
Abstract
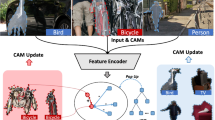
This paper addresses the task of fine-grained label learning in object detection with the weak supervision of auxiliary information attached to images. Most of the recent work focused on the label prediction for objects in the same category space as in training data under the fully-supervised learning framework and cannot be expanded to the learning of more fine-grained categories that have not been defined in training sets. In this paper, we propose a new weakly-supervised learning approach, called label inference curriculum network (LICN), to detecting objects and learning their fine-grained category labels based on supervision of captions via curriculum learning. First, we build a semantic mapping based on embedding techniques and a knowledge base to measure the correspondence between coarse labels and fine-grained label proposals; second, we introduce a label inference curriculum network, which ranks the order of training samples by the complexity of samples. We construct two datasets, namely FG-COCO and FGs-COCO, consisting of both coarse and fine-grained labels based on MS COCO and Visual Genome to train and test our approach. Experimental results demonstrate the effectiveness of our proposed LICN model, and LICN-E2C achieves an improvement of 1.7% mAP with 0.5:0.05:0.95 IoU compared with the LICN-C2E on the FG-sCOCO test dataset.











Similar content being viewed by others


Data Availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Ahmed A, Jalal A, Kim K (2021) Multi-objects detection and segmentation for scene understanding based on texton forest and kernel sliding perceptron. J Electr Eng Technol 16(2):1143–1150
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 6077–6086
Bengio Y, Louradour J, Collobert R, Weston J (2009) Curriculum learning. In: Proceedings of the 26th annual international conference on machine learning, pp 41–48
Bhujade S, Kamaleshwar T, Jaiswal S, Babu DV (2022) Deep learning application of image recognition based on self-driving vehicle. In: International conference on emerging technologies in computer engineering, Springer, pp 336–344
Bilen H, Vedaldi A (2016) Weakly supervised deep detection networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2846–2854
Buonviri A, York M, LeGrand K, Meub J (2019) Survey of challenges in labeled random finite set distributed multi-sensor multi-object tracking. In: 2019 IEEE Aerospace Conference, IEEE, pp 1–12
Diba A, Sharma V, Pazandeh A, Pirsiavash H, Van Gool L (2017) Weakly supervised cascaded convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 914–922. https://doi.org/10.1109/CVPR.2017.545
Du W, Phlypo R, Adalı T (2019) Adaptive feature selection and feature fusion for semi-supervised classification. J Signal Process Syst 91(5):521–537
Everingham M, Van Gool L, Williams C K, Winn J, Zisserman A (2010) The pascal visual object classes (voc) challenge. Int J Comput Vis 88(2):303–338
Fang H, Gupta S, Iandola F, Srivastava RK, Deng L, Dollár P, Gao J, He X, Mitchell M, Platt JC, et al. (2015) From captions to visual concepts and back. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1473–1482
Ge W, Yang S, Yu Y (2018) Multi-evidence filtering and fusion for multi-label classification, object detection and semantic segmentation based on weakly supervised learning. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1277–1286
Guo S, Huang W, Zhang H, Zhuang C, Dong D, Scott MR, Huang D (2018) CurriculumNet: weakly supervised learning from large-scale web images. In: Proceedings of the european conference on computer vision (ECCV), pp 135–150
Hacohen G, Weinshall D (2019) On the power of curriculum learning in training deep networks. arXiv:190403626
Jerbi A, Herzig R, Berant J, Chechik G, Globerson A (2020) Learning object detection from captions via textual scene attributes. arXiv:200914558
Kantorov V, Oquab M, Cho M, Laptev I (2016) ContextLocNet: context-aware deep network models for weakly supervised localization. In: European conference on computer vision, Springer, pp 350–365
Krause J, Johnson J, Krishna R, Fei-Fei L (2017) A hierarchical approach for generating descriptive image paragraphs. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 317–325
Krishna R, Zhu Y, Groth O, Johnson J, Hata K, Kravitz J, Chen S, Kalantidis Y, Li L J, Shamma D A, et al. (2017) Visual genome: connecting language and vision using crowdsourced dense image annotations. Int J Comput Vis 123(1):32–73
Li C, Ma T, Zhou Y, Cheng J, Xu B (2017) Measuring word semantic similarity based on transferred vectors. In: International conference on neural information processing, Springer, pp 326–335
