
Abstract
A new palmprint recognition system is presented here. The method of extracting and evaluating textural feature vectors from palmprint images is tested on the PolyU database. Furthermore, this method is compared against other approaches described in the literature that are founded on binary pattern descriptors combined with spiral-feature extraction. This novel system of palmprint recognition was evaluated for its collision test performance, precision, recall, F-score and accuracy. The results indicate the method is sound and comparable to others already in use.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Biometric authentication is a valuable technique for the automated recognition of individuals. The palmprint recognition (PPR) biometric technique is regarded as reliable and efficient as it has a high recognition rate but is relatively low cost and user friendly. The methods used for PPR can roughly be categorised according to palm features on which the scheme is based. (1) Lines and minutiae. The success of this technique is dependent upon very high resolution of at least 500 dpi [2] to capture the main lines and minutiae of the palm [1]. Edge detectors, such as the Sobel filter [3] or templates [4], can be used to extract the principal lines within the print. Detection of minutiae points is achieved by locating the ridge bifurcation points and endings [5]. (2) Texture. Local binary patterns (LBP) schemes use texture to collect the global pattern of lines [6], ridges and wrinkles. Examples of LBP that accurately recognise, even very low-resolution palm-print images (PPIs) include Gabor transform [7], Palmcode [8], Fusion code [9], Competitive code [10] and Contour Code [11]. (3) Appearance. There are a number of techniques that are appearance based, including linear discriminant analysis (LDA) [12], principal component analysis (PCA) [1], kernel discriminant analysis (KDA) [13] and kernel PCA (KPCA) [13]. The PCA mixture model (PCAMM) is a generative-model-based approach that can also be used to discern palm appearance [14]. Schemes may also combine a mixture of line and minutiae, edge detection or appearance techniques. These hybrid schemes are considered superior as another can compensate limitations in one scheme.
In [15], Fei et al. introduced a method that used a double half-orientation bank of half-Gabor filters, designed for half-orientation extraction. A double-orientation code based on Gabor filters and nonlinear matching scheme was described in [15]. The methods presented in [15, 16] were evaluated using multispectral palmprints from the MS-PolyU database, a proposed method for palmprint recognition (PPR) based on BSIF and Histogram of oriented gradients (HOG) [17]. The palmprint recognition scheme presented in this study combines a novel spiral feature extraction with a sparse representation of binarized statistical image features (BSIF). BSIF are comparable to LBP, with exception to the method by which filters are learned [18]. In contrast to LBP, where filters are manually predefined, the texture descriptors of BSIF are learned from natural images; a binary string is created from a PPI by convolving with filters. In this study, a K-nearest-neighbour (KNN) classifier [19] was used to conduct subject verification on the fusion features acquired.
The main contributions of this paper are summarized as follows:
-
A new PPR method is proposed based on feature selection from a fusion of BSIF and spiral features.
-
Extensive experiments are carried out on palm-print databases (PPDBs): the PolyU contact PPDB with 356 subjects [20].
-
Comprehensive analysis is performed by comparing the proposed scheme with nine different state-of-the-art contemporary schemes based on BSIF-SRC [23], LBP [14], palmcode [8], fusion code [9], the Gabor transform with KDA [7], A double-orientation code [15, 16], BSIF and HOG [17] and the Gabor transform with sparse representation [23].
The rest of this paper is structured as follows. Section 2 discusses the proposed scheme for robust PPR. Section 3 discusses the experimental setup, protocols, and results. Section 4 draws conclusions.
2 Spiral Local Image Features
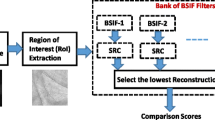
The proposed method pipeline for PPR based on BSIF and spiral features is depicted in Fig. 1.

Proposed method pipeline
Effective PPR demands accurate ROI extraction, the identification of a region of the palm print that is rich in features, such as principal lines, ridges and wrinkle, which is then extracted. Using the algorithm devised by Zhang et al. [22], which computes the centre of mass and valley regions to align the palm print.
