
Abstract
Soft computing (SC) techniques are being used by drilling experts to have proper control on drilling processes and decrease the overall expenditure of these operations by providing the possibility of pre-estimating the drilling incidents. In this research study, several methods including generalized reduced gradient (GRG) method and SC techniques such as multilayer perceptron (MLP) and radial basis function (RBF) are employed to model apparent viscosity (AV), plastic viscosity (PV) and yield point (YP) values of water-based drilling fluids (WBDFs). Furthermore, to ameliorate the estimation capability of the SC models, the performance of different MLP learning algorithms such as Levenberg–Marquardt (LM), Bayesian regularization (BR), scaled conjugate gradient (SCG) and resilient backpropagation (RB) were investigated and finally the four top models were unified into a paradigm using a committee machine intelligent system (CMIS). Moreover, to facilitate the on-site estimation of AV, PV and YP parameters, GRG method was adopted and three novel correlations were proposed. Finally, the performance analysis of all the constructed models is done and with respect to the obtained results, the CMIS method is found to be the most successful method for the tested dataset. The average absolute percent relative errors (AAPRE) of this model was found to be 6.51%, 8.01% and 11.72% for AV, PV and YP respectively, indicating that this model outperforms almost all the other predictive approaches existing so far. Although other models in the literature produced a better accuracy, dataset used in this study is more complicated and generalized. Additionally, in comparison with the existing correlations, more accurate results for the tested dataset were provided by the correlations developed in this study.













Similar content being viewed by others
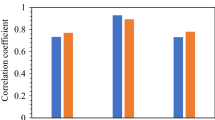
Abbreviations
- AI:
-
Artificial intelligence
- ARE:
-
Absolute relative error
- APRE:
-
Average percent relative error
- AAPRE:
-
Average absolute percent relative error
- ANN:
-
Artificial neural network
- AV:
-
Apparent viscosity
- BR:
-
Bayesian regularization
- CICD:
-
Continuous integration/deployment
- CMIS:
-
Committee machine intelligent system
- GRG:
-
Generalized reduced gradient
- LM:
-
Levenberg–Marquardt
- MFV:
-
Marsh funnel viscosity
- MW:
-
Mud weight
- MLP:
-
Multilayer perceptron
- MSE:
-
Mean square error
- PV:
-
Plastic viscosity
- PRE:
-
Percent relative error
- R2 :
-
Coefficient of determination
- RMSE:
-
Root mean square error
- RBF:
-
Radial basis function
- RB:
-
Resilient backpropagation algorithm
- SD:
-
Standard deviation
- SC:
-
Soft computing
- SCG:
-
Scaled conjugate gradient
- SP:
-
Solid percent
- T:
-
Temperature
- WBDF:
-
Water-based drilling fluid
- YP:
-
Yield point
References
Jafarifar, I., et al.: Evaluation and optimization of water-salt based drilling fluids for slim-hole wells in one of Iranian central oil fields. Upstream Oil and Gas Technology 5, 100010 (2020)
Fadairo, A.A. et al.: Environmental impact evaluation of a safe drilling mud. In SPE middle east health, safety, security, and environment conference and exhibition. Society of Petroleum Engineers (2012)
Bourgoyne Jr, A.T. et al.: Applied drilling engineering (1991)
Rooki, R., et al.: Optimal determination of rheological parameters for herschel-bulkley drilling fluids using genetic algorithms (GAs). Korea-Aust. Rheol. J. 24(3), 163–170 (2012)
Jondahl, M.H.; Viumdal, H.: Estimating rheological properties of non-newtonian drilling fluids using ultrasonic-through-transmission combined with machine learning methods. In 2018 IEEE International Ultrasonics Symposium (IUS). IEEE (2018)
