
Abstract
Our objective is to locate and provide a unique identifier for each mouse in a cluttered home-cage environment through time, as a precursor to automated behaviour recognition for biological research. This is a very challenging problem due to (i) the lack of distinguishing visual features for each mouse, and (ii) the close confines of the scene with constant occlusion, making standard visual tracking approaches unusable. However, a coarse estimate of each mouse’s location is available from a unique RFID implant, so there is the potential to optimally combine information from (weak) tracking with coarse information on identity. To achieve our objective, we make the following key contributions: (a) the formulation of the object identification problem as an assignment problem (solved using Integer Linear Programming), (b) a novel probabilistic model of the affinity between tracklets and RFID data, and (c) a curated dataset with per-frame BB and regularly spaced ground-truth annotations for evaluating the models. The latter is a crucial part of the model, as it provides a principled probabilistic treatment of object detections given coarse localisation. Our approach achieves 77% accuracy on this animal identification problem, and is able to reject spurious detections when the animals are hidden.
Similar content being viewed by others


1 Introduction
We are motivated by the problem of tracking and identifying group-housed mice in videos of a cluttered home-cage environment, as in Fig. 1. This animal identification problem goes beyond tracking to assigning unique identities to each animal, as a precursor to automatically annotating their individual behaviour (e.g. feeding, grooming) in the video, and analysing their interactions. It is also distinct from object classification (recognition) [1]: the mice have no distinguishing visual features and cannot be merely treated as different objects. Their visual similarity, as well as the close confines of the enriched cage environment make standard visual tracking approaches very difficult, especially when the mice are huddled or interacting together. We found experimentally that standard trackers alone break down into outputting short tracklets, with spurious and missing detections, and thus do not provide a persistent identity. However, we can leverage additional information provided by a unique Radio-Frequency Identification (RFID) implant in each mouse, to provide a coarse estimate of its location (on a \(3 \times 6\) grid). This setting is not unique to animal tracking and can be applied to more general objects. Similar situations arise, e.g. when identifying specific team-mates in robotic soccer [2] (where the object identification is provided by the weak self-localisation of each robot), or identifying vehicles observed by traffic cameras at a busy junction (as required for example for law-enforcement), making use of a weak location signal provided by cell-phone data.
Our solution starts from training and running a mouse detector on each frame, and grouping the detections together with a tracker [3] to produce a set of tracklets, as shown in Fig. 3c. We then formulate an assignment problem to identify each tracklet as belonging to a mouse (based on RFID data) or a dummy object (to capture spurious tracklets). This problem is solved using Integer Linear Programming (ILP), see Fig. 3f. Tracking is used to reduce the complexity of the problem relative to a frame-wise approach and implicitly enforce temporal continuity for the solution.

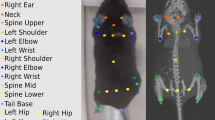
Sample frames from our dataset. To improve visualisation, the frames are processed with CLAHE [4] and brightened: our methods operate on the raw frames. The mice are visually indistinguishable, their identity being inferred through the RFID pickup, shown as Red/Green/Blue crosses projected into image-space. This is enough to distinguish the mice when they are well separated (left): however, as they move around, they are occluded by cage elements (Green in centre) or by cage mates (Green by Blue in right) and we have to reason about temporal continuity and occlusion dynamics
The problem setup is not standard Multi-Object Tracking (MOT), since we go beyond tracking by identifying individual tracklets using additional RFID information which provides persistent unique identifiers for each animal. Our main contribution is thus to formulate this object identification as an assignment problem, and solve it using ILP. A key part of the model is a principled probabilistic treatment for modelling detections from the coarse localization information, which is used to provide assignment weights to the ILP.
We emphasise that we are solving a real-world problem which is of considerable importance to the biological community (as per the International Mouse Phenotype Consortium (IMPC) [5]), and which needs to scale up to thousands of hours of data in an efficient manner—this necessarily affects some of our design choices. More generally, with home-cage monitoring systems being more readily available to scientists [6], there are serious efforts in maximising their use.Footnote 1 Consequently there is a real need for analysis methods like ours, particularly where multiple animals are co-housed.
In this paper, we first frame our problem in the light of recent efforts (Sect. 2), indicating how our situation is quite unique in its formulation. We discuss our approach from a theoretical perspective in Sect. 3, postponing the implementation mechanics to Sect. 4. Finally, we showcase the utility of our solution through rigorous experiments (Sect. 5) on our dataset which allows us to analyse its merits in some depth. A more detailed description of the dataset, details for replicating our experimental setups (including parameter fine-tuning) as well as deeper theoretical insights are relegated to the Supplementary Material. The curated dataset, together with code and some video clips of our framework in action, is available at https://github.com/michael-camilleri/TIDe (see Sect. 6 and Appendix D for details).
2 Related work
Below we discuss related work w.r.t. MOT, re-identification (re-ID) and animal tracking. We defer discussion of our ILP formulation relative to other work after discussing the method in Sect. 3.2.
Multi-object tracking
There have been many recent advances in MOT [7], fuelled in part by the rise of specialised neural architectures [8,9,10]. Here the main challenge is keeping track of an undefined number of visually distinct objects (often people, as in, e.g. [11, 12]), over a short period of time (as they enter and exit a particular scene) [13]. However, our problem is not MOT because we need to identify (rather than just track) a fixed set of individuals using persistent, externally assigned identities, rather than relative ones (as in, e.g. [14]): i.e. our problem is not indifferent to label-switching. We care about the absolute identity assigned to each tracklet—even if we had input from a perfect tracker, there would still need to be a way to assign the anonymous tracklets to identities, as we do below.
There is another important difference between the current state-of-the-art in MOT (see e.g. [9, 14,15,16,17,18,19]) and our use-case. As the mice are essentially indistinguishable, we cannot leverage appearance information to distinguish them but must rely on external cues—the RFID-based quantised position. On top of this, there are also the challenges of operating in a constrained cage environment (which exacerbates the level of occlusion), and the need to consistently and efficiently track mice over an extended period of time (on the order of hours).
(Re-)Identification
Re-ID [20] addresses the transitory notion of identity by using appearance cues to join together instances of the same object across ‘viewpoints’. Obviously, this does not work when objects are visually indistinguishable, but there is also another key difference. The standard re-ID setup deals with associating together instances of the same object, often (but not necessarily) across multiple non-overlapping cameras/viewpoints [21]. In our specific setup, however, we wish to relate objects to an external identity (e.g. RFID-based position); our work thus sits on top of any algorithm that builds tracklets (such as that of Fleuret et al. [20]).
Animal Tracking
Although generally applicable, this work was conceived through a collaboration with the Mary Lyon Centre at MRC Harwell [22], and hence seeks to solve a very practical problem: analysis of group-housed mice in their enriched home-cage environment over extended periods of 3-day recordings. This setup is thus significantly more challenging than traditional animal observation models, which often side-step identification by involving single animals in a purpose-built arena [23,24,25,26] rather than our enriched home-cage. Recent work on multiple-animal tracking [16, 27,28,29] often uses visual features for identification which we cannot leverage (our subjects are visually identical): e.g. the CalMS21 [28] dataset uses recordings of pairs of visually distinct mice, while Marshall et al. [29] attach identifying visual markers to their subjects in the PAIR-R24M dataset. Most work also requires access to richer sources of colour/depth information [30, 31] rather than our single-channel Infra-Red (IR) feed, or employs top-mounted cameras [16, 31,32,33,34] which give a much less cluttered view of the animals. Indeed, systems such as idtracker.ai [35] or DeepLabCut [36, 37] do not work for our setup, since the mice often hide each other and keypoints on the animals (which are an integral part of the methods) are not consistently visible (besides requiring more onerous annotations). Finally we reiterate that our goal is to identify tracklets through fusion with external (RFID) information, which none of the existing frameworks support—for example the multi-animal version of DeepLabCut [37] only supports supervised identity learning for visually distinct individuals.
3 Methodology
This section describes our proposed approach to identification of a fixed set of animals in video data. We explain the methodology through the running example of tracking group-housed mice. Specifically, consider a scenario in which we have continuous video recordings of mice housed in groups of three as shown in Fig. 1. The data, captured using a setup similar to that shown in Fig. 2a, consists of single-channel IR side-view video and coarse RFID position pickup from an antenna grid below the cage as in Fig. 2b. Otherwise, the mice have no visual markings for identification. Implementation details are deferred to Sect. 5.1.

The Actual Analytics Home-Cage Analysis system. a The rig used to capture mouse recordings (Illustration reproduced with permission from [22]). b The (numbered) points on the checkerboard pattern used for calibration (measurements are in mm): the numbers correspond also to the RFID antenna receivers on the baseplate
Overview
Our system takes in candidate detections about the fixed set of animals in the form of Bounding Boxes (BBs) and assigns an identity to each of them using a two-stage pipeline, as shown in Fig. 3. First, we use a Tracker [3] to join the detections across frames into tracklets based on optimising the Intersection-over-Union (IoU) between Bounding Boxes (BBs) in adjacent frames. This stage injects temporal continuity into the object identification, filters out spurious detections, and, as will be seen later, reduces the complexity of the identification problem. Then, an Identifier, using a novel ILP formulation, combines the tracklets with the coarse position information to identify which tracklet(s) belong to each of the known animals, based on a probabilistic weight model of object locations.

