
Abstract
Supervisor assessments are critical for both formative and summative assessment in the workplace. Supervisor ratings remain an important source of such assessment in many educational jurisdictions even though there is ambiguity about their validity and reliability. The aims of this evaluation is to explore the: (1) construct validity of ward-based supervisor competency assessments; (2) reliability of supervisors for observing any overarching domain constructs identified (factors); (3) stability of factors across subgroups of contexts, supervisors and trainees; and (4) position of the observations compared to the established literature. Evaluated assessments were all those used to judge intern (trainee) suitability to become an unconditionally registered medical practitioner in the Australian Capital Territory, Australia in 2007–2008. Initial construct identification is by traditional exploratory factor analysis (EFA) using Principal component analysis with Varimax rotation. Factor stability is explored by EFA of subgroups by different contexts such as hospital type, and different types of supervisors and trainees. The unit of analysis is each assessment, and includes all available assessments without aggregation of any scores to obtain the factors. Reliability of identified constructs is by variance components analysis of the summed trainee scores for each factor and the number of assessments needed to provide an acceptably reliable assessment using the construct, the reliability unit of analysis being the score for each factor for every assessment. For the 374 assessments from 74 trainees and 73 supervisors, the EFA resulted in 3 factors identified from the scree plot, accounting for only 68 % of the variance with factor 1 having features of a “general professional job performance” competency (eigenvalue 7.630; variance 54.5 %); factor 2 “clinical skills” (eigenvalue 1.036; variance 7.4 %); and factor 3 “professional and personal” competency (eigenvalue 0.867; variance 6.2 %). The percent trainee score variance for the summed competency item scores for factors 1, 2 and 3 were 40.4, 27.4 and 22.9 % respectively. The number of assessments needed to give a reliability coefficient of 0.80 was 6, 11 and 13 respectively. The factor structure remained stable for subgroups of female trainees, Australian graduate trainees, the central hospital, surgeons, staff specialist, visiting medical officers and the separation into single years. Physicians as supervisors, male trainees, and male supervisors all had a different grouping of items within 3 factors which all had competency items that collapsed into the predefined “face value” constructs of competence. These observations add new insights compared to the established literature. For the setting, most supervisors appear to be assessing a dominant construct domain which is similar to a general professional job performance competency. This global construct consists of individual competency items that supervisors spontaneously align and has acceptable assessment reliability. However, factor structure instability between different populations of supervisors and trainees means that subpopulations of trainees may be assessed differently and that some subpopulations of supervisors are assessing the same trainees with different constructs than other supervisors. The lack of competency criterion standardisation of supervisors’ assessments brings into question the validity of this assessment method as currently used.
Similar content being viewed by others


Background
Assessment and evaluative feedback during supervised training and clinical work plays a crucial role in the achievement of professional and medical competence for medical trainees (Wass et al. 2001; Norcini and Burch 2007). Consistency and quality of that evaluative feedback in the workplace is essential for learning as well as standard setting (Sadler 1989). Clinical supervisors play an integral role in workplace-based formative and summative assessments. For such assessments, the measurement “method” is the supervisors’ interpretation of the competency construct and their ability to recognise it in the trainee being assessed (Govaerts et al. 2007).
However, evidence abounds of variation in the quality of workplace-based competency assessments (Levine and McGuire 1971; Crossley et al. 2011; Cook et al. 2010; Lurie et al. 2009; Regehr et al. 2011). One reason for variation in quality of assessments, among many, relates to problems with the assessor’s ability to consistently identify and evaluate competency constructs being assessed (Kastner et al. 1984; Hawkins et al. 1999; McGill et al. 2011; Crossley et al. 2011). Commonly it is assumed that one rater is as competent to judge the competency of an individual as another and that an individual rater can be treated as a constant factor (Remmers et al. 1927). However, a rater in different contexts provides a specific assessment which will include their own understanding of the competency construct being assessed without any measure of how different raters’ interpret the constructs. Although this issue has been known for decades (Remmers et al. 1927), whether raters are using the same interpretation for competency based assessments in medical education is still uncertain. For example it is unclear whether the rater’s judgement can be treated as a constant factor, whether the rater is as competent as another to make the assessment, or if the rater is competent at all to make the assessment (van der Vleuten 1996; Ginsburg et al. 2010; Hutchinson et al. 2002; Hamdy et al. 2006; Kogan et al. 2009; Miller and Archer 2010; Lurie et al. 2009; Regehr et al. 2011). Moreover, differences in the understanding and categorisation of competency constructs could affect their reliable interpretation (Gingerich et al. 2011). Supervisors may even be assessing something in a valid way which is not identified by the stated constructs (Govaerts et al. 2007). The identification of possible variation in the competency construct interpretation between raters has not been a routine undertaking for the widely used supervisor end-of-term assessments.
Identifying sources of variation in rater-based competency assessments, as previously identified (van der Vleuten 1996), still needs more clarification (Gingerich et al. 2011). Furthermore, to reliably interpret rater-based assessments, the attributes that are meant to be identified should be validly linked to the measurement (Forsythe et al. 1986). In addition, global-constructs as well as individual competency items need evidence of being reliably identified, since the competency items on which global constructs are based show measurable variation for rater-based assessments (McGill et al. 2011; Crossley et al. 2011). Even differences in the description of individual competency items can affect the reliability of assessment (Crossley et al. 2011). Although studies of the reliability of individual competency items for rater-based assessments abounds, the routine evaluation of how reliably any global-construct can be assessed has not been a routine undertaking in the validation processes of rater-based assessments.
