
Abstract
Conventional measures of competitiveness in terms of final prices shed little light on how those measures are affected by public expenditure. By taking productivity as a common factor to any index of competitiveness we propose to assess the Italian Public Sector contribution by its productivity in providing public services. Integration of Data Envelopment Analysis with Principal Component Analysis provides a consistent methodology to face the problem of high dimensions, which is a characterising feature of public services provision. Results show a large geographical variability in Public Sector productivity and a significant differentiation in terms of both layers of government and types of services. Thus offering evidence to identify areas, services and tiers of government lacking efficiency and constituting a potential obstacle for growth. A East–West divide emerges on top of the Country’s traditional, though less marked than commonly thought, North–South divide.
Similar content being viewed by others

Introduction
Competitiveness is seen as a key indicator for Country’s economic potential. Conventional measures tend to concentrate either on the private sector, or to treat the economy as a peculiar large private company. Either way, factors cost and goods final prices play a major role in any measure of competitiveness.Footnote 1 A significant exception is provided by the Global Competitiveness Index which, by means of a large variety of indices, aims at including a wide set of factors, not directly observable in market operations, such as, for instances, people’s perception of obstacles in running business activities and in the functioning of institutions, public and private (World Economic Forum 2012).Footnote 2
Here we follow this more general approach to competitiveness as it provides a framework in which to pose the question of how the Public Sector affects competitiveness. We depart, however, from the Global Competitiveness Index way of including public institutions due to its heavy reliance on “subjective” measures. Our contribution goes in the direction of devising a more objective way to link the working of public institutions to the Country’s economic performance. We follow the idea, put forward by Krugman (1994), that although competitiveness could have many and even opposing meanings they all have to be grounded on the concept of productivity. Indeed, World Economic Forum (2008), defines national competitiveness as a set of factors, policies and institutions that determine the Country’s productivity level.
With productivity in mind the question of measuring Public Sector’s contribution comes to be very close to the old question of getting a measure for the “real” value of public expenditure. It is well known that National Accounts assume for public expenditure a one to one productivity in terms of final services and, therefore, uniform throughout the Country. Partial relaxation of this assumption is what characterizes this paper.Footnote 3
Public expenditure can better be seen as the financial side of Public Sector provision of services in the economy, its “real” value is not the same throughout the Country as it varies significantly across areas: The North–South growth problem is a well-known and lasting example.Footnote 4 We need, therefore, measurements of Public Sector contribution to be area-specific, that is to be decomposable by area. In addition, taking also into account the quest for efficiency improvements in public expenditure, the overall measure of Public Sector productivity has to be decomposable in terms of policies’ objectives (type of public services).
To make such measurements amenable, the first problem is that of isolating final services provided by the Public Sector, their cost and the government tiers responsible for provision. Once data are made available we estimate services’ productivity, and proceed to aggregate it at local (Provinces) level.Footnote 5 This provides the basic tool to arrive at an efficiency adjusted measure of public expenditure: a measure of its productivity. Its geographical distribution provides indicators of how Public Sector’s policies affect the Country’s overall and local productivity. Comparing the index across services and tiers of government helps identifying areas and causes of lack in productivity.
The paper develops as follows: Sect. 2 describes the way public services are provided in Italy according to layers of government; Sect. 3 and the Appendix document the organisational aspects of provision and illustrate the different measures of outputs needed to account for the multidimensional nature of public services; Sect. 4 presents the basics of Data Envelopment Analysis (Dea) and the characteristics of a Slack Based Measure (Sbm) of efficiency integrated with Principal Component Analysis in order to make the multidimensional characteristic of the data manageable; Sect. 5 presents and discusses the results and Sect. 6 summarises and concludes.
Public Services by Tiers of Government
If one had to rely just on National Accounts data, Public Sector’s contribution to productivity could be obtained by isolating public from private components in per capita Gdp.Footnote 6 For the 109 Italian Provinces this exercise is in Fig. 1. It shows the conventional picture:
-
(a)
A North–South divide, whereby Southern Provinces show, on average, lower productivity (per capita Gdp, Fig. 1a) coupled with lower per capita public expenditure (Fig. 1b). Therefore, private per capita Gdp is much lower in Southern Provinces than in rest of the Country;
-
(b)
More productive Provinces have an average productivity above Eu(17)’s average (25,500 €), Fig. 1a;
-
(c)
Higher than average productivity (per capita Gdp) in some Northern Provinces (Aosta Valley e Trentino Alto Adige) and Rome is due to high public contribution to Gdp by means of relative high local public spending (Fig. 1b).

According to National Accounts, current final expenditure from General Government comes up to 325 bln euro in 2009, that is 21 % of Gdp (ISTAT 2012f). This, however, underestimates the actual role of Public Sector in terms of command over resources. Since mid-Eighties a new aggregate, the “Enlarged Public Sector” (Eps) has been introduced in order to account for Local public companiesFootnote 7 which provide public services although they are not necessarily fully owned by bodies belonging to the General Government. Eps’s contribution to Gdp is of 599 bln euro in 2009 (39 % of Gdp, MSE 2012).Footnote 8
Lack of data prevents us from accounting for the whole of Eps’s expenditure. Data collection on public services is non-systematic and does not guarantee full coverage by services and tiers of government. However by gathering information from different official sources, data have been collected for services listed in Table 1. In this way, the percentage of expenditure accounted for in our analysis goes from 100 % for Health services, to 15 % in Security, with an average over all services of almost 60 % (Table 1) and covering almost 85 % of Provinces.Footnote 9
The Multidimensional Nature of Public Services
Most often public services do not have a market: they are not sold but rather provided either for free or at heavily subsidised fares. For instances the functioning of the institutional bodies (Administration), Road maintenance, Security, Social services of Table 1 belong to such a category. Even in the case of marketed services, when a cost oriented price does exit, externalities in provision and in consumption are relevant to the extent that the overall benefit to the community is only indirectly linked to users’ price (Transport, Health, Education, Waste management). In either case, marketed and non-marketed services, collective benefits to the community are made of direct (users’ surplus) and indirect (external effects) components. Benefits are not always observable, but rather have the nature of latent variables. Health services are probably the most obvious case although by no means the only ones among public services. Latent variables are the outcome of complex, unknown combination of otherwise observable variables. To recover them a large set of data has to be collected and statistical Principal Component Analysis be used. In this effort, however, one faces a traditional trade off between quantity of information and the selective power of the methodology to be used.Footnote 10
In addition, these peculiarities of public services have their bearings upon the method to follow in efficiency estimation. Not only final prices for public services are non-observable, but they also reflect local government’s preferences in terms of the just above mentioned direct (users’ surplus) and indirect (external effects) components of benefits. The same tend to hold for inputs despite the fact that at first sight factors prices are observable and fairly common (though there might be Regional differences) among layers of government. That happens because even input mix is a relevant policy variable in public service provision due to the external effects on local community’s welfare and in terms of political consensus.
Preferences of local government’s decision bodies and managers also affect the choice of technologies in service provision and the internal organisation of provision. These preferences are likely to vary among government tiers and there is no reason to assume that they can be represented by some sort of common average.
This implies that, in selecting the method to estimate efficiency, it is to be preferred one in which efficiency is not assessed with reference to an average mix of inputs and outputs or to a pre-specified supposedly common technology. Otherwise estimations would be biased by the assumption made even if observed data does not reject it.
Data Envelopment Analysis (Dea) models do not require the assumption of a common technology although such an advantage comes at the price of limiting the possibility of making conventional statistical inference.Footnote 11 This point can better be described by noticing that there are two basic approaches to the estimation of production frontiers: parametric and non-parametric.Footnote 12 The first being characterized by the assumption of a functional form for the underlying production function, that is the assumption of a common technology (Ces, Translog, \(\ldots \)). In addition, specific assumptions are made about the error term distribution (truncated or one side distribution). Under these assumptions, single (or input demand system) regression yields marginal products, marginal cost or partial elasticities from which efficiency index can be constructed.Footnote 13
Dea is non parametric in that it does not require the underlying production function to belong to any specific functional form. It does not require any assumption on the error term, because it assumes that any deviation from frontier is due to inefficiency. This very last assumption, while exposing Dea to errors from poor data quality,Footnote 14 provides the way to economize in data requirements and because of this makes efficiency analysis possible even when other methods of estimation would not be applicable. Dea evaluates the Decision Making Unit (Dmu)Footnote 15 efficiency by allowing input and output (virtual) weights to take the most favourable value for the Dmu under assessment, which is the way the no assumption about common technology is allowed for in the analysis (cf. Cooper et al. 2007, p. 13).Footnote 16
The efficiency index comes as a result of comparing each Dmu relative to all others under the constraint that all lie on or below the efficient frontier. Efficiency index is obtained by scaling the inefficient Dmu against a convex combination of efficient Dmus nearest to it. Therefore efficiency has a relative meaning: it is relative to the efficient Dmu. This implies that technological efficiency, that corresponding to a Dmu operating on the (engineer or mathematical) production function, might not be the term of reference unless the efficient Dmu does in fact operates on it. In other words, if efficient Dmu contains any inefficiency slack, that would not be accounted for by Dea.Footnote 17
Efficiency and Productivity
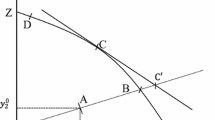
One important point has to be made when using Dea models to measure productivity rather than efficiency. To clarify let us refer to Fig. 2 where four Dmus (a, b, c, d) are depicted, and assume they produce just one output out of a single input. The set made of all points between the piecewise production frontier a, b, c and the input axis makes the production set. Dmus operating on the frontier (a, b, c) are efficient, whereas Dmu d is inefficient because while using the same input as Dmu c it produces less output.