Power, D.; Zamora, M.: Drilling fluid yield stress: measurement techniques for improved understanding of critical drilling fluid parameters. in National Technology Conference “Practical Solutions for Drilling Challenges”: American Association of Drilling Engineers, Technical Conference papers, AADE-03-NTCE-35. (2003)
Abdelgawad, K., et al.: Real-time determination of rheological properties of spud drilling fluids using a hybrid artificial intelligence technique. J. Energy Resour. Technol. 141(3), 032908 (2019)
Feng, Y.; Gray, K.: Review of fundamental studies on lost circulation and wellbore strengthening. J. Petrol. Sci. Eng. 152, 511–522 (2017)
Elkatatny, S.; Mousa, T.; Mahmoud, M.: A new approach to determine the rheology parameters for water-based drilling fluid using artificial neural network. In SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition. Society of Petroleum Engineers (2018)
Elkatatny, S.: Determination the rheological properties of invert emulsion based mud on real time using artificial neural network. In SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition. Society of Petroleum Engineers (2016)
Elkatatny, S.; Gomaa, I.; Moussa, T.: New approach to obtain the rheological properties of drill-in fluid on a real-time using artificial intelligence. Petroleum (2019)
Stroud, B.K.: Mud laden fluids and tables on specific gravities and collapsing pressures. Department of Conservation (1922)
Stroud, B.K.: Application of mud-laden fluids to oil or gas wells. Google Patents (1926)
Weikey, Y.; Sinha, S.L.; Dewangan, S.K.: Role of additives and elevated temperature on rheology of water-based drilling fluid: A review paper. Int. J. Fluid Mech. Res. 45(1) (2018)
Lahalih, S.; Dairanieh, I.: Development of novel polymeric drilling mud dispersants. Eur. Polym. J. 25(2), 187–192 (1989)
Razi, M.M., et al.: Artificial neural network modeling of plastic viscosity, yield point, and apparent viscosity for water-based drilling fluids. J. Dispersion Sci. Technol. 34(6), 822–827 (2013)
Paiaman, A.; Ghassem, M.; Salamani, B.; Al-Anazi, B.D.; Masihi, M.: Effect of fluid properties on Rate of Penetration. NAFTA 60(3), 129–134 (2009)
Gowida, A., et al.: Data-driven framework to predict the rheological properties of CaCl2 brine-based drill-in fluid using artificial neural network. Energies 12(10), 1880 (2019)
Tchameni, A.P., et al.: Predicting the rheological properties of waste vegetable oil biodiesel-modified water-based mud using artificial neural network. Geosyst. Eng. 22(2), 101–111 (2019)
Al-Khdheeawi, E.A.; Mahdi, D.S.: Apparent viscosity prediction of water-based muds using empirical correlation and an artificial neural network. Energies 12(16), 3067 (2019)
Zhang, F., et al.: Pressure profile in annulus: Solids play a significant role. J. Energy Resour. Technol. 137(6), 064502 (2015)
Marsh, H.N.: Properties and treatment of rotary mud. Trans. AIME 92(01), 234–251 (1931)
Pitt, M.: The Marsh funnel and drilling fluid viscosity: a new equation for field use. SPE Drill. Complet. 15(01), 3–6 (2000)
Balhoff, M.T., et al.: Rheological and yield stress measurements of non-Newtonian fluids using a Marsh Funnel. J. Petrol. Sci. Eng. 77(3–4), 393–402 (2011)
Almahdawi, F.H.; Al-Yaseri, A.Z.; Jasim, N.: Apparent viscosity direct from Marsh funnel test. Iraqi J. Chem. Pet. Eng. 15(1), 51–57 (2014)
Elkatatny, S.; Mahmoud, M.: Real time prediction of the rheological parameters of NaCl water-based drilling fluid using artificial neural networks. In SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition. Society of Petroleum Engineers (2017)