Our proposed architecture. Given per-frame detections of animals (a), a tracker (b) joins these into tracklets, shown (c) in terms of their temporal span. After discarding spurious detections based on a lifetime threshold, the identifier (e) combines these with coarse localisation traces over time (d), to produce identified Bounding Boxes (BBs) for each object throughout the video, shown [f] as coloured tracklets/(BBs)
3.1 Tracking
We use the tracker to inject temporal continuity into our problem, encoding the prior that animals can only move a limited distance between successive frames. Subsequently, we formulate our object identification problem as assigning tracklets to animals over a recording interval indexed by \(t\in \left\{ 1,..., T\right\} \).
The tracker also serves the purpose of simplifying the optimisation problem. While (BBs) and positions are registered at the video frame rate, it is not necessary to run our optimisation problem (below) at this granularity. Rather, we group together the sequence of frames for which the same subset of tracklets are active: a new interval will begin when a new tracklet is spawned, or when an existing one disappears. The observation is thus broken up into intervals, indexed sequentially by \(t\), shown as \(\tau _{\{ 0, \dots , 9 \}}\) at the top of Fig. 3c.
3.2 Object identification from tracklets
The tracker produces I tracklets: to this we add T special ‘hidden’ tracklets for which no (BBs) exist, and which serve to model occlusion at any time-step. The goal of the Identifier is then to assign object identities to the set of tracklets, \(\textbf{S}\), of size \(I+T\). The subset of tracklets active at time \(t\) is represented by \(\textbf{S}^{\{t\}}\). We assume there are J animals \(o_1, \ldots , o_J\) we wish to track/identify (and for which we have access to coarse location through time); an extra dummy object \(o_{J+1}\) is a special outlier/background model which captures spurious tracklets in \(\textbf{S}\).
We also define a utility \(w_{i j}\), which is a measure of the quality of the match between tracklet \(s_i\) and animal \(o_j\): we assume that tracklets cannot switch identities and are assigned in their entirety to one animal (this is reasonable if we are liberal in breaking tracklets). The weight is typically a function of the BB features and animal position (see Sect. 3.3). Given the above, our ILP optimises the assignment matrix A with elements \(a_{i j} \in \left\{ 0, 1\right\} \) (where \(a_{i, j} = 1 \Leftrightarrow \) ‘\(s_i\) is assigned to \(o_j\)’), that maximises:
Constraint (2) ensures that a generated tracklet is assigned to exactly one animal, which could be the outlier model. Constraint (3) enforces that each animal (excluding the outlier model) is assigned exactly one tracklet (which could be the ‘hidden’ tracklet) at any point in time, and finally, Eq. ((4)) prevents assigning the hidden tracklets to the outlier model. Unfortunately, these constraints mean that the resulting linear program is not Totally Unimodular [38], and hence does not automatically yield integral optima. Consequently, solving the ILP is in general NP-Hard, but we have found that due to our temporal abstraction, using a branch and cut approach efficiently finds the optimal solution on the size of our data without the need for any approximations.
Our ILP formulation of the object identification process is related to the general family of covering problems [39] as we show in our Supplementary Material (see Sect. B.1). In this respect, our problem is a generalisation of Exact-Set-Cover [40] in that we require every animal to be ‘covered’ by one tracklet at each point in time: i.e. we use the stronger equality constraint rather than the inequality in the general ILP (see Eq. B.2). Unlike the Exact-Set-Cover formulation, however, (a) we have multiple objects (animals) to be covered, (b) some objects need not be covered at all (outlier model), and (c) all detected tracklets must be used (although a tracklet can cover the ‘extra’ outlier model). Note that with respect to (a), this is not the same as Set Multi-Cover [41] in which the same object must be covered more than once: i.e. \(b_f\) in Eq. (B.2) is always 1 for us.
3.3 Assignment weighting model
The weight matrix with elements \(w_{ij}\) is the essential component for incorporating the quality of the match between tracklets and locations. It is easier to define the utility of assignments on a per-frame basis, aggregating these over the lifetime of the tracklet. The per-frame weight boils down to the level of agreement between the features of the BB and the position of the object at that frame, together with the presence of other occluders.
We can use any generative model for this purpose, with the caveat that we can only condition the observations ((BBs)) on fixed information which does not itself depend on the result of the ILP assignment. Specifically, we can use all the RFID information and even the presence of the tunnel, but not the locations of other (BBs). The reason for this is that if we condition on the other detections, the weight will depend on the other assignments (e.g. whether a BB is assigned to a physical object or not), which invalidates the ILP formulation.
We define our weight model as the probability that an animal picked up by a particular RFID antenna j, or the outlier distribution \(J+1\), could have generated the BB i. For the sake of our ILP formulation, we also allow animal j to generate a hidden BB when it is not visible.

a Model for assigning \(BB_i\) to \(o_j\) per-frame in F (frame index omitted to reduce clutter) when \(o_j\) is an animal. Variable \(p_j\) refers to the position of animal j, and \(c_j\) captures contextual information. The visibility is represented by \(v_j\), and the BB (actual or occluded) by \(BB_i\). b Model for assigning \(BB_i\) under the outlier model. c Neighbourhood definition for representing \(c_j\)
For objects of interest (\(j \le J\)), we employ the graphical model in Fig. 4a. Variable \(p_{j}\) represents the position of object j: \(c_j\) captures contextual information, which impacts the visibility \(v_j\) of the BB and is a function of the RFID pickups of the other animals in the frame. The visibility, \(v_j\), can take on one of three values: (a) clear (fully visible), (b) truncated (partial occlusion), and (c) hidden (object is fully occluded and hence no BB appears for it). The BB parameters are then conditioned on both the object position (for capturing the relative arrangement within the observation area) and the visibility as:
where the parameters of the Gaussian are in general a function of object position and visibility. Note that in the top line of Eq. ((5)) we allow only a hidden object to generate a ‘hidden’ tracklet. Conversely, under the outlier model, Fig. 4b, the BB is modelled as a single broad distribution, capturing the probability of having spurious detections.
Bringing it all together, the per-frame weight is
with:
where we have dropped the frame index for clarity. The complete tracklet-object weight \(w_{i, j}\) is then the sum of the log-probabilities over the tracklet’s visible lifetime.
3.4 Relation to other methods
A number of works (see e.g. [20, 42,43,44]) have used ILP to address the tracking problem; however, we reiterate that our task goes beyond tracking to data association with the external information. Indeed, in all of the above cited approaches, the emphasis is on joining the successive detections into contiguous tracklets, while our focus is on the subsequent step of identifying the tracklets by way of the RFID position.
Solving identification problems similar to our is typically achieved through hypothesis filtering, e.g. Joint Probabilistic Data Association (JPDA) [42]. While we could have posed our problem into this framework (which would be a contribution in its own right, with the inclusion of the position-affinity model in Sect. 3.3), exact inference for such a technique increases exponentially with time. While there are approximation algorithms (e.g. [45]), our ILP formulation: (a) does not explicitly model temporal continuity (by delegating this to the tracker), (b) imposes the restriction that the (per-frame) weight of an animal-tracklet pair is a function only of the pair (i.e. independent of the other assignments), (c) estimates a Maximum-A-Posteriori (MAP) tracklet weight rather than maintaining a global distribution over all possible tracklets, but then (d) optimises for a globally consistent solution rather than running online frame-by-frame filtering. The combination of (a), (b) and (c) greatly reduce the complexity of the optimisation problem compared to JPDA, allowing us to optimise an offline global assignment (d) without the need for simplifications/approximations.
4 Implementation details
4.1 Detector
While the detector is not the core focus of our contribution, it is an important first component in our identification pipeline.
We employ the widely used FCOS object detector [46] with a ResNet-50 [47] backbone, although our method is agnostic to the type of detector as long as it outputs (BBs). We replace the classifier layer of the pre-trained network with three categories (i.e. mouse, tunnel and background) and fine-tune the model on our data (see Supplementary Material Sect. C.1). In the final configuration, we accept all detections with confidence above 0.4, up to a maximum of 5 per image. We further discard (BBs) which fall inside the hopper area by thresholding on a maximum ratio of overlap (with hopper) to BB area of 0.4. This setup achieves a recall (at IoU = 0.5) of 0.90 on the held-out test-set (average precision is 0.87, CoCo Mean Average Precision (mAP) = 0.60). Given our focus on the rest of the identification pipeline, we leave further optimisation over architectures to future work.