Productivity and inefficiencies in Dea models
For Dmu d to gain efficiency it would require a movement towards point d \(_{3}\) or to point c. Either points would guarantee efficiency, although at a different level of productivity. In d \(_{3}\), productivity, as measured by the ratio of output to input, is higher than in c due to decreasing returns to scale. Therefore, in measuring productivity, inefficiency has to include two different sources: technical inefficiency, if Dmu is lying below the frontier; and scale inefficiency, if Dmu does not exploit returns to scale. In Fig. 2, Dmu b is both technical and scale efficient, hence it has the highest productivity.
Although standard in Dea literature, describing the results of our analysis will be easier if the close link between productivity and efficiency is stated with reference to Fig. 2. Productivity index (technical efficiency in Dea literature), for Dmu d is given by:
Failure to attain maximum productivity of 1 can be ascribed to Scale inefficiency, when service is operated at a scale different from optimal:

and/or to Pure technical inefficiency, which is a measure of managerial failure in efficiently allocating inputs in production:

As shown in Fig. 2, Productivity index (1) is obtained by Dea models under constant returns to scale assumption (Crs Frontier), whereas Pure technical inefficiency index (Pti) requires variable returns to scale assumption (Vrs Frontier). The Crs technology identifies the long run equilibrium (zero profit, optimal scale of production), while the Vrs assumption portraits the short run equilibrium. The difference between the two equilibria is a measure of the distance of (actual) short run scale from optimal scale (Fare et al. 1985, ch. 8).
If no inefficiency is present (Si \(=\) Pti \(=\) 0), productivity is at its maximum value (P \(=\) 1), as in case of Dmu B; otherwise it is less than maximum (P \(\le \) 1) and either or both inefficiencies are present (Si;Pti \(\ge \) 0).
Quite often in the text, we will find it convenient to deal with the complement to one of index (1) and name it Productivity gap (i.e.: Pg \(=\) 1 \(-\) P), where the gap is relative to maximum value of 1. Then:

That is, the Productivity gap is due to two factors: Scale inefficiency (Si) and Pure technical inefficiency, the managerial component of inefficiency, (Pti).
It is worth stressing that all indices (1–4) have a double “relative” content. They are relative to the Dmus considered, in that indices are not invariant to the inclusion (exclusion) of Dmus in the analysis. And they are relative to the efficient Dmu. That is, any inefficiency contained in the best performing unit (efficient Dmu) has no role in computing efficiency indices (1–4). Therefore all indices in (4) are “gross” of any lack of efficiency burdening the best performing Dmu.
In addition, a warning is in place as for the fact that productivity according to any Dea model is at most equal to one, as it is also made clear in (4). Attention should therefore be paid in comparing conventional aggregate productivity, such as, for example, that provided by the ratio of Gdp to population (see Fig. 1) and productivity measured according to (1). Not only the two ratios have different denominators, but that provided by (1) is also subject to a scaling factor that makes its values range from 0 to 1.
The way we estimate the Vrs and Crs frontier in Fig. 2 is by means of a Dea model known as Slack Based Measure (Sbm) of efficiency (Tone 2001). We summarize without describing the main characteristics of the efficiency index provided by this model: it is consistent with the Pareto-Koopmans efficiency; can be understood as a radial measure in the sense that all partial measures (slacks) are added up into a scalar; it is “unit invariant” due to the characteristic of converting absolute slacks into proportional ones; it is not “translation invariant”, as it carries the basic characteristics of additive models; it is monotonic increasing with respect to input and output slacks; it depends (as any Dea efficiency index) only on the reference set.Footnote 18
The Sbm model is:Footnote 19
where Y is the s by n matrix of s outputs and n Dmu.Footnote 20 Each row vector \({\varvec{y}}_{\varvec{i}}\) (\(\hbox {i} = 1,\ldots ,\hbox {s}\)) represents one dimension along which output is being measured; the number of Dmu (n) is given by the number of Municipalities, Provinces, Regions or Local public companies depending on which layer of government the analysis is run (see Table 2); X is the m by n matrix of current expenditure; t is a scalar, s and z are (s \(\times \) 1) and (m \(\times \) 1) column vectors of output and input slacks, respectively; \({\varvec{p}}_{\varvec{Y}}^{\varvec{T}}\) and \({\varvec{p}}_{\varvec{X}}^{\varvec{T}}\) are row vectors of output and input weights, respectively. t is the sign for transpose.
Objective function in (5) provides, for each Dmu, a scalar \(\tau \) (\(0\le \tau \le 1)\) which is an efficiency index. Depending on whether the linear program (5) is solved under the assumption of constant return to scale (\(\varvec{\lambda } \ge 0)\) or variable return to scale (\(\varvec{e}^T\varvec{\lambda } =1),\) the resulting efficiency index (\(\tau \)) is that described by (1) or (1 \(-\) Pti) in (3), respectively Banker et al. (1984).
The reason we selected this particular model out of the set of Dea models is that it combines all the advantages of additive models, (that is, it takes into account non zero slacks which go unaccounted in radial models) hence its estimates also mix efficiency (in outputs and inputs) while, at the same time, it provides a single index of efficiency (in the 0–1 range) which is what the additive types of models do not. Because Sbm model manages to measure mix inefficiency it embodies a partial balance, as compared to other Dea models, to the characteristic of Dea of assessing efficiency under the most advantageous selection of parameters for the unit being evaluated.Footnote 21
Model (5) is not, however, suitable for cases where the number of variables (inputs and outputs) is large relatively to the number of Dmu. When this happens Dea is caught into a dimensionality curse: its discriminating power tends to vanish. But this is indeed the case of public services provision due to the multidimensional characteristics of outputs (see Sect. 3).
We therefore integrate model (5) with Principal Component Analysis (Pca) in order to reduce dimensions while keeping most of the variance accounted for by the remaining variables. Integration of Dea model with Pca is due to Ueda and Hoshiai (1997), Adler and Golany (2001, 2007) and Adler and Yazhemsky (2010). The extension of Pca to Sbm models is a novelty, not yet developed as far as we know. We label such an extension Pca-Sbm model:
Where, in addition to the usual symbols, we have introduced matrices \(L_X \) and \(L_Y \) made of (row) eigenvectors obtained from single value decomposition of X and Y correlation matrix, respectively.
Dimensions reduction comes through elimination of eigenvectors with lower eigenvalue, usually values less than 1, while retaining at least 70–80 % of total variance.Footnote 22 In this way (6) maintains a high discriminating power despite the presence of a large number of variables.
Because Dea models are highly sensitive to extreme values of inputs and outputs, data were subjected to outliers detection by applying the data cloud method proposed by Wilson (1993, 1995).Footnote 23
In addition it is known that Dea faces a bias problem because its efficiency estimates are meant to be relative to a (true) but unobserved production frontier. Since estimates necessarily come from a sample of the population, it follows that efficiency indices depend on sampling variations. More precisely Dea efficiency indices are upward biased because by construction full efficiency is reached by at least one unit in any sample. Bootstrap techniques have been proposed to deal with this problem. Banker (1993) and Banker and Natarasan (2004) deal with the case of a single output multi input case and show that Dea frontier estimates are consistent estimators of any monotone concave production technology. The extension to the multiple input-output case is due to Simar and Wilson (1998) and Daraio and Simar (2007). The basic idea is that of sampling with replacement observations from the data set and in that way create a random data set (replicates) from which to obtain a bias corrected estimator and confidence intervals for significance tests.Footnote 24
Pca-Sbm model (6) provides efficiency indices \((\tau )\) which one wished to be able to compare across services and tiers of government.Footnote 25 But, in general, that is not the case. If (6) is separately run on two different services, say Health and Education, then efficiency indices obtained for Education cannot be compared to those for Health. However some sort of comparability is needed if we want to draw a picture meaningful for the whole Country.
At first sight it might seem that if an aggregate measure of productivity was aimed at then one should run an “all inclusive” Dea by assigning to each Provinces all the services provided within its boundaries, no matter whether provided by the Province itself, the Municipalities (within it) or by the Region the Province belongs to.Footnote 26 That would then allow for comparability of results across Provinces but it would do so at the cost of: (i) not being able to distinguish by layers of government because only Provinces would remain; (ii) not being able to distinguish among services within the Provinces as they all would be credited the same productivity. In other words, an all-inclusive Dea with Provinces as Dmus would overlook the fact that in reality different services not only are different in nature but they are also provided by different layers of government. These are, in some cases Municipalities, in others, Provinces, or Regions or even Local public companies.Footnote 27
We propose, instead, to rely on an assumption similar to that contained in National Accounts methods about public expenditure. In the same way as there it is assumed that productivity for all types of public expenditure is comparable across levels of government and services, and in addition that it equals one, we propose to retain the assumption as far as comparability of productivity across services and levels of government is concerned, but remove the assumption about level of productivity being fixed at one and replace it with the estimates from model (6). In other words, while National Accounts assume that the scale for productivity is made of just a single value: 1, and further assumes that it is comparable across services and tiers of governments; we propose, instead, that productivity’s scale ranges from 0 to 1, and (as in National Accounts) that it is comparable across services and layers of government. This amounts to credit the ranking coming out from (6) with a degree of level comparability across services and levels of government.
Following this assumption, indices from (6), are aggregated across:
-
(a)
Services, within a layer of government, according to the service’s budget share;
-
(b)
Layers of government, for given service, according to the government layer’s expenditure share for the service.
Either way the aggregate index is a convex combination of elementary efficiency indices from (6). To aggregate across services (within a layer of government, in our case the Provinces), we group services into two groups: those (\(\hbox {j}=1,\ldots ,\hbox {J}\))Footnote 28 provided by Regions (the top layer), and those (\(\hbox {i}=1,\ldots \hbox {I}\))Footnote 29 provided by Provinces or layers below (Municipalities and Local public companies). For each of the \(k(1,\ldots ,K)\) Provinces we compute each service’s budget shares as:
where \(c_{i,k} ,\) (\(i=1,\ldots ,I\)) is the expenditure level for each service (\(i=1,\ldots ,I)\) in Provinces \(k(1,\ldots ,K)\); while \(c_{j,k} ,\) (\(j=1,\ldots ,J)\) is the expenditure level for services (\(j=1,\ldots ,J\)) in Provinces \(k(1,\ldots ,K)\). The peculiarity for group J services (those provided by Regions: Health and Administration services) is that expenditure is assigned to Provinces, within the Region, according to their share of Regional Public Sector value added (\(q_k\)).Footnote 30
The overall index of efficiency for Provinces (k) is then given by:
where \(\tau _{i,k} \), (i \(=\) 1,...,I) and \(\tau _{j,k} \), (j \(=\) 1,...,J) are efficiency indices from (6) for the \(i=1,\ldots ,I\) and the \(j=1,\ldots ,J\) services and \(\mathop \sum \nolimits _{i=1}^I w_{i,k} +\mathop \sum \nolimits _{j=1}^J w_{j,k} =1\).Footnote 31
A second type of aggregation takes place for given service \(h(1,\ldots ,H)\), over tiers of government within a Region \((r=1,\ldots ,R)\). The aim being that of arriving at a Regional index of productivity for each service. For each Dmu \((l=1,\ldots ,L)\) providing a given service within a Region (no matter if at Regional, Provinces or Municipality level) its share of expenditure is given by:Footnote 32
Then the overall Regional index of productivity for service \(h(1,\ldots ,H)\), Dmu \(l( {1,\ldots ,L})\) and Region \(r(1,\ldots ,R)\) is:
with \(\mathop \sum \nolimits _{l=1}^L w_{l,h} =1\).
Results
Applying Pca-Sbm model (6) to public services listed in Table 1 and detailed in Tables 4, 5, 6, 7, 8, 9, 10, 11, 12, 13 and 14 in the Appendix provides a large set of information which can be summarised according to productivity and inefficiency measures as in (4). However in order to correct model (6) estimates for bias we have followed Dea’s best practice of providing bias corrected estimates by means of bootstrap procedure. That has allowed us to construct a 95 % confidence interval for efficiency estimates (see Sect. 4). The intervals turn out to be rather narrow showing that the sampling error is well accommodated by the model (see Tables 15, 16, 17 in the Appendix, for major services).
Summary information about coverage (as share of population) per services and layers of government is provided in Table 2, which also reports the numbers of original variables (Inputs and Outputs) and the Principal component numbers of variables. Pc-variables are only used on the output side because inputs are in all cases made of total current expenditure.Footnote 33 The explained variance is in the last column and is in all cases well above the literature recommended 70–80 % threshold of total variance (Adler and Yazhemsky 2010). No Pc-variables were used in Security (municipal) because due to the large number of observations model (6) showed enough discriminating power. The lowest number of Pc-variable has been intentionally kept at 2, even if further restriction would have been justified in terms of explained variance, in order to let model (6) have room to also estimate mix inefficiency, which is what, among other features, distinguishes Sbm models from other Dea (radial) models.Footnote 34
For convenience of presentation we first deal with Productivity gap (Pg) and Pure technical inefficiency (Pti) indices for each service listed in Table 1, and to save space we group the results at Regional level (Sect. 5.1), then we examine Scale inefficiency (Si) and the related question of optimal size (Sect. 5.2), eventually we summarize the results in a territorial index of Public Sector productivity, with Provinces as units of reference (Sect. 5.3).
Public Services Productivity
Figure 3a–c and Table 3 provide a condensed representation of Pg and Pti indices as from (4) aggregated at Regional level according to (8). One first interesting result is about indices for Health and Education (over 70 % of public expenditure accounted for in the analysis, cf. Table 1). Although both services are financed by Central Government, actual provision comes under Local Government supervision (Regions for Health services; Municipalities and Provinces for Education). The results suggest that such a supervision has an important role as far as productivity is concerned. Both Pg and Pti indices show a wide differentiation across Regions hinting for a substantial role of Local Governments in organising efficient provision.