Da Silva Bispo, V.D., et al.: Development of an ANN-based soft-sensor to estimate the apparent viscosity of water-based drilling fluids. J. Petrol. Sci. Eng. 150, 69–73 (2017)
Avcı, E.: An artificial neural network approach for the prediction of water-based drilling fluid rheological behaviour. Int. Adv. Res. Eng. J. 2(2), 124–131 (2018)
Al-Azani, K. et al.: Real time prediction of the rheological properties of oil-based drilling fluids using artificial neural networks. In SPE Kingdom of Saudi Arabia Annual Technical Symposium and Exhibition. Society of Petroleum Engineers (2018)
Tomiwa, O. et al.: Improved water based mud using solanum tuberosum formulated biopolymer and application of artificial neural network in predicting mud rheological properties. In SPE Nigeria Annual International Conference and Exhibition. Society of Petroleum Engineers (2019)
Hankins, D.; Salehi, S.; Saleh, F. K.: An integrated approach for drilling optimization using advanced drilling optimizer. J. Pet. Eng., (2015)
Nilsson, N.J.: Learning machines (1965)
Haykin, S.: Neural networks: a comprehensive foundation. Prentice Hall PTR, New Jersey (2007)
Haji-Savameri, M., et al.: Modeling dew point pressure of gas condensate reservoirs: Comparison of hybrid soft computing approaches, correlations, and thermodynamic models. J. Pet. Sci. Eng. 184, 106558 (2020)
Perrone, M.P.; Cooper, L.N.: When networks disagree: Ensemble methods for hybrid neural networks. Brown Univ providence RI Inst for brain and neural systems (1992)
Hashem, S.; Schmeiser, B.: Approximating a function and its derivatives using MSE-optimal linear combinations of trained feedforward neural networks. Purdue University, Department of Statistics (1993)
Shokrollahi, A.; Tatar, A.; Safari, H.: On accurate determination of PVT properties in crude oil systems: Committee machine intelligent system modeling approach. J. Taiwan Inst. Chem. Eng. 55, 17–26 (2015)
Swearingen, T. et al.: ATM: A distributed, collaborative, scalable system for automated machine learning. In 2017 IEEE international conference on big data (big data), pp. 151–162 (2017)
Barbosa, L.F.F.M.; Nascimento, A.; Mathias, M.H.; de Carvalho, J.A.: Machine learning methods applied to drilling rate of penetration prediction and optimization - A review. J. Pet. Sci. Eng. 183, 106332 (2019)
Hajizadeh, Y.: Machine learning in oil and gas; a SWOT analysis approach. J. Petrol. Sci. Eng. 176, 661–663 (2019)
Kadkhodaie-Ilkhchi, A.; Rahimpour-Bonab, H.; Rezaee, M.: A committee machine with intelligent systems for estimation of total organic carbon content from petrophysical data: an example from Kangan and Dalan reservoirs in South Pars Gas Field. Iran. Comput. Geosci. 35(3), 459–474 (2009)
Chen, C.-H.; Lin, Z.-S.: A committee machine with empirical formulas for permeability prediction. Comput. Geosci. 32(4), 485–496 (2006)
Osman, E.; Aggour, M.: Determination of drilling mud density change with pressure and temperature made simple and accurate by ANN. In Middle East Oil Show. Society of Petroleum Engineers (2003)
Ameli, F., et al.: Determination of asphaltene precipitation conditions during natural depletion of oil reservoirs: A robust compositional approach. Fluid Phase Equilib. 412, 235–248 (2016)
Karkevandi-Talkhooncheh, A., et al.: Modeling minimum miscibility pressure during pure and impure CO2 flooding using hybrid of radial basis function neural network and evolutionary techniques. Fuel 220, 270–282 (2018)
Rostami, A.; Hemmati-Sarapardeh, A.; Shamshirband, S.: Rigorous prognostication of natural gas viscosity: Smart modeling and comparative study. Fuel 222, 766–778 (2018)
Gill, P.E.; Murray, W.; Wright, M.H.: Practical optimization. SIAM (2019)
Abadie, J.: Generalization of the Wolfe reduced gradient method to the case of nonlinear constraints. Optimization, pp. 37–47 (1969)
