
Abstract
Partial least squares path modeling (PLS-PM) has become very popular in recent years, for measuring concepts that depend on different aspects and that are based on different types of relationships. PLS-PM represents a useful tool to explore relationships and to analyze the influence of the different aspects on the complex phenomenon analyzed. In particular, the use of higher-order constructs has allowed researchers to extend the application of PLS-PM to more advanced and complex models. In this work, our attention is focused on higher-order constructs that include reflective or formative relationships. Even if the dispute between formative models and reflective models is not exactly recent, it is still alive in current literature, for the most part within the context of structural equation models. This paper focuses attention on theoretical and mathematical differences between formative and reflective measurement models within the context of the PLS-PM approach. A simulation study is proposed in order to show how these approaches fit well in different modeling situations. The approaches have been compared using empirical application in a sustainability context. The findings from the simulation and the empirical application can help researchers to estimate and to use the higher-order PLS-PM approach in reflective and formative type models.
Similar content being viewed by others
1 Introduction
Over the last 30 years, many researchers have focused their attention on measuring the importance of constructs and the nature of the relationships between constructs. The focus of their scientific works, regarding reflective and formative relationships, has been primarily on identification and estimation issues (Blalock 1982; Bollen and Lennox 1991). The choice between formative or reflective models has enjoyed increasing attention in the literature of the recent years (Andreev et al. 2009; Diamantopoulos et al. 2008; Coltman et al. 2008; Jarvis et al. 2003; MacKenzie et al. 2005; Petter et al. 2007). As Howell et al. (2007) write, “the works of Bollen and Lennox (1991), MacCallum and Browne MacCallum and Browne (1993), Edwards and Bagozzi (2000) and Bollen and Ting (2000) have given conceptual and methodological tools to deal with observable formative and reflective indicators. [...] Researchers in a number of disciplines are now opting to depart from the dominant reflective measurement tradition in the social sciences, choosing instead to develop and use formative measures. Diamantopoulos and Winklhofer (2001) presented guidelines for developing a formative measure that parallels DeVellis’s (DeVellis 2016) paradigm for scale development under the reflective model”. Particularly, Bollen and Ting (2000) proposed an empirical test to determine whether indicators are more likely to be formative or reflective. Similarly, Jarvis et al. (2003) suggested guidelines for the development of formative measures. The choice between formative and reflective models is also investigated in the PLS-PM approach and in particular in the Higher Order PLS-PM approach (Diamantopoulos and Siguaw 2006; Bollen and Lennox 1991). In PLS-PM, the selection of the construct mode of the Higher-Order approach, reflective or formative, is an important moment for researchers. They can choose among a reflective-reflective, reflective-formative, formative-reflective or formative-formative model (Jarvis et al. 2003; Wetzels et al. 2009). Each type represents the specific relationship between higher-order (HOC) and lower-order (LOC) constructs, as well as the measurement model used in the LOCs (Hair et al. 2017; Cheah et al. 2019). There are already many studies which have compared the approaches reported in the literature in the case of the reflective-formative type of HOCs in PLS-PM. The aim of this paper is to compare the performance of the different approaches available in PLS-PM to estimate the HOCs in different modeling situations through a simulation study, in which we include all types of HOCs in our conceptual framework. The results of the simulation will allow us to formulate guidelines and recommendations for the use of the different approaches for different type higher-order constructs in PLS-PM. The paper is organized as follow: in Sect. 2 we provide some conceptual background to the problem of formative vs reflective constructs; Sect. 3 reports the theoretical principles of the PLS-PM approach and, in detail, Higher-Order PLS-PM; in Sect. 4 the different approaches proposed in the literature are discussed; Sect. 5 presents the results of the simulation study while Sect. 6 reports the main results of the application case study; some concluding remarks will be made in the final Section.
2 Formative Versus Reflective Constructs
In the last few years, many articles have focused on the different constructs model, and about theoretical errors resulting from model misspecification (Bollen and Lennox 1991; Diamantopoulos and Winklhofer 2001; Jarvis et al. 2003; MacKenzie et al. 2005; Roy et al. 2012). In a reflective model (Edwards and Bagozzi 2000; Diamantopoulos and Winklhofer 2001) the construct is considered as the cause and the indicators its manifestations. For example, as Eboli et al. (2018) claim, “intelligence determines the responses of a subject to a questionnaire designed to assess this aspect and not vice versa”. Hence, if the intelligence of a person increases, this will lead to an increase in the number of correct answers to all questions (Simonetto 2012). Thus, the construct determines its indicators (as shown on the left of Fig. 1) and each indicator, being a manifestation of the construct, can be removed if its coefficient is not statistically significant (Bollen and Lennox 1991). In a formative model, the indicators determine the latent construct (Bollen and Lennox 1991) (Fig. 1, on the right). According to MacCallum and Browne (1993), “in many cases indicators could be viewed as causing rather than being caused by the latent variable measured by the indicators”. In this kind of model, a single indicator cannot be removed without affecting the definition of the construct. As Mazziotta and Pareto highlight in their works (Mazziotta and Pareto 2013, 2019), “a typical example of formative model is the measurement of well-being of society. This depends on health, income, occupation, services, environment, etc., and not vice versa. Therefore, if any one of these factors improves, well-being will increase (even if the other factors do not change). However, if well-being increases, this will not necessarily be accompanied by an improvement in all the other factors”.

