
Abstract
Traditional classification approaches are all pixel-based and do not utilize the spatial and context information of an object and its surroundings, which has potential to further enhance digital image classification. Instead of pixel-based, pixels groupings and object segmentation offers more innovative techniques to image classification. In this study, land cover types in the Klang valley, Malaysia were analyzed to compare classification accuracy between the pixel-based and the object-oriented image classification approaches. Landsat 7 ETM+ with six spectral bands was used for the land cover classification. In the pixel-based image classification, supervised classification was performed using the maximum likelihood classifier. On the other hand, the object-oriented image classification was performed using the combination of object segmentation using fuzzy dimension techniques. The selected parameters for image segmentation were: scale parameter 15, homogeneity composition criterion (color 0.7 and shape 0.3), shape criterion (smoothness 0.9 and compactness 0.1). Fuzzy dimension functions were devised to classify the segmented image objects. The classification results showed that the object-oriented cum fuzzy logic approach was superior to that of the pixel-based supervised classification. The former has achieved higher overall, producer and user accuracies for most of the land cover classes compared to those of the latter. In addition, the accuracy of the former has met the requirements of international standard for digital mapping with overall accuracy exceeding 85%; Kappa value above 0.85 while accuracy differences among the classes were kept minimal.
Similar content being viewed by others

Introduction
Since the early 1990s, many countries in the developing world have commenced using moderate-resolution satellite imageries such as the Landsat TM and SPOT 4 for land cover and forest-type classification at the national level. The visual classification approach has been widely accepted to get reliable results (Kumar 2003; Loh 2003). However, since this has been a time-consuming process, most of the developing countries could hardly afford to update their land cover digital database regularly using these traditional approaches.
Digital supervised classification has not been adopted at national level in many countries, although it is a faster alternative in extracting land cover information. This was attributed due to unacceptable mapping accuracy of less than 80%. However, at the sub-national level, accuracy above 85% has been achieved occasionally through the use of high spectral dimensional satellite datasets with careful selection of uncorrelated spectral bands for classification (Dwivedi and Rao 1992; Mausel et al. 1990). Generally, two major setbacks confronted in digital classification are: (1) firstly, over-dependent on spectral values of the training areas often resulting in many misclassified and unclassified pixels; (2) secondly, the output map normally has inconsistent salt and pepper appearance due to the rich information content of moderate-resolution satellite images than the high-resolution images.
There is a need for an enhanced digital classification approach to replace the visual-based techniques with equal if not better accuracy while keeping it cost effective is a prerequisite in the developing world. Countries like China, Malaysia, Thailand, and Vietnam, which are developing rapidly, are required to regularly update the national land-use digital database for the purpose of spatial planning and decision support for national development. In recent years, some researches have been conducted using object-oriented and fuzzy logic digital classification on moderate-resolution satellite imageries. Wong et al. (2003) and Shattri et al. (2008) have done some research on land cover mapping and on biodiversity mapping (Daqamseh 2007). These works were, however, limited to localize project site areas at the sub-district level covering less than 300 acres. Although their findings have shown classification accuracy exceeding 85% but the results have not been verified over larger areas. This study highlights the findings of work conducted using the combination of object-oriented and fuzzy logic digital classification, which showed significantly higher accuracy than supervised digital classification using the maximum likelihood classifier. This paper further explores and demonstrates the capability of object-oriented image analysis software eCognition (Definiens Imaging, Germany) for landcover classification from Landsat ETM imagery. The combination of complex object description, hierarchical image object network, and fuzzy system makes eCognition a challenge to knowledge-based image interpretation in a range of landcover classification applications.
Study area
The study area is located in the west coast of Peninsular Malaysia within the 3°28′ N, 101°41′ E (Fig. 1). The area is captured in a single Landsat TM scene (Path:Row = 125:59) and it is suitable for this study because it contains typical conglomerate land cover types found in Malaysia. A subset (2,779 × 1,938 pixels) from the Landsat ETM+ image is taken as the experiment image. On the ground, it encompasses the federal territory of Kuala Lumpur, Petaling Jaya, Shah Alam, and Klang, which are clearly depicted on the image with the coastal outlet at Port Klang in the West (Fig. 1). The Eastern fringe of study area is surrounded by mountains belonging to the main range of Malaysia. Land-use is dominated by urban residential developments (44%), forest reserves (34%), agriculture (15%), and commercial/industry (7%).