a–c Major public services productivity and inefficiency indices by Region
As for Health services (53.3 % of total expenditure, Table 1), Fig. 3a shows that Basilicata has the best performance in terms of Productivity gap (lowest value of Pg index), while some Northern Regions (Lombardy, Veneto and Emilia e Romagna) and some of the Central Regions (Umbria, Marche, Abruzzo and Molise) come out to be relatively more productive than the remaining Regions.Footnote 35 The worst results are for Friuli Venezia, Apulia, Calabria, Sardinia and Piedmont. Pti index, which is a measure of managerial conduct, is relatively high for most Southern Regions hinting to the possibility of large efficiency gain through better managerial performance. Moreover Pti is significantly smaller than Pg for large Regions like Lombardy, Veneto, Emilia e Romagna, Lazio, Campania and Sicily and small for small Region such as Aosta Valley, thus providing evidence of increasing returns to scale at small size and decreasing returns at large size. As argued infra, (Sect. 5.2.1) coordination within service’s decision units is likely to be the factor behind decreasing returns. However such inefficiency is by its nature outside the reach of managerial control. These results conform rather well with Giordano and Tommasino (2011) even though they use different output measures (life expectancy).
Contrary to common wisdom Southern Regions fare well as far as Education is concerned (19 % of total expenditure, Table 1).Footnote 36 Relatively low Pg indices show for most Southern Regions, whereas a rather ample set of regions (Piedmont, Lombardy, Veneto, Liguria, Friuli Venezia Giulia, Tuscany, Lazio and Campania) has higher values (Fig. 3b). The bulk part of the gap is due to the managerial component, the Pti index. On the other side, Scale inefficiency (as measured in Fig. 3b by the distance between Pti and Pg indices) is a problem characterizing mainly large Regions. In this case, our results are in contrast with those in Giordano and Tommasino (2011). Most likely the difference is due to the variables selected as output indictors. Giordano and Tommasino use the Invalsi test. However Montanaro (2008) and Cipollone et al. (2010) find that pupils performance is strongly correlated to socio-economic variables.
As for Administration (21.5 % of expenditure, Table 1), Pg and Pti indices are widely differentiated across Regions (Fig. 3c). Special Statute Regions (Ssr) show high level of both. However, this result might be due to data heterogeneityFootnote 37. Ssr, because of their wider set of devolved matters, provide services not provided by other Regions. Although these services have not been included in the analysis, absence of reliable accounting procedures at national level makes Administration, in some respects, a catch all type of expenditure. Southern Regions (except Basilicata and Abruzzo) are on average less productive (higher Pg index); whereas more productive Regions in the North and Centre are Piedmont, Lombardy, Veneto, Emilia e Romagna, Tuscany and Marche. Scale inefficiency is a problem limited to very few cases. Large Regions (Piedmont and above all Lombardy) more than smaller Regions (Umbria, Basilicata), suffer for Scale inefficiency, pointing to the possibility that decreasing returns are more of a problem than increasing returns.
Table 3 shows overall averages for Productivity gap and inefficiency indices for the above major services and for the minor ones of Table 1. As for major services, on average Pg is more pronounced for Administration and Education (66 and 45 %) than for Health (34 %). In accounting for the level of Pg index in Health and Administration services, the major role is for the managerial component (Pti), while scale inefficiency (Si) is of minor importance, on average. Smaller services (Transport, Waste management, Social services, Security and Road maintenance) add up to 6.3 % of total expenditure (see Table 1).Footnote 38 The peculiarity of productivity and inefficiency indices for this group of services is the high level of both Pure technical (i.e. managerial) and Scale inefficiency. That is Productivity gap is relatively high because of both a sizeable managerial slacks and a scale of operation far from optimal.Footnote 39
In short these results provide evidence of a significant role by tiers of government in affecting productivity despite services being mainly centrally financed. Local Governments differ widely in terms of productivity. At the same time, within levels of government, different services show different level of productivity thus providing a hint for the presence of sector specific sources of inefficiency. That is confirmed by the presence of large slacks in terms of managerial efficiency (Pti index). Returns to scale also show as a major source of gap in productivity and to them we now address the analysis.
The Scale Problem
Scale inefficiency index (2) measures how productivity is constrained by sub-optimal scale of production. Dmu’s scale can, however, mean different things because we deal with two types of dimensions: (i) the size of the Dmu providing each service, and (ii) the size of the government’s tier. For instance, while scale efficiency for a Local public company providing public transport depends on the size of the service provided, most commonly measured in terms of total expenditure; instead, for a given level of government, say Municipality, scale does not depend on the expenditure level for a single service, but rather on total expenditure for services provided and on the number of production units to coordinate.
The distinction between these two types of scale comes from the role played by the internal organisation of Local Governments (coordination among services providing units) as a separate production factor form the internal organisation of a single service providing unit. What distinguishes a “small” from a “large” level of government is not just the dimension (scale) of each service provided but rather the complexity in internal organisation due to the presence of many service providing units. For example, in providing Health services a small Region faces a less complex problem than a large Region, not so much in technical aspects of service provision, but rather in the number and size of local health units (Asl) to operate and coordinate. Likewise what distinguishes a small Municipality from a larger one is the amount of coordination effort required to organise together large services as compared to small ones.Footnote 40
Of course these two organisational activities tend, in general, to have a joint role and to distinguish one from the other is an almost impossible task in practice. In our case, however, we can test for their effects on efficiency by running separate Dea models on each service and on each tier of government. In short, we have two distinct scale inefficiencies: one for each service (to be dealt with in Sect. 5.2.1) and one for each level of government (Sect. 5.2.2).
From an operational point of view scale inefficiency provides no hint as to how increase productivity in the short run. Its usefulness is towards the long run type of decisions about optimal scale of production. In describing the results we concentrate, therefore, on locating optimal scale with respect to actual scale. This provides evidence on how scale for services or for levels of government should be adjusted in order to gain in long term productivity. It also provides guidelines on why and how Central Government should exclude scale inefficiency from the computation of standard cost in order to consistently set incentives for Local Governments’ accountability.
Scale Inefficiency in Major Services
We now look at major services in terms of expenditure levels: Administration (for each of the three tiers of government), Health (Regions) and Education (Provinces) together they represent almost 90 % of expenditure for services included in our analysis (see Table 1).
Figure 4 contains box plots of actual scale of production for Administration at each level of government (Regions, Provinces and Municipalities). It also shows optimal scale location. In most cases Regions operate under decreasing returns to scale as it is clear from optimal scale (1.3 bln—Emilia e Romagna and Tuscany) being below actual median scale (1.4 bln, Veneto). On average, therefore, productivity is hindered by scale inefficiency which burdens larger Regions more than smaller ones. Peculiarly, Provinces hardly show any increasing returns. That is, optimal scale of production is close to the smallest actual scale. This result is even sharper for Municipalities. For large ones, scale is the major problem: Rome, Milan and Naples operate at much lower level of productivity than smaller towns: the optimal scale being roughly less than 1/100 the size of large Municipalities.Footnote 41

