
Abstract
In recent years, the number of video film has been in the constant expansion dramatically due to the rapid development of digital devices and network/communication technologies. The increasing diversity and complexity of video contents make a challenge toward file management and fast retrieval. This study considered military movies as research targets and used ELAN (a video annotation tool) to increase the descriptive data of the movie, which provides more detail metadata for improving video retrieval. The objective of this study is to develop a military movie knowledge retrieval service based on the Linked Open Data, which not only provides basic metadata and annotated words that include the timeline characteristic, but also links specified concepts with the related and extensive knowledge. Results represent that the service system is helpful for enhancing the effectiveness of military movie retrieval.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The concept of Web 2.0 proposed by O’Reilly and Battelle [10] describes the interactive share and collaborative involvement among users in the cyber world. The Internet and digital product complement each other nowadays. Widespread digital camera and smart phone bring people the convenience, hence instant share of photo and video has become entertainment in our life. In turn, the easy access to the Internet shortens users’ distance, further facilitating the trend of multimedia-content uploading and sharing. After video work is digitalized in computer information system; however, people still cannot search or even know its digital information without textual descriptions. The number of video film nowadays has been in the constant growth dramatically, which makes a challenge towards file management and fast retrieval [13]. Thus it is necessary to establish retrieval system for better file management, alone with the users’ efficiency in search and browsing mode. Although video web portal (e.g. YouTube, DailyMotion, Metacafe, and Vimeo) allows users manually annotate the title of video file and content description, video retrieval is still ineffective since annotation function could only present summary of whole video film. Therefore, the issues like “How to deal with semantic description in more precise manner” and “How to extend the application of metadata from video film” will be more obvious and difficult [1]. For most of current video film with general description, Yu et al. [13] suggested increasing detailed description on single frame or scene fragment through timeline-based annotation can be the solution.
Web of Documents in Web 2.0 era is built for people’s easy reading and browsing information while Linked Data aims to establish a structured-data network where a machine can understand and interpret its semantic content [3]. Linked Data has collected many data sets from diverse fields: General encyclopedia knowledge (e.g. DBpedia, YAGO), movie (e.g. LinkedMDB), academic publication (e.g. DBLP, RKB Explorer) and so on. After Linked Data is added with the concept “Open Data” and satisfy both standards, it called Linked Open Data (LOD). Through other data sets online, LOD is to strengthen the exchange and connection of knowledge among multimedia metadata, and eventually increase the value of data on the Internet [1]. The utilization of LOD on development system or application has been growing. Many relevant researches on video film have been published. The project “EuscreenFootnote 1” funded by the European Union, for instance, is to convert earlier analog TV data into RDF (Resource Description Framework) format and link to the other LOD data set, preserving and extending its knowledge implication of culture and history. Yu et al. [13] proposed using Linked Data technology to reinforce distance learning-supported education video files; Mirizzi et al. [9] focused on the link between the core data set of LOD (i.e. DBpedia) and semantic technology. Thus it can be seen that linking the existing video film resources to derivative knowledge via linked data technology is still in a sustainable developing way.
Taiwan’s video files for military-information delivery, by contrast, are only available for independent program or movie without further description on content. If a fast and effective video retrieval environment could be provided for certain military video contents, it will be significantly helpful for users to get not only preferred video file but also knowledge supplement.
Based on the property of LOD, this research reinforced the semantic model of military video resources. Then, it further conducted the meta-analysis of knowledge extension by structured (i.e. Metadata) and unstructured (i.e. Annotation data) information contents. The aims of this research are as follows:
-
Propose a video retrieval service architecture with the integration of metadata, annotation data and LOD. Meanwhile, it can further increase clues for film search by increasing detailed description on film. According to annotation-based knowledge extension mode, it also extends knowledge scope covered by video resource.
-
Present the diversity of military issues by retrieval service system with military movie examples, as well as the concept of mashup. Furthermore, verify the feasibility and utility of the proposed architecture.
