
Abstract
Background
Clinical prediction models are formal combinations of historical, physical examination and laboratory or radiographic test data elements designed to accurately estimate the probability that a specific illness is present (diagnostic model), will respond to a form of treatment (therapeutic model) or will have a well-defined outcome (prognostic model) in an individual patient. They are derived and validated using empirical data and used to assist physicians in their clinical decision-making that requires a quantitative assessment of diagnostic, therapeutic or prognostic probabilities at the bedside.
Purpose
To provide intensivists with a comprehensive overview of the empirical development and testing phases that a clinical prediction model must satisfy before its implementation into clinical practice.
Results
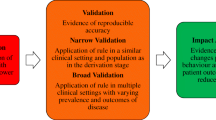
The development of a clinical prediction model encompasses three consecutive phases, namely derivation, (external) validation and impact analysis. The derivation phase consists of building a multivariable model, estimating its apparent predictive performance in terms of both calibration and discrimination, and assessing the potential for statistical over-fitting using internal validation techniques (i.e. split-sampling, cross-validation or bootstrapping). External validation consists of testing the predictive performance of a model by assessing its calibration and discrimination in different but plausibly related patients. Impact analysis involves comparative research [i.e. (cluster) randomized trials] to determine whether clinical use of a prediction model affects physician practices, patient outcomes or the cost of healthcare delivery.
Conclusions
This narrative review introduces a checklist of 19 items designed to help intensivists develop and transparently report valid clinical prediction models.



Similar content being viewed by others

References
Laupacis A, Sekar N, Stiell IG (1997) Clinical prediction rules. A review and suggested modifications of methodological standards. JAMA 277:488–494
Moons KG, Royston P, Vergouwe Y, Grobbee DE, Altman DG (2009) Prognosis and prognostic research: what, why, and how? BMJ 338:375
Steyerberg EW, Moons KG, van der Windt DA et al (2013) Prognosis Research Strategy (PROGRESS) 3: prognostic model research. PLoS Med 10:e1001381
Vincent JL, Moreno R (2010) Clinical review: scoring systems in the critically ill. Crit Care 14:207
Reilly BM, Evans AT (2006) Translating clinical research into clinical practice: impact of using prediction rules to make decisions. Ann Intern Med 144:201–209
Moons KG, Altman DG, Vergouwe Y, Royston P (2009) Prognosis and prognostic research: application and impact of prognostic models in clinical practice. BMJ 338:b606
Steyerberg EW (2009) Clinical prediction models: a practical approach to development, validation, and updating. Springer, New York
McGinn TG, Guyatt GH, Wyer PC et al (2000) Users’ guides to the medical literature: XXII: how to use articles about clinical decision rules. Evidence-Based Medicine Working Group. JAMA 284:79–84
Royston P, Moons KG, Altman DG, Vergouwe Y (2009) Prognosis and prognostic research: developing a prognostic model. BMJ 338:b604
Altman DG, Vergouwe Y, Royston P, Moons KG (2009) Prognosis and prognostic research: validating a prognostic model. BMJ 338:b605
Wasson JH, Sox HC, Neff RK, Goldman L (1985) Clinical prediction rules. Applications and methodological standards. N Engl J Med 313:793–799
Moons KG, Kengne AP, Grobbee DE et al (2012) Risk prediction models: II. External validation, model updating, and impact assessment. Heart 98:691–698
Moons KG, Kengne AP, Woodward M et al (2012) Risk prediction models: I. Development, internal validation, and assessing the incremental value of a new (bio)marker. Heart 98:683–690
Stiell IG, Wells GA (1999) Methodologic standards for the development of clinical decision rules in emergency medicine. Ann Emerg Med 33:437–447
