
Abstract
Objectives
Radiomic features have demonstrated encouraging results for non-invasive detection of molecular biomarkers, but the lack of guidelines for pre-processing MRI-data has led to poor generalizability. Here, we assessed the influence of different MRI-intensity normalization techniques on the performance of radiomics-based models for predicting molecular glioma subtypes.
Methods
Preoperative MRI-data from n = 615 patients with newly diagnosed glioma and known isocitrate dehydrogenase (IDH) and 1p/19q status were pre-processed using four different methods: no normalization (naive), N4 bias field correction (N4), N4 followed by either WhiteStripe (N4/WS), or z-score normalization (N4/z-score). A total of 377 Image-Biomarker-Standardisation-Initiative-compliant radiomic features were extracted from each normalized data, and 9 different machine-learning algorithms were trained for multiclass prediction of molecular glioma subtypes (IDH-mutant 1p/19q codeleted vs. IDH-mutant 1p/19q non-codeleted vs. IDH wild type). External testing was performed in public glioma datasets from UCSF (n = 410) and TCGA (n = 160).
Results
Support vector machine yielded the best performance with macro-average AUCs of 0.84 (naive), 0.84 (N4), 0.87 (N4/WS), and 0.87 (N4/z-score) in the internal test set. Both N4/WS and z-score outperformed the other approaches in the external UCSF and TCGA test sets with macro-average AUCs ranging from 0.85 to 0.87, replicating the performance of the internal test set, in contrast to macro-average AUCs ranging from 0.19 to 0.45 for naive and 0.26 to 0.52 for N4 alone.
Conclusion
Intensity normalization of MRI data is essential for the generalizability of radiomic-based machine-learning models. Specifically, both N4/WS and N4/z-score approaches allow to preserve the high model performance, yielding generalizable performance when applying the developed radiomic-based machine-learning model in an external heterogeneous, multi-institutional setting.
Clinical relevance statement
Intensity normalization such as N4/WS or N4/z-score can be used to develop reliable radiomics-based machine learning models from heterogeneous multicentre MRI datasets and provide non-invasive prediction of glioma subtypes.
Key Points
• MRI-intensity normalization increases the stability of radiomics-based models and leads to better generalizability.
• Intensity normalization did not appear relevant when the developed model was applied to homogeneous data from the same institution.
• Radiomic-based machine learning algorithms are a promising approach for simultaneous classification of IDH and 1p/19q status of glioma.
Similar content being viewed by others
Introduction
Gliomas are the most common malignant primary tumors of the central nervous system in adults and are currently stratified based on both histology and molecular markers according to the 2021 WHO Classification, where the IDH status and the 1p19q codeletion currently represent the most relevant mutations [1, 2].
There have been numerous attempts to find non-invasive radiological markers for these mutations since their inclusion in the WHO classification, both through purely visual assessment techniques [3] and through advanced imaging sequences such as perfusion-weighted or diffusion-weighted imaging with varying results [4, 5]. Radiomic features have recently demonstrated a convincing performance for non-invasive detection of mutations [6,7,8,9,10] but have also come under scrutiny due to a lack of reporting standards [11, 12].
This is particularly relevant for MRI-based features, since voxel values are not based on a standardized scale but rather on arbitrary intensity values that can vary based on the device manufacturer, field strength, sequence acquisition parameters, and type, thus differing not only between patients but also between examinations of the same patient [13]. Understandably, this can affect the extraction of radiomics and hinder the reproducibility and/or comparability of results, and intensity normalization is a necessary step according to the TRIPOD/RQS Guidelines [11, 12].
Previous studies have focused on assessing the impact of various pre-processing steps onto the signal intensity and the resulting radiomic features, for example, demonstrating that bias field correction reduces the inhomogeneity within a tissue [14], and that skull-stripping can remove the regions with the greatest intensity fluctuations [15]. Even though there is a consensus on the general steps required in a radiomics pre-processing pipeline [11, 16], there is still no agreement onto which specific methodology might be the most indicated for each of them [17]. Previous studies have investigated the impact of intensity normalization on the reproducibility of radiomics, but none have compared different intensity normalization approaches on the predictive power of machine learning algorithms for the detection of radiogenomic phenotypes of brain tumors [17].
