
Abstract
It is well-known that the naive bootstrap yields inconsistent inference in the context of data envelopment analysis (DEA) or free disposal hull (FDH) estimators in nonparametric frontier models. For inference about efficiency of a single, fixed point, drawing bootstrap pseudo-samples of size m < n provides consistent inference, although coverages are quite sensitive to the choice of subsample size m. We provide a probabilistic framework in which these methods are shown to valid for statistics comprised of functions of DEA or FDH estimators. We examine a simple, data-based rule for selecting m suggested by Politis et al. (Stat Sin 11:1105–1124, 2001), and provide Monte Carlo evidence on the size and power of our tests. Our methods (i) allow for heterogeneity in the inefficiency process, and unlike previous methods, (ii) do not require multivariate kernel smoothing, and (iii) avoid the need for solutions of intermediate linear programs.



Similar content being viewed by others

Notes
FDH estimators are also widely used, though not as widely as DEA estimators. On 11 August 2010, a search with Google Scholar using the keywords “fdh”, “input”, “output”, and “efficiency” returned approximately 2,080 results. Statistical properties of FDH estimators have been examined by Korostelev et al. (1995a), Park et al. (2000), Wheelock and Wilson (2008), and Wilson (2010).
Convexity of the production set is typically assumed in the microeconomic theory of the firm for convenience. However, there may be cases where the assumption is violated, and there is no theorem saying that production sets are necessarily convex.
By “nondegenerate,” we mean the distribution is not a probability mass at a single point.
The argument used here is standard; in addition, it is straightforward to verify that the result also holds in the unrestricted case where \({P\in{\mathbb P}}\). The only difference will be in the expressions for the mean and the variance of \({\tau_n({\mathcal S}_n)}\) that appear in Eqs. 35 and 36. Of course, to satisfy the Lyapunov condition an additional technical regularity condition on the random variable \(T(\user2{Z})\) is needed. In particular, \(T(\user2{Z})\) must have finite moments up to order 4 (when H 0 is true, \({P\in{\mathbb P}_0}\) and \(T(\user2{Z})\) is a degenerate random variable equal to zero). Hence, for \({P\in {\mathbb P}}\),
$$ \sqrt{n} \left(\tau_n({\mathcal S}_n) -\left(\tau(P)+ \mu_Q/n^{\kappa}\right)\right) {\mathop{\longrightarrow}\limits^{\mathcal L}}\, {\mathcal N} \left(0,\sigma^2_Q/n^{2\alpha} + O\left(n^{-\kappa}\right)\sigma(P) +\sigma^2(P) \right). $$Note that the rate of convergence is slower when the null is false.
Of course, situations involving more than one output can be easily handled using our methods; here, we use only one output to simplify the process of simulating data. In all of the theoretical results about properties of DEA and FDH estimators, including Korostelev et al. (1995a, b), Park et al. (2000, 2010), Kneip et al. (1998, 2008, 2010), Gijbels et al. (1999), and Wilson (2010), it is the dimensionality (p + q) rather than the ratio p/q that is important for determining properties of the estimators; consequently, we expect no loss of generality from simulating only one output.
The interval given by Eq. 19 is a special case of this, where \({\widehat \theta}\) is the VRS-DEA estimator.
Results from the experiments using the m-bootstrap are available in a separate appendix, available on-line at http://www.stat.ucl.ac.be/ISpub/ISdp.html/.
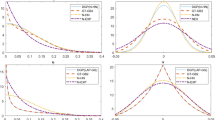
Figure A.1 in the separate appendix mentioned in footnote 8 shows plots of rejection rates versus subsample sizes analogous to those in Fig. 2, except that the rejection rates depicted in Fig. A.1 are those obtained using the m-bootstrap. Comparing the results shown in the two figures, it is apparent that for given dimensionality (p + q) and sample size n, the optimal subsample size m is smaller when resampling is done with replacement as opposed to without replacement. In addition, holding dimensionality and sample size constant, resampling with replacement typically results in less test power than resampling without replacement for given subsample sizes and departures from the null.