4.2 Tracker
We use the SORT tracker of Bewley et al. [3] which maintains a ‘latent’ state of the tracklet (the centroid (x, y) of the BB, its area and the aspect ratio, together with the velocities for all but the aspect ratio) and assigns new detections in successive frames based on IoU. At each frame, the state of each active tracklet is updated according to the Kalman predictive model, and new detections matched to existing tracklets by the Hungarian algorithm [3] on the IoU (subject to a cutoff).
Our plug’n’play approach would allow us to use other advanced trackers (e.g. [10, 43, 48, 49]), but we chose this tracker for its simplicity. Since most of the above methods leverage visual appearance information, and all mice are visually similar, it is likely that any marginal improvements would be outweighed by a bigger impact on scalability. In addition, previous research (e.g. [13]) has shown that simple methods often outperform more complex ones, but we leave experimentation with trackers as possible future research.
We do, however, make some changes to the architecture, in the light of the fact that we do not need online tracking, and hence can optimise for retrospective filtering. The first is that tracklets emit (BBs) from the start of their lifetime, and we do not wait for them to be active for a number of frames: this is because, we can always filter our spurious detections at the end. Secondly, when filtering out short tracklets, we do this based on a minimum number of contiguous (rather than total) frames—again, we can do this because we have access to the entire lifetime of each tracklet. We also opt to emit the original detection as the BB rather than a smoothed trajectory, since we believe that the current model assuming a fixed aspect ratio might be too restrictive for our use-case—indeed, we plan to experiment with different models for the Kalman state in the future. Finally, we take the architectural decision to kill tracklets as soon as they fail to capture a detection in a frame: our motivation is that we prefer to have broken tracklets which we can join later using the identification rather than increasing the probability of a tracklet switching identity.
To optimise the two main parameters of the tracker—the IoU threshold for assigning new detections to existing tracklets, and the minimum lifetime of a tracklet to be considered viable—we used the combined training/validation set, and ran our ILP object identification end-to-end over a grid of parameters. The optimal results were obtained using a length cutoff of 2 frames and IoU threshold of 0.8 (see Supplementary Material Sect. C.2 for details).
4.3 Weight model
We represent (BBs) by the 4-vector containing the centroid [x, y] and size [width, height] of the axis-aligned BB. A hidden BB is denoted by the zero-vector and is handled explicitly in logic. The visibility, \(v_j\), can be one of clear, truncated or hidden as already discussed, while the position, \(p_j\), is an integer representing the one-of-18 antennas in which the mouse is picked up. For \(c_j\), we consider the RFID pickups of the other two mice, but we must represent them in an (identity) permutation-invariant way: i.e. the representation must be independent of the identity of the animal we are predicting for (all else being equal). To this end, we define a nine-point neighbourhood around the antenna \(p_j\) as in Fig. 4c, where \(p_j\) would fall in cell 4. Note that where the neighbourhood extends beyond the range of the antenna baseplate, these cells are simply ignored. \(c_j\) is then simply the count of animals picked up in each cell (0, 1 or 2).
Under the outlier model (Fig. 4b), the BB centroids, [x, y], are drawn from a very wide Gaussian over the size of the image: the size, [w, h], is Gaussian with its mean and covariance fit on the training/validation annotations. For the non-outlier case (Fig. 4a), we model the distribution \(p(v_j|p_j,c_j)\) using a Random Forest (RF): this proved to be the best model in terms of validation log-likelihood (this metric is preferable for a calibrated distribution). The mean \(\mu _{pv}\) of the multivariate Gaussian for the BB parameters at position p with visibility v in Eq. ((5)) is defined as follows. The centroid components [x, y] are the same irrespective of the visibility, and governed by a homography mapping between the antenna positions on the ground-plane and the annotated (BBs) centroids in the image. The width and height, [w, h], are estimated independently for each row in the antenna arrangement (see Fig. 1b) and visibility (clear/truncated). This models occlusion and perspective projection but allows us to pool samples across pickups for statistical strength. The covariance matrix \(\Sigma _{pv}\) is estimated solely on a per-row basis and is independent of the visibility. Further details on fine-tuning the parameters appear in our Supplementary Material (Sect. C.3).
4.4 Solver
Unfortunately, our linear program is not Totally Unimodular [38] due to the constraints in Eqs. (2–4), and hence, we have to explicitly enforce integrality. Consequently, solving the ILP is in general NP-Hard, but we have found that due to our temporal abstraction, using a branch and cut approach efficiently finds the optimal solution on the size of our data. We model our problem through the Python MIP package [50], using the COIN-OR Branch and Cut [51] paired with the COIN-OR Linear Programming [52] solvers. Running on a conventional desktop (Intel Xeon E3-1245 @3.5GHz with 32Gb RAM), the solver required on the order of a minute on average for each 30-minute segment.
5 Experiments
5.1 Dataset
Source
We apply and evaluate our method on a mouse dataset, [22], provided by Mary Lyon Centre at MRC Harwell, Oxfordshire (MLC at MRC Harwell). All the mice in the study are one-year old males of the C57BL/6Ntac strain. The mice are housed as groups of three in a cage and are continuously recorded for a period of 3 to 4 days at a time, with a 12-hour lights-on, 12-hour lights-off cycle. We have access to 15 distinct cages. The recordings are split into 30-minute periods, which form our unit of processing (segments). Since we are interested in their crepuscular rhythms, we selected the five segments straddling either side of the lights-on/off transitions at 07:00 and 19:00 every day. This gives us about 30 segments per cage.
The data—IR side-view video and RFID position pickup—is captured using one of four Home-Cage Analyser (HCA) rigs from Actual Analytics\(^{\textrm{TM}}\): a prototypical setup is shown in Fig. 2a. Video is recorded at 25 frames per second (FPS), while the antenna baseplate (\(3\times 6\) cells, see Fig. 2b) is scanned at a rate of about 2Hz and upsampled to the frame rate. The latter, however, is noisy due to mouse huddling and climbing. The video also suffers from non-uniform lighting, occasional glare/blurring and clutter, particularly due to a movable tunnel and bedding. Most crucially, however, being single strain (and consequently of the same colour), and with no external markings, the mice are visually indistinguishable.
Pre-processing
A calibration routine was used to map all detections into the same frame of reference using a similarity transform. In order to maintain axis-aligned (BBs), we transform the four corners of the BB but then define the transformed BB to be the one which intersects the midpoints of each transformed edge (we can do this because the rotation component is very minimal, \(<2^\circ \)). A minimal number of segments which exhibited anomalous readings (e.g. spurious/missing RFID traces) that could not be resolved were discarded altogether (see Supplementary Material Sect. A.1).
Ground-truthing
Using the VIA tool [53], we annotate video frames at four-second intervals for three-minute ‘snippets’ at the beginning, middle and end of each segment, as well as on the minute throughout the segment. This gives a good spread of samples with enough temporal continuity to evaluate our models. The annotations consist of an axis-aligned BB for each visible mouse, labelling the identity as Red/Green/Blue and the level of occlusion as clear vs. truncated: hidden mice are by definition not annotated. A Difficult flag is set when it is hard to make out the mouse even for a human observer. Where the identity of any mouse cannot be ascertained with certainty, this is noted in the schema and the frame discarded in the final evaluation. Refer to Supplementary Material Sect. A.2 for further details.
Data splits
Our 15 cages were stratified into training (7), validation (3) and testing (5). This guarantees unbiased generalisation estimates, and shows that our method can work on entirely novel data (new cages/identities) without the need for additional annotations. We annotated a random subset of 7 segments (3.5 Hrs) for training, 6 (3 Hrs) for validation and 10 (5 Hrs) for testing (2 per cage). This yielded a total of 740 (training), 558 (validation) and 766 (testing) frames in which the mice could be unambiguously identified. We used all frames within the training/validation sets for optimising the weight model, but the rest of the architecture is trained and evaluated on three-minute snippets only, using 498, 398 and 699 frames, respectively. For testing, we remove snippets in which 50% or more of the frames show immobile mice or tentative/huddles due to severe occlusion.
5.2 Comparison methods
We compare the performance of our architecture to two simpler baseline models and off-the-shelf trackers. For overall statistics, we also report the maximum possible achievable performance given the detections.
The first of the baselines, Static (C), is a per-frame assignment (Hungarian algorithm) based on Euclidean distance between the centroid of the (BBs) and the projected RFID tag. The second model, Static (P), uses the probabilistic weights of Sect. 3.3, but is assigned on a per-frame basis.
Our problem is quite unique for the reasons enumerated in Sect. 2, and hence, off-the-shelf solutions do not typically apply. Most systems are either designed for singly housed mice [54, 55] or leverage different fur-colours/external markings [27, 56] to identify the mice. We ran some experiments with idtracker.ai [35], but it yielded no usable tracks—the poor lighting of the cage, coupled with the side-view camera interfered with the background-subtraction method employed. Bourached et al. [57] showed that the widely used DeepLabCut [36] framework does not work on data from the Harwell lab, possibly because of the side-view causing extreme occlusion of key body parts. The newer version of DeepLabCut [37] supports multi-animal tracking, but for identification it requires supervision with annotated samples (full keypoints) for each new cage. Such a level of supervision would be highly onerous and impractical. In contrast our method can be applied to new cages without retraining, as long as the visual configuration is similar (and indeed, we test it on cages for which we have not trained on). As a proof of concept, we explored annotating body parts for one of the cages, but found it impossible to identify reproducible body parts due to the frequent occlusions. For this reason, we cannot report any results for any of the above methods.