Reflective and formative constructs
Today, formative models are becoming a standard tool in socio-economic research, particularly in the fields of causal modeling and multidimensional evaluation. Although theoretically the debate on the use of formative models is still very heated (there are still unsolved methodological problems encountered when addressing structural equation models comprising formative constructs), in practice these models are applied in many studies (Diamantopoulos et al. 2008). Generally, it is important to understand the nature of indicators, the reflective or formative nature, because an incorrect specification of the latent constructs can undermine the construct content validity, misrepresent a model, and lead to less useful theories for both researchers (Coltman et al. 2008). According to Coltman et al. (2008) there are three theoretical assumptions to consider when deciding whether the measurement model is formative or reflective: the nature of the construct, the direction of causality between the indicators and the latent construct, and the characteristics of the indicators used to measure the construct (Eboli et al. 2018).
In order to determine whether a construct is reflective or formative, the statistical instruments can also be used. As a matter of fact, the constructs are assessed through the theory underpinning each LV (Bagozzi 2007; Chin 1998b) and their validity by means of Cronbach’s alpha and Average Variance Extracted (AVE) (Coltman et al. 2008). Additionally, the indicator-construct causality flow can also be checked using Weight-Loading Sign (WLS). A negative WLS indicates a causality issue which means that the indicator-construct link is impossible or reverse (Kock 2013; Wagner 1982), a tale-tale sign of a Simpson paradox instance (Kock 2015; Roni et al. 2015). Roy et al. (2012) claim “Wrongly modeling a reflective model as formative, and vice versa, is known as model misspecification”. A misspecification in the measurement model impacts on the structural paths of the LV, thus leading to erroneous path coefficients (Jarvis et al. 2003; MacKenzie et al. 2005). For this reason, it is critical to understand when the use of formative or reflective measurement models is appropriate and how such models should be formulated (Roy et al. 2012).
3 Higher-Order Constructs in PLS-PM
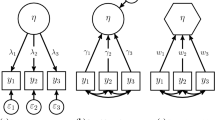
The PLS-PM approach analyzes multiple relationships between a set of blocks of Manifest Variables (MV), assuming that each block of variables is represented by a Latent Variable (LV) or by a theoretical concept and that the relationships between the blocks are established on the basis of the knowledge (theory) of the phenomenon analyzed. PLS-PM is evolving as a statistical modeling technique, and there are several published articles on the method (Bollen 1989; Chin 2010; Joseph et al. 2014). Two very important review papers on the PLS approach to Structural Equation Modeling (SEM) are Chin (1998b) and Tenenhaus et al. (2005). Lately, Lauro et al. (2018) showed recent developments in PLS-PM for the treatment of non-metric data, hierarchical data, longitudinal data and multi-block data. PLS-PM is made up of two elements, the “Measurement Model” (also called the “Outer Model”), which describes the relationships between the MVs and their respective LVs, and the “Structural Model” (also called the “Inner Model”), which describes the relationships between the LVs (Esposito et al. 2010; Roy et al. 2012; Eboli et al. 2018). As Lauro et al. (2018) write, “the PLS-PM approach consists of an iterative algorithm that computes the estimation of the LVs, measured by a set of MVs, and the relationships between them, by means of an interdependent system of equations based on multiple and simple regression. The idea is to determine the scores of the LVs through a process, that, iteratively, computes, first, an outer and, secondly, an inner estimation (Tenenhaus et al. 2005). For this reason, the procedure name is partial (Aria et al. 2018). In recent years, in the context of PLS-PM models, HOCs have become very popular (Edwards 2001; Jarvis et al. 2003; Johnson et al. 2012). According to Chin (1998b); Chin et al. (2003), “HOC Models, also known as Hierarchical Models, are explicit representations of multidimensional constructs that exist at a higher level of abstraction and are related to other constructs at a similar level of abstraction completely mediating the influence from or to their underlying dimensions”. Law et al. (1998) define “[...] a construct as multidimensional when it consists of a number of interrelated attributes or dimensions and exists in multidimensional domains. These dimensions can be conceptualized under an overall abstraction, and it is theoretically meaningful and parsimonious to use this overall abstraction as a representation of the dimensions.” Typically, HOC Models are characterized by the number of levels in the model (often restricted to second-order models) (Rindskopf and Rose 1988) and the different relationships between the HOCs and the LOCs (reflective and formative relationships) (Edwards 2001; Jarvis et al. 2003; Joseph et al. 2014; Wetzels et al. 2009; Becker et al. 2012). As shown by Becker et al. (2012), “a higher (or second)-order construct is a general concept that is either represented (reflective) or constituted (formative) by its dimensions (lower (or first)-order constructs). Therefore, the relation between the higher and lower-order constructs is not a question of causality, but rather a question of the nature of the hierarchical LV, as the higher-order construct (the general concept) does not exist without its lower-order constructs (dimensions). If the higher-order construct is reflective, the general concept is manifested by several specific dimensions, themselves being latent (unobserved). If the higher-order construct is formative, it is a combination of several specific (latent) dimensions in a general concept” (Edwards 2001; Wetzels et al. 2009). As we can see in Fig. 2, there are four main types of HOC Models discussed in the literature (Jarvis et al. 2003; Wetzels et al. 2009) and used in applications (Johnson et al. 2012). These types of models depend on the relationship among the first-order latent variables and their manifest variables, and the second-order latent variables and the first-order latent variables (Becker et al. 2012).