Optimal scale (filled circle) and box plot for actual scale of production in Administration. a Relative absolute deviation from the mean: 64 % Regions, 58 % Provinces, 112 % Municipalities; b outliers (above 1.5 interquartile distance) are not shown
Health services are made of three groups of services: collective health care; District health care and Hospital services (see Appendix for details). Each group of services has its own optimal scale. For Collective health care optimal scale is that of Friuli Venezia Giulia, while for Hospital services is that of Molise and that of District health care that of Abruzzo. In all cases they are Region relatively small.
On average, however, Scale inefficiency for Health is smaller than for other services because the bulk part of the Productivity gap index is due to Pure technical inefficiency (see Table 3).
A different situation is that of Education (Fig. 5) whose Dmu is the Province level of government.Footnote 42 Returns to scale are decreasing, with optimal size of 250 mln (average between Sassari and Trieste) and a median size of 270 mln (Caltanissetta and Mantova). Even in this case it is plausible that decreasing returns are due to a lack of coordination that gets more severe as size (expenditure) increases.
Overall, the emerging picture is one of decreasing returns as the main characteristic of major public services.

Optimal scale (filled circle) for District health care and Education, Optimal scale (filled diamond) for Collective health care, Optimal scale (filled triangle) for Hospital services and box plot for actual scale of production in Health and Education. a Relative absolute deviation from the mean: 68 % Health, 64 % Education; b in Education outliers (above 1.5 interquartile distance) are not shown
Scale Inefficiency by Levels of Government
In order to study Scale inefficiency by levels of government we run a separate Dea-Sbm (6) on services grouped according to the tier of government they belong to. We assign Health and the Regional share of Administration to the Region group; then, the Provinces share of Administration, Road maintenance and Education to the Provinces group; and, the Municipality share of Administration, Transport, Waste management, Social services, Road maintenance and Security to the Municipality group.Footnote 43
The single input, for each group, is total expenditure for all services belonging to the group, whereas outputs are the set of all outputs provided by the services within the group (see Sect. 3 and Appendix). Results are summarized in Fig. 6. On average, sources of inefficiencies differ depending on levels of government.Footnote 44 Municipalities have a higher productivity level (lower and less disperse Productivity gap), while Regions are at the bottom of the scale with the highest gap. Interestingly, though, the main source of differentiation comes more from Scale inefficiency than from Pure technical inefficiency. While Provinces fare worse than Regions and Municipalities in terms of managerial efficiency (Pti), the contrary happens in terms of Scale inefficiency. Therefore, in the short run, productivity gains can be achieved through better managerial efficiency at Regional and Municipal level.

Productivity and inefficiency indices by tiers of government
Only four Regions (Lombardy, Lazio, Sicily and Campania) operate under significant decreasing returns to scale, all the others face sharp increasing returns up to a budget of about 10 bln Euro (the optimal scale, see Fig. 7).Footnote 45 Considering that by themselves Administration and Health, the two most representative Regional services, operate under decreasing return to scale and that for the two of them the optimal scale is of about 5 bln (as average scale from Emilia e Romagna, Tuscany, Friuli Venezia G., Abruzzo and Molise, see Figs. 4, 5), whereas Fig. 7 shows that for Regional services taken together, optimal scale comes up to a budget of about 10 bln, we can speculate that the supervising role of Regions over the entire set of services is an activity characterized by increasing returns to scale up to the 10 bln scale.

Optimal scale (filled circle) and box plot for actual scale of production by tiers of government. a Relative absolute deviation from the mean: 61 % Regions, 51 % Provinces, 120 % Municipalities; b outliers (above 1.5 interquartile distance) are not shown
As for Provinces (Fig. 7), three have size of above the 400 mln (Rome, Milan and Turin) and none in the area between 200 and 400 mln. Optimal scale is of 56 mln,Footnote 46 therefore in most cases Provinces operate under decreasing returns to scale. That is, on average, they are “too big” for efficiency.
Municipalities in Fig. 7 show a very high variability in budget size (Relative absolute deviation of 120 %). Optimal scale is about 64 mln and most of them operate under significant decreasing returns. Such a result cannot entirely be taken as a support in favour of smaller Municipalities because those examined here are County Towns, which although small are still much bigger than average sized Municipality.
Public Sector Contribution to Productivity
Taking Productivity index (1), as provided by model (6), and aggregating—according to (7)—the expenditure weighted indices of productivity across services within each Provinces level of government, we get a measure of average productivity of public services expenditure at the level of Provinces.Footnote 47 Figure 8a shows the ranking of Provinces according to Public Sector index of productivity. Major points worth stressing are:
-
(i)
Most Northern Regions, more productive in terms of conventional per capita Gdp (see Fig. 1a), have also high levels of Public Sector productivity (with the important exception of Ssr);
-
(ii)
North–South divide, which is apparent in the ranking based on per capita Gdp (see Fig. 1a), is less evident in terms of Public Sector productivity. In addition, it emerges an East–West divide for Central and Southern Regions.
Altogether these results suggest that Public Sector productivity varies significantly across the Country. Moreover the relationship between conventional productivity measure (per capita Gdp, Fig. 1a) and Public Sector productivity (Fig. 8a) seems to be rather weak.Footnote 48 In fact, cases are observed where high per capita Gdp goes together with high Public Sector productivity (some of the Northern Regions), and case where low per capita Gdp goes together with high public productivity (Regions on the Eastern coast).

a, b Public sector productivity index (2009)
Special Statute Regions (Ssr), show very low level of Public Sector productivity (Fig. 8a). On this point we have already noticed (Sect. 5.1) that Ssr fare rather badly on Administration (see Fig. 3c), probably due to Ssr’s specific activities which end up being classified in this group of services. To isolate the role on final results played by this group of services we have excluded it from the analysis to obtain Fig. 8b. Indeed, Ssr gain in terms of productivity (mainly Trentino Alto Adige, Aosta Valley and Sardinia) thus confirming the problematic role of Administration. Friuli Venezia and Sicily, however, still lack in productivity and the emerging picture of an East–West divide is confirmed.
It is of some interest to note that these results hold even if convexity assumption is relaxed and a Full Disposable Hull (Fdh) model is used in place of model (6). Figure 9a shows that the main results of Fig. 8a: North–South divide (although less evident than commonly thought) and the relatively new East–West divide hold even for Fdh model specification.Footnote 49