The literature about supervisor-based competency assessments has consistently highlighted major problems with competency construct validity, problems that also exist for other rater-based assessments (Levine and McGuire 1971; Williams et al. 2003; Lurie et al. 2009; Regehr et al. 2011). Exploratory factor analysis (EFA) has commonly been used as part of the evaluation of the validity for global ratings of trainee competences, including construct validity. Despite diversity in methods, processes and the type of competency constructs being assessed, small numbers of factors have been consistently obtained. Competency items may or may not align with a small number of a priori determined global-constructs that represent major global competency domains used for deciding the clinical and professional competency of medical practitioners. Factor numbers have varied in past studies according to different times and contexts, and so may not be stable identifiers of competency (Forsythe et al. 1986; Silber et al. 2004; McLaughlin et al. 2009). The ordered evaluation of potential confounding influences on rater-based assessments has not been consistently performed.
In summary, the investigation of expected and/or latent competency constructs, the evaluation of confounding influences on supervisor construct interpretation, and the evaluation of the reliability of global constructs have not been routinely undertaken for supervisors’ assessments in the workplace. The aims of this study were to explore these issues using exploratory factor analysis (EFA) of end-of-term supervisor ratings within a specific population and context for medical trainees. The first aim was to determine if individual competency items align with “face value” domain constructs defined a priori, or if alternate or additional latent factors exist. Secondly to evaluate the stability of the factor structure for the assessment process and determine if the overall factor structure observed is affected by different contexts such as hospital type, and different types of supervisors and trainees. Thirdly introduce the concept of using reliability measures as a routine for the application of global-competency constructs for assessment.
Methods
Sampling context and participants
Context and population
The assessments used in this study were end-of-term and summative. They provided information about the competency of an intern (trainee) and were the assessments used by the Australian Capital Territory (ACT) Medical Board to grant full registration for the trainee to practice as a fully registered medical practitioner in Australia. The sample included all de-identified assessments of trainees for the years 2007 and 2008 at The Canberra Hospital (TCH). TCH is a tertiary referral level teaching hospital in the ACT with 3 associated peripheral hospitals to which trainees were seconded for one term. There are 5 rotation terms and the trainee had a supervisor for each rotation. Therefore the trainee was assessed by 5 different supervisors. If a trainee fails a term assessment, that term is repeated with additional attention to remediation. The medical registration would be delayed until a satisfactory assessment was provided.
The supervisor often used information about the trainee’s competence and performance from other sources. These include other senior medical staff in the unit and often registrars. Often opinions were also sought from senior nursing staff with whom the trainee works on a daily basis, and sometimes from other professional staff. All supervisors at the time were experienced at being term supervisors, and had been recruited as volunteers after being nominated by their department. No formal training in supervision or assessment was provided.
As previously described (McGill et al. 2011), there were a total of 374 assessments (trainee and supervisor interaction for an end-of-term assessment) involving 74 trainees and 73 supervisors. From the 74 trainees, 64 had 5 assessments, 12 handed in 4 and 2 had 3 assessments available. From all assessments nearly one third of supervisors (23 of 73) performed only 1 assessment (6.1 % of all assessments), with 93.9 % of assessments being performed by 2 or more supervisors. Seven performed 10 or more assessments. There were no exclusion criteria and every assessment performed was included for all trainees, all supervisors and for all competency items assessed, as previously described (McGill et al. 2011).
Trainee performance rating process
The exact 2007–2008 version of the form and the method of application as recommended by the then Institute of Medical Education and Training (IMET) personnel were used for all assessments (McGill et al. 2011). The coded de-identified data from all forms were collated in an SPSS database (Version 19) on a high-level-password protected laptop computer. The analysis was with anonymous data and precluded the identification of any individual. This evaluation was undertaken as part of a quality improvement process for the current assessment methods for junior trainees within the hospital. As such, Institutional Ethics Committee Approval was not sought.
The trainee assessment form used by supervisors describes a number of competence items representing different types of constructs of clinical and professional performance to be judged by the assessor. The form used for 2007–2008 was partitioned into 4 domain constructs: (1) Clinical; (2) Communication; (3) Personal and Professional; and (4) Overall competency. Each competency item was presumed to be measuring several different dimensions of an overarching clinical competence needed by medical practitioners for independent practice. The rating form used in this study included 14 competence items with a 5 point scale format, 4 of which described levels of competency (requires substantial assistance, requires further development, consistent with level of experience, performance better than expected); and one which allowed a statement of “not applicable/not-observed” (McGill et al. 2011). No previous validation of the form and process has been available or published.
The overall clinical construct was composed of explicitly stated competency items, namely: (1) knowledge base assessing “adequate knowledge of basic and clinical sciences and application of this knowledge”; (2) clinical skills assessing the demonstration of “appropriate clinical skills including history taking and physical examination”; (3) clinical judgement/decision making skills assessing demonstrating “the ability to organize, synthesise and act on information”; (4) emergency skills assessing “ability to act effectively when urgent medical problems arise, including acknowledgement of own limitations and need to seek help when appropriate”; and (5) procedural skills assessing “the ability to perform simple procedures competently”.
The overall communication construct consists of two explicitly stated competency items: (1) communication assessing the “ability to communicate effectively and sensitively with patients and their families; and (2) teamwork skills assessing the “ability to work effectively in a multidiscipline team”.
The overall personal and professional constructs consist of six defined competencies consisting of: (1) professional responsibility assessing “professional responsibility” demonstrated through “punctuality, reliability and honesty”; (2) awareness of limitations assessed by acknowledging “own limitations and seeking help when required”; (3) professional obligations to patients assessed by “showing respect for patient autonomy and quality information sharing”; (4) teaching/learning by demonstrating that “participates in teaching and/or education activities”; (5) time management skills assessing ability to “organize and prioritize tasks to be undertaken”; and (6) medical records assessing the ability to “maintain clear, comprehensive and accurate records.
