
Abstract
In data envelopment analysis, we are often puzzled by the large difference between the constant-returns-scale and variable returns-to-scale scores, and by the convexity production set syndrome in spite of the S-shaped curve, often observed in many real data sets. In this paper, we propose a solution to these problems. Initially, we evaluate the constant-returns-scale and variable returns-to-scale scores for all decision-making units by means of conventional methods. We obtain the scale-efficiency for each decision-making unit. Using the scale-efficiency, we decompose the constant-returns-scale slacks for each decision-making unit into scale-independent and scale-dependent parts. Following this, we eliminate scale-dependent slacks from the data set, and thus obtain a scale-independent data set. Next, we classify decision-making units into several clusters, depending either on the degree of scale-efficiency or on some other predetermined characteristics. We evaluate slacks of scale-independent decision-making units within the same cluster using the constant-returns-scale model, and obtain the in-cluster slacks. By summing the scale-dependent and the in-cluster slacks, we define the total slacks for each decision-making unit. Following this, we evaluate the efficiency score of the decision-making unit and project it onto the efficient frontiers, which are no longer guaranteed to be convex and are usually non-convex. Finally, we define the scale-dependent data set by which we can find the scale elasticity of each decision-making unit. We apply this model to a data set of Japanese universities’ research activities.









Similar content being viewed by others

References
Avkiran, N.K.: Investigating technical and scale efficiencies of Australian universities through data envelopment analysis. Socio-Eco. Plann. Sci. 35, 57–80 (2001)
Avkiran, N.K., Tone, K., Tsutsui, M.: Bridging radial and non-radial measures of efficiency in DEA. Ann. Oper. Res. 164, 127–138 (2008)
Bogetoft, P., Otto, L.: Benchmarking with DEA, SFA, and R. Springer, New York (2010)
Dekker, D., Post, T.: A quasi-concave DEA model with an application for bank branch performance evaluation. Eur. J. Oper. Res. 132, 296–311 (2001)
Kousmanen, T.: DEA with efficiency classification preserving conditional convexity. Eur. J. Oper. Res. 132, 326–342 (2001)
Podinovski, V.V.: Local and global returns to scale in performance measurement. J. Oper. Res. Soc. 55, 170–178 (2004)
Olesen, O.B., Petersen, N.C.: Imposing the regular ultra Passum law in DEA models. Omega 41, 16–27 (2013)
Farrell, M.J.: The measurement of productive efficiency. J. Royal Statist. Soc. Ser. A (General) 120(III), 253–281 (1957)
Farrell, M.J., Fieldhouse, M.: Estimating efficient production functions under increasing returns to scale. J. Royal Statist. Soc. Ser. A (General) 125(2), 252–267 (1962)
Charnes, A., Cooper, W.W., Rhodes, E.: Evaluating program and managerial efficiency: an application of data envelopment analysis to program follow through. Manag. Sci. 27, 668–678 (1981)
Førsund, F.R., Kittelsen, S.A.C., Krivonozhko, V.E.: Farrell revisited—visualizing properties of DEA production frontiers. J. Oper. Res. Soc. 60, 1535–1545 (2009)
Krivonozhko, V.E., Utkin, O.B., Volodin, A.V., Sablin, I.A., Patrin, M.: Constructions of economic functions and calculation of marginal rates in DEA using parametric optimization methods. J. Oper. Res. Soc. 55, 1049–1058 (2004)
Deprins, D., Simar, L., Tulkens, H.: Measuring labor efficiency in post office. In Marchand, P., Pestieau, P., Tulkens, H. (eds.) The performance of public Enterprises: Concepts and measurement, pp. 243–267. North-Holland (1984)
Tone, K.: A slacks-based measure of efficiency in data envelopment analysis. Eur. J. Oper. Res. 130, 498–509 (2001)
Avkiran, N.K.: Applications of data envelopment analysis in the service sector. In: Handbook on Data Envelopment Analysis, Chapter 15. Springer, New York (2011)
Paradi, J. C., Yang, Z., Zhu, H.: Assessing bank and bank branch performance—modeling considerations and approaches. In: Handbook on Data Envelopment Analysis, Chapter 13. Springer, New York (2011)
Cook, W. D.: Qualitative data in DEA. In: Handbook on Data Envelopment Analysis, Chapter 6. Springer, New York (2011)
Charnes, A., Cooper, W.W., Rhodes, E.: Measuring the efficiency of decision making units. Eur. J. Oper. Res. 2, 429–444 (1978)
Banker, R.D., Charnes, A., Cooper, W.W.: Some models for estimating technical and scale inefficiencies in data envelopment analysis. Manag. Sci. 30, 1078–1092 (1984)
Banker, R.D., Thrall, R.M.: Estimation of returns to scale using data envelopment analysis. Eur. J. Oper. Res. 62, 74–84 (1992)
Banker, R.D., Cooper, W.W., Seiford, L.M., Thrall, R.M., Zhu, J.: Returns to scale in different DEA models. Eur. J. Oper. Res. 154, 345–362 (2004)
Färe, R., Primond, D.: Multi-Output Production and Duality: Theory and application. Kluwer Academic Press, Norwell, MA (1995)
Førsund, F.R., Hjalmarsson, L.: Are all scales optimal in DEA? theory and empirical evidence. J. Prod. Anal. 21, 25–48 (2004)
Førsund, F.R., Hjalmarsson, L.: Calculating scale elasticity in DEA models. J. Oper. Res. Soc. 55, 1012–1038 (2004)
Cooper, W.W., Seiford, L.M., Tone, K.: Data Envelopment Analysis: A Comprehensive Text with Models, Applications, References and DEA-Solver Software. Springer, Berlin (2007)
Acknowledgments
We are grateful to two reviewers for their comments and suggestions on the previous version of the manuscript. This research was supported by JSPS KAKENHI Grant Number 25282090.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Jamal Ouenniche.