2.1 Moment Statistics
Statistical moments were used to extract the spiral image feature. Starting at the central block, the image was divided into N blocks (Each block has same size such as BSIF Filter) and based on the algorithm illustrated in Fig. 3 the route was followed as depicted in Fig. 2. The spiral feature vector of a block \( k \) is: \( s_{k} = \left[ {w_{k} \times \left( {\text{var} (x_{k} ,y_{k} ),Moy(x_{k} ,y_{k} ),skew(x_{k} ,y_{k} ),kurt(x_{k} ,y_{k} )} \right)} \right] \)

Spiral feature extraction scheme
where \( w_{k} \) represents the weight of the block \( k \) in the image according to spiral ordering. The final spiral feature vector is:
where N is the number of blocks in the image
2.2 Binarized Statistical Image Features
BSIF was first put forward by Kannala and Rahtu [18]. The method represents a binary code string for the pixels of a given image; the code value of a pixel is considered as a local descriptor of the image surrounding the pixel. Given an image \( {\text{I}}_{\text{p}} \) and a linear filter \( {\text{W}}_{\text{i}} \) of the same size, the filter response \( {\text{R}}_{\text{i}} \) is found by
where m and n denote the size of the PPI patch, \( W_{i} \) denotes the number of linear filters \( \forall i = \left\{ {1,2, \ldots \ldots .,n} \right\} \) whose response can be calculated and binarized to obtain the binary string as follows [24]:
The BSIF codes are presented as a histogram of pixel binary codes, which can effectively distinguish the texture features of the PPI. The filter size and the length of bit strings are important to evaluate effectively the BSIF descriptor for palm-print verification.
In this study, eight different filter sizes (3 × 3, 5 × 5, 7 × 7, 9 × 9, 11 × 11, 13 × 13, 15 × 15 and 17 × 17) with four different bit lengths (6, 7, 9 and 11) were assessed (see Fig. 3). The 17 × 17 filter with an 11-bit length was selected based upon the superior experimental accuracy achieved with this combination.

Samples from PolyU database and corresponding BSIF codes
2.3 Global Features
Compared to score-level fusion, feature-level fusion has a faster response time. The drawback of the system that has limited its widespread uptake is that it struggles to fuse incompatible feature vectors derived from multiple modalities. Creating a linked series of extracted features is the simplest type of feature-level fusion, but concatenating two feature vectors may result in a large feature vector, leading to the ‘curse of dimensionality’ problem. To offset the poor learning performance of the high-dimensional fused feature vector data, PCA is used.
Therefore, the range of all features should be normalized so that each feature contributes approximately proportionately to the final distance. In this study, the Min–Max normalisation scheme was used to normalise the feature vectors in the range [0.1]. By concatenating the normalised feature vectors of BSIF and spiral features into a single fused vector, the definitive fused vector is achieved. Let the normalized feature vectors of an image I be \( E = \left[ {e_{1} \ldots e_{k} \ldots e_{N} } \right] \) and \( S = \left[ {s_{1} \ldots s_{k} \ldots s_{N} } \right] \) respectively for BSIF and spiral extraction. Then, the fused vector is represented as:
To find the optimal projection bases, PCA draws upon statistical distribution of the set of the given features to generate new features [23]. This method aims to locate the projection of the feature vector on a set of basis vectors, in order to create the new feature vector.
2.4 Extreme Learning Machine
Single-hidden layer feedforward neural networks have often been learnt by utilizing ELM [17]. The iterative tuning of obscured nodes is not necessary after random initialization using ELM has been performed. Thus, learning must occur only for the input weight parameters. If \( (x_{j} ,y_{j} ),j = \left[ {1, \ldots ,q} \right] \) indicates A as the training sample with \( x_{j} \in R^{M} \) and \( y_{j} \in R^{M} \), then the following equation can be used for the ELM’s output function with L obscured neurons:
The \( m\text{ > }1 \) output nodes associated with the \( L \) hidden nodes by the output weight vector \( G = \left[ {g_{1} , \ldots ,g_{L} } \right] \). With the nonlinear activation function represented by \( \Omega (x) = \left[ {w_{1} (x), \ldots ,w_{L} (x)} \right] \).
