Abstract
Candida vulturna is a new member of the Candida haemulonii species complex that recently received much attention as it includes the emerging multidrug-resistant pathogen Candida auris. Here, we describe the high-quality genome sequence of C. vulturna type strain CBS 14366T to cover all genomes of pathogenic C. haemulonii species complex members.
Similar content being viewed by others


Candida vulturna was recently described as a member of the Candida haemulonii species complex that currently comprises nine species of which four are known as human pathogens: C. haemulonii (including the variety vulnera), Candida pseudohaemulonii, Candida duobushaemulonii and C. auris [1,2,3]. The type strain of C. vulturna was first described in 2016, originated from a flower, but since then several cases of C. vulturna invasive candidiasis were reported in Malaysian patients (Ratna Mohd Tap, personal communication; [3]).
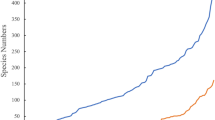
Misidentification of C. haemulonii species complex members has been one of the major driving forces behind the global emergence of the multidrug-resistant pathogen C. auris (Fig. 1; [4]). As decreased amphotericin B and fluconazole susceptibilities have been reported for C. haemulonii species complex members, a reliable identification is of upmost importance for daily clinical practice [5]. Molecular detection and identification methods set foot in diagnostic mycology laboratories. Hence, there is a need for high-quality genome data to set up molecular tools to reliably detect and identify pathogens, to detect emergence of mutations related to antifungal resistance and other biological processes [6]. As visualized by the plethora of published C. auris qPCR assays [7], different sets of sibling species were used to develop the assays, which may result in incorrect identification and/or detection results.

Colony phenotypes of pathogenic members of the Candida haemulonii species complex. The colony phenotypes of Candida vulturna CBS 14366T (top), Candida haemulonii CBS 5149T (right), Candida duobushaemulonii CBS 7798T (bottom) and Candida pseudohaemulonii CBS 10004T (left) are depicted. Strains were inoculated onto Candiselect chromogenic agar (Bio-Rad, Marnes-la-Coquette, France) and incubated for 48 h at 35 °C
There are several genomes published of pathogenic C. haemulonii species complex members, mostly being C. auris [8], and single or few genomes of C. haemulonii [9], C. duobushaemulonii [10] and C. pseudohaemulonii [8, 11]. Unfortunately, C. vulturna has not been considered in previous genome sequencing projects. Therefore, we sequenced a high-quality genome of this emerging fungal pathogen.
Candida vulturna CBS 14366T was cultured in 10 ml yeast peptone glucose broth for 3 days at 25 °C on a rotary shaker (125 rpm). Strain identity was confirmed by standard ITS sequencing (GenBank MN330068; [3]); however, MALDI-TOF analysis (Brüker-Daltonics, Bremen, Germany) yielded repetitively a good, yet incorrect, hit with its sibling C. pseudohaemulonii.
An established cetyltrimethylammonium bromide (CTAB) DNA extraction protocol was optimized to yield high quantity and quality genomic DNA, as in detail described hereafter [12]. Biomass was collected by centrifugation at 4,000 rpm for 10 min (Centrifuge 5810R; Eppendorf, Hamburg, Germany), supernatant was decanted, and 1.5 ml CTAB-buffer (see [12]) containing 1 mg proteinase K (V3021, Promega, Leiden, The Netherlands) was added followed by 2 h incubation at 60 °C with periodically vortexing. The sample was cooled to room temperature, and 2 ml chloroform/isoamyl alcohol (24:1) was added and mixed by 5–10 min flipping. After centrifugation at 4,000 rpm for 10 min, the supernatant (~ 1200 µl) was collected in a 2.0-ml DNA low-binding tube (0030108078; Eppendorf). DNA was precipitated by adding 660 µl ice-cold 2-propanol (I9516; Sigma-Aldrich, Saint Louis, MO, USA) and mixed by flipping. DNA yield increased by overnight incubation at -20 °C. After centrifugation at 14,000 rpm (Centrifuge 5430; Eppendorf) for 10 min, supernatant was removed and the pellet was washed with 1 ml 70% ice-cold ethanol. The dried pellet was resuspended in 150 µl IDTE-buffer (10 mM Tris, 0.1 mM EDTA, pH 8; IDT, San Diego, CA, USA); more IDTE was added until the pellet dissolved completely. RNA was removed by adding 1 µl RNAse Cocktail Enzyme mix (AM2286; ThermoFisher, Waltham, MA, USA) per 100 µl sample and incubated for 1 h at 37 °C. DNA samples were again washed with chloroform/isoamyl alcohol and precipitated with 2-propanol as described above. DNA quality and quantity were measured in triplicate using Qubit and Nanodrop (both ThermoFisher); purity and integrity was checked on 0.8% agarose gel. DNA was stored at -20 °C until further use.
