
Abstract
Proximal device discovery is an essential initial phase in the installment of a device-to-device communication system in cellular networks. Therefore, an efficient device discovery scheme must be proposed with characteristics of minimum latency, discover maximum devices, and energy-efficient discovery in dense areas. In this paper, a bat echolocation-based algorithm derived from the bat algorithm is proposed and analyzed to fulfill the requirement of a proximal device discovery procedure for the cellular networks. The algorithm is applied to multiple hops and cluster devices when they are in a poor coverage zone. In this proposed algorithm, devices are not required to have prior knowledge of proximal devices, nor device synchronization is needed. It allows devices to start discovering instantly at any time and terminate the proximal device discovery session on completion of the discovery of the required proximal devices. Finally, device feedback is utilized to discover the hop devices in the clusters and analyze proximal discovery in a multi-hop setting. Along with this, a random device mobility pattern is defined based on human movement, and the device discovery algorithm is applied. The device discovery probability is calculated based on the contact duration and meeting time of the devices. We set up an upper bound less than 10 ms in long-term evolution of running time of the bat echolocation-based algorithm; this upper bound signifies the maximum degree of device discovery (more than 75% of the system) and the total number of devices. The outcomes thus imply that the proposed bat echolocation-based algorithm upper bound is better than 10 ms.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
A device to device (D2D) communication is typically an organization of two or more intelligent devices to communicate without the involvement or partial involvement of communication infrastructure [1,2,3]. A device has no information regarding other devices in its transmission coverage and aims to communicate with its proximal devices in the network. Therefore, proximal device discovery is a key initial phase for the initialization of D2D communication in the cellular system. Device proximal knowledge is essential for data routing algorithms, medium access control algorithms, and D2D network formation algorithms to work correctly and efficiently [4, 5]. Many device discoveries schemes have been proposed in D2D communication, but the main issues are discovered device synchronization, discovery delay, energy consumption, and discovery accuracy. Proximal device discovery is a non-trivial problem for several reasons and needs an optimized solution [6]. First, proximal device discovery must manage collisions in randomized proximal device discovery; second, when devices are heterogeneous in nature; and third, when devices are asynchronous.
Proximal device discovery algorithms can be categorized into two methods: randomized and deterministic [7,8,9,10]. In randomized proximal device discovery, every device transmits at a random time and discovers its proximal devices with high probability at each time. In deterministic proximal discovery, every device transmits as per an encoded transmission schedule that enables it to discover every one of its proximal devices with maximum probability. In a distributed network, discovery time increases, so the network needs the synchronization and a priori knowledge of the proximal devices. In an asynchronous system, devices can start discovery at random and may miss transmissions from each other. Furthermore, when the proximal users are unknown, devices do not know when or how to finish the proximal discovery process [11]. To guarantee fast device discovery, the authors in [12] projected a quick pairing methodology by utilizing an inverse popularity matching order strategy rather than traditionally utilized Kuhn-Munkres algorithm in [13]. A Signature-based device discovery technique was suggested in [14]. The paper gives a proficient method to limit the collisions during the discovery stage while utilizing the least physical resources. The autonomous device discovery technique dependent on FlashLinQ [15] was offered in [16]. Noteworthy power consumption of devices is a genuine worry during the device discovery phase. Besides, anyhow continual searching, this issue turns out to be more basic. Hence, the researchers in [17,18,19] have been given energy efficiency device discovery schemes while enhancing the performance of the system.
The hunting space search-based bats algorithm is most prominent in discovering their prey. Therefore, due to these motivations bat echolocation-based algorithm is proposed to solve device discovery issues. The discovery procedure is separated into two phases: investigation and the manipulation phase. The optimizer must incorporate devices globally to investigate the search space, and movements ought to be randomized. The manipulation phase follows the investigation phase and can be characterized as the process of exploring in detail the promising areas of the pursuit space. Manipulation thus relates to the neighborhood seeking ability in the promising areas of configured space found in the investigation phase. Finding a legitimate synchronization among investigation and manipulation is the most difficult assignment in the advancement of any meta-heuristic technique because of the stochastic idea of the optimization discovery procedure. Therefore, the bat echolocation-based algorithm is ideal to discover (investigation and manipulation) the proximal devices efficiently and has the capability to discover the heterogeneous devices even in poor coverage zoon. Echolocation is used to detect distance and recognizes prey and barriers, flying haphazardly. Therefore, the discovery signal strength adaptation of bat echolocation is used for proximal device discovery. These are good features for computational geometry applications for device discovery. All the idealization characteristics are incorporated in the bat echolocation-based algorithm to solve the discovery issue. The main discovery issues are exact device discovery, energy consumption and routing between devices for D2D communication. The bat echolocation-based algorithm addresses all these issues and gives better performance in terms of discovery, energy utilization, and routing. To verify this algorithm, a device mobility pattern is defined based on human movements. Using the Euclidean distance equation, distance is calculated between the responding devices in a mobility pattern by the bat echolocation algorithm. The discovery probability is calculated using contact duration and meeting probability frequency and verified by the Coupon Collector’s Problem [20].