Location of the study area: a false-color image composite (4, 5, 3) of the Landsat ETM+image
Data and methodology
The Landsat TM datasets, geo-referenced to the Malaysian Rectified Skewed Orthormorphic map projection, was used for the research as depicted in Fig. 1.
Ancillary data acquired for the study that includes:
-
1.
Topographical maps from the national mapping and survey department\
-
2.
Forest map from the department of forestry
-
3.
Land-use map from the department of agriculture
-
4.
Aerial photographs from the national mapping and survey department
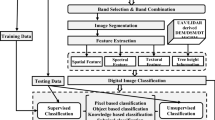
Figure 2 shows the methodology flowchart adopted for the analysis. In the first step, the imagery was geometrically registered and radiometrically corrected. The Landsat TM image was radiometrically corrected using Dark object subtraction (DOS) which is an image-based absolute atmospheric correction approach for classification and change detection applications. For Landsat TM data, the dominant atmospheric effect is scattering which is additive to the remotely sensed signals, while multiplicative effect from absorption is often neglected because the TM bands were selected to avoid effects due to absorption. In the second step, land cover image objects were generated using an image segmentation algorithm. Image segmentation was performed to further handle high spectral variation and overlapping values of classes. In this phase, the image was split into smaller regions (object primitives) to simplify the complex data content thematically (Baatz et al. 2003). The classification was then performed using segments instead of single pixels. In this case, fuzzy c-means algorithm was used for image segmentation. In the third step, created objects were classified through a pixel-based classification method as well as using fuzzy logic classification. For the definition of the membership functions for the class descriptions, fuzzy logic membership functions were used to define object features. Fuzzy description enables classes to be assigned according to the membership degree. The following features were applied: (a) object features: mean layer values (blue, red, NIR, brightness, GLCM mean 3 × 3, IHS, Sobel NIR), ratio layer values (blue, red), area generic shape feature; (b) class-related features: relative border to neighbor objects, relative area of sub-objects, existence of sub-objects (super-objects); (c) customized NDVI index, HIS brightness index. The training samples used for the former classification were carefully chosen after field investigation and reference were made to available ancillary maps. In the latter classification, fuzzy limits were set using appropriate spectral bands for individual land cover classes. Finally, the accuracy of the classification results derived from both methods were assessed using reliable reference sites.

Flowchart of image processing for land cover classification
Multi-resolution segmentation analysis
The Landsat TM imageries (bands 1, 2, 3, 4, and 5) were segmented into three levels in hierarchical-network-based homogeneity criteria. Those criteria are not only using the color and form from which the segments are embedded into the intrinsic pixel statistics but also pixel spatial continuity, encompassing texture, shape, and context. Within each segmentation level, an image object is not only linked to its neighbors, but also its super-object and its sub-object providing useful context information for classification analysis (Hall et al. 2004). Table 1 shows the parameters selected for segmentation as facilitated in the eCognition Version 3.2 software. The hierarchical network showing the relationship between the three levels are shown in Fig. 3.

Hierarchical network of image objects—level 1 (10 pixels), level 2 (15 pixels), and level 3 (30 pixels)
In this study, segmentation level 2 of scale parameter 15 was selected for classification as it gave the best result in visualization of land and water classes based on color and form homogeneity. It will provide the optimal information for classification analysis (Daqamseh 2007).
eCognition v3.2 object-oriented image analysis software offers a relative segmentation technique called multi-resolution segmentation (Definiens 2005). This study attempted to detect the positive and negative effects of segmentation parameters. So, in eCognition v 3.2 software, segmentation parameters were changed one by one and the segmentation results were monitored by using ground-sampled distance. This initial segmentation process is knowledge-free and therefore the image objects generated are regarded as object primitives. To build up the knowledge-base structure of these objects, a class hierarchy was created, which contained all the classes relevant for classification—inheritance as well as semantic classes.
Formulation of class hierarchy starts with identifying the general parent classes and their related child classes, which is called the inheritance class hierarchy. In this hierarchy, the class description is defined in parent classes, and subsequently is passed on to their respective child classes. eCognition also allows the restructuring of these child classes to fall under relevant semantic groupings under a specified classification scheme. It is apparent that while child classes in the inheritance hierarchy differentiate the parent classes, these child classes contain also relevant information that enabled them to be semantically grouped under a superior class. The feature classes hierarchy created in this research are shown in Fig. 4.