It should be emphasised that there is a misalignment of goals when it comes to comparing our method with state-of-the-art MOT trackers—no matter the quality of the tracker, there is still the need for an identification stage, and hence, the comparison degenerates to optimising over tracker architectures (which is outside the scope of our research). For example, while DeepLabCut does support multi-animal scenarios, it requires a consistent identification across videos (possibly using visual markings) to support identifying individuals; otherwise, it generates simple tracklets.
However, by way of exploration, we can envision having a human-in-the-loop that seeds the track (if the tracker supports this) and provides the identifying information. To simulate this, we took each three-minute snippet, extracted the ground-truth annotation at the middle frame, and initialised a SiamMask [8] tracker per-mouse, which we ran forwards and backwards to either end of the snippet. We used this architecture as it is designed to be a general purpose tracker with no need for pre-training on new data, and hence was readily usable with the annotations we already had.
5.3 Evaluation
The standard MOT metrics ((Multi-Object Tracking Precision (MOTP) and Multi-Object Tracking Accuracy (MOTA)) [58] do not sufficiently capture the needs of our problem, in that (a) we have a fixed set of objects we need to track (making the problem better defined), but (b) we also care about the absolute identity (i.e. permutations are not equivalent). While there is a similarity with object detection [59, 60] (using identity for object class), we know a priori that we cannot have more than one detection per ‘identity’ in each frame, and thus we modify existing metrics to suit our constraints.
Overall performance
For each (annotated) frame f and animal j, we define a ground-truth BB, \(GT_j^{[f]}\)—this is null when the animal is hidden. The identifier itself outputs a single hypothesis \(\smash {BB_j^{[f]}}\) for animal j, which can also be null. Subsequently, the ‘Overall Accuracy’, \(A_{O}\), is the ratio of ground-truths that are correctly identified: i.e. where (a) the object is visible and the IoU between it and the identified BB is above a threshold, or (b) when the object is hidden and the identifier outputs null. Mathematically, this is:
where
In the above, we assume that IoU is 0 if any of the (BBs) is null: we use an IoU threshold, \(\phi \) of 0.5 for normal objects, and 0.3 for annotations marked as Difficult.
A separate score, the ‘Overall IoU’, captures the average overlap between correct assignments, and is defined only for objects which are visible:
where \(J^{[f]}\) represents the number of ground-truth visible mice in frame f: again, we assume that the IoU is 0 if any BB is null.
We also report some ‘binary’ metrics. The false negative rate (FNR) is given by the average number of times a visible object is not assigned a BB by the identifier:
where \(\wedge \) is the logical and. Note that this metric does not consider whether the predicted BB is correct: this is handled by the ‘Uncovered Rate’ which augments the FNR\(_)\) by measuring the average number of times a visible object is assigned a BB that does not ‘cover’ it:
Finally, the false positive rate (FPR) counts the (average) number of times a hidden object is wrongly assigned a BB:
where \(\overline{J^f}\) represents the number of animals hidden at frame f.
Performance conditioned on detections
The above metrics conflate the localisation of the BB (i.e. performance of the detector) with the identification error, which is what we actually seek to optimise. We thus define additional metrics conditioned on an oracle assignment of detections to ground-truth. Under the oracle, each candidate detection i is assigned to the ‘closest’ (by IoU) ground-truth annotation j using the Hungarian algorithm with a threshold of 0.5: this is relaxed to 0.3 for detections marked as Difficult. The identity of the detection \(O_{i}^{[f]}\) is then that of the assigned ground-truth or, null if not assigned. Given the identity \(ID_{i}^{[f]}\) assigned by our identifier to BB i, we define the Accuracy given Detections as the fraction of detections which are given the correct (same as oracle) assignment by the identifier (including null when required):
where \(I^{[f]}\) is the number of detections in Frame f, and \(\delta \) is the Kronecker delta (i.e. \(\delta (a,b) = 1\) iff \(a = b\) and 0 otherwise).
We also report the rate of Mis-Identifications (i.e. a wrong identity is assigned): these are (BBs) which are given an identity by the oracle and a different identity by the Identifier.
For the purpose of this metric, null assignments are not counted as erroneous, and we normalise the count by the number of non-null oracle assignments.
Always relative to the oracle, we also quote the FPR and FNR. The FPR is now defined as the fraction of (BBs) with a null oracle assignment that are assigned an identity:
and conversely, the ratio of (BBs) with a non-null oracle assignment that are not identified define the FNR:
In fact, if we consider raw counts (rather than ratios), the sum of Mis-Identifications, FPR and FNR constitute all the errors the system makes.
Evaluation data-size
Table 1 summarises the size of each of the normalisers (within each dataset) that are used to compute the above metrics: the symbols used are the same as those used in the normalisers of Eqs. (8–17).
5.4 Results
We comment on the quantitative performance of our approach. We also make available a sample of video clips showing our framework in action at https://github.com/michael-camilleri/TIDe: we comment on these in the Supplementary Material (see Sect. D).
Performance on the test-set
Table 2 shows the results of our model and comparative architectures evaluated on the held-out test-set (the number of samples in each case appear in Table 1), where our scheme clearly outperforms all other methods on all metrics apart from FNR\(_{O}\). Table 3 on the other hand shows the raw counts of the same metrics as Table 2. Looking first at the left-side of the table, the overall accuracy is quite high at 77%. To get a feel of what this means consider that we are limited by the recall of the detector. In fact, the oracle, which represents an upper bound (given the detector), scores 94%. The FPR seems high, but in reality, the number of hidden samples (see Table 3) is only 85 (4%).
The FNR\(_O\) is the only overall metric in which our method suffers, mostly because it prefers not to assign a BB rather than assign the wrong one: this is evidenced instead by the lower rate of Uncovered. Note that in moving from the baseline through to our final method, the performance strictly improves each time for all other metrics. Indeed, a big jump is achieved simply by the use of the weight model. On the other hand, the performance of the SiamMask [8] architecture is comparable to the Static (C) baseline. It should be noted that such a method would require a level of ground-truth annotation per-video to jump-start the process (i.e. a human-in-the-loop), but then could have been a viable baseline given that it requires no fine-tuning, while our detector needed to be trained using annotations. However, its performance is inadequate mostly because (a) it is not tailored to tracking mice and (b) because it cannot reason about occlusion, leading to high-levels of false positives.
The contrast between methods is starker when it comes to the analysis given detections (the SiamMask cannot be compared because it does not utilise detections). This can be explained because in the former, the performance of the detector acts as an equaliser between alternatives, while \(A_{GD}\) teases out the capability of the identification system from the quality of the detector. Here the FPR\(_{GD}\) is lower, although from the point of view of detections, there are more of them that should be null (1563 or 45%), and hence, the ability of the identification system to reject spurious detections is illustrated. Note that the number of background (BBs) (impacting the FPR\(_{GD}\)) is higher. We also investigated outlier models which were fit explicitly to the outliers in our data but validation-set evaluation yielded a drop in performance.
Example of successful identifications
Figure 5 shows a visualisation of the identification using our method (top) and the baseline/ablation models (below) for three sample frames. Panel (a) shows an occlusion scenario: the Blue mouse is entirely hidden by the Red one. This throws off the Static (C) method, to the extent that it classifies all mice incorrectly and picks up the tunnel as the Green mouse. The observation model in the Static (P) ablation is able to reject this spurious tunnel detection, but is confused by the other two detections, with the Red mouse marked Blue and the Green mouse identified as Red. Our method is able to use the temporal context to reason about this occlusion and correctly identifies Red/Green and rejects Blue as Hidden. A similar phenomenon is manifested in panel (c), where the temporal context present in our method (OURS) helps to correctly make out Red/Blue but the baseline/ablation get them mixed up: Static (P) particularly, uses the wrong BB altogether (which covers half a mouse).

Examples of successful identifications for OUR method (cropped to appropriate regions and brightened with CLAHE for clarity). Mouse pickups are marked by crosses of the appropriate colour. In each panel, a–c, the ground-truth (GT) and identifications according to our model (OURS) appear in the top row, while the bottom part shows the identifications due to the centroid-distance (S (C)) and static probabilistic (S (P)) models
Moving on to panel (b), this illustrates a particularly challenging scenario due to the three mice being in very close proximity under the hopper. In this case, annotation was only possible after repeated observations and following through of the RFID traces: indeed, while Green and Red are somewhat visible, Blue is almost fully occluded and is annotated as Difficult. Most significantly, however, the RFID pickups are shifted although in the correct relative arrangement. The baseline/ablation methods completely miss out the Green mouse due to this, and while Blue is assigned a correct BB, Red is confused as Green, with the Red BB covering a spurious detection. Despite this, our method correctly identifies all three mice, even if the (BBs) for Red and Blue do not perfectly cover the extent of the respective mice.