The rest of this paper is organized as follows: basic bat algorithm is explained in Sect. 2 and echolocation characteristics are presented in Sect. 3. Section 4 defines the device mobility pattern. In Sect. 5 device discovery mechanism is explained and results are discussed with the coupon collector problem in Sect. 6. In the end, the paper is concluded in Sect. 7.
2 Basic bat algorithms
Heuristic and meta-heuristic algorithms with evolutionary and swarm techniques are currently becoming effective for solving numerous optimization issues, particularly real-world engineering issues because of reliability [21]. These algorithms have been derived from the behavior of physical and biological systems in nature. Bats are fascinating, and they have the innovative capability of echolocation [22]. Using echolocation capabilities, bats identify different attributes for both moving and stationary prey in their echo environment. Each prey has many features, and bats have capabilities to manipulate these features including distances, subtended angle, absolute size, azimuth, elevation, and velocity. Using idealization characteristics of the echolocation, the bat-inspired algorithm is proposed for device discovery. Echolocation allows bats to sense the distance between prey and barriers in a magical way. Bats fly haphazardly with velocity \(v_{i}\) at location \(x_{i}\) with frequency \(f_{i}\), varying \(\lambda\) and loudness \(A^{\text{t}}\) to discover the prey. They can adjust \(\lambda\) of echo signal and pulse emission rate \(r\) at the limit \(\left[ {0, 1} \right],\) depending upon the proximity of their prey. Loudness \(A^{t}\) can diverge in many ways but in this proposed algorithm is considered to be high \(A^{t}\) to minimum \(A^{0} \left( {A_{ \hbox{min} } } \right).\)
Bat echolocation can perceive the area of the devices (prey) and enclose them. Since the location of the search space is not known from the earlier efforts, the bat algorithm expects that the present best contender solution is the objective device or is near to optimum. After the best search, the bat (discoverer) transmits the other inquiry signal that will henceforth attempt to refresh their positions towards the best search discoveries [23]. This phenomenon is represented by the accompanying conditions:
where \(t\) is the present iteration; \(A\), \(C,\) and \(D\) are coefficient vectors; \(X'\left( t \right)\) is the discovery position vector; \({\text{X}}\left( {\text{t}} \right)\) is the discoverer position vector; \(||\) is the absolute value; and \(\cdot\) is the dot product. \(X^{\prime}\left( t \right)\) ought to be refreshed in every iteration to get the best solution. The vectors \(A\) and \(C\) in (2) are ascertained as \(A = 2a \;\cdot\;r {-} a\) and \(C = 2 \cdot r\) where \(a\) is linearly diminished through the span of iterations in both investigation and exploitation phases. Figure 1 shows the justification behind (2) where the location \(\left( {X, Y} \right)\) of a search mediator can be refreshed by the position of the present best record \(\left( {X^{\prime}, Y^{\prime}} \right)\). Better positions can be expected to improve the present position by modifying the estimation of \(A\) and \(C\) vectors. By characterizing the random discovery vector, it is conceivable to achieve any position in the inquiry space situated between the key-foci appearing in Fig. 1. Hence, (2) enables any search operator to refresh its position in the proximal current best arrangement and encircle the location of the devices.

2D position vectors and their possible next locations
3 Echolocation characteristics
The basic Bat algorithm does not much depend upon the power of the devices, while echolocation-based Bat algorithm depends upon the power of the devices. In our propose model devices power has significant role in device discovery in D2D communication. There are two phases to disseminate the echolocation signal for discovery: manipulation and estimation.
Manipulation phase Two approaches exist in the manipulation phase to determine the bat echolocation behavior-based device discovery model describes as follows:
(1) Growing echo mechanism This mechanism is accomplished by decreasing the estimation of \(a,\) and it is noted that the variance range of vector \(A\) is additionally decreased by \(a\). At the end of the day, vector \(A\) will be an irregular incentive in the interval \(\left[ { - a, a} \right],\) where \(a\) is diminished through the span of emphases. Setting random consequences for vector \(A\) in \(\left[ { - 1, 1} \right]\), the new location of a device can be characterized at any place between the first position of the device and the present position. Figure 1 demonstrates the conceivable positions from \(X, Y\) towards \(\left( {X^{\prime},Y^{\prime}} \right)\) that can be accomplished by \(0 \le A \le 1\) in 2-dimensional space. (2) Echo updating position mechanism an echo equation is built between the position of discoverer and discovery to imitate the echo-shaped movement of bats as follows:
This approach initially figures the separation between the discoverer device situated at \(\left( {X,Y} \right)\) and the discovery devices situated at \(\left( {X^{\prime},Y^{\prime}} \right),\) also indicating the separation of the \(i{\text{th}}\) discoverer devices from the discovery device, \(b\) is a constant to define the state of the logarithmic, \(l\) is an arbitrary number in \(\left[ { - 1,1} \right]\), and \(\cdot\) is a dot product [24].