Lin TY, Maire M, Belongie S, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL (2014) Microsoft coco: common objects in context. In: European conference on computer vision, Springer, pp 740–755
Manning CD, Surdeanu M, Bauer J, Finkel JR, Bethard S, McClosky D (2014) The Stanford CoreNLP natural language processing toolkit. In: Proceedings of 52nd annual meeting of the association for computational linguistics: system demonstrations, pp 55–60
Mikolov T, Chen K, Corrado G, Dean J (2013a) Efficient estimation of word representations in vector space. arXiv:13013781
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J (2013b) Distributed representations of words and phrases and their compositionality. In: Advances in neural information processing systems, pp 3111–3119
Misra I, Lawrence Zitnick C, Mitchell M, Girshick R (2016) Seeing through the human reporting bias: visual classifiers from noisy human-centric labels. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2930–2939
Oquab M, Bottou L, Laptev I, Sivic J (2015) Is object localization for free?-Weakly-supervised learning with convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 685–694
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 779–788
Ren S, He K, Girshick R, Sun J (2015) Faster R-CNN: Towards real-time object detection with region proposal networks. In: Advances in neural information processing systems, pp 91–99
Song Y, Soleymani M (2019) Polysemous visual-semantic embedding for cross-modal retrieval. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1979–1988
Tang P, Wang X, Bai X, Liu W (2017) Multiple instance detection network with online instance classifier refinement. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2843–2851
Tang P, Wang X, Bai S, Shen W, Bai X, Liu W, Yuille A (2018) PCL: proposal cluster learning for weakly supervised object detection. IEEE Trans Pattern Anal Mach Intell 42(1):176–191
Teney D, Anderson P, He X, Van Den Hengel A (2018) Tips and tricks for visual question answering: learnings from the 2017 challenge. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4223–4232
Thomas C, Kovashka A (2019) Predicting the politics of an image using webly supervised data. In: Advances in neural information processing systems, pp 3630–3642
Tian Jl, Zhao W (2010) Words similarity algorithm based on Tongyici Cilin in semantic web adaptive learning system. J Jilin University (Inf Sci Ed) 28 (06):602–608
Wan F, Wei P, Jiao J, Han Z, Ye Q (2018) Min-entropy latent model for weakly supervised object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1297–1306
Wang J, Wang X, Liu W (2018) Weakly- and semi-supervised Faster R-CNN with curriculum learning. In: 2018 24th International Conference on Pattern Recognition (ICPR), IEEE, pp 2416–2421
Wei Y, Shen Z, Cheng B, Shi H, Xiong J, Feng J, Huang T (2018) TS2C: tight box mining with surrounding segmentation context for weakly supervised object detection. In: Proceedings of the european conference on computer vision (ECCV), pp 434–450
Ye K, Zhang M, Kovashka A, Li W, Qin D, Berent J (2019) Cap2Det: learning to amplify weak caption supervision for object detection. In: Proceedings of the IEEE international conference on computer vision, pp 9686–9695
Zakraoui J, Saleh M, Al-Maadeed S, Jaam JM (2021) Improving text-to-image generation with object layout guidance. Multimed Tools Appl 80(18):27423–27443
Zhang M, Hwa R, Kovashka A (2018) Equal but not the same: understanding the implicit relationship between persuasive images and text. arXiv:180708205
Zhang X, Wei Y, Feng J, Yang Y, Huang TS (2018) Adversarial complementary learning for weakly supervised object localization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1325–1334
Zhou B, Khosla A, Lapedriza A, Oliva A, Torralba A (2016) Learning deep features for discriminative localization. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2921–2929
Acknowledgments
This research is supported in part by China Scholarship Council (No. 20190628 0464), the National Key R&D Program (No. 2018AAA0101501) and the National Natural Science Foundation (61375040, 61772415), of China.
Funding
China Scholarship Council (No. 201906280464), the National Key R&D Program (No. 2018AAA0101501) and the National Natural Science Foundation (61375040, 61772415), of China.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interests
The authors declare that there is no conflict of interests regarding the publication of this paper.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, X., Du, Y., Verberne, S. et al. Fine-grained label learning in object detection with weak supervision of captions. Multimed Tools Appl 82, 6557–6579 (2023). https://doi.org/10.1007/s11042-022-13592-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-022-13592-7