The final separate competency item was “overall” assessment of performance during the term, with the specific descriptor: “Overall performance during the term. This should be consistent with ratings above” (See Appendix 1 for the original summative assessment form).
Factor and component analysis
Principal component analysis (PCA) with variance maximizing (Varimax) rotation was used for data reduction to test whether the competency items reduced into domains consistent with their stated group competency meanings. Principle Axis Factoring (PAF) was used for the EFA to determine if there were any potential latent factors. The unit of analysis was each assessment, and thus includes all trainee and all supervisor assessments without aggregation of any scores.
Varimax orthogonal rotation was chosen a priori to obtain a linear combination of factors to maximise the variance of the factor loadings but also minimise any correlation between consecutive factors. Orthogonal rotation was also used to maximise the potential for reproducible methods (Henson and Roberts 2006). Only those samples with data evaluation results indicating that the sampling was adequate were to be used to ensure that appropriate factor analysis was undertaken (Norman and Streiner 2008; Pett et al. 2003).
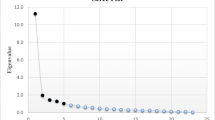
To standardize accepted descriptions, components will subsequently be referred to also as Factors (Norman and Streiner 2008; Tabachnick and Fidell 2007). The criteria for Factor extraction follow traditional recommendations (Norman and Streiner 2008; Pett et al. 2003). Components with Eigenvalues greater than 1 were initially retained (Kaiser 1960) and Parallel Analysis (Ruscio and Roche 2012) were used to assess the component and Factor solution. These provided a 2 and 1 Factor solution respectively. However, an examination of the Scree plot (Norman and Streiner 2008) indicated a possible 3 component model with an Eigenvalue >0.6. Factor loading values >0.55 were accepted for inclusion into the component model. Loadings of 0.6 and above were considered “high” and those below 0.4 were considered “low” (Tabachnick and Fidell 2007).
Exploring the reliability of factors as competency domain constructs
Latent Factors may or may not be equivalent to a priori determined global domain constructs. They may also be more reliable than scores for the individual observed competence items comprising the latent Factors or the global domain constructs (Tabachnick and Fidell 2007). To assess the reliability of the Factor, the competence item score for each individual assessment were added for each identified Factor. The columns of the data matrix comprised the total scores for the grouped competence items representing each Factor. The rows of the matrix of summed scores of each Factor were the trainees’ assessment by a specific supervisor. Because each trainee assessment is the unit of analysis, the rater was nested within the trainee. Using variance components analysis, the percent variance attributable to the trainee for each summed Factor score was identified, with all other variance considered error (McGill et al. 2011). Variance components were estimated by the minimum norm quadratic unbiased estimator (MINQUE) which was chosen because it requires no distributional assumptions and is recommended for unbalanced study designs (Baltagi et al. 2002). For the data-matrix there were only two measureable sources of variance: trainee assessment score variance and what would be considered error variance. The error variance included rater effect, trainee-rater interaction, general error variance, and trainee-rater-general error interaction variance. The percent variance due to the trainee and the number of observations needed to achieve a reliability coefficient of 0.80 can be calculated using the standard reliability formula from Classic Test Theory (Streiner and Norman 2009). The unit of analysis for the variance components were the trainee scores for each competency by different supervisors. Homogeneity of the competence items comprising a Factor was measured using Cronbach’s alpha.
Evaluation of the stability of component (Factor) structures for supervisor assessment
Sensitivity analysis
A comparison between PAF and the PCA was performed as a sensitivity analysis. This is theoretically appropriate for latent variable investigation (Fabrigar et al. 1999). Comparing the PAF and PCA results as a sensitivity analysis arose from the debate about practical differences between component and Factor analysis (Velicer and Jackson 1990; Fabrigar et al. 1999). Solution similarity between the two methods is stronger for well-designed data sets, and solutions become dissimilar under poor conditions for analysis (Velicer and Jackson 1990). A comparison of the solutions between Factor and component analysis was used also to evaluate the stability of the solutions.
Factor stability
To assess Factor stability, those variables having differences in scores as assessed by univariate analysis were evaluated individually regarding their influence on the Factor structure. The variables that had differences in scores of some competency items were intern and supervisor gender, clinical type of supervisor, place of training (Australia or overseas), and central or peripheral hospital. Because of multiple variable testing the significance level was set a priori at a p value < 0.01). The subgroups further analysed by PCA analysis needed the characteristics indicating adequate sampling as described above.
Results
Every trainee was assessed and every available assessment was included in the data analysis. Approximately 2.3 % evaluations of individual competency items were not scored. The demographics of the population and reliability of the assessment process has been previously reported (McGill et al. 2011). The basic score data are provided in Table 1.
Component analysis
Analysis of the data for appropriateness for factor analysis
An evaluation of competence item correlation and sampling adequacy indicated that the data were appropriate for Factor analysis. In summary, all competence item correlations r-values are >0.30 and < 0.70 with p values < 0.001; Cronbach’s alpha = 0.935, and therefore the error variance = (1-α2) = 12.6 %; Kaiser–Meyer–Olkin Measure of Sampling Adequacy = 0.923; Bartlett’s Test of Sphericity p value < 0.000; and measures of sampling adequacy from the anti-image correlation matrix except awareness of limitations were >0.900, with mostly low anti-image covariances indicating that the variables are relatively free of unexplained correlations (evidence for sampling adequacy is provided in Appendix 2).
Criteria for extracting the factors
Extraction communalities (estimates of the variance in each variable accounted for by the Factors) for each competence item are reasonably high indicating common variance due to the Factors. All extraction communalities were above 0.60 and below 0.85 again suggesting that the small sample size is adequate.