3.1 Estimation phase
A similar approach considering the variation of the vector \({\text{A}}\) can be used to search for devices (investigation). Discoverer devices look haphazard as indicated by their relative positions. Therefore, \(A\) with the arbitrary esteem is more noteworthy than 1 or under − 1 to constrain the search device to move far from a reference point. Compared with the manipulation phase, the position of a device in the estimation stage is refreshed as indicated by a haphazardly picked searching operator rather than the best search operator discovered so far. This method and \(\left| A \right| > 1\) accentuate the investigation and allow the bat optimization algorithm to work for global search. The bat optimization algorithm can be represented on the mathematical model below:
where \(X_{rand}\) is the random position of discovery devices chosen from the existing population.
4 Devices mobility pattern
The devices mobility pattern is designed in Fig. 2 to clarify the random movement of the devices. The devices mobility pattern is defined by 200m × 200m coverage area and the device mobility pattern may assume an imperative part to decide the discovery ratio and routing algorithm performance. It is utilized to mimic the mobility pattern of focused real-life applications sensibly [25]. Consequently, while assessing the device discovery algorithm, it is important to pick the correct underlying mobility pattern. Random device mobility pattern is considered in this research and is the benchmark of the mobility pattern to evaluate the device discovery routing algorithm because it is simple and widely available [11]. To make the random waypoint device discovery model, the MATLAB tool including network simulator is used and lets the underlying position of the device \(Rs\) and \(Ds\) be \(\left( {x_{n} , y_{n} } \right)\). correspondingly at a time, as explained in Fig. 3. Random movement allows the devices to communicate with each other when they are in coverage of each other by the consent of the access point.

Discovered devices mobility pattern in 200 × 200 m2

Energy base discovery route for device discovery
The \(Rs\) and \(Ds \;{\text{of}}\;{\text{the}}\;{\text{device}}\) change with variable speeds in a specific direction with angles \(\theta_{1}\) and \(\theta_{2}\) regarding the positive x-axis, correspondingly. Device \(R\) covers a distance \(d_{1}\), and device \(D\) covers a distance \(d_{2}\) in spa \({\text{n }}0 \to t\). At time t, after movement, the devices \(R\) and \(D\) change to position \(\left( {x_{k} , y_{k} } \right)\) and \(\left( {x_{n} , y_{n} } \right)\) separately, as shown in Fig. 4. The Euclidean distance \(\left( {d\left( {RD,0} \right)} \right)\) between the device \(R\left( {x_{1} , y_{1} } \right)\) and \(D \left( {x_{2} , y_{2} } \right)\) at time \(t = 0\;{\text{is}}\) given by

The new position of the device after mobility
Let the devices \(R\) and \(D\) change with the variable speed \(v_{R}\) and \(v_{D}\) forming an angle \(\theta_{1}\) and \(\theta_{2}\) with the cluster, separation \(d_{1}\) and \(d_{2}\) crossed by the cluster in a specific time \(t\) is given by \(d_{1} = v_{R} \times t\) and \(d_{2} = v_{D} \times t\). At time \(t\), when device \(R\left( {x_{1} , y_{1} } \right) \;{\text{has}}\) traveled distance \(d_{1}\) with angle \(\theta_{1}\) and the x-axis, then the new location of the device will be \(D\left( {x_{6} , y_{6} } \right),\) as depicted in Fig. 4. The estimation of \(x_{6}\) and \(y_{6}\) as far as speed and time t is given as
Thus, when device \(D\left( {x_{2} , y_{2} } \right)\) transport is at a distance \(d_{2}\), assembling \(\theta_{2}\) angle along the x-axis in the new location of the device will be \(D\left( {x_{3} , y_{3} } \right).\) The coordinate estimation of \(x_{3}\) and \(y_{3}\) as far as speed and time \(t\) is given as
when a device \(R\) and \(D\) shifts to a new location \(R\left( {x_{6} , y_{6} } \right)\) and \(D\left( {x_{3} , y_{3} } \right)\), correspondingly. The new distance \(\left( {d\left( {RD,t} \right)} \right)\) among the devices \(R\left( {x_{6} , y_{6} } \right)\) and \(D\left( {x_{3} , y_{3} } \right)\) at \(t\) is given by
The reliability factor \((R_{Factor} )\) with constant \(w\) of device discovery
5 Device discovery mechanism
All the discussions in the previous sections have formed the background for the device discovery. Manipulation, estimation, and mobility pattern are included for efficient device discovery and based on these parameters; the bat echolocation-based algorithm is applied for device discovery. The proposed scheme is more reliable than whale optimization and other related algorithms [21].