Types of higher-order constructs
The Type I is the Reflective-Reflective Measurement Model, known as the Second-Order Construct Type I, one of the models most frequently applied in SEM among researchers nowadays. The Type II is the Reflective-Formative Measurement Model Type II. According to Chin’s clarification, the LOCs are selectively measured constructs that do not share a common cause but rather form a general concept that fully mediates the impact on subsequent endogenous variables (Chin 1998b). In recent years, this type of model has become the most widely used in empirical applications, currently being considered by researchers, also thanks to the recent availability of appropriate model software (Roni et al. 2015). Several works describe different methods used to estimate the reflective-formative HOCs (Becker et al. 2012; Ciavolino 2012). The third type is the Formative-Reflective Measurement Model Type III, slightly different compared to the Reflective-Formative Type II in the explanation above. In this instance, the HOC is a common concept of several specific formative LOCs. Examples in the empirical literature are rather scarce, but a meaningful application of such a model could be firm performance as a reflective HOC measured by several different indices of a firm performance as formative LOCs (Becker et al. 2012). Finally, the fourth type is represented by the Formative-Formative Measurement Model Type III, the least frequently implemented in the SEM. This application is appropriate when both the HOC and LOCs are formative constructs.
Empirical studies reports that HOC PLS-PM, the reflective-formative type and formative-formative type, were most frequently employed. This indicates the predominance of formative type hierarchical LV models, even if clear guidelines on their use are lacking in the literature (Joseph et al. 2014). For PLS-PM, guidelines are mainly available for HOCs with reflective relationships (Lohmöller 2013; Wetzels et al. 2009; Wold 1982), even though Joseph et al. (2014) show that HOCs with reflective relationships in the first-order and second-order of the hierarchy represent only a minority (20%) of the models applied in MIS Quarterly. However, there is a large need for guidelines on the use and modeling of HOCs with formative relationships in PLS-SEM (Becker et al. 2012).
4 Estimation of Higher-Order Constructs in PLS-PM
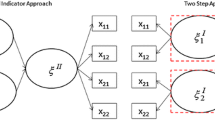
Within the frame of PLS-PM, two main approaches have been developed in the literature in order to estimate the parameters of HOCs: the Repeated Indicator Approach Lohmöller (2013) and the Two Step Approach (Joseph et al. 2014; Wetzels et al. 2009). Recently, other two approaches have been presented: the Mixed Two Step Approach and the PLS Components Regression Approach (Cataldo et al. 2017). All these approaches will be briefly described in this section. For a more detailed discussion and step-by-step illustration, see Becker et al. (2012), Lohmöller (2013), Joseph et al. (2014), Lauro et al. (2018) and Cataldo et al. (2017). The Repeated Indicators Approach is the first and the most popular approach: the indicators of the LOCs are used as the MVs of the HOC (Wilson and Henseler 2007) (Fig. 3). The Two Step Approach, as described by Cataldo et al. (2017), “consists of two phases: first, the LV scores of the LOCs are computed without the HOC (Rajala and Westerlund 2010); then, the PLS-PM analysis is performed using the computed scores as indicators of the HOCs. The implementation is not performed through a single PLS run; this implies that any Second-Order Construct, investigated in stage two, is not taken into account when estimating the LV scores in stage one” (Fig. 3).

Model building: the repeated indicator approach and the two step approach
The Mixed Two Step Approach begins with the implementation of the PLS-PM using the indicators of the LOCs as the MVs of the HOC, such as the Repeated Indicators Approach. In this way, the algorithm gives the scores of the LOCs. Then, the scores of the blocks become indicators of the HOC, and the PLS-PM algorithm is run again (Fig. 4). At last, the PLS Component Regression Approach is described by Cataldo et al. (2017) as consisting of three different steps (Fig. 5): “firstly, a HOC is formed of all the MVs of the LOCs; then, PLS-Regression is applied in order to obtain h components for each block; once h components have been obtained, they represent the MVs of the HOC and the PLS-PM algorithm is performed”.