Class hierarchy of the study
The parent classes are water and non-water. The non-water class then spawns two sub-classes—none vegetated (urban and built-up) and vegetated which in turns spawns seven child classes—swamp, rubber, oil palm, grassland, forest, coconut, and agriculture. Upon completion of the class hierarchy, fuzzy membership values for the parent and child classes were estimated in gray scale feature view, considering relevant bands of the Landsat TM data set used for each class. Ground-truthing was also performed to substantiate the features defined by the fuzzy limits.
In eCognition, the conditions are defined by expressions that are inserted into the class descriptions. Fuzzy classification is a technique that basically translates feature values of arbitrary range into fuzzy values between 0 and 1; it enables the formulation of complex descriptions by means of logical operations and hierarchical class descriptions (Pradhan et al. 2009). Each class of a classification scheme formulated in eCognition contains a class description. Each class description consists of a set of fuzzy expressions allowing the evaluation of specific features and their logical operation. The output of the system is twofold: a fuzzy classification with detailed information of class mixture and reliability of class assignment, and a final crisp classification where each object is assigned to exactly one class (or none, if no assignment was possible). A fuzzy rule can have one single condition or can consist of a combination of several conditions that have to be fulfilled for an object to be assigned to a class. In eCognition, these conditions are defined by expressions that are inserted into the class descriptions.
For instance, the fuzzy limits for two general classes of the study—water and vegetation were estimated in feature view using Bands 4 and 1, respectively, through expert visualization of gray values (Fig. 5). Water absorbs infrared radiation and therefore Band 4 (near infrared) was selected to separate water from other non-water land features. Band 1 (blue band) was used to differentiate urban and related non-vegetated features from vegetated features as the former would give higher reflectance values (Jensen 1996).

Gray scale feature of Bands 4 and 1
The fuzzy limit for water lies between 0 and 25 mean values of Band 4. Essentially, these limits separate water from non-water features. The limits for vegetation ranges from 26 to 74 mean values of Band 1. The class water is defined by a low-layer mean using one-dimensional membership function by a graphical interface. By one-dimensional membership function, all available knowledge about the relations between features and class assignment can be integrated. The simplest fuzzy rule is to base the class assignment on only one condition, one single fuzzy feature. First, the membership function for the object feature "layer mean" has to be defined for the fuzzy set "low layer mean (LLM)". Then, formulating a fuzzy rule representing the knowledge about the relation between the values of layer mean and the class assignment: if layer mean (object)E LLM, then land cover (object) = water. The fuzzy limits of water and vegetation appear in Fig. 6. In a similar manner, the fuzzy limits for all other classes and sub-classes were determined. These values were then used for class description and fuzzy membership expression.

Fuzzy limits of water and vegetation classes defined by mean values of Bands 4 and 1, respectively
This image object classification was based on fuzzy logic, using single-dimension membership function, to separate two classes—water and non-water (Fig. 7). Through these means, water features were isolated as a parent class before proceeding to the classification of non-water and its related sub-classes. Class-related features only refer to the child classes, when used in relation to respective parent classes in the group hierarchy. The result of this class-related classification is based on fuzzy membership functions of individual child classes (Fig. 8).

Classification layer showing water and non-water classes

Result of classification with segmentation
Classification-based segmentation
The previous classification was based on one image object level of segmentation, which yields image objects of somewhat similar sizes, while different structures in an image are embedded in different resolution scales. Classification-based segmentation was conducted to refine the classification considering the structural element of super and sub-objects, where merging and regrouping were materialized. The resultant layer is shown in Fig. 8.
Result and discussions
As this study is advocating the use of object-oriented–fuzzy classification for land-use cover digital mapping, it will be more realistic that its accuracy be compared to the traditional pixel-based classification. Figure 9 shows the results of pixel-based maximum likelihood supervised classification. In order to make a direct comparison of accuracy assessment between the pixel-based and polygon-based classification results, the accuracy assessment has been carried out in the same environment (Table 2). The program automatically picks out 520 random sample points plus 50 ground-truth points for accuracy assessment. To compare the accuracies of both classification algorithms, confusion matrices were prepared as shown in Tables 3 and 4. Such error matrices are in line with previous works on accuracy assessments (Stehman and Czaplewski 1998).

