
Abstract
Performance is an open issue in data intensive applications (e.g. data mining tasks). Parallel and distributed computing systems (e.g. multicore computing, grid computing, cloud computing,etc.), along with hybrid programming models (e.g. MapReduce, MPI, etc.), is seen a sought-after solution for accelerating data-intensive applications. One of main challenges is how to exploit these advanced technologies effectively in facilitating fundamental science discoveries such as those in Biomedical Sciences. This paper explores how MapReduce and Cloud computing can accelerate performance of data intensive applications through a real data mining use case in the Biomedical Sciences. We have first adapted the data mining task using MapReduce model and then deployed it onto the Cloud. We have built an analytic model based on the MapReduce computations to evaluate the efficiency and performance of the prototype. The results, from both experiments and the evaluation model, show the performance and scalability can be enhanced through these advanced technologies.








Similar content being viewed by others
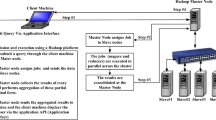
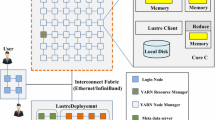
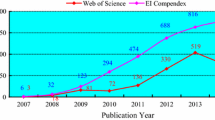
References
Amazon: Amazon elastic compute cloud. http://aws.amazon.com/ec2 (2013). Accessed on 23 Dec 2013
Apache: Apache hadoop. http://hadoop.apache.org/core/ (2013). Accessed on 23 Dec 2013
Arpaci-Dusseau, R.H., Anderson, E., Treuhaft, N., Culler, D.E., Hellerstein, J.M., Patterson, D., Yelick, K.: Cluster i/o with river: making the fast case common. In: Proceedings of the Sixth Workshop on I/O in Parallel and Distributed Systems, pp. 10–22. ACM, New York (1999)
Atkinson, M., van Hemert, J., Han, L., Hume, A., Liew, C.S.: A Distributed Architecture for Data Mining and Integration, pp. 11–20. ACM, New York (2009)
Beynon, M.D., Kurc, T., Catalyurek, U., Chang, C., Sussman, A., Saltz, J.: Distributed processing of very large datasets with DataCutter. Parallel Comput. 27, 1457–1478 (2001)
Cellknn: Cell-knn: an implementation of the knn algorithm on sti’s cell processor. http://code.google.com/p/cell-knn/ (2011) Accessed on 19 April 2014
Condor DAGMan (directed acyclic graph manager): http://www.cs.wisc.edu/condor/dagman (2007) Accessed on 19 April 2014
Cover, T., Hart, P.: Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 30(1), 21–27 (1967)
DB2: IBM DB2: http://www-01.ibm.com/software/data/db2/ (2013). Accessed on 23 Dec 2013
Dean, J., Ghemawat, S.: MapReduce: Simplified data processing on large clusters. In: Proceedings of the 6th Symposium on Operating Systems Design and Implementation (OSDI), pp. 137–150 (2004).
Deelman, E., Singh, G., Su, M.H., Blythe, J., Gil, Y., Kesselman, C., Mehta, G., Vahi, K., Berriman, G.B., Good, J., Laity, A.C., Jacob, J.C., Katz, D.S.: Pegasus: a framework for mapping complex scientific workflows onto distributed systems. Sci. Program. 13(3), 219–237 (2005)
Disco: Disco mapreduce framework. http://discoproject.org/ (2013). Accessed on 23 Dec 2013
Duda, R.O., Hart, P.E.: Pattern Classification and Scene Analysis. Wiley, New York (1973)
Gokhale, M., Cohen, J., Yoo, A., Miller, W.: Hardware technologies for high-performance data-intensive computing. IEEE Comput. 41(4), 60–68 (2008)
Gorton, I., Greenfield, P., Szalay, A., Williams, R.: Data-intensive computing in the 21st century. Computer 41(4), 30–32 (2008)
Han, L., Saengngam, T., van Hemert, J.: Accelerating data-intensive applications: a cloud computing approach to parallel image pattern recognition tasks. In: W. Gentzsch, P. Lorenz, O. Dini (eds.) ADVCOMP 2010: The Fourth International Conference on Advanced Engineering Computing and Applications in Sciences, 978-1-61208-101-4, pp. 148–153. IARIA (2010)
Han, L., van Hemert, J., Baldock, R.: Automatically identifying and annotating mouse embryo gene expression patterns. Bioinformatics 27(8), 1101–1107 (2011)