a, b Public sector managerial productivity and Fdh index (2009)
As for the different role of Scale Inefficiency (Si) and Pure Technical (managerial) Inefficiency (Pti), Fig. 9b shows that major results depicted in Fig. 8a are overall confirmed even with reference to the only Pure Technical Inefficiency. That is to say that managerial inefficiency on itself contributes to what still remains of the North–South divide and to the emerging East–West divide. Spending review type of policy would benefit from this sort of analysis as it shows what can plausibly be achieved in the short run in terms of efficient expenditure.
A further result can be drawn if we assume Public Sector productivity index from Fig. 8a to hold for the whole of public expenditure in National Accounts (i.e. the Public Sector component of Gdp). It is clearly an assumption which can lead only to speculative results because Public Sector productivity index in Fig. 8a concerns only services detailed in Table 1, and by no means they exhaust the set of services provided by the General government.Footnote 50 The aim of such an exercise is that of showing how conventional measure of productivity (Gdp per head) could be modified once Public Sector productivity is taken into account.
Per-capita Gdp distribution by Provinces is in Fig. 1a, while Fig. 1b shows the distribution of per-capita final public expenditure, both from National Accounts data. This is the conventional picture, characterized by standard assumption of 1–1 inputs to outputs ratio for public expenditure.Footnote 51 We replace this ratio by Public Sector productivity index (1) as from Fig. 8a, which allows us to compute a per capita inefficient expenditure (Fig. 10a).Footnote 52 That is, the amount per capita public expenditure (from National Accounts) could be reduced while keeping public services at given level. This reduced (real) public expenditure once added to private final expenditure, from National Accounts, leads to a new level of Gdp which embodies an efficient (real) level of public services. Let us call it “efficient-Gdp”