Graves, R.L.; Wolfe, P.: Recent advances in mathematical programming (1963)
Sharma, R.; Glemmestad, B.: On generalized reduced gradient method with multi-start and self-optimizing control structure for gas lift allocation optimization. J. Process Control 23(8), 1129–1140 (2013)
David, C.Y., et al.: An optimal load flow study by the generalized reduced gradient approach. Electric Power Syst. Res. 10(1), 47–53 (1986)
Wilde, D.J.; Beightler, C.S.: Foundations of optimization. (1967)
Asadisaghandi, J.; Tahmasebi, P.: Comparative evaluation of back-propagation neural network learning algorithms and empirical correlations for prediction of oil PVT properties in Iran oilfields. J. Petrol. Sci. Eng. 78(2), 464–475 (2011)
Van, S.L.; Chon, B.H.: Effective prediction and management of a CO2 flooding process for enhancing oil recovery using artificial neural networks. J. Energy Resour. Technol. 140(3) (2018)
Fausett, L.: Fundamentals of neural networks: architectures, algorithms, and applications. Prentice-Hall, Inc., New Jersey (1994)
González, A.; Barrufet, M.A.; Startzman, R.: Improved neural-network model predicts dewpoint pressure of retrograde gases. J. Petrol. Sci. Eng. 37(3–4), 183–194 (2003)
Shahin, M.A.; Jaksa, M.B.; Maier, H.R.: Recent advances and future challenges for artificial neural systems in geotechnical engineering applications. Adv. Artif. Neural Syst. (2009)
Agwu, O.E., et al.: Artificial intelligence techniques and their applications in drilling fluid engineering: a review. J. Petrol. Sci. Eng. 167, 300–315 (2018)
Specht, L.P., et al.: Modeling of asphalt-rubber rotational viscosity by statistical analysis and neural networks. Mater. Res. 10(1), 69–74 (2007)
Razi, M., et al.: Experimental study and numerical modeling of rheological and flow behavior of Xanthan gum solutions using artificial neural network. J. Dispersion Sci. Technol. 35(12), 1793–1800 (2014)
Hinton, G.E.: Learning to represent visual input. Philos. Trans. R. Soc. B Biol. Sci. 365(1537), 177–184 (2010)
Mohaghegh, S.: Virtual-intelligence applications in petroleum engineering: part 3—fuzzy logic. J. Petrol. Technol. 52(11), 82–87 (2000)
Mohammadi, A.H.; Richon, D.: Use of artificial neural networks for estimating water content of natural gases. Ind. Eng. Chem. Res. 46(4), 1431–1438 (2007)
Nakamoto, P.: Neural networks and deep learning: deep learning explained to your granny A visual introduction for beginners who want to make their own Deep Learning Neural Network. CreateSpace Independent Publishing Platform (2017)
Varamesh, A., et al.: Development of robust generalized models for estimating the normal boiling points of pure chemical compounds. J. Mol. Liq. 242, 59–69 (2017)
Hemmati-Sarapardeh, A., et al.: On the evaluation of the viscosity of nanofluid systems: Modeling and data assessment. Renew. Sustain. Energy Rev. 81, 313–329 (2018)
Bolooki, M.L.; Hezave, A.Z.; Ayatollahi, S.: Artificial neural network as an applicable tool to predict the binary heat capacity of mixtures containing ionic liquids. Fluid Phase Equ. 324, 102–107 (2012)
Ameli, F., et al.: Modeling interfacial tension in N 2/n-alkane systems using corresponding state theory: Application to gas injection processes. Fuel 222, 779–791 (2018)
Hemmati-Sarapardeh, A., et al.: Determination of minimum miscibility pressure in N2–crude oil system: a robust compositional model. Fuel 182, 402–410 (2016)
Panda, S.S.; Chakraborty, D.; Pal, S.K.: Flank wear prediction in drilling using back propagation neural network and radial basis function network. Appl. Soft Comput. 8(2), 858–871 (2008)