In this study, we evaluated the impact of intensity normalization on multiclass models for simultaneous prediction of IDH and 1p19q status in gliomas and verified the generalizability of the models on two external, publicly available datasets from The Cancer Genome Atlas (TCGA) project and the University of California San Francisco (UCSF).
Material and methods
The retrospective study was approved by the internal ethics committee, and the requirement to obtain informed consent was waived (S-784 2018).
Consecutive adult patients with confirmed diagnosis of glioma according to the WHO 2021 Classification and who received preoperative MRI at the Department of Neuroradiology of the Heidelberg University Hospital (Heidelberg, Germany) between 03/2009 and 07/2020 were included in the study (n = 621). IDH and 1p/19q status based on DNA methylation assay was available for all patients [18]. Ultimately, n = 3 cases were excluded due to insufficient quality of MRI images (e.g., motion artifacts, which prevented an adequate tumor segmentation) and n = 3 due to errors in data processing, resulting in an internal dataset of n = 615 patients in total. The internal dataset (HD) was acquired during routine clinical examination using a 3-T MRI machine (Magnetom Verio, Trio TIM or Skyra, Siemens Healthcare). The imaging protocol was performed according to international guidelines and included 3D T1-weighted images both before (T1) and after (cT1) administration of a bolus of 0.1 mmol/kg gadoterate meglumine (Dotarem, Guerbet), as well as axial 2D FLAIR and T2-weighted images [19]; a detailed description of the MRI acquisition parameters is available in the Supplementary Methods and Materials.
External testing was performed using two publicly available preoperative MRI datasets of glioma, namely the public dataset from TCGA database with 242 patients and the UCSF dataset with 501 patients [20, 21]. From the TCGA dataset, n = 41 cases were removed due to insufficient quality of MRI images, n = 29 cases due to unknown IDH or 1p/19q status, and n = 12 due to failed intensity normalization, so that the TCGA dataset ultimately comprised n = 160 patients. From the UCSF dataset, n = 91 cases were removed due to unknown 1p/19q status, ultimately including n = 410 patients. As in the training dataset, data in the external validation included T1-weighted images before and after contrast administration, FLAIR, and T2 weighted images. Information on the sequences included in the datasets is found at https://doi.org/10.7937/tcia.bdgf-8v37.
Image pre-processing and tumor segmentation
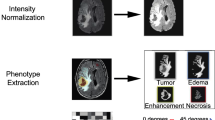
Images from the HD and TCGA dataset were processed using publicly available and validated software as previously described [22, 23]. Briefly, this included (i) neural-network-based brain extraction through the HD-BET tool (https://github.com/MIC-DKFZ/HD-BET) [24], (ii) rigid registration of the image volumes to the native T1-w image using FSL (FMRIB), and (iii) automated deep-learning based tumor segmentation into the contrast-enhancing, T2-FLAIR, and necrotic components of the tumor using a variant of HD-GLIO (https://github.com/NeuroAI-HD/HD-GLIO). The segmentations were visually reviewed and, if necessary, corrected by MF (neuroradiology resident with 5 years of experience).
The UCSF dataset consisted of pre-processed sequences as well as a multicompartment tumor segmentation including enhancing tumor, and T2/FLAIR hyperintense as well as non-enhancing/necrotic tumor compartments, downloaded through https://doi.org/10.7937/tcia.bdgf-8v37 [21].
