
Abstract
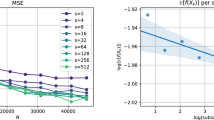
Stochastic gradient Markov chain Monte Carlo (SG-MCMC) has been developed as a flexible family of scalable Bayesian sampling algorithms. However, there has been little theoretical analysis of the impact of minibatch size to the algorithm’s convergence rate. In this paper, we prove that at the beginning of an SG-MCMC algorithm, i.e., under limited computational budget/time, a larger minibatch size leads to a faster decrease of the mean squared error bound. The reason for this is due to the prominent noise in small minibatches when calculating stochastic gradients, motivating the necessity of variance reduction in SG-MCMC for practical use. By borrowing ideas from stochastic optimization, we propose a simple and practical variance-reduction technique for SG-MCMC, that is efficient in both computation and storage. More importantly, we develop the theory to prove that our algorithm induces a faster convergence rate than standard SG-MCMC. A number of large-scale experiments, ranging from Bayesian learning of logistic regression to deep neural networks, validate the theory and demonstrate the superiority of the proposed variance-reduction SG-MCMC framework.
Similar content being viewed by others

References
Gan Z, Chen C Y, Henao R, et al. Scalable deep Poisson factor analysis for topic modeling. In: Proceedings of International Conference on Machine Learning, 2015
Liu C, Zhu J, Song Y. Stochastic gradient geodesic MCMC methods. In: Proceedings of Conference on Neural Information Processing System, 2016
Chen T, Fox E B, Guestrin C. Stochastic gradient Hamiltonian Monte Carlo. In: Proceedings of International Conference on Machine Learning, 2014
Ding N, Fang Y H, Babbush R, et al. Bayesian sampling using stochastic gradient thermostats. In: Proceedings of Conference on Neural Information Processing System, 2014
Şimşekli U, Badeau R, Cemgil A T, et al. Stochastic quasi-Newton Langevin Monte Carlo. In: Proceedings of International Conference on Machine Learning, 2016
Wang Y X, Fienberg S E, Smola A. Privacy for free: posterior sampling and stochastic gradient Monte Carlo. In: Proceedings of International Conference on Machine Learning, 2015
Springenberg J T, Klein A, Falkner S, et al. Bayesian optimization with robust Bayesian neural networks. In: Proceedings of Conference on Neural Information Processing System, 2016
Li C Y, Chen C Y, Carlson D, et al. Preconditioned stochastic gradient Langevin dynamics for deep neural networks. In: Proceedings of AAAI Conference on Artificial Intelligence, 2016
Chen C Y, Ding N, Carin L. On the convergence of stochastic gradient MCMC algorithms with high-order integrators. In: Proceedings of Conference on Neural Information Processing System, 2015
Dubey A, Reddi S J, Póczos B, et al. Variance reduction in stochastic gradient Langevin dynamics. In: Proceedings of Conference on Neural Information Processing System, 2016
Welling M, Teh Y W. Bayesian learning via stochastic gradient Langevin dynamics. In: Proceedings of International Conference on Machine Learning, 2011
Teh Y W, Thiery A H, Vollmer S J. Consistency and fluctuations for stochastic gradient Langevin dynamics. J Mach Learn Res, 2016, 17: 193–225
Vollmer S J, Zygalakis K C, Teh Y W. Exploration of the (Non-)asymptotic bias and variance of stochastic gradient Langevin dynamics. J Mach Learn Res, 2016, 17: 5504–5548
Ma Y A, Chen T Q, Fox E B. A complete recipe for stochastic gradient MCMC. In: Proceedings of International Conference on Machine Learning, 2015
Ghosh A P. Backward and forward equations for diffusion processes. Wiley Encyclopedia of Operations Research and Management Science, 2011. doi: 10.1002/9780470400531.eorms0080
Schmidt M, Le Roux N, Bach F. Minimizing finite sums with the stochastic average gradient. Math Program, 2017, 162: 83–112
Johnson R, Zhang T. Accelerating stochastic gradient descent using predictive variance reduction. In: Proceedings of Conference on Neural Information Processing System, 2013
Reddi S J, Hefny A, Sra S, et al. Stochastic variance reduction for nonconvex optimization. In: Proceedings of International Conference on Machine Learning, 2016
Allen-Zhu Z, Hazan E. Variance reduction for faster non-convex optimization. In: Proceedings of International Conference on Machine Learning, 2016