Appendices
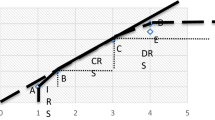
Appendix A: Clustering Using Returns-to-Scale and Scale-Efficiency
We already know the returns-to-scale (RTS) characteristics of each DMU, \(i.e.\), increasing-returns-to-scale (IRS), CRS or DRS (decreasing returns-to-scale), as it is obtained from the VRS solution by projecting VRS inefficient DMUs onto the VRS efficient frontiers. We first classify CRS DMUs as Cluster C. Then, we classify IRS DMUs depending on the degree of scale-efficiency, \(\sigma \). For example, IRS DMUs with 1\(>\sigma \ge \)0.8 are classified as I1, and IRS DMUs with 0.8\(>\sigma \ge \)0.6 as I2, and so on. DRS DMUs with 1\(>\sigma \ge \)0.8 are classified as D1, and so on, as above. We determine the number of clusters and their bandwidth by considering the number of DMUs in the cluster. Each cluster is expected to have at least as many DMUs as a few times the sum of the input and output factors. Figure 10 illustrates this point. This figure corresponds to the input-oriented case, where DMUs with highly different input scales may be classified into the same cluster. If such classification is inappropriate, we may try the output-oriented, non-oriented or directional distance models to determine clusters.

Clustering by the degree of scale-efficiency
Appendix B: Proof of Propositions
Proposition 3.1
\( \theta _k^{\mathrm{{SAS}}} \ge \theta _k^{\mathrm{{CRS}}} \quad (k=1,\ldots ,n).\)
Proof
The CRS scores for \(({\mathbf {x}}_k,{\mathbf {y}}_k )\) and \(({\overline{\mathbf {x}}}_k,{\overline{\mathbf {y}}}_k )\), respectively, are defined by:
and
We prove this proposition for two individual cases.
(Case 1) All DMUs belong to the same cluster.
In this case (B.2) becomes:
Let \(({\varvec{\lambda }}^*,{\mathbf {t}}^{-*},{\mathbf {t}}^{+*})\) be an optimal solution for (B.3). Since \(P({\mathbf {X}},{\mathbf {Y}})=P(\overline{\mathbf {X}} ,\overline{\mathbf {Y}} )\) by Lemma 3.1, and both sets have the same efficient DMUs which span \(({\overline{\mathbf {x}}}_k ,{\overline{\mathbf {y}}}_k )\;\), we have:
This indicates that \(({\varvec{\lambda }}^*,{\mathbf {t}}^{-*}+(1-\sigma _k ){\mathbf {s}}_k^{-*} ,{\mathbf {t}}^{+*}+(1-\sigma _k ){\mathbf {s}}_k^{+*} )\) is feasible for (B.1), and hence its objective function value is not less than the optimal value, \(\theta _k^{\mathrm{{CRS}}} \).
Conversely, \({\mathbf {t}}^{-*} =\sigma _k {\mathbf {s}}_k^{-*}\,\text{ and }\,{\mathbf {t}}^{+*} =\sigma _k {\mathbf {s}}_k^{+*}\) are feasible for SAS, and hence it holds that \(\theta _k^{\mathrm{{SAS}}} =\theta _k^{\mathrm{{CRS}}} \,(k=1,\ldots ,n).\)
(Case 2) Multiple clusters exist.
In this case, we have additional constraints to (B.3) to define the cluster restriction, as follows:
Since adding constraints results in an increase of the objective value, it holds that:
\(\square \)
Proposition 3.2
If \(\theta _o^{\mathrm{{CRS}}} =1\), then it holds that \(\theta _o^{\mathrm{{SAS}}} =\theta _o^{\mathrm{{CRS}}} \), but not vice versa.