5.1 Bat echolocation-based discovery algorithm
By using the idealization of the echolocation, the bat echolocation-based algorithm has the capability of discovering the heterogeneous devices even in the poor coverage zone. The following idealized rules are utilized for efficient device discovery. (1) All bats utilize echolocation to detect distance, and they additionally know prey and barriers. (2) Bats fly haphazardly with speed \(v_{i}\) at position \(x_{i}\) with varying wavelength and use different discovery signal strength \(A^{t}\) to scan for prey. They can adjust the frequency of their transmitted discovery signal automatically and change the rate of signal \(r \in \left[ {0,1} \right]\), contingent upon the proximity of their prey. (3) Although the discovery signal strength can change in many ways, it is always expected that the signal strength varies positively. Therefore, these are good features for computational geometry applications for device discovery, and all the characteristics are incorporated into the bat echolocation-based algorithm to solve the discovery issues. The bat echolocation-based algorithm gives better performance in terms of fast discovery, energy utilization, and routing. To verify this algorithm, the device mobility pattern is defined based on human movements. Using the Euclidean distance equation, distance is calculated between responding devices in a mobility pattern by the bat echolocation algorithm. The discovery probability is calculated using contact duration and meeting probability frequency and verified by the Coupon Collector’s Problem.
The bat algorithm is based on mimicking the nourishing behavior of bats and transmits natural waves to identify the position of the prey, accordingly, changing its position to pursue the prey. With the departure of the prey getting nearer, the loudness steadily lessens, and the frequency of emanation becomes quicker [26]. The frequency of natural waves and the span of prey are connected. The bat additionally assaults the prey with the echolocation methodology as described in Fig. 5. In the echolocation methodology, the bat transmits sound waves and wait for reflection or echo. When the bat receives echo and based on echo characteristics it decides the location of prey. The same concept is implemented for the device discovery algorithm in a specific search space. A discoverer device sends a signal or takes help from the base station to get the position of the proximal devices. Discoverer devices and proximal devices give the response via a base station or directly to the discovery devices. Depending on the network configuration, it may be device-centric or centralized. A device movement pattern is saved in the pattern table, which helps to discover the devices with minimum delay. This technique is numerically detailed as follows: suppose at time \(t\), \(X\) demonstrates the position of a bat, and \(v\) addresses speed, which implies the level of the difference in the positions. Then, the position-refreshing technique of the bat can be calculated as follows:

Bat echolocation methodology for prey discovery
As indicated by the qualities of bats, bats modify their flight speed as per their separation from prey [27], which is detailed as
where \(f\) addresses the frequency of natural waves, \(X'\) addresses the position of the prey. To emulate the irrational actions of bats, for example, flight straying from a known prey with the level of deviation in the scope of loudness, the equation is as follows:
where \(\varepsilon\) between \(\left[ { - 1 1} \right]\) follows a uniform distribution, and \(A^{t}\) signifies signal strength, the loudness appraisal formula is
where \(A_{i} \left( {t + 1} \right) \to 0 {\text{as t}} \to \infty\) and \(\propto\) is the empirical value. Bats estimate the separation from the prey by switching the frequency of emanation. The frequency of emanation update is as follows:
while \(r_{i} \left( t \right) \to r_{i} \left( 0 \right) as t \to \infty ,\) and \(\gamma\) is the empirical constant and is explained in the Pseudocode of the bat algorithm in Fig. 6.

Pseudocode of the Bat echolocation like algorithm
When a source device needs to send multicast discovery information to a cluster of destination devices, multicast paths have been made utilizing a reliable neighboring device assortment scheme. In this plan, the next device is chosen, considering the estimation of the quality pair factor. The framework works in the accompanying steps: (1) computation of \(R_{Factor}\) among the devices and expulsion of those devices having less dependability esteem in contrast with the threshold quality esteem factor \(R_{Factor} < R_{{th\left( {Factor} \right)}}\). (2) Finding of the multicast courses utilizing path request and path answer signal. (3) A multicast path has been allotted based on maximum \(R_{Factor}\) of the path. The information has been exchanged from the source device to a group of connected destination devices with the help of the device information table, which is associated with each device in the system. When the source device transmits the discovery request across the network, the devices listen to the request which is near to the source device. The discovery request contains such information in its header as the address of the source device, the cluster address, the reliability factor, the destination address and the battery power ratio. Each device in the network contains two tables which are updated regularly: the proximal information table and the routing information table. The proximal information table keeps the address of the proximal devices that are joining in the transmission area of the device with their \(R_{Factor} ,\) and the routing information table provides the flow of signal intelligently.