Separated competency items into different factor clustering
The data analysed with a PCA with Varimax rotation demonstrated good indicators of factorability, and the residuals indicate the solution was adequate. The first component (Factor 1) includes clinical judgement, communication, teamwork skills, professional responsibility, time management skills and overall rating (highlighted in bold type in Table 2). Factor 1 contains competency items that range across all pre-defined overall competency domains. The second component (Factor 2), defined as an overall “Clinical” domain, includes all 5 competency items under this pre-defined overall construct (highlighted in bold type in Table 2). The third component (Factor 3) includes many but not all of the “Personal and professional” overall competency construct (highlighted in bold type in Table 2). Because this evaluation was not the original validity assessment, cross-loading competence items were not eliminated. This left “Clinical Judgement” potentially in 2 Factors. For the reliability assessment of the Factors, “Clinical Judgement” was included in Factor 1 which accounted for most of the variance, and was not included in Factor 2 competence item score summation.
The majority of the explained variance is associated with Factor 1 which explains 54.4 % of the variance. Only the first Factor clusters with the Overall Rating measure (Table 2). The difference in the magnitude of the Eigenvalues indicates the relative importance of each Factor in the underlying structure of this rating form.
Interpretation of component definitions
Factor 1 includes competency items with the descriptions of an ability to organize, synthesise and act on information (clinical judgement/decision making skills assessing); the ability to communicate effectively and sensitively with patients and their families (communication); the ability to work effectively in a multidiscipline team (teamwork skills); the demonstration of professional responsibility through punctuality, reliability and honesty (professional responsibility); and the ability to organize and prioritize tasks to be undertaken (time management skills). All of these competencies dimensions could be described by an overall competency construct of “general professional job performance”, that is, being efficient and effective for the day-to-day work of a complex professional clinical workplace environment.
An overall assessment of performance during the term was required to be consistent with the assessments performed for all the previously assessed competency items. This was most associated with Factor 1 with a borderline association with Factor 2 (Table 2).
Factor 2 included all the competency items for the predefined construct of “clinical competence” and hence it would be appropriate to continue to be so defined. Factor 3 has many of the predefined “professional and personal competency” items collapsing into one Factor. Also this predefined construct could continue to be defined as such.
Exploring the reliability of combined factor scores
The homogeneity measures using Cronbach’s alpha were 0.895, 0.861 and 0.832 for Factor’s 1, 2 and 3 respectively. When scores of Factors are obtained for each individual they are more reliable than scores on the individual observed variables (Tabachnick and Fidell 2007), and this was demonstrated with the current study (Table 3). Factor 1 (general professional job performance) and the original construct of communication skills (communication) achieve an acceptable reliability level in comparison to the other Factors. Factor 1 provides over 40 % of the variance attributable to the trainee and only 6 assessments are needed to provide adequate reliability (Table 3). The reliability measures for the summed values of the original a priori “Clinical”, “Communication” and “Professional and Personal” competency domains are the alternate Competency constructs 1, 2 and 3 respectively for the overall data. The reliability evaluation suggests that the supervisors more reliably assess a trainee’s “general clinical job performance” and communication skills than other competency domain constructs or individual competency constructs (Table 3).
Sensitivity analysis for data-reduction results with an exploratory Factor analysis
PAF was used for identification of a latent variable. The same Factor outcomes were obtained for the data-reduction analysis using PCA. The PAF for the overall data yielded a 3 Factor solution with the 3 Factors consisting of the same grouping of competency items as was obtained by PCA. Although the Factor loadings sizes were lower for PAF, all the same Factor loadings remained >0.50.
Factor stability among sub-groups
The sub-groups used to assess Factor stability for the overall group included female trainees (229 assessments), male trainees (145 assessments), Australian graduate trainees (232 assessments), staff specialist supervisors (169), visiting medical officer supervisors (139 assessments), surgeon as supervisors (110 assessments), physicians as supervisors (123 assessments), assessments preformed in the central hospital (TCH) (283 assessments), and the separate year analysis for 2007 (187 assessments) and 2008 (187 assessments). Apart from the surgical supervisor subgroup and the overseas trained graduates, those with a sample number >120 had sampling features indicating that the data was adequate for the Factor analysis model (information available on request).
Some sub-groups did not have sufficient data to allow an adequate PCA or PAF, and were not used for evaluating their effect on Factor stability. These included network hospitals alone (91 assessments), medical administrators as supervisor (63 assessments), emergency physicians as supervisors (75 assessments), female supervisors (107 assessments), and overseas trained graduates (145 assessments).
The subgroup analysis demonstrated that competency items for the subgroups of female trainees, Australian graduate trainees, the central hospital (TCH), surgeons, staff specialists, VMOs and the separation into single years (2007 and 2008), all collapsed into the same 3 constructs as defined in the whole population analysis (data not shown).
Three sub-groups had a different distribution of competency items in 3 Factors compared to the overall analysis, suggesting the presence of Factor instability in some subgroups. These were physicians as supervisors (123 assessments), male trainees (145 assessments), and male supervisors (267 assessments). All 3 of these latter subgroups had competency items collapse into the predefined “face value” constructs of competence (Table 4).
Discussion
This study raises the possibility that supervisors are able to more reliably assess a domain of competence consistent with a general professional job performance construct. Supervisors group together a set of competencies that differentiates a potentially useful construct about trainees’ competency which may only need 6 assessments for an adequately reliable assessment. This is much fewer than other individual competency items or pre-defined domain constructs in this population of supervisors and trainees. The caveat to such an observation is that it at present can only be implied for the population studied.
