution is also a Gaussian:
with
where, \(y^ \ast\) is the measured value of point \(x^ \ast\), \(\bar \mu (x^ \ast )\) is the posterior mean and \(\bar K\left( {x^ \ast ,x^ \ast } \right)\) the posterior variance of point \(x^ \ast\), \(K\left( {X_n,x^ \ast } \right) = (K\left( {x_1,x^ \ast } \right), \ldots ,K\left( {x_n,x^ \ast } \right))\) is the vector of covariance between \(x^ \ast\) and all observations, which only varies with the position of \(x^ \ast\) and the noise estimation.
After obtaining the posteriors, we can use them to find the next sampling point with the help of acquisition function, which balances between exploration and exploitation. We used the Upper Confidence Bound (UCB) and Parallel Upper Confidence Bound (qUCB)42 implemented in BoTorch as the acquisition function for sBO and fBO (with Thompson sampling), respectively. The hyperparameters used for UCB and qUCB were adjusted accordingly in the different tests. For the CFM model, the global hyperparameters of sBO were set to 16; for the CTM model the hyperparameters were 49 for the initial 10 iterations and 4 for the remaining steps. Whereas for the tests using the experimental data, the hyperparameters were set to 100 for the initial 18 iterations and 1 for the remaining steps. For all simulations, the reason for using high values at the beginning is that our ABO starts with a small initial sample size, such high exploration values can give us a rough overall data distribution and prevent the ABO from ending at a local minimum.
Trust region Bayesian optimization
Although the traditional Bayesian optimization shows its power in low-dimensional gradient-free fitting, it is still limited by the exponential growth in computational complexity with high-dimensional parameters and large sample size43,44,45. For the high-dimensional black-box problem like the CFM and CTM models, it is difficult to describe this complex distribution precisely with a GP using a stationary kernel. In addition, the Bayesian optimization tends to stop at a local optimum due to the non-convexity of the problem46. To address these challenges, we applied the trust region (TR) method in the optimization. In the TR method, the algorithm selects the candidates according to each different TR, introduces a separate GP surrogate model for each TR, and optimizes its hyperparameters accordingly. Thus, within TR, the surrogate model is sufficiently accurate to describe the problem locally and is able to provide an optimal solution47. During the optimization, TR is chosen to be a hyper-rectangle area with the current best solution x* located at the center of it. The base side length of each dimension of this hyper-rectangle is set to be L, and the actual side length of each dimension of parameters can be obtained by \(L_i = \lambda _iL/( {\mathop {\scriptstyle\prod}\nolimits_{j = 1}^d {\lambda _j} } )^{\frac{1}{d}}\), where \(\lambda _i\) is the length-scale of parameters in GP. In each step we selected a batch of candidates within the TR with the help of GP and acquisition function. If the algorithm finds a better optimal solution than the current one in two successive iterations, the current TR is treated to be small enough so that the existing GP surrogate model is already capable of predicting with good accuracy. The L of TR is then doubled to allow the surrogate model to search in a larger range. If the algorithm cannot find a better solution in two iterations, the current TR is considered to be too large and will be halved. The algorithm will stop when the side length L meets maximum threshold \(L_{{{{\mathrm{max}}}}}\) or minimum threshold \(L_{{{{\mathrm{min}}}}}\). It is noted that a single TR cannot guarantee a global optimum but mostly the local minimum. To solve this problem, a parallelization of TRs with varying local GPs was introduced by TuRBO. The best result is then selected by:
where \(x_i^{\left( t \right)}\) the optimal point of our selection; \(l \in \{ 1,2, \ldots ,m\}\) denotes all the TRs utilized in each iteration, \(f_l^{\left( i \right)}\sim GP_l^{\left( t \right)}\left( {\mu _l\left( x \right),k_l\left( {x,x^\prime } \right)} \right)\) is the GP surrogate model applied in \(TR_l\)48.
Data availability
All data needed to produce the work are available from the corresponding author.
Code availability
ABO code is available upon reasonable request from the corresponding author.
References
Zimmermann, P. et al. Modern X-ray spectroscopy: XAS and XES in the laboratory. Coord. Chem. Rev. 423, 213466 (2020).
de Groot, F. M. F. et al. 2p x-ray absorption spectroscopy of 3d transition metal systems. J. Electron Spectrosc. Relat. Phenom. 249, 147061 (2021).
Stener, M., Fronzoni, G. & de Simone, M. Time dependent density functional theory of core electrons excitations. Chem. Phys. Lett. 373, 115–123 (2003).
