
Abstract
COVID19 pandemic has put the global health emergency response to the test. Providing health and socio-economic justice across communities/regions helps in resilient response. In this study, a Geographic Information Systems-based framework is proposed and demonstrated in the context of public health-related hazards and pandemic response, such as in the face of COVID19. Indicators relevant to health system (HS) and socio-economic conditions (SC) are utilized to compute a response readiness index (RRI). The frequency histograms and the Analysis of Variance approaches are applied to analyze the distribution of response readiness. We further integrate spatial distributional models to explore the geographically-varying patterns of response readiness pinpointing the priority intervention areas in the context of cross-regional health and socio-economic justice. The framework’s application is demonstrated using Pakistan’s most developed and populous province, namely Punjab (districts scale, n = 36), as a case study. The results show that ~ 45% indicators achieve below-average scores (value < 0.61) including four from HS and five from SC. The findings ascertain maximum districts lack health facilities, hospital beds, and health insurance from HS and more than 50% lack communication means and literacy-rates, which are essential in times of emergencies. Our cross-regional assessment shows a north–south spatial heterogeneity with southern Punjab being the most vulnerable to COVID-like situations. Dera Ghazi Khan and Muzaffargarh are identified as the statistically significant hotspots of response incompetency (95% confidence), which is critical. This study has policy implications in the context of decision-making, resource allocation, and strategy formulation on health emergency response (i.e., COVID19) to improve community health resilience.
Similar content being viewed by others


1 Introduction
Building resilient communities in the face of health-related hazards such as COVID-19 is one of the top priorities of national and sub-national government bodies globally, which is also underscored by the United Nations Secretary-General (Djalante et al., 2020). COVID19 has become a global phenomenon as well as a challenge for the leadership due to its rapid human to human transmission as just within two months from its origin, the endemic spread worldwide, resulting in global stresses (Raza et al., 2020; Renzaho, 2020; WHO, 2020). The outbreak has become a matter of public health, economic, and geopolitical-concern for the governments (both national and sub-national), relevant health department, concerned authorities, and policy-making institutions around the world because the disease has potential to infect more 40–70% of the world’s populationFootnote 1 (John Hopkins Dashboard COVID19). As of latest, there are more than 258 million confirmed cases of COVID19 throughout the world, with ~ 5.16 million deaths. Although the major chunk of the confirmed cases belongs to the United States of America (USA), ~ 48 million cases), the case-fatality is higher for Yamen, Peru, Mexico, Sudan, and Ecuador as reported by the John Hopkin’s mortality analysis (https://coronavirus.jhu.edu/data/mortality). While the outbreak of the virus is tamed down in China, it has surged in the rest of the world such as countries like USA, Mexico Italy, Pakistan, India, United Kingdom, Iran, and so on—resulting in shifting of the hotspots of the COVID19 pandemic. This outbreak has most certainly put the health systems of different governments to a test as well as challenging their health emergency response readiness. To this extent, poor health systems, particularly in the developing world coupled with their vulnerable socio-economic status/conditions, can enhance the risk to outbreaks such as COVID19 many folds. This situation calls for an early assessment of health systems as well as socio-economic vulnerability of places to evaluate the readiness, which can progressively inform an effective response (Kruk et al., 2017; OECD, 2021; Rogers et al., 2021). These assessments can further support corrective decision-making and resource allocation in the case of outbreak, which might result in reducing the impacts via equitable health and socio-economic incentives.
In Pakistan—a country ranked by the UNICEF as the riskiest to born in—as of December 31, 2020, there were 482,178 confirmed cases of COVID19 reported in all parts of Pakistan. This includes 144,111 (~ 30%) cases and 4242 deaths (~ 42%) in Punjab, 224,004 cases in Sindh, 18,351 cases in Baluchistan, 60,751 cases in Khyber Pakhtunkhwa provinces, 38,970 cases in Islamabad (capital city), 4879 in Gilgit Baltistan, and 8451 cases in specially administered regions Azad Jammu & Kashmir region.Footnote 2 The virus has resulted in 10,176 deaths so far, but the number of cases is expected to rise many folds as developing countries like Pakistan and India are left blindfolded due to low test rates.Footnote 3 Pakistan has already started to realize the profound effects of COVID19 which has penetrated the economy through public health. In particular, a humongous decline in KSE 100 index from 41,630 on Jan 1st, 2020 to 30,971 indexes by April 8, 2020 was observed.Footnote 4 As a result, federal and provincial governments have started taking aggressive measures to combat the spread through closing down the educational institutions, restaurants, suspending international flights, railways, and other small business throughout the year 2020.
It is important to note that Pakistan has mix health care provisions, which implies the health care system is practically vertical and in part, horizontal (Malik & Bhutta, 2018). In other words, both the public and private sectors are responsible for health care provisioning. The private sector covers 70% of the health care services and the remaining 30% comes from the public sector. Punjani et al. (2014) documented the existing disparity in the context of access to health care in Pakistan and the United States. They conclude that only 27% of the population which primarily consists of government employees, and members of armed forces enjoys publicly provided healthcare, whereas, the remaining 73% relies on out of pocket expenditures in Pakistan. Under such circumstances for a developing country like Pakistan, if socio-economically vulnerable groups are exposed to COVID19, their wellbeing will be undermined due to the non-availability of universal healthcare in combination with their existing deprived conditions. Consequently, the risk associated with such a pandemic for such groups—constituting a bigger chunk of Pakistan’s population—is relatively higher. Ahmad et al. (2020) discuss that if Pakistan does not enhance the testing capacity, the spread of COVID19 is bound to accelerate. They further highlight that optimal response to COVID19 is the early development of the relevant vaccine. Although their work stresses to determine the efficient response, it lacks a theoretical frame. In addition to this, Qureshi et al. (2020) discuss several factors contributing to the outbreak of COVID19 such as animal to human transmission. Thereafter, they argue that since Pakistan is sharing a large border with China there will be many implications for Pakistani travelers. Their claim is instantly validated as earlier we observed the installation of thermal scanners at the airports to determine the COVID19 infection in the travelers and more recently the closure of Pakistan’s air space for two weeks. Thus, they visualize the implication for travelers but without involving the optimal response. Another neighboring country, Iran, has also been a hotspot of the pandemic, which further pressurizes Pakistan. While studies on COVID-related vulnerabilities are being conducted for effective decision-making (Zhai et al., 2021; Zhai & Yue, 2021), such investigations are rare to find in Pakistan. In addition, to date, the readiness of Pakistan to such bio-hazards and pandemics has not been assessed particularly through an integrated health-system-societal-conditions perspective.
In this study, we aim to propose an integrated geographic information systems (GIS)-based framework to combine different health system indicators with socio-economic conditions of communities to assess the vulnerability to COVID19 like health emergency situations. The vulnerability here refers to the likelihood of different communities to be disproportionally in the need for actions and immediate support during an emergency (Sajjad & Chan, 2019; Thekdi & Aven, 2020). The indicator data are collected from several resources to compute a response readiness index (RRI) in a spatial environment using GIS. Due to its ability to deal with multi-dimensional complex data and current effective application to monitor the outbreak of COVID19, GIS is a useful tool for health planning and it acts as an operative decision-support-system aiding risk management (D.V. Chan et al., 2014; Knobel et al., 2019; Kpienbaareh et al., 2019; Sadler et al., 2019; Sajjad, Chan, et al., 2020; Sajjad, Chan, et al., 2020; Sajjad, Lin, et al., 2020). The RRI is a representative measure of competency/incompetency of different regions to deal with COVID19-like health crisis situations based on their health system and socio-economic vulnerability. The proposed framework is applied to the most developed and populous province of Pakistan, namely Punjab (~ 52% population share and 60% national GDP share), as the case study (Fig. 1). It is noted that though it would be ideal to apply the framework to entire Pakistan, at this particularly moment the data is not readily available for all the provinces except Punjab. Despite the data availability, Punjab (having highest COVID19 cases as of April 03, 2020) is the most developed province of Pakistan; thus, it could be used as a benchmark to make comparison with other regions in future. While this preliminary effort will help decision-/policy-making institutions to assess different administrative regions that are comparatively more vulnerable to COVID19 and similar situations, the findings will support resource allocation departments for a timely response during emergencies. The assessments as such can progressively aid in responding to outbreaks through the identification of priority intervention areas, which can enable effectively combating different emergencies with limited resources, driving overall community health resilience enhancement against pandemics and bio-hazards.