Construct validity: comparison with the literature
Past investigations have not made a great impact on improving this area of assessment. No consistent set of individual competency items or overall domain constructs have been developed. From the published literature there is no way of identifying what global judgements about clinical competence can be best made by supervisors, especially what can be generalised to different contexts. Moreover, the question is still not answered as to what the raters are assessing with the global performance assessments. Many of the issues raised in this study have been noted before (Kastner et al. 1984; Forsythe et al. 1986; Thompson et al. 1990). As identified by the authors of one of the more recent studies, there may be little to be gained by using multi-item forms in their current structure for assessing trainees’ clinical performance (Pulito et al. 2007).
The past reports of supervisors’ assessments of trainees’ competencies have made many similar observations to those of this current study. A large proportion of unexplained variance and only a small number of Factors have been identified in most studies. However marked variation exists about the criteria used to form the assessments as well as variation in the competency items used and the formats of the forms. The definitions of what the observed Factors may be measuring, that is Factor interpretation, also vary a great deal between previously reported studies. Some educators believe that noncognitive variables, such as involvement and motivation, may be more important in the assessment of competence than knowledge (Quarrick and Sloop 1972; Metheny 1991).
Even though there is no consistent agreement about what should be measured by supervisors, the characteristics combining to form a “general professional job performance” global competency would be valued in most work-based activities. This construct consisted of competency items that cross the predefined face-value construct domains of clinical competence, communication competence, professional behaviour competence, and overall competence. Hence this is a different construct needing an alternative interpretation and definition. As stated above, one such interpretation could be as a “general professional job performance” construct. The presence of a general job performance Factor is a well-documented observation for workplace job performance evaluation in the general workplace research literature (Viswesvaran et al. 2005) (Schmidt and Kaplan 1971) and possibly for medical competency assessment (Brumback and Howell 1972). The characteristics of our “general professional job performance” are similar to those described in the general workplace (Viswesvaran et al. 2005).
Reliability of supervisors’ assessment of global constructs
An aspect not well evaluated in the past is the reliability characteristics of the global constructs. Only two studies evaluated the reliability of Factor constructs by raters for trainees (Ramsey et al. 1993) (Pulito et al. 2007). To achieve a generalizability coefficient of at least 0.7, 11 physician-associate ratings were required for each competency area; and for the rating of overall clinical skills, 10 physician-associate ratings were required to achieve a generalizability coefficient of 0.7 (Ramsey et al. 1993). These values are of similar to those found in our study but for a lower level of reliability. Another recent study used intra-class correlation (ICC) and also demonstrated low inter-rater reliability among faculty preceptors in their evaluation of medical students (Pulito et al. 2007). This additional approach to assessing construct validity is useful for determining an adequate application in the workplace in a practical way and should be considered as a routine part of construct validation.
Stability of factors
Only a minority of previous studies evaluated the stability of Factors to evaluate the effect of different contexts, variables and/or raters. The majority of studies did not even attempt to establish whether the Factor structures found were stable across different subpopulations. Only one attempted a systematic evaluation of a number of potential influences on Factor stability (Silber et al. 2004). They found that a two Factor structure was stable for groups of specialties, and residents’ gender and training level (Silber et al. 2004). Others have shown that Factor structure in time periods in 1 year were reproducible (Dielman et al. 1980); and Factor loadings for peer and supervisor ratings are “quite similar” (Forsythe et al. 1985, 1986). However, others found different years of training produce different Factors (Gough et al. 1964). Different groups of evaluators of the same trainees rate trainees differently. For example Metheny and colleagues found each group used only one Factor and each group used a Factor entirely different to the others (Metheny 1991). We have shown both stability and instability. Factor structure stability in in different contexts, types of raters and types of trainees was stable, while some types of trainees and raters produced different Factor structures. Such variation highlights the probability that supervisors in different contexts rate differently and that some groups of trainees may be rated differently. This has important implications for high-stakes assessments and needs further investigation.
Limitations of the study
Many concerns exist about reducing individual competency items to Factors, and they all apply to the present study. The potential to “lose” information about individual competencies is problematic (Forsythe et al. 1986). A detailed understanding of an individual’s strengths and weaknesses is not possible, so global domain evaluations of performance may be “relatively useless” for performance counselling (King et al. 1980). “Forced” inferences may also be made about a clinician’s clinical and nonclinical effectiveness (Brumback and Howell 1972). The “need” to give a score will exaggerate the main method biases of halo, leniency and range restriction. An evaluation of the psychological and behavioural processes for each performance dimension is not possible (Schmidt and Kaplan 1971). Furthermore, simple data-reduction can hide the classic bias problems of rater-based decision making (Saal et al. 1980; Podsakoff et al. 2003) which is very relevant to supervisor assessments (Forsythe et al. 1986). These aspects are important given evidence that general mental ability and conscientiousness may be the dominant competency and behavioural constructs that influence job performance (Viswesvaran et al. 2005).
As an a priori decision, the extraction rules were not based on the most parsimonious Factor solution. This choice was made because of the ubiquitous problem of method bias which would reduce the number of Factor solutions. Because of this and other potential biases, theoretically interesting new constructs could be missed altogether if too few Factors are included in the data analysis. Exploration of uncertainty requires an ability to identify subsets of items that may reveal an otherwise hidden pattern in the data (Ruscio and Roche 2012). Since the Factors extracted were not to be considered definitive, the least parsimonious method was used to choose the number of Factors to be extracted. The changes in the Scree plot were used to define 3 Factors. The effects of this decision are illustrated by applying other extraction rules. The Kaiser Eigenvalue of 1 gave a 2 Factor solution. Parallel Analysis gave an initial Eigenvalue of 1.3 which gave only a 1 Factor solution. For Parallel Analysis eigenvalues are calculated for randomly generated data sets of the same dimensions (N cases with k items) (Velicer and Jackson 1990). For this method, data-sets are constructed at random from a population with no Factors, so that the eigenvalues for the random data differ from 1 due to sampling error alone. Therefore it is possible that a 3 Factor solution is incorrect. However, the 2 Factor PAF solution accounted for 53 % total explanatory variance and the one Factor PAF solution explained only 48 % of the variance. The 3 Factor PAF solution explained substantially more explanatory variance of 68.5 % (data not shown but available on request).