Sample failure cases
Despite outperforming the competition, our model is not perfect. We show some such failure cases in Fig. 6. Focusing first on panel (a), the switched identification between the Red and Blue mice happens due to a lag in the RFID pickup. In this case, Blue has climbed on the tunnel, but this is too high to be picked up by the baseplate and hence its position remains at its original location, occupying the same antenna space as Red. When this happens, symmetry is broken solely by the temporal tracking, but it appears this failed in this case.

Visualisation of failure cases illustrating a switched identification, b false negative and c false positive cases. The markups follows the arrangement in Fig. 5
Panel (b) shows a challenging huddling scenario, with the mice in close proximity: indeed, the Green mouse is barely visible, as it is hid by the Red mouse and the hopper. This produces a false negative: our method is unable to pick up the Green mouse, classifying it as Hidden, although it correctly identifies Red and Blue. A similar scenario appears in panel (c), although this time, the method also causes a false positive. In (c), the Red mouse is completely hidden behind the Blue/Green mice. Our method picks up green correctly, but assigns Red’s BB to Blue, effectively incurring two errors: a false positive (Blue should be occluded) and a false negative (Red is not picked up).
The last example also illustrates the interdependent nature of the errors, a side-effect of the constraint that there are at most one of each ‘colour’ of mice. This justifies our use of specific metrics to mitigate this overlap: note how our definition of Uncovered (Eq. 12) and Misidentification (Eq. 15) explicitly discounts such instances as they would have already been captured by false negatives/positives.
6 Conclusions
We have proposed an ILP formulation for identifying visually similar animals in a crowded cage using weak localisation information. Using our novel probabilistic model of object detections, coupled with the tracker-based combinatorial identification, we are able to correctly identify the mice 77% of the time, even under very challenging conditions. Our approach is also applicable to other scenarios which require fusing external sources of identification to video data. We are currently looking towards extending the weight model to take into account the orientation of the animals as this allows us to reason about the relative position of the BB to the RFID pickup, as well as modelling the tunnel which can occlude the mice.
Supplementary Material. We make available the curated version of the dataset and code at https://github.com/michael-camilleri/TIDe, with instructions on how to use it. We provide two versions of the data: a detections-only subset to train and evaluate the detection component, as well as an identification subset. In both cases, we provide ground-truth annotations. For detections, we provide the pre-extracted frames. For identification, in addition to the raw video and position pickups, we also released the (BBs) as generated by our trained FCOS detector, allowing researchers to evaluate the methods without the need to re-train a detector. Further details about the repository are provided in the Appendix D.
Notes
See e.g. the TEATIME consortium https://www.cost-teatime.org/
References
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., Berg, A.C., Fei-Fei, L.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. (IJCV) 115(3), 211–252 (2015). https://doi.org/10.1007/s11263-015-0816-y
Silva, J., Lau, N., Rodrigues, J., Azevedo, J.L., Neves, A.J.R.: Sensor and information fusion applied to a robotic soccer team. In: Baltes, J., Lagoudakis, M.G., Naruse, T., Ghidary, S.S. (eds.) RoboCup 2009: Robot Soccer World Cup XIII, pp. 366–377. Springer, Berlin (2010)
Bewley, A., Ge, Z., Ott, L., Ramos, F., Upcroft, B.: Simple online and realtime tracking. In: Proceedings—International Conference on Image Processing, ICIP, vol. 2016-Augus, pp. 3464–3468. IEEE Computer Society (2016). https://doi.org/10.1109/ICIP.2016.7533003
Zuiderveld, K.: Contrast limited adaptive histogram equalization. In: Heckbert, P.S. (ed.) Graphics Gems, pp. 474–485. Academic Press, Cambridge (1994)
Brown, S.D.M., Moore, M.W.: The International Mouse Phenotyping Consortium: past and future perspectives on mouse phenotyping. Mamm. genome 23(9–10), 632–640 (2012). https://doi.org/10.1007/s00335-012-9427-x
Baran, S.W., Bratcher, N., Dennis, J., Gaburro, S., Karlsson, E.M., Maguire, S., Makidon, P., Noldus, L.P.J.J., Potier, Y., Rosati, G., Ruiter, M., Schaevitz, L., Sweeney, P., LaFollette, M.R.: Emerging role of translational digital biomarkers within home cage monitoring technologies in preclinical drug discovery and development. Front. Behav. Neurosci. (2022). https://doi.org/10.3389/fnbeh.2021.758274
Leal-Taixé, L., Milan, A., Schindler, K., Cremers, D., Reid, I., Roth, S.: Tracking the trackers: an analysis of the state of the art in multiple object tracking. arXiv preprint cs.CV (2017). arXiv:1704.02781
Wang, Q., Zhang, L., Bertinetto, L., Hu, W., Torr, P.H.S.: Fast online object tracking and segmentation: a unifying approach. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1328–1338 (2019)
Zhang, Y., Wang, C., Wang, X., Zeng, W., Liu, W.: FairMOT: on the fairness of detection and re-identification in multiple object tracking. arXiv preprint cs.CV (2020). arXiv:2004.01888
Peng, J., Wang, C., Wan, F., Wu, Y., Wang, Y., Tai, Y., Wang, C., Li, J., Huang, F., Fu, Y.: Chained-tracker: chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking. In: Lecture Notes in Computer Science (including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), vol. 12349, pp. 145–161. Springer, Glasgow (2020). https://doi.org/10.1007/978-3-030-58548-8_9
Leal-Taixé, L., Milan, A., Reid, I., Roth, S., Schindler, K.: MOTChallenge 2015: towards a benchmark for multi-target tracking. arXiv preprint cs.CV (2015). arXiv:1504.01942
Dendorfer, P., Rezatofighi, H., Milan, A., Shi, J., Cremers, D., Reid, I., Roth, S., Schindler, K., Leal-Taixé, L.: MOT20: a benchmark for multi object tracking in crowded scenes. arXiv cs.CV (2003.09003) (2020). arXiv:2003.09003
Dave, A., Khurana, T., Tokmakov, P., Schmid, C., Ramanan, D.: TAO: a large-scale benchmark for tracking any object. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) Computer Vision—ECCV 2020, pp. 436–454. Springer, Cham (2020)
Lan, L., Wang, X., Hua, G., Huang, T.S., Tao, D.: Semi-online multi-people tracking by re-identification. Int. J. Comput. Vis. 128(7), 1937–1955 (2020). https://doi.org/10.1007/s11263-020-01314-1
Tang, S., Andriluka, M., Andres, B., Schiele, B.: Multiple people tracking by lifted multicut and person re-identification. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3701–3710. IEEE, Honolulu, Hawai (2017). https://doi.org/10.1109/CVPR.2017.394. http://ieeexplore.ieee.org/document/8099877/
Bergamini, L., Pini, S., Simoni, A., Vezzani, R., Calderara, S., D’Eath., R., Fisher, R.: Extracting accurate long-term behavior changes from a large pig dataset. In: Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications—Volume 5: VISAPP, pp. 524–533. SciTePress, University of Edinburgh (2021)
Yu, S.-I., Yang, Y., Li, X., Hauptmann, A.G.: Long-term identity-aware multi-person tracking for surveillance video summarization. arXiv cs.CV(1604.07468) (2016). arXiv:1604.07468
Fagot-Bouquet, L., Audigier, R., Dhome, Y., Lerasle, F.: Improving multi-frame data association with sparse representations for robust near-online multi-object tracking. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) Computer Vision—ECCV 2016, pp. 774–790. Springer, Cham (2016)
Tang, S., Andriluka, M., Schiele, B.: Detection and tracking of occluded people. Int. J. Comput. Vis. 110(1), 58–69 (2014). https://doi.org/10.1007/s11263-013-0664-6
Fleuret, F., Ben Shitrit, H., Fua, P.: Re-Identification for Improved People Tracking. Person Re-Identification, pp. 309–330. https://doi.org/10.1007/978-1-4471-6296-4_15
Ye, M., Shen, J., Lin, G., Xiang, T., Shao, L., Hoi, S.C.H.: Deep learning for person re-identification: a survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. (2021). https://doi.org/10.1109/TPAMI.2021.3054775
Bains, R.S., Cater, H.L., Sillito, R.R., Chartsias, A., Sneddon, D., Concas, D., Keskivali-Bond, P., Lukins, T.C., Wells, S., Acevedo Arozena, A., Nolan, P.M., Armstrong, J.D.: Analysis of individual mouse activity in group housed animals of different inbred strains using a novel automated home cage analysis system. Front. Behav. Neurosci. 10, 106 (2016). https://doi.org/10.3389/fnbeh.2016.00106
Qiao, M., Zhang, T., Segalin, C., Sam, S., Perona, P., Meister, M.: Mouse academy: high-throughput automated training and trial-by-trial behavioral analysis during learning. bioRxiv (2018). https://doi.org/10.1101/467878