3 Experimental Results
3.1 Palmprint Databases
To test the validity of the scheme, exhaustive experiments were conducted using data available famous PPDBs: The PolyU database contains 7,752 palmprint images collected from 386 palms of 193 individuals. Of them, 131 individuals are males and the rest are females. The palmprint images were collected in two sessions with the average interval over two months. In each session, about 10 palmprint images were captured from each palm. So there are 386 classes of palm in the PolyU database, each of which contains about 20 palmprint images. The images in the PolyU database were cropped to a size of 128 × 128 pixels [20, 21].
3.2 Palmprint Identification
For this study, the BSIF histogram and spiral feature vectors were combined to form the last feature vector. To detect the best results, BSIF filters with different sizes and bits were chosen. The accuracy is shown in Fig. 4. The probe samples are sorted so that they are associated with the class to which they are most similar. For this study, based on our previous work [17] and to validate our identification algorithms we have calculated the Recognition Rate. For PolyU (352 * 10 * 2 images) we have taken 10 images of one user for training and remaining 10 for testing.

Average accuracy for PolyU palm-print databases
The 17 × 17 filter with an 11-bit length was selected based on the superior experimental accuracy achieved with this combination. The rate of errors in the identification process is used to estimate the performance of palmprint identification. The performance of the fused SPIRAL and BSIF features are applied to different databases is presented in Table 1. It shows that, compared to other feature extraction methods [7,8,9, 14,15,16,17, 23, 25], the experimental method provides a superior performance, with an EER from 0 to 2.06. The performance of the method applied on the PolyU PPDB is presented in Table 1. It shows that compared to other feature extraction methods the experimental method has a superior performance, with an EER of 2.06%. This is almost half the error rate of scheme [23], which of all the single BSIF features schemes included, has the next lowest ERR. This reinforces the applicability of the proposed scheme for PPR.
4 Conclusion
The accuracy and reliability of PPR is dependent upon the precision of the features represented. In this paper, a novel PPR approach is presented that uses extracted spiral features that are fused with BSIF. The experimental method was validated by conducting extensive tests on PolyU database. The performance results were compared to the performance results of six well-established state-of-the-art schemes. The results demonstrate that the experimental scheme was comparable or superior to the other methods, justifying it as being an efficient and robust tool for accurate PPR. In the future, we need to do more research on fusing two biometric modalities, which are the palmprint and iris to extract more discriminative information for bimodal identification system.
References
Connie, T., Teoh, A., Goh, M., Ngo, D.: Palmprint recognition with PCA and ICA. In: Proceedings of Image and Vision Computing, Palmerston North, New Zealand, pp. 232–277 (2003)
Dai, J., Zhou, J.: Multifeature-based high-resolution palmprint recognition. IEEE Trans. Pattern Anal. Mach. Intell. 33(5), 945–957 (2011)
Ekinci, M., Aykut, M.: Gabor-based kernel PCA for palmprint recognition. Electron. Lett. 43(20), 1077–1079 (2007)
Han, C., Cheng, H., Lin, C., Fan, K.: Personal authentication using palmprint features. Pattern Recogn. 37(10), 371–381 (2003)
Zhang, D., Guo, Z., Guangming, L., Zhang, L., Zuo, W.: An online system of multi-spectral palmprint verification. IEEE Trans. Instrum. Measur. 59(2), 480–490 (2010)