Study area map. The inset map shows the location of the study area (Punjab province) in Pakistan
2 Study Design: Material and Methods
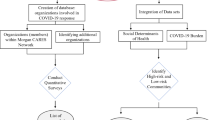
We begin with the establishment of a geospatial data repository to store the collected data. The whole work process is completed in three steps. Firstly, the data on health and socio-economic indicators are collected through screening various provincial and national statistical yearbooks, online data repositories, and government archives. Secondly, the indicators are assessed statistically as well as spatially using different approaches—detailed in the following sub-sections. Lastly, the results are communicated, and discussions are made on the findings for potential implications. The overall schematic of the research work is presented in Fig. 2.

Overall schematic of the study
2.1 Computation of the Response Readiness Index
To assess the response readiness, we start with selecting the potential indicators as it is a critical aspect to compute the index (Cutter & Derakhshan, 2018; Raude et al., 2019). For this purpose, we follow the published work and use a system approach to assess the readiness (Cutter & Derakhshan, 2018; Green et al., 2018; Hu et al., 2017; Sajjad & Chan, 2019). Under this notion, an overall system (i.e., communities or neighborhoods) is composed of several sub-components or sub-systems. These sub-components, also referred to as capitals contribute towards overall functionality of the systems through various means. For example, the health system is driven by a number of factors including the availability and accessibility of medical units (i.e., clinics, hospitals, out-door patient treatment facilities), immunization rates, health insurance coverage, and so on. Similarly, socio-economic capitals are driven by population, education, economic situations, and access to basic amenities such as transportation among many others. In a similar fashion, the readiness of communities to disruptive events such as COVID-19 depends upon several factors primarily including but not limited to the health system and socio-economic conditions (Zhai & Yue, 2021; Zhai et al., 2021). While better health system (HS) and good societal conditions (SC, socio-economic status) can prepare communities well to effectively respond to pandemics such as COVID19, the higher vulnerability and poor health system can put them at higher risk resulting in severe consequences. In this study, two key reasons are taken into consideration for the selection of indicators. First is the availability of most recent data and second is the importance as well as the ability of these indicators to represent the component (i.e., HS and SC). Hence, based on a comprehensive literature review, we initially list the representative indicators within the domains of SC and HS. Later, we use the well-known expert opinion approach to finalize the indicators using the specialized opinion of two specialists in the field (one each from academia and industry). Both of these experts are selected keeping the subject matter in the view (i.e., relevancy to the topic along with expertise in socio-economic evaluations and understanding of health capital within societies). Under this process, we integrate multi-round expert opinion to make mutual agreement for an issue (Alshehri et al., 2014; Hernantes et al., 2019). Using this approach, we finally select 19 most representative different indicators (eight representing the HS and eleven representing the SC capitals) based on their influence on HS and SC (Table 1). The data on these indicators are collected from different resources including Punjab Development Statistics (2018), Multiple Indicator Cluster Survey Punjab 2018, Bureau of Statistics Punjab and Pakistan, screening various provincial and national statistical yearbooks, online data repositories, and government archives.
As the emphasis of our study is quantitative analysis, which focuses on the measurement of data and statistics, it is essential to compare the indicators on the same scale. Due to different measurement units of these indicators, we use a normalization method to make them non-dimensional (Sajjad et al., 2019). This normalization method distributes the indicator values between 0 and 1 making the indicators comparable on the same scale, where values closer to 1 means better situation and vice versa. It is noted that this normalization is made by keeping the positive and negative influence of each indicator towards the overall readiness, where positive influence enhances the readiness and negative influence reduces it. The normalization is made as follows:
where \(I^{\prime}\) is the normalized (non-dimensional) value between 0 and 1, \(x\) the original value, \(x_{\max }\) the maximum value across all the districts for a specific indicator, and \(x_{\min }\) the minimum value.
Using these normalized indicator values, we calculate the overall scores for both HS and SC as:
in which, \({C}_{i}\) is the component score of district\(i\), \(n\) is the number of indicators representing that specific component (in our case, eight for the HS and eleven for the SC components), and \({a}_{(i)}\) is the normalized score of variables for district \(i\),
Later, an overall response readiness index (RRI) is computed for each district (n = 36) via summing the overall scores of the components HS and SC (Cutter et al., 2010). This computation results in RRI for each district ranging between 0 and 2, where the scores closer to 2 represent higher response readiness and scores closer to 0 represent response readiness incompetency of the associated district. It is noted that all the indicators in this study are equally weighted following several existing studies (Green et al., 2018; Sajjad, Chan, et al., 2020; Sajjad, Chan, et al., 2020; Sajjad et al., 2018; Sajjad, Lin, et al., 2020). Given the same weights to avoid any subjectivity related to the computed index, the additive approach is more appropriate as compared to principal components or factor analysis. Additionally, another issue with the component/factor-based approach is that it restricts the potential of indices in terms of decision-making and managerial aspects due to resultant components/factors resulting from a mix of HS and SC indicators (Sajjad, 2021).
2.2 Validating the Computed Index
In order to check whether or not the computed index is a representative of response readiness against pandemics, we run a regression between total observed cases of COVID-19 by each district and the corresponding index value. The data on total number of cases until 31st December 2020 for each district is retrieved from the Health Department, Punjab, Government of Pakistan (www. health.punjab.gov.pk). Due to the spatial nature of data (i.e., districts), we choose the well-known Geographically Weighted Regression (GWR) to analyze the relationship between COVID cases (dependent variable) and the computed index (independent variable). The selection of GWR is primarily based on its straightforward processing as compared to more complicated techniques such as spatial lag regression or spatial error regression methods. Furthermore, Bidanset and Lombard (2014) show that GWR model achieves relatively more uniform results as compared with spatial lag model. Also, as there are only two variables under consideration, we keep the process uncomplicated and simply run the GWR tool in ArcGIS Pro using district polygons as the feature class with the index and cases count appended to corresponding districts in the data table (more details are available at www. pro.arcgis.com).
2.3 Statistical Analysis
To statistically evaluate the computed overall RRI and both components (i.e., HS and SC), we start with analysing the distributions of the scores using histograms and computing the summary statistics including mean, minimum, maximum, standard deviation, skewness, and kurtosis. Later, to compare the means of all the indices (RRI, HS, and SC) across the study area, the one-way Analysis of Variance (ANOVA) approach is used. The ANOVA helps identify if the means of all the indices are statistically significantly different at the confidence of one’s choice (p = 0.05 for this study). To compare the means, the Tukey–Kramer test (also known as Tukey HSD test) is used based on all possible combination pairs (Kramer, 1956; Tukey et al., 1984). The Tukey–Kramer test provides an Honestly Significant Difference (HSD)-Threshold-Matrix expressing if the means are statistically significantly different. Under this condition, the pairs are statistically significantly different if the value for a pair is positive. The null hypothesis (H0) for the ANOVA test is that the means of the indices are similar with no significant difference among the pairs. To perform this analysis, we use the well-known JMP Pro. Software from the SAS Institute (see for details: www.sas.com).
2.4 Spatial Distributional Assessment
To evaluate the geographical heterogeneities in response readiness to bio-hazards and pandemics, we apply spatial information models in ArcGIS to overall RRI and both components (Frigerio et al., 2018; Moghadas et al., 2019; Sajjad, Lin, et al., 2020). Comprehensive maps are produced to communicate the information on RRI, HS, and SC presenting overall geographical patterns in the study area. In addition to this, the Local Indicators of Spatial Autocorrelation (LISA) is applied to analyse localized patterning in the data, if any. LISA is a well-known and widely applied approach to identify any localized statistically significant (p = 0.05, CI = 95%) clustering of high values (hot-spots represented by High-High clusters), low values (cold-spot represented by Low-Low clusters), and spatial outliers (represented by High-low and Low–High clusters) in space. However, it is noted that before applying LISA, we perform a global analysis using Moran’s I to check and justify the global spatial relationship between the units. The LISA is applied once the global spatial association is confirmed. The LISA model is provided as,
where \({x}\) represents the scores of each district, \(i\) the candidate district for which \({I}_{Local}\) is being calculated, \(j\) different neighboring districts, \(\overline{x }\) the average score over all the districts, n the total number of districts (n = 36), \({w}_{ij}\) the spatial weight matrix, and \({S}^{2}\) the variance in the sample calculated as:
in which, the parameters are the same as Eq. 4. The weight matrix \({w}_{ij}\) defines a neighbourhood for each district, which is further used for the spatial autocorrelation measurements. The elements in the weight matrix are calculated as:
where \({C}_{ij}\) is equal to 1 when the district \(i\) is within the defined neighbourhood to district \(j\) and 0 when it is not.