The mixed two step approach

Model building: the partial least squares component regression approach
In the literature there are already works that compare these approaches within the reflective-formative type of HOC in PLS-PM. In particular (Becker et al. 2012) compared the Repeated Indicators Approach and the Two Step Approach using a simulation study and an empirical application in strategic human resource management context. Many authors Joseph et al. (2014), Wetzels et al. (2009), Cheah et al. (2019) agree that the Two Step Approach has the advantage of estimating a more parsimonious model and proves suitable for the estimation of Second-Order Constructs since it produces estimates that are better than those obtained through the Repeated Indicators Approach. However, the Two Step Approach presents some important limitations related to the components of each block, such as the fact that only one component is chosen for each block, and this has a strong representative power but a weak predictive power in the analysis of the HOC. For these reason, lately, the two other approaches, the Mixed Two Step Approach and the PLS Components Regression Approach, have been proposed in order to overcome these drawbacks. Since the aim of PLS-PM is to estimate the relationships between the LVs, these two approaches provide components that are at the same time representative of their blocks and predictive of the Second-Order Construct (Cataldo et al. 2017). Moreover, the PLS Component Regression Approach overcomes the problem of the number of components of the First-Order Constructs, giving the possibility of choosing the number of components to be extracted manually or according to a specific criterion (Cataldo et al. 2017). Cataldo et al. (2017) compared all four approaches through a simulation study with only one type of HOCs, particularly the reflective-formative type of HOCs and their findings suggest that the Mixed Two Step and PLS Component Regression Approaches are always the best choices, in terms of the bias and Mean Squared Error (MSE) of the estimates, when the researcher aims at studying the formative relationships of the structural model with constructs measured reflectively by their indicators. Starting from the simulation study of Cataldo et al. (2017), in this paper we propose an extended version of that simulation study, the approaches have been compared with all type categories reported by (Jarvis et al. 2003).
5 Simulation Study
The objective of this paper is to analyze and compare, within the same simulation design, the performance of the different approaches available in PLS-PM to estimate HOCs: the Repeated Indicators Approach, the Two Step Approach, the Mixed Two Step Approach and the PLS Component Regression Approach. In the literature there are works that apply simulation study for comparing the performance of the first two approaches for modeling HOCs, for example (Ciavolino and Nitti 2013; Becker et al. 2012). In this simulation work, we have included all the types of HOCs discussed in the literature (Jarvis et al. 2003) in our conceptual framework, using different sample sizes, in order to understand the effect of the sample dimension on the type of HOC. The performances have been evaluated in terms of the prediction accuracy, the estimate bias and the efficiency of the considered approach. The Monte Carlo simulation is used to compare the performance of these approaches, through the R language package. The data generation process is consistent with the procedure described by Paxton et al. (2001) for a Monte Carlo SEM study. In this simulation the same structure of the model and the parameters of the population has been adopted such as in the Cataldo et al. work (Cataldo et al. 2017). Firstly, we defined the structure of the model and the parameters of the population. Then, we generated randomly the Second-Order LV and, given the parameters and the error terms, we estimated the First-Order LVs. According to the outer parameters and error terms, finally, we generated the First and Second-Order MVs. The underlying population model used for the simulation consisted of one Second-Order LV (denoted by \(\xi ^{II}\)) and four First-Order LVs (denoted by \(\xi _{1}^{I}\), \(\xi _{2}^{I}\), \(\xi _{3}^{I}\), and \(\xi _{4}^{I}\)), each of them formed of five MVs. The approach performances have been compared on the basis of the different sample size (n = 100, 250, 500, 1000). In the study design we considered 500 replications for each condition. Obviously, the Second-Order LV, in terms of the number of items, differed according to the estimation approach used: for the Repeated Indicators Approach it was formed of all the MVs of the First-Order constructs; for the Two Step and Mixed Two Step Approaches, it corresponded to the number of First-Order LVs; while for the PLS Component Regression Approach, the numerosity of the block depended on the number of components of the First-Order dimension extracted by the PLS Regression.
The starting point was the generation of the First-Order LVs \(\xi _{i}^{I}\) as random variables \(\xi _{q}^{I}\sim N(0,1)\). The data generated were rescaled in the interval [1, 100].
For the formative structural model, the Second-Order Construct \(\xi _{j}^{II}\) was computed as the product of \(\xi _{q}^{I}\) by the path coefficient vector \(\beta _{qj}\) with the addition of an error component \(\zeta _{j}\) according to the Eq. (1):
For the reflective structural model, the First-Order construct \(\xi _{j}^{I}\) was computed as the product of \(\xi _{q}^{II}\) by the path coefficient vector \(\beta _{qj}\) with the addition of an error component \(\zeta _{q}\) according to the Eq. (2):
The path coefficient vector (\(\beta \)) of the structural model was assumed to have elements equal to 0.7.