2 The Development and Application of LOD
The internet content nowadays is mostly presented in HTML webpage. For computer, HTML format represents the expression syntax of web file, but computer cannot understand the meaning inside the format content. To make computer read semantic meaning behind the words, Berners-Lee et al. proposed Semantic Web in 2001. Computer could comprehend webpage content by interlinked data on the web, and then convert it to semantic documents and data. This enables the linking of knowledge network increases the efficiency and accuracy of web search.
Regarding the issue “How to embody the concept of full-function and meaningful semantic web”, Berners-Lee proposed “Linked Data” in 2006. It is the technology to publish, share and interlink the structured data on the web. As the best practice of semantic web, Linked Data enables machine find and link web data from each field [7]. In short, Linked Data publish structured data in RDF format on the web via HTTP URI method. This lowers the data providers and users’ thresholds to access data; meanwhile, it is expected to form a rich and available data space [6].
The World Wide Web Consortium (W3C) promoted the LOD program in 2007, so the existing data can be interlinked by Linked Data technology and released on the web for people’s utilization. LOD connects numerous data sets; it could be regarded as an Internet-scale data space which unites multiple fields [6]. To prevent its application-level development from copyright concerns, all Linked Data should announce authorization for use during their release on the web.
As the main core of Linked Data, DBpedia locates in the hub location of LOD. It is a special application example of semantic web: it extracts structured data from Wikipedia webpage by semantic technology; meanwhile, it also uses RDF property to link and integrate data sets from other fields. In consequence, DBpedia with a wide range of topics and contents has become the largest interdisciplinary Ontology in the world. Besides, DBpedia provides all potential concepts a chance to be a concrete URI, which links different data sets through the share and reference of URI form.
Once data sets are published in the LOD cloud and interlinked with others, all published data will be equipped with LOD property. When an organization owns abundant information document, they can be changed into specific LOD data sets by data conversion, or further connection with internal database system to provide solutions for organization and enterprise’s resource decision, disaster management, knowledge management or market intelligence & research report [2]. With the wide use in many ways, the development of LOD application has reached considerable achievements thus far.
Public sector publishes data on the LOD web, increasing its transparency in government; The Linked Data application has brought people convenient life information, and the links of music or movie optimize users’ reference integrity [4, 7]. Among few Linked Data researches in video films nowadays, the early-stage of them proposed solutions for different multimedia formats and annotation system [12]. Although scholars later conducted applied researches based on LOD technology such as education video resource and academic conference video (Table 1), researches on military movies are still in the blank so far.
3 Research Framework
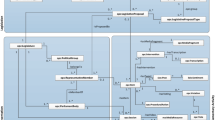
“The knowledge retrieval service of linked movie annotation data” developed by this study presented the basic metadata of military movies where the specific movie scenes are annotated by timeline. The extensible data of annotation word inside were thus linked to LOD data sets through Linked Data technology, further expanding its knowledge inside the content. The research framework is shown as Fig. 1.

The research framework
The Source of Movie Data.
Considering the efficiency of system operation, the research narrowed down the scope of video films, from all military films to movies with the World War II issues for study. Among military movie titles associated with the World War II in military-movie blogs worldwide and Wikipedia entries, the known films released in Taiwan were thus selected as candidate list (e.g. Saving Private Ryan and Pearl Harbor, etc.). Each experimental video mainly extracted video resources from the multimedia data from the library of National Defense University, other sources were Chinese Taipei Film Archive, National Digital Archives Program and other open sources on the web (e.g. YouTube).
The Capture of Metadata.
The related attributes of movies’ metadata were explained in words, including films’ credits (e.g. performer, filmmaker) and information (e.g. running time, publisher, and language). They are all the basic data of movie, without any changes. Through JavaScirpt program, InfoBox data captured from Wikipedia movie webpage were directly presented in retrieval service area, which not only provides movies with the existing attribute data but also conceptual basis for extended data.
The Frame Annotation of Movie.