There are two different techniques that are commonly used to identify the weight matrix. The first one is a distance-based spatial matrix and is used if the spatial data is in vector-points (e.g., buildings, accidents, crime locations and so on). Whereas, the other technique is the contiguity-based weight matrix used in the situations where the data is in the form of vector-polygons (ESRI, 2016). These polygons could be regular (i.e., grids) or irregular (i.e., administrative boundaries). Similarly, the contiguity-based approach could either be a rook contiguity—sharing boundary should be of some length—or a first-order queen contiguity—smaller lengths of boundary sharing is also considered (Frigerio & DeAmicis, 2016; Pagliacci, 2020). Because the administrative boundaries of spatial units could have a large difference in size—allowing all the units to have at least one neighbor—the first-order queen contiguity is more appropriate, which is also well-practiced in the literature (Sajjad, Chan, et al., 2020; Sajjad, Chan, et al., 2020; Sajjad, Lin, et al., 2020). As our data is in the administrative boundaries of the districts (vector-polygons), we, in this study, use the contiguity-based weight matrix as the spatial neighborhood under this scheme is defined based on sharing boundaries of polygons—administrative regions. To bind the results between -1 and 1 and to assign equal weights during the computation, we use the row-standardization (Cutter et al., 2014; Sajjad et al., Sajjad, Lin, et al., 2020; Zou et al., 2018). The application of LISA provides a broader range of information on the hotspots of comparatively highly vulnerable regions. This information can provide a focus-for-action to decision-makers in the study area helping the prioritization process for immediate or long-term measures.
Furthermore, we use the machine-learning-based spatial Multivariate Clustering Analysis approach to catalogue the districts into statistically distinct spatial groups. This method is based on the unsupervised machine-learning algorithms, which identifies different natural clusters (statistically distinct) in the data—RRI, HS, and SC scores in this study (Duda et al., 2000; Jain, 2010; Sajjad et al., Sajjad, Lin, et al., 2020). As the method is an unsupervised clustering technique, no pre-classified feature set is required for training purposes in order to capture the spatial clusters. The frequency of clusters is based on the well-recognized Calinski-Harabasz pseudo-F-statistic, which reduces the subjectivity and the likelihood of pre-judging the number of cluster providing more reliable clusters information (Caliñski & Harabasz, 1974). Using the optimal cluster frequency from the pseudo-F-statistic, the algorithm seeks a solution where the within-cluster features are as similar as possible, whereas, all the significantly distinct groups (clusters) are as different as possible based on the values and locations of the provided attribute set. We apply this method to analyse the spatial clusters based on the overall RII, HS, and SC scores in the study area. This multivariate approach is not only helpful to explore the drivers of less or high readiness, but also provides spatial references to the districts grouped in a specific distinct cluster, showing the distribution across the study region.
3 Results
3.1 Statistical Analysis: Descriptive Statistics and Stylized Facts
The descriptive statistics and overall distribution of the final scores regarding RRI, HS, and SC are presented in Fig. 3. In particular, to the mean values of HS and SC presented in the table (0.52 \(\pm\) 0.11 std. dev. and 0.67 with \(\pm\) 0.12 std. dev., respectively), we observe that the SC in the province out-performed the HS in a broader perspective, also evident from the box-plots. The results show that ~ 40% of districts achieve-below average scores for the HS and SC components (Fig. 3a and b). On the other hand, ~ 50% of districts achieve below-average scores regarding RRI (Fig. 3c). Hence, it is evident that while no district achieve the highest possible score (out of 1 for HS and SC and out of 2 for RRI), most of the districts in the study area achieve below average HS, SC, and RRI scores, which indicate the overall critical situation. Furthermore, although the non-symmetric behaviors are observed in all the distributions, the SC component shows the largest skewness as compared to HS and RRI. However, this non-symmetric behavior could very well be the result of the presence of the smaller values on the lower-tail of the distribution (i.e., 3% values for the scores between 0.35 and 0.55, Fig. 3b). The similar behavior is also observed for overall RRI, representing presence of higher incompetency of the districts.

Distribution of the scores for all the indices: a HS, b SC, and c overall RRI. The diamond in the box-plot is the mean value whereas, the bar inside the box-plot represents the median value over all the districts (n = 36). The red bracket above the box-plot shows the shortest half presenting the densest (50%) of the data values. The table presents the summary statistics
The results from the ANOVA show that the variance among the means of HS, SC, and RRI is more than expected to observe by chance, leading to reject the null-hypothesis that the means are similar (R-squared = 0.79), which is also evident from the larger F-ratio (201.91), see Table 2. The Tukey–Kramer test further complements this result as the values of the pairs-of-means are positive (95% confidence). The difference between both components (i.e., HS and SC) is found to be 0.07. In short, though the mean scores for both components are close to each other (summary statistic in Fig. 3), their means are statistically significantly different from each other (95% confidence, Table 2) as revealed by the ANOVA analysis.
3.2 Indicator Performance Evaluation
It is important to note that the overall performance of ~ 45% indicators is below average (0. 61, averaged over 36 districts and 19 indicators), see Fig. 4. These 45% indicators include four from the HS and five from the SC components. From the HS component, the lowest-performing indicators (scores < 0.61) include HS1, 2, 4, and 6. Contrarily, SC3, 4, 6, 10, and 11 perform comparatively lower from the SC component (scores < 0.61).

Overall indicator performance evaluation. The scores are the normalized values for each indicator where 0 and 1 are the minimum and maximum, respectively. The arrangement of indicators is based on the scores—making it easy to identify relatively low performing indicators among all. The green shade is the achieved score, whereas, the red shade is the average calculated over all the indicators across the study area (value 0.61). The shaded arrow represents the performance reference where red represents low performance and green represents high performance
This indicators level performance can further be segmented at the district-level to provide a comprehensive piece of information to concerned authorities. Figure 5 details the indicator performance for each district through the heat-map table. The cells highlighted in red—clustered at the right-side of the table—are the ones whose performance is low and need to be prioritized in action plans. For example, most of the districts show low performance for the indicators HS6, HS2, and HS1 representing health insurance, availability of hospital beds, and health facilities, respectively, in the districts. Therefore, these factors are related to public health and should be prioritized throughout Punjab province in order to enhance the overall response readiness. Otherwise, these districts may experience severe impacts in case they are exposed to bio-hazards and pandemics. Similarly, most of the districts (> 50%) lack in SC4, SC3, and SC6 from the SC component representing access to the internet, literacy rate, and access to the mobile phone, respectively.

Heat-map representing the individual indicator score for each district. The results here are presented after applying a clustering method using Euclidean distance to find the similarity between the score of different indicators. The red color represents the lower score achieved by the regions, and green color represents higher scores achieved by the regions. The dendrograms represent the distance/dissimilarity between clusters. Note that the scores are normalized using min‐max scaling method. The data used here is for the year 2018. The indicators are placed at the x-axis and the districts are at the y-axis
3.3 Geographical Profiling and Spatial Statistical Assessment for Hotspots Identification
To help understand the varying geographical disparities in response readiness among the districts and for the sake of effective results communication, maps are prepared for all the indices (i.e., HS, SC, and RRI), see Fig. 6. Based on the results of the spatial distribution, the entire study area can be easily demarcated in three parts such as northern, central, and southern, showing higher (value > 0.5 std. dev.), intermediate (value 0.5 std. dev.), and low performance (value < 0.5 std. dev.) regarding all the indices, respectively. Notably, the results reveal that the developed districts such as Lahore and Faisalabad stand out in terms of relatively least vulnerability towards COVID19-like situations (relatively high response readiness), which is reasonable given that the cities are large economic hubs in Pakistan after Karachi. On the other hand, bio-hazards and pandemics might cause serious impacts in the districts of southern Punjab such as Rajanpur, Dera Ghazi Khan, Rahim Yar Khan, and Khushab given their bad situation (values < 0.5 std. dev.) in terms of both HS and SC, and consequently the overall response readiness (values < 1.5 std. dev.).