5.2 Discovery reply mechanism
Whenever destination devices cluster receives the discovery request, they initiate the discovery reply phase as is presented in Fig. 3. The receiver devices generate a reply (or acknowledgment) that is routed back to the source devices through the adapted path using the path information field attached to a source request. The reply message contains the following data in its header: source address, receiver device path information, reverse path, and cluster head address. Suppose the destination cluster devices \(D_{1}\), \(D_{2}\), and \(D_{3}\) produce the reply signal and transmit it to the up-devices \(R_{7}\) and \(R_{5} ,\) correspondingly. After accepting the reply, device \(R_{7}\) again sends the reply to its proximal device, called relay \(R_{2} ,\) and saves in its header. This operation is done until the source device \(S1\) has gotten the answer from the destination device. Similarly, the upstream device \(R_{5}\) also replies toward the source device \(S1\) until it receives the answer. Finally, the source \(S1\) receives the two answer messages by means of two unique paths. Hence, two unique paths are set up for data transmission.
5.3 Discovery route maintenance mechanism
The route maintenance mechanism monitors communication operation and reports errors to source device \(S1\) (refer to Fig. 3). When the device mobility expands, the routes might be inaccessible between the devices. When a source device \(S1\) needs to send information to another device, and the connections among the devices are not working, then the direct solution is to transmit an error signal back to the source device \(S1\). For this situation, the source device starts the route discovery procedure once again, which has been explained in the flow chart of Fig. 7. There is a route from source device \(S1\) to the destination devices \(D2: S1 \to R_{3} \to R_{6} \to R_{7} \to D_{2}\). If the device \(R_{6}\) goes out from the coverage area of the device \(R_{3} ,\) then a communication link separates between the devices \(R_{3}\) and \(R_{7}\). In this situation, the device \(R_{3}\) transmits the information data to the device \(R_{6}\) and waits for an acknowledgment from \(R_{6}\). If the device \(R_{3}\) will not get the acknowledgment from \(R_{6}\), then device \(R_{6}\) is considered out of coverage, showing that no transmission link exists between the device \(R_{3}\) and \(R_{6}\).

Flow chart of cluster devices mobility management
Consequently, the device \(R_{3}\) transmits a route error to source device \(S1,\) and the source device initiates the route discovery procedure once again to build up the new route. A constant bit rate model is used as a data traffic type, and in this model, the source device \(S1\) transmits a certain amount of signal for discovery. Some fixed parameters are utilized as a part of the simulation, and the performance evaluation parameters used in the simulation are explained as follows:
Discovery signal delivery ratio (DSDR) DSDR is the ratio of the discovery received signal at the destination to the transmitted discovery signal from the source.
Discovery signal delivery delay (DSDD) DSDD is the average time to send the discovery signal from the source device to the cluster receiver devices.
Signaling overhead (SO) SO is the average discovery signal exchange between the reliable devices and the proximal devices at any time.
where \(R\) is a reliable device on the network, and \(M\) is proximal to each reliable device; signals are the messages exchanged among every reliable device and its proximal devices.
Control overhead (CO) CO is the number of control signals that are required to establish a steady routing path from the source device to the cluster device receivers.
6 Results and discussion
In this section, the results are evaluated with discussion in terms of device discovery probability ratio and discovery signal probability, and results are compared with the Coupon Collector’s Problem. The MATLAB simulator is used to execute the algorithm, and the proposed system model has been developed. We simulate a cell of length 100 × 100 m2, with a single base station placed in the middle of the cell, and a variable number of scheduled and uncoordinated devices that are uniformly and randomly distributed in the cell. All devices have omnidirectional antennas. There are 50 devices out of which 45 are blind devices (uncoordinated or random devices) and work at 5G frequencies. The reference power of each device is 2.2 mW. The standard (AWGN) channel is considered in this scenario and multipath scenarios is added because there are 50 random devices are deployed in simulation setup.
6.1 Discovery meeting probability
Let \(P\left( {S,D} \right)\) be the meeting probability between any two devices such as the source devices \(S\) and the destination device \(D\). For example, when device \(S\) and device \(D\) or \(R\) meet each other and make a connection with each other, they will interchange their meeting probability tables individually to the devices. Provided that the met device relay \(R\) has a greater probability to the \(D\), device \(S\) will convey the proposed signal to device \(D\). However, if \(D\) has a lesser probability, device \(S\) will not transmit the proposed signal to \(D\) (refer to Fig. 3). The meeting probability [28] is given as follows if device \(S\) meets device \(D\):
If device \(S\) does not meet device \(D\) in a period, then
\(P_{orignal}\) is an initialization, \(\gamma\) is a constant between \(0\;{\text{and }}\;1\) and \(k\) is the interval since the previous meeting until now. If device \(S\) meets device \(R\) regularly and device \(R\) meets device \(D\) regularly, then the meeting probability of device \(S\) and device \(D\) will be updated as follows:
where \(\beta \;{\text{is}}\) a signal transfer factor, which signifies the effect of meeting probability by signal transfer. From (22) to (24), if device \(S\) and device \(D\) encounter each other more regularly in the network, the meeting probability among them becomes larger. When two devices encounter each other in the network, the discovery signal will be redirected to the device that meets more regularly with the destination device. To get better results from this algorithm when two devices meet, the discovery signal will be redirected successfully, and signal delivery probability is equal to encounter probability.