For people who do not have expertise on military background or historical battle, they might not understand meaning behind the scenes such as the certain historical people, military facilities or equipment shown in the movies. Therefore, the frame annotation formed by timeline could strengthen users’ understandings besides the existing metadata. It also can benefit annotators’ frame and scene annotation based on timeline. Moreover, annotation words were stratified and categorized themselves by classes. To link each data set from LOD’s fields, the research conducted annotation description on film fragment or people, place and military aircraft. Afterwards, exported annotated data as XML file, and transferred to local MySQL database.
The Extraction of Linked Data.
After movie frames were annotated and saved, the research then utilized the built-in RDF library of ARC2 and SPARQL to do syntax-module query. When keywords were sent, the data mapped to corresponding attributes and attribute values by triples from the RDF file of LOD data sets like DBpedia, GeoNames and LinkedMDB. The data structure of triples mapped to corresponding RDF pattern inside the specific LOD data sets, and then SPARQL endpoint retransmitted the extracted triples as JSON files to local server. After JSON files were received as array form, they were read by loop of PHP’s for each function. Then, their corresponding attributes and attribute values were saved. Eventually, three variable data (people, places and military aircrafts) were shown in PHP syntax on the webpage.
The SPARQL syntax and target data of the three-type annotation word are further explained below.
-
Person annotation
Because retrieval results of keyword query conducted by people’s nicknames usually show poor efficiency, the research utilized UNION syntax to link two RDF predicates “rdfs:labelFootnote 2” and “dbpo:wikiPageRedirectsFootnote 3”. In this way, SPARQL query firstly checked whether the linked URI of “rdfs:label” match, then compared “dbpo:wikiPageRedirects”. To eliminate ambiguity problems caused by people’s nicknames and aliases, it followed the attribute value of “wikiPageRedirects” to provide two RDF patterns with replaceable URI names inside the DBpedia.
-
Place annotation
In general, most place annotations for movie scenes normally focus on the names of geographical locations, administrative regions and famous buildings. However, these annotation words cannot deliver further data description. In this study, we linked to the RDF data of DBpedia and GeoNames’s endpoints by SPARQL syntax and extracted the extended data of place names which include the longitude, latitude, profile of site, names and pictures of local cities. Through Google visualization tools, these data were presented as tables and map markers, which helped users’ easy understandings and comparisons. Besides, the additional use of Sgvizler (i.e. a RDF query tool developed by JavaScript) can be further combined with Google Chat Tools, in order to visualize the collected data; that is, it is much easier for users to understand the geographical locations occurred in the movie, through the map method.
-
Military aircraft annotation
With the diverse categories, military aircrafts also differ in their performances and specifications. As a result, the extended information of military aircraft annotation took the “Template: Aircraft Specifications” from Wikipedia InfoBox as the basis of data extraction. It extracted the required attribute value, then selected the more common aircraft (e.g. Crew, Wingspan, Max. takeoff weight), performance data (e.g. Cruise speed, Rate of climb, Service ceiling) and weapon (e.g. Bombs). During the information query, every aircraft showed different attribute data because the RDF linked description data of DBpedia entity URI still shows no unified attribute specification nowadays.
Retrieval Query Interface.
The research designed web retrieval interface by combing PHP, JavaScript and CSS (Cascading Style Sheets) syntax. The interface was divided into query function area and data presentation area. The former provided the retrieval service of military movies; the latter displayed the query results like basic data of movies and annotation word.
4 Implementation and Evaluation
This retrieval service is a Mashup web application, which combines LOD technology, HTML5 video tag, JavaScript webpage capture, Sgvizler and Google tools. As shown in Fig. 2, the process starts from query category. There are three types: movie title, the name of actor and director as well as extensible query of annotation word. During selection of movie title, users can obtain the basic data of movie and annotation word list. Regarding the query on the name of actor or director, results show their information from LinkedMDB, following with the titles of their past movies. As for the place annotation, people and military aircraft inside the type “Annotation word query”, it facilitates users’ selections and retrievals based on their own demands. The system first filters out keyword type from Freebase, then conducts the query in order to improve search accuracy. During the process, the metadata and the same annotation word list shown in other movies are transmitted in SPARQL syntax.

The function and process of retrieval service.
4.1 Functions of the Retrieval Service
The retrieval service system consists of three main functions.