Zhao, N.; Li, S.; Yang, J.: A review on nanofluids: Data-driven modeling of thermalphysical properties and the application in automotive radiator. Renew. Sustain. Energy Rev. 66, 596–616 (2016)
Elsharkawy, A.M.: Modeling the properties of crude oil and gas systems using RBF network. In SPE Asia Pacific oil and gas conference and exhibition. Society of Petroleum Engineers (1998)
Lashkenari, M.S.; Taghizadeh, M.; Mehdizadeh, B.: Viscosity prediction in selected Iranian light oil reservoirs: Artificial neural network versus empirical correlations. Pet. Sci. 10(1), 126–133 (2013)
Wu, Y. et al.: Using radial basis function networks for function approximation and classification. ISRN Appl. Math. (2012)
Park, J.; Sandberg, I.W.: Universal approximation using radial-basis-function networks. Neural Comput. 3(2), 246–257 (1991)
Chen, S.; Cowan, C.F.; Grant, P.M.: Orthogonal least squares learning algorithm for radial basis function networks. IEEE Trans. Neural Networks 2(2), 302–309 (1991)
Kişi, Ö.; Uncuoğlu, E.: Comparison of three back-propagation training algorithms for two case studies. (2005)
Hagan, M.T.; Menhaj, M.B.: Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Networks 5(6), 989–993 (1994)
MacKay, D.J.: Bayesian interpolation. Neural Comput. 4(3), 415–447 (1992)
Foresee, F.D.; Hagan, M.T.: Gauss-Newton approximation to Bayesian learning. in Proceedings of International Conference on Neural Networks (ICNN'97). IEEE (1997)
Pan, X.; Lee, B.; Zhang, C.: A comparison of neural network backpropagation algorithms for electricity load forecasting. In 2013 IEEE International Workshop on Inteligent Energy Systems (IWIES). IEEE (2013)
Yue, Z.; Songzheng, Z.; Tianshi, L.: Bayesian regularization BP Neural Network model for predicting oil-gas drilling cost. In 2011 International Conference on Business Management and Electronic Information. IEEE (2011)
Hagan, M.; Demuth, H.; Beale, M.: Neural network design. PWS. Boston OpenURL, (1996)
Møller, M.F.: A scaled conjugate gradient algorithm for fast supervised learning. Aarhus University, Computer Science Department (1990)
Riedmiller, M.; Braun, H.: A direct adaptive method for faster backpropagation learning: The RPROP algorithm. in IEEE international conference on neural networks. IEEE (1993)
Acknowledgements
The authors would like to thank the Iranian central oil fields company (ICOFC) for providing the data bank and supporting this study. Special thanks go to Dr. Robello Samuel, Chief Technical Advisor and Halliburton Technology Fellow for his guidance and helpful suggestions.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendix
Appendix
1.1 Estimation Techniques
1.1.1 Generalized Reduced Gradient
GRG can be used as a method to solve multivariable problems. To be more specific, this method is capable of solving linear and nonlinear problems and is capable of providing a significant prediction accuracy by choosing the most appropriate variables for target equations [47]. Indeed, GRG generates a linear estimation for the gradient at a specified point (e.g., x). The gradient and restrictions are concurrently explained and the objective function could be defined as the gradients of restrictions. Thereafter, it is possible to move the search space in a possible direction and the search area size can be reduced, consequently. For the objective function of f(x) which is subjected to h(x), we have:
Subjected to:
This method can also be described as shown in Eq. (A.3):
It is noteworthy that a necessary situation for minimizing f(x) is that df(x) = 0 or the same condition for an unlimited least is that \(\frac{df}{{dx_{k} }} = 0\) (Ameli et al., 2016). To get more informed about this concept, reviewing prior research studies on this subject [48,49,50,51,52] is suggested.