Chen C Y, Ding N, Li C Y, et al. Stochastic gradient MCMC with stale gradients. In: Proceedings of Conference on Neural Information Processing System, 2016
Schmidt M, Roux N L, Bach F. Minimizing finite sums with the stochastic average gradient. 2013. ArXiv:1309.2388
Zhang L J, Mahdavi M, Jin R. Linear convergence with condition number independent access of full gradients. In: Proceedings of Conference on Neural Information Processing System, 2013
Defazio A, Bach F, Lacoste-Julien S. SAGA: a fast incremental gradient method with support for non-strongly convex composite objectives. In: Proceedings of Conference on Neural Information Processing System, 2014
Reddi S J, Sra S, Póczos B. Fast stochastic methods for nonsmooth nonconvex optimization. In: Proceedings of Conference on Neural Information Processing System, 2016
Allen-Zhu Z, Richtárik P, Qu Z, et al. Even faster accelerated coordinate descent using non-uniform sampling. In: Proceedings of International Conference on Machine Learning, 2016
Reddi S J, Hefny A, Sra S, et al. On variance reduction in stochastic gradient descent and its asynchronous variants. In: Proceedings of Conference on Neural Information Processing System, 2015
Chen Y T, Ghahramani Z. Scalable discrete sampling as a multi-armed bandit problem. In: Proceedings of International Conference on Machine Learning, 2016
Bardenet R, Doucet A, Holmes C. On Markov chain Monte Carlo methods for tall data. J Mach Learn Res, 2017, 18: 1–43
Baker J, Fearnhead P, Fox E B, et al. Control variates for stochastic gradient MCMC. 2017. ArXiv:1706.05439
Chatterji N S, Flammarion N, Ma Y A, et al. On the theory of variance reduction for stochastic gradient Monte Carlo. In: Proceedings of International Conference on Machine Learning, 2018
Zou D F, Xu P, Gu Q Q. Subsampled stochastic variance-reduced gradient Langevin dynamics. In: Proceedings of Conference on Uncertainty in Artificial Intelligence, 2018
Harikandeh R, Ahmed M O, Virani A, et al. Stop wasting my gradients: practical SVRG. In: Proceedings of Conference on Neural Information Processing System, 2015
Frostig R, Ge R, Kakade S M, et al. Competing with the empirical risk minimizer in a single pass. In: Proceedings of Conference on Learning Theory, 2015
Shah V, Asteris M, Kyrillidis A, et al. Trading-off variance and complexity in stochastic gradient descent. 2016. ArXiv:1603.06861
Lei L H, Jordan M I. Less than a single pass: stochastically controlled stochastic gradient method. In: Proceedings of Conference on Neural Information Processing System, 2016
Lian X R, Wang M D, J Liu. Finite-sum composition optimization via variance reduced gradient descent. In: Proceedings of International Conference on Artificial Intelligence and Statistics, 2017
Hernández-Lobato J M, Adams R P. Probabilistic backpropagation for scalable learning of Bayesian neural networks. In: Proceedings of International Conference on Machine Learning, 2015
Blundell C, Cornebise J, Kavukcuoglu K, et al. Weight uncertainty in neural networks. In: Proceedings of International Conference on Machine Learning, 2015
Louizos C, Welling M. Structured and efficient variational deep learning with matrix Gaussian posteriors. In: Proceedings of International Conference on Machine Learning, 2016
He K M, Zhang X Y, Ren S Q, et al. Deep residual learning for image recognition. In: Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, 2016
Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput, 1997, 9: 1735–1780
Merity S, Xiong C M, Bradbury J, et al. Pointer sentinel mixture models. 2016. ArXiv:1609.07843
Zaremba W, Sutskever I, Vinyals O. Recurrent neural network regularization. 2014. ArXiv:1409.2329
Zhang Y Z, Chen C Y, Gan Z, et al. Stochastic gradient monomial Gamma sampler. In: Proceedings of International Conference on Machine Learning, 2017
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Rights and permissions
About this article

Cite this article
Chen, C., Wang, W., Zhang, Y. et al. A convergence analysis for a class of practical variance-reduction stochastic gradient MCMC. Sci. China Inf. Sci. 62, 12101 (2019). https://doi.org/10.1007/s11432-018-9656-y
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11432-018-9656-y