Geographic distribution of the scores for all the indices including (a) HS, b SC, and c overall RRI, and LISA-based statistically significant clustering for (d) HS, e SC, and f overall RRI. The results in the maps a, b, and c are presented as 1 standard deviation showing how the values vary from the mean. The green shades represent higher performance (higher scores) and red represents low performance indicating comparatively higher vulnerability
Based on the global autocorrelation analysis based on Moran’s I, it is observed that all the indices (i.e., HS, SC, and Overall RRI) have spatial association. The values of Moran’s Index for HS, SC, and RRI are computed as 0.11, 0.65, and 0.50, respectively (p < 0.001)—z-scores 1.4, 6.5, and 5.1, respectively. This reflects that the highest global spatial association is observed for SC followed by RRI and HS. Furthermore, the results from the LISA analysis also show that the clusters of higher values for HS, SC, and RRI are found in the northern regions (Fig. 4d, e, and f, respectively, 95% confidence). Despite all the hotspots (clusters of the districts with low performance) are identified in the southern regions of the study area, the number of districts identified as the statistically significant hotspots for the HS component is much lower (three districts including Dera Ghazi Khan, Layyah, and Muzaffargarh: spatial IDs 7, 18, and 23 respectively) than the SC component (five districts including Bahawalpur, Dera Ghazi Khan, Muzaffargarh, Rahim Yar Khan, and Rajanpur: spatial IDs 3, 7, 23, 28, and 29, respectively) and the overall RRI (6 districts including Bahawalpur, Dera Ghazi Khan, Layyah, Muzaffargarh, Rahim Yar Khan, and Rajanpur).
The information about these clusters helps to understand the geographic region where districts are least or well equipped to deal with bio-hazards such as COVID19. As we look at the low-low region in red which is also statistically significant with a 95% confidence level. In a nutshell, it is noteworthy to realize that entire southern Punjab is vulnerable to bio-hazards and pandemics such as COVID19 in the context of a health system, societal conditions and consequently lacks in overall response readiness. On the other hand, northern Punjab seems relatively better equipped to effectively respond to such emergencies.
3.4 Multivariate Spatial Clustering Analysis
We apply the machine-learning-based multivariate clustering analysis to the two components (i.e., HS and SC) and the overall RRI. The results show that the overall study area can be grouped in three statistically distinct spatial groups (p = 0.05) having maximum within-group similarity and intra-group disparity (Fig. 7). These groups can be evaluated regarding overall response readiness given as highest readiness (RRI value > 3rd quartile), intermediate level (mid-range) of readiness (1st quartile < values < 3rd quartile), and lowest readiness (value < 1st quartile). These groups are color-coded as red, blue, and green representing lowest, intermediate, and highest response readiness, respectively. The red group (cluster ID 3) lacks in both components (i.e., HS and SC) with the situation of SC worse than HS. This most vulnerable group comprises ~ 20% districts belonging to the southern Punjab region. Contrarily, the SC situation of the blue group (cluster ID 2, ~ 40% districts from central Punjab) out-performs the HS. The green group (cluster ID 1, ~ 40% districts from northern Punjab) performs well in both HS and SC consequently showing relatively batter response readiness as compared to clusters 2, and 3. Notably, one district from the southern Punjab region (Multan, code 22, 7th largest city in Pakistan) is also grouped in cluster 1 (95% confidence).

Results from the Multivariate Spatial Clustering analysis (p = 0.05). a box-plot summarizing the statistically distinct spatial groups from the multivariate spatial grouping analysis. The standardized values are the average scores for each variable for all the districts indicated in the specific group. b bar-graphs showing the frequency of features (in this case districts) for each cluster. c map showing the geographical distribution of the statistically distinct spatial groups based on the HS, SC, and RRI
3.5 Validating the Response Readiness Index
One important question that might arise is where or not the computed response readiness index (RRI) and its spatial disparities are correlated with the observed cases of a pandemics such as the COVID-19. The results from the GWR analysis show a strong relation between the observed numbers of COVID cases and RRI. The GWR tool in ArcGIS Pro. provides three key measures including percent deviance explained by: (a) the global model (a non-spatial relationship assessment), (b) local model to analyze the performance of local model inclusive of spatial aspects, and (c) a comparison of global and local models (i.e., comparing the performance of global Generalized Linear Regression and local Geographically Weighted Regression). This percent deviance is a measure of goodness-of-fit and the values of measure vary between 0.0 and 1.0, where values closer to 1 indicate a model performing better. In the comparison of global and local models, the measuring value closer to 1.0 signifies that the performance of local model is better than global model. The analysis of the relationship between RRI and observed COVID cases till December 31, 2020 results into goodness-of-fit values of 0.36, 0.97, and 0.96 for global model, local model, and global vs local, respectively. The distributions of independent variable and local R-squared are represented in Fig. 8a and b, respectively. It is noticed that while the model performs relatively better (R2 values > 0.90) in the northern areas (districts in our case) having comparatively higher number of COVID-19 cases (Fig. 8b), the performance for southern areas is also reasonable (minimum R2 value 0.57)—see Fig. 8a. This situation indicates that the model is able to comprehend > 55% variance even in the low performing areas. Furthermore, it is evident that while the local GWR model results into a strong geographic relationship among RRI and COVID cases, its performance is way better than the GLR, which do not account for the spatial aspects of a variable. Hence, not only the computed RRI is a reliable measure to make cross-regional comparison of societal conditions and health system, it is a representative composite index and can provide important references for informed decisions and policy to build resilient communities.

Independent variable distribution (a) and local R-squared distribution (b) across the study area
In order to check which sub-component among HS and SC is more related to the COVID cases in a spatial context, we also modelled the relationship between district-scale COVID cases and individual sub-component values. It is observed that the goodness-of-fit measure for HS and SC are 0.97 and 0.99, respectively according to GWR. Similarly, these goodness-of-fit values based on non-spatial model (GLR) are 0.83 and 0.35, respectively. Hence, it is evident that the HS is more related to COVID cases as compared to SC, which is also a general observation as health facilities are more integral to cope with the pandemic/emergency situations.
4 Discussion
The year 2020, which was meant to be a “super year” in the context of sustainability through global collaborations, consolidated actions, and fast-tracking transformations essential to achieve the 2030 agenda, became a struggling year to respond to COVID19 (Djalante et al., 2020; UN, 2020). Public health improvements and equitable provisioning of socio-economic resources is considered one of the significant pre-requisites to reduce the incidence of COVID19 and associated mortality (Talic et al., 2021). In this context and in the face of worsening impacts of COVID19, this study proposes the integration of health system indicators and societal conditions (represented by socio-economic vulnerability) to inform a resilient response to such pandemics and associated bio-hazards. A robust and practical integrated framework is put forward to analyze the competency/incompetency of different regions using sound statistical and spatial distributional models in a GIS environment. Rather than focusing on the health system only (Alameddine et al., 2019; O’Sullivan et al., 2013; Rogers et al., 2021), the proposed framework also considers the socio-economic vulnerability providing a multi-dimensional perspective on community health resilience management. Through the application of the proposed framework to Punjab, Pakistan, this study provides a baseline to make comparisons with other regions in Pakistan and beyond. The findings from this study will provide important references for resource allocation enabling a timely response during emergencies.