1.1.2 Multilayer Perceptron
There are different tools and methods for explaining intricate issues and nonlinear relations between input and output parameters, including typical ANNs [53,54,55,56,57,58]. ANNs can be described as mathematical systems in which data is processed in a similar way to that of a biological neural system with similar intricacy and functionality [43, 59, 60]. Neurons are considered as primary units of ANN models, therefore adjusting the optimum number of neurons along with other key parameters (e.g., weights and biases) facilitates the control of network’s performance [61,62,63,64].
The most frequently used ANNs are known to be MLP and RBF [65, 66]. There are several layers in an MLP neural network, in which the first and the last ones represent the inputs and outputs of the model and the middle layers are known as hidden layers [67, 68]. In order to specify the number of hidden layers, the most common method is to evaluate different ANN structures based on trial and error. For ordinary problems, an MLP model with one hidden layer may be proper and enough, while using two hidden layers or more would be considered in more complicated problems [69]. There is an interconnection between the neurons of one determined hidden layer and the neurons of prior and next layers, in a particular network with Purlin function for its output layer, and Logsig and Tansig activation functions for the hidden layers. The model output can be calculated from Eq. (A.4):
where b1 and b2 stand for the bias vectors of the first and the second hidden layers, respectively, and b3 represents the bias of the output layer. In addition, w1 and w2 indicate the weight matrix of the first and the second hidden layers, in order, and w3 represents the weight matrix of the output layer.
Furthermore, four optimization algorithms are applied in current research, including LM, BR, SCG and RB. For more information and details about the mentioned algorithms, checking the study conducted by Hemmati-Sarapardeh et al. [64] is recommended.
1.1.3 Radial Basis Function
RBF network is among the most famous kinds of ANNs that is typically applied for regression purposes. RBF neural networks contain three feed-forward layers, an input layer, a hidden layer and an output layer [70]. The input layer is formed of input nodes, where the input nodes and input factors of the model are equal in number [65]. The hidden layer can be regarded as the most important part of an RBF network, as it transfers the information from the input space to the hidden space [71].
RBF is considered to be a widely used method in mathematics and physics problems to estimate different types of properties. This approach has several features, including the generalization of data to different dimensional spaces, the possibility to handle scattered data and the resolution of spectral precision [68, 72, 73]. Primary models are feed-forward neural networks which have two layers [74, 75]. A training process with three steps is also used to specify all of the parameters for RBF units. First of all, K-means grouping algorithm are used to specify the units’ centers. In the second step, an optimization procedure like gradient descend is applied to specify the weights. Finally, a superposition rule is used to determine the weights connecting the RBF elements to the output. Some localized basis functions are also applied in the RBF approximation technique, e.g., ϕ (xi) for the regression of y (x). As it can be seen, the linear combination produces the following output functions:
where φ (xi) indicates the transport function, b indicates the bias parameter and wT is the vector of the transferred output layer.
In the initial step, centers are determined utilizing random methods. The hidden layer constitutes the most crucial part of the algorithm. Gaussian function is considered to be among the most practical types of transfer functions which are commonly used [76]:
Using the transport function, a correlation is attained as shown in Eq. (A.7):
In Eq. (A.7), ci indicates the centers, δ represents the spread coefficient, φki (x) represents the Gaussian transport function, and M and N signify the numbers of data points and kernels, respectively.
If a linear superposition method is used, the model output is expressed as shown in Eq. (A.8):
where N represents the clusters number, w0 indicates the bias factor, M stands for the number of inputs and outputs and finally yk represents the output of the model.