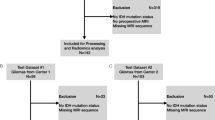
For each sequence, four normalization approaches were compared: (1) no normalization (naive), (2) N4 bias field correction (N4), (3) N4 bias field correction followed by WhiteStripe normalization (N4/WS), and (4) N4 bias field correction followed by Z-score normalization (N4/z-score). Figure 1 shows a schematic representation of the study structure. Detailed descriptions of the different normalization methods can be found in Supplementary Methods and Materials. Both the Z-score and WhiteStripe are freely available normalization methods that are commonly used in MRIs of the brain [25]. N4 bias field correction, as well as Z-score and WhiteStripe normalization were performed using the ANTsR and WhiteStripe packages implemented in R (R version 4.0.2., R Foundation for Statistical Computing, https://github.com/muschellij2/WhiteStripe).

Schematic representation of the study structure. Four different conditions were compared: no normalization (naive), N4 bias field correction (N4), N4 bias field correction followed by white stripe normalization (N4/WS), and N4 bias field correction followed by z-score normalization (N4/z-score). For each of the conditions, radiomics were extracted from all four sequences (T1 before and after contrast, T2, and FLAIR) from each of the three data sets. Using the training dataset from HD (n = 492), 9 different machine learning models were trained for each condition and validated using the holdout test dataset (n = 123). External validation was performed using TCGA (n = 160) and UCSF data set (n = 410)
Radiomic feature extraction and selection
Feature extraction and selection was performed in Python (version 3.8.5) using PyRadiomics (https://pyradiomics.readthedocs.io) [9]. For the feature extraction the different segmentation masks of contrast-enhancing, T2-FLAIR and necrotic components of the tumor were combined into one, so the radiomics were extracted from the whole tumor. All reproducible radiomic features according to the Image Biomarker Standardisation Initiative were calculated on all used anatomical sequences. This included 13 shape-based, 17 first order, 23 Gy-level co-occurrence matrix, 16 Gy-level run length matrix, 16 Gy-level size zone matrix, 14 Gy-level dependence matrix, and 5 neighboring gray tone difference matrix. A list of all extracted radiomics is shown in Supplementary Table 1. As radiomics based on the morphology of the tumor are the same for all four sequences, shape features were only kept from the T1 pre-contrast sequence, resulting in a total of 377 radiomics for each intensity normalization approach in each dataset.
Data analysis
The HD dataset was divided into a training and test set with 80:20 split and by maintaining a similar distribution across the three classes in both datasets.
Feature selection was performed to avoid overfitting using ANOVA F-statistics on the training data of the HD dataset. Here, an ANOVA was performed for each feature to classify the three different tumor classes, and the result were given as F-statistic. For the final models, we then used the five radiomic features with the highest F-statistic [26].
Machine learning models were built with the scikit-learn library in Python (version 3.8.5). We compared nine different algorithms, namely Logistic Regression, Linear Discriminant Analysis, k-nearest neighbor, Decision Tree, Gaussian naïve Bayes, C-Support Vector Classification, Random Forest, Extra-trees Classifier, and eXtreme Gradient Boosting. To avoid potential bias when comparing the different normalization approaches, we did not perform hyperparameter tuning like grid search, but instead used the default setting for each model.
Undersampling of the IDH-wt group and SMOTE oversampling of the IDH-mut group was performed to balance the training data set.
Models were evaluated with areas under the receiver operating characteristic curve (AUC), and sensitivity, specificity, and accuracy as target parameters (Supplementary Table 2–4). Confusion matrices matrices of various classifiers can be found in Supplementary Table 8. Confidence intervals were calculated using bootstrapping (Supplementary Fig. 4). DeLong’s test was used to compare AUC of the models. Subsequently, the p values were corrected for each data set individually using false discovery rate (FDR) correction. All corrected p values of the individual classes for each data set are shown in Supplementary Table 5–7. Kruskal–Wallis test was used to compare continuous and chi-square test was used to compare categorical data. A p value < 0.05 was considered significant for all analyses.