The results presented here are of particular interest to decision-makers and professionals in the field of health emergency response, community health planning, and administrative bodies. For example, the indicator performance results have useful implications to provide a focus-for-action in the context of devising appropriate actions. In particular to HS, overall Punjab needs aggressive measures to improve the low-performing indicators such as health facilities, the number of beds, and health insurance, which are all key to emergency response not only in times of pandemics but also during other disasters such as floods and earthquakes (Banwell et al., 2018; Stephanie Seneff, 2016). Similarly, despite its relatively better performance as compared with HS (Fig. 3), most of the below-average indicators belong to the SC component (Fig. 4), which is considered a significant pillar of overall community resilience to tackle uncertainties(Sajjad, 2021). Therefore, this sector also needs reasonable efforts to strengthen district health resilience.
While on the COVID19 is considered as a “great equalizer”, but, in reality, segregated communities in terms of socio-economic and health facilities bear a disproportionate burden (Zhai et al., 2021). To mitigate such segregation, this study provides spatial heterogeneities in both, societal conditions and provisioning of health facilities, aspects—highlighting the inequity among different regions. The evident spatial disparities estimated in this study are in line with other studies such as Texas (Kiaghadi et al., 2020) and Brazil (Campos et al., 2021). For example, our results from spatial analysis reveal that Dera Ghazi Khan and Muzaffargarh the statistically significant hotspots (high incompetency) in the context of all three indices (i.e., HS, SC, and RRI), see Fig. 6. This situation discloses that due to poor health systems intertwined with vulnerable societal conditions, these districts might be the most at-risk to bio-hazards and pandemics such as the current COVID19 outbreak if exposed. Therefore, since the majority of the districts in northern and some from the central parts of Punjab are relatively better prepared, thus, the efforts should be more focused on the southern areas to improve the response readiness of the districts, particularly the hotspots (Fig. 6d, e, and f).
Building health resilience in the face of looming uncertainties such as COVID19 requires measuring the critical capacities of societies ahead of crisis (Kruk et al., 2017). After the Ebola epidemic in 2014, millions of dollars were invested to drive the global progress on the millennium Development Goals. Despite this, health systems remained week in the face of COVID19 and were not able to cope with the situation (Ezeamama et al., 2016; Petherick, 2015; Talic et al., 2021). Hence, supporting socio-economic resilience building and better health systems development through integrated approaches are desirable to resist, withstand, and cope with such emergencies at local and national levels (Lancet, 2014; Zhai & Yue, 2021). The proposed framework provides heuristics to effectively direct the efforts to enhance community health resilience, which can further support achieving sustainable development goals, particularly SDG-3 (good health and well-being). The proposed poor health system and socially-vulnerable centric approach not only provides opportunities to improve the health emergency response, but also helps building resilient communities in the wake of disasters, which is also stressed by the 2015–2030 Sendai Framework for Disaster Risk Reduction and SDG-13, which stresses strengthening community disaster resilience through local actions (Aitsi-Selmi et al., 2015; Kelman, 2015; Sajjad & Chan, 2019). The approach provides a road-map to develop comprehensive health system resilience indices not only considering the health systems but also the socio-economic conditions of societies as well (Kruk et al., 2017; Talic et al., 2021)—providing a more holistic overview.
4.1 Policy Implications
As the world is recognizing that it is Imperative to strengthen information sharing, and health-related humanitarian issues to cope with the looming under certainties related to health, Pakistan lacks way behind in this regard as Pakistan spends ~ 2.8% of its GDP on health expenditure compared to 17.1% for the US and 8.9% for Italy (Agrawal, 2020; Malik & Bhutta, 2018; Scott et al., 2020). Currently, the large urban centers such as Lahore, Faisalabad, and Multan (Fig. 1) receive about 70% of Pakistan’s total health sector allocation, leaving a very insignificant proportion for smaller regions such as southern Punjab Region (Pakistan, 2018). This could very well be the reason behind poor response readiness in districts such as Dera Ghazi Khan, and Muzaffargarh (statistically significant hotspots of incompetency, 95% confidence). In Pakistan, currently, no effective pre-planned pandemic response policy exists and the country has imposed emergency measures related to COVID19 including quarantine, social distancing, and travel restrictions, which are equally being practiced in other countries globally (Kraemer et al., 2020). Similarly, the National Action Plan for Corona virus disease (COVID19) Pakistan (National Institute of Health, 2020) is exclusive of socio-economic vulnerability, which could further increase the impacts on vulnerable districts (i.e., hotspots). The evaluation of response readiness based on the health system and societal conditions such as this study, is helpful in the formulation of response policy. The earlier integration of such information in pandemic response would have better prepared Pakistan than making it up as we go along. The results can also act as a heuristic to design long-term investment plans in the context of health services and socio-economic justice across districts improving their overall resilience to respond to COVID19-like emergencies (Legido-Quigley et al., 2020).
The information on geographical variations such as presented in this study is particularly useful for researchers and policymakers to design appropriate interventions in the context of health and wellbeing (McLafferty et al., 2020). For example, the policy institutions in Punjab should priorities the most vulnerable districts (Fig. 6) in policymaking. For instance, the higher budgetary allocation can remove critical problems, such as more beds could be provided, practical initiatives for better health coverage, more doctors, hospital or dispensaries. Likewise, for socio-economic indicators, the provincial government may look further into the literacy rate of these districts since after the 18th constitutional amendment education is a responsibility of the provincial government. Besides, in addition to other low performing indicators, dependency ratio and access to the internet are a pressing issue in Southern Punjab. Perhaps these are long-term objectives, but again, this area can be further improved with proper resource allocation. Similarly, the multivariate clustering from machine learning-based approach is useful to prioritize regions with least response readiness. The analysis further explores that major reason behind this lower readiness is the lowest performance of SC domain. The locations of the least ready cluster in the southern areas and the cluster with higher readiness in the northern region of the study area depicts a clear inequity among the HS and SC related resources. Combining these results with LISA and indicator-level (Figs. 4, 5 and 6) progressively highlights the areas where the concerned authorities should focus more. Consequently, it should be the matter of policy to enhance community health resilience through prioritizing the low performing indicators (i.e., number of beds per thousand, health facilities, and health insurance) and vulnerable districts particularly the hotspots of response incompetency. The studies as such can progressively act as a reference for these policies.
4.2 Limitations and the Way-Forward
The authors do acknowledge the current limitations of this primary effort. First of all, due to the unavailability of the data on several health system indicators (e.g., the availability of ventilators, which is very important in current scenario), we had to rely on the information available and made the best use of it as highlighted by Hu et al. (2017). However, the primary focus of this study is to put forward an integrated framework and demonstrate its application to inform pandemic response, which is well served. Based on the availability of data, future studies might consider including other potential indicators, if needed. For example, the accessibility to health service providers can also be accounted for in the assessment, which is an important indicator of community health resilience (Green et al., 2018). However, this might require additional data (e.g., road infrastructure and transportation system) in the area of interest, higher computational power, and technical capabilities when applied to large-scales such as this study. Likewise, the proposed approach could also be used to monitor the temporal fluctuations in the response readiness via a pre- and post-event assessment—subjective to data availability. This temporal assessment can also help evaluate the policy effectiveness. Given the deprived conditions of both health system and societal conditions in Pakistan like many developing countries, the indicators from both components are weighted equally, following existing literature. Future researchers might use different weights depending upon the situation. Similarly, the proposed approach and results are useful to risk assessment in Pakistan once the data on COVID19 hazard becomes available using the Risk = hazard x vulnerability model (Chan & Shaw, 2020; Lo et al., 2017).
5 Conclusions
In this study, we integrate health system and socio-economic vulnerability indicators to inform a resilient response to bio-hazards and pandemics such as COVID19 against which the entire world is currently struggling to cope. This study is an initial effort to couple the health system and societal conditions to determine the vulnerability to COVID19 like situations. Using the data on representative indicators from multiple repositories, well-known statistical and spatial information models are applied to the constructed indices to facilitate the cross-regional health and socio-economic justice. District-wise-mapping is performed to detect spatial patterning in response readiness and to identify the priority intervention areas for a rapid or gradual response. Our calculations from spatial analysis confirm that the districts in southern Punjab are extremely vulnerable to bio-hazards and pandemics (e.g., COVID19) due to the underprivileged health system and deprived socio-economic conditions—suggesting the need of appropriate actions on a priority basis. The results from the multivariate analysis are robust since they reveal 7 districts are highly vulnerable to circumstances like COVID19 and the cluster of those districts belongs to Southern Punjab. Finally, the proposed framework is equally applicable to other regions across the globe, with a reasonable effort, regardless of the scale of the study.