Vinson, J., Rehr, J. J., Kas, J. J. & Shirley, E. L. Bethe-Salpeter equation calculations of core excitation spectra. Phys. Rev. B 83, 115106 (2011).
Thole, B. T. et al. 3d X-ray-absorption lines and the 3d94fn+1 multiplets of the lanthanides. Phys. Rev. B 32, 5107–5118 (1985).
Thole, B. T., Carra, P., Sette, F. & van der Laan, G. X-ray circular dichroism as a probe of orbital magnetization. Phys. Rev. Lett. 68, 1943–1946 (1992).
Winder, M., Hariki, A. & Kuneš, J. X-ray spectroscopy of the rare-earth nickelate LuNiO3: LDA + DMFT study. Phys. Rev. B 102, 085155 (2020).
Hariki, A., Uozumi, T. & Kuneš, J. LDA+DMFT approach to core-level spectroscopy: Application to 3d transition metal compounds. Phys. Rev. B 96, 045111 (2017).
Haverkort, M. W., Zwierzycki, M. & Andersen, O. K. Multiplet ligand-field theory using Wannier orbitals. Phys. Rev. B 85, 165113 (2012).
Green, R. J., Haverkort, M. W. & Sawatzky, G. A. Bond disproportionation and dynamical charge fluctuations in the perovskite rare-earth nickelates. Phys. Rev. B 94, 195127 (2016).
Haverkort, M. W. et al. Bands, resonances, edge singularities and excitons in core level spectroscopy investigated within the dynamical mean-field theory. EPL Europhys. Lett. 108, 57004 (2014).
Bethe, H. Termaufspaltung in Kristallen. Ann. Phys. 395, 133–208 (1929).
Sugano, S. & Shulman, R. G. Covalency effects in KNiF3. III. Theoretical studies. Phys. Rev. 130, 517–530 (1963).
Fujimori, A., Minami, F. & Sugano, S. Multielectron satellites and spin polarization in photoemission from Ni compounds. Phys. Rev. B 29, 5225–5227 (1984).
Fujimori, A. & Minami, F. Valence-band photoemission and optical absorption in nickel compounds. Phys. Rev. B 30, 957–971 (1984).
Gunnarsson, O. & Schönhammer, K. Photoemission from Ce compounds: exact model calculation in the limit of large degeneracy. Phys. Rev. Lett. 50, 604–607 (1983).
Gunnarsson, O. & Schönhammer, K. Electron spectroscopies for Ce compounds in the impurity model. Phys. Rev. B 28, 4315–4341 (1983).
van der Laan, G., Zaanen, J., Sawatzky, G. A., Karnatak, R. & Esteva, J.-M. Comparison of X-ray absorption with X-ray photoemission of nickel dihalides and NiO. Phys. Rev. B 33, 4253–4263 (1986).
Zaanen, J., Westra, C. & Sawatzky, G. A. Determination of the electronic structure of transition-metal compounds: 2p x-ray photoemission spectroscopy of the nickel dihalides. Phys. Rev. B 33, 8060–8073 (1986).
Fisher, R. A. The Arrangement of Field Experiments. In Breakthroughs in Statistics: Methodology and Distribution. 82–91 (Springer, 1992).
Noack, M. M. et al. Gaussian processes for autonomous data acquisition at large-scale synchrotron and neutron facilities. Nat. Rev. Phys. 3, 685–697 (2021).
Ueno, T. et al. Adaptive design of an X-ray magnetic circular dichroism spectroscopy experiment with Gaussian process modelling. npj Comput. Mater. 4, 1–8 (2018).
Ueno, T., Ishibashi, H., Hino, H. & Ono, K. Automated stopping criterion for spectral measurements with active learning. npj Comput. Mater. 7, 1–9 (2021).
Rasmussen, C. E. & Williams, C. K. I. Gaussian Processes for Machine Learning (The MIT Press, 2005).
Li, M. & Sethi, I. K. Confidence-based active learning. IEEE Trans. Pattern Anal. Mach. Intell. 28, 1251–1261 (2006).
Yano, J. & Yachandra, V. K. X-ray absorption spectroscopy. Photosynth. Res. 102, 241 (2009).
Koningsberger, D. C. & Prins, R. X-ray Absorption: Principles, Applications, Techniques of EXAFS, SEXAFS, and XANES (Wiley, 1988).
Alders, D. et al. Temperature and thickness dependence of magnetic moments in NiO epitaxial films. Phys. Rev. B 57, 11623–11631 (1998).
Honarmandi, P., Duong, T. C., Ghoreishi, S. F., Allaire, D. & Arroyave, R. Bayesian uncertainty quantification and information fusion in CALPHAD-based thermodynamic modeling. Acta Mater. 164, 636–647 (2019).