Labarere J, Schuetz P, Renaud B et al (2012) Validation of a clinical prediction model for early admission to the intensive care unit of patients with pneumonia. Acad Emerg Med 19:993–1003
Renaud B, Labarere J, Coma E et al (2009) Risk stratification of early admission to the intensive care unit of patients with no major criteria of severe community-acquired pneumonia: development of an international prediction rule. Crit Care 13:R54
Guyatt GH (2006) Determining prognosis and creating clinical decision rules. In: Haynes RB, Sackett DL, Guyatt GH, Tugwell P (eds) Clinical epidemiology: how to do clinical practice research. Lippincott Williams & Wilkins, New York
Altman DG (2009) Prognostic models: a methodological framework and review of models for breast cancer. Cancer Invest 27:235–243
Randolph AG, Guyatt GH, Calvin JE, Doig G, Richardson WS (1998) Understanding articles describing clinical prediction tools. Evidence Based Medicine in Critical Care Group. Crit Care Med 26:1603–1612
Altman DG (1991) Practical statistics for medical research. Chapman & Hall/CRC, London
Aujesky D, Obrosky DS, Stone RA et al (2005) Derivation and validation of a prognostic model for pulmonary embolism. Am J Respir Crit Care Med 172:1041–1046
Fine MJ, Auble TE, Yealy DM et al (1997) A prediction rule to identify low-risk patients with community-acquired pneumonia. N Engl J Med 336:243–250
Royston P, Altman DG, Sauerbrei W (2006) Dichotomizing continuous predictors in multiple regression: a bad idea. Stat Med 25:127–141
Altman DG, Lausen B, Sauerbrei W, Schumacher M (1994) Dangers of using “optimal” cutpoints in the evaluation of prognostic factors. J Natl Cancer Inst 86:829–835
Steyerberg EW, Schemper M, Harrell FE (2011) Logistic regression modeling and the number of events per variable: selection bias dominates. J Clin Epidemiol 64:1464–1465 (author reply 1463–1464.)
Sauerbrei W, Royston P, Binder H (2007) Selection of important variables and determination of functional form for continuous predictors in multivariable model building. Stat Med 26:5512–5528
Harrell FE Jr (2001) Regression modelling strategies with applications to linear models, logistic regression, and survival analysis. Springer, New York
Vergouwe Y, Royston P, Moons KG, Altman DG (2010) Development and validation of a prediction model with missing predictor data: a practical approach. J Clin Epidemiol 63:205–214
Altman DG, Bland JM (2007) Missing data. BMJ 334:424
Groenwold RH, White IR, Donders AR et al (2012) Missing covariate data in clinical research: when and when not to use the missing-indicator method for analysis. CMAJ 184:1265–1269
Groenwold RH, Donders AR, Roes KC, Harrell FE Jr, Moons KG (2012) Dealing with missing outcome data in randomized trials and observational studies. Am J Epidemiol 175:210–217
Liublinska V, Rubin DB (2012) Re: “dealing with missing outcome data in randomized trials and observational studies”. Am J Epidemiol 176:357–358
Janssen KJ, Donders AR, Harrell FE Jr et al (2010) Missing covariate data in medical research: to impute is better than to ignore. J Clin Epidemiol 63:721–727
Concato J, Feinstein AR, Holford TR (1993) The risk of determining risk with multivariable models. Ann Intern Med 118:201–210
Harrell FE Jr, Lee KL, Mark DB (1996) Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med 15:361–387
Peduzzi P, Concato J, Kemper E, Holford TR, Feinstein AR (1996) A simulation study of the number of events per variable in logistic regression analysis. J Clin Epidemiol 49:1373–1379
Courvoisier DS, Combescure C, Agoritsas T, Gayet-Ageron A, Perneger TV (2011) Performance of logistic regression modeling: beyond the number of events per variable, the role of data structure. J Clin Epidemiol 64:993–1000
Breiman L, Friedman JH, Olshen RA, Stone CJ (1984) Classification and regression trees. Chapman & Hall/CRC, New York
Marshall RJ (2001) The use of classification and regression trees in clinical epidemiology. J Clin Epidemiol 54:603–609