References
ADB. (2013). Ensuring a disaster-resistant future investing in resilience: ensuring a disaster-resistant future. Retrieved from www.adb.org
Agrawal, R. (2020). A Coronavirus Disaster Is Looming in South Asia, Even as India Locks Down. Retrieved from https://foreignpolicy.com/2020/03/24/south-asia-looming-disaster-coronavirus-india-pakistan-lockdown-public-health-crisis/
Ahmad, T., Khan, M., Khan, F. M., & Hui, J. (2020). Are we ready for the new fatal Coronavirus: Scenario of Pakistan? Human Vaccines & Immunotherapeutics, 16(3), 736–738. https://doi.org/10.1080/21645515.2020.1724000
Aitsi-Selmi, A., Egawa, S., Sasaki, H., Wannous, C., & Murray, V. (2015). The Sendai framework for disaster risk reduction: Renewing the global commitment to people’s resilience, health, and well-being. International Journal of Disaster Risk Science, 6(2), 164–176. https://doi.org/10.1007/s13753-015-0050-9
Alameddine, M., Fouad, F. M., Diaconu, K., Jamal, Z., Lough, G., Witter, S., & Ager, A. (2019). Resilience capacities of health systems: Accommodating the needs of Palestinian refugees from Syria. Social Science and Medicine, 220, 22–30. https://doi.org/10.1016/j.socscimed.2018.10.018
Alshehri, S. A., Rezgui, Y., & Li, H. (2014). Delphi-based consensus study into a framework of community resilience to disaster. Natural Hazards, 75(3), 2221–2245. https://doi.org/10.1007/s11069-014-1423-x
Arouri, M., Nguyen, C., & Youssef, A. B. (2015). Natural disasters, household welfare, and resilience: Evidence from Rural Vietnam. World Development, 70, 59–77. https://doi.org/10.1016/j.worlddev.2014.12.017
Ayyub, B. M. (2015). Practical resilience metrics for planning, design, and decision making. ASCE-ASME Journal of Risk and Uncertainty in Engineering Systems, Part a: Civil Engineering, 1(3), 04015008. https://doi.org/10.1061/AJRUA6.0000826
Banwell, N., Rutherford, S., Mackey, B., Street, R., & Chu, C. (2018). Commonalities between disaster and climate change risks for health: A theoretical framework. International Journal of Environmental Research and Public Health, 15(3), 538. https://doi.org/10.3390/ijerph15030538
Bhandari, S., & Alonge, O. (2020). Measuring the resilience of health systems in low- and middle-income countries: A focus on community resilience. Health Research Policy and Systems, 18(1), 81. https://doi.org/10.1186/s12961-020-00594-w
Bidanset, P. E., & Lombard, J. R. (2014). A Comparison of geographically weighted regression and the spatial lag model. Cityscape, 16(3), 169–182.
Burke, S., Thomas, S., Barry, S., & Keegan, C. (2014). Indicators of health system coverage and activity in Ireland during the economic crisis 2008–2014 – from ‘more with less’ to ‘less with less.’ Health Policy, 117(3), 275–278. https://doi.org/10.1016/j.healthpol.2014.07.001
Caliñski, T., & Harabasz, J. (1974). A dendrite method foe cluster analysis. Communications in Statistics, 3(1), 1–27. https://doi.org/10.1080/03610927408827101
Campos, I. S., Aratani, V. F., Cabral, K. B., Limongi, J. E., &Oliveira, S. V.de. (2021). A vulnerability analysis for the management of and response to the COVID-19 epidemic in the second most populous state in Brazil . Frontiers in Public Health. Retrieved from https://www.frontiersin.org/article/https://doi.org/10.3389/fpubh.2021.586670
Chan, D. V., Helfrich, C. A., Hursh, N. C., Sally Rogers, E., & Gopal, S. (2014). Measuring community integration using geographic information systems (GIS) and participatory mapping for people who were once homeless. Health and Place, 27, 92–101. https://doi.org/10.1016/j.healthplace.2013.12.011
Chan, E. Y. Y., & Shaw, R. (2020). Overview of Health-EDRM and health issues in DRR: Practices and challenges (pp. 1–6). Springer.
Cremades, R., Surminski, S., Máñez Costa, M., Hudson, P., Shrivastava, P., & Gascoigne, J. (2018). Using the adaptive cycle in climate-risk insurance to design resilient futures. Nature Climate Change, 8, 4–7. https://doi.org/10.1038/s41558-017-0044-2
Cutter, S. L., & Derakhshan, S. (2018). Temporal and spatial change in disaster resilience in US counties, 2010–2015. Environmental Hazards. https://doi.org/10.1080/17477891.2018.1511405
Cutter, S. L., & Finch, C. (2008). Temporal and spatial changes in social vulnerability to natural hazards. Proceedings of the National Academy of Sciences of the United States of America, 105(7), 2301–2306. https://doi.org/10.1073/pnas.0710375105
Cutter, S. L., Burton, C. G., & Emrich, C. T. (2010). Disaster resilience indicators for benchmarking baseline conditions. Journal of Homeland Security and Emergency Management. https://doi.org/10.2202/1547-7355.1732
Cutter, S. L., Ash, K. D., & Emrich, C. T. (2014). The geographies of community disaster resilience. Global Environmental Change, 29, 65–77. https://doi.org/10.1016/J.GLOENVCHA.2014.08.005
Das, S., & DSouza, N. M. (2020). Identifying the local factors of resilience during cyclone Hudhud and Phailin on the east coast of India. Ambio, 49(4), 950–961. https://doi.org/10.1007/s13280-019-01241-7
Djalante, R., Shaw, R., & DeWit, A. (2020). Building resilience against biological hazards and pandemics: COVID-19 and its implications for the Sendai Framework. Progress in Disaster Science, 6, 100080. https://doi.org/10.1016/j.pdisas.2020.100080
Duda, R. O., Hart, P. E., & Stork, D. G. (2000). Pattern classification (2nd ed.). Wiley-Interscience.
ESRI. (2016). An Overview of the Spatial Statistics Toolbox. ArcGIS 10.5 Online Help System. (ArcGIS 10.5 Desktop, Release 10.5, 2016). Environmental Systems Research Institute, Redlands, CA.