Wiltschko, A.B., Johnson, M.J., Iurilli, G., Peterson, R.E., Katon, J.M., Pashkovski, S.L., Abraira, V.E., Adams, R.P., Datta, S.R.: Mapping sub-second structure in mouse behavior. Neuron 88(6), 1121–1135 (2015). https://doi.org/10.1016/j.neuron.2015.11.031
Tufail, M., Coenen, F., Mu, T., Rind, S.J.: Mining movement patterns from video data to inform multi-agent based simulation. In: Cao, L., Zeng, Y., An, B., Symeonidis, A.L., Gorodetsky, V., Coenen, F., Yu, P.S. (eds.) Agents and Data Mining Interaction, pp. 38–51. Springer, Cham (2015)
Geuther, B.Q., Deats, S.P., Fox, K.J., Murray, S.A., Braun, R.E., White, J.K., Chesler, E.J., Lutz, C.M., Kumar, V.: Robust mouse tracking in complex environments using neural networks. Commun. Biol. 2(1), 1–11 (2019). https://doi.org/10.1038/s42003-019-0362-1
Segalin, C., Williams, J., Karigo, T., Hui, M., Zelikowsky, M., Sun, J., Perona, P., Anderson, D.J., Kennedy, A.: The Mouse Action Recognition System (MARS): a software pipeline for automated analysis of social behaviors in mice. bioRxiv (2020). https://doi.org/10.1101/2020.07.26.222299
Sun, J.J., Karigo, T., Chakraborty, D., Mohanty, S., Wild, B., Sun, Q., Chen, C., Anderson, D., Perona, P., Yue, Y., Kennedy, A.: The multi-agent behavior dataset: mouse dyadic social interactions. In: Vanschoren, J., Yeung, S. (eds.) Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, vol. 1 (2021). https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/file/7f1de29e6da19d22b51c68001e7e0e54-Paper-round1.pdf
Marshall, J.D., Klibaite, U., Gellis, A., Aldarondo, D.E., Ölveczky, B.P., Dunn, T.W.: The PAIR-R24M Dataset for Multi-animal 3D Pose Estimation. bioRxiv (2021). https://doi.org/10.1101/2021.11.23.469743
de Chaumont, F., Ey, E., Torquet, N., Lagache, T., Dallongeville, S., Imbert, A., Legou, T., Sourd, A.-M.L., Faure, P., Bourgeron, T., Olivo-Marin, J.-C.: Live Mouse Tracker: real-time behavioral analysis of groups of mice. bioRxiv (2018)
Jiang, Z., Liu, Z., Chen, L., Tong, L., Zhang, X., Lan, X., Crookes, D., Yang, M.-H., Zhou, H.: Detection and tracking of multiple mice using part proposal networks. arXiv preprint cs.CV(1906.02831) (2019). arXiv:1906.02831
Sadafi, A., Katsageorgiou, V.-M., Huang, H., Papaleo, F., Murino, V., Sona, D.: Multiple mice tracking: occlusions disentanglement using a Gaussian mixture model. In: 2018 24th International Conference on Pattern Recognition (ICPR), pp. 2433–2437. IEEE, Beijing, China (2018). https://doi.org/10.1109/ICPR.2018.8545402. https://ieeexplore.ieee.org/document/8545402/
Giancardo, L., Sona, D., Huang, H., Sannino, S., Managò, F., Scheggia, D., Papaleo, F., Murino, V.: Automatic visual tracking and social behaviour analysis with multiple mice. PLoS ONE 8(9), 1–14 (2013). https://doi.org/10.1371/journal.pone.0074557
Lorbach, M., Poppe, R., Veltkamp, R.C.: Interactive rodent behavior annotation in video using active learning. Multimed. Tools Appl. 78, 19787–19806 (2019). https://doi.org/10.1007/s11042-019-7169-4
Romero-Ferrero, F., Bergomi, M.G., Hinz, R.C., Heras, F.J.H., de Polavieja, G.G.: idtracker.ai: tracking all individuals in small or large collectives of unmarked animals. Nat. Methods 16(2), 179–182 (2019). https://doi.org/10.1038/s41592-018-0295-5
Mathis, A., Mamidanna, P., Cury, K.M., Abe, T., Murthy, V.N., Mathis, M.W., Bethge, M.: DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 21(September), 1281–1289 (2018). https://doi.org/10.1038/s41593-018-0209-y
Lauer, J., Zhou, M., Ye, S., Menegas, W., Nath, T., Rahman, M.M., Santo, V.D., Soberanes, D., Feng, G., Murthy, V.N., Lauder, G., Dulac, C., Mathis, M.W., Mathis, A.: Multi-animal pose estimation and tracking with DeepLabCut. bioRxiv (2021). https://doi.org/10.1101/2021.04.30.442096
Hoffman, A., Kruskal, J.: Integral boundary points of convex polyhedra. In: Junger, M., Liebling, T., Naddef, D., Nemhauser, G., Pulleyblank, W., Reinelt, G., Rinaldi, G., Wolsey, L. (eds.) 50 Years of Integer Programming 1958–2008: From the Early Years to the State-of-the-Art, vol. 38, pp. 49–76. Springer, Berlin (2010). https://doi.org/10.1007/978-3-540-68279-0_3
Vazirani, V.V.: Approximation Algorithms. Springer, Berlin (2003). https://doi.org/10.1007/978-3-662-04565-7
Karp, R.M.: Reducibility among combinatorial problems. In: Miller, R.E., Thatcher, J.W., Bohlinger, J.D. (eds.) Complexity of Computer Computations: Proceedings of a Symposium on the Complexity of Computer Computations, Held March 20–22, 1972, at the IBM Thomas J. Watson Research Center, Yorktown Heights, New York, and Sponsored by the Office of Naval Research, Ma, pp. 85–103. Springer, Boston, MA (1972). https://doi.org/10.1007/978-1-4684-2001-2_9
Hua, Q.S., Wang, Y., Yu, D., Lau, F.C.M.: Dynamic programming based algorithms for set multicover and multiset multicover problems. Theoret. Comput. Sci. 411(26–28), 2467–2474 (2010). https://doi.org/10.1016/j.tcs.2010.02.016
Bar-Shalom, Y., Daum, F., Huang, J.: The probabilistic data association filter: estimation in the presence of measurement origin uncertainty. IEEE Control Syst. 29(6), 82–100 (2009). https://doi.org/10.1109/MCS.2009.934469
Jiang, H., Fels, S., Little, J.J.: A linear programming approach for multiple object tracking. In: Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (2007). https://doi.org/10.1109/CVPR.2007.383180
Wang, X., Türetken, E., Fleuret, F., Fua, P.: Tracking interacting objects optimally using integer programming. In: Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), pp. 17–32 (2014). https://doi.org/10.1007/978-3-319-10590-1_2
Rezatofighi, S.H., Milan, A., Zhang, Z., Shi, Q., Dick, A., Reid, I.: Joint probabilistic data association revisited. In: 2015 IEEE International Conference on Computer Vision (ICCV), pp. 3047–3055 (2015). https://doi.org/10.1109/ICCV.2015.349
Tian, Z., Shen, C., Chen, H., He, T.: FCOS: Fully convolutional one-stage object detection. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9626–9635 (2019)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778 (2016). https://doi.org/10.1109/CVPR.2016.90
Kim, C., Li, F., Ciptadi, A., Rehg, J.M.: Multiple hypothesis tracking revisited. In: 2015 IEEE International Conference on Computer Vision (ICCV), pp. 4696–4704 (2015). https://doi.org/10.1109/ICCV.2015.533
Bhat, G., Danelljan, M., Van Gool, L., Timofte, R.: Know your surroundings: exploiting scene information for object tracking. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) Computer Vision—ECCV 2020, pp. 205–221. Springer, Glasgow (2020)
Toffolo, T.A.M., Santos, H.G.: Python-MIP. https://python-mip.com/. Accessed 17 June 2021
Forrest, J., Lougee-Heimer, R.: CBC user’s guide. https://coin-or.github.io/Cbc/. Accessed 17 June 2021
Forrest, J., de la Nuez, D., Lougee-Heimer, R.: CLP user guide. https://www.coin-or.org/Clp/userguide/index.html. Accessed 17 June 2021
Dutta, A., Zisserman, A.: The VIA annotation software for images, audio and video. In: Proceedings of the 27th ACM International Conference on Multimedia. MM ’19. ACM, New York, NY, USA (2019). https://doi.org/10.1145/3343031.3350535
Graving, J.M., Chae, D., Naik, H., Li, L., Koger, B., Costelloe, B.R., Couzin, I.D.: DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning. eLife (2019). https://doi.org/10.7554/eLife.47994
Pereira, T.D., Aldarondo, D.E., Willmore, L., Kislin, M., Wang, S.S.H., Murthy, M., Shaevitz, J.W.: Fast animal pose estimation using deep neural networks. Nat. Methods 16(1), 117–125 (2019). https://doi.org/10.1038/s41592-018-0234-5
Sourioux, M., Bestaven, E., Guillaud, E., Bertrand, S., Cabanas, M., Milan, L., Mayo, W., Garret, M., Cazalets, J.-R.: 3-D motion capture for long-term tracking of spontaneous locomotor behaviors and circadian sleep/wake rhythms in mouse. J. Neurosci. Methods 295, 51–57 (2018). https://doi.org/10.1016/J.JNEUMETH.2017.11.016
Bourached, A., Nachev, P.: Unsupervised videographic analysis of rodent behaviour. arXiv cs.Cv(1910.11065) (2019). arXiv:1910.11065
Bernardin, K., Stiefelhagen, R.: Evaluating multiple object tracking performance: the CLEAR MOT metrics. EURASIP J. Image Video Process. (2008). https://doi.org/10.1155/2008/246309
Everingham, M., Eslami, S.M.A., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The PASCAL visual object classes challenge: a retrospective. Int. J. Comput. Vis. 111(1), 98–136 (2014). https://doi.org/10.1007/s11263-014-0733-5
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) Computer Vision—ECCV 2014, pp. 740–755. Springer, Cham (2014)
Hartley, R., Zisserman, A.: Multiple View Geometry in Computer Vision, 2nd edn. Cambridge University Press, Cambridge (2004). https://doi.org/10.1017/CBO9780511811685
Alekseyenko, A.V.: Multivariate Welch t-test on distances. Bioinformatics 32(23), 3552–3558 (2016). https://doi.org/10.1093/bioinformatics/btw524
Acknowledgements
We thank our collaborators at the Mary Lyon Centre at MRC Harwell, Oxfordshire, especially Dr Sara Wells and Dr Pat Nolan for providing and explaining the data set.