a, b Public sector contribution to productivity (2009)
Comparing per capita efficient-Gdp to actual per capita Gdp at Provinces level (as from Fig. 1a) leads to changes in rankings (re-ranking) among Provinces which are depicted in Fig. 10b.Footnote 53 The overall picture is rather familiar by now: public expenditure is productivity enhancing both for some of the “rich” Northen Provinces and for “poor” Centre-Eastern and Southern Provinces. For almost all Provinces belonging to the Ssr (including Islands) public expenditure tends to reduce overall productivity. The same happens for some of the West-Central Provinces, namely those in Liguria and Lazio.Footnote 54
Concluding Remarks
We have shown how to measure Public Sector contribution to the Country’s overall productivity, hence competitiveness. We have faced two major difficulties. One is that data are not being systematically collected for this purpose. Full coverage in terms of services, areas and tiers of government is, therefore, a serious problem. And so is that of gathering a set of outputs and inputs measurements to consistently represent public services which are by their nature characterized by high dimensions both in provision and utilization. And this leads to the second major difficulty, that of devising a viable methodology capable of dealing with large set of variables while retaining for the underlying model enough of its discriminating powers.
Systematic data collection on public services is the only satisfactory solution for the first problem. At the present it can only be partially solved, as we have done, by recourse to a merge of data sets. As for the second problem, Data Envelopment Analysis integration with Principal Component Analysis provides a satisfactory way to deal with large dimensions while maintaining a sufficient discriminatory power to Dea models.
Results show that Public Sector contribution to productivity is very differentiated across services, layers of government and area. If National Accounts were to include such a measure of Public Sector productivity, the “correction” to the Country’s conventional economic picture could be substantial. The qualitative results in terms of services productivity and its territorial variability are of help in assessing public policy programs and the conduct of Local Governments. The long lasting problem of enhancing economic growth gains an additional instrument which allows to identify areas, services and levels of government that constitute an obstacle to growth and a cause of waste in terms of public expenditure. This type of analysis contributes to explain why, in the more consolidated line of research on the determinants of growth, different items of public expenditure are differently correlated to growth (Aiello and Scoppa 2000; D’Acunto et al. 2004).
Notes
The problem of providing a better estimate for quality and quantity of public expenditure has given raise to a vast literature. Limiting the attention to some of the most recent Italian contributions, Birpi et al. (2011) review the large amount of work carried out by the Bank of Italy on public services and show how, in almost all cases, lack in efficiency burdens the Southern regions more than the rest of the Country. As for sector specific studies, education and health services have gathered most of the attention. Montanaro (2008), Cipollone et al. (2010) and Giordano and Tommasino (2011) provide evidence of the persistence of a North–South divide in efficiency and quality in education, with some exception (Abruzzo fares better than Liguria and Trentino Alto Adige), which turn out to be in line with some results of our research. As for health services, (Alampi et al. 2010) show that in terms of expenditure Italy has followed similar trends to those of major industrialised countries, although diversity persist within the Country both in terms of per capita expenditure and in terms of quality. Francese and Romanelli (2010) and Alampi and Lozzi (2009) show the presence of inefficiency due to internal organization in service providing with a large variability across areas. This variability only partially conforms to the North–South Divide. There are relevant exception, on the positive sign, for instance, Puglia does better on some services than Piedmont and Liguria.
The determinants of the North–South growth gap have been debated for long and there seem to be no widespread agreement short of the acknowledgement for the strategic role of public expenditure. Aiello and Scoppa (2000) show the lack of convergence among Italian Regions and the positive correlation between growth and public expenditure in infrastructures while it appears to be a negative sign for the redistributive components of public expenditure. D’Acunto et al. (2004) and Bronzini and Piselli (2009) both provide evidence of a lack in public expenditure to provide the required investment in human capital capable to sustain growth.
Provinces are the Eurostat Nuts3 statistical territorial units.
Current final expenditure by General Government. Therefore, redistribution through transfer payments is not included.
From a legal point of view they are private companies. However either because they are 100 % owned by public institutions or because as a matter of fact public institutions take the role of residual claimant, they are better seen as belonging to the Public Sector.
Such a figure is obtained by netting Eps’s total current expenditure from transfers to the private sector. It is therefore a rough estimate of Eps’s final consumption of goods and services.
In Table 1, first column, total expenditure comes to be less than 599 bln. because some of major nationally provided services are excluded, such as Administration, Defence and Security. We believe that exclusion of these services would not alter the results because the best working hypothesis would be that of uniform territorial distribution. Some minor services are also excluded due to lack of reliable measures of service output.
In the direction of limiting the data set, more effectively than this trade off operates the lack of systematic data collection on public services at local level. A description of the organisational aspects of services provision by tiers of government together with a list of variables used to measure services’ quantity and quality is contained in the Appendix.
However, bootstrap techniques are available to overcome the problem to a large extent. See further Sect. 4.
The term Dmu is jargon in Dea literature to generically indicate the decision centre responsible for converting inputs into outputs. In practice, however, data availability constraints the choice of the decision centre. With reference to the services listed in Table 1 the Dmus are as follows: (i) Administration is made of three different group of services one for each layer of government: Regions, Provinces and Municipalities, and they are taken to be the Dmu; (ii) as for Health the Dmu are supposed to be the Regions. This choice is guided by the fact that data are available at regional level, although decisions are mainly taken at the lower level of Local Health Authorities (Asl) and/or Hospitals; (iii) as for Education the Dmu are Provinces even though schools and Municipalities have degrees of freedom in decision making; (iv) in the case of Transport and Waste management, Local Companies make the Dmu; (v) as for Social services the Dmu are the Municipalities, even though at times they operate through concessions to private non-profit organizations; (vi) as Security concerns only services provided by local Police we considered Municipalities as the Dmu; (vii) Road Maintenance is divided into two services: Provincial roads and Municipal roads. Accordingly Provinces and Municipalities constitute the Dmu. More details on the number of Dmu per services, coverage and number of inputs and outputs are further on in Table 2 and in the Appendix.
Or by any parametric method for that matter. Because parametric models, in as much as they rely on regression analysis, take an “average” of observed values.
Additionally, although not exploited in this paper, Sbm provides information on input and output specific slacks, which is of interest for research with a managerial objective in order to detect actions to carry out to improve efficiency. A word is due about the convexity assumption required by Sbm and most of Dea models (short of Fdh model). More than an assumption that is forced by the way data are collected or made available. We do not have data on each school, hospital and so on, but rather aggregate data, that is the single units have been added up beforehand and in the addition units of different dimension (scale) have been brought together. In other words, the assumptions of additivity and divisibility (i.e. scaling) have been implicitly used in the process of data collection. But the two together imply convexity (e.g. Mas-Colell 1987, p. 654). We thank a Referee for calling our attention on this point.
This being the commonly accepted rule. In this paper, however, explained variance never goes below 80 %.
Before applying Wilson (1993, 1995)’s procedure, observations with missing values in one or more outputs have been excluded. While Regional provided services (mainly General administration and Health) never showed any missing value, instead for services provided by Provinces and Municipalities (County towns) elimination of observation with missing value has reduced the set of about 20 %. In addition, for Municipal Security, where the set of observation is relatively large (3051), we followed Barone and Mocetti (2009) criterion of discarding first and last percentile. Wilson (1993, 1995) data cloud procedure is implemented by the Fear software (Wilson 2008).
As a precautionary choice, we have set the number of replicates at 2000, well above the recommended value of 1000 (Simar and Wilson 1998, p. 57) , while the smoothing parameter has been kept at default value of 0.14. To run the bootstrap method we made use of the package Benchmarking for R (Cran repository) by Bogetoft P. and L. Ott.
There is no open source or commercial software that implements Sbm-Pca model. We have therefore developed an optimization code in R for use with model (6).
Grouping according to Regions would not leave enough room for differentiation at local level.
However if an all-inclusive Dea was resorted to, we would have to face the problem that not all services are present at Provinces level. Hence a very limited analysis would have been possible. In addition, by adding together expenditure for different services one would lose the information contained in budget shares as weights for different services.
With J \(=\) 4 as there are two services provided at the Regional level: Health (made up of three distinct services, see Appendix) and Administration.
Where I \(=\) 9. Namely, three at Provinces level (Administration, Education, and Road maintenance); four at Municipality level (Administration, Social services, Road maintenance, and Security); two for Local public companies (Transport and Waste management).
Data kindly provided by ISTAT
For services with no available data at a given layer of government, budget shares are set to zero. Thus the overall efficiency index is not affected by lack of data.
In aggregating over tiers of government within the Region no distinction is needed between I and J groups of services. Hence set H of services is the union of previously defined sets I and J.
Even in cases where more than one input variable were available (Transport) we decided to uniform to the single variable after noticing that efficiency indices (and ranking) were very close under the two and the single variable model.
In selecting principal components loadings we have followed the procedure suggested by Yap et al. (2013).
In selecting output variables for Health services we followed the list of Lea (Essential Levels of Assistance) as from (Decreto Ministero Salute 12/12/2001) and the Report on Lea issued on 2011 (Ministero della Salute 2011b). The list includes conventional output indicators but also includes indicators such as n. of doctors and n. of beds which are usually seen as inputs. Our choice of including them as output indicators rests on the observation that: (i) They are indicators that embody incentive mechanism in terms of financing and therefore come to constitute mandatory services; (ii) These variables have the role of intermediate outputs or are proxy for services which are not easily observed (Nuti et al. 2011) or are used as an indirect way to measure quality (Salinas-Jimenez and Smith 1996). With special reference to the Italian case Nuti et al. (2011) sought advice from a group of hospital managers in order to select the output variable and on p. 325 they observe that: “A particular case is the number of physicians. It is generally considered as an input variable. However, the Tuscan healthcare managers explicitly requested to consider the number of physicians as an output variable because, in their view, it provides the best proxy for measuring primary care services delivered by general practitioners, paediatricians, duty doctors and ambulance services.”; (iii) Selection of outputs (and inputs) has to take into account the overall production process under assessment. For instance, if under evaluation is a set of hospitals then doctors, beds and similar are bound to be considered inputs. Indeed they might even be seen as non discretionary inputs in so far as they are decided by higher decision bodies (i.e. Asl, Regional Assembly). On the other hand, if under evaluation is the whole regional health system (as in Nuti et al. 2011 and in our case) then Central Government finance is bound to be input, while doctors, beds etc. are intermediate outputs or rather they are outputs of first stage of production. To evaluate the whole regional health system it is necessary to include both intermediate and final outputs, that is outputs from all stages of production. If not, a Region which dissipate a share of Central Government finance and therefore provides its hospitals with less doctors, beds an similar, could end up being efficient because evaluated only for the (few) doctors beds etc.. it actually has. We thank a Referee for calling our attention on the need to clarify this point.
This result should be interpreted with caution because quality in our data set is represented only via proxy variables.
Aosta Valley, Trentino Alto Adige, Friuli Venezia Giulia, Sicily and Sardinia are Special Statute Regions (Ssr). A status granted by Constitutional Act. They benefit from higher level of per capita public spending and wider degree of independence in terms of own legislation.