Results
The HD dataset consists of n = 442 IDH wild-type (IDH-wt) gliomas, n = 89 IDH-mutated and 1p/19q non-codeleted (IDH-mut 1p/19q non-codel) gliomas as well as n = 84 IDH-mutated and 1p19q codeleted (IDH-mut 1p/19q codel) gliomas. The full characteristics of the included patients from each of the three datasets are summarized in Table 1.
We tested nine different machine learning algorithms. Among these, the support vector machine (SVM) model showed the best performance, with a macro-average AUC for the multi-class detection of molecular characteristics of 0.84 (95% CI = 0.75–0.89) using naive data, 0.84 (95% CI = 0.76–0.90) using N4, 0.87 (95% CI = 0.80–0.91) using N4/WS, and 0.87 (95% CI = 0.81–0.91) using N4/z-score in the HD test set. The individual detection rates for each of the molecular mutation classes were 0.87 (95% CI = 0.76–0.93) (naive), 0.86 (95% CI = 0.77–0.93) (N4), 0.90 (95% CI = 0.84–0.94) (N4/WS), and 0.91 (95% CI = 0.85–0.95) (N4/z-score) for the IDH-wt class, 0.82 (95% CI = 0.64–0.91) (naive), 0.79 (95% CI = 0.60–0.88) (N4), 0.84 (95% CI = 0.75–0.91) (N4/WS), and 0.86 (95% CI = 0.78–0.92) (N4/z-score) for the IDH-mut 1p/19q non-codel class, and 0.82 (95% CI = 0.73–0.89) (naive), 0.85 (95% CI = 0.77–0.92) (N4), 0.86 (95% CI = 0.77–0.92) (N4/WS), and 0.84 (95% CI = 0.75–0.90) (N4/z-score) for the IDH-mut 1p/19q codel class (Fig. 2), without a significant difference in model performance when comparing the different types of normalization approaches (FDR-adjusted p ≥ 0.19 each) (Supplementary Table 5–7). The ROC curves obtained with the eight other tested models are shown in Supplementary Fig. 1–3. The respective accuracy values including the 95% CI are shown in Supplementary Fig. 4.

Support vector machine model performance on holdout test dataset (n = 123) of HD to classify IDH-wt vs. IDH-mut 1p/19q codel vs. IDH-mut 1p/19q non-codel via radiomic features across normalization conditions (Naiv, no-normalization; N4, N4 bias field correction; N4/WS, N4 bias field correction followed by white stripe normalization; and N4/z-score, N4 bias field correction followed by Z-score normalization)
When applying the developed SVM model to the external TCGA data, the macro-average AUC changed from 0.45 (95% CI = 0.35–0.54) using naive to 0.52 (95% CI = 0.43–0.61) using N4, 0.85 (95% CI = 0.76–0.89) using N4/WS, and 0.87 (95% CI = 0.80–0.91) using N4/z-score. The individual detection rates for each of the molecular mutation classes were 0.41 (95% CI = 0.33–0.50) (naive), 0.47 (0.38–0.56) (N4), 0.89 (0.82–0.94) (N4/WS), and 0.90 (95% CI = 0.84–0.95) (N4/z-score) for the IDH-wt class; 0.39 (95% CI = 0.29–0.49) (naive), 0.49 (95% CI = 0.39–0.59) (N4), 0.88 (95% CI = 0.81–0.92) (N4/WS), and 0.91 (95% CI = 0.85–0.94) (N4/z-score) for the IDH-mut 1p/19q non-codel class; and 0.55 (95% CI = 0.39–0.75) (naive), 0.58 (95% CI = 0.39–0.73) (N4), 0.77 (95% CI = 0.59–0.86) (N4/WS), and 0.79 (95% CI = 0.61–0.89) (N4/z-score) for the IDH-mut 1p/19q codel class (Fig. 3A). Both the prediction of IDH-wt and IDH-mut 1p/19q non-codel classes showed higher performance for N4/WS and N4/z-score as compared to approaches without normalization (FDR-adjusted p < 0.0001 each) as well as to N4 alone (FDR-adjusted p < 0.0001 each), whereas no difference was found for the IDH-mut 1p/19q codel class (FDR-adjusted p ≥ 0.07 each). In all three groups, there was no performance difference between N4/WS and N4/z-score (FDR-adjusted p ≥ 0.24 each).