Funding
MC’s work was supported by the EPSRC Centre for Doctoral Training in Data Science, funded by the UK Engineering and Physical Sciences Research Council (Grant EP/L016427/1) and the University of Edinburgh. LZ was supported by NSFC (No. 62106050). RSB was supported by funding to MLC at MRC Harwell from the Medical Research Council UK (Grant A410). Funding was also provided by the EPSRC Programme Grant Seebibyte EP/M013774/1.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical approval
Data collection for all animal studies and procedures used in the mouse dataset were carried out at MLC at MRC Harwell, in accordance with the Animals (Scientific Procedures) Act 1986, UK, Amendment Regulations 2012 (SI 4 2012/3039) as indicated in [22].
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A Dataset
In this section, we elaborate on the Dataset used in our work, including the annotation schema used.
1.1 A.1 Data cleaning and calibration
We removed one of the cages as it had a non-standard setup. The RFID metadata was then filtered through consistency logic to ensure that the same mice were visible in all recordings from the same cage and that there was no missing data. In some cases, missing data due to huddling mice (which causes the RFID to be jumbled) could be filled in by looking at neighbouring periods to see if the mice moved in between and if not the same position filled in: otherwise, the segment was discarded. Segments in which there was a significant timing mismatch between recording time and RFID traces (indicating a possible invalid trace) were also discarded.
Since the data was captured using one of four different rigs, a calibration routine was required to bring all videos in the same frame of reference, simplifying downstream processing. We were given access to a number of calibration videos for each rig at multiple points throughout the data collection process (but always in between whole recordings), yielding 8 distinct configurations. Using a checkerboard pattern on the bottom of the rig (see Fig. 4b in main paper), we annotated 18 reproducible points, which we split into training (odd) and validation (even) sets. Note that the chosen points correspond to the centres of the RFID antennas on the baseplate, but this is immaterial to this calibration routine. We then used the training set of points to fit affine transforms of varying complexity and also optimised which setup to use as the prototype. We found that a Similarity transform proved ideal in terms of residuals on the validation set, as seen in Fig. 7.

Distribution of Calibration points across setups, before (top) and after (bottom) calibration
1.2 A.2 Annotation schema
We annotated our data using the VIA tool [53]. The annotation requires drawing axis-aligned (BBs) around the mice and the tunnel: the latter was included since we expect future work to incorporate the presence of the tunnel in reasoning about occlusion. For each frame, we annotate all visible objects (mice/tunnel): hidden objects are defined by their missing an annotation. For the mice, we do not include the tail or the paws in the BB: the tunnel includes the opening. For each annotation, we specify:
-
The identity of the mouse as Red/Green/Blue: we allow specifying multiple tentative identities when it cannot be ascertained with certainty, or when the mice are huddling and immobile (in the latter case, the BB extends over the huddle).
-
The level of occlusion: Clear, Truncated or NA when it is difficult to judge/marginal. Note that for this purpose, truncation refers to the size of the BB relative to how it would like if the mouse were not occluded. In other words, it may be possible for a mouse to be partially occluded in such a way that the BB is not Truncated.
-
For detections which are hard to make out even for a human annotator, e.g. when the mouse is almost fully occluded, a ‘Difficult’ flag is set.
Our policy was to annotate frames at 4 s intervals. Within each 30-minute segment, we annotate three snippets, at 00:00–03:00, 13:32–16:28 and 27:00–29:56. The last snippet does not include 30:00, since the last recorded frame is just before the 30:00 min mark. In some segments, we alternatively/also annotate every minute on the minute, again with the caveat that the last annotation is at 29:56 to follow the 4 s rule.
Appendix B Theory
1.1 B.1 ILP formulation as covering problem
We show that our ILP formulation is a special case of the covering problem [39].
The general cover problem is defined as a linear program:
in which, the constraint coefficients d, the objective costs c and the constraint values b are non-negative [39, p. 109]. Here \(x_e\) represents an assignment variable and f iterates over constraints.
Let
represent the flattened assignment matrix A, where \(\textbf{a}_i\) are the rows of the original matrix. Index e is consequently the index over i/j in row-major order given by:
If we assume that log-probabilities are always negative, our original objective, Eq. (1) involves maximising a sum of negative weights, which is equivalent to minimising the sum of the negated weights, and thus would fit the condition that the \(c_e\)’s in Eq. ((B1)) should be non-negative. In reality, probability densities may be greater than 1, and hence our assumption that the weight is always negative may not hold. However, we can circumvent this if we note that after computing all the weights, we can subtract a constant term such that all weights are negative. This means we can define c as:
where \(\textbf{w}_i\) are again the rows of the original weight matrix. In this case, k would be the maximum value over W, added to all the elements, such that \(\min c = 0\). Note that in our implementation we do not need to do this, since the solver is not impacted by the formulation as a covering problem.
As for the constraints of our original formulation, Eqs. (2–4), these are all summations over the assignment matrix (now represented by x) and the coefficients \(d_{fe} \in \left\{ 0,1\right\} \), encoding over which entries (in x) we perform summation (e.g. the set of visible tracklets active at time t). These are clearly non-negative as required in the covering problem formulation.
1.2 B.2 Motivation for performance given detections
Consider the scenario in Fig. 8. The ground-truth assignment for the ‘Blue’ mouse is shown as a blue BB; however, the detector only outputs the BB in magenta. Clearly, the right thing for the identifier to do is to not assign the magenta BB to any mouse, especially if the system is to be used down the line to say predict mouse behaviour. However, under the definition of overall accuracy, whatever the identifier does, its score on this sample will always be 0.

Hypothetical scenario in which the performance of the identifier is overshadowed by the detector (only Blue ground-truth is shown to reduce clutter)
Our metrics conditioned on the oracle assignment are designed to handle such cases, and tease out the performance of the identifier from any shortcomings of the detector. Note how in the same example, the oracle assignment will reject the magenta BB as having no identity: hence, the identifier can now get a perfect score if it correctly rejects the BB. This is possible because of the key difference between \(A_{O}\) and \(A_{GD}\): the former evaluates how well objects j are identified, but the latter measures identification performance for detections i.
Appendix C Fine-tuning
In this section, we comment on the various details of the methods employed, including how we came to choose certain configurations over others.
1.1 C.1 Fine-tuning the detector
We use the network pre-trained on CoCo [60] with the typical “1x” training settings (see public codebaseFootnote 2). For this, our grayscale images are replicated across the colour channels to yield RGB input to the model. We remove the COCO classifier layer of 81 classes and set a randomly initialised classifier with three categories (i.e. mouse, tunnel and background), and proceed to optimise the weights of the entire network. We investigate training using either: (a) the full set of 3247 annotated frames ((BBs) without identities), or (b) a reduced subset of 3152 frames, discarding frames marked as Difficult (see Sect. A.2). We set a constant learning rate 0.0001 for 30,000 iterations with batch size 16, checkpointing every 1000 iterations. Evaluation on the held-out annotations from the validation set indicated that the best performing model was that trained on the reduced subset (b), for 11,000 iterations.