In assessing these results care should be taken for services such as Waste Management, Transport and Social Services where the coverage is lower than for the other services (see Table 21 in Appendix).
Exceptionally high Productivity gap indices in Table 3 are due to large Dmus suffering from huge scale inefficiency which, because of their expenditure level, dominate averages.
This is not to say that large tiers of government are less organisationally efficient. Indeed, even organisational activities exhibit economies or diseconomies of scale.
Municipalities also show larger size variability (Relative absolute deviation of 112 %) as compared to Regions (64 %) and Provinces (58 %), as reported in notes to Fig. 4.
Strictly speaking Provinces do not have total freedom in educational service provision. Some of the services’ basic characteristics are set at national level. However, coordination among schools and building maintenance are managed at Provinces and Municipal level.
Each group is made of: 20 Regions; 81 Provinces; 25 Municipalities. The relative small number of Municipalities is due to the difficulties of gathering cases where all services are present in all the Municipalities. Therefore results for Municipalities should be taken with care.
Of course such a comparison rests on the comparability assumption made in Sect. 4.
Simple optimal scale average of peer Regions (Veneto and Emilia e Romagna).
Average of 10 Provinces operating at optimal scale.
We aggregate at Provinces level all public services covered in the analysis (Table 1). Such an aggregation is only for computational purposes and is independent of which level of government is responsible for provision. Therefore even Health services are figuratively attributed to the Provinces even if are Regions responsible for provision.
Correlation coefficient is just about 0.15 (***).
In particular, national public goods type of services are not considered although most of the services provided locally and some of those centrally financed are included. For more details see notes to Table 1. One could observe, as we did in Sect. 2, that national public goods would probably have a uniform distribution across the Country, therefore not affecting the results in Fig. 8a, b.
i.e.: productivity equals 1 in terms of our Eq. (1).
This result remains substantially unaltered if Administration is excluded from the set of services.
Regional expenditure for Administration has been obtained by netting total expenditure of capital outlay at the same proportion as for the total, COPAFF (2010). For Provinces and Municipalities expenditure data come from Ministero dell’Interno (2012). Municipalities include only County towns (capoluogo).
Data come from Ministero della Salute (2011b). The gap for Trentino Alto Adige and Calabria has been filled with data from ISTAT (2012b) for which distribution by groups of services follows national distribution. It is worth noticing that Ministero della Salute (2011b) directly provides total expenditure by Group of Health services of Table 5 in Appendix.
Act 833/78, states that as a rule Local Health Units comprise from 50,000 to 200,000 inhabitants. Exceptions can only be granted by Regions depending on social and geographical peculiarities.
Expenditure data come from MIUR (2012) which includes expenditure at each school level. Therefore no matter which level of government provides finance, all the expenditure is included. Even included are fees and contributions for guided educational trips.
We do not consider Universities because their actual distribution across the Country would not account for the significant spillorver effects among Regions and Provinces.
Private schools even if receive public funding have not been included.
Expenditure data come from ISTAT (2011c) which includes expenditure from all government level (citizens’ co-payment included). Therefore expenditure from all tiers of government and Local public companies is included.
Data expenditure both for Municipalities and Provinces come from Ministero dell’Interno (2012).
Expenditure is the cost of service (running cost) reported by local public company (or companies), for each County Town (Capoluogo) AIDA-Bureau Van Dijk (2012).
Expenditure refers to the services’ running cost, as from Local public companies budget balance, AIDA-Bureau Van Dijk (2012).
References
ACI (Automobile Club d’Italia) (2011) Annuario Statistico 2011
Adler N, Golany B (2001) Evaluation of deregulated airlines network using data envelopment analysis combined with pricipal component analysis with an application to western Europe. Eur J Oper Res 132:260–673
Adler N, Yazhemsky E (2010) Improving discrimination in data envelopment analysis: P ca-D ea or variable reduction. Eur J Oper Res 202:273–284
Adler N, Golany B (2007) P ca-D ea. In: Zhu J, e Cook DW (eds) Modeling data irregularities and structural complexities in data envelopment analysis. Springer, Berlin
AIDA-Bureau Van Dijk (2012) Banca dati analisi informatizzata delle aziende, Roma
Aiello F, Scoppa V (2000) Uneven regional development in Italy: explaining differences in productivity levels. G Econ 59(2):270–298
Alampi D, Iuzzolino G, Lozzi M, Schiavone A (2010) La sanità. In: Il Mezzogiorno e la politica economica dell’Italia, Banca d’Italia
Alampi D, Lozzi M (2009) Qualità della spesa pubblica nel Mezzogiorno: il caso di alcune spese decentrate. In: Mezzogiorno e politiche regionali, Banca d’Italia
Banca d’Italia (2011), Le infrastrutture in Italia: dotazione, programmazione, realizzazione. In: Workshops and Conferences, vol 7, Roma
Banker R, Charnes A, Cooper W (1984) Models for estimating technical and scala efficiency. Manag Sci 30:1078–1092
Banker RD, Conrad RF, Strauss RP (1986) A Comparative application of data envelopment analysis and translog methods: an illustrative study of hospital production. Manag Sci 32(1):30–44
Banker R (1993) Maximum likelihood. Consistency and data envelopment analysis: a statistical foundation. Manag Sci 39:1265–1273
Banker R, Natarasan R (2004) Statistical tests based on D ea efficiency scores. In: Cooper WW, Seiford LM, Zhu J (eds) Handbook on data envelopment analysis, Chapter 11. Kluwer, Norwell
Bardhan IR, Cooper WW, Kumbhakar SC (1998) A simulation study of joint uses of data envelopment analysis and stochastic regressions for production function estimation and efficiency evaluation. J Product Anal 9:249–278
Barone G, Mocetti S (2009) Tax morale and public spending inefficiency. In: Temi di discussione (working papers), vol 732. Banca d’Italia, Roma
Bauer PW (1990) Recent developments in the econometric estimation of frontiers. J Econometr 46:39–56
Bentivogli C, Cullino R, Del Colle DM (2008) Regolamentazione ed efficienza del trasporto pubblico locale: I divari regionali. In: Questioni di economia e Finanza (occasional papers), vol 20. Banca d’Italia, Roma
Birpi F, Carmignani A, Giordano R (2011) La qualità dei servizi pubblici in Italia. In: Questioni di economia e Finanza, occasional paper. Banca d’Italia, Roma
Bronzini R, Piselli P (2009) Determinants of long-run regional productivity with geographic spillovers: the role of R&D, human capital and public infrastructure. Reg Sci Urban Econ 39(2):187–199
Centro Studi Unioncamere (2013) Demografia delle imprese, Roma
Charnes A, Cooper W, Rhodes E (1978) Measuring the efficiency of decision making units. Eur J Oper Res 2:429–444
Cipollone P, Montanaro P, Sestito P (2010) Misure di valore aggiunto per le scuole superiori italiane: i problemi esistenti e alcune prime evidenze. In: Temi di discussione (working papers), vol 754. Banca d’Italia, Roma
CNEL (Consiglio Nazionale di Economia e Lavoro) (2012) Osservatorio sui servizi pubblici locali. Open data online in http://www.cnel.it
Cooper WW, Ray SC (2008) A response to M. Stone: ‘how not to measure the efficiency of public services (and how one might)’. J R Stat Soc Ser A (Stat Soc) 171(2):443–448
Cooper W, Seiford LM, Tone K (2007) Data envelopment analysis: a comprehensive text with models, applications, references, and DEA-solver software, 2nd edn. Springer, NewYork
COPAFF (Commissione tecnica paritetica per l’attuazione del federalismo fiscale) (2010) I bilanci delle regioni in sintesi–2009. Ministero dell’Economia e delle Finanze, Roma
D’Acunto S, Destefanis S, Musella M (2004) Exports, supply constraints and growth: an investigation using regional data. Int Rev Appl Econ 18:167–188
Daraio C, Simar L (2007) Advanced robust and nonparametric methods in efficiency analysis. In: Methodology and applications, Springer, Berlin
Diewert WE, Nakamura AO (2007) The measurement of productivity for nations. In: Handbook of econometrics, Ch. 66. Elsevier, New York
Durand M, Giorno C (1990) Indicators of international competitiveness: conceptual aspects and evaluation. Oecd Econ Stud 147–197
Eurostat (2013) National accounts. Eurostat, Luxembourg
Fare R, Grosskopf S, Lovell K (1985) The measurement of efficiency of production. Kluwer, Boston
Farrel MJ (1957) The measurement of productive efficiency. J R Stat Soc A 120-Part 3:253–281
France G, Taroni F, Donatini A (2005) The Italian health-care system. Health Econ 14:S187–S202
Francese M, Romanelli M (2010), Health care in Italy: expenditure determinants and regional differentials. In: Proceedings of the XXXVI international ORAHS conference, operations research for patient. Centered Health Care Delivery, Franco Angeli
Giordano R, Tommasino P (2011) Public sector efficiency and political culture. In: Temi di discussione (working Papers), vol 786. Banca d’Italia, Roma
ISTAT (2009) Classificazione internazionale della spesa pubblica per funzione (Cofog), Roma
ISTAT (2011c) Indagine censuaria sugli interventi e servizi sociali dei Comuni singoli e associati, Roma
ISTAT (2011d) Indicatori sui trasporti urbani, Roma
ISTAT (2011e) Indicatori ambientali urbani, Roma
ISTAT (2012a) Conti economici regionali Anni 1995–2011, Roma
ISTAT (2012b) Health for all–Italia, sistema informativo territoriale su sanità e salute, Roma
ISTAT (2012c) Demografia in cifre, dati ufficiali sulla popolazione residente nei comuni italiani derivanti dalle indagini effettuate presso gli Uffici di Anagrafe. Open data online in http://demo.istat.it
ISTAT (2012d) Rilevazione degli incidenti stradali con lesioni a persone, Roma
ISTAT (2012f) Conti economici nazionali, Roma
ISTAT (2012g) Trasporti urbani, Roma
ISTAT (2013) La superficie delle Regioni, delle Province e de Comuni, Roma
Krugman P (1994) Competitiveness: a dangerous obsession. Foreign Aff 73(2):28–44
Kumbhakar SC, Lovell KCA (2000) Stochastic frontier analysis. Cambridge University Press, Cambridge
Lo Scalzo A, Donatini A, Orzella L, Cicchetti A, Profili S, Maresso A (2009) Italy: health system review. Health Syst Trans 11(6):1–216
Lovell KCA, Schmidt P (1988) A comparison of alternative approaches to the measurement of productive efficiency. In: Dogramaci A, Färe R (eds) Applications of modern production theory: efficiency and productivity. Kluwer, Boston
Mas-Colell A (1987) Non-convexity. In: Eatwell J, Milgate M, Newman P (eds) The new palgrave: a dictionary of economics, 1st edn. Macmillan, Palgrave, pp 653–661
Ministero della Salute (2011a) Report on the health status of the Country. Centro stampa del Ministero della salute, Roma
Ministero della Salute (2011b) Rapporto nazionale di monitoraggio dei livelli essenziali di assistenza Anno 2007–2009, Roma
Ministero dell’Interno (2012) Certificati consuntivi delle amministrazioni provinciali, dei comuni, delle comunità montane e delle unioni di comuni. Open data online in http://finanzalocale.interno.it
MIT (Ministero delle Infrastrutture e dei Trasporti) (2011) Conto Nazionale delle infrastrutture e dei trasporti, Roma
MIUR (Ministero dell’Istruzione, Università e Ricerca) (2012) La scuola in chiaro. Open data online in http://archivio.pubblica.istruzione.it
Montanaro P (2008) I divari territoriali nella preparazione degli studenti italiani: evidenze dalle indagini nazionali e internazionali. In: Questioni di economia e Finanza, vol 28. Banca d’Italia, Roma
MSE (Ministero dello Sviluppo Economico) (2012) Conti pubblici territoriali. Open data online in http://www.dps.tesoro.it
Neary JP (2006) Measuring Competitiveness. In: I mf Working paper, September, WP/06/209
Newhouse JP (1994) Frontier estimation how useful a tool for health economics. J Health Econ 13(3):317–322
Nuti S, Daraio C, Speroni C, Vainieri M (2011) Relationships between technical efficiency and the quality and costs of health care in Italy. Int J Qual Health Care 23:324–330
Porter ME (1990) The competitive advantage of nations. Free Press, New York
Salinas-Jimenez J, Smith P (1996) Data envelopment analysis applied to quality in primary health care. Ann Oper Res 67:141–161
Simar L, Wilson PW (1998) Sensitivity analysis of efficiency scores: how to bootstrap in nonparametric frontier models. Manag Sci 44:49–61
Spottiswoode C (2000) Improving police performance: a new approach to measuring police efficiency. In: Report. Public services productivity panel, Her Majesty’s Treasury, London. (http://www.treasury.gov.uk/pspp/studies.htm)
Thomson S, Osborn R, Squires D, Reed SJ (2011) International profiles of health care systems. The Commonwealth Fund, New York
Tone K (2001) A slacks-based measure of efficiency in data envelopment analysis. Eur J Oper Res 130:498–509
Ueda T, Hoshiai Y (1997) Application of principal component analysis for parsimonious summarization of Dea inputs and/or outputs. J Oper Res Soc Jpn 40:466–478
Wilson PW (1993) Detecting outliers in deterministic nonparametric frontiers models with multiple outputs. J Bus Econ Stat 11:319–323
Wilson PW (1995) Detecting influential observations in data envelopment analysis. J Product Anal 6:27–46
Wilson PW (2008) FEAR 1.0: a software package for frontier efficiency analysis with R. Soc-Econ Plann Sci 42:247–254
World Economic Forum (2008) The global competitiveness report 2006–2007, Geneva
World Economic Forum (2012) The global competitiveness report 2012–2013, Geneva
Yap GLC, Ismail WR, Isa Z (2013) An alternative approach to reduce dimensionality in data envelopment analysis. J Appl Mod Stat Methods 12:128–147
Acknowledgments
For helpful comments and for support in data collection the authors wish to thank: Filippo Elba (Università di Firenze), Paolo Roberti, Maria Grazia Calza and Edoardo Pizzoli (Istat), Bruno Spadoni (Confservizi), Emanuele Proia (Asstra), Sara De Marco and Fabian Mazza (Bureau Van Dijk). Generous access to Aida Database by Bureau Van Dijk and funding by the European Commission, Seventh Framework Programme, Grant Agreement No: 244767 is kindly acknowledged. We thank two anonymous referees for their very helpful comments.