Sun GW, Shook TL, Kay GL (1996) Inappropriate use of bivariable analysis to screen risk factors for use in multivariable analysis. J Clin Epidemiol 49:907–916
Hosmer DW, Lemeshow S (2000) Applied logistic regression, 2nd edn. Wiley, New York
Sullivan LM, Massaro JM, D’Agostino RB Sr (2004) Presentation of multivariate data for clinical use: the Framingham Study risk score functions. Stat Med 23:1631–1660
Steyerberg EW, Vickers AJ, Cook NR et al (2010) Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology 21:128–138
Rufibach K (2010) Use of Brier score to assess binary predictions. J Clin Epidemiol 63:938–939
Vergouwe Y, Steyerberg EW, Eijkemans MJ, Habbema JD (2005) Substantial effective sample sizes were required for external validation studies of predictive logistic regression models. J Clin Epidemiol 58:475–483
Justice AC, Covinsky KE, Berlin JA (1999) Assessing the generalizability of prognostic information. Ann Intern Med 130:515–524
Altman DG, Royston P (2000) What do we mean by validating a prognostic model? Stat Med 19:453–473
Steyerberg EW, Harrell FE Jr, Borsboom GJ et al (2001) Internal validation of predictive models: efficiency of some procedures for logistic regression analysis. J Clin Epidemiol 54:774–781
Efron B, Tibshirani RJ (1993) An introduction to the bootstrap. Chapman & Hall/CRC, New York
Bleeker SE, Moll HA, Steyerberg EW et al (2003) External validation is necessary in prediction research: a clinical example. J Clin Epidemiol 56:826–832
Toll DB, Janssen KJ, Vergouwe Y, Moons KG (2008) Validation, updating and impact of clinical prediction rules: a review. J Clin Epidemiol 61:1085–1094
Peek N, Arts DG, Bosman RJ, van der Voort PH, de Keizer NF (2007) External validation of prognostic models for critically ill patients required substantial sample sizes. J Clin Epidemiol 60:491–501
Janssen KJ, Moons KG, Kalkman CJ, Grobbee DE, Vergouwe Y (2008) Updating methods improved the performance of a clinical prediction model in new patients. J Clin Epidemiol 61:76–86
Collins GS, Moons KG (2012) Comparing risk prediction models. BMJ 344:e3186
Campbell MK, Piaggio G, Elbourne DR, Altman DG (2012) Consort 2010 statement: extension to cluster randomised trials. BMJ 345:e5661
Donner A, Klar N (2000) Design and analysis of cluster randomized trials in health research. Arnold, London
Hussey MA, Hughes JP (2007) Design and analysis of stepped wedge cluster randomized trials. Contemp Clin Trials 28:182–191
Ramsay CR, Matowe L, Grilli R, Grimshaw JM, Thomas RE (2003) Interrupted time series designs in health technology assessment: lessons from two systematic reviews of behavior change strategies. Int J Technol Assess Health Care 19:613–623
von Elm E, Altman DG, Egger M et al (2007) The Strengthening the Reporting of Observational Studies in Epidemiology (STROBE) statement: guidelines for reporting observational studies. Ann Intern Med 147:573–577
Renaud B, Santin A, Coma E et al (2009) Association between timing of intensive care unit admission and outcomes for emergency department patients with community-acquired pneumonia. Crit Care Med 37:2867–2874
Chalmers JD, Mandal P, Singanayagam A et al (2011) Severity assessment tools to guide ICU admission in community-acquired pneumonia: systematic review and meta-analysis. Intensive Care Med 37:1409–1420
Marti C, Garin N, Grosgurin O et al (2012) Prediction of severe community-acquired pneumonia: a systematic review and meta-analysis. Crit Care 16:R141
Ewig S, Woodhead M, Torres A (2011) Towards a sensible comprehension of severe community-acquired pneumonia. Intensive Care Med 37:214–223
Yealy DM, Auble TE, Stone RA et al (2005) Effect of increasing the intensity of implementing pneumonia guidelines: a randomized, controlled trial. Ann Intern Med 143:881–894
Acknowledgments
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors. On behalf of all authors, the corresponding author states that there is no conflict of interest. The authors thank Linda Northrup from English Solutions for her assistance in editing the manuscript.