Pixel-based classification result
Confusion matrix is a simple cross-tabulation of the mapped classes against that observed on the ground or reference sites extracted from the imageries. Obviously, the reference sites should not include areas taken as training samples in the pixel-based classification to eliminate bias in accuracy assessment. The overall accuracy is calculated by dividing the number of correctly classified pixels by the total number of reference and ground pixels. Although it is simple, the overall accuracy has been the most conventional approach in accuracy assessment (Woodcock 2002). An improvement to the overall accuracy assessment is the Kappa coefficient of agreement is computed, which expresses the proportionate reduction in error generated by a classifier compared with the error of a completely random classification. Reference and ground samples were randomly generated, and then the respective informational classes were labeled by referring to the ortho-corrected digital land-use map provided by Department of Agriculture, Malaysia. For this research, 518 reference and ground sites were selected. The results of the accuracy assessments of both image classifications are presented in Tables 3 and 4.
It was found that the accuracy of object-oriented classification is higher than the pixel-based classification. The overall accuracy and Kappa coefficient are significantly higher in the object-oriented classification. Producer and user accuracies also give better results in the object-oriented classification.
The overall accuracy achieved by the object-oriented classification is 87.87%. The kappa coefficient is found to be 0.871 which is high, especially for a classification containing as many as nine types of land-covers. In addition, the object-oriented method significantly narrowed down the variation of class-based accuracies compared with the result of the pixel-based classification method. Further, from the findings of Anderson et al. (1976), it has been reported that the accuracy of interpretation for different categories should be about equal and it is found that object-oriented classification meets this requirement.
Conclusion
The present study has proven that the object-oriented–fuzzy logic classification of land cover/use is superior to the pixel-based classification. In addition, the accuracy of the former has met the requirements of international standards for digital mapping in that its overall accuracy exceeded 85%; Kappa value above 0.85 and accuracy differences among the classes has been kept minimal. The result is testimony of similar studies achieved by some recent studies conducted on a much smaller area, which leads to a conclusion that object-oriented–fuzzy logic classification can be carried out for large-scale mapping of land-use/cover reliably.
References
Anderson JR, Hardy EE, Roach JT, Witmer RE (1976) A land use and land cover classification system for use with remote sensor data. US Geological Survey, Washington, DC
Baatz M, Benz UC, Dehghani S, Heynen M, Höltje A, Hoffmann P, Lingenfelder I, Mimler M, Sohlbach M, Weber M, Wilhauck G (2003) eCognition object oriented image analysis user guide. Definiens, Munchen
Daqamseh ST (2007) Phytobiodiversity mapping using objects oriented analysis. Master Thesis, UPM, Malaysia
Dwivedi RS, Rao BRM (1992) The selection of the best possible Landsat TM band combination for delineating salt-affected soils. Int J Remote Sens 13:2051–2058
Hall GJ, Hay AB, Marceau DJ (2004) Detecting dominant landscape objects through multiple scales: an integration of object-specific methods and watershed segmentation. Landsc Ecol 19(1):59–76
Jensen JR (1996) Introductory digital image processing: a remote sensing perspective, prentice hall. Englewood Cliffs, NJ, USA
Kumar PU (2003) Regional Asia: TCP/RAS/2904 (A) – Towards the development and applications of a multi-purpose environmental and natural resources information base for food security and sustainable development (ASIACOVER) Report of the inception visit to participating countries, mission report, vol. 1 & 2, FAO_UN
Loh KF (2003) Report on land use and natural resources mapping for Malaysia, Asia cover project, FAO_UN
Mausel PW, Krambler WJ, Lee JK (1990) Optimum band selection for supervised classification of multispectral data. Photogramm Eng Remote Sensing 56:55–60
Pradhan B, Saulaiman Z, Samad R (2009) Landcover mapping and spectral analysis using multi sensor satellite data: a case study in Tioman Island, Malaysia. Journal of Geomatics, vol. 3, no. 2 (in press)
Shattri M, Wong TH, Loh KF (2008) Object oriented digital image classification. International Journal for Geo-Informatics 4(3):67–76
Stehman SV, Czaplewski RL (1998) Design and analysis for thematic map accuracy assessment: fundamental principles. Remote Sens Environ 64:331–344
Woodcock CE (2002) Uncertainty in remote sensing. In: Foody GM, Atkinson PM (eds) Uncertainty in remote sensing and GIS. Wiley, New York, pp 19–24
Wong TH, Shattri BM, Mispan MR, Ahmad N, Sulaiman WN (2003) Feature extraction based on object oriented analysis. In: Proceedings of ATC 2003 Conference, 20–21 May 2003, Malaysia
Acknowledgments
The authors would like thank to the Department of Agriculture, Malaysia for providing various datasets used in this study. Special thanks to two anonymous reviewers and editorial comments by Professor Dr. Alessandro Capra which was very helpful during the revision of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License ( https://creativecommons.org/licenses/by-nc/2.0 ), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Al Fugara, A.M., Pradhan, B. & Ahmed Mohamed, T. Improvement of land-use classification using object-oriented and fuzzy logic approach. Appl Geomat 1, 111–120 (2009). https://doi.org/10.1007/s12518-009-0011-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12518-009-0011-3