Future implications
Our observations require further investigation. Identifying confounding effects of variables that alter the reliability and validity of high-stakes assessments, especially any that may be changeable, would seem a mandatory requirement. The demonstration of possible Factor instability between institutions would also mean that separate evaluation of different training programmes and even different terms within training programs may be needed. Results in one institution may be different to another. Each training programme may have differing contextual characteristics that influence the validity of a supervisors’ assessment. However, firstly the observations need to be replicated in a larger population.
The testing of inferences about constructs identified by EFA needs to be considered a normal follow-on for construct validation since any defined competency constructs by EFA can only be considered tentative possibilities. Given the potential for major errors in construct interpretation because of common method biases (Podsakoff et al. 2003), the fitting response to any observations from an EFA is a follow-on study using confirmatory Factor analysis (McKinley and Boulet 2005) and/or other prospective hypothesis driven exploration (Forsythe et al. 1986). Such inquiry needs greater emphasis in validation studies for rater-based assessments. However, these types of hypothesis driven analyses often require larger sample populations, possibly needing multi-institutional studies rather than a local training context, particularly if multiple interaction variables are to be assessed (Schumacher and Lomax 2010).
That assessment standards need to be developed beyond traditional psychometric considerations (van der Vleuten and Schuwirth 2005) is now well accepted (Swing et al. 2009). Assessment method development should occur according to observable, applicable and reproducible standards such as reliability, validity, ease of use, resources required, ease of interpretation, and educational impact (Swing et al. 2009). Supervisors’ competency assessments usually are easy to use and interpret, require no additional resources, and are generally used as an essential part of postgraduate medical training. Our observations provide support to further investigate the concept of improving the construct validity of judgements made by supervisors. This is essential to improve the reliability and overall validity of these types of competency assessments.
Conclusions
Firstly, the results are consistent with earlier published research indicating that clinicians may be only able to view competence in a very small number of broad dimensions. Most supervisors in this study appear to be assessing a dominant construct domain which is similar to a general professional job performance concept. Second, in this study population, assessment reliability was improved by identifying the competency constructs that supervisors spontaneously align, and which together may represent a competency domain that they can more effectively evaluate. This effectiveness was identified by an increased ability to more consistently agree on competency achievement for the equivalent of a general professional job performance construct. Thirdly, Factor structure instability between different populations of supervisors and trainees means that some subpopulations of trainees may be assessed differently and that some subpopulations of supervisors are assessing the same trainees differently. There is a critical need for the standardisation of the criterion of competencies used by supervisors for supervisor’s assessments.
References
Baltagi, B. H., Song, S. H., & Jung, B. C. (2002). A comparative study of alternative estimators for the unbalanced 2-way error component regression model. Econometrics Journal, 5, 480–493.
Brumback, G. B., & Howell, M. A. (1972). Rating the clinical effectiveness of employed physicians. Journal of Applied Psychology, 56, 241–244.
Cook, D., Beckman, T., Mandrekar, J., & Pankratz, V. (2010). Internal structure of mini-CEX scores for internal medicine residents: Factor analysis and generalizability. Advances in Health Sciences Education, 15, 633–645.
Crossley, J., Johnson, G., Booth, J., & Wade, W. (2011). Good questions, good answers: Construct alignment improves the performance of workplace-based assessment scales. Medical Education, 45, 560–569.
Dielman, T. E., Hull, A. L., & Davis, W. K. (1980). Psychometric properties of clinical performance ratings. Evaluation and the Health Professions, 3, 103–117.
Fabrigar, L. R., Wegener, D. T., MacCallum, R. C., & Strahan, E. J. (1999). Evaluating the use of exploratory factor analysis in psychological research. Psychological Methods, 4, 272–299.
Field, A. (2005). Discovering statistics using SPSS (2nd ed.). London: Sage Publications.
Forsythe, G. B., McGaghie, W. C., & Friedman, C. P. P. (1985). Factor structure of the resident evaluation form. Educational and Psychological Measurement, 45, 259–264.
Forsythe, G. B., McGaghie, W. C., & Friedman, C. P. P. (1986). Construct validity of medical clinical competence measures: A multitrait-multimethod matrix study using confirmatory factor analysis. American Educational Research Journal, 23, 315–336.
Gingerich, A., Regehr, G., & Eva, K. W. (2011). Rater-based assessments as social judgments: Rethinking the etiology of rater errors. Academic Medicine, 86, S1–S7.
Ginsburg, S. M., McIlroy, J. P., Oulanova, O. M., Eva, K. P., & Regehr, G. P. (2010). Toward authentic clinical evaluation: Pitfalls in the pursuit of competency. Academic Medicine, 85, 780–786.
Gough, H. G., Hall, W. B. P., & Harris, R E Ph. (1964). Evaluation of performance in medical training. Journal of Medical Education, 39, 679–692.
Govaerts, M. J., van der Vleuten, C. P., Schuwirth, L. W., & Muijtjens, A. M. (2007). Broadening perspectives on clinical performance assessment: Rethinking the nature of in-training assessment. Advances in Health Sciences Education, 12, 239–260.
Hamdy, H., Prasad, K., Anderson, M. B., Scherpbier, A., Williams, R., Zwierstra, R., et al. (2006). BEME systematic review: Predictive values of measurements obtained in medical schools and future performance in medical practice. Medical Teacher, 28, 103–116.