Library preparation was done by the ligation sequencing kit (SQK-LSK108; ONT, Oxford, UK) followed by the nanopore sequencing run on a MinION flow cell (FLO-MIN106; ONT) according to the manufacturer’s instructions.
Basecalling of raw data was performed using Guppy (v3.2.2 + 9fe0a78; parameters: –flow cell FLO-MIN106 –kit SQK-LSK108) [13]. A draft assembly was prepared using Canu (v1.8; parameters: genomeSize = 13 m -nanopore-raw) [14]. The raw reads produced by Guppy were re-mapped into the draft genome using minimap2 (v 2.17-r954-dirty; parameters: -L -ax map-ont) [15]. The draft assembly was polished twice, first with racon (v1.4.6; parameters: -m 8 -x -6 -g -8 -t 6) and, after manual inspection and curation, with medaka (v0.8.1-p; parameters: -m r941_min_high) [15, 16].
Assembly of the Candida vulturna CBS 14366T reads produced 8 scaffolds between 4.2Mbp and 300Kbp (N50 = 1,937,935 bp), and a shorter scaffold of 43Kbp whose best blast hit within the NCBI database is annotated as mitochondrial DNA (Candida auris JCM 15448 = CBS 10913T; accession AP018713) for a total of 12.9Mbp. The 9 scaffolds likely correspond to 8 chromosomes plus the mitochondrial genome; similar numbers have been reported for other pathogenic members of the C. haemulonii species complex [8,9,10, 17, 18]. Draft genome was analyzed with funannotate (v1.6.0-297abc4; https://github.com/nextgenusfs/funannotate). Genes (n = 5,560) were predicted ab initio and functionally annotated with Pfam (v32), InterProScan (v75), BuscoDB (Saccharomycetales_odb9) and eggnog (v5.0).
This whole-genome shotgun project has been deposited at DDBJ/ENA/GenBank under the BioProject accession number PRJNA560499. The version described in this paper is the first version. The Sequence Read Archive (SRA) accession number is SRR10142922, associated with the BioSample number SAMN12587626.
References
Cendejas-Bueno E, Kolecka A, Alastruey-Izquierdo A, Theelen B, Groenewald M, Kostrzewa M, Cuenca-Estrella M, Gómez-López A, Boekhout T. Reclassification of the Candida haemulonii complex as Candida haemulonii (C. haemulonii group I), C. duobushaemulonii sp. nov. (C. haemulonii group II), and C. haemulonii var. vulnera var. nov.: three multiresistant human pathogenic yeasts. J Clin Microbiol. 2012;50:3641–51. https://doi.org/10.1128/JCM.02248-12.
Satoh K, Makimura K, Hasumi Y, Nishiyama Y, Uchida K, Yamaguchi H. Candida auris sp. nov., a novel ascomycetous yeast isolated from the external ear canal of an inpatient in a Japanese hospital. Microbiol Immunol. 2009;53:41–4. https://doi.org/10.1111/j.1348-0421.2008.00083.x.
Sipiczki M, Tap RM. Candida vulturna pro tempore sp. nov., a dimorphic yeast species related to the Candida haemulonis species complex isolated from flowers and clinical sample. Int J Syst Evol Microbiol. 2016;66:4009–15. https://doi.org/10.1099/ijsem.0.001302.
de Jong AW, Hagen F. Attack, defend and persist: how the fungal pathogen Candida auris was able to emerge globally in healthcare environments. Mycopathologia. 2019;184:353–65. https://doi.org/10.1007/s11046-019-00351-w.