Ziatdinov, M. A. et al. Hypothesis learning in automated experiment: application to combinatorial materials libraries. Adv. Mater. 34, 2201345 (2022).
Kass, R. E. & Raftery, A. E. Bayes factors. J. Am. Stat. Assoc. 90, 773–795 (1995).
Cowan, R. D. The Theory of Atomic Structure and Spectra (University of California Press, 1981).
de Groot, F. M. F. & Kotani, A. Core Level Spectroscopy of Solids (CRC press, 2008).
Huffman, G. P. et al. Quantitative analysis of all major forms of sulfur in coal by x-ray absorption fine structure spectroscopy. Energy Fuels 5, 574–581 (1991).
Xia, K. et al. XANES studies of oxidation states of sulfur in aquatic and soil humic substances. Soil Sci. Soc. Am. J. 62, 1240–1246 (1998).
Clancy, J. P. et al. Spin-orbit coupling in iridium-based 5d compounds probed by x-ray absorption spectroscopy. Phys. Rev. B 86, 195131 (2012).
Igarashi, Y. et al. Appropriate basis selection based on Bayesian inference for analyzing measured data reflecting photoelectron wave interference. Preprint at http://arxiv.org/abs/2105.02341 (2021).
Dagotto, E. Correlated electrons in high-temperature superconductors. Rev. Mod. Phys. 66, 763–840 (1994).
Zhang, H. et al. CCDCGAN: deep learning prediction of crystal structures. Acta Crystallogr. Sect. Found. Adv. 77, C75–C75 (2021).
Gardner, J., Pleiss, G., Weinberger, K. Q., Bindel, D. & Wilson, A. G. In Advances in Neural Information Processing Systems. Vol. 31 (Curran Associates, Inc., 2018).
Balandat, M. et al. In Advances in Neural Information Processing Systems. Vol. 33 21524–21538 (Curran Associates, Inc., 2020).
Wilson, J. T., Moriconi, R., Hutter, F. & Deisenroth, M. P. The reparameterization trick for acquisition functions. Preprint at https://arxiv.org/abs/1712.00424 (2017).
Chen, B., Castro, R. & Krause, A. Joint Optimization and Variable Selection of High-dimensional Gaussian Processes. In Proceedings of the 29th International Conference on Machine Learning. 1423–1430 (IMLS, 2012).
Kandasamy, K., Schneider, J. & Poczos, B. High dimensional bayesian optimisation and bandits via additive models. in Proceedings of the 32nd International Conference on Machine Learning. 295–304 (PMLR, 2015).
Wang, Z., Hutter, F., Zoghi, M., Matheson, D. & de Feitas, N. Bayesian Optimization in a billion dimensions via random embeddings. J. Artif. Intell. Res 55, 361–387 (2016).
Shahriari, B., Swersky, K., Wang, Z., Adams, R. P. & de Freitas, N. Taking the human out of the loop: a review of bayesian optimization. Proc. IEEE 104, 148–175 (2016).
Yuan, Y. A review of trust region algorithms for optimization. Proceedings of the 4th International Congress on Industrial & Applied Mathematics (ICIAM 99), Edinburgh, 271–282 (1999).
Eriksson, D., Pearce, M., Gardner, J., Turner, R. D. & Poloczek, M. In Advances in Neural Information Processing Systems. Vol. 32 (Curran Associates, Inc., 2019).
Acknowledgements
The authors appreciate Gabriel Gomez for insightful discussions, and gratefully acknowledge computational time on the Lichtenberg High-Performance Supercomputer. Yixuan Zhang thanks the financial support from the Fulbright-Cottrell Award. This work was also supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation)—Project-ID 405553726—TRR 270. We also acknowledge support by the Deutsche Forschungsgemeinschaft (DFG—German Research Foundation) and the Open Access Publishing Fund of Technical University of Darmstadt.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
This work originated from the discussion of H.Z., Y.Z., R.X., and T.L. H.Z. and R.X. supervised the research. Y.Z. and T.L. worked on the machine learning model. Y.Z. and R.X. worked on the Quanty simulations. Y.Z., R.X., D.G., H.W., and K.O. worked on data analysis. All authors contributed in the writing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, Y., Xie, R., Long, T. et al. Autonomous atomic Hamiltonian construction and active sampling of X-ray absorption spectroscopy by adversarial Bayesian optimization. npj Comput Mater 9, 46 (2023). https://doi.org/10.1038/s41524-023-00994-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41524-023-00994-w