Han, L., Liew, C.S., van Hemert, J.I., Atkinson, M.P.: A generic parallel processing model for facilitating data mining and data integration. J. Parallel Comput. 37(1), 157–171 (2011)
Hey, T., Tansley, S., Tolle, K.: The Fourth Paradigm: Data-Intensive Scientific Discovery, 1st edn. Microsoft Research, Redmond (2009)
IDC digital universe study: Big data is here, now what? Accessed on 23 Dec 2013
Jin, R., Agrawal., G.: A middleware for developing parallel data mining implementations. In: Proceedings of the First SIAM Conference on Data Mining (Apr, 2001)
Jin, R., Yang, G., Agrawal, G.: Shared memory parallelization of data mining algorithms: techniques, programming interface, and performance. IEEE Trans. Knowl. Data Eng. 17(1), 71–89 (2005)
Laszewski, G., Hategan, M.: Workflow concepts of the Java Cog Kit. Grid Comput. 3(3–4), 239–258 (2005)
Laszewski, G., Hategan, M.: Java CoG Kit Karajan-Gridant Workflow Guide. Technical Report. Argonne National Laboratory, Argonne (2005)
LINQ: The LINQ project. http://msdn.microsoft.com/netframework/future/linq/ Accessed on 19 April 2014
Microsoft: http://research.microsoft.com/en-us/projects/Dryad/ (2013). Accessed on 23 Dec 2013
Oinn, T., Greenwood, M., Addis, M., Alpdemir, N., Ferris, J., Glover, K., Goble, C., Goderis, A., Hull, D., Marvin, D., Li, P., Lord, P., Pocock, M., Senger, M., Stevens, R., Wipat, A., Wroe, C.: Taverna: lessons in creating a workflow environment for the life sciences. Concurr. Comput. 18(10), 1067–1100 (2006). doi:10.1002/cpe.v18:10
Pacheco, P.S.: Parallel Programming with MPI. Morgan Kaufmann Publishers, Inc., San Francisco (1997)
Pike, R., Dorward, S., Griesemer, R., Quinlan, S.: Interpreting the data: Parallel analysis with Sawzal. Sci. Program. 13(4), 277–298 (2005)
PVM: http://www.csm.ornl.gov/pvm/ (2013). Accessed on 23 Dec 2013
Raicu, I., Zhao, Y., Dumitrescu, C., Ian Foster, M.W.: Falkon: a fast and light-weight task execution framework. In: IEEE/ACM SC 2007 (2007)
Raicu, I., Zhao, Y., Foster, I., Szalay, A.: Accelerating large-scale data exploration through data diffusion. In: International Workshop on Data-Aware Distributed Computing 2008. IEEE Computer Scociety (2008)
t Grossman, R., Gu, Y.: Data mining using high performance clouds: Experimental studies using sector and sphere. In: Proceedings of The 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, New York (2008)
Taylor, I., Shields, M., Wang, I., Harrison, A.: The Triana Workflow Environment: architecture and applications. In: I. Taylor, E. Deelman, D. Gannon, M. Shields (eds.) Workflows for e-Science, pp. 320–339. Springer, London (2007)
Teradata: http://www.teradata.com/ (2013). Accessed on 23 Dec 2013
Vertica: http://www.vertica.com/ (2013). Accessed on 23 Dec 2013
Wang, L., Tao, J., Ma, Y., Khan, S.U., Kolodziej, J., Chen, D.: Software design and implementation for MapReduce across distributed data centers. Appl. Math. Inf. Sci. 7(1), 85–90 (2013)
Zhao, Y., Hategan, M., Clifford, B., Foster, I., von Laszewski, G., Nefedova, V., Raicu, I., Stef-Praun, T., Wilde, M.: Swift: Fast, reliable, loosely coupled parallel computation. In: IEEE Congress on Services (Services 2007), pp. 199–206 (2007)
Acknowledgments
The authors acknowledge the support of the EurExpress team (EU-FP6 funding) at the MRC Human Genetics Unit, UK, a BBSRC funded Project (Agile) and Amazon EC2 on the continuation of this work. The authors would also like to thank the anonymous reviewers, who provided detailed and constructive comments on an earlier version of this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Han, L., Ong, H.Y. Parallel data intensive applications using MapReduce: a data mining case study in biomedical sciences. Cluster Comput 18, 403–418 (2015). https://doi.org/10.1007/s10586-014-0405-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10586-014-0405-9