Colombo AL, Júnior JNA, Guinea J. Emerging multidrug-resistant Candida species. Curr Opin Infect Dis. 2017;30:528–38. https://doi.org/10.1097/QCO.0000000000000411.
Mac Aogáin M, Chaturvedi V, Chotirmall SH. MycopathologiaGENOMES: the new ‘home’ for the publication of fungal genomes. Mycopathologia. 2019. https://doi.org/10.1007/s11046-019-00366-3.
Kordalewska M, Perlin DS. Identification of drug resistant Candida auris. Front. Microbiol. 2019;10:1918. https://doi.org/10.3389/fmicb.2019.01918.
Muñoz JF, Gade L, Chow NA, Loparev VN, Juieng P, Berkow EL, Farrer RA, Litvintseva AP, Cuomo CA. Genomic insights into multidrug-resistance, mating and virulence in Candida auris and related emerging species. Nat Commun. 2018;9:5346. https://doi.org/10.1038/s41467-018-07779-6.
Chow NA, Gade L, Batra D, Rowe LA, Juieng P, Ben-Ami R, Loparev VN, Litvintseva AP. Genome sequence of a multidrug-resistant Candida haemulonii isolate from a patient with chronic leg ulcers in Israel. Genome Announc. 2018;6:e00176-18. https://doi.org/10.1128/genomeA.00176-18.
Chow NA, Gade L, Batra D, Rowe LA, Juieng P, Loparev VN, Litvintseva AP. Genome sequence of the amphotericin B-resistant Candida duobushaemulonii strain B09383. Genome Announc. 2018;6:e00204-18. https://doi.org/10.1128/genomeA.00204-18.
Tap RM, Kamarudin NA, Ginsapu SJ, Ahmed Bakri AR, Ahmad N, Amran F. Sipiczki M (2018) Draft genome sequence of Candida pseudohaemulonii isolated from the blood of a neutropenic patient. Genome Announc. 2018;6:e00166-18. https://doi.org/10.1128/genomeA.00166-18.
Gerrits van den Ende AHG, de Hoog GS. Variability and molecular diagnostics of the neurotropic species Cladophialophora bantiana. Stud Mycol. 1999;43:151–62.
Wick RR, Judd LM, Holt KE. Performance of neural network basecalling tools for Oxford Nanopore sequencing. Genome Biol. 2019;20:129. https://doi.org/10.1186/s13059-019-1727-y.
Koren S, Walenz BP, Berlin K, Miller JR, Bergman NH, Phillippy AM. Canu: scalable and accurate long-read assembly via adaptive k-mer weighting and repeat separation. Genome Res. 2017;27:722–36. https://doi.org/10.1101/gr.215087.116.
Li H. Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics. 2018;34:3094–100. https://doi.org/10.1093/bioinformatics/bty191.
Vaser R, Sović I, Nagarajan N, Šikić M. Fast and accurate de novo genome assembly from long uncorrected reads. Genome Res. 2017;27:737–46. https://doi.org/10.1101/gr.214270.116.
Bravo Ruiz G, Ross ZK, Holmes E, Schelenz S, Gow NAR, Lorenz A. Rapid and extensive karyotype diversification in haploid clinical Candida auris isolates. Curr Genet. 2019;65:1217–28. https://doi.org/10.1007/s00294-019-00976-w.
Oh BJ, Shin JH, Kim MN, Sung H, Lee K, Joo MY, Shin MG, Suh SP, Ryang DW. Biofilm formation and genotyping of Candida haemulonii, Candida pseudohaemulonii, and a proposed new species (Candida auris) isolates from Korea. Med Mycol. 2011;49:98–102. https://doi.org/10.3109/13693786.2010.493563.
Acknowledgements
Jorge C. Navarro-Muñoz was financially supported by the Stichting Odo van Vloten Foundation, The Netherlands.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical statement
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Navarro-Muñoz, J.C., de Jong, A.W., Gerrits van den Ende, B. et al. The High-Quality Complete Genome Sequence of the Opportunistic Fungal Pathogen Candida vulturna CBS 14366T. Mycopathologia 184, 731–734 (2019). https://doi.org/10.1007/s11046-019-00404-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11046-019-00404-0