Results for tests of convexity based on the statistic \({{\widehat \tau}_1({\mathcal S}_n)}\) defined in Eq. 42 are available in the separate appendix mentioned in footnote 8.
Of course, the null hypothesis in our test is a composite hypothesis. We have considered only two values of δ where the null is true while the size of the test is equal to the supremum of rejection rates for each value of δ ∈ (0,1].
Trials represented in Fig. 3 were chosen by generating uniform random integers between 1 and 1,024 (inclusive).
Results for convexity tests based on the LFDH estimator are available in the separate appendix mentioned in footnote 8.
Similar results from experiments using the m-bootstrap appear in Tables A.7–A.8 of the separate appendix.
In our experiments with unbalanced resampling, setting the bootstrap efficiency estimator equal to one when the estimate is infeasible amounts to recognizing that the particular bootstrap replication has no useful information for inference, and avoids imposing conditioning in the bootstrap world that is not present in the real world. This does not alter the asymptotic properties of our bootstrap. A similar device was used by Jeong and Simar (2006).
References
Banker RD (1993) Maximum likelihood, consistency and data envelopment analysis: a statistical foundation. Manag Sci 39:1265–1273
Banker RD (1996) Hypothesis tests using data envelopment analysis. J Prod Anal 7:139–159
Beran R, Ducharme G (1991) Asymptotic theory for bootstrap methods in statistics. Centre de Reserches Mathematiques, University of Montreal, Montreal
Bickel PJ, Freedman DA (1981) Some asymptotic theory for the bootstrap. Ann Stat 9:1196–1217
Bickel PJ, Sakov A (2008) On the choice of m in the m out of n bootstrap and confidence bounds for extrema. Stat Sin 18:967–985
Bretagnolle J (1983) Lois limites du bootstrap des certaines fonctionnelles. Ann Inst Henri Poincare (Sect B) 19:223–234
Charnes A, Cooper WW, Rhodes E (1978) Measuring the efficiency of decision making units. Eur J Oper Resarch 2:429–444
Charnes A, Cooper WW, Rhodes E (1979) Measuring the efficiency of decision making units. Eur J Oper Res 3:339
Debreu G (1951) The coefficient of resource utilization. Econometrica 19:273–292
Deprins D, Simar L, Tulkens H (1984) Measuring labor inefficiency in post offices. In: Pestieau MMP, Tulkens H (eds) The performance of public enterprises: concepts and measurements. North-Holland, Amsterdam, pp 243–267
Efron B (1979) Bootstrap methods: another look at the jackknife. Ann Stat 7:1–16
Färe R (1988) Fundamentals of production theory. Springer, Berlin
Färe R, Grosskopf S, Lovell CAK (1985) The measurement of efficiency of production. Kluwer-Nijhoff Publishing, Boston
Farrell MJ (1957) The measurement of productive efficiency. J R Stat Soc A 120:253–281
Gijbels I, Mammen E, Park BU, Simar L (1999) On estimation of monotone and concave frontier functions. J Am Stat Assoc 94:220–228
Härdle W, Mammen E (1993) Comparing nonparametric versus parametric regression fits. Ann Stat 21:1926–1947
Jeong SO (2004) Asymptotic distribution of DEA efficiency scores. J Korean Stat Soc 33:449–458
Jeong SO, Simar L (2006) Linearly interpolated FDH efficiency score for nonconvex frontiers. J Multivar Anal 97:2141–2161
Kittelsen SAC (1999) Monte Carlo simulations of DEA efficiency measures and hypothesis tests. Unpublished working paper, memorandum no. 09/99, Department of Economics, University of Oslo, Norway
Kneip A, Park B, Simar L (1998) A note on the convergence of nonparametric DEA efficiency measures. Econom Theory 14:783–793
Kneip A, Simar L, Wilson PW (2008) Asymptotics and consistent bootstraps for DEA estimators in non-parametric frontier models. Econom Theory 24:1663–1697
Kneip A, Simar L, Wilson PW (2010) A computationally efficient, consistent bootstrap for inference with non-parametric DEA estimators. Comput Econ (forthcoming)