6.2 Discovery signal delivery probability
Meeting probability means the probability that a relay device meets with the destination device during mobility. In this algorithm, the forwarded discovery signal to the relay node is chosen by the difference in the value of the meeting probability. Signal delivery probability is symbolized as \(P\left( {R, D} \right)\), which shows the probability of the signal being successfully delivered to device \(D\) from device \(R\). Updating of the discovery message delivery probability \(P\left( {R,D} \right)\) is given in the following steps: discovery signal probability increases as meeting frequency and contact time increase. When two devices meet, they will update the discovery signal sending a probability table using the given mathematical model:
and
\(T_{RD}\) denotes the total contact duration between the relay device \(R\) and destination device \(D\). \(t_{{RD_{end} }} \left( j \right) \;{\text{is}}\;{\text{the}}\) end time of the \(j{\text{th}}\) link between relay device \(R\) and destination device \(D\), and \(t_{{RD_{start} }} \left( j \right) \;{\text{is}}\;{\text{the}}\) start time of the \(j{\text{th}}\) link between device \(R\) and destination \(D\). In addition, \(T_{R} = \mathop \sum \limits_{{{\text{i}} = 1}}^{n} t_{Ri}\) is the time where the relay device \(R\) is in contact with other devices in the network, and \(T_{D} = \sum\nolimits_{k = 1}^{n} {t_{Dk} }\) is the total time that device \(D\) is in contact with other devices in the network. \(\frac{{T_{RD} }}{{\left( {T_{R} + T_{D} } \right)/2}}\) is the amount of contact time between devices \(R\) and \(D\) in the average of contact time \(\left( {T_{r} + T_{d} } \right)/2\).
6.3 Neighbor discovery as Coupon Collector’s Problem
First, the proximal device discovery problem transforms into the Coupon Collector’s Problem [29], and the probability of successful discovery transmission by device \(X_{i}\) in a given time is:
\(P\) is normally distributed for each device \(i, 1 \le i \le n.\) The procedure of proximal device discovery translates into a Coupon Collector’s Problem as follows: consider Coupon Collector \(C\) depicting coupons with substitution from a vase containing \(n\) different coupons, with every coupon comparing to a device in the clique. In every time, C discovers proximal devices by coupon draw with probability \(p\) and remains idle with probability \(\left( {1 - np} \right)\). Therefore, if \(C\) gathers \(n\) different coupons regarding the discovery event, each device in the clique has discovered the greater part of its \(\left( {n - 1} \right)\) neighbors.
Discovery time The derivation of \(E\left[ W \right]\), where \(W\) is an arbitrary variable that means the time required for every device to discover its proximal devices. The proximal device discovery procedure can be considered as comprising a sequence of discovery periods, every discovery period comprising at least one period. Suppose \(W_{m}\) denotes discovery time length \(\left( {m, 0 \le m \le \left( {n - 1} \right)} \right)\); discovery time length begins when the \(m{\text{th}}\) device is discovered and finishes when the \(m + 1{\text{st}}\) device is discovered. Therefore, in the \(m{\text{th}}\) time slot, there are \(\left( {n - m} \right)\) devices still to be discovered and all have probability \(p\) to be discovered in each time span. The discovery time length \(W_{m}\) is geometrically scattered with parameter \(\left( {n - m} \right)p\). Therefore, taking note that \(W = W_{0} + \cdots + W_{n - 1}\), we get
Unknown number of neighbors By reduction, suppose that every device belongs to a clique. The bat echolocation-based algorithm works in stages, with each stage comprising at least one discovery time slot. In the \(r{\text{th}}\) stage, which endures for \(2^{r + 1} \;\cdot\;e\;\cdot\;ln2^{r}\) discovery slots, every device transmits the discovery signal with probability \(1/2^{r}\). Therefore, the devices geometrically diminish their transmission probabilities until they join an execution suitable for the cluster size, which occurs when devices enter the \(\log n{\text{th}}\) stage, and during this stage, every device sends with probability \(1/n\) for an interval of \(2\;\cdot\;n\;\cdot\;e\;\cdot\;ln n\) time slots. So
From (29), all \(n\) devices will be found by the \(\log n{\text{th}}\) stage with high probability. The aggregate number of discovery time slots, \(W\), until all n devices are found with high probability can be described as
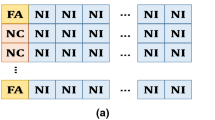
Compared to (29), the absence of the information of \(n\) outcomes slow down no more than twice. The coupon transmission by the devices in the clusters is presented in Fig. 8. If the value of the coupon is greater than the threshold value (5 in this case), then these devices are eligible for discovery and qualify for D2D communication. As the value of the coupon is high, it has more probability for discovery. The same holds in the bat echolocation-based algorithm. First, if the loudness of the signal is high, then more devices will be discovered. Second, if the bat signal is spread over a large area, there is a smaller chance to capture the prey. Therefore, in this case, four quadrants are proposed for device discovery, and each quadrant utilizes the minimum power and receives the best response from the discovery devices (RSSI), as presented in Fig. 9.