Proof
If \(\theta _k^{\mathrm{{CRS}}} =1\), then we have \({\mathbf {s}}_k^{-*} ={\mathbf {0}}\,\text{ and } {\mathbf {s}}_k^{+*} ={\mathbf {0}}\). Hence, we have total slacks=0 and \(\theta _k^{\mathrm{{SAS}}} =1\). The converse is not always true, as demonstrated in the example below, where all DMUs belong to an independent cluster.
DMU | (l)x | (O)y | Cluster |
|---|---|---|---|
A | 2 | 2 | a |
B | 4 | 2 | b |
C | 6 | 2 | c |
DMU | CRS-I | SAS-I | Cluster |
|---|---|---|---|
A | 1 | 1 | a |
B | 0.5 | 1 | b |
C | 0.3333 | 1 | c |
\(\square \)
Proposition 3.3
SAS decreases with increasing input and decreasing output so long as both DMUs remain in the same cluster.
Proof
Let \(( {{\mathbf {x}}_p,{\mathbf {y}}_p })\,\,\text{ and } ( {{\mathbf {x}}_{q},{\mathbf {y}}_q })\,\text{ with } {\mathbf {x}}_p \le {\mathbf {x}}_q \,\text{ and } {\mathbf {y}}_p \ge {\mathbf {y}}_q \) be the original and varied DMUs, respectively, in the same cluster. Let \({\mathbf {x}}_q ={\mathbf {x}}_p +{\varvec{\delta }}_p^- \;({\varvec{\delta }}_p^- \ge {\mathbf {0}}),{\mathbf {y}}_q ={\mathbf {y}}_p -{\varvec{\delta }}_p^+ \;({\varvec{\delta }}_p^+ \ge {\mathbf {0}})\) and the optimal solution for \(( {{\mathbf {x}}_{p},{\mathbf {y}}_p })\,\) be \((\theta _p^{\mathrm{{SAS}}},{\varvec{\lambda }}_p^*,{\mathbf {s}}_p^{-*},{\mathbf {s}}_p^{+*} )\). We have \({\mathbf {X}}{\varvec{\lambda }}_p^*+{\mathbf {s}}_p^{-*} ={\mathbf {x}}_p ={\mathbf {x}}_q -{\varvec{\delta }}_p^-, \quad {\mathbf {Y}}{\varvec{\lambda }}_p^*-{\mathbf {s}}_p^{+*} ={\mathbf {y}}_p ={\mathbf {y}}_q +{\varvec{\delta }}_p^+ \). Hence \(({\mathbf {s}}_p^{-*} +{\varvec{\delta }}_p^- ,{\mathbf {s}}_p^{+*} +{\varvec{\delta }}_p^+ )\)is a feasible slack for \(( {{\mathbf {x}}_{q},{\mathbf {y}}_q })\,\). We have
\(\square \)
Proposition 3.4
The projected DMU \((\overline{{\overline{{\mathbf {x}}}}}_k ,\overline{{\overline{{\mathbf {y}}}}}_k )\) is efficient under the SAS model among the DMUs in its containing cluster. It is CRS and VRS efficient among the DMUs in its cluster.
Proof
From the definition of \((\overline{{\overline{{\mathbf {x}}}}}_k ,\overline{{\overline{{\mathbf {y}}}}}_k )\), it is SAS efficient. Thus, it is CRS and VRS efficient in its cluster. \(\square \)
Proposition 5.1
Proof
This term is increasing in \(\sigma _k \) and is equal to 1 when \(\sigma _k \)=1. \(\square \)
Proposition 5.2
Proof
If \(\sigma _k =1\), it holds \(\theta _k^{scale} =\sigma _k +\theta _k^{\mathrm{{CCR}}} -\sigma _k \theta _k^{\mathrm{{CCR}}} =1.\) Conversely, if \(\theta _k^\mathrm{{scale}} =\sigma _k +\theta _k^{\mathrm{{CCR}}} -\sigma _k \theta _k^{\mathrm{{CCR}}} =1\), we have \(\sigma _k (1-\theta _k^{\mathrm{{CCR}}} )=1-\theta _k^{\mathrm{{CCR}}} \). Hence, if \(\theta _k^{\mathrm{{CCR}}} <1\), then it holds \(\sigma _k =1.\) If \(\theta _k^{\mathrm{{CCR}}} =1\), then we have \(\theta _k^{\mathrm{{BCC}}} =1\;\text{ and }\,\sigma _k =1.\) \(\square \)
Rights and permissions
About this article

Cite this article
Tone, K., Tsutsui, M. How to Deal with Non-Convex Frontiers in Data Envelopment Analysis. J Optim Theory Appl 166, 1002–1028 (2015). https://doi.org/10.1007/s10957-014-0626-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-014-0626-3
Keywords
- Data envelopment analysis
- S-shaped curve
- Constant returns-to-scale
- Variable returns-to-scale
- Scale elasticity