For the formative measurement model, the LV was supposed to be generated by its own MVs, following the Eq. (3):
For the reflective measurement model, the MVs are generated starting from the LVs, given the lambda coefficients, following the Eq. (4):
where the error term was distributed as a continuous uniform: \(\delta \sim U(-1,1)\). We estimated each approach with a centroid inner weighting scheme.
In order to assess and compare the methods estimated we used the Relative Bias (RB) and Standard Deviation (StD) following the indications in (Cataldo et al. 2017).
The RB was computed as:
where n represents the number of replications in the simulation, \({\hat{\theta }}_{i}\) is the parameter estimate for each replication and \(\theta \) is the corresponding population parameter. The formula is equivalent to the mean RB (Reinartz et al. 2002).
The StD was computed as:
where \(E({\hat{\theta }})\) is the mean of the estimates across the 500 simulated datasets. A positive RB indicates an overestimation of the true parameter, a negative RB an underestimation. Instead StD index provides information on the efficiency of the estimates. For each scheme it was decided to compare the communality index which is always calculable with each type of relationship both for the structural model and for the measurement model. Furthermore, for the reflective models, the communality was equal to the AVE net of a constant, whereas for the training models it approximated the redundancy index. Table 1 reports the simulation results relating to the communality, relative bias and standard deviation. The results are grouped according to the estimation approach used, sample size and type of higher-order construct.
The estimated community was always significant for all approaches except for the Repeated Indicators Approach that had very low values. Considering the value of the indicator, as can be seen in Fig. 6, it was always higher using the PLS-Regression algorithm, both as the number of samples increased and with each type of model ratio. With the Mixed Two Step approach, instead, it was always lower than with the PLS-Regression but however higher than with the Two Step Approach. Only for the reflective-reflective type, did the communality index of the two approaches have the same value. In Table 1 we also note how, as the number of the sample increased, the variability of the estimate was lower for the PLS-Regression than for the other approaches.

Communality comparison
In the “Appendix, Tables 5, 6, 7 and 8” report the simulation results relating to the coefficients (computed as the average of the 500 replications), relative bias and standard deviation. The results are grouped according to the estimation approach used and sample size. For each combination, the path coefficients, relative bias and standard deviation of the four parameters are reported. As can be seen in Tables 5, 6, 7 and 8 , the estimated paths did not differ much for all the sample sizes and for all the approaches and frameworks used. The path estimates were always significant but, while remaining low, the variability of the estimates was lower when using the Mixed Two Step and PLS-Regression Approaches. Finally, the relative bias of the path coefficients are reported in detail in Tables 9, 10, 11 and 12 grouped for each framework (see the “Appendix”). The Two Step Approach heavily underestimated all the path coefficients linking the First-Order Construct with the Second-Order LV in all sample sizes. Looking at the new methods proposed, we can see that for relative small samples (n=100; n=250) the Mixed Two Step Approach worked best, producing estimates near to zero, while the methods had the same performance for large samples (n=500; n=1000), giving an equivalent accuracy.
The Mixed Two Step and PLS-Regression approaches demonstrated a greater accuracy in predicting the higher level construct, since the communality index was higher than that of the Two Step Approach. The difference is remarkable for all sample size. Therefore, these approaches were also the best option for predicting the Second-Order LV. Overall, the results show that these two methods were always the best choice, in terms of the bias and MSE of the estimates.
6 Application Case Study
The approaches have been compared also in an empirical application in a sustainability context. Global Sustainability was conceived as a Third-Order Construct affecting the Second-Order dimensions, which in turn shaped the First-Order LVs, underlying specific aspects of the Second-Order dimensions. There were 17 First-Order LVs Sustainable Development Goals (SDGs) with, in total, 169 elementary indicators (MVs) (Cataldo et al. 2020). For the sake of simplicity and for illustrative purposes only, the analysis focuses on the social area of Sustainability and its related goals with 54 elementary indicators. This decision was made in order to facilitate, particularly, the implementation of the different approaches. This section reports the main results of the Higher-Order PLS-PM analysis, with a special consideration of the evaluation of the measurement model and the structural model.
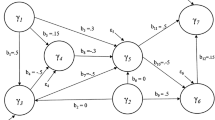
The application case focuses on the Type II category reported by Jarvis et al. (2003), a model resulting from the combination of formative LOC and formative HOC (Fig. 7).

The social area of sustainability and its goals
The official data derive from the database of the United Nations “Sustainable Development Goals”. The analysis was developed with reference to the European Community countries, in total 28. The data are related to the triennium 2015-2017, in particular to the year 2017 (however, for some variables, because of the lack of data for that year, the previous years of this triennium were taken as the reference). Considering that each EIs has different units and values, for the purposes of comparison all the units were first normalized to a value between 0 and 1, where 0 was the value assigned to the least sustainable country while 1 was assigned to the most sustainable for each EI. The Sanchez “plspm” package in the R programming language (Sanchez 2013) was used in order to perform the PLS-PM analysis involving the formative indicators and the centroid scheme for the inner estimation.