-
1.
The retrieval of movie’s information
Through the retrieval by inputting movie title “Pearl Harbor”, the system was divided into two categories displaying related data (Fig. 3): one as “The retrieval section of movie’s basic information” provided the retrieval results of basic data, including movie’s content and its metadata. Another one as “The retrieval section of movie’s annotation data” shows movie’s annotation type, time and frame screenshot.
Fig. 3. 
The system interface of movie retrieval service.
-
The movie’s play: Embedded with HTML5 video tag, film’s play function provides dynamic fragment and frame review. Besides, the time-display button combining with annotation word enables users to directly browse the scene fragment of word shown in the film. This not only dramatically shortens retrieval time, but also strengthens users’ concepts towards annotation word.
-
The movie’s metadata: After selecting movie (e.g. movie “Pearl Harbor”) for query by capturing Wikipedia webpage by PHP and JavaScirpt, system automatically extracts InfoBox data as metadata, namely attribute data (e.g. director, actor, producer, screenwriter, etc.) as the same as the concept extension basis of movie knowledge.
-
-
2.
Extensible link service
By linking to LOD data sets (DBpedia, LinkedMDB and GeoNames) through SPARQL, extensible link service can obtain related attribute and attribute value extended from annotation word. Taking the person annotation for example, Colm Feore is an American-Canadian stage, film and television actor who plays as the role of Admiral Husband E. Kimmel in the movie “Pearl Harbor.” “Colm Feore” is a basic attribute value (actor) in the movie’s metadata and “Husband E. Kimmel” is an annotation word that can be linked to Wikipedia’s infobox and other films’ information (see Fig. 4).
Fig. 4. 
The link service of person annotation - the case of Husband E. Kimmel.
-
3.
The Linked Data query of actor and director
Actor and director are basic metadata in the movie which are acquirable in the retrieval of movie title. If users request more related information in the movie, they can conduct the query through this retrieval service. In addition, the research also treats LinkedMDB as one of the movie sources, which provides the query for the past movies list of actor and director (as shown in Fig. 5).
Fig. 5. 
The retrieval service of actor’s film list - the case of Tom Cruise.



4.2 System Evaluation
Based on the reference of software product quality requirement and evaluation criteria (ISO25010), the research conducted an evaluation for item “User’s satisfaction” involved by Quality in Use. The five-point Likert scale was applied into online questionnaire in the research. As a result, the importance of each indicator was firstly divided into five responses: “Strongly disagree”, “Disagree”, “General”, “Agree” and “strongly agree”. Then, the five responses were converted into 1 (lower importance) to 5 (higher importance) points for the statistical analysis of questionnaire. The questionnaire was designed from two aspects: literature review and the reference of measurement variable proposed by foreign researchers. A total of 30 users were evaluated in system satisfaction by online questionnaire after they operated the system.
The statistics of evaluation showed that the average value among questions from five dimensions (system effectiveness, reliability, operating comfort, enjoyment, and overall satisfaction) is greater than 3 while standard deviation shows insignificant/tiny difference. This can indicate users are generally satisfied with the retrieval content and result of system.
5 Conclusion
The research focused on the application of abundant LOD resources, and studied the related data of military movies by Linked Data technology. With the establishment of a retrieval-service platform ultimately, it can provide users with the query of basic data and the extensible knowledge and concept of annotation word link. The main contributions of the research are summarized as follows:
-
Establish LOD-based retrieval service to get the data sets from different fields by SPARQL syntax. The direct acquirement of available open data indeed decreases redundant databases with overlapping contents, the consumption of storage resources and data maintenance costs. Furthermore, this retrieval service can integrate different videos or movie data, achieving advanced application.
-
Combine LOD with video annotation to provide the reference for knowledge learning and teaching assistance. This combination mode also provides a new orientation to add pilot concept for military information media application and innovative thinking for national defense system in the future internet era.