1.2 C.2 Fine-tuning tracker parameters
Using the combined training/validation set, we ran the identification process using our ILP method for different combinations of the parameters, in a grid-search, with IoU \(\in \left\{ 0.65, 0.7, 0.75, 0.8, 0.85, 0.9 \right\} \) and length \(\in \left\{ 1, 2, 5, 7, 10, 15\right\} \). The resulting accuracies appear in Fig. 9. In terms of the metric given detections, (a), the best score is achieved with \(L=7\) and IoU\(=0.75\). However, we see that the alternative configuration \(L = 2\), IoU\(=0.8\) is only marginally worse, and it is also among the optimal in terms of Overall Accuracy (b). We thus opted for the latter configuration as a compromise between the two scores.

Accuracy a given detections, and b overall, for various configurations of the tracker IoU threshold and the minimum tracklet length
1.3 C.3 Fine-tuning the weight model
Tuning the parameters of the weight model is perhaps the central aspect which governs the performance of our solution. We document this in some depth below.
Choice of context vector
Using data from the combined training/validation set, and ignoring marginal visibility outcomes, we compared the mutual information between various choices of summarising the configuration c and the annotated visibility, and settled on counting the number of occupancies in each cell as the imparting the most information. This is natural, but we wanted to see if there was any simpler representation (such as leveraging left/right symmetry).
Predicting \(\mathbf {v_j}\)
Given position \(p_j\) and context \(c_j\), our next task is to generate a distribution over visibility \(v_j\). We explored using multinomial Linear Regression (LR), Naïve Bayes (NB), decision trees, RFs and three-layer Neural Networks (NNs), all of which we optimised using five-fold cross-validation on the combined training/validation data. Note that since we will be summing out \(v_j\), getting a calibrated distribution is the key requirement, and hence, when choosing/optimising the models, we used the held-out data log-likelihood as our objective. Our best score was achieved with a RF classifier, with 100 estimators, a maximum depth of 12, minimum samples per-split at 5 and minimum samples at leaf nodes of 2. Despite the seemingly excessive depth, the mean number of leaf nodes per estimator was around 140 (and never going above 180), due to the regularisation nature of the ensemble method. The chosen configuration was eventually retrained on the entire training/validation dataset and used in the final models.
Probability of (BBs) under the object model
As in Eq. (5) from the main paper, when the object is presumed hidden (\(v_j = \) Hidden), the probability mass function is a Kronecker delta with probability 0 for all detections, and 1 for the hidden BB. It remains to define the parameters of the Gaussian distribution over visible (BBs) when \(v_j\) is Clear or Truncated, which we fit to the training/validation set, but discarding annotations marked as marginal.
We start with defining the means. In the case of the BB centroids, (x, y), we verified that the mean values per-antenna pickup were largely similar across clear/truncated visibilities. Subsequently, we fit a single model per-antenna. Given that there is limited data for some antennas, we sought to pool information from the geometrical arrangement of neighbouring antennas. To this end, we fit a homography [61] between the antenna positions on the baseplate (in world-coordinates, as they appear in Fig. 4b in main body of the paper), and the corresponding BB annotations (in image-space). The homography construct provides a principled way of sharing statistical strength across the planar arrangement.
On the other hand, inline with our intuition, a Hotelling T2 test [62] on the sizes of the (BBs), (w, h), yielded significant differences (with an 0.01 significance level) between (BBs) marked as clear or truncated in all but three of the antenna positions. Subsequently, we fit individual models per-visibility per-antenna. Again, we find the need to pool samples for statistical strength, and again we leverage the geometry of the cage. Specifically, our belief is that the sizes of the (BBs) will vary mostly with depth (into the cage) due to perspective, and are largely stable across antennas at the same depth (or conceptual row, in Fig. 4b). We thus estimate the mean sizes on a per-‘row’ basis, such that for example, antennas 1, 4, 7, 10, 13 and 16 share the same mean size.
We next discuss estimating the covariance. In actuality, fitting both the homography on the centroids and the size-means on a per-row/per-visibility basis assumes uniform variance in all directions. However, we investigated computing a more general covariance matrix using the centred data given the ‘means’ inferred from the above step. We explored three scenarios: (a) uniform variance on all dimensions (spherical, as assumed by our mean models), (b) full covariance, pooled across antennas and visibilities, and (c) full covariance pooled across antennas but independently per visibility. We fit the statistics on the training set and compared the log-likelihood of the validation-set annotations: Table 4 shows that option (c) achieved the best scores and was chosen for our weight model.
Probability of (BBs) under the outlier model
For the general outlier model, we fit a Gaussian independently on the centroid, (x, y) and size, (w, h) components. Ideally, we would use a uniform distribution over the size of the image for the former, but in the interest of uniformity with the size-model, we approximate it with a broad Gaussian. The parameters for the sizes are simply estimated on all BB annotations in our training/validation data.
Appendix D Description of the supporting material
We provide the Dataset, Code and Sample Video Clips at https://github.com/michael-camilleri/TIDe
1.1 D.1 DataSet
We have packaged a curated version of the dataset, containing the annotations, detections and position pickups as pandas dataframes. Further details appear in the repository’s Readme.
1.2 D.2 Code
We make available the tracking, identification and evaluation implementations: note that the code is provided as is for research purposes and scrutiny of the algorithm, but is not guaranteed to work without the accompanying setup/frameworks.
-
‘Evaluation.py’: implements the various evaluation metrics,
-
‘Trackers.py’: implementing our changes to the SORT Tracker and packaging it for use with our code,
-
‘Identifiers.py’: implementing the Identification problem and its solution.
1.3 D.3 Dataset sample
Clip 1
This shows a sample video clip of 30 s from our data. The original raw video appears on the left: on the right, we show the same video after being processed with CLAHE [4] to make it more visible to human viewers, together with the RFID-based position of each mouse overlayed as coloured dots. Note that our methods all operate on the raw video and not on the CLAHE-filtered ones.
1.4 D.4 Sample tracking and identification videos
We present some illustrative video examples showing the BB tracking each mouse as given by our identification method, and comparisons with other techniques. Apart from the first clip, the videos are played at 5 FPS for clarity, and illustrate the four methods we are comparing in a four-window arrangement with Ours on the top-left, the baseline on the top-right, the static assignment with the probabilistic model bottom-left and the SiamMask tracking bottom-right. The frame number is displayed in the top-right corner of each sub-window. The videos are best viewed by manually stepping through the frames.
Clip 2
We start by showing a minute-long clip of our identifier in action, played at the nominal framerate of 25FPS. This clip illustrates the difficulty of our setup, with the mice interacting with each other in very close proximity (e.g. Blue and Green in frames 42,375–42,570) and often partially/fully occluded by cage elements such as the hopper (e.g. Red in frames 42,430–42,500) or the tunnel (e.g. Blue in frames 42,990–43,020).
Clip 3
This clip shows the ability of our model to handle occlusion. Note for example how in frames 40,594–40,605, the relative arrangement of the RFID tags confuses the baseline (top-right), but the (static) probabilistic weight model is sufficient to reason about the occlusion dynamics and the three mice. Temporal continuity does, however, add an advantage, as in the subsequent frames, 40,607–40,630, even the static assignment (bottom-left) mis-identifies the mice, mostly due to the lag in the RFID signal. The SiamMask (bottom-right) fails to consistently track any of the mice, mostly because of occlusion and passage through tunnel which happens later on in the video (not shown here), and shows the need for reasoning about occlusions.
Clip 4
This clip shows the weight model successfully filtering out spurious detections. For clarity, we show only the static assignment (left) and the baseline (right). Note how due to a change in the RFID antenna for Green, its BB often gets confused for noisy detections below the hopper (see e.g. frames 40,867–40,875); however, the weight model, and especially the outlier distribution, is able to reject these and assign the correct BB.
Clip 5
This shows another difficult case involving mice interacting and hiding each other. The SiamMask is unable to keep track of any of the mice consistently. While our method does occasionally lose the red mouse when it is severely occluded (e.g. frame 40,990), the baseline gets it completely wrong (mis-identifying green for red in, e.g. frames 40,990–41,008), mostly due to a lag in the RFID which also trips the static assignment with our weight model.
Clip 6
Finally, this shows an interesting scenario comparing our method (left) to the SiamMask tracker (right). The latter is certainly smoother in terms of the flow of (BBs), with the tracking-by-detection approach understandably being more jerky. However, SiamMask’s inability to handle occlusion comes to the fore towards the end of the clip (frames 40,693-end), where the green track latches to the face of the Blue mouse.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Camilleri, M.P.J., Zhang, L., Bains, R.S. et al. Persistent animal identification leveraging non-visual markers. Machine Vision and Applications 34, 68 (2023). https://doi.org/10.1007/s00138-023-01414-1
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00138-023-01414-1