Hawkins, R. E., Sumption, K. F., Gaglione, M. M., & Holmboe, E. S. (1999). The in-training examination in internal medicine: Resident perceptions and lack of correlation between resident scores and faculty predictions of resident performance. The American Journal of Medicine, 106, 206–210.
Henson, R. K., & Roberts, J. K. (2006). Use of exploratory factor analysis in published research. Educational and Psychological Measurement, 66, 393–416.
Hutchinson, L., Aitken, P., & Hayes, T. (2002). Are medical postgraduate certification processes valid? A systematic review of the published evidence. Medical Education, 36, 73–91.
Kaiser, H. F. (1960). The application of electronic computers to factor analysis. Educational and Psychological Measurement, 20, 141–151.
Kaiser, H. F. (1974). An index of factorial simplicity. Psychometrika, 39, 31–36.
Kastner, L., Gore, E., & Novack, A. H. (1984). Pediatric residents’ attitudes and cognitive knowledge, and faculty ratings. The Journal of Pediatrics, 104, 814–818.
King, L. M., Schmidt, F. L., & Hunter, J. E. (1980). Halo in a multidimensional forced-choice evaluation scale. Journal of Applied Psychology, 65, 507–516.
Kogan, J. R., Holmboe, E. S., & Hauer, K. S. (2009). Tools for direct observation and assessment of clinical skills of medical trainees: A systematic review. Journal of the American Medical Association, 302, 1316–1326.
Levine, H. G., & McGuire, C. H. (1971). Rating habitual performance in graduate medical education. Academic Medicine, 46, 306–311.
Lurie, S. J., Mooney, C. J., & Lyness, J. M. (2009). Measurement of the general competencies of the accreditation council for graduate medical education: A systematic review. Academic Medicine, 84, 301–309.
McGill, D., Van der Vleuten, C., & Clarke, M. (2011). Supervisor assessment of clinical and professional competence of medical trainees: A reliability study using workplace data and a focused analytical literature review. Advances in Health Sciences Education, 16, 405–425.
McKinley, D. W., & Boulet, J. R. (2005). Using factor analysis to evaluate checklist items. Academic Medicine RIME: Proceedings of the Forty-fourth Annual Conference, 80, S102–S105.
McLaughlin, K., Vitale, G., Coderre, S., Violato, C., & Wright, B. (2009). Clerkship evaluation: What are we measuring? Medical Teacher, 31, e36–e39.
Metheny, W. P. P. (1991). Limitations of physician ratings in the assessment of student clinical performance in an obstetrics and gynecology clerkship. Obstetrics and Gynecology, 78, 136–141.
Miller, A., & Archer, J. (2010). Impact of workplace based assessment on doctors’ education and performance: A systematic review. British Medical Journal, 341, c5064. doi:10.1136/bmj.c5064.
Norcini, J., & Burch, V. (2007). Workplace-based assessment as an educational tool: AMEE Guide No. 31. Medical Teacher, 29, 855–871.
Norman, G. R., & Streiner, D. L. (2008). Biostatistics. The Bare Essentials. (3rd ed.) Shelton, Connecticut: People’s Medical Publishing House.
Pett, M. A., Lackey, N. R., & Sullivan, J. J. (2003). Making sense of factor analysis. The use of factor analysis for instrument Development in Health Care Research. Thousand Oaks: Sage Publications.
Podsakoff, P. M., MacKenzie, S. B., Lee, J. Y., & Podsakoff, N. P. (2003). Common method biases in behavioral research: A critical review of the literature and recommended remedies. Journal of Applied Psychology, 88, 879–903.
Pulito, A. R., Donnelly, M. B., & Pylmale, M. (2007). Factors in faculty evaluation of medical students’ performance. Medical Education, 41, 667–675.
Quarrick, E. A., & Sloop, E. W. (1972). A method for identifying the criteria of good performance in a medical clerkship program. Journal of Medical Education, 47, 188–197.
Ramsey, P. G., Wenrich, M. D., Carline, J. D., Inui, T. S., Larson, E. B., & LoGerfo, J. P. (1993). Use of peer ratings to evaluate physician performance. Journal of the American Medical Association, 269(13), 1655–1660.
Regehr, G., Eva, K., Ginsburg, S., Halwani, Y., & Sidhu, R. (2011). Assessment in postgraduate medical education: Trends and issues in assessment in the workplace Members of the FMEC PG consortium.
Remmers, H. H., Shock, N. W., & Kelly, E. L. (1927). An empirical study of the validity of the Spearman-Brown formula as applied to the Purdue Rating Scale. The Journal of Educational Psychology, 18, 187–195.
Ruscio, J., & Roche, B. (2012). Determining the number of factors to retain in an exploratory factor analysis using comparison data of known factorial structure. Psychological Assessment, 24, 282–292.
Saal, F. E., Downey, R. G., & Lahey, M. A. (1980). Rating the ratings: Assessing the psychometric quality of rating data. Psychological Bulletin, 88, 413–428.
Sadler, D. R. (1989). Formative assessment and the design of instructional systems. Instructional Science, 18, 119–144.
Schmidt, F. L., & Kaplan, L. B. (1971). Composite versus multiple criteria: A review and resolution of the controversy. Personnel Psychology, 24, 419–434.
Schumacher, R. E., & Lomax, R. G. (2010). A beginner’s guide to structural equation modelling (3rd ed.). New York: Taylor and Francis Group.
Silber, C. G., Nasca, T. J., Paskin, D. L., Eiger, G., Robeson, M., & Veloski, J. J. (2004). Do global rating forms enable program directors to assess the ACGME competencies? Academic Medicine, 79, 549–556.