Table 2 reports the main quality measurements of the four model approaches.
The Communality measure of the Mixed Two Step approach and the PLS-Regression approach was higher than that of the Repeated Approach and the Two Step Approach. Therefore, the amount of variability of the MVs captured by the social area construct of SDGs using these two methods was higher than when the two classic methods known in the literature were adopted. It is important to note that there is a difference in the use of the scores of the First-Order dimensions. In order to assess the significance of the path coefficients, Table 3 reports the value and significance of the structural coefficients linking the First-Order dimensions to the Second-Order construct.
The model estimated with the Repeated Indicator approach and the Two Step Approach some not significant paths. In all the approaches the goal “Good Health and Well-Being” Goal proves to be most influential among all the factors. This dimension proves not to be significant for the Two Step Approach precisely because it is related to the way it is calculated.
The quality of the model (Tenenhaus et al. 2004) (Table 4) is quite high in all approaches, except the Repeated Indicators Approach, but slightly higher if we estimate the components with the Mixed Two Step Approach and PLS Component Regression Approach. Therefore, the application case focused on the Type II category reported by Jarvis et al. (2003) demonstrated how well the approaches fit the construct in terms of communality and path significance. We can see that the PLS-Regression approach works better than the other approaches reported in the literature.
7 Conclusions and Future Research
The debate over the reflective or formative approach is still open. In the literature it is possible to find considerations on this theme, sometimes in conflict with each other. The goal of this work has been to present the approaches for the PLS-PM parameter estimation in the presence of HOCs. The performances of the Higher-Order approaches have been compared in different modeling situations through simulations, in which we have tested all types of HOCs in our conceptual framework. The performances of these approaches have been analyzed through a simulation study. The PLS-Regression and the Mixed Two Step approaches, compared with the Repeated Indicators Approach and the Two Step Approach have almost always shown more stable estimates, both when the sample size changes and when the relationships between the LVs and the MVs change. In all the cases considered, the communalities are always higher when using the PLS-Regression Approach. The PLS-Regression Approach has shown a higher variability than the mixed approach for small samples. As the sample size increases, PLS-Regression improves in terms of estimates, becoming more stable than the Mixed Two Step Approach. In terms of relative error, the results vary with respect to the type of relationship that binds them. The Mixed Two Step and PLS Regression approaches are always the best choices, in terms of bias and MSE of the estimates. They slightly outperform, in terms of prediction accuracy, the Repeated Indicators Approach and the Two Step Approach. In general, if we work on large samples these two methods have the same performance. To be more accurate, the PLS Regression Approach would seem to be the best, because, as shown in the simulations, it works better than the Mixed Two Step Approach. In the empirical example about Sustainability we proposed, we have verified that with small samples if we want to study the formative relationships of the structural model, with constructs measured by their indicators in a formative way, the Mixed Two Step Approach and PLS Component Regression Approach are the most powerful methods, in terms of quality of the model and path significance. It is interesting to note that it is not possible to define strict rules to choose between a reflective or a formative model. The researchers to decide the mode must consider the latent construct and the indicators (observable or observed) at their disposal. The simulation study we have performed considers a simple situation with only one Second-order LV and four First-order LV. In the future we want to study a more complex model considering also Third or Fourth order LV, using more and more MV and LV. In this way will see how the different approaches analyzed perform when the complexity increase. We intend to test, also, the performance of high order PLS path models with qualitative external informations to take into account characteristics about the units or about the variables (Ciavolino et al. 2015). In our application for example we could have considered the qualitative external information: name of the UE Country in order to to compare the performances of the different Nations.
References
Andreev, P., Heart, T., Maoz, H., & Pliskin, N. (2009) . Validating formative partial least squares (PLS) models: Methodological review and empirical illustration. ICIS 2009 proceedings, 193.
Aria, M., Capaldo, G., Iorio, C., Orefice, C. I., Riccardi, M., & Siciliano, R. (2018). PLS Path Modeling for causal detection of project management skills: A research field in National Research Council in Italy. Electronic Journal of Applied Statistical Analysis, 11(2), 516–545.
Bagozzi, R. P. (2007). On the meaning of formative measurement and how it differs from reflective measurement: Comment on Howell, Breivik, and Wilcox (2007). Washingdon. DC: American Psychological Association.
Blalock, H. M. (1982). Conceptualization and measurement in the social sciences.
Becker, J.-M., Klein, K., & Wetzels, M. (2012). Hierarchical latent variable models in PLS-SEM: Guidelines for using reflective-formative type models. Long Range Planning, 45(5–6), 359–394.
Bollen, K. A. (1989). Structural equations with latent variables. New York: Wiley.