Conflict of interest
The authors declare that they have no conflict of interest.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Administration
This expenditure is considered for each of three tiers of government: Region, Provinces and Municipalities.Footnote 55 It is, therefore, treated as three different groups of services according to the layer of government each refers to. Description of detailed services included in this sort of catch-all expenditure is rather difficult as they are heavily characterized by joint cost in production and externalities in utilisation. Services include management of personnel; the working of legislative bodies; expenditures to support economic development when not directly attributed to that specific service (ISTAT 2009); strategic planning and implementation of programs and other services; registry services (birth, marriage, death ceremonies and obtaining certificate copies, for Municipalities is the bulk part); businesses licensing and local tax collection.
As this type of expenditure concerns implementation of policies set by the governing board, it seems justified to include, as a measure of output, the overall efficiency index obtained from the analysis of the remaining services (see Table 1 in the text). Table 4 details the variables taken as output indicators for this group of services.
Health
Health bears the highest expenditure (see Table 1 in the text).Footnote 56 Its governance is essentially in the hands of Regions, in charge of defining the organisational structure of Health Care Districts, providing for a suitable territorial dimension. Although with significant differences at some local areas, Health Care Districts tend to coincide with the second tier of Local Government: Provinces.Footnote 57 Services provision is organised at local level by administrative units: Local Health Authority (Asl), in charge of 50,000–200,000 inhabitants. Population aging, changes in epidemiology and the quest for increased effectiveness and cost concern have oriented health policies towards reorganisation based on division of labour among General Practitioners (Gps), Hospitals and Specialists. In addition, the contribution of families and patients in terms of “out of pocket” payments is undergoing a continuous increase. This has brought a change in the role of hospitals (towards increasing specialisation in terms of professional know-how and technological equipment for treatment of acute illnesses) and a strengthening of Primary care systems (the front-office type of services towards patients). Form an organizational point of view services are divided into three groups: Collective health care; District health care and Hospital services (cr. Table 5).
Collective Health Care
Asl are primarily concerned with protecting, promoting public health and for achieving health objectives and targets set by Central and Regional Government. Each Asl has a health promoting department covering activities such as: prevention; children vaccination; oncological screening; preventing occupational diseases and accidents; immunization against specific and professional hazards; non-communicable diseases; health promotion and education; preventing environmental hazards; prevention, diagnosis and treatment of animal diseases; educational public programs to prevent lifestyles diseases related (smoking, food, alcohol); environmental risk management, legal purposes assessment; issuing of medical certificates. The variables considered as outputs for the analysis are in Table 6.
District Health Care
The name for this group of services comes from its geographical type of organization that turns out to correspond to actual Provinces. Besides the misleading name, services under this heading are those of Primary care of international use (cf. World Health Organization. Health systems). They are provided by Gps, paediatricians and self-employed physicians working under a contractual agreement with the National Health System (Ssn). Gps and paediatricians are expected to provide most Primary care. They act as “front office” for access to Secondary care services. Admission in hospital requires prescription either by Gps or by doctors at the Emergency. Following surgery and primary rehabilitation at the hospital, patients might need services that belong to the Primary Care, such as home care. Old people assistance and care are also provided by Primary care organisations. Mental health care is provided by Ssn in a variety of community-type services. The set of variables used to measure this group of services is in Table 7.
Hospital Services
Hospital services have undergone a deep reorganization in order to gain efficiency by increasing horizontal integration between operational units and vertical integration within types of specialty. National standards have been set for allocation of hospital beds as to 4 per 1000 inhabitants, including 0.7 beds for rehabilitation and long-term care (cf. Ministero della Salute 2011a). The aim being that of promoting a shift from hospitalisation to day care and from day care to outpatient care, home support and residential care (France et al. 2005; Thomson et al. 2011). Currently, hospital care is delivered mainly by almost 700 public structures. Major groups of hospital services are: (a) Healthcare services, provided during inpatient hospital stay and; (b) during outpatient hospital admissions (day hospital); (c) Rehabilitative healthcare services. Elderly and disabled receive care through residential and communal home. Patients are free to choose hospitals while choice of specialists is not allowed. Asl face payments for the treatment received by residents from providers located in other Regions (outward mobility) and, in turn, they receive payments for services provided to patients from other Regions (inward mobility) (cf. Lo Scalzo et al. 2009). Table 8 reports variables used as outputs measurements for this group of services.
Education
Expenditure for Education is the second highest level of expenditure after Health (Table 1 in the text),Footnote 58 and is financed mainly by the Central government with contribution for selected services and objectives from European Union, Regions, Provinces and Municipalities.
From an organisational point of view, Education is Central Government controlled and schools, public and private, have to comply with curricula and teaching methods set by the Ministry of Public Education. Some degree of autonomous decision making has recently been granted to schools. Educational system is divided into 5 levels: Nursery, Primary school, Lower secondary school, Upper secondary school and University.Footnote 59 Length of compulsory education has in recent years been extended up to the age of eighteen. At primary level, which starts at the age of six to end at eleven, students are provided free tuition and textbooks. Primary level can be preceded by three years of pre-school nursery. Secondary education is divided into two levels: Lower secondary school and the Upper secondary school.
The unit of analysis for the present work are the Provinces to which is imputed the whole expenditure for Education (however financed: EU. Government. Region or Municipalities) made up of expenditures by each school within the Provinces. In very much the same way, on the output side, each Provinces is credited with outputs from each of its public schools.Footnote 60 The data collected in order to provide measurements for educational outputs are in Table 9.
Social Services
Social services are provided by a network of public and private partners. Municipalities supervise provision through an accreditation procedure. Finance from EU, Central government, Regions and Private donors is collected by Municipalities.Footnote 61 Act 328/2000 on social welfare makes Municipalities responsible for managing social services, and Regions are in charge for the planning. Expenditure distribution by type of services reveals that support to families with young children accounts for 39.8 % of total; next are services to elderly and disabled, with a share of 21 and 20 %, respectively. Policies aiming at curbing poverty and social exclusion come to 8.3 %, to multi-purpose activities goes 6.3 %. Minor shares go to finance support to immigrants and nomads (2.7 %) and different types of addictions (0.9 %).
Per capita expenditure varies significantly across the Country: Southern Regions and Islands (except Sardinia) all fare below average, whereas their share of reducing poverty and social exclusion type of expenditure is higher than average. Northern Regions, with the exception of Lombardy and Emilia-Romagna, see elderly and disabled related expenditure above average (ISTAT 2011c). Table 10 summarises the variables used to measure outputs for this group of services.
Road Maintenance
Road building and maintenance is shared among different layers of government. Besides motorways network, mainly privately managed on a long term concession contract, the rest of the Country’s road system is managed by a Central Government agency (Anas), Regions, Provinces and Municipalities. Roads classification by layers of government is according to Act (Dlgs 112/1998) which also transferred most of Central Government roads (strade statali) to Regions. Following classification, each layer of government has to finance construction and maintenance out of its own budget. The Country’s road network is about 183.705 km (excluding Municipal roads) of which 4 % are motorways, 11 % Central Government roads and 85 % are managed by Regions and Provinces (MIT 2011; Banca d’Italia 2011). Provinces and Regional roads have a higher share in Northern and Southern Regions (about 40 % each) whereas Central Regions are at about 20 %. As far as Municipal roads, the distribution sees North with about 38 %, Centre 28 % and South 34 %.
Lack of data forces us, however, to limit the analysis to road maintenance at Municipal and Provinces levels.Footnote 62 Table 11 lists the variables used as outputs for this group of services.
Transport
Local transport (city and suburbs busses, underground and local trains) is provided by private or publically owned companies (mostly, Municipalities), under a concession type of contract which, while granting monopoly power, also subsidies the company. Persistent financial distress and worsening of services quality have brought the Parliament to issue a radical reform (D.lgs. 422/97 and 400/99), which grants concessions only through tendering. An incentive type of regulation sets upper subsidy and fares limits, quality standards and penalties in case of underperformance. In addition, reform has brought a substantial devolution to local tiers of government of strategic functions such as coordination of transport systems within the Region (Bentivogli et al. 2008). Division of labour exists among levels of government, with Provinces having the duty of organizing ad providing suburban transport services, while Regions take care of local train transport, and city bus services belong to the Municipalities.
Transport infrastructures are not uniformly distributed across the Country. Taking a network density index given by network length per 100 km\(^2\). major Municipalities have higher indices with no significant differences across the Country. Medium and small Municipalities with low density index are, instead, more frequent in Southern Regions and Islands. Similar imbalance exists in terms of level in service provision. Coaches to population ratio takes its highest values in 30 Municipalities of which 21 are from the North. Symmetrically, out of 22 Municipalities faring the lowest ratio, more than half are from the South (ISTAT 2011d, 2012g).Footnote 63 Table 12 contains the variables used as measures of outputs.
Waste Management
The service belongs to the devolved matters and is organized following subsidiarity principle: Regions have coordination and planning, including the setting of regulatory norms, environmental standards and management of landfill sites (Act 22/1997, Decreto Ronchi). Provinces coordinate management and collection within sub Regional area (Ato, Ambito Territoriale Ottimale); Municipalities take the largest burden of actual provision, being responsible for: (i) Collection, including transportation to transfer stations, drop-off sites for recyclables or disposal facilities; (ii) Transport to landfill sites; (iii) Cleaning of public spaces and streets; (iv) Disposal, including maintenance and operating of special processing and collection facilities, waste transfer stations and landfill sites.Footnote 64
In 2009, waste sorting was active in all the 116 County towns of our Municipality sample. Average waste collection per head was 604.3 kg, showing a reduction when confronted to previous years, mainly in the share of unsorted waste collection, while there is an increase in sorted collection by then reaching 30.4 %. Northern towns show higher per capita waste collection: (660 kg), next come North Est (640 kg), followed by Islands (602 kg) then South and North West (555 kg). As for the share of sorted waste collection, North Eastern Municipalities reach top level of 44.5 %, followed by North West (39.7), Centre (26.9), South (20.4) and Islands (13.5) (ISTAT 2011e). Table 13 lists the variables used as outputs for this group of services.
Security
Local Security is made by a group of services provided by three different Police corps: Municipal; Businesses; and Administrative. Although the bulk activity concerns traffic and road regulation, including fines and documents checking, there is a set of additional activities encompassing a great deal of Municipal collective life. According to National Act 65/1986 Local policemen are public officers, therefore in addition to their duty arising from Mayor’s decisions, they also have to operate in accordance with local public Prosecutor. Businesses Police has a supervisor role on shops and businesses licensing with respect to opening hours, safety, health conditions and consumers’ protection. Administrative police’s principal role is that of enforcing regulation mainly as far as shops permits is concerned and is in charge for administrative procedures of fining. Table 14 contains the variables used as measurements of outputs for this group of services.
Additional Tables
See Tables 15, 16, 17, 18, 19, 20 and 21.
Rights and permissions
About this article

Cite this article
Patrizii, V., Resce, G. Public Sector Contribution To Competitiveness. Ital Econ J 1, 401–443 (2015). https://doi.org/10.1007/s40797-015-0017-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40797-015-0017-4