ROC curves of support vector machine model of external validation with TCGA (A) and UCSF data set (B) to differentiate between IDH-wt vs. IDH-mut 1p/19q codel vs. IDH-mut 1p/19q non-codel across different normalization conditions (Naiv, no-normalization; N4, N4 bias field correction; N4/WS, N4 bias field correction followed by white stripe normalization; and N4/z-score, N4 bias field correction followed by Z-score normalization)
When applying the developed SVM model to the external UCSF data, the macro-average AUC changed from 0.19 (95% CI = 0.15–0.25) using naive to 0.26 (95% CI = 0.20–0.31) using N4, 0.87 (95% CI = 0.82–0.90) using N4/WS, and 0.86 (95% CI = 0.80–0.89) using N4/z-score. The individual detection rates for each of the molecular mutation classes were 0.18 (95% CI = 0.14–0.23) (naive), 0.25 (95% CI = 0.20–0.31) (N4), 0.89 (95% CI = 0.84–0.92) (N4/WS), and 0.92 (95% CI = 0.87–0.94) (N4/z-score) for the IDH-wt class; 0.21 (95% CI = 0.16–0.26) (naive), 0.29 (95% CI = 0.23–0.34) (N4), 0.86 (95% CI = 0.81–0.90) (N4/WS), and 0.81 (95% CI = 0.76–0.86) (N4/z-score) for the IDH-mut 1p/19q non-codel class; and 0.18 (95% CI = 0.10–0.30) (naive), 0.22 (95% CI = 0.12–0.35) (N4), 0.84 (95% CI = 0.70–0.91) (N4/WS), and 0.85 (95% CI = 0.65–0.91) (N4/z-score) for the IDH-mut 1p/19q codel class (Fig. 3B). All three molecular mutation classes showed significantly higher performance for N4/WS and N4/z-score as compared to no normalization (FDR-adjusted p < 0.0001 each) as well as to N4 alone (FDR-adjusted p < 0.0001 each). There was no significant performance difference between N4/WS and N4/z-score in the IDH-mut 1p/19q codel group (FDR-adjusted p = 0.84). In the IDH-mut 1p/19q non-codel group the N4/WS (AUC = 0.86) outperformed the N4/z-score (AUC = 0.81) approach (FDR-adjusted p = 0.009). On the other hand, in the IDH-wt group the N4/z-score (AUC = 0.92) outperformed the N4/WS (AUC = 0.89) approach (FDR-adjusted p = 0.024).
Discussion
Radiomic prediction of molecular subtypes of glioblastoma is a promising and clinically highly relevant field of research. The lack of standardized processing is negatively impacting the diffusion of radiomics by limiting their generalizability. Here, we investigated the relevance of intensity normalization as an important pre-processing step in MRI radiomics extraction and its potential influence on the predictive power of machine learning algorithms. We could demonstrate that while the model performance was not influenced by the intensity normalization of the MR images when using an internal test, however the performance depended on intensity normalization when applying the models in an external heterogeneous, multi-institutional setting. Furthermore, we were able to show that radiomic-based machine learning algorithms are a promising approach for simultaneous classification of IDH and 1p/19q status of glioma.
Our results highlight the importance of intensity normalization for removing the scanner-dependent signal intensity changes to build generalizable radiomic-based prediction models, which becomes essential when applying these models to previously unseen, heterogeneous multicenter cohorts. Although no clear consensus has emerged as to which approach is the most reliable intensity normalization approach [27], we have shown that both N4/z-score and N4/white-stripe yield comparable results, allowing to build generalizable radiomic-based models for predicting molecular glioma subtypes, in contrast to N4 or naive approaches which significantly limited the generalizability of these models.