Conflicts of interest
The authors have no conflict of interest to report.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1. Development of the Risk of Early Admission to the Intensive Care Unit prediction model
Rationale Previous studies have reported that patients with progressive CAP but no major pneumonia severity criteria on emergency department presentation may benefit from direct intensive care unit (ICU) admission [60], although identification of these patients remains a daily challenge for clinicians [61, 62]. Therefore a model that accurately predicts the risk for admission to the ICU might be helpful for early recognition of severe CAP that is not obvious on presentation [63].
Study design The Risk of Early Admission to the ICU prediction model was derived using data obtained from four prospective multicentre cohort studies conducted in the USA and Europe. With the exception of the EDCAP cluster randomized trial [64], all studies were observational in design.
Outcome of interest The outcome of interest predicted by the Risk of Early Admission to the ICU model was defined by admission to the ICU within 3 days following emergency department presentation. This time frame was chosen because most sepsis-related organ failures in severe CAP occur early, whereas late ICU admission may be associated with the worsening of a pre-existing comorbid condition or the occurrence of a pneumonia-unrelated adverse event such as hospital-acquired infection or venous thromboembolism. However, ICU admission may be confounded by various factors, including local admission practices, bed availability or presence of an intermediate care unit. Modelling ICU admission might lead to circular reasoning, with a clinical prediction model fitting observed physician practices (i.e. modelling “what physicians do” rather than “what should be done”) [62]. Reassuringly, the Risk for Early Admission to the ICU prediction model also demonstrated satisfactory accuracy in predicting early intensive respiratory or vasopressor support [15], which is considered a more reliable outcome measure of severe CAP than ICU admission across institutions and healthcare systems.
Statistical methods Given the binary nature of the outcome, multivariable logistic regression was used for model derivation. The model was developed by removing candidate predictors from a full main effects regression model using a backward approach with a cut-off value of P = 0.10. Overall, 25 prespecified candidate predictors were entered in the model including baseline demographic characteristics (age and gender), comorbid conditions (eight predictors), and physical (six predictors), radiographic (two predictors) and laboratory (seven predictors) findings [15, 16]. The number of events per candidate predictors was 12 (303/25).
Model simplification Regression coefficients were divided through the smallest coefficient (which was assigned by definition a value of 1) and then rounded to the closest integer (Table 2). However, this approach is not optimal because it capitalizes on the estimate of one coefficient and may lead to unnecessary uncertainty in the converted coefficients [7].
Appendix 2. Modelling continuous candidate predictors
Although not recommended, it is usual to divide the range of continuous candidate predictors into two groups at suitable cutpoints. Most pneumonia prognostic models include binary baseline systolic blood pressure, with a prespecified cutpoint at 90 mmHg. Yet, the resulting step function may be a poor approximation of the nonlinear relationship between the candidate predictor and outcome of interest. As illustrated (Fig. 4), the odds of early admission to the ICU rose steadily with decreasing systolic blood pressure values and was poorly modelled with a constant category for systolic blood pressure less than 90 mmHg. In contrast, a constant category might be suitable for modelling the odds of early admission to the ICU for systolic blood pressure values of at least 90 mmHg. In practice, a quadratic function, involving systolic blood pressure and (systolic blood pressure)2 terms, or fractional polynomials proved to fit this nonlinear relationship well.