Streiner, D. L., & Norman, G. R. (2009). Health measurement scales. A pratcial guide to their development and use. (4th ed.) Oxford: Oxford University Press.
Swing, S. R., Clyman, S. G., Holmboe, E. S., & Williams, R. G. (2009). Advancing resident assessment in graduate medical education. Journal of Graduate Medical Education, 1, 278–286.
Tabachnick, B. G., & Fidell, L. S. (2007). Using multivariate statistics (5th ed.). Boston: Pearson Allyn and Bacon.
Thompson, W. G., Lipkin, M, Jr, Gilbert, D. A., Guzzo, R. A., & Roberson, L. (1990). Evaluating evaluation: Assessment of the American Board of Internal Medicine Resident Evaluation Form. Journal of General Internal Medicine, 5, 214–217.
van der Vleuten, C. P. M. (1996). The assessment of professional competence: Developments, research and practical implications. Advances in Health Sciences Education, 1, 41–67.
van der Vleuten, C. P., & Schuwirth, L. W. (2005). Assessing professional competence: From methods to programmes. Medical Education, 39, 309–317.
Velicer, W. F., & Jackson, D. N. (1990). Component analysis versus common factor analysis: Some issues in selecting an appropriate procedure. Multivariate Behavioral Research, 25, 1.
Viswesvaran, C., Schmidt, F. L., & Ones, D. S. (2005). Is there a general factor in ratings of job performance? A meta-analytic framework for disentangling substantive and error influences. Journal of Applied Psychology, 90, 108–131.
Wass, V., Van der Vleuten, C., Shatzer, J., & Jones, R. (2001). Assessment of clinical competence. The Lancet, 357, 945–949.
Williams, R. G., Klamen, D. A., & McGaghie, W. C. (2003). Cognitive, social and environmental sources of bias in clinical performance ratings. Teaching and Learning in Medicine, 15, 270–292.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1

Appendix 2: Sampling adequacy
Assessing the characteristics of the correlation matrix between the competency items: No items have a correlation r > 0.80 indicating that multicollinearity is less likely to be a problem (Appendix Table 5). No items have an r-value < 0.30 indicating that there is sufficient shared variance. The Pearson correlation coefficient for all pairs had a significance level with p-value < 0.001. Since all r-values were <0.80 and >0.30, all variables were included in the component analysis. Although the determinant is less useful in PCA, it was identified as being <0.001. A determinant >1 × 10−5 can be due to the fact that a number of items are strongly correlated with each other (r > 0.60) and possibly some other items may be redundant. However a very low value does not allay concerns about multicollinearity as being a problem.
Common variance represents the variance that is shared between a set of items that can be explained by a set of common factors. Specific or unique variance is the variance specific to a particular variable that is not shared with other items in the correlation matrix but may be shared with other items excluded from the matrix. Error variance is the measurement error. Some use the internal consistency coefficient α to assess error variance (Cronbach’s α = 0.935 and Cronbach’s Alpha Based on Standardized Items = 0.935 for 14 items). Taking into account the matrix and the limitations of the matrix design with repeated measures from trainees and supervisors, the error variance can be calculated as (1 − α2). The “measurement error” value is (1 − 0.9352 = 0.1258); so the total percent variance for “measurement error” is 12.6 %. Most of the variance comes from the sources of variance other than “measurement error”, taking into account that supervisor variance can be considered measurement error.
The anti-image matrices contain the negative partial covariances and correlations. They can give an indication of correlations which aren’t due to the common factors. Small values for the anti-image correlation indicate that the variables are relatively free of unexplained correlations. Most or all values off the diagonal should be small (close to zero) in the anti-image correlation matrix (Field 2005) p650 (Norman and Streiner 2008) p197. Each value on the diagonal of the anti-image correlation matrix shows the Measure of Sampling Adequacy (MSA) for the respective item (Appendix Table 6). All values for the MSA are >0.700 and all the values on the “off-diagonal” are small, except for clinical skills and clinical judgement, emergency skills and knowledge base, emergency skills and procedural skills, teamwork skills and communication, professional responsibility and teamwork skills, professional obligations and awareness of limitations, medical records and teaching and learning, and medical records and time management, indicating that most but not all variables fit the structure well.
The Kaiser–Meyer–Olkin measure of sampling adequacy tests whether the partial correlations among variables are small. Bartlett’s test of sphericity tests whether the correlation matrix is an identity matrix, which would indicate that the factor model is inappropriate. The significance level gives the result of the test. Very small values (less than 0.05) indicate that there are probably significant relationships among the variables. A value higher than about 0.10 or so may indicate that the data are not suitable for factor analysis.
The matrix of the competency items has a significant Bartlett’s test of sphericity so there is probably a sufficient sample size (Appendix Table 8). A Kaiser–Meyer–Olkin (KMO) Test with a KMO value above 0.90 supports the conclusion that the correlation matrix is not an identity matrix Table (Appendix Table 8). The KMO statistic (0.935) also indicates that the sample size is sufficient relative to the number of items (Kaiser 1974). The measures of sample adequacy are all above 0.90 as assessed in the anti-image covariance matrix (Appendix 1 Table 6) indicating that the correlations among the individual items are strong enough to indicate that a factor analysis of the correlation matrix is appropriate. In summary, the KMO statistic indicates that factor analysis is most likely appropriate for the data (See Appendix Tables 5, 6, 7, 8, 9, 10, 11).
Rights and permissions
About this article
Cite this article
McGill, D.A., van der Vleuten, C.P.M. & Clarke, M.J. A critical evaluation of the validity and the reliability of global competency constructs for supervisor assessment of junior medical trainees. Adv in Health Sci Educ 18, 701–725 (2013). https://doi.org/10.1007/s10459-012-9410-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10459-012-9410-z