In addition to the relevance of intensity normalization, we showed that radiomics-based models can perform well for simultaneous prediction of IDH and 1p/19q status in gliomas. Previous studies primarily focused on separated binary classification of IDH-mutations and/or 1p19q status in gliomas [4, 28] which may however yield inconsistent predictions not in accordance with the current WHO classification of CNS tumors (e.g., prediction of 1p19q codeletion in the setting of IDH wild-type tumors). We circumvented this by implementing a multiclass model which directly predicts the molecular glioma subtypes, i.e., classifying cases as either IDH-wt, or IDH-mut 1p19q code, or IDH-mut 1p19q non-codel. Similarly, Cluceru and colleagues previously presented a multiclass model for the simultaneous classification of IDH and 1p/19q status [7] which yielded an overall test accuracy of 85.7%. However, their model relied on a more sophisticated neural network–based approach and additionally required diffusion-weighted imaging as input modality, thereby potentially limiting clinical applicability.
Our study has some limitations. First, we restrict ourselves to the anatomical MRI sequences and do not investigate functional MRI sequences such as diffusion and perfusion which may allow to further improve the performance when predicting molecular glioma subtypes [29, 30]. However, in contrast to anatomical sequences, functional sequences are not represented in arbitrary but absolute values and are thus comparable, even though the influence of normalization on functional MRI sequences should be part of further research. Second, we did not perform hyperparameter tuning, e.g., through grid search which may allow to improve the model performance, but instead kept the model parameters constant to eliminate potential bias when assessing the model performance of different sequence normalization approaches. Third, both Z-score and WhiteStripe normalization are quite similar methods, and we did not compare novel ones such as convolutional neural network–based methods [31]. However, as these two methods are among the most widely used in radiomic research [32] and there are hardly any publications that compare two or more standardization methods, this study provides a valid basis and the comparison to novel methods needs to be explored in the future.
In conclusion, in this study we were able to develop a reliable multiclass model for the classification of glioma genetic subtypes and demonstrate the relevance of intensity normalization of MR images to increase the generalizability of this models.
Abbreviations
- CNN:
-
Convolutional neural network
- IBSI:
-
Image Biomarker Standardisation Initiative
- IDH:
-
Isocitrate dehydrogenase
- NAWM:
-
Normal-appearing white matter
- ROI:
-
Region of Interest
- RQS:
-
Radiomics Quality Score
- TCGA:
-
The Cancer Genome Atlas
- TRIPOD:
-
Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis
- UCSF:
-
University of California San Francisco
- WHO:
-
World Health Organization
References
Ostrom QT, Gittleman H, Liao P et al (2017) CBTRUS Statistical Report: Primary brain and other central nervous system tumors diagnosed in the United States in 2010–2014. Neuro Oncol 19:v1–v88
Louis DN, Perry A, Wesseling P et al (2021) The 2021 WHO Classification of Tumors of the Central Nervous System: a summary. Neuro Oncol 23:1231–1251
Foltyn M, Nieto Taborda KN, Neuberger U et al (2020) T2/FLAIR-mismatch sign for noninvasive detection of IDH-mutant 1p/19q non-codeleted gliomas: validity and pathophysiology. Neurooncol Adv 2:vdaa004
Cindil E, Sendur HN, Cerit MN et al (2022) Prediction of IDH mutation status in high-grade gliomas using DWI and high T1-weight DSC-MRI. Acad Radiol 29(Suppl 3):S52–S62