Bat echolocation like algorithm is like Coupon Collector’s Problem. Each device has his coupon value which helps to discovery

Power consumption of devices and response of the device in term of RSSI
Discovered devices in the given area have its own coverage area in the clusters and get information directly or via a relay of the proximal devices when they are under the coverage of each other. During relay services, if some devices are not eligible for D2D communication because of low power, then destination devices will be affected. There are many cases in which devices not eligible for D2D. Therefore, in this proposed methodology based on these facts, simulation results using regression, discovered devices and failure devices are shown in Fig. 10.

Discovery ratio in the proposed model
As the number of devices in the cluster increases in our proposed model, the relative energy consumption decreases as explained in Fig. 11. The bat echolocation-based algorithm works efficiently when devices form the clusters. When 10 devices are in the cluster, devices consume more energy (in dBm) compared to 20 to 50 devices in the cluster. The bat echolocation-based algorithm converges rapidly compared to other techniques presented in [30] and is shown in Fig. 12. In an 8th iteration, maximum devices discover with minimum power consumption in milli watts.

Energy consumption (dBm) using bat echolocation like algorithm

The convergence of the proposed algorithm with power consumption in milli watts and time in milli seconds
7 Conclusions
A D2D communication is typically organized for two or more intelligent devices to communicate without or with partial involvement of wireless communication infrastructure. To initiate D2D communication, proximal device discovery is the primary issue. It is a non-trivial problem due to the collision, heterogeneity, a-synchronicity, and completion of the discovery process. Therefore, an intelligence optimization solution for proximal device discovery is needed. The bat echolocation-based algorithm for device discovery is proposed in this work has the capability of discovering the heterogeneous devices even in the poor coverage zone. Using the invention of echolocation characteristics of bats, the device knows the barriers and varies the loudness that is used for proximal device discovery. The bat echolocation-based algorithm is applied, and it has the intelligence to discover maximum devices with minimum energy consumption regardless of whether the number of devices increases. This work can be further enhanced for data routing and resource allocation for device discovery and for large geographical area.
References
Hayat O, Ngah R, Mohd Hashim SZ, Dahri MH, Firsandaya Malik R, Rahayu Y (2019) Device discovery in D2D communication: a survey. IEEE Access 7:131114–131134
Zhang HL, Liao Y, Song LY (2017) D2D-U: device-to-device communications in unlicensed bands for 5G system. IEEE Trans Wirel Commun 16(6):3507–3519. https://doi.org/10.1109/Twc.2017.2683479
Zhang Z, Wang L, Liu D, Zhang Y (2017) Peer discovery for D2D communications based on social attribute and service attribute. J Netw Comput Appl 86:82–91
Masood A, Sharma N, Alam MM, Le Moullec Y, Scazzoli D, Reggiani L, Magarini M, Ahmad R (2019) Device-to-device discovery and localization assisted by UAVs in pervasive public safety networks. In: ACM MobiHoc workshop on innovative aerial communication solutions for first responders network in emergency scenarios, Catania, Italy, July 2019, pp 6–11
Zhang P, Lu J, Wang Y, Wang Q (2017) Cooperative localization in 5G networks: a survey. ICT Express 3(1):27–32. https://doi.org/10.1016/j.icte.2017.03.005
Nur FN, Sharmin S, Habib MA, Razzaque MA, Islam MS, Almogren A, Hassan MM, Alamri A (2017) Collaborative neighbor discovery in directional wireless sensor networks: algorithm and analysis. EURASIP J Wirel Commun Netw 1:119
Li B, Guo WS, Liang YC, An CY, Zhao CL (2018) Asynchronous device detection for cognitive device-to-device communications. IEEE Trans Wirel Commun 17(4):2443–2456. https://doi.org/10.1109/Twc.2018.2796553
Burghal D, Tehrani AS, Molisch AF (2018) On expected neighbor discovery time with prior information: modeling, bounds and optimization. IEEE Trans Wirel Commun 17(1):339–351. https://doi.org/10.1109/Twc.2017.2766219
Zhang JY, Deng LK, Li X, Zhou YC, Liang YN, Liu Y (2017) Novel device-to-device discovery scheme based on random backoff in LTE-advanced networks. IEEE Trans Veh Technol 66(12):11404–11408. https://doi.org/10.1109/Tvt.2017.2727078