Korostelev A, Simar L, Tsybakov AB (1995a) Efficient estimation of monotone boundaries. Ann Stat 23:476–489
Korostelev A, Simar L, Tsybakov AB (1995b) On estimation of monotone and convex boundaries. Publ Inst Stat Univ Paris XXXIX 1:3–18
Mammen E (1992) When does bootstrap work? Asymptotic results and simulations. Springer, Berlin
Park BU, Simar L, Weiner C (2000) FDH efficiency scores from a stochastic point of view. Econom Theory 16:855–877
Park BU, Jeong S-O, Simar L (2010) Asymptotic distribution of conical-hull estimators of directional edges. Ann Stat 38:1320–1340
Politis DN, Romano JP (1994) Large sample confidence regions based on subsamples under minimal assumtions. Ann Stat 22:2031–2050
Politis DN, Romano JP (1999) Subsampling. Springer, New York
Politis DN, Romano JP, Wolf M (2001) On the asymptotic theory of subsampling. Stat Sin 11:1105–1124
Serfling RJ (1980) Approximation theorems of mathematical statistics. Wiley, New York
Shephard RW (1970) Theory of cost and production functions. Princeton University Press, Princeton
Simar L (1996) Aspects of statistical analysis in DEA-type frontier models. J Prod Anal 7:177–185
Simar L, Wilson PW (1998) Sensitivity analysis of efficiency scores: how to bootstrap in nonparametric frontier models. Manag Sci 44:49–61
Simar L, Wilson PW (1999a) Some problems with the Ferrier/Hirschberg bootstrap idea. J Prod Anal 11:67–80
Simar L, Wilson PW (1999b) Of course we can bootstrap DEA scores! But does it mean anything? Logic trumps wishful thinking. J Prod Anal 11:93–97
Simar L, Wilson PW (2000a) A general methodology for bootstrapping in non-parametric frontier models. J Appl Stat 27:779–802
Simar L, Wilson PW (2000b) Statistical inference in nonparametric frontier models: the state of the art. J Prod Anal 13:49–78
Simar L, Wilson PW (2001a) Nonparametric tests of returns to scale. Eur J Oper Res 139:115–132
Simar L, Wilson PW (2001b) Testing restrictions in nonparametric efficiency models. Commun Stat 30:159–184
Swanepoel JWH (1986) A note on proving that the (modified) bootstrap works. Commun Stat Theory Methods 15:3193–3203
van der Vaart AW (2000) Asymptotic statistics. Cambridge University Press, Cambridge
Wheelock DC, Wilson PW (2008) Non-parametric, unconditional quantile estimation for efficiency analysis with an application to Federal Reserve check processing operations. J Econom 145:209–225
Wilson PW (2008) FEAR: a software package for frontier efficiency analysis with R. Socio Econ Plan Sci 42:247–254
Wilson PW (2010) Asymptotic properties of some non-parametric hyperbolic efficiency estimators. In: van Keilegom I, Wilson PW (eds) Exploring research frontiers in contemporary statistics and econometrics. Physica-Verlag, Berlin (forthcoming)
Acknowledgments
We have benefited from discussions with Peter Bickel, Alois Kneip, and Jean-Marie Rolin. Financial support from the “Interuniversity Attraction Pole”, Phase VI (No. P6/03) from the Belgian Government (Belgian Science Policy) and from the Chair of Excellency “Pierre de Fermat”, Région Midi-Pyrénées, France are gratefully acknowledged. This work was made possible by the Palmetto cluster maintained by Clemson Computing and Information Technology (CCIT) at Clemson University; we are grateful for technical support by the staff of CCIT. The usual caveats apply.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Simar, L., Wilson, P.W. Inference by the m out of n bootstrap in nonparametric frontier models. J Prod Anal 36, 33–53 (2011). https://doi.org/10.1007/s11123-010-0200-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-010-0200-4
Keywords
- Nonparametric frontier
- Efficiency
- Bootstrap
- Nonparametric testing
- Testing convexity
- Testing returns to scale