Leu K, Ott GA, Lai A et al (2017) Perfusion and diffusion MRI signatures in histologic and genetic subtypes of WHO grade II-III diffuse gliomas. J Neurooncol 134:177–188
Bhandari AP, Liong R, Koppen J, Murthy SV, Lasocki A (2021) Noninvasive determination of IDH and 1p19q status of lower-grade gliomas using MRI radiomics: a systematic review. AJNR Am J Neuroradiol 42:94–101
Cluceru J, Interian Y, Phillips JJ et al (2022) Improving the noninvasive classification of glioma genetic subtype with deep learning and diffusion-weighted imaging. Neuro Oncol 24:639–652
Lu CF, Hsu FT, Hsieh KL et al (2018) Machine learning-based radiomics for molecular subtyping of gliomas. Clin Cancer Res 24:4429–4436
van Griethuysen JJM, Fedorov A, Parmar C et al (2017) Computational radiomics system to decode the radiographic phenotype. Cancer Res 77:e104–e107
Zhou H, Vallieres M, Bai HX et al (2017) MRI features predict survival and molecular markers in diffuse lower-grade gliomas. Neuro Oncol 19:862–870
Park JE, Kim D, Kim HS et al (2020) Quality of science and reporting of radiomics in oncologic studies: room for improvement according to radiomics quality score and TRIPOD statement. Eur Radiol 30:523–536
Park JE, Kim HS, Kim D et al (2020) A systematic review reporting quality of radiomics research in neuro-oncology: toward clinical utility and quality improvement using high-dimensional imaging features. BMC Cancer 20:29
Collewet G, Strzelecki M, Mariette F (2004) Influence of MRI acquisition protocols and image intensity normalization methods on texture classification. Magn Reson Imaging 22:81–91
Moradmand H, Aghamiri SMR, Ghaderi R (2020) Impact of image preprocessing methods on reproducibility of radiomic features in multimodal magnetic resonance imaging in glioblastoma. J Appl Clin Med Phys 21:179–190
Zinn PO, Singh SK, Kotrotsou A et al (2018) A coclinical radiogenomic validation study: conserved magnetic resonance radiomic appearance of periostin-expressing glioblastoma in patients and xenograft models. Clin Cancer Res 24:6288–6299
Zwanenburg A, Vallieres M, Abdalah MA et al (2020) The Image Biomarker Standardization Initiative: standardized quantitative radiomics for high-throughput image-based phenotyping. Radiology 295:328–338
Fatania K, Mohamud F, Clark A et al (2022) Intensity standardization of MRI prior to radiomic feature extraction for artificial intelligence research in glioma-a systematic review. Eur Radiol. https://doi.org/10.1007/s00330-022-08807-2
Capper D, Jones DTW, Sill M et al (2018) DNA methylation-based classification of central nervous system tumours. Nature 555:469–474
Ellingson BM, Bendszus M, Boxerman J et al (2015) Consensus recommendations for a standardized Brain Tumor Imaging Protocol in clinical trials. Neuro Oncol 17:1188–1198
Calabrese E, Villanueva-Meyer JE, Rudie JD et al (2022) The University of California San Francisco preoperative diffuse glioma MRI dataset. Radiol Artif Intell 4:e220058
Clark K, Vendt B, Smith K et al (2013) The Cancer Imaging Archive (TCIA): maintaining and operating a public information repository. J Digit Imaging 26:1045–1057
Kickingereder P, Isensee F, Tursunova I et al (2019) Automated quantitative tumour response assessment of MRI in neuro-oncology with artificial neural networks: a multicentre, retrospective study. Lancet Oncol 20:728–740
Jayachandran Preetha C, Meredig H, Brugnara G et al (2021) Deep-learning-based synthesis of post-contrast T1-weighted MRI for tumour response assessment in neuro-oncology: a multicentre, retrospective cohort study. Lancet Digit Health 3:e784–e794
Isensee F, Schell M, Pflueger I et al (2019) Automated brain extraction of multisequence MRI using artificial neural networks. Hum Brain Mapp 40:4952–4964
Stamoulou E, Spanakis C, Manikis GC et al (2022) Harmonization strategies in multicenter MRI-based radiomics. J Imaging 8(11):303