Bollen, K., & Lennox, R. (1991). Conventional wisdom on measurement: A structural equation perspective Psychological bulletin. American Psychological Association, 110(2), 305.
Bollen, K. A., & Ting, K. F. (2000). A tetrad test for causal indicators. Psychological methods, 5(1), 3.
Cataldo, R., Grassia, M. G., Lauro, N. C., & Marino, M. (2017). Developments in Higher-Order PLS-PM for the building of a system of Composite Indicators Quality & Quantity. Springer, 51(2), 657–674.
Cataldo, R., Crocetta, C, Grassia, M. G, Lauro, N. C., Marino, M., & Voytsekhovska, V. (2020). Methodological PLS-PM framework for SDGs system Social Indicators Research, Springer, 1–23.
Cheah, J. H., Ting, H., Ramayah, T., Memon, M. A., Cham, T. H., & Ciavolino, E. (2019). A comparison of five reflective-formative estimation approaches: Reconsideration and recommendations for tourism research. Quality & Quantity, 53(3), 1421–1458.
Chin, W. W. (1998a). Issues and opinion on structural equation modeling. MIS Quarterly, 22(1), vii–xvi.
Chin, W. W. (1998b). The partial least squares approach to structural equation modeling. In G. A. Marcoulides (Ed.), Modern business research methods (pp. 295–336). Mahwah: Lawrence Erlbaum Associates.
Chin, W. W. (2010). How to write up and report PLS analyses. In V. V. Esposito, W. W. Chin, J. Henseler, & H. Wang (Eds.), Handbook of partial least squares (PLS): Concepts, methods and applications (pp. 655–690). Berlin: Springer.
Chin, W. W., Marcolin, B., & Newsted, P. (2003). A partial least squares latent variable modeling approach for measuring interaction effects: Results from a Monte Carlo simulation study and an electronic-mail emotion/adoption study. Information systems research, INFORMS, 14(2), 189–217.
Ciavolino, E. (2012). General distress as second order latent variable estimated through PLS-PM approach. Electronic Journal of Applied Statistical Analysis, 5(3), 458–464.
Ciavolino, E., Carpita, M., & Nitti, M. (2015). High-order pls path model with qualitative external information. Quality & Quantity, 49(4), 1609–1620.
Ciavolino, E., & Nitti, M. (2013). Simulation study for PLS path modelling with high-order construct: A job satisfaction model evidence. In Advanced dynamic modeling of economic and social systems (pp. 185–207). Springer, Berlin, Heidelberg.
Coltman, T., Devinney, T. M., Midgley, D. F., & Venaik, S. (2008). Formative versus reflective measurement models: Two applications of formative measurement. Journal of Business Research, Elsevier, 61(12), 1250–1262.
DeVellis, R. F. (2016). Scale development: Theory and applications (Vol. 26). Sage publications.
Diamantopoulos, A., Riefler, P., & Roth, K. P. (2008). Advancing formative measurement models. Journal of Business Research, 61(12), 1203–1218.
Diamantopoulos, A., & Siguaw, J. A. (2006). Formative versus reflective indicators in organizational measure development: A comparison and empirical illustration. British Journal of Management, 17(4), 263–282.
Diamantopoulos, A., & Winklhofer, H. (2001). Index construction with formative indicators: An alternative to scale development. Journal of Marketing Research, 38(2), 269–277.
Eboli, L., Forciniti, C., & Mazzulla, G. (2018). Formative and reflective measurement models for analysing transit service quality. Public Transport, 10(1), 107–127.
Edwards, J. R. (2001). Multidimensional constructs in organizational behavior research: An integrative analytical framework. Organizational Research Methods, 4(2), 144–192.
Edwards, J. R., & Bagozzi, R. P. (2000). On the nature and direction of relationships between constructs and measures. Psychological methods, American Psychological Association, 5(2), 155.
Esposito, V. V., Trinchera, L., & Amato, S. (2010). PLS path modeling: From Foundations to Recent developments and open issues for model assessment and improvement. In V. V. Esposito, W. W. Chin, J. Henseler, & H. Wang (Eds.), Handbook of partial least squares (PLS): Concepts, methods and applications. Berlin: Springer.
Hair, J. F, Jr., Sarstedt, M., Ringle, C. M., & Gudergan, S. P. (2017). Advanced issues in partial least squares structural equation modeling. Sage Publications.
Howell, R. D., Breivik, E., & Wilcox, J. B. (2007). Reconsidering formative measurement. Psychological Methods, 12(2), 205.
Jarvis, D., MacKenzie, S., & Podsakoff, P. (2003). A critical review of construct indicators and measurement model misspecification in marketing and consumer research. Journal of Consumer Research, 30(3), 199–218.
Johnson, R., Rosen, C., Djurdjevic, E., & Taing, M. (2012). Recommendations for improving the construct clarity of higher-order multidimensional constructs. Human Resource Management Review, 22(2), 66–72.