Ezeamama, A. E., Elkins, J., Simpson, C., Smith, S. L., Allegra, J. C., & Miles, T. P. (2016). Indicators of resilience and healthcare outcomes: Findings from the 2010 health and retirement survey. Quality of Life Research, 25(4), 1007–1015. https://doi.org/10.1007/s11136-015-1144-y
Fahlberg, A., Vicino, T. J., Fernandes, R., & Potiguara, V. (2020). Confronting chronic shocks: Social resilience in Rio de Janeiro’s poor neighborhoods. Cities, 99, 102623. https://doi.org/10.1016/j.cities.2020.102623
Frigerio, I., & DeAmicis, M. (2016). Mapping social vulnerability to natural hazards in Italy: A suitable tool for risk mitigation strategies. Environmental Science & Policy, 63, 187–196. https://doi.org/10.1016/J.ENVSCI.2016.06.001
Frigerio, I., Carnelli, F., Cabinio, M., & Amicis, M. D. (2018). Spatiotemporal pattern of social vulnerability in Italy. International Journal of Disaster Risk Science. https://doi.org/10.1007/s13753-018-0168-7
Gillespie-Marthaler, L., Nelson, K., Baroud, H., & Abkowitz, M. (2019). Selecting indicators for assessing community sustainable resilience. Risk Analysis, 39(11), 2479–2498. https://doi.org/10.1111/risa.13344
Green, M. A., Daras, K., Davies, A., Barr, B., & Singleton, A. (2018). Health & place developing an openly accessible multi-dimensional small area index of ‘ access to healthy assets and hazards ’ for Great Britain, 2016. Health & Place, 54, 11–19. https://doi.org/10.1016/j.healthplace.2018.08.019
Hajra, R., Szabo, S., Tessler, Z., Ghosh, T., Matthews, Z., & Foufoula-Georgiou, E. (2017). Unravelling the association between the impact of natural hazards and household poverty: Evidence from the Indian Sundarban delta. Sustainability Science, 12(3), 453–464. https://doi.org/10.1007/s11625-016-0420-2
Hernantes, J., Maraña, P., Gimenez, R., Sarriegi, J. M., & Labaka, L. (2019). Towards resilient cities: A maturity model for operationalizing resilience. Cities, 84, 96–103. https://doi.org/10.1016/j.cities.2018.07.010
Hu, H., Galea, S., Rosella, L., & Henry, D. (2017). Big data and population health: Focusing on the health impacts of the social, physical, and economic environment. Epidemiology, 28(6), 759–761. https://doi.org/10.1097/EDE.0000000000000711
Jain, A. K. (2010). Data clustering: 50 years beyond K-means. Pattern Recognition Letters, 31(8), 651–666. https://doi.org/10.1016/J.PATREC.2009.09.011
Johannessen, Å., Rosemarin, A., Thomalla, F., Gerger Swartling, Å., Axel Stenström, T., & Vulturius, G. (2014). Strategies for building resilience to hazards in water, sanitation and hygiene (WASH) systems: The role of public private partnerships. International Journal of Disaster Risk Reduction, 10, 102–115. https://doi.org/10.1016/j.ijdrr.2014.07.002
Jones, L., & d’Errico, M. (2019). Whose resilience matters? Like-for-like comparison of objective and subjective evaluations of resilience. World Development, 124, 104632. https://doi.org/10.1016/j.worlddev.2019.104632
Kelman, I. (2015). Climate change and the Sendai framework for disaster risk reduction. International Journal of Disaster Risk Science, 6, 117–127. https://doi.org/10.1007/s13753-015-0046-5LB-Kelman2015
Kiaghadi, A., Rifai, H. S., & Liaw, W. (2020). Assessing COVID-19 risk, vulnerability and infection prevalence in communities. PLoS ONE, 15(10), e0241166. https://doi.org/10.1371/journal.pone.0241166
Knobel, P., Dadvand, P., & Maneja-Zaragoza, R. (2019). A systematic review of multi-dimensional quality assessment tools for urban green spaces. Health and Place, 59, 102198. https://doi.org/10.1016/j.healthplace.2019.102198
Kpienbaareh, D., Atuoye, K. N., Ngabonzima, A., Bagambe, P. G., Rulisa, S., Luginaah, I., & Cechetto, D. F. (2019). Spatio-temporal disparities in maternal health service utilization in Rwanda: What next for SDGs? Social Science and Medicine, 226, 164–175. https://doi.org/10.1016/j.socscimed.2019.02.040
Kraemer, M. U. G., Yang, C.-H., Gutierrez, B., Wu, C.-H., Klein, B., Pigott, D. M., et al. (2020). The effect of human mobility and control measures on the COVID-19 epidemic in China. Science. https://doi.org/10.1126/science.abb4218
Kramer, C. Y. (1956). Extension of multiple range tests to group means with unequal numbers of replications. Biometrics, 12, 307–310. https://doi.org/10.2307/3001469
Kruk, M. E., Ling, E. J., Bitton, A., Cammett, M., Cavanaugh, K., Chopra, M., et al. (2017). Building resilient health systems: A proposal for a resilience index. BMJ, 357, j2323. https://doi.org/10.1136/bmj.j2323
Lam, N. S. N., Qiang, Y., Arenas, H., Brito, P., & Liu, K. B. (2015). Mapping and assessing coastal resilience in the Caribbean region. Cartography and Geographic Information Science, 42(4), 315–322. https://doi.org/10.1080/15230406.2015.1040999
Lancet, T. (2014). The silver bullet of resilience. Elsevier.
Legido-Quigley, H., Mateos-García, J. T., Campos, V. R., Gea-Sánchez, M., Muntaner, C., & McKee, M. (2020). The resilience of the Spanish health system against the COVID-19 pandemic. The Lancet. Public Health, 2667(20), 19–20. https://doi.org/10.1016/S2468-2667(20)30060-8
Lo, S. T. T., Chan, E. Y. Y., Chan, G. K. W., Murray, V., Abrahams, J., Ardalan, A., et al. (2017). Health emergency and disaster risk management (Health-EDRM): Developing the research field within the Sendai framework paradigm. International Journal of Disaster Risk Science, 8(2), 145–149. https://doi.org/10.1007/s13753-017-0122-0
Malik, S. M., & Bhutta, Z. A. (2018). Reform of primary health care in Pakistan. The Lancet, 392(10156), 1375–1377. https://doi.org/10.1016/S0140-6736(18)32275-X
McLafferty, S., Schneider, D., & Abelt, K. (2020). Placing volunteered geographic health information: Socio-spatial bias in 311 bed bug report data for New York City. Health and Place, 62, 102282. https://doi.org/10.1016/j.healthplace.2019.102282
Moghadas, M., Asadzadeh, A., Vafeidis, A., Fekete, A., & Kötter, T. (2019). A multi-criteria approach for assessing urban flood resilience in Tehran, Iran. International Journal of Disaster Risk Reduction, 35, 101069. https://doi.org/10.1016/j.ijdrr.2019.101069
O’Sullivan, T. L., Kuziemsky, C. E., Toal-Sullivan, D., & Corneil, W. (2013). Unraveling the complexities of disaster management: A framework for critical social infrastructure to promote population health and resilience. Social Science and Medicine, 93, 238–246. https://doi.org/10.1016/j.socscimed.2012.07.040
OECD. (2021). Focus on resilient healthcare. Retrieved October22, 2021, from https://www.oecd.org/coronavirus/en/themes/resilient-healthcare
Opach, T., Scherzer, S., Lujala, P., & Ketil Rød, J. (2020). Seeking commonalities of community resilience to natural hazards: A cluster analysis approach. Norsk Geografisk Tidsskrift, 74(3), 181–199. https://doi.org/10.1080/00291951.2020.1753236
Pagliacci, F. (2020). Be (and have) good neighbours ! Factors of vulnerability in the case of multiple hazards. Ecological Indicators, 111, 105969. https://doi.org/10.1016/j.ecolind.2019.105969
Pakistan. (2020). National Action Plan for Corona virus disease (COVID-19) Pakistan. Retrieved April1, 2020, from https://www.nih.org.pk/novel-coranavirus-2019-ncov/?__cf_chl_jschl_tk__=3d22fab728e5da697ec4e4ee159ab1d83ce3c269-1585741375-0-AXibmvfG1cZ2QMop97xUiTnALeongnm23j1iTU48wKJ9o5-Kh0o1mweCX6S3ePE88VhXtP4T1ShZdaO2UjTrZfIA0Eg_39rUDafZYAXTa9goOvIB3H0dmtPLsAs3i853i
Pakistan, G. of. (2018). Ministry of Finance. Poverty Reduction Strategy Paper (PRSP) progress report FY2015–FY2017. http://www.finance.gov.pk/ prsp_report.html.
Parsons, M., Glavac, S., Hastings, P., Marshall, G., McGregor, J., McNeill, J., et al. (2016). Top-down assessment of disaster resilience: A conceptual framework using coping and adaptive capacities. International Journal of Disaster Risk Reduction, 19, 1–11. https://doi.org/10.1016/j.ijdrr.2016.07.005
Petherick, A. (2015). Ebola in west Africa: Learning the lessons. The Lancet, 385(9968), 591–592.