Elssied NOF, Ibrahim O, Osman AH (2014) A novel feature selection based on one-way ANOVA F-test for E-mail spam classification. Res J Appl Sci Eng Technol 7:625–638
Fatania K, Mohamud F, Clark A et al (2022) Intensity standardization of MRI prior to radiomic feature extraction for artificial intelligence research in glioma-a systematic review. Eur Radiol 32:7014–7025
van der Voort SR, Incekara F, Wijnenga MMJ et al (2019) Predicting the 1p/19q codeletion status of presumed low-grade glioma with an externally validated machine learning algorithm. Clin Cancer Res 25:7455–7462
Zhang L, Min Z, Tang M, Chen S, Lei X, Zhang X (2017) The utility of diffusion MRI with quantitative ADC measurements for differentiating high-grade from low-grade cerebral gliomas: evidence from a meta-analysis. J Neurol Sci 373:9–15
Kim M, Jung SY, Park JE et al (2020) Diffusion- and perfusion-weighted MRI radiomics model may predict isocitrate dehydrogenase (IDH) mutation and tumor aggressiveness in diffuse lower grade glioma. Eur Radiol 30:2142–2151
DeSilvio T, Moroianu S, Bhattacharya I, Seetharaman A, Sonn G, Rusu M (2021) Intensity normalization of prostate MRIs using conditional generative adversarial networks for cancer detection. In: Mazurowski MA, Drukker K, (eds) Medical Imaging 2021: Computer-Aided Diagnosis, pp 115970J
Hoebel KV, Patel JB, Beers AL et al (2021) Radiomics repeatability pitfalls in a scan-rescan MRI study of glioblastoma. Radiol Artif Intell 3:e190199
Tustison NJ, Avants BB, Cook PA et al (2010) N4ITK: improved N3 bias correction. IEEE Trans Med Imaging 29:1310–1320
Shinohara RT, Sweeney EM, Goldsmith J et al (2014) Statistical normalization techniques for magnetic resonance imaging. Neuroimage Clin 6:9–19
Chaddad A, Kucharczyk MJ, Daniel P et al (2019) Radiomics in glioblastoma: current status and challenges facing clinical implementation. Front Oncol 9:374
Funding
Open Access funding enabled and organized by Projekt DEAL. MF, MS, and GB were funded by the Physician-Scientist Program of Heidelberg University, Faculty of Medicine. Parts of this work were also funded by the Deutsche Forschungsgemeinschaft (the German Research Foundation; project identifier 404521405 [SFB 1389—UNITE Glioblastoma, Work Package C02], project identifier 402688427/428223917 [Priority Programme 2177 Radiomics: Next Generation of Biomedical Imaging, KI 2410/1–1, MA 6340/18–1, MA 6340/18-2, VO 2801/1-2]). PV is funded through an Else Kröner Clinician Scientist Endowed Professorship by the Else Kröner Fresenius Foundation (reference number: 2022_EKCS.17).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Guarantor
The scientific guarantor of this publication is Philipp Vollmuth.
Conflict of interest
The authors of this manuscript declare no relationships with any companies whose products or services may be related to the subject matter of the article.
Statistics and biometry
One of the authors (PV and MFD) has significant statistical expertise.
Informed consent
Written informed consent was waived by the Institutional Review Board.
Ethical approval
Institutional Review Board approval was obtained.
Study subjects or cohorts overlap
No study subjects or cohorts have been previously reported.
Methodology
-
retrospective
-
diagnostic or prognostic study
-
multicenter study
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Gianluca Brugnara and Philipp Vollmuth share the last authorship.
Supplementary information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Foltyn-Dumitru, M., Schell, M., Rastogi, A. et al. Impact of signal intensity normalization of MRI on the generalizability of radiomic-based prediction of molecular glioma subtypes. Eur Radiol 34, 2782–2790 (2024). https://doi.org/10.1007/s00330-023-10034-2
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00330-023-10034-2