Joseph, F., Hair, J. F., Hult, G. T. M., Ringle, C. M., & Sarstedt, M. (2014). A primer on partial least squares structural equation modeling (PLS-SEM). Thousand Oaks: SAGE Publications Inc.
Kock, N. (2013) .WarpPLS 4.0 User Manual, ScriptWarp Systems, Laredo Texas.
Kock, N. (2015). How Likely is Simpson’s Paradox in Path Models? International Journal of e-Collaboration (IJeC), 11(1), 1–7.
Law, K., Wong, C., & Mobley, W. (1998). Toward a taxonomy of multidimensional constructs. Academy of Management Review, 23(4), 741–755.
Lohmöller, J. B. (2013). Latent variable path modeling with partial least squares. Berlin: Springer.
Lauro, N. C., Grassia, M. G., & Cataldo, R. (2018). Model based composite indicators: New developments in partial least squares-path modeling for the building of different types of composite indicators. Social Indicators Research, 135(2), 421–455.
MacCallum, R. C., & Browne, M. W. (1993). The use of causal indicators in covariance structure models: Some practical issues. Psychological Bulletin, 114(3), 533.
MacKenzie, S., Podsakoff, P., & Jarvis, C. B. (2005). The problem of measurement model misspecification in behavioral and organizational research and some recommended solutions. Journal of Applied Psychology, 90(4), 710.
Mazziotta, M., & Pareto, A. (2013). Methods for constructing composite indices: one for all or all for one? Rivista Italiana di Economia Demografia e Statistica, LXVIII, n.2.
Mazziotta, M., & Pareto, A. (2019). Use and misuse of PCA for measuring well-being. Social Indicators Research, 142(2), 451–476.
Paxton, P., Curran, P. J., Bollen, K. A., Kirby, J., & Chen, F. (2001). Monte carlo experiments: Design and implementation. Structural Equation Modeling, 8(2), 287–312.
Petter, S., Straub, D., & Rai, A. (2007). Specifying formative constructs in information systems research (pp. 623–656). JSTOR: MIS quarterly.
Rajala, R., & Westerlund, M. (2010). Antecedents to consumers’ acceptance of mobile advertisements: A hierarchical construct PLS structural equation model. In XLIIIth Hawaii International Conference on Systems Sciences (HICSS).
Reinartz, W., Echambadi, R., & Chin, W. W. (2002). Generating non-normal data for simulation of structural equation models using Mattson’s method. Multivariate Behavioural Research, 37(2), 227–244.
Rindskopf, D., & Rose, T. (1988). Second order factor analysis: Some theory and applications. Multivariate Behavioral Research, 23(1), 51–67.
Roni, S. M., Djajadikerta, H., & Ahmad, M. A. N. (2015). PLS-SEM approach to second-order factor of deviant behaviour: Constructing perceived behavioural control. Procedia Economics and Finance, 28, 249–253.
Roy, S., Tarafdar, M., Ragu-Nathan, T. S., & Erica, M. (2012). The effect of misspecification of reflective and formative constructs in operations and manufacturing management research. Electronic Journal of Business Research Methods, 10(1).
Sanchez, G. (2013). PLS Path Modeling with R. Berkeley: Trowchez Editions.
Simonetto, A. (2012). Formative and reflective models: State of the art. Electronic Journal of Applied Statistical Analysis, 5(3), 452–457.
Tenenhaus, M., Amato, S., Esposito, & Vinzi, V. (2004). A global goodness-of-fit index for PLS structural equation modelling. In Proceedings of the $XLII^{th}$ SIS Scientific Meeting, 1, 739–742.
Tenenhaus, M., Esposito, V. V., Chatelin, Y. M., & Lauro, N. C. (2005). PLS path modeling. Computational Statistics and Data Analysis, 48(1), 159–205.
Wagner, C. H. (1982). Simpson’s paradox in real life. The American Statistician, 36(1), 46–48.
Wetzels, M., Odekerken-Schröder, G., & Van Oppen, C. (2009). Using PLS path modeling for assessing hierarchical construct models: Guidelines and empirical illustration (pp. 177–195). JSTOR: CMIS quarterly.
Wilson, B., & Henseler, J. (2007). Modeling reflective higher-order constructs using three approaches with PLS path modeling: a Monte Carlo comparison. Otago: Department of Marketing, School of Business, University of Otago.
Wold, H. (1982). Soft modeling: The basic design and some extensions. Systems under Indirect Observation, 2, 343.
Funding
Open access funding provided by Università di Foggia within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
See Tables 5, 6, 7, 8, 9, 10, 11 and 12.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Crocetta, C., Antonucci, L., Cataldo, R. et al. Higher-Order PLS-PM Approach for Different Types of Constructs. Soc Indic Res 154, 725–754 (2021). https://doi.org/10.1007/s11205-020-02563-w
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11205-020-02563-w