The main purpose of this equation is to underrate mean square error (MSE) by using optimization design like gradient descent. The following equation calculates the optimized weight:
Using the above scheme, it is possible to characterize the centers and optimize the weights, which is called “the approximated outputs.” This algorithm has two main factors, including the spread coefficient and the neurons number, which are optimized in the developed neural network to improve the estimation of mud rheological properties. These optimum values could be obtained by trial-and-error approach. To meet this purpose, the amounts of spread coefficient and neurons number were changed and various Gaussian RBF networks were designed. Finally, the optimum amounts are chosen by reducing the mean square error.
1.2 Optimization Techniques
1.2.1 Levenberg–Marquardt Algorithm
Several techniques are available to optimize the biases and weights in an MLP model among which, the LM algorithm is regarded as one of the best and most common ones. This technique is utilized to solve the nonlinear least square issues. Furthermore, this technique does not cause a universal minimization, yet it can find the ultimate solution even based on an unsuitable initial surmise. Another point to mention about this method is that it does not calculate the Hessian matrix. To put it in other way, since the performance function is represented as sum of the squares, the approximation of the Hessian matrix and the gradient are expressed as follows [68, 76, 78]:
where J stands for the Jacobian matrix that consists of the first system formative of the network error in relation to biases and weights, and e represents the network errors vector.
The order can be updated as follows:
where x denotes the connection weight, η represents a constant which is altered to less amounts when the steps are taken successfully and is changed to greater amounts as a hesitant stage expands the performance function.
As it is seen, after each iteration the performance function value is reduced, which has a detailed explanation provided and stated in the literature [68, 78].
1.2.2 Bayesian Regularization Algorithm
BR technique is considered as a training algorithm that is able to update biases and weights based on LM optimization [79, 80]. This algorithm decreases a combination of squared errors and weights and afterward specifies the appropriate composition to develop a network [81]. The weights of the networks for the objective function are specified as shown in Eq. (A.13) [68, 82]:
where ED, Eω and F(ω) represent the total of network errors, the total of squared network weights and the objective function, respectively. Moreover, α and β are factors of the objective function.
Weight of network can be introduced as the random parameter of the BR neural network. Additionally, the training sets and network weight can be created according to the Gaussian distribution. Then, the best amounts for the determined variables are computed and after that, learning phase of the algorithm is performed by LM algorithm to minimize the objective function and update the weight space. If a divergence occurs, the parameters should be updated and the procedure should be repeated [68, 82].
1.2.3 Scaled Conjugate Gradient Algorithm
The weights used in this technique are adopted from the most negative gradient; however, it is not considered as the most rapid algorithm [68, 77]. Using a search algorithm like the conjugate gradient leads in a faster convergence. In this algorithm, assuming Pk as the search direction (or the conjugate direction) and to optimize the current search direction, the following equations are used [68, 77, 83]:
The procedure of computing β specifies the degree of conjugate gradient. Line search method, which is regarded as a prediction method for the stage size, is not cost-effective in terms of computation expenses. In another method, known as SCG, the CG algorithm is combined with trust area method, but with a less cost [68, 84].
1.2.4 Resilient Backpropagation Algorithm
Different transfer functions, such as Sigmoid or Tansig, can be used in an MLP algorithm. The task of these functions is to reduce the infinite input domain to the finite output domain. In an activation function like Tansig, the line slope becomes closer to zero by entering a big input, which might lead to some issues while applying steepest descent to train the network. This is due to the fact that the gradient has a minor amount and hence, small variations are made in weights and biases. In order to solve these problems, the RB algorithm has been suggested to remove the undesirable effects of the partial derivatives [85].
Rights and permissions
About this article

Cite this article
Jafarifar, I., Najjarpour, M. Modeling Apparent Viscosity, Plastic Viscosity and Yield Point in Water-Based Drilling Fluids: Comparison of Various Soft Computing Approaches, Developed Correlations and a Committee Machine Intelligent System. Arab J Sci Eng 47, 11553–11577 (2022). https://doi.org/10.1007/s13369-021-06224-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13369-021-06224-z