Choi KW, Wiriaatmadja DT, Hossain E (2016) Discovering mobile applications in cellular device-to-device communications: hash function and bloom filter-based approach. IEEE Trans Mob Comput 15(2):336–349. https://doi.org/10.1109/Tmc.2015.2418767
Yadav AK, Tripathi S (2017) QMRPRNS: design of QoS multicast routing protocol using reliable node selection scheme for MANETs. Peer Peer Netw Appl 10(4):897–909. https://doi.org/10.1007/s12083-016-0441-8
Wang L, Wu H (2014) Fast pairing of device-to-device link underlay for spectrum sharing with cellular users. IEEE Commun Lett 18(10):1803–1806
Alamouti SM, Sharafat AR (2014) Resource allocation for energy-efficient device-to-device communication in 4G networks. In: 2014 7th international symposium on telecommunications (IST). IEEE, pp 1058–1063
Zou KJ, Wang M, Yang KW, Zhang JJ, Sheng WX, Chen Q, You XH (2014) Proximity discovery for device-to-device communications over a cellular network. IEEE Commun Mag 52(6):98–107. https://doi.org/10.1109/Mcom.2014.6829951
Wu XZ, Tavildar S, Shakkottai S, Richardson T, Li JY, Laroia R, Jovicic A (2013) FlashLinQ: a synchronous distributed scheduler for peer-to-peer ad hoc networks. IEEE ACM Trans Netw 21(4):1215–1228. https://doi.org/10.1109/Tnet.2013.2264633
Baccelli F, Khude N, Laroia R, Li J, Richardson T, Shakkottai S, Tavildar S, Wu X (2012) On the design of device-to-device autonomous discovery. In: 2012 fourth international conference on communication systems and networks (COMSNETS 2012). IEEE, pp 1–9
Seo J, Cho K, Cho W, Park G, Han K (2016) A discovery scheme based on carrier sensing in self-organizing bluetooth low energy networks. J Netw Comput Appl 65:72–83
Kaleem Z, Khan A, Hassan SA, Vo N-S, Nguyen LD, Nguyen HM (2019) Full-duplex enabled time-efficient device discovery for public safety communications. Mob Netw Appl 25:1–9
Bracciale L, Loreti P, Bianchi G (2016) The sleepy bird catches more worms: revisiting energy efficient neighbor discovery. IEEE Trans Mob Comput 15(7):1812–1825. https://doi.org/10.1109/Tmc.2015.2471299
Vempaty A, Varshney LR, Varshney PK (2017) A coupon-collector model of machine-aided discovery. arXiv preprint arXiv:170803833
Chakri A, Khelif R, Benouaret M (2016) Improved bat algorithm for structural reliability assessment: application and challenges. Multidiscip Model Mater Struct
Yang XS, Gandomi AH (2012) Bat algorithm: a novel approach for global engineering optimization. Eng Comput 29(5–6):464–483. https://doi.org/10.1106/02644401211235834
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008
Zhao XY, Yuan PY, Chen YJ, Chen P (2017) Femtocaching assisted multi-source D2D content delivery in cellular networks. EURASIP J Wirel Commun Netw 1:125. https://doi.org/10.1186/s13638-017-0910-7
Gilani SMM, Hong T, Jin WQ, Zhao GF, Heang HM, Xu C (2017) Mobility management in IEEE 802.11 WLAN using SDN/NFV technologies. EURASIP J Wirel Commun Netw 2017(1):67. https://doi.org/10.1186/s13638-017-0856-9
Yang X-S (2010) A new metaheuristic bat-inspired algorithm. Nature inspired cooperative strategies for optimization (NICSO 2010, pp 65–74
Chunyu W, Yun P (2015) Discrete bat algorithm and application in community detection. Open Cybern Syst J 9:967–972
Yu C, Tu ZQ, Yao DZ, Lu F, Jin H (2016) Probabilistic routing algorithm based on contact duration and message redundancy in delay tolerant network. Int J Commun Syst 29(16):2416–2426. https://doi.org/10.1002/dac.3030
Vasudevan S, Adler M, Goeckel D, Towsley D (2013) Efficient algorithms for neighbor discovery in wireless networks. IEEE ACM Trans Netw 21(1):69–83. https://doi.org/10.1109/Tnet.2012.2189892
Hayat O, Ngah R, Zahedi Y (2017) Cooperative device-to-device discovery model for multiuser and ofdma network base neighbour discovery in in-band 5G cellular networks. Wirel Pers Commun 97(3):4681–4695. https://doi.org/10.1007/s11277-017-4745-7
Acknowledgements
The authors would like to express their gratitude to the Ministry of Higher Education (MOHE) in Malaysia and Universiti Teknologi Malaysia (UTM) for providing the financial support for this research through the HICoe Research Grant Scheme (R. J130000.7851.4J412). The Grant is managed by Research Management Centre (RMC) at UTM.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hayat, O., Ngah, R. & Mohd Hashim, S.Z. Bat echolocation-based algorithm for device discovery in D2D communication. SN Appl. Sci. 2, 1452 (2020). https://doi.org/10.1007/s42452-020-03244-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-020-03244-6