Wang, X., Gong, H., Zhang, H., Li, B., Zhuang, Z.: Palmprint identification using boosting local binary pattern. In: 18th International Conference on Pattern Recognition, 2006. ICPR 2006, vol. 3, pp. 503–506. IEEE (2006)
Raghavendra, R., Dorizzi, B., Rao, A., Kumar, G.H.: Designing efficient fusion schemes for multimodal biometric system using face and palmprint. Pattern Recogn. 44(5), 1076–1088 (2011)
Kumar, A., Shekhar, S.: Personal identification using multibiometrics rank-level fusion. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 41(5), 743–752 (2011)
Kong, A., Zhang, D., Kamel, M.: Palmprint identification using feature-level fusion. Pattern Recogn. 39(3), 478–487 (2006)
Wei, J., Jia, W., Wang, H., Zhu, D.-F.: Improved competitive code for palmprint recognition using simplified Gabor filter. In: Huang, D.-S., Jo, K.-H., Lee, H.-H., Kang, H.-J., Bevilacqua, V. (eds.) ICIC 2009. LNCS, vol. 5754, pp. 371–377. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-04070-2_42
Khan, Z., Mian, A., Hu, Y.: Contour code: robust and efficient multispectral palmprint encoding for human recognition. In: IEEE International Conference on Computer Vision, pp. 1935–1942 (2011)
Wu, X., Zhang, D., Wang, K.: Fisherpalms based palmprint recognition. Pattern Recogn. Lett. 24(15), 2829–2838 (2003)
Ekinci, M., Aykut, M.: Gabor-based kernel pca for palmprint recognition. Electron. Lett. 43(20), 1077–1079 (2007)
Raghavendra, R., Rao, A., Hemantha, G.: A novel three stage process for palmprint verification. In: International Conference on Advances in Computing, Control, Telecommunication Technologies, pp. 88–92 (2009)
Fei, L., Xu, Y., Zhang, D.: Half-orientation extraction of palmprint features. Pattern Recogn. Lett. 69, 35–41 (2016)
Fei, L., Xu, Y., Tang, W., Zhang, D.: Double-orientation code and nonlinear matching scheme for palmprint recognition. Pattern Recogn. 49, 89–101 (2016)
Attallah, B., et al.: Histogram of gradient and binarized statistical image features of wavelet subband-based palmprint features extraction. J. Electron. Imaging 26(6), 063006 (2017)
Kannala, J., Rahtu, E.: BSIF: binarized statistical image features. In: 2012 Pattern Recognition (ICPR), pp. 1363–1366. IEEE (2012)
Zhu, Z., Nandi, A.K.: Automatic Modulation Classification: Principles, Algorithms and Applications. John Wiley & Sons (2014)
Zhang, D., Kong, W.K., You, J., Wong, M.: Online palmprint identification. Pattern Anal. Mach. Intell. IEEE Trans. 25(9), 1041–1050 (2003)
Kumar, A.: Incorporating cohort information for reliable palmprint authentication. In: 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing. ICVGIP 2008. IEEE (2008)
Zhang, D., Guo, Z., Lu, G., Zhang, Y.L.L., Zuo, W.: Online joint palmprint and palmvein verification. Expert Syst. Appl. 38(3), 2621–2631 (2011)
Raghavendra, R., Busch, C.: Novel image fusion scheme based on dependency measure for robust multispectral palmprint recognition. Pattern Recogn. 47(6), 2205–2221 (2014)
Boukhari, A., Serir, A.: Weber binarized statistical image features (WBSIF) based video copy detection. J. Vis. Commun. Image Represent. 34, 50–64 (2015)
Yuan, L., chun Mu, Z.: Ear recognition based on local information fusion. Pattern Recogn. Lett. 33(2), 182–190 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Attallah, B., Chahir, Y., Serir, A. (2018). Geometrical Local Image Descriptors for Palmprint Recognition. In: Mansouri, A., El Moataz, A., Nouboud, F., Mammass, D. (eds) Image and Signal Processing. ICISP 2018. Lecture Notes in Computer Science(), vol 10884. Springer, Cham. https://doi.org/10.1007/978-3-319-94211-7_45
Download citation
DOI: https://doi.org/10.1007/978-3-319-94211-7_45
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-94210-0
Online ISBN: 978-3-319-94211-7
eBook Packages: Computer ScienceComputer Science (R0)