Punjani, N. S., Shams, S., & Bhanji, S. M. (2014). Analysis of health care delivery systems: Pakistan versus United States. International Journal of Endorsing Health Science Research (ijehsr), 2(1), 38. https://doi.org/10.29052/ijehsr.v2.i1.2014.38-41
Qureshi, U. U., Saleem, S., Khan, A., Afzal, M. S., Ali, M. S., & Ahmed, H. (2020). Outbreak of novel Corona virus (2019-nCoV); implications for travelers to Pakistan. Travel Medicine and Infectious Disease. https://doi.org/10.1016/j.tmaid.2020.101571
Rahman Qureshi, U. U., Saleem, S., Khan, A., Afzal, M. S., Ali, M. S., & Ahmed, H. (2020). Outbreak of novel corona virus (2019-nCoV); Implications for travelers to Pakistan. Travel Medicine and Infectious Disease. https://doi.org/10.1016/j.tmaid.2020.101571
Raude, J., MCColl, K., Flamand, C., & Apostolidis, T. (2019). Understanding health behaviour changes in response to outbreaks: Findings from a longitudinal study of a large epidemic of mosquito-borne disease. Social Science and Medicine, 230, 184–193. https://doi.org/10.1016/j.socscimed.2019.04.009
Raza, S. H., Haq, W., & Sajjad, M. (2020). COVID-19: A psychosocial perspective. Frontiers in Psychology, 11, 1–12. https://doi.org/10.3389/fpsyg.2020.554624
Renzaho, A. M. N. (2020). Challenges associated with the response to the coronavirus disease (COVID-19) pandemic in Africa—an African diaspora perspective. Risk Analysis, 41(5), 831–836. https://doi.org/10.1111/risa.13596
Rogers, H. L., Barros, P. P., Maeseneer, J. D., Lehtonen, L., Lionis, C., McKee, M., et al. (2021). Resilience testing of health systems: How can it be done? International Journal of Environmental Research and Public Health. https://doi.org/10.3390/ijerph18094742
Sadler, R. C., Hippensteel, C., Nelson, V., Greene-Moton, E., & Furr-Holden, C. D. (2019). Community-engaged development of a GIS-based healthfulness index to shape health equity solutions. Social Science and Medicine, 227, 63–75. https://doi.org/10.1016/j.socscimed.2018.07.030
Sajjad, M. (2021). Disaster resilience in Pakistan: A comprehensive multi-dimensional spatial profiling. Applied Geography, 126, 102367. https://doi.org/10.1016/j.apgeog.2020.102367
Sajjad, M., & Chan, J. C. L. (2019). Risk assessment for the sustainability of coastal communities: A preliminary study. Science of the Total Environment, 671, 339–350. https://doi.org/10.1016/j.scitotenv.2019.03.326
Sajjad, M., Li, Y., Tang, Z., Cao, L., & Liu, X. (2018). Assessing hazard vulnerability, habitat conservation, and restoration for the enhancement of mainland China’s coastal resilience. Earth’s Future, 6(3), 326–338. https://doi.org/10.1002/2017EF000676
Sajjad, M., Li, Y. Y., Li, Y. Y., Chan, J. C. L. J. C. L., & Khalid, S. (2019). Integrating typhoon destructive potential and social-ecological systems toward resilient coastal communities. Earth’s Future, 7(7), 805–818. https://doi.org/10.1029/2019EF001226
Sajjad, M., Chan, J. C. L., & Lin, N. (2020a). Incorporating natural habitats into coastal risk assessment frameworks. Environmental Science and Policy, 106, 99–110. https://doi.org/10.1016/j.envsci.2020.01.004
Sajjad, M., Chan, J. C. L., & Kanwal, S. (2020b). Integrating spatial statistics tools for coastal risk management: A case-study of typhoon risk in mainland China. Ocean and Coastal Management, 184, 105018. https://doi.org/10.1016/j.ocecoaman.2019.105018
Sajjad, M., Lin, N., & Chan, J. C. L. (2020). Spatial heterogeneities of current and future hurricane flood risk along the U.S. Atlantic and Gulf coasts. Science of the Total Environment, 713, 136704. https://doi.org/10.1016/j.scitotenv.2020.136704
Sajjad, M., Chan, J. C. L., & Chopra, S. S. (2021). Rethinking disaster resilience in high-density cities: Towards an urban resilience knowledge system. Sustainable Cities and Society, 69, 102850. https://doi.org/10.1016/j.scs.2021.102850
Scott, R. P., Cullen, A. C., & Chabot-Couture, G. (2020). Disease surveillance investments and administration: Limits to information value in Pakistan polio eradication. Risk Analysis, 41(2), 273–288. https://doi.org/10.1111/risa.13580
Seneff, S. (2016). Statins and myoglobin: How muscle pain and weakness progress to heart, lung and kidney failure. British Medical Bulletin, 119(1), 75. https://doi.org/10.1093/BMB
Talic, S., Shah, S., Wild, H., Gasevic, D., Maharaj, A., Ademi, Z., et al. (2021). Effectiveness of public health measures in reducing the incidence of covid-19, SARS-CoV-2 transmission, and covid-19 mortality: Systematic review and meta-analysis. BMJ, 375, e068302. https://doi.org/10.1136/bmj-2021-068302
Thekdi, S. A., & Aven, T. (2020). A risk-science approach to vulnerability classification. Risk Analysis, 41(8), 1289–1303. https://doi.org/10.1111/risa.13637
Tukey, J. W., William S. Cleveland, H. I. B. J. W. T. L. V. J. D. R. B. D. R. C., Brillinger, D. R., Jones, L.V, Cox, M. G., Cox, D. R., et al. (1984). The Collected Works of John W. Tukey. Wadsworth Advanced Books & Software. Retrieved from https://books.google.com.hk/books?id=ZLiYGNCCE8wC
UN. (2020). Policy Brief: It’s Time to Talk about Expectations for Super Year 2020 | SDG Knowledge Hub | IISD. Retrieved March 28, 2020, from https://sdg.iisd.org/commentary/policy-briefs/its-time-to-talk-about-expectations-for-super-year-2020/
Walters, P. (2015). The problem of community resilience in two flooded cities: Dhaka 1998 and Brisbane 2011. Habitat International, 50, 51–56. https://doi.org/10.1016/j.habitatint.2015.08.004
WHO. (2020). WHO Director-General’s opening remarks at the Mission briefing on COVID-19 - 12 March 2020. Retrieved March28, 2020, from https://www.who.int/dg/speeches/detail/who-director-general-s-opening-remarks-at-the-mission-briefing-on-covid-19---12-march-2020
Yang, Y., Ng, S. T., Zhou, S., Xu, F. J., Li, D., & Li, H. (2020). A federated pre-event community resilience approach for assessing physical and social sub-systems: An extreme rainfall case in Hong Kong. Sustainable Cities and Society, 52, 101859. https://doi.org/10.1016/j.scs.2019.101859
Zhai, W., & Yue, H. (2021). Economic resilience during COVID-19: An insight from permanent business closures. Environment and Planning a: Economy and Space, 54(2), 219–221.
Zhai, W., Fu, X., Liu, M., & Peng, Z.-R. (2021). The impact of ethnic segregation on neighbourhood-level social distancing in the United States amid the early outbreak of COVID-19. Urban Studies. https://doi.org/10.1177/00420980211050183
Zou, L., Lam, N. S. N., Shams, S., Cai, H., Meyer, M. A., Yang, S., et al. (2018). Social and geographical disparities in Twitter use during Hurricane Harvey. International Journal of Digital Earth. https://doi.org/10.1080/17538947.2018.1545878
Acknowledgements
We are thankful to the Ministry of Health-Pakistan, Government of Punjab-Pakistan, Ministry of National Health Services Regulation and Coordination-Pakistan, and Pakistan Bureau of Statistics for the data.
Funding
No dedicated funds were available for this research.
Author information
Authors and Affiliations
Contributions
MS was the main author if this manuscript, proposed the idea, performed data analysis (methods and visualization), and prepared the initial draft. SHR and AAS contributed towards data collection discussions, editing, revision, and final manuscript preparation. All the authors contributed to the article and approved the submitted version.
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare no conflict of interest in conducting this study.
Availability of data and material
All the data used in this study is freely available and the resources are mentioned within this paper. The results from this study will be uploaded to an interactive platform designed by Sajjad M. (Tracking COVID-19 Outbreak in Pakistan: https://arcg.is/15v1u0) to communicate the situation of respond readiness.
Code availability
Not Applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Sajjad, M., Raza, S.H. & Shah, A.A. Assessing Response Readiness to Health Emergencies: A Spatial Evaluation of Health and Socio-Economic Justice in Pakistan. Soc Indic Res (2022). https://doi.org/10.1007/s11205-022-02922-9
Accepted:
Published:
DOI: https://doi.org/10.1007/s11205-022-02922-9