Modelling of the relationship between systolic blood pressure and the odds of early admission to the intensive care unit in the full development data set (n = 6,560)
Appendix 3. Missing-data mechanisms (adapted from [7, 27])
Three types of missing-data mechanisms exist:
1. Missing completely at random (MCAR): the missing values occur completely at random; data elements are missing for reasons that are unrelated to any observed or unobserved characteristics of individuals. The individuals with missing values are a simple random sample from the complete population. Examples of MCAR include missing laboratory tests resulting from a dropped test tube.
2. Missing at random (MAR): missing values do not occur at random; the probability that a value is missing depends on the values for other observed variables (but does not depend on values for unmeasured variables). The individuals with missing values are no longer a simple random sample from the complete population. Yet, they are only randomly different from other subjects, given the values of other observed variables. As an example, one may consider missing values for older subjects.
3. Missing not at random (MNAR): missing values do not occur at random; the probability that a value is missing depends on the values that are missing or on other unobserved predictors. For example, clinicians may choose not to measure a laboratory value (pH) in individuals suspected of having normal values.
Appendix 4. Handling missing values in predictors
Of 6,560 patients included in the full development data set, 4,618 (70 %) had missing values for one or more predictors included in the Risk for Early Admission to the Intensive Care Unit prediction model. The percentages of missing values for predictors ranged from 5 % for heart rate to 65 % for arterial pH. To assess the robustness of the model, we used the following approaches for handling missing values: case-wise deletion of observations with any missing predictor value, assuming that unknown values were normal, and performing multiple imputations of missing values (Table 3). The predictor and dependent variables were entered into the imputation model. Sixty imputed data sets were created with a total run length of 60,000 iterations and imputations made every 1,000 iterations. As illustrated, performing case-wise deletion was inefficient (70 % of observations in the development data set were discarded) and had the potential for selection bias (as suggested by the 9.5 % prevalence of early ICU admission). In contrast, the two other approaches used the full data set. Yet, the c statistic was higher for the approach assuming that unknown values were normal in comparison to multiple imputations of missing values. This might be explained by the mechanism of data-missing for laboratory values (see “Appendix 3”).
Appendix 5. Internal and external validation
In order to assess the internal and external validity of the Risk for Early Admission to the Intensive Care Unit prediction model, we evaluated the predictive performance in the derivation and external validation samples (Table 4). In the derivation sample, we estimated apparent and internal validation predictive performance measures. Internal validation was performed using split-sampling and bootstrapping approaches, respectively. In the split-sampling approach, 70 % of the patients were randomly assigned to a derivation cohort and 30 % to an internal validation cohort. In the bootstrapping approach, 1,000 bootstrap samples were drawn with replacement form the derivation set. Optimism-corrected performance estimates were computed (Fig. 3). External validation was done using the original data from a multicentre prospective randomized controlled trial conducted by investigators independent of those who developed the model [15, 16].
Because the full derivation data set was large, the apparent performance measures were likely to be valid and therefore model optimism appeared to be limited in internal validation, for both split-sampling and bootstrapping procedures. Yet, the calibration intercept estimate was 0.20 (for an expected value of 0) and likely reflected less stable results for the split-sampling procedure. In the external validation sample, miscalibration was mainly driven by a significant decrease in intercept (referred as to “calibration-in-the-large”), reflecting that the mean predicted probability was too high in comparison to observed frequency of early admission to the ICU. Although the calibration slope term was not significantly different from 1.00 (P = 0.37), only 54 patients had the outcome of interest in the external validation sample and the test may lack power for the detection of relevant miscalibration. In the external validation sample, the Risk for Early Admission to the ICU prediction model performed better than the pneumonia severity assessment tools but failed to demonstrate an accuracy advantage over alternate prediction models in predicting early ICU admission (data not shown).
Rights and permissions
About this article
Cite this article
Labarère, J., Bertrand, R. & Fine, M.J. How to derive and validate clinical prediction models for use in intensive care medicine. Intensive Care Med 40, 513–527 (2014). https://doi.org/10.1007/s00134-014-3227-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00134-014-3227-6