The video annotation software adopted by the research still focuses on text mode as the main annotation description. During the extensible query of annotation word, it first uses strings to get URI, and then links outwards to other data. To achieve the purpose of semantic annotation, the research thus suggests that the further development of semantic annotation tool can reinforce semantic description by URI, which reduces the ambiguity word and increase the URI-link scope of annotation word.
Besides, Linked Data along with the data are converted and published to the phases like data integration and inter-correlation. The research merely used application programs to acquire data link by adding annotation word through SPARQL syntax. For this reason, the user-built annotation word bank can be used to publish. Furthermore, SILK (Link Discovery Framework) can also help it conduct the RDF link of triples from different data sets. This eventually makes annotation data and each LOD data set interlinked, maximizing knowledge exploration ability of Linked Data.
References
Arias Gallego, M., Corcho, O., Fernández, J.D., Martínez-Prieto, M.A., Suárez-Figueroa, M.C.: Compressing semantic metadata for efficient multimedia retrieval. In: Bielza, C., Salmerón, A., Alonso-Betanzos, A., Hidalgo, J., Martínez, L., Troncoso, A., Corchado, E., Corchado, J.M. (eds.) CAEPIA 2013. LNCS, vol. 8109, pp. 12–21. Springer, Heidelberg (2013)
Bauer, F., Kaltenböck, M.: Linked Open Data: The Essentials. Edition mono/monochrom, Vienna (2011)
Berners-Lee, T.: Linked Data-Design Issues. https://www.w3.org/DesignIssues/LinkedData.html
Bizer, C., Heath, T., Berners-Lee, T.: Linked data - the story so far. Int. J. Semant. Web Inf. Syst. 5(3), 1–22 (2009)
Haslhofer, B., Jochum, W., King, R., Sadilek, C., Schellner, K.: The LEMO annotation framework: weaving multimedia annotations with the web. Int. J. Digit. Libr. 10(1), 15–32 (2009)
Hausenblas, M., Karnstedt, M.: Understanding linked open data as a web-scale database. In: 2010 Second International Conference on Advances in Databases Knowledge and Data Applications (DBKDA), Menuires, pp. 56–61 (2010)
Heath, T., Bizer, C.: Linked data: evolving the web into a global data space. Synth. Lect. Semant. Web Theor. Technol. 1(1), 1–136 (2011)
Li, Y., Wald, M., Omitola, T., Shadbolt, N., Wills, G.: Synote: Weaving media fragments and linked data. In: 5th International Workshop on Linked Data on the Web (LDOW 2012), Lyon, France (2012)
Mirizzi, R., DiNoia, T., Ragone, A., Ostuni, V., DiSciascio, E.: Movie recommendation with DBpedia. In: 3rd Italian Information Retrieval Workshop (IIR 2012), Bari, Italy (2012)
O’Reilly, T., Battelle, J.: Opening Welcome: State of the Internet Industry, San Francisco, California (2004)
Sack, H., Waitelonis, J.: Towards exploratory video search using linked data. Multimedia Tools Appl. 59(2), 645–672 (2012)
W3C Interest Group Note: Cool URIs for the Semantic Web. http://www.w3.org/TR/cooluris/
Yu, H., Pedrinaci, C., Dietze, S., Domingue, J.: Using Linked Data to Annotate and Search Educational Video Resources for Supporting Distance Learning. IEEE Trans. Learn. Technol. 5(2), 130–142 (2012)
Acknowledgements
This research was partially sponsored by the Ministry of Science and Technology, Taiwan (MOST 103-2410-H-606-005-MY2).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Chen, LC., Tseng, JT., Lien, YH., Hsieh, CJ., Shih, IC. (2016). Exploring a LOD-Based Application for Military Movie Retrieval. In: Nah, FH., Tan, CH. (eds) HCI in Business, Government, and Organizations: eCommerce and Innovation. HCIBGO 2016. Lecture Notes in Computer Science(), vol 9751. Springer, Cham. https://doi.org/10.1007/978-3-319-39396-4_27
Download citation
DOI: https://doi.org/10.1007/978-3-319-39396-4_27
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-39395-7
Online ISBN: 978-3-319-39396-4
eBook Packages: